

《闪存数据库概念与技术》
厦门大学数据库实验室 林子雨 编著
(本网页是第6章内容,全书内容请点击这里访问本书官网,官网提供本书整本电子书PDF下载)
第6章 闪存数据库缓冲区管理
在内存中设置数据库页的缓存可以有效提升数据库的性能,通过把那些经常被访问的数据库页放置到缓冲区中,当外部请求到达时,如果请求页正好在缓冲区中,那么,就不需要到辅助存储设备(比如磁盘或闪存)中读取该页,由于内存读写速度要远远高于辅助存储设备,因此,缓冲区可以明显减少I/O开销。
缓冲区替换策略的有效性,会严重影响到数据库系统性能。虽然,闪存比磁盘具有更好的I/O性能,但是,闪存仍然比内存的速度低两个数量级。一个有效的策略可以减少代价高昂的磁盘访问,从而有效提高数据库的整体性能。缓冲区替换策略是充分发挥缓冲区作用的关键,它可以在数据库服务器对外提供服务的过程中,动态决定把哪些数据放入缓冲区,哪些数据驱逐出缓冲区,从而使得数据库服务器随着负载特性的不断变化,仍能够提供高性能的服务。设计不恰当的缓冲区替换策略,不仅无法提升数据库性能,反而会导致数据库性能的恶化,因为,替换策略如果做出错误的放置和驱逐页的决定,可能会带来更多的I/O开销。因此,必须设计合理高效的闪存数据库缓冲区管理策略。
本章首先概要介绍缓冲区管理策略,然后介绍面向闪存的缓冲区管理策略,最后介绍一些代表性的研究成果。
| 概念区分:从严格意义上讲,缓存(Cache)和缓冲区(Buffer)是两个不同的概念。缓存的作用是加速“读”操作,即在内存中开辟一块空间,用来保存从磁盘上读出的数据,这些数据通常是被频繁访问的数据,由于内存访问速度要比磁盘访问速度快许多,因此,把频繁访问的数据保存到内存中,可以提高整体的数据读速度。缓冲区的作用是缓冲“写”操作,即在内存中开辟一块空间,把即将要写入到磁盘上的数据都暂时保存在这里,等到某个特定的时刻,才一次性地批量刷新到磁盘中,这样做可以降低IO开销,因为,每次磁盘写操作都包含了固定的磁盘启动开销,如果每次都只写入少量数据,就会带来很大的磁盘反复启动开销,而批量写入则只要一次启动开销就可以写入大量数据,从而可以把启动开销分摊到大量的数据中。在很多情况下,缓存和缓冲区这两个名词并没有严格区分,因为,很多时候缓存或缓冲区会是读写混合类型,因此,本章内容后续的论述中,统一称为“缓冲区”。 |
6.1 缓冲区管理策略概述
当缓冲区替换发生时,通常包括两种类型的替换代价。一种是当一个被请求的页从辅助存储中抓取到缓冲区中的代价;另一种是当一个脏页从缓存中被驱逐出来写入到辅助存储(比如闪存和磁盘)中的代价,因为,为了保证数据的一致性,一个脏的缓冲区页,当被缓冲区替换策略选中为驱逐页时,必须把该脏页回写到辅助存储。通过选择一个干净页来驱逐,可以最小化第二种代价。因为,一个干净页和闪存中原来的数据页的内容是一样的,因此,从缓冲区中被驱逐出去即可,不需要执行写入闪存的操作。
上述两种替换代价中,只要减少其中一种代价,就可以使得数据库性能获得收益,但是,两种代价不是完全独立的,即其中一种代价的增加或减少,可能在远期会对另外一种代价产生影响。例如,一个替换策略为了减少针对闪存的写操作和擦除操作代价,可能会决定把尽可能多的脏页放入缓冲区。但是,这种做法可能会让缓冲区逐渐耗尽空间,访问缓冲区时脱靶(即被请求的页不在缓冲区中)的次数就会大量增加,一旦访问缓冲区页时发生脱靶,就需要到辅助存储设备上读取相应的页,这意味着会增加从辅助存储中读取被请求页的替换代价。再比如,一个替换策略,如果只关注增加命中率,就会尽量驱逐脏页,这就会增加把脏页写入到辅助存储中的替换代价。因此,一个好的缓冲区替换策略必须综合考虑上述两种类型的代价,从而获得最好的整体性能。
最具有代表性的缓冲区替换策略就是LRU(Least Recently Used)策略,或称为最近最少使用策略。LRU策略有许多种不同的实现方式,最常见方式是链表法。当采用链表法实现LRU策略时,缓冲区中的所有页被组织成一个链表,称为LRU链表。LRU链表按照页的访问频度来排列页,最近最频繁使用的页被放置在链表的MRU(Most Recently Used)位置,最近最少使用的页被放置在链表的LRU(Least Recently Used)位置。当访问一个页面P时,就到缓冲区的LRU链表寻找P,如果P已经在缓冲区中,就把P从链表的当前所在位置移除,放置到链表的MRU位置;如果P不在缓冲区中,并且缓冲区还有额外的空间,则把P放入链表的MRU位置;如果缓冲区已满,则需要进行页的替换,把处于链表LRU位置的页作为驱逐页,驱逐出缓冲区,腾出空间后,把P放置到链表的MRU位置。一个页第一次从辅助存储(比如磁盘或闪存)读取到缓冲区时,没有经过任何修改,被称为“干净页”,一旦缓冲区中的页被修改过,就变成“脏页”。在进行缓冲区页的替换时,当一个驱逐页是干净页的时候,可以直接驱逐出缓冲区,不需要其他操作,当一个驱逐页是脏页的时候,为了保证数据一致性,必须把脏页“回写”到辅助存储中。
图[LRU]给出了一个LRU算法的实例。假设缓冲区最多只能容纳5个页。在初始阶段(见图[LRU](a)),缓冲区中包含了P0,P1,P2,P3,P4共5个页,P0处于LRU位置,P4处于MRU位置。这时,一个针对页P2的读操作到达,LRU算法检查LRU链表后发现P2已经在缓冲区中,就直接从缓冲区读取P2,P2被访问后,LRU算法就把P2从链表的当前位置移除,重新放置到MRU位置,如图[LRU](b)所示。然后,一个针对页P5的读操作到达,LRU算法检查LRU链表后发现P5不在缓冲区中,需要到辅助存储中读取P5放入缓冲区。但是,这时缓冲区已满,LRU算法选择当前处于LRU位置的页P0作为驱逐页,驱逐出缓冲区,然后,把从辅助存储中读取到得P5放入到LRU链表的MRU位置,如图[LRU](c)所示。
