
版权声明:本站对所有站内资源拥有版权,严禁用于商业用途,侵权必究
访问2024年7月最新第4版教材官网


本教材官网为“高校大数据课程公共服务平台”的11大工程中的“1号子工程”
《大数据技术原理与应用(第2版)》
ISBN:978-7-115-44330-4 定价:49.80元
人民邮电出版社 2017年1月第2版
访问2024年7月第4版教材官网
作者:林子雨(ziyulin@xmu.edu.cn, https://dblab.xmu.edu.cn/post/linziyu)
祝贺《大数据技术原理与应用》课程视频在中国大学MOOC上线(观看视频)
祝贺《大数据技术原理与应用》课程荣获“2018年国家精品在线开放课程”
祝贺进阶级大数据教材《Spark编程基础(Scala版)》正式出版(教材官网)
工信部”全国云计算及大数据应用技术人才培训考试项目”唯一指定大数据教材
荣获中国工信出版传媒集团2018年优秀出版物奖
2019年福建省精品在线开放课程
全国众多高校大数据课程选用本教材,高校大数据入门课程首选教材
京东、当当等各大网店畅销书籍,累计销量突破10万册
荣获“人民邮电出版社2017年度好书”
入门级精品教材,丰富的教材配套资源帮助读者实现“零基础”学习大数据

扫一扫手机访问本主页
教材配套资源快速访问链接
1.开课申请表(下载)、教学进度表(下载)和教学大纲(下载)
2.教材配套讲义PPT(下载)
3.教材配套授课视频(观看视频)
4.教材配套实验指导书《大数据基础编程、实验和案例教程》(教材官网)
5.教材配套大数据软件安装使用和基础编程实践指南(访问)
6.大数据实验环境虚拟机镜像文件(下载)
7.教材配套上机实验题目和答案、课后习题(选择题)题目和答案(请老师发送邮件索取:ziyulin@xmu.edu.cn)
8.教材配套课后上机练习题目(访问)
9.教材配套教师备课指南(访问)
10.教材配套综合实验案例(访问)
11.教材配套机房上机实验指南(访问)
12.学习本教材之后的进阶学习教材:林子雨编著《Spark编程基础》(教材官网)
13.全国高校大数据课程师资培训班(报名主页)
14.本教材配套MOOC课程制作过程全记录与经验分享(访问)
15.采用本教材教学的厦门大学大数据示范班级(访问)
16.在阿里云中搭建大数据实验环境(访问)
17.高校大数据实训课程系列案例教材(访问)
18.高校大数据实训课程样板工程(访问)
19.第15期全国高校大数据课程教师培训交流班(Hadoop+Spark综合班,线上培训,暑假,2020年7月25日-30日)(报名主页)
祝贺《大数据技术原理与应用》课程视频在中国大学MOOC上线(观看视频)




-485x680.jpg)
林子雨,男,1978年出生,博士,现为厦门大学计算机科学系副教授,曾任厦门大学信息科学与技术学院院长助理、晋江市发展和改革局副局长。现为中国计算机学会数据库专业委员会委员,中国计算机学会信息系统专业委员会委员,厦门市计算机学会理事。中国高校首个“数字教师”提出者和建设者,厦门大学数据库实验室负责人,厦门大学云计算与大数据研究中心主要建设者和骨干成员。于2001年获得福州大学水利水电专业学士学位,2005年获得厦门大学计算机专业硕士学位,2009年获得北京大学计算机专业博士学位。主要研究方向为数据库、数据仓库、数据挖掘、大数据、云计算和物联网,并以第一作者身份在《软件学报》《计算机学报》和《计算机研究与发展》等国家重点期刊以及国际学术会议上发表多篇学术论文。作为项目负责人主持的科研项目包括1项国家自然科学青年基金项目(No.61303004)、1项福建省自然科学青年基金项目(No.2013J05099)和1项中央高校基本科研业务费项目(No.2011121049)。
高校大数据课程公共服务平台,由中国高校首个“数字教师”的提出者和建设者——林子雨老师发起,由厦门大学数据库实验室全力打造,由厦门大学云计算与大数据研究中心、海峡云计算与大数据应用研究中心携手共建。平台从2013年5月开始建设,2015年8月1日完成1号工程(教材出版),2015年11月2日,平台正式上线。这是国内第一个服务于高校大数据课程建设的公共服务平台,旨在促进国内高校大数据课程体系建设,提高大数据课程教学水平,降低大数据课程学习门槛,提升学生课程学习效果。
平台重点打造“13个1工程”,即1本教材(含官网)、1个教师服务站、1个学生服务站、1个公益项目、1堂巡讲公开课、1个示范班级、1门在线课程、1个交流群(QQ群、微信群)、1个保障团队、1个培训交流基地、1个实验平台、1个课程群和1个微信公众号。
