
《高校大数据实训课程系列案例之电影推荐系统(Scala版)》教材官网
厦门大学 林子雨 编著
(E-mail: ziyulin@xmu.edu.cn)
全国高校大数据教学名师精品力作
系列案例,与相关大数据教材一脉相承
资源全面,提供全方位一站式在线服务
教材已经由人民邮电出版社出版发行
ISBN:978-7-115-50306-0 定价:45元
本页面内容导航
教材简介 | 案例概述 | 下载专区 | 实训样板工程 | 拓展阅读 | 大数据学习路线图 | 大数据课程公共服务平台 | 其他案例系列教材

扫一扫访问本网页

图书ISBN:978-7-115-50306-0 人民邮电出版社
本书详细介绍了一个大数据应用案例——电影推荐系统,案例涉及数据预处理、数据存储与管理、数据分析和数据可视化等流程,涵盖Linux、MySQL、Hadoop、Spark、IntelliJ IDEA、Kettle、Node.js等系统和软件的安装与使用方法。本案例采用Scala语言编写Spark程序。
本书适合用于高校大数据实训课程的教学,本书中的具体案例,将有助于学生综合运用大数据课程知识以及各种工具软件,实现数据分析全流程操作。
本书提供了丰富的免费在线教学资源,可以较好地满足高校在大数据实训课程环节对相关大数据教学资源的需求。
本书作为大数据实训课程教材,和大数据入门教材《大数据技术原理与应用》以及大数据进阶教材《Spark编程基础(Scala版)》一起,初步形成了完整的大数据教材体系,可以作为高等院校计算机、软件工程、信息管理、数据科学与大数据技术等相关专业的大数据实训课程教材,也可供相关技术人员参考。
本案例涉及数据预处理、数据存储与管理、数据分析和数据可视化等流程,涵盖Linux、MySQL、Hadoop、Spark、IntelliJ IDEA、Kettle、Node.js等系统和软件的安装与使用方法。本案例采用Scala语言编写Spark程序。本案例适合用于高校大数据实训课程的教学。通过本案例,将有助于学生综合运用大数据课程知识以及各种工具软件,实现数据分析全流程操作。
1.1 案例目的
本案例旨在帮助学生形成以下几个方面的能力:
(1)掌握Linux操作系统的安装和使用;
(2)掌握Hadoop的安装和使用方法;
(3)掌握关系数据库的原理以及MySQL数据库的安装和使用方法;
(4)掌握使用IntelliJ IDEA开发Scala程序的方法;
(5)掌握ETL工具Kettle的安装和使用方法;
(6)掌握Spark程序(包括Spark SQL程序和Spark MLlib程序)开发方法;
(7)掌握推荐系统的原理;
(8)掌握基于协同过滤的推荐算法的原理及其具体使用方法;
(9)掌握数据挖掘的步骤和方法;
(10)掌握基于js的网页开发方法;
(11)掌握利用网页可视化呈现数据分析结果的方法。
1.2 适用对象
本案例适用于以下对象:
(1)高校(本科和高职)教师;
(2)高校(本科和高职)学生;
(3)大数据学习者。
1.3 时间安排
本案例可以作为高校大数据实训课程的实践教学案例,建议安排80学时左右完成本案例。
1.4 预备知识
本案例是对大数据课程知识体系的综合实践,需要案例使用者具备如下预备知识:
(1)学习过大数据相关课程,了解大数据相关技术的基本概念与原理,掌握基础的Hadoop使用方法和Spark编程方法;
(2)由于本案例全部在Linux操作系统下完成实验,因此,需要使用者了解Linux操作系统的基本原理和使用方法;
(3)了解关系数据库的原理,掌握基本的SQL语句编写方法;
(4)了解HTML语言和网页开发的基本方法;
(5)了解Scala编程语言以及使用Scala语言编写Spark程序的方法。
1.5 硬件要求
本案例可以在单机、伪分布式、分布式集群环境下完成实验。对于Hadoop而言,三种模式的区别在于:
(1)单机模式:只在一台机器上运行,存储是采用本地文件系统,没有采用分布式文件系统HDFS;
(2)伪分布式模式:存储采用分布式文件系统HDFS,但是,HDFS的名称节点和数据节点都在同一台机器上;
(3)分布式模式:存储采用分布式文件系统HDFS,而且,HDFS的名称节点和数据节点位于不同机器上。
需要说明的是,高校采用真正分布式集群环境进行实验的必要性不强,很多高校也不具备多人同时开展分布式编程实践的大数据实验平台,因此,建议在伪分布式环境下完成本案例。
在使用伪分布式模式进行安装配置时,如果采用在Windows系统上安装Linux虚拟机的方式,则对计算机的配置要求较高,建议的计算机硬件配置为:50GB以上硬盘和8GB以上内存。如果采用双操作系统方式,开机启动后直接进入Linux系统,则使用普通的台式机或者笔记本电脑,都可以顺利完成本案例。
由于在程序编译打包环节需要从网络上下载相关文件,因此,要确保计算机能够接入互联网。
1.6 软件工具