![图[LRU]LRU算法的一个实例](https://dblab.xmu.edu.cn/wp-content/uploads/2015/09/图LRULRU算法的一个实例.jpg)
图[LRU] LRU算法的一个实例
6.2 面向闪存的缓冲区管理
本节介绍重新设计面向闪存的缓冲区替换策略的必要性,以及设计面向闪存的缓冲区管理策略的考虑因素和关键技术。
6.2.1 重新设计面向闪存的缓冲区替换策略的必要性
此前,许多数据库系统都使用一个近似的LRU(Least Recently Used:最近最少使用)算法作为替换策略,取得了较好的性能。但是,以前这些替换策略都是针对磁盘这种块访问设备而设计的,替换策略只考虑缓冲区的命中率,即在给定的缓冲区尺寸下,最小化缓冲区脱靶的概率。但是,最小化缓冲区脱靶率,在基于闪存的数据库系统中,可能会带来较差的I/O性能。这是因为,和磁盘相比,闪存有一个内在的特性——读写不对称性,即写操作会比读操作慢一个数量级,而且由于写操作可能会引起擦除操作,这就进一步提高了写操作的代价。由于这种非对称性,缓冲区管理策略必须对写操作和读操作进行区分。例如,在缓冲区中保留一个写操作比较集中的脏页所能带来的收益,要比保留一个读操作集中的干净页的收益大。而在传统的LRU策略下,往往会把很多脏页替换出去,因为,LRU替换的是链表尾部的页,而在实际应用中脏页往往容易集中在LRU链表的尾部。替换脏页会带来大量的I/O开销,这就恶化了基于闪存的数据库的性能。
因此,对于使用闪存作为辅助存储的数据库系统而言,当需要替换缓冲区页来释放缓冲区空间时,一方面,应该充分考虑闪存具有读和写操作代价不对称这个特点,尽量减少代价高昂的写操作和擦除操作的数量;另一方面,还要尽量减少缓冲区“脱靶”的数量,因为脱靶会导致大量的读操作。此外,闪存要比磁盘快一个数量级,这种低的访问延迟,不允许采用复杂的、具有高计算代价的数据结构和算法,比如,在缓冲区中选择一个驱逐页的算法应该尽可能简单,从而不会抵消由闪存低访问延迟带来的I/O收益。因此,设计充分考虑闪存特性的数据库缓冲区替换策略,是一件具有挑战性的工作。
6.2.2 设计面向闪存的缓冲区替换策略的考虑因素
设计面向闪存的缓冲区替换策略的一个主要目标就是,尽量减少针对闪存的写操作和擦除操作的数量。需要注意的是,缓冲区替换策略生成的I/O序列只会包含读写操作,而不会包含擦除操作,因为擦除操作是由闪存内部自己控制的。不过,一般来说,来自缓冲区层的写操作的数量,通常和针对闪存的物理写和擦除操作的数量成正比。因此,面向闪存的缓冲区替换策略的目标都是尽量降低来自缓冲区层的写操作数量,由写操作引发的擦除操作的数量自然就会相应降低。
针对闪存的写操作,通常都是由于替换缓冲区中的脏页引起的。当把一个脏页驱逐出缓冲区时,为了保证数据的一致性,必须把这个脏页“回写”到闪存中。因此,替换策略应该尽量让脏页在缓冲区中停留更长的时间。但是,保留更多的脏页在缓冲区中,也就意味着分配给干净页的空间就会相应减少,可能会导致缓冲区命中率的下降,引起更多的闪存读操作,恶化整体I/O性能。因此,缓冲区替换策略应该综合考虑脏页和干净页的驱逐代价,一个基本原则是:由于缓冲区脏页带来的写操作代价的减少,一定要大于由此带来的读操作代价的增加。比如,如果一个干净页p必须被反复读取n次,一个脏页q必须被反复修改m次,如果n和m值相差不大,那么就应该最好去替换p而不是q,因为,直接在内存中服务这m个写操作的收益,要比n个闪存读操作的代价大许多。
设计面向闪存的缓冲区替换策略的基本原则是:
- 最小化物理写操作的数量,尤其是最小化随机写操作的数量;
- 调整写模式来改进写操作效率;
- 保持一个相对较高的命中率。
同时,缓冲区替换策略应该充分考虑不同操作类型对不同类型缓冲区页的操作代价,具体如下:
(1)读取干净页:直接从缓冲区中读取一个干净页,不需要到闪存读取,因此,代价非常小;
(2)读取脏页:直接从缓冲区中读取一个脏页,不需要到闪存读取,因此,代价非常小;
(3)写干净页:直接对缓冲区中的干净页进行写操作,这个页变成一个脏页,如果以后被驱逐出缓冲区,就会引起脏页回写到闪存的写操作,代价较大;
(4)写脏页:直接对缓冲区中的脏页进行写操作,相当于和之前对该页的写操作进行了合并,不管这个脏页在缓冲区停留期间发生过多少次写操作,当这个脏页被驱逐出缓冲区时,只需要一次回写到闪存的代价,节省了若干次回写到闪存的写操作代价。因此,缓冲区替换策略让脏页在缓冲区中停留更长时间,可以获得收益。
此外,每个页被访问的频度也是不同的,被频繁访问的页称为“热页”,很少被访问的页称为“冷页”。相应地,脏页可以分为“热脏页”和“冷脏页”,干净页也可以分为“热干净页”和“冷干净页”。对于不同类型的页,缓冲区替换代价也是不同的。通常有如下关系成立:Cost(CC) < Cost(CD) < Cost(HC) < Cost(HD),其中,Cost(CC)表示替换冷干净页的代价,Cost(CD)表示替换冷脏页的代价,Cost(HC)表示替换热干净页的代价,Cost(HD)表示替换热脏页的代价。也就是说,替换热脏页的代价最大,替换冷干净页的代价最小。因此,替换策略应该优先替换冷干净页,尽量延缓替换热脏页。
6.2.3 设计面向闪存的缓冲区替换策略的关键技术
许多性能较好的缓冲区替换策略,都需要考虑页的访问频度,确定一个页属于冷页还是热页,然后,根据热脏页、冷脏页、热干净页和冷干净页的不同替换代价,设计最优的缓冲区替换策略。因此,判定一个页冷热情况的“热探测”(或也可称为“冷探测”)技术,是许多缓冲区替换策略必须采用的基本技术。