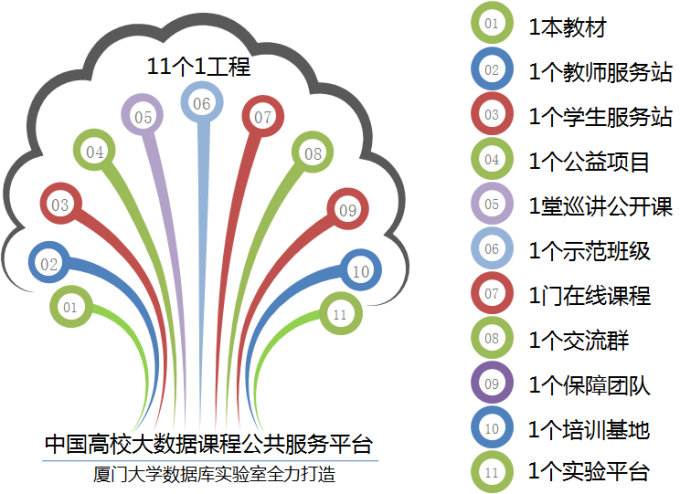
高校大数据课程公共服务平台,是一个开放的平台,不断进步提升的平台,热忱欢迎国内高校热爱大数据教学的开拓创新者加入平台,为平台建设添砖加瓦,共同推进中国高校大数据教学事业不断迈上新的台阶。
(本教材已经由人民邮电出版社正式出版发行,已经在当当网、京东商城等各大网店上架销售)
《大数据技术原理与应用(第2版)》
人民邮电出版社 ISBN:978-7-115-44330-4 定价:49.80元
|
正 书 名 |
大数据技术原理与应用(第2版) |
||
|
责任者及著作方式 |
林子雨 编著 |
||
|
文种、各种文字对照 |
简体中文 |
||
|
第一责任者及著作方式 |
林子雨 编著 |
||
|
版 次 |
2 |
印 次 |
1 |
|
出 版 者 |
人民邮电出版社 |
出版年月 |
2017年1月第2版 |
|
页数或卷册数 |
283 |
印张 |
轻型纸 |
|
开本尺寸 |
16开 |
成品尺寸 |
185X260 |
|
字 数 |
487000 |
印 数 |
3000册 |
|
正丛书名 |
大数据创新人才培养系列 |
||
|
ISBN |
978-7-115-44330-4 |
定价 | 49.80元 |
|
内容简介 |
(1) 概念篇:介绍当前紧密关联的最新IT领域技术云计算、大数据和物联网。(2) 大数据存储篇:介绍分布式数据存储的概念、原理和技术,包括HDFS、HBase、NoSQL数据库、云数据库。(3) 大数据处理与分析篇:介绍MapReduce分布式编程框架、基于内存的分布式计算框架Spark、图计算、流计算。(4) 大数据应用篇:介绍基于大数据技术的推荐系统。 |
||
|
网店销售 |
|||
|
教材使用者 |
工信部”全国云计算及大数据应用技术人才培训考试项目”唯一指定大数据教材 |
||
本书系统介绍了大数据相关知识,全书共有15章,系统地论述了大数据的基本概念、大数据处理架构Hadoop、分布式文件系统HDFS、分布式数据库HBase、NoSQL数据库、云数据库、分布式并行编程模型MapReduce、基于内存的分布式计算框架Spark、流计算、图计算、数据可视化以及大数据在互联网、生物医学和物流等各个领域的应用。在Hadoop、HDFS、HBase、MapReduce和Spark等重要章节,安排了入门级的实践操作,让读者更好地学习和掌握大数据关键技术。
本书可以作为高等院校计算机专业、信息管理等相关专业的大数据课程教材,也可供相关技术人员参考、学习、培训之用。

上图是2017年2月第2版教材封面

上图是2015年8月第1版教材封面
(第1版 教材前言)
大数据作为继云计算、物联网之后IT行业又一颠覆性的技术,备受关注。大数据无处不在,包括金融、汽车、零售、餐饮、电信、能源、政务、医疗、体育、娱乐等在内的社会各行各业,都融入了大数据的印迹,大数据对人类的社会生产和生活必将产生重大而深远的影响。
大数据时代的到来,迫切需要高校及时建立大数据技术课程体系,为社会培养和输送一大批具备大数据专业素养的高级人才,满足社会对大数据人才日益旺盛的需求。本书定位为大数据技术入门教材,为读者搭建起通向“大数据知识空间”的桥梁和纽带。本书将系统梳理总结大数据相关技术,介绍大数据技术的基本原理和大数据主要应用,帮助读者形成对大数据知识体系及其应用领域的轮廓性认识,为读者在大数据领域“深耕细作”奠定基础、指明方向。在本书的基础上,感兴趣的读者可以通过其他诸如《Hadoop权威指南》等工具书,继续深入学习和实践大数据相关技术。
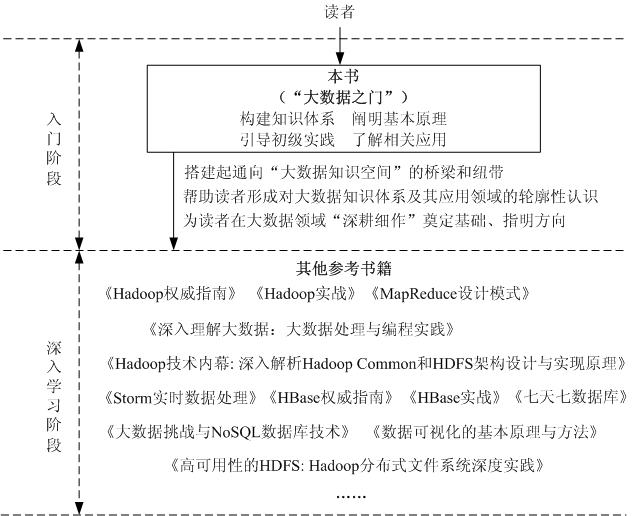
本书紧紧围绕“构建知识体系、阐明基本原理、引导初级实践、了解相关应用”的指导思想,对大数据知识体系进行系统梳理,做到“有序组织、去粗取精、由浅入深、渐次展开”。本书共分四大部分,包括大数据基础篇、大数据存储篇、大数据处理与分析篇和大数据应用篇。在大数据基础篇中,第一章介绍大数据的基本概念和应用领域,并阐述大数据、云计算和物联网的相互关系;第二章介绍大数据处理架构Hadoop,由于Hadoop已经成为应用最为广泛的大数据技术,因此,本书的大数据相关技术主要围绕Hadoop展开,包括Hadoop MapReduce、HDFS和HBase,因此,该章是后面其他章节(第三、四、七章)内容的基础。在大数据存储篇中,用五个章节(第三、四、五、六章)的内容,分别介绍了大数据存储相关技术的概念与原理,包括分布式文件系统HDFS、分布式数据库HBase、NoSQL数据库和云数据库。在大数据处理与分析篇,首先在第七章介绍了大数据处理和分析的核心技术——分布式并行编程模型MapReduce,然后,在第八章和第九章分别介绍了大数据时代两种新兴的数据分析技术——流计算和图计算,最后在第十章简单介绍了可视化技术。在大数据应用篇,用三章(第十一、十二、十三)内容介绍了大数据在互联网、生物医学和物流等各个领域的典型应用。