本案例所涉及的系统及软件包括:Linux、MySQL、Hadoop、Spark、IntelliJ IDEA、Kettle和Node.js等,并且采用Scala语言编写Spark程序。相关软件的版本建议如下:
(1)Linux:Ubuntu 16.04;
(2)MySQL:5.7;
(3)Hadoop:2.7.1;
(4)IntelliJ IDEA:2017.3.5;
(5)Spark:2.1.0;
(6)Kettle:6.1;
(7)Node.js:8.9。
教材官网提供了全部软件的下载,要严格按照相应版本安装系统和软件,否则,可能会引起一些不必要的意外错误。
1.7 数据集
本案例采用电影评分数据集MovieLens,数据集中包含了三个数据文件:
(1)用户评分数据集dat;
(2)样本评分数据集txt;
(3)电影数据集dat。
可以访问教材官网的“下载专区”,到“数据集”目录中下载数据文件movie_recommend.zip获取数据集。
1.8 案例任务
本案例需要在Linux系统环境下完成以下任务:
(1)安装JDK;
(2)安装关系型数据库MySQL;
(3)安装大数据软件Hadoop;
(4)安装大数据软件Spark;
(5)安装开发工具IntelliJ IDEA;
(6)安装ETL工具Kettle;
(7)使用Kettle将数据文件从Linux本地文件导入到HDFS;
(8)使用协同过滤算法实现电影的推荐;
(9)编写Spark程序实现电影推荐功能;
(10)使用Node.js语言搭建动态网页呈现推荐结果。
图1-1给出了本案例的数据分析整体过程,具体如下:
(1)使用Kettle将数据文件从Linux本地文件导入到HDFS;
(2)使用Scala语言编写Spark程序,根据数据集训练模型,为用户推荐其最感兴趣的电影;
(3)利用Node.js搭建动态网页呈现电影推荐结果。
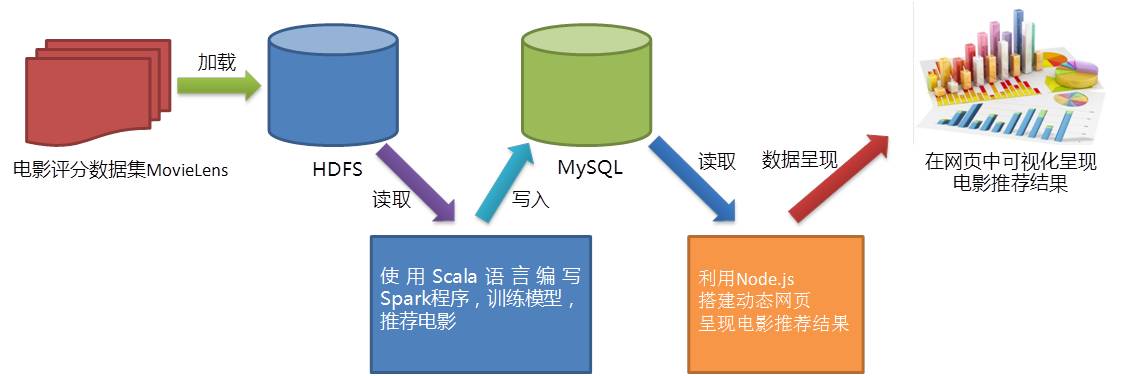
图 电影推荐系统的数据分析整体过程
“下载专区”栏目提供了本教材内各个章节所涉及到的源代码、软件和数据集的下载,为了方便读者查找相关软件和代码,表1给出了“下载专区”目录及其内容的概览。
“下载专区”所有资源全部放在百度云盘中(请点击这里访问)(提取码:bxug ),需要在电脑上安装百度云盘客户端,才能顺利下载内容。
表1 “下载专区”目录及其内容概览
| 目录 | 文件清单 | |
| 软件 | Kettle(data-integration.zip) hadoop-2.7.1.tar.gz IntelliJ IDEA(ideaIU-2017.3.5.tar.gz、scala-intellij-bin-2017.3.5.zip) jdk-8u162-linux-x64.tar.gz mysql-connector-java-5.1.40.tar.gz spark-2.1.0-bin-without-hadoop.tgz ubuntukylin-16.04-desktop-amd64.iso VirtualBox_5.0.10.4061_104061_Win.1448355141.exe |
|
| 代码 | 第3章 | WordCount.scala、pom.xml |
| 第5章 | 向spark.student表中插入记录的代码.txt、pom.xml、SparkOperateMySQL.scala | |
| 第6章 | MovieLensALS.scala、pom.xml | |
| 第7章 | 使用Express框架和Jade模板引擎 (expressjade.js、test.jade) 实例1:设计网页实现用户注册登录功能 (index.html、ok.html、register.html、userlogin.js) 实例2:采用Jade模板引擎实现用户注册登录功能 (index.jade、ok.jade、registerpage.jade、userloginapp.js) 实例3:通过网页调用词频统计应用程序 (index.jade、index.js、server.js、WordCount.scala) |
|
| 第8章 | Node.js代码、Spark程序 | |
| 第9章 | Node.js代码、Spark程序 | |
| 数据集 | movie_recommend.zip、MovieRecommendDatabase.sql | |
根据实验室打造“高校大数据实训课程样板工程”的实践经验,全面介绍高校大数据实训课程的教学方法和课程资源,包括课程设计目的要求、选题原则、设计内容、教学方法、授课过程、资源平台、教学管理平台等,为全国高校更好开展大数据实训课程建设提供参考。
课程亮点:高校大数据教学名师和企业大数据工程师联合指导、“教学过程一体化管理平台”和“高校大数据课程公共服务平台”全程助力、为高校量身定制的大数据实训案例教材、围绕工程教育认证要求制定课程内容