文献[HsiehCK05]提出了一种面向闪存的、基于哈希的热探测机制,是在FTL中实现的,可以实时跟踪记录针对各个逻辑块地址(LBA:Logical Block Address)的访问,确定哪些LBA包含了热数据,为数据访问的空间局部性提供高效的在线分析。大量实验表明,这种热探测技术可以获得较好的性能,为其他面向闪存的缓冲区替换策略提供辅助。
在这种热探测机制中,对于每个LBA,都使用K个独立的哈希函数映射到哈希表的K个条目上。哈希表的每个条目(entry),都包含了一个C位的计数器,来跟踪针对某个LBA的写操作的数量。当FTL接收到针对某个LBA的写请求时,这个LBA会被K个独立的哈希函数映射到哈希表的K个条目上,这K个条目中的计数器的值就增加1。由于计数器最多只有C个二进制位,因此,最大计数值为2C-1。计数器增加到最大值以后,就不会继续增加。另外,如果只是简单地把写操作数量累加到计数器中,那么,经过一段较长的时间后,许多计数器的值都可以累加到足够大的值,这对于判定冷热数据是没有意义的,因为,对于缓冲区替换算法而言,只有最近一段时间范围内的统计信息才是有价值的。因此,为了让计数器中统计到的写操作数量具有阶段时效性,计数器的值会进行阶段性衰减,衰减的方法是,每经过一段时间,计数器的值都会被除以2,即所有写操作数量都随着时间流逝呈现指数级递减。由于计数器的值采用C个二进制位进行存储,因此,只要进行简单的向右移位操作,即可以实现除以2的效果。计数器一共有C个二进制位,其中,左边有M个二进制位被称为“最明显位”,它们用来辅助判定一个LBA是否包含热数据。一个LBA被判定包含热数据的条件是:对于与这个LBA对应的K个哈希表条目中的K个计数器而言,必须保证每个计数器的最明显位中出现至少一个1。可以看出,最明显位的个数M是用来确定是否包含热数据的门槛值,也就是说,只有当所有K个计数器中累加得到的写操作的数量大于2(C–M)-1时,才可能判定一个LBA包含热数据。如果其中某个计数器的最明显位都是0,没有出现1,就说明计数器中累计的写操作数量还没有超过这个门槛值,即2(C–M)-1。
![图[hot-detection]基于哈希表的热探测机制](https://dblab.xmu.edu.cn/wp-content/uploads/2015/09/图hot-detection基于哈希表的热探测机制-680x409.jpg)
图[hot-detection] 基于哈希表的热探测机制
图[hot-detection]是一个关于基于哈希表的热探测机制的实例。图[hot-detection](a)演示了计数器的更新,其中,K=4,C=4,M=2,也就是说,采用4个不同的哈希函数,计数器用4个二进制位存储,每个计数器包括2个最明显位,即只有当所有4个计数器中累加得到的写操作的数量大于3(即2(4-2)-1)时,才可能判定一个LBA包含热数据。x是一个LBA,当一个针对x的写请求到达时,使用4个独立的哈希函数H1,H2,H3和H4分别把x映射到哈希表的4个不同条目t1,t2,t3和t4上,需要为这4个条目上的计数器增加1。在计数器没有增加1之前,这4个计数器的4个二进制位分别是:t1=(1,0,1,0), t2=(0,0,0,1), t3=(0,1,0,0), t4=(1,1,0,1)。在增加1以后,这4个计数器的4个二进制位分别是:t1=(1,0,1,1), t2=(0,0,1,0), t3=(0,1,0,1), t4=(1,1,1,0)。计数器4个位中,左边2位是最明显位,因此,t1的最明显位是1和0,t2的最明显位是0和0,t3的最明显位是0和1,t4的最明显位是1和1。可以看出,t1、t3和t4的最明显位中至少有一个1,但是,t2的最明显位都是0,没有出现1。一个LBA被判定包含热数据的条件是:对于与这个LBA对应的K个哈希表条目中的K个计数器而言,必须保证每个计数器的最明显位中出现至少一个1。可以看出,t2不符合条件,因此,x不会被判定为包含热数据。
图[hot-detection](b)演示了一个LBA被判定为包含热数据的情形,从图中可以看出,y被4个独立的哈希函数映射到4个不同的哈希表条目上,这4个条目上的计数器分别增加1以后,它们的二进制位分别是(1,1,0,0)、(1,0,1,0)、(1,0,0,0)和(0,1,0,1)。每个计数器的左边2位是最明显位,可以看出,这4个计数器的最明显位中都至少出现一个1,因此,可以判定y包含热数据。
基于哈希的热探测机制之所以采用K个独立的哈希函数,是为了减少错误识别率。哈希方法通常是把一个很大的地址空间映射到一个较小的空间上,因此,就会存在映射冲突,即不同的LBA被哈希函数映射到同一个哈希表条目上。当只采用一个哈希函数时,一个LBA被哈希函数映射到一个哈希表条目上以后,如果仅仅根据这个条目上的计数器超过事先规定的门槛值,就认为这个LBA包含热数据,那就有可能做出错误的识别。因为,由于存在映射冲突,多个不同的LBA可能被映射到同一个条目上,导致该条目上计数器数值的增加,反过来说,计数器值的增加是由多个LBA一起贡献的,因此,当计数器值超过门槛值时,自然就不能确切地断定是映射到该条目的其中某个LBA包含了热数据。而通过K个独立哈希函数映射得到的K个条目,一起来判断LBA是否包含热数据,就会大大降低错误识别率。为了进一步减少错误识别率,基于哈希的热探测机制还采用了其他改进策略。在访问一个LBA时,并不是把与该LBA对应的所有K个计数器都增加1,而只是对这K个计数器中具有最小值的那个计数器增加1。因为,如果一个LBA包含热数据,那么,上面这种方式也可以最终让与这个LBA对应的全体K个计数器的值都超过门槛值,从而判定该LBA包含热数据。
6.3 代表性方法