本书面向高校计算机专业和信息管理等相关专业的学生,可以作为专业必修课或选修课教材。在教学过程中,建议安排32个授课学时,16个教学周,每周2学时,每个章节的具体学时分配如下:第一、二、五、六、八、十、十一每个章节安排2个学时;第三、四、九章每个章节安排4个学时;第七章安排6个学时;第十二、十三章这两章内容由学生自学完成。
本书由林子雨执笔。在撰写过程中,厦门大学计算机科学系硕士研究生刘颖杰、叶林宝、蔡珉星、李雨倩、谢荣东、罗道文以及本科生黄梓铭、李粲等同学做了大量辅助性工作,在此,向这些同学的辛勤工作表示衷心的感谢。
本书官方网站是https://dblab.xmu.edu.cn/post/bigdata/,提供教学PPT和相关资料下载,并接受错误反馈和发布教材勘误信息。
本书在撰写过程中,我参考了大量国内外教材、专著、论文和资料,对大数据知识进行了系统梳理,有选择性地把一些重要知识纳入本书。本书也是我多年在数据科学领域从事教学、科研、产业方面工作的系统总结。但是,本人才疏学浅,难免有许多不足之处,望学术同仁不吝赐教。
厦门大学计算机科学系数据库实验室
林子雨
2015年3月,于厦门
(第2版 教材前言)
《大数据技术原理与应用》第1版于2015年8月出版,虽然距今仅有一年左右的时间,但是,在过去一年里,大数据技术发展迅猛,诸如Spark等新技术迅速崛起,开始改变Hadoop一枝独秀的市场格局。因此,我们及时对第1版内容进行了补充和修改,以适应大数据技术的快速发展,保持本书的先进性和实用性。
本书依然沿用第1版的篇章设计,共分四大部分,包括大数据基础篇、大数据存储与管理篇、大数据处理与分析篇和大数据应用篇。在大数据基础篇中,第1章介绍大数据的基本概念和应用领域,并阐述大数据、云计算和物联网的相互关系;第2章介绍大数据处理架构Hadoop,并补充介绍了Hadoop版本演化。在大数据存储与管理篇中,第3章介绍了分布式文件系统HDFS,在编程实践部分根据最新版本的API进行了修订;第4章介绍了分布式数据库HBase,在编程实践部分根据最新版本的API进行了修订;第5章介绍了NoSQL数据库;第6章介绍了云数据库。在大数据处理与分析篇,首先在第7章介绍了分布式并行编程模型MapReduce,然后,在新增的第8章中对Hadoop进行了再探讨,介绍了Hadoop的发展演化和一些新特性,并在新增的第9章中介绍了当前比较热门的、基于内存的分布式计算框架Spark,接下来,在第10章和第11章分别介绍了两种典型的大数据分析技术——流计算和图计算,最后在第12章简单介绍了可视化技术。在大数据应用篇,用3章(第13章~第15章)内容介绍了大数据在互联网、生物医学和物流等领域的典型应用。
本书第1版于2015年8月出版后,厦门大学数据库实验室建设了与本书配套的“中国高校大数据课程公共服务平台”(https://dblab.xmu.edu.cn/post/bigdata-teaching-platform/),为教师教学和学生学习大数据课程提供讲义PPT、学习指南、备课指南、上机习题、实验指南、技术资料、授课视频等全方位、一站式免费服务,并提供面向全国高校的大数据实验平台建设方案和大数据课程师资培训服务。
本书已经作为厦门大学计算机科学系大数据课程教材,根据近几年教学实践,建议安排32学时理论课,16个教学周,每周2学时。每章的具体学时分配如下:第1、3、4、5、6、8、10、11、12、13章每章安排2学时;第2、7、9章每章安排4学时;第14、15章这两章内容由学生自学完成。对于已经建设大数据教学实验室的高校,可以增加16学时上机实践课,分成4次上机课,每次连续4节课,“中国高校大数据课程公共服务平台”的“教师服务站”为本书提供了配套的上机实验指南。
本书第1版出版后,笔者收到了大量的读者来信,对本书提出了许多宝贵的改进意见和建议,这里表示衷心的感谢。同时,笔者举办了多期全国高校大数据课程教师培训交流班和全国高校大数据教学论坛,开展了全国高校大数据公开课巡讲计划与辅助国内高校开设大数据课程公益项目,建立了大数据课程教师交流群,与全国高校大数据课程教师进行了广泛的接触、沟通和交流,更好地了解了当前国内高校大数据教学发展需求和前进方向,这也为本书第2版撰写奠定了很好的基础。这里向参与交流的全国高校大数据课程教师表示衷心的感谢!