(2018年9月3日-28日 林子雨老师指导厦门理工学院2015级本科生开展大数据实训)
| 教材章节 | 阅读内容 | 阅读目的 | 阅读 |
| 第2章 大数据实验环境搭建 | Linux系统安装指南 | 了解如何在Windows系统中采用虚拟机方式安装Linux | 查看 |
| 第2章 大数据实验环境搭建 | Hadoop集群安装配置教程 | 了解如何利用多台机器、采用分布式模式构建Hadoop集群 | 查看 |
| 第2章 大数据实验环境搭建 | Spark集群搭建及程序运行 | 了解如何搭建Spark集群以及如何在Spark集群上运行分布式程序 | 查看 |

从2013年至今,历经5年,厦门大学林子雨老师团队建设了目前国内高校最丰富的大数据教学资源,为高校教学提供了包括教材、讲义PPT、视频、实验、案例等在内的全方位、一站式服务,成为目前国内高校大数据教学领域具有较高影响力的团队,教材已经被国内众多高校采用,在线资源每年访问量超过200万次。“大数据学习路线图”(访问)将为大数据学习者提供轻松、高效的学习路径,帮助学习者利用厦大数据库实验室提供的全套教学资源,顺利地、一站式完成大数据的入门学习和进阶学习。

由厦门大学数据库实验室建设的高校大数据课程公共服务平台(访问),旨在为全国高校教师和学生提供大数据教学资源一站式“免费”在线服务,包括课程教材、讲义PPT、课程习题、实验指南、学习指南、备课指南、授课视频和技术资料等。平台重点打造“11个1工程”,即1套教材、1个教师服务站、1个学生服务站、1个公益项目、1堂巡讲公开课、1个示范班级、1门在线课程、1个交流群(QQ群、微信群)、1个保障团队、1个培训交流基地和1个教学研讨会。平台自2013年5月建设以来,内容不断补充完善,形成了丰富的在线大数据教学资源,吸引了大量用户访问,目前每年访问量超过100万次,成为全国高校大数据教学知名品牌。
致谢
本书由林子雨执笔。在撰写过程中,厦门大学计算机科学系硕士研究生魏亮、曾冠华、程璐、林哲、郑宛玉、陈杰祥等同学以及厦门大学计算机科学系2015级本科生张庆晓和罗景亮同学等做了大量辅助性工作,在此,向这些同学的辛勤工作表示衷心的感谢。衷心感谢夏小云老师在教材校对工作中的辛勤付出!