为了解决闪存盘中的读写不对称问题,研究人员已经提出了许多缓冲区管理策略[JungYSPKC07] [OnLHWLX10][ParkJKKL06][JinOHL12][KimA08] [YangWHGC11] [TangMLL11]。许多方法都继承了面向磁盘的缓冲区替换策略(比如LRU和LIRS[JiangZ02]),但是,对脏页给予更高的优先级,让它有更多的机会保留在缓冲区中。因为,替换一个脏页会引起闪存的写操作,比驱逐一个干净页的代价高得多。例如,CFLRU[ParkJKKL06]替换策略把LRU链表分成两个区域,即工作区域和干净优先区域,干净优先区域中的干净页会被优先选择作为驱逐页,而只有当干净优先区域内没有干净页时,才会考虑驱逐脏页。CFDC[OuHJ09] [OuH10]替换策略是针对CFLRU替换策略的改进版本,可以获得更好的性能,包括:(1)减少了查找干净页作为驱逐页的时间;(2)采用页簇最小化脏页回写到闪存的代价;(3)尽可能避免了顺序访问模式对缓冲区性能的负面影响。CFDC中的页簇技术,是以页簇方式驱逐脏页,可以减少总代价,提高缓冲区性能。页簇技术和缓冲区管理策略,是两个相对独立的问题,前者可以被集成到后者,来进一步改善后者的性能,因此,和文献[OuHJ09]类似,文献[SeoS08] 也采用簇脏页技术进行批量驱逐。FD-Buffer[OnLHWLX10]也采用了和CFLRU和CFDC类似的策略,把缓冲区分成两个部分,分别服务于干净页和脏页;但是,CFLRU和CFDC会高度依赖于现有的特定替换策略,而FD-Buffer则可以对两个不同的缓冲区区域采用不同的替换策略,因此,可以灵活地直接利用不同类型的传统替换策略。LIRS-WSR[JungYSPKC07]和LRU-WSR[JungSPKC08]分别继承自LIRS和LRU,都对脏页给予了更高的优先级,如果一个脏页第二次被选中作为驱逐页,就把该脏页驱逐出缓冲区。但是,CFLRU和LRU-WSR等机制都没有考虑干净页的访问频度,有时候会导致较差的I/O性能。因此,CCF-LRU[LiJSCY09]对LRU-WSR进行了改进,它根据访问的频率把干净页分成热页和冷页,在驱逐时,首先驱逐冷干净页,当冷干净页不存在时才驱逐热干净页。AD-LRU[JinOHL12]替换策略是针对CCF-LRU替换策略的改进版本,其主要改进体现在设法控制缓冲区中冷区的大小,避免“干净页刚读入缓冲区就被选择为驱逐页”的情况,从而提高了缓冲区的命中率。相对于CCF-LRU算法而言,AD-LRU获得了更好的性能,并且在不同访问模式的工作负载下都能获得较好的性能。文献[LvCHC11]在设计替换策略FOR时,不仅充分考虑了闪存的特性,而且同时考虑了页面状态和未来的写操作,从而获得了更好的缓冲区性能改进。文献[OuH10]指出,其他算法都是通过优先替换干净页来减少替换脏页引起的物理写操作开销,因为,闪存的写代价明显高于读代价,但是,这些算法都没有充分考虑不同闪存设备具有不同读写代价比的情况,无法保证在不同的闪存设备上都可以获得较好的性能。因此,文献[OuH10]在设计面向闪存的缓冲区替换策略时,充分考虑了不同闪存设备的读、写代价比,以此适应不同读、写代价比的闪存设备。
6.3.1 CFLRU
文献[ParkJKKL06]在传统的LRU替换策略的基础上进行适当修改,设计了充分考虑闪存读写代价不对称特性的替换策略CFLRU(Clean-First LRU),可以用在包括数据库系统在内的各种系统的缓冲区管理中。CFLRU不仅考虑缓冲区命中率,而且考虑了驱逐脏页的替换代价,因为,从访问时间和能量消耗的角度来衡量,脏页的替换代价会比干净页的替换代价高。CFLRU的基本思想是在缓冲区中特意维护一定数量的脏页,这就等于增加了缓冲区中脏页的空间,使得脏页在闪存中比干净页停留更长的时间(文献[KoltsidasV08s]中的缓冲区替换策略也采用了类似的思路),从而减少闪存写操作和擦除操作的数量;但是,这会带来缓冲区命中率的恶化,因此,CFLRU的另一个设计目标就是要保证恶化的缓冲区命中率不会降低系统的总体性能。从大量实验结果来看,CFLRU在命中率方面有时候确实会低于普通的LRU算法,但是,在大多数情况下,CFLRU确实有效地减少了写操作和擦除操作的数量。
图[CFLRU]给出了关于CFLRU算法的一个实例。LRU链表中的页包括P1,P2,P3,P4,P5,P6,P7和P8,其中,P1,P4,P5是干净页, P2,P3,P6,P7和P8是脏页。CFLRU替换策略采用了“双区域”机制,把LRU链表划分成两个区域,即工作区域和干净优先区域,两个区域可以采用各种成熟的替换算法(比如LRU)。工作区域包含了最近最常使用(MRU:Most Recently Used)的页,即P1,P2和P3,大多数缓冲区命中都发生在这个区域。干净优先区域包含了作为驱逐候选的页,即P4,P5,P6,P7和P8,这些页有可能被驱逐出缓冲区。干净优先区域的窗口大小是w,必须选择合适的w值,因为,如果这个值太大,那么,缓冲区的命中率就会急剧下降。当请求某个页时,如果发生缓冲区脱靶,就需要启动驱逐和替换过程,CFLRU会首先在干净优先区域中选择一个干净页来驱逐,从而减少闪存写代价。如果干净优先区域中不再有干净页,那么就在LRU链表中的末尾选择一个脏页来驱逐。例如,在LRU替换算法下,LRU链表中的最后一个页经常被首先驱逐,因此,作为驱逐页的优先级顺序是P8,P7,P6,P5和P4。但是,在CFLRU替换策略下,作为驱逐页的优先级顺序是P5,P4,P8,P7和P6,也就是说,干净页P5,P4被首先驱逐,当干净页都被驱逐出去以后,才会考虑驱逐脏页P8,P7和P6。干净优先区域中的某个页被驱逐出去以后,就有了多余的空间来存放从工作区域驱逐出来的页,这时就可以从工作区域的LRU链表的尾部选择一个页,转移到干净优先区域,放在干净优先区域的LRU链表的头部,最后,从闪存中把被请求的页读取到缓冲区的工作区域中。