本书由林子雨执笔。在撰写第2版过程中,厦门大学计算机科学系硕士研究生蔡珉星、李雨倩、谢荣东、罗道文、邓少军、阮榕城、薛倩、魏亮、曾冠华等做了大量辅助性工作,在此,向这些同学的辛勤工作表示衷心的感谢。
大数据技术发展日新月异,在今后的工作中,笔者以及厦门大学数据库实验室会持续跟踪大数据技术发展趋势,把大数据最新技术和本书相关补充资料及时发布到“中国高校大数据课程公共服务平台”,方便本书读者通过网络及时免费获取相关信息。由于笔者能力有限,本书难免存在不足之处,望广大读者不吝赐教。
林子雨
厦门大学计算机科学系数据库实验室
2016年9月
第一篇 大数据基础
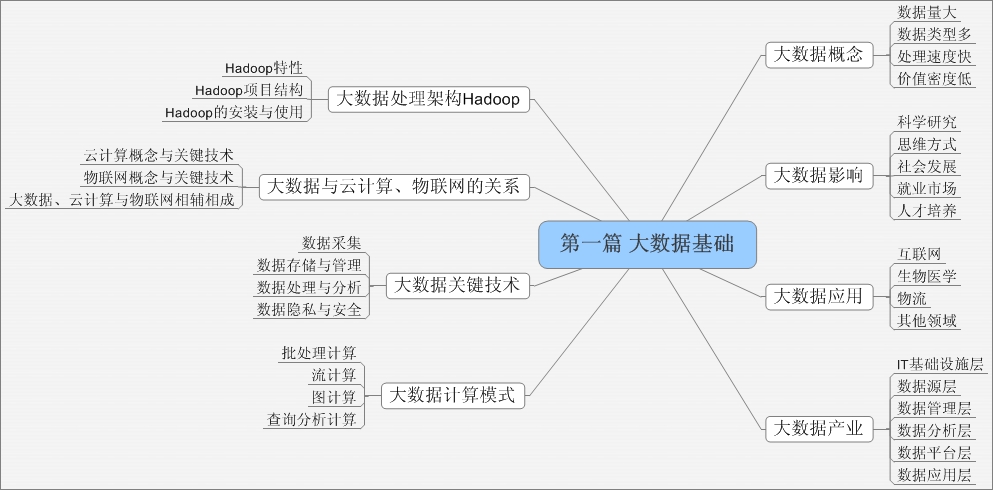
本篇内容介绍大数据(Big Data)的基本概念、影响和应用领域,并阐述大数据、云计算和物联网的相互关系,同时还将介绍大数据处理架构Hadoop。由于Hadoop已经成为应用最为广泛的大数据技术,因此,本书的大数据相关技术主要围绕Hadoop展开,包括Hadoop MapReduce、HDFS和HBase。本篇内容是理解后续其他篇章内容的基础。
本篇包括2章。第一章介绍大数据的概念和应用,分析了大数据、云计算和物联网的相互关系;第二章介绍大数据处理架构Hadoop。
第二篇 大数据存储
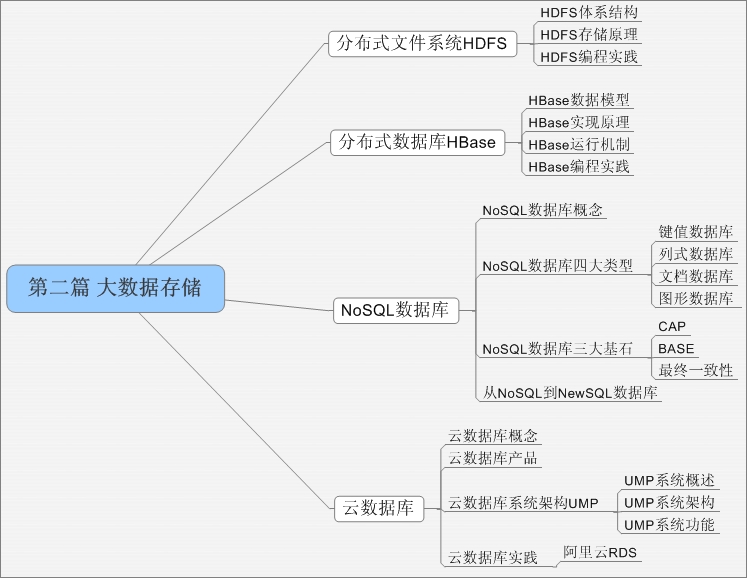
本篇介绍大数据存储相关技术的概念与原理,包括分布式文件系统HDFS、分布式数据库HBase、NoSQL数据库和云数据库。HDFS提供了在廉价服务器集群中进行大规模分布式文件存储的能力。HBase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要用来存储非结构化和半结构化的松散数据。NoSQL数据库可以支持超大规模数据存储,灵活的数据模型可以很好地支持Web2.0应用,具有强大的横向扩展能力,可以有效弥补传统关系型数据库的不足。云数据库是部署和虚拟化在云计算环境中的数据库,可以将用户从繁琐的数据库硬件定制中解放出来,同时让用户拥有强大的数据库扩展能力,满足各种不同类型用户的数据存储需求。需要特别指出的是,虽然云数据库在概念上更偏向于云计算的范畴,但是,云计算和大数据是密不可分的两种技术,不能割裂看待,而且,了解云数据库有助于拓展对大数据存储和管理方式的认识,因此,本篇内容介绍了云数据库的概念和相关产品。
本篇包括4章。第三章介绍分布式文件系统HDFS;第四章介绍分布式数据库HBase;第五章介绍NoSQL数据库;第六章介绍云数据库。
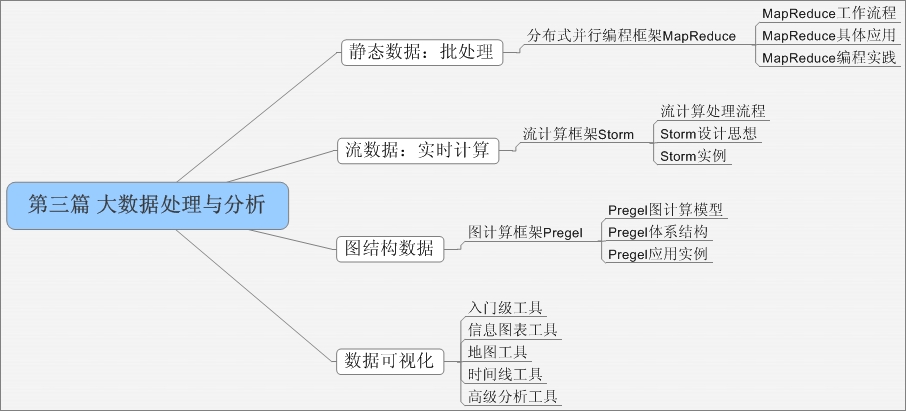
第三篇 大数据处理与分析
本篇介绍大数据处理与分析的相关技术。大数据包括静态数据和动态数据(流数据),静态数据适合采用批处理方式,动态数据需要进行实时计算。分布式并行编程框架MapReduce可以大幅提高程序性能,实现高效的批量数据处理。基于内存的分布式计算框架Spark,是一个可应用于大规模数据处理的快速、通用引擎,如今是Apache软件基金会下的顶级开源项目之一,正以其结构一体化、功能多元化的优势,逐渐成为当今大数据领域最热门的大数据计算平台。流计算框架Storm是一个低延迟、可扩展、高可靠的处理引擎,可以有效解决流数据的实时计算问题。大数据中包括很多图结构数据,但是,MapReduce不适合用来解决大规模图计算问题,因此,新的图计算框架应运而生,Pregel就是其中一种具有代表性的产品。此外,数据可视化是大数据分析的最后环节,也是非常关键的一环,因此,本篇将简要介绍数据可视化的概念和相关工具。
本篇包括6章。第7章介绍分布式并行编程框架MapReduce;第8章对Hadoop进行了再探讨;第9章介绍了基于内存的分布式计算框架Spark;第10章介绍开源流计算框架Storm;第11章介绍图计算框架Pregel;第12章简要介绍数据可视化的概念和相关工具。
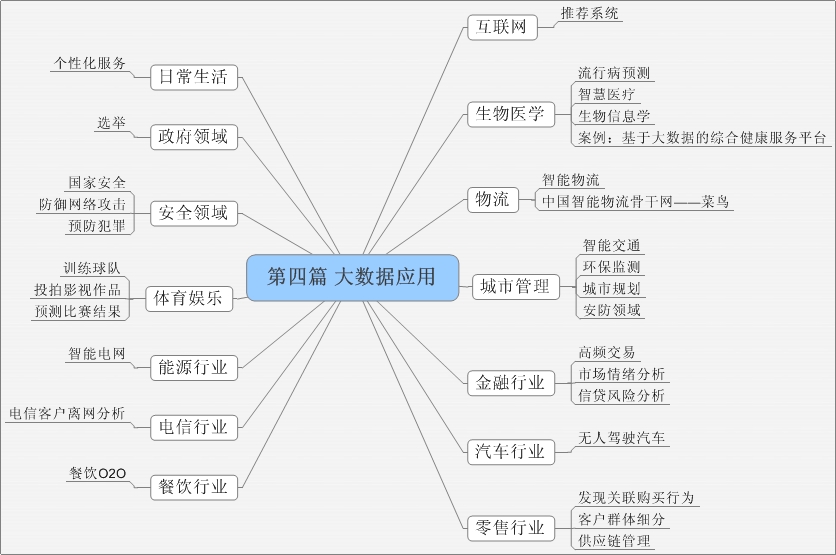
第四篇 大数据应用
大数据已经在社会生产和日常生活中得到了广泛的应用,对人类社会的发展进步起着重要的推动作用。本篇内容介绍大数据在互联网、生物医学、物流、城市管理、金融、汽车、零售、餐饮、电信、能源、体育娱乐、安全、政府、日常生活等方面的应用,从中我们可以深刻地感受到大数据对社会的影响及其重要价值。
本篇包括3章。第13章以推荐系统为核心介绍大数据在互联网领域的应用;第14章介绍大数据在生物医学领域的应用;第15章介绍大数据在其他领域的应用。其中,第13章需要重点理解,其他章节可以作为开拓视野的拓展性阅读材料。
第2版教材目录
第一篇 大数据基础
第1章 大数据概述 2
1.1 大数据时代 2
1.1.1 第三次信息化浪潮 2
1.1.2 信息科技为大数据时代提供
技术支撑 3
1.1.3 数据产生方式的变革促成大数据时代的来临 5
1.1.4 大数据的发展历程 6
1.2 大数据的概念 7
1.2.1 数据量大 7
1.2.2 数据类型繁多 8
1.2.3 处理速度快 9
1.2.4 价值密度低 9
1.3 大数据的影响 9
1.3.1 大数据对科学研究的影响 10
1.3.2 大数据对思维方式的影响 11
1.3.3 大数据对社会发展的影响 11
1.3.4 大数据对就业市场的影响 12
1.3.5 大数据对人才培养的影响 13
1.4 大数据的应用 14
1.5 大数据关键技术 14
1.6 大数据计算模式 15
1.6.1 批处理计算 16
1.6.2 流计算 16
1.6.3 图计算 16
1.6.4 查询分析计算 17
1.7 大数据产业 17
1.8 大数据与云计算、物联网 18
1.8.1 云计算 18
1.8.2 物联网 21
1.8.3 大数据与云计算、物联网的关系 25
1.9 本章小结 26
1.10 习题 26
第2章 大数据处理架构Hadoop 28
2.1 概述 28
2.1.1 Hadoop简介 28
2.1.2 Hadoop的发展简史 28
2.1.3 Hadoop的特性 29
2.1.4 Hadoop的应用现状 29
2.1.5 Hadoop的版本 30
2.2 Hadoop生态系统 30
2.2.1 HDFS 31
2.2.2 HBase 31
2.2.3 MapReduce 31
2.2.4 Hive 32
2.2.5 Pig 32
2.2.6 Mahout 32
2.2.7 Zookeeper 32
2.2.8 Flume 32
2.2.9 Sqoop 32
2.2.10 Ambari 33
2.3 Hadoop的安装与使用 33
2.3.1 创建Hadoop用户 33
2.3.2 Java的安装 34
2.3.3 SSH登录权限设置 34
2.3.4 安装单机Hadoop 34
2.3.5 Hadoop伪分布式安装 35
2.4 本章小结 37
2.5 习题 38
实验1 安装Hadoop 38
第二篇 大数据存储与管理
第3章 分布式文件系统HDFS 42
3.1 分布式文件系统 42
3.1.1 计算机集群结构 42
3.1.2 分布式文件系统的结构 43
3.1.3 分布式文件系统的设计需求 44
3.2 HDFS简介 44
3.3 HDFS的相关概念 45
3.3.1 块 45
3.3.2 名称节点和数据节点 46
3.3.3 第二名称节点 47
3.4 HDFS体系结构 48
3.4.1 概述 48
3.4.2 HDFS命名空间管理 49
3.4.3 通信协议 49
3.4.4 客户端 50
3.4.5 HDFS体系结构的局限性 50
3.5 HDFS的存储原理 50
3.5.1 数据的冗余存储 50
3.5.2 数据存取策略 51
3.5.3 数据错误与恢复 52
3.6 HDFS的数据读写过程 53
3.6.1 读数据的过程 53
3.6.2 写数据的过程 54
3.7 HDFS编程实践 55
3.7.1 HDFS常用命令 55
3.7.2 HDFS的Web界面 56
3.7.3 HDFS常用Java API及应用实例 57
3.8 本章小结 60
3.9 习题 61
实验2 熟悉常用的HDFS操作 61
第4章 分布式数据库HBase 63
4.1 概述 63
4.1.1 从BigTable说起 63
4.1.2 HBase简介 63
4.1.3 HBase与传统关系数据库的对比分析 64
4.2 HBase访问接口 65
4.3 HBase数据模型 66
4.3.1 数据模型概述 66
4.3.2 数据模型的相关概念 66
4.3.3 数据坐标 67
4.3.4 概念视图 68
4.3.5 物理视图 69
4.3.6 面向列的存储 69
4.4 HBase的实现原理 71
4.4.1 HBase的功能组件 71
4.4.2 表和Region 71
4.4.3 Region的定位 72
4.5 HBase运行机制 74
4.5.1 HBase系统架构 74
4.5.2 Region服务器的工作原理 76
4.5.3 Store的工作原理 77
4.5.4 HLog的工作原理 77
4.6 HBase编程实践 78
4.6.1 HBase常用的Shell命令 78
4.6.2 HBase常用的Java API及
应用实例 80
4.7 本章小结 90
4.8 习题 90
实验3 熟悉常用的HBase操作 91
第5章 NoSQL数据库 94
5.1 NoSQL简介 94
5.2 NoSQL兴起的原因 95
5.2.1 关系数据库无法满足
Web 2.0的需求 95
5.2.2 关系数据库的关键特性在Web 2.0时代成为“鸡肋” 96
5.3 NoSQL与关系数据库的比较 97
5.4 NoSQL的四大类型 98
5.4.1 键值数据库 99
5.4.2 列族数据库 100
5.4.3 文档数据库 100
5.4.4 图数据库 101
5.5 NoSQL的三大基石 101
5.5.1 CAP 101
5.5.2 BASE 103
5.5.3 最终一致性 104
5.6 从NoSQL到NewSQL数据库 105
5.7 本章小结 107
5.8 习题 107
第6章 云数据库 108
6.1 云数据库概述 108
6.1.1 云计算是云数据库兴起的基础 108
6.1.2 云数据库的概念 109
6.1.3 云数据库的特性 110
6.1.4 云数据库是个性化数据
存储需求的理想选择 111
6.1.5 云数据库与其他数据库的关系 112
6.2 云数据库产品 113
6.2.1 云数据库厂商概述 113
6.2.2 Amazon的云数据库产品 113
6.2.3 Google的云数据库产品 114
6.2.4 微软的云数据库产品 114
6.2.5 其他云数据库产品 115
6.3 云数据库系统架构 115
6.3.1 UMP系统概述 115
6.3.2 UMP系统架构 116
6.3.3 UMP系统功能 118