![图[CFLRU]CFLRU算法的一个实例](https://dblab.xmu.edu.cn/wp-content/uploads/2015/09/图CFLRUCFLRU算法的一个实例.jpg)
图[CFLRU] CFLRU算法的一个实例
CFLRU替换策略的缺陷表现在以下几个方面:
(1)需要动态调整窗口大小w,否则就很难适应不同类型的负载,但是,根据不同类型的负载确定一个合理的窗口大小,并不是一件容易的事情,可能需要根据一些采样数据进行大量实验从而确定获得最优性能的窗口大小。
(2)没有考虑缓冲区页的访问频度,在进行驱逐替换操作时,容易保留较老的脏页,而驱逐热的干净页,这就会导致命中率的降低,会比普通的LRU策略带来更多的读操作,恶化总体I/O性能。
(3)寻找干净页的开销较大。从图[CFLRU]中可以看出,干净页并不总是出现在LRU链表的尾部,而是倾向于待在“干净优先区域”中靠近工作区域的位置,比如,干净页P4,P5就不在LRU链表的尾部,而是出现在工作区域附近。因此,在选择驱逐一个干净页时,算法就必须反向搜索LRU链表来获得一个干净页,而且需要反向搜索较长的LRU链表,时间开销比较大。
(4)没能充分利用“干净优先区域”中的脏页所占据的内存资源。在LRU算法的假设中,处于“干净优先区域”中的脏页被重新访问的概率更低,因此,这部分宝贵的内存资源应该被更好地利用,用来最小化回写脏页的代价。
(5)顺序访问模式会恶化算法性能。CFLRU具有和LRU同样的问题,当负载中混杂了很多较长的顺序访问模式时,它的效率会变得很低,因为,顺序访问模式所访问过的页,会把之前缓冲区中的热页都排挤出缓冲区。
(6)替换脏页时,没有区分热脏页和冷脏页,有时候会恶化性能。在替换脏页时,替换冷脏页和替换热脏页的效果是不同的,通常而言,替换冷脏页的代价要小于替换热脏页的代价,因此,应该优先替换冷脏页。但是,CFLRU没有对脏页进行冷热区分,因此,无法获得最优的I/O总体性能。
6.3.2 CFDC
文献[OuHJ09]提出的CFDC(Clean-First Dirty-Clustered)替换策略,用在数据库系统的缓冲区管理层,是针对CFLRU替换策略的一种改进版本,它克服了CFLRU存在的一些缺陷,从而获得更好的性能。
CFDC有效解决了CFLRU中存在的三个问题:(1)寻找干净页的开销较大;(2)没能充分利用“干净优先区域”中的脏页所占据的内存资源来实现脏页回写代价最小化;(3)顺序访问模式会恶化算法性能。
针对CFLRU替换策略中存在的第一个问题,文献[OuHJ09]提出了CFLRU的改进算法——CFDC。如图[CFDC]所示,与采用“双区域”机制的CFLRU策略类似,CFDC策略也需要管理两个区域:(1)工作区域:保存那些被频繁访问的热页;(2)优先区域:通过为不同的页赋予不同的优先级,可以优化替换代价。优先区域中包含两个队列,即干净队列和脏队列,前者用于存放干净页(即P4,P5),后者用于存放脏页(即P6,P7和P8)。当一个页被驱逐出工作区域时,如果是一个干净页,就会进入优先区域的干净页队列,否则进入脏页队列。当发生缓冲区脱靶时,会从优先区域的干净队列的尾部选择一个干净页作为驱逐页,如果干净队列为空,就从脏队列的尾部选择一个脏页作为驱逐页。由于CFDC把干净页和脏页分开保存到两个不同的队列中,而不是像CFLRU那样统一保存在一个LRU链表中,因此,CFDC查找驱逐页的过程要比CFLRU快许多,前者只需要找到队列的尾部就可以确定驱逐页,而后者需要沿着LRU链表反向查找很长的距离。
![图[CFDC]CFDC算法的一个实例](https://dblab.xmu.edu.cn/wp-content/uploads/2015/09/图CFDCCFDC算法的一个实例.jpg)
图[CFDC] CFDC算法的一个实例
针对CFLRU替换策略中存在的第二个和第三个问题,CFDC采用的方法是,在“脏页”队列中支持页簇,也就是说,并不是维护一个脏页的队列,而是为页簇维护一个优先级队列。一个页簇是一个页的列表,具有位置相近性,也就是一个簇内的各个页的页号彼此接近,不同簇会被赋予不同的优先级,优先级较低的簇会首先被驱逐。CFDC设计了一个哈希表来管理这些脏页的簇,哈希表的键是簇号。当一个脏页进入优先区域时,CFDC会首先生成它的簇号,并且使用这个簇号执行一个哈希查询。如果这个簇已经存在,这个脏页就会被加入到该簇的尾部,该簇在脏页优先级队列中的位置就会发生调整。如果这个簇还不存在,包含该脏页的一个新簇就会被创建,插入到脏页队列中,并且在哈希表中注册这个新建的簇。当访问命中一个簇中的某个页的时候,这个页就会被转移到工作区域。在请求某个页的时候,如果发生缓冲区脱靶,就需要进行页的驱逐和替换,CFDC会首先从优先区域的干净队列的尾部选择一个干净页作为驱逐页,驱逐出缓冲区,如果优先区域中的干净队列是空的,就选择脏页队列中优先级最低的簇中的第一个页作为驱逐页,驱逐该页后得到的空间,可以用来存放从工作区域驱逐出来的页,这时可以从工作区域的LRU链表的尾部选择一个页,移动到优先区域,如果这个页是个干净页,就进入干净页队列,如果这个页是脏页,就进入脏页队列的某个簇中,转移结束后,工作区域就有了剩余的空间,这时就可以把被请求的页从闪存读入工作区域。