6.4 云数据库实践 121
6.4.1 阿里云RDS简介 121
6.4.2 RDS中的概念 121
6.4.3 购买和使用RDS数据库 122
6.4.4 将本地数据库迁移到云端RDS数据库 126
6.5 本章小结 127
6.6 习题 127
实验4 熟练使用RDS for MySQL数据库 128
第三篇 大数据处理与分析
第7章 MapReduce 132
7.1 概述 132
7.1.1 分布式并行编程 132
7.1.2 MapReduce模型简介 133
7.1.3 Map和Reduce函数 133
7.2 MapReduce的工作流程 134
7.2.1 工作流程概述 134
7.2.2 MapReduce的各个执行阶段 135
7.2.3 Shuffle过程详解 136
7.3 实例分析:WordCount 139
7.3.1 WordCount的程序任务 139
7.3.2 WordCount的设计思路 139
7.3.3 WordCount的具体执行过程 140
7.3.4 一个WordCount执行过程的实例 141
7.4 MapReduce的具体应用 142
7.4.1 MapReduce在关系代数运算中的应用 142
7.4.2 分组与聚合运算 144
7.4.3 矩阵-向量乘法 144
7.4.4 矩阵乘法 144
7.5 MapReduce编程实践 145
7.5.1 任务要求 145
7.5.2 编写Map处理逻辑 146
7.5.3 编写Reduce处理逻辑 147
7.5.4 编写main方法 147
7.5.5 编译打包代码以及运行程序 148
7.6 本章小结 150
7.7 习题 151
实验5 MapReduce编程初级实践 152
第8章 Hadoop再探讨 155
8.1 Hadoop的优化与发展 155
8.1.1 Hadoop的局限与不足 155
8.1.2 针对Hadoop的改进与提升 156
8.2 HDFS2.0的新特性 156
8.2.1 HDFS HA 157
8.2.2 HDFS联邦 158
8.3 新一代资源管理调度框架YARN 159
8.3.1 MapReduce1.0的缺陷 159
8.3.2 YARN设计思路 160
8.3.3 YARN体系结构 161
8.3.4 YARN工作流程 163
8.3.5 YARN框架与MapReduce1.0
框架的对比分析 164
8.3.6 YARN的发展目标 165
8.4 Hadoop生态系统中具有代表性的功能组件 166
8.4.1 Pig 166
8.4.2 Tez 167
8.4.3 Kafka 169
8.5 本章小结 170
8.6 习题 170
第9章 Spark 172
9.1 概述 172
9.1.1 Spark简介 172
9.1.2 Scala简介 173
9.1.3 Spark与Hadoop的对比 174
9.2 Spark生态系统 175
9.3 Spark运行架构 177
9.3.1 基本概念 177
9.3.2 架构设计 177
9.3.3 Spark运行基本流程 178
9.3.4 RDD的设计与运行原理 179
9.4 Spark的部署和应用方式 184
9.4.1 Spark三种部署方式 184
9.4.2 从“Hadoop+Storm”架构转向Spark架构 185
9.4.3 Hadoop和Spark的统一部署 186
9.5 Spark编程实践 186
9.5.1 启动Spark Shell 187
9.5.2 Spark RDD基本操作 187
9.5.3 Spark应用程序 189
9.6 本章小结 192
9.7 习题 193
第10章 流计算 194
10.1 流计算概述 194
10.1.1 静态数据和流数据 194
10.1.2 批量计算和实时计算 195
10.1.3 流计算的概念 196
10.1.4 流计算与Hadoop 196
10.1.5 流计算框架 197
10.2 流计算的处理流程 197
10.2.1 概述 197
10.2.2 数据实时采集 198
10.2.3 数据实时计算 198
10.2.4 实时查询服务 199
10.3 流计算的应用 199
10.3.1 应用场景1:实时分析 199
10.3.2 应用场景2:实时交通 200
10.4 开源流计算框架Storm 200
10.4.1 Storm简介 201
10.4.2 Storm的特点 201
10.4.3 Storm的设计思想 202
10.4.4 Storm的框架设计 203
10.4.5 Storm实例 204
10.5 Spark Streaming 206
10.5.1 Spark Streaming设计 206
10.5.2 Spark Streaming与Storm的对比 207
10.6 本章小结 208
10.7 习题 208
第11章 图计算 210
11.1 图计算简介 210
11.1.1 传统图计算解决方案的不足之处 210
11.1.2 图计算通用软件 211
11.2 Pregel简介 211
11.3 Pregel图计算模型 212
11.3.1 有向图和顶点 212
11.3.2 顶点之间的消息传递 212
11.3.3 Pregel的计算过程 213
11.3.4 实例 214
11.4 Pregel的C++ API 216
11.4.1 消息传递机制 217
11.4.2 Combiner 217
11.4.3 Aggregator 218
11.4.4 拓扑改变 218
11.4.5 输入和输出 218
11.5 Pregel的体系结构 219
11.5.1 Pregel的执行过程 219
11.5.2 容错性 220
11.5.3 Worker 221
11.5.4 Master 221
11.5.5 Aggregator 222
11.6 Pregel的应用实例 222
11.6.1 单源最短路径 222
11.6.2 二分匹配 223
11.7 Pregel和MapReduce实现PageRank算法的对比 224
11.7.1 PageRank算法 224
11.7.2 PageRank算法在Pregel中的实现 225
11.7.3 PageRank算法在MapReduce中的实现 225
11.7.4 PageRank算法在Pregel和MapReduce中实现的比较 228
11.8 本章小结 228
11.9 习题 228
第12章 数据可视化 230
12.1 可视化概述 230
12.1.1 什么是数据可视化 230
12.1.2 可视化的发展历程 230
12.1.3 可视化的重要作用 231
12.2 可视化工具 233
12.2.1 入门级工具 233
12.2.2 信息图表工具 234
12.2.3 地图工具 235
12.2.4 时间线工具 236
12.2.5 高级分析工具 236
12.3 可视化典型案例 237
12.3.1 全球黑客活动 237
12.3.2 互联网地图 237
12.3.3 编程语言之间的影响力关系图 238
12.3.4 百度迁徙 239
12.3.5 世界国家健康与财富之间的关系 239
12.3.6 3D可视化互联网地图APP 239
12.4 本章小结 240
12.5 习题 240
第四篇 大数据应用
第13章 大数据在互联网领域的应用 242
13.1 推荐系统概述 242
13.1.1 什么是推荐系统 242
13.1.2 长尾理论 243
13.1.3 推荐方法 243
13.1.4 推荐系统模型 244
13.1.5 推荐系统的应用 244
13.2 协同过滤 245
13.2.1 基于用户的协同过滤 245
13.2.2 基于物品的协同过滤 246
13.2.3 UserCF算法和ItemCF算法的对比 248
13.3 协同过滤实践 248
13.3.1 实践背景 248
13.3.2 数据处理 249
13.3.3 计算相似度矩阵 249
13.3.4 计算推荐结果 250
13.3.5 展示推荐结果 250
13.4 本章小结 251
13.5 习题 251
第14章 大数据在生物医学领域的应用 252
14.1 流行病预测 252
14.1.1 传统流行病预测机制的不足 252
14.1.2 基于大数据的流行病预测 253
14.1.3 基于大数据的流行病预测的
重要作用 253
14.1.4 案例:百度疾病预测 254
14.2 智慧医疗 255
14.3 生物信息学 256
14.4 案例:基于大数据的综合健康服务平台 257
14.4.1 平台概述 257
14.4.2 平台业务架构 258
14.4.3 平台技术架构 258
14.4.4 平台关键技术 259
14.5 本章小结 260
14.6 习题 261
第15章 大数据的其他应用 262
15.1 大数据在物流领域中的应用 262
15.1.1 智能物流的概念 262
15.1.2 智能物流的作用 263
15.1.3 智能物流的应用 263
15.1.4 大数据是智能物流的关键 263
15.1.5 中国智能物流骨干网—菜鸟 264
15.2 大数据在城市管理中的应用 266
15.2.1 智能交通 266
15.2.2 环保监测 267
15.2.3 城市规划 268
15.2.4 安防领域 269
15.3 大数据在金融行业中的应用 269
15.3.1 高频交易 269
15.3.2 市场情绪分析 269
15.3.3 信贷风险分析 270
15.4 大数据在汽车行业中的应用 271
15.5 大数据在零售行业中的应用 272
15.5.1 发现关联购买行为 272
15.5.2 客户群体细分 273
15.5.3 供应链管理 273
15.6 大数据在餐饮行业中的应用 274
15.6.1 餐饮行业拥抱大数据 274
15.6.2 餐饮O2O 274
15.7 大数据在电信行业中的应用 276
15.8 大数据在能源行业中的应用 276
15.9 大数据在体育和娱乐领域中的应用 277
15.9.1 训练球队 277
15.9.2 投拍影视作品 278
15.9.3 预测比赛结果 279
15.10 大数据在安全领域中的应用 280
15.10.1 大数据与国家安全 280
15.10.2 应用大数据技术防御网络攻击 280
15.10.3 警察应用大数据工具预防犯罪 281
15.11 大数据在政府领域中的应用 282
15.12 大数据在日常生活中的应用 283
15.13 本章小结 284
15.14 习题 284
参考文献 285
2015年8月1日出版发行的《大数据技术原理与应用》教材(第1版)共13章,针对2015、2016年大数据技术的新发展,2016年林子雨老师为第1版教材新增了三个章节,新增第14章基于Hadoop的数据仓库Hive、第15章Hadoop架构再探讨、第16章Spark。请在下面链接中下载新增章节的PDF格式的电子书。