在CFDC替换策略中,簇越大,优先级越低,当发生缓冲区脱靶时,越会被首先驱逐。CFDC采用这种设计策略的原因是:(1)越大的簇,空间局部性越好,写入闪存时的效率越高,因此,被驱逐出缓冲区时,会具有更小的I/O开销;(2)簇越大,该簇内的页以顺序访问模式为主的可能性越大,而把顺序访问模式为主的页放在缓冲区中,会恶化缓冲区的性能,为了提升缓冲区性能,应该让以随机访问模式为主的页在缓冲区中停留更长的时间。从上面论述可以看出,CFDC替换策略可以最小化回写脏页的代价,并尽可能避免了顺序访问模式对缓冲区性能的负面影响,因此,CFDC替换策略可以有效解决CFLRU替换策略中存在的第二个和第三个问题。
6.3.3 LRU-WSR
LRU-WSR替换策略是为了克服CFLRU策略的缺陷而提出的,目标也是减少写操作的数量。CFLRU算法的一个缺陷是,它会驱逐干净页,在缓冲区中尽量保留脏页,但是,没有考虑这些脏页的访问频度。对于一个很少被访问的冷脏页而言,留在缓冲区的收益很小,会降低缓冲区命中率,恶化总体I/O性能,因此,应该被优先驱逐。
为了克服CFLRU的这个缺陷,LRU-WSR采用的策略是,延迟驱逐一个具有较高访问频度的脏页,具体而言就是:(1)使用和文献[HsiehCK05]中类似的“冷探测”技术来判断一个页是冷页还是热页;(2)如果一个页被判定为“非冷”,即该页不是冷页,就延迟把该脏页回写到闪存。使用这种策略,LRU-WSR的命中率会比普通LRU算法低,会带来更高的物理读操作。但是,这种算法有效减少了写操作和擦除操作的数量。因此,它提高了基于闪存的存储系统的整体I/O性能。需要注意的是,LRU-WSR是基于二次机会算法[Sliberschantz04]的启发式算法。在理论上,很难证明驱逐脏页可以提高总体I/O性能,但是,在实验结果上,确实可以看出LRU-WSR能够有效减少写操作和擦除操作的数量,同时不会导致命中率的严重恶化。
在LRU-WSR中,缓冲区中的所有页构成一个链表,每个页都有“冷页标记位”,但是,替换算法只会检查脏页的“冷页标记位”,而不会检查干净页的“冷页标记位”。如果一个页是冷页,就设置冷页标记位,如果一个页不是冷页(或称为“非冷页”),就清除冷页标记位。在进行缓冲区页替换时,当一个脏页P被选中作为候选驱逐页时,需要首先检查P的冷页标记位。如果P的冷页标记位没有被设置,P就会被移动到链表的MRU位置,并且设置它的冷页标记位,然后把链表的LRU位置的页作为候选驱逐页。如果P是脏页,并且已经设置了冷页标记位,说明P是一个冷脏页,就会被驱逐出缓冲区,回写到闪存。如果P是一个干净页,就不会考虑它的冷页标记位,直接被驱逐。当链表中的一个页被访问时,这个页就会被转移到链表的MRU位置,如果该页是脏页,还要清除它的冷页标记位。
![图[LRU-WSR]LRU-WSR算法的一个实例](https://dblab.xmu.edu.cn/wp-content/uploads/2015/09/图LRU-WSRLRU-WSR算法的一个实例.jpg)
图[LRU-WSR] LRU-WSR算法的一个实例
图[LRU-WSR]给出了LRU-WSR算法的一个实例。如图[LRU-WSR](a)所示,缓冲区的LRU链表包括5个页,即P0,P1,P2,P3,P4,其中,P2和P4是干净页,P0,P1,P3是脏页,P1被设置了冷页标记位,是一个冷脏页,P0和P3还未设置冷页标记位,都是非冷页。假设缓冲区只能容纳5个页,当访问第6个页P5时,由于P5不在缓冲区中,就会发生缓冲区页的替换。在替换缓冲区页时,从链表的LRU位置选择P0作为候选驱逐页(见图[LRU-WSR](a)),P0的冷页标记位还未设置,说明P0是非冷页,于是就把P0移动到MRU位置,并且设置P0的冷页标记位,P1变成了LRU位置,如图[LRU-WSR](b)所示。然后,LRU-WSR算法选择处于LRU位置的页P1作为候选驱逐页,由于P1已经为设置了冷页标记位,说明P1是一个冷脏页,因此,会被驱逐出缓冲区,回写到闪存中。最后,把P5放入缓冲区的LRU链表的MRU位置。
LRU-WSR的缺陷是没有考虑干净页的访问频度。在进行替换驱逐的时候,如果一个候选驱逐页是干净页,就不会考虑它的冷页标记位,直接被驱逐,很有可能被驱逐的是热干净页。和驱逐冷干净页相比,驱逐热干净页的代价更大。驱逐热干净页可能会引起额外的读操作,因为,热干净页是未来很可能会被再次访问的页,被驱逐出去以后,下次再被访问时,就需要再次从闪存读取。此外,在LRU-WSR中,可能出现一些最近只被访问一次的冷干净页污染缓冲区的情况,导致冷脏页和热干净页更快地被驱逐出去。而已有的研究[LiJSCY09]表明,驱逐冷脏页和热干净页的代价都要比驱逐冷干净页的代价大。
图[LRU-WSR-shortcoming]是说明LRU-WSR算法缺陷的一个实例。在LRU链表中,一共包括5个页,即P0,P1,P2,P3,P4,其中,P0,P2和P4是干净页,P1,P3是脏页,P1被设置了冷页标记位,是一个冷脏页,P3还未设置冷页标记位,都是非冷页。假设缓冲区只能容纳5个页。当访问第6个页P5时,由于P5不在缓冲区中,就会发生缓冲区页的替换。在替换缓冲区页时,根据LRU-WSR算法,首先从LRU链表中选择LRU位置的页P0作为候选驱逐页,P0是一个干净页,可以直接驱逐,然后,把P5放入到链表的MRU位置。接下来,假设需要再次访问P0,由于刚才已经把P0驱逐出缓冲区,因此,就会再次发生页的替换。算法会选择P1作为候选驱逐页,P1是一个脏页,需要检查冷页标记位,发现是一个冷脏页,就可以直接驱逐出去,把P1回写到闪存,并从闪存中读取P0到缓冲区中,放到链表的MRU位置。从上述过程可以看出,为了完成对P5和P0的访问,总共发生了一次写操作(把脏页P1回写到闪存)和一次读操作(从闪存读取P0到缓冲区)。实际上,在驱逐P0时,如果能够考虑到它是一个热干净页,就不应该直接驱逐,因为驱逐热干净页会带来额外的开销,代价较大;更好的做法是,在驱逐P0时,如果发现它是一个热干净页,就不驱逐,而是继续寻找下一个候选驱逐页,找到P1后,发现是一个冷脏页,就可以直接驱逐出去。这样,下次再访问P0时,P0仍然在缓冲区中,不需要到闪存读取P0。在这种新的替换策略下,完成对P5和P0的访问就只需要一次写操作(把脏页P1回写到闪存),很显然,代价比LRU-WSR算法更低。 ![图[LRU-WSR-shortcoming]LRU-WSR算法缺陷的一个实例](https://dblab.xmu.edu.cn/wp-content/uploads/2015/09/图LRU-WSR-shortcomingLRU-WSR算法缺陷的一个实例.jpg)