| 第1版教材之外新增的章节 | 版本号 | 下载PDF格式电子书 |
| 第14章基于Hadoop的数据仓库Hive (没有放入第2版教材) |
2016年4月6日 | 下载电子书 |
| 第15章Hadoop架构再探讨 (已经放入第2版教材的第8章) |
2016年4月13日 | 下载电子书 |
| 第16章Spark (已经放入第2版教材的第9章) |
2016年4月20日 | 下载电子书 |
请点击这里下载厦门大学林子雨编著《大数据技术原理与应用》教材配套讲义PPT。可以下载到2015年8月出版的第1版教材和2017年1月出版的第2版教材配套的讲义PPT。
教材编写过程
林子雨在数据库、数据仓库、数据挖掘、大数据、云计算和物联网等领域有着十多年的知识积累,对各个领域知识都有比较深入的了解,在政府发改部门的两年挂职期间对大量企业的调研,使其形成了比较宽泛的视野和对产业的深入了解。
2013年9月,由林子雨主讲的厦门大学计算机科学系研究生课程《大数据技术基础》正式开课。由于当时国内尚未出现适合本科和研究生教学的大数据专业教材,林子雨结合自身研究成果,并调研大量网络资料,历时半年编写完成了免费开源的课程讲义,发布到网络上,受到广大网友好评。
2014年开始,历时一年多时间,林子雨系统总结理论研究成果和教学实践经验,将相关大数据知识综合成一本适合本科和研究生教学的教材——《大数据技术原理与应用》。该教材由人民邮电出版社出版发行,2015年8月正式在当当、京东、淘宝、亚马逊等各大网店上架销售,并成为畅销书籍。近几年的教学实践证明,目前市场已有的各类其他书籍,大都偏于技术,比较适合作为深入学习的工具书来使用,不适合作为高校本科和研究生教学的教材。高校教学应更加侧重理论层面的教学,即对大数据领域知识体系的普及和背后原理的阐述,而非让学生深入学习和实践某一种大数据技术。从这个角度来说,《大数据技术原理与应用》是国内高校第一本系统介绍大数据知识的专业教材,也是第一本适合用于本科和研究生教学的入门级教材。
2017年1月,教材第2版正式出版发行,增加了最新的Spark技术介绍。
本教材源自林子雨老师在厦门大学计算机系的多年教学实践,从2013年开始已经应用于厦门大学计算机系研究生课程《大数据技术基础》和厦门大学本科生课程《大数据技术原理与应用》的实践教学,受到学生的欢迎!点击这里访问《大数据技术基础》2013班级主页。
| 时间 | 课程名称 | 课程性质 | 授课对象 | 授课内容 | 教材 | 班级主页 |
| 2013年秋季学期 | 大数据基础基础 | 专业选修课 | 厦大计算机系2013级研究生 | 大数据技术原理,包括Hadoop,HDFS,HBase,MapReduce,NoSQL数据库、云数据库、流计算、图计算、Zookeeper、Google Spanner、Google Dremel等 | 林子雨编著《大数据技术基础》PDF免费开源电子书 | 访问主页 |
| 2016年春季学期 | 大数据处理技术 | 专业选修课 | 厦大计算机系2015级研究生 | 大数据技术原理与应用,包括Hadoop,HDFS,HBase,MapReduce,NoSQL数据库、云数据库、流计算、图计算、数据可视化、推荐系统、大数据在各个领域的应用等 | 林子雨编著《大数据技术原理与应用(第1版)》 | 访问主页 |
| 2017年春季学期 | 大数据处理基础 | 专业选修课 | 厦大计算机系2016级研究生 | 基于内存的分布式计算框架Spark,完整讲解整套Spark技术 | 林子雨编著在线版《Spark入门教程》 | 访问主页 |
| 2017年春季学期 | 大数据技术原理与应用 | 全校公共选修课 | 厦大本科生 | 大数据技术原理与应用,包括Hadoop,HDFS,HBase,MapReduce,NoSQL数据库、云数据库、流计算、图计算、数据可视化、推荐系统、大数据在各个领域的应用等 | 林子雨编著《大数据技术原理与应用(第2版)》 | 访问主页 |

注:在教材使用过程中,如发现任何错误,欢迎联系教材作者林子雨:ziyulin@xmu.edu.cn。在此向读者表示衷心的感谢!
| 序号 | 勘误日期 | 错误修改说明 |
| 暂无 | 暂无 | 暂无 |
感谢读者对本书的关注和批评指正,相关反馈意见将在后续版本中加以改进,查看读者名单。
本书由林子雨执笔。在撰写过程中,厦门大学计算机科学系硕士研究生刘颖杰(2012级硕士研究生)、叶林宝(2012级硕士研究生)、蔡珉星(2013级硕士研究生)、李雨倩(女,2013级硕士研究生)、谢荣东(2014级硕士研究生)、罗道文(2014级硕士研究生)、邓少军(2014级硕士研究生)、阮榕城(2015级硕士研究生)、薛倩(2015级硕士研究生)、魏亮(2016级硕士研究生)、曾冠华(2016级硕士研究生)以及本科生黄梓铭(2011级本科生)、李粲(女,2012级本科生)等同学做了大量辅助性工作,在此,向这些同学的辛勤工作表示衷心的感谢。
 |
 |
 |
 |
| 刘颖杰 | 叶林宝 | 蔡珉星 | 李雨倩 |
 |
 |
 |
 |
| 谢荣东 | 罗道文 | 黄梓铭 | 李粲 |
 |
 |
 |
 |
| 阮榕城 | 薛倩 | 魏亮 | 曾冠华 |

(图 2015年11月30日在北京人民邮电出版社合影 吴婷(本书编辑)、林子雨、潘春燕(高教出版分社社长)、邹文波(信息技术编辑部主任))