图[LRU-WSR-shortcoming] LRU-WSR算法缺陷的一个实例
6.3.4 CCF-LRU
CFLRU和LRU-WSR都使用干净优先机制来首先驱逐缓冲区中的干净页。虽然这些方法比传统的LRU策略性能好,但是,它们都没有考虑干净页的访问频度,有时可能会导致较差的I/O性能。为了解决这个问题,文献[LiJSCY09]提出了新的缓冲区替换策略CCF-LRU(Cold-Clean-First LRU),它可以改善之前的CFLRU和LRU-WSR算法的性能。CCF-LRU的主要目标就是通过减少写操作的次数来改进整体I/O性能。
CCF-LRU算法的主要思想是:使用“冷探测”机制来判断一个页是热页还是冷页;在替换操作时,尽可能优先驱逐冷干净页,尤其是那些最近只被访问过一次的干净页;如果不存在上述冷干净页,就驱逐冷脏页,而不是驱逐热干净页。
CCF-LRU采用上述策略是因为,驱逐一个热脏页的代价是最大的,驱逐一个冷干净页的代价是最小的,驱逐热干净页的代价,比驱逐冷干净页的代价大。为了提高整体I/O性能,就必须尽量减少驱逐热脏页和热干净页的次数。
图[CCF-LRU]显示了CCF-LRU算法的数据结构,包括两个链表,即ML链表(Mixed LRU List)和CCL链表(Cold Clean LRU List)。ML链表用于维护热干净页和脏页(包括热脏页和冷脏页),CCL链表用于维护冷干净页。ML链表可以容纳L1个页,CCL链表可以容纳L2个页,并且有如下关系成立:L1+L2=L,其中L表示缓冲区可以容纳的页的数量。也就是说,ML链表和CCL链表共享缓冲区空间,二者的尺寸L1和L2都位于区间[0,L]内,在算法运行过程中,二者的尺寸会在区间[0,L]内动态变化,但是,一直都会满足条件L1+L2=L。
![图[CCF-LRU]CCF-LRU算法的数据结构](https://dblab.xmu.edu.cn/wp-content/uploads/2015/09/图CCF-LRUCCF-LRU算法的数据结构.jpg)
图[CCF-LRU] CCF-LRU算法的数据结构
在CCF-LRU算法中,第一次被访问的页都默认被看成是冷页,每个页都被插入到CCL链表中,并设置冷标志位。当CCL链表中的页再次被访问或者变成脏页时,它就会被移动到ML链表的MRU(Most Recently Used)位置。当ML链表中的某个页被访问的时候,它会被移动到ML链表的MRU位置。当需要进行页的替换时,就需要选择一个驱逐页,CCF-LRU确定驱逐页的过程如下:
(1)如果CCL链表不为空,就把CCL链表中处于LRU位置的页作为驱逐页;
(2)如果CCL链表为空,就把处于ML链表的LRU位置的页作为候选驱逐页,如果这个候选驱逐页是一个冷脏页,就选定作为最终驱逐页,把它从缓冲区中驱逐出去;如果这个候选驱逐页是一个热脏页,就把它标记为“冷”,并且移动到ML链表的MRU位置。如果候选驱逐页是一个热干净页,就标记为“冷”,从ML链表中移除,移动到CCL链表的MRU位置,然后继续检查ML链表的LRU位置。如果在遍历一次ML链表以后没有找到驱逐页,就需要再次调用CCF-LRU算法重新寻找驱逐页。
CCF-LRU算法的缺陷是无法探测热干净页。CCF-LRU在设计上采用了两个链表,即CCL链表(Cold Clean LRU List)和ML链表(Mixed LRU List)。在进行页的替换时,算法会首先选择CCL链表中的冷干净页进行驱逐,随着系统的运行,CCL链表会逐渐缩小,甚至最终可能变成空。在这种情况下,当一个新的读页插入到CCL链表中以后,当再有一个新的页需要缓冲区空间的时候,这个读页就会被立即驱逐。因此,除非一个页被连续两次读取,否则,一个干净页根本没有机会成为热页。由此导致的结果是,当脏页完全占据缓冲区以后,干净页是很难再获得缓冲区的。
6.3.5 AD-LRU
相对于CCF-LRU算法而言,AD-LRU[JinOHL12]算法在性能有了进一步的提升,该算法设法控制缓冲区中冷区的大小,以此避免“一个干净页刚读入缓冲区就被选择为驱逐页”的情况。AD-LRU主要思想如下:
- 将缓冲区分为冷区和热区,冷区中存放那些只访问过一次的页,热区中存放那些至少访问过两次的页;
- 冷、热区的大小是动态调整的。当冷区中的页被命中时,就将该页转移到热区,此时,冷区容量减少,热区容量增加;当替换操作发生在热区时,AD-LRU会在热区中选择驱逐页,并将新读入的页存到冷区的MRU位置,此时,热区容量减少,冷区容量增加;
- 冷区容量有一个下界(min_lc),当冷区的容量大于等于min_lc时,替换操作发生在冷区,当冷区的容量小于min_lc时,替换操作发生在热区;
- 替换操作无论发生在冷区还是在热区,都优先替换干净页,若冷区中没有干净页,则其它页的替换顺序和LRU算法一样,若热区中没有干净页,则使用二次机会策略替换脏页。
![图[AD-LRU]AD-LRU算法的数据结构](https://dblab.xmu.edu.cn/wp-content/uploads/2015/09/图AD-LRUAD-LRU算法的数据结构.jpg)
图[AD-LRU] AD-LRU算法的数据结构
如图[AD-LRU]所示,AD-LRU算法将缓冲区分为冷区和热区,且冷、热区的大小是动态调整的。第一次引用一个新页时,它将会被插入到冷区的MRU位置,缓冲区中的页被再次引用时,它将会被转移到热区的MRU位置。参数min_lc用于防止冷区不断缩减,最后出现冷区为空的情况,从而发生干净页刚读入缓冲区就被选择为驱逐页的情况。变量FC用于指向最近最少使用的干净页,以此加快驱逐页的查找速度。
图[AD-LRU-example]给出了一个AD-LRU算法的实例。假设缓冲区最多只能同时容纳6个页,且冷区的下界min_lc为2。在初始阶段(见图[AD-LRU-example](a)),缓冲区中包含了P0,P1,P2,P3,P4,,P5共6个页,其中,P0和P1是冷脏页,P2是冷干净页,P3是热脏页,P4和P5是热干净页。这时,一个针对页P1的读操作到达,AD-LRU算法检查缓冲区后发现P1已经在缓冲区中,就直接从缓冲区读取P1,P1被访问后,AD-LRU算法将P1转移到热区的MRU位置,如图[AD-LRU-example](b)所示。然后,一个针对页P6的读操作到达,AD-LRU算法检查缓冲区后发现P6不在缓冲区中,需要到辅助存储中读取P6放入缓冲区。但是,这时缓冲区已满,需要驱逐一页以腾出空间存放P6,AD-LRU算法先判断冷区是否达到下界,以确定是在冷区中选择驱逐页还是在热区中选择驱逐页,由于此时冷区中依然有两个页,大于等于冷区的下届min_lc,所以AD-LRu算法在冷区中选择驱逐页。AD-LRU算法总是在冷区中优先选择干净页,只有冷区中没有干净页时,才会选择脏页作为驱逐页,在本例中,AD-LRU算法将会选择冷干净页P2为驱逐页,驱逐出缓冲区,然后,把从辅助存储中读取到得P6放入冷区的MRU位置,如图[AD-LRU-example](c)所示。
![图[AD-LRU-example]AD-LRU算法的一个实例](https://dblab.xmu.edu.cn/wp-content/uploads/2015/09/图AD-LRU-exampleAD-LRU算法的一个实例-647x680.jpg)
图[AD-LRU-example] AD-LRU算法的一个实例
AD-LRU虽然获得了比CCF-LRU更好的性能,但是,AD-LRU算法存在以下三个问题:(1)它并没有彻底解决CCF-LRU的缺陷,这是因为AD-LRU在冷区中总是优先替换干净页,随着系统的运行,脏页可能完全占据冷区。当脏页完全占据冷区时,会出现与CCF-LRU一样的问题,即一个干净页刚读入缓冲区就被选择为驱逐页,从而导致该页没有机会成为热页,降低了缓冲区的命中率;(2)在系统运行一段时间以后,冷热区的容量趋于稳定,此时,缓冲区中冷、热区的容量不再是动态调整的;(3)AD-LRU也很难根据不同访问模式的工作负载确定一个合理的冷区下界(min_lc)。确定一个合理的冷区下界并不是一件容易的事情,可能需要根据一些采样数据进行大量实验,从而确定获得最优性能的冷区下界(min_lc)。
6.3.6 FOR
现有的面向闪存的缓冲区替换算法,虽然改善了基于闪存的数据库系统的性能,但是,它们只是简单地考虑了当前页面的状态,忽略了未来操作的时间局部性。对于那些不存在未来写操作或者已经长时间没有活动的页,应该被驱逐出去,从而释放宝贵的缓冲区资源。因此,页面状态和未来操作对于缓冲区管理而言都是非常重要的。
因此,文献[LvCHC11]提出了一个新的缓冲区替换算法——FOR(Flash-based Operation-aware buffer Replacement),核心思想是基于操作感知的页权重策略来进行缓冲区替换。缓冲区中的每个页都会被赋予一个权重,权重较低的页面会首先被驱逐。在计算页权重时,综合考虑了页面的状态(干净页还是脏页)以及页的热度,而页的热度是与页的操作统计信息有关的。一个页p的权重Wp的计算公式如下:
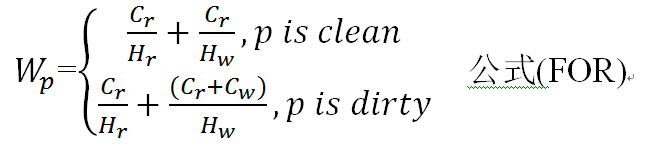
其中,Cr表示从闪存中读取一个页的代价,Cw表示向闪存写入一个页的代价。Hr表是一个读操作的热度,Hw表示一个写操作的热度。
一般而言,把热页(被频繁访问的页)保存在缓冲区中,可以明显提高命中率。在已有的研究中,已经有许多种方法可以用来衡量缓冲区页的热度,最常见的衡量方法是频度(frequence)和新颖度(Recency)。文献[LvCHC11]的作者采用了全新的缓冲区页热度计算方法,综合考虑了频度和新颖度。由于闪存读写操作具有不同的特性,因此,作者对一个页分别定义了读操作热度和写操作热度。在操作热度中综合考虑频度和新颖度。作者定义了两个概念,即操作间距离(IOD:Inter-operation Distance)和操作新颖度(OR:Operation Recency)来分别反映一个页操作的频度和新颖度。
在一个由多个操作构成的操作序列中,一个操作e的操作间距离IODe是指,针对一个页的两个同样的操作之间所间隔的不同操作的数量,如果这个操作序列中只包含一个操作e,即操作e只出现过1次,那么,IODe的值就为空。IODe的值越小,操作e的热度越高。一个操作e的操作新颖度ORe是指,在操作e出现以后执行的不同操作的数量。ORe的值越小,说明操作e越新,即操作e执行的时刻距离当前时刻越近。
![图[FOR]采用FOR算法计算IOD和OR的一个实例](https://dblab.xmu.edu.cn/wp-content/uploads/2015/09/图FOR采用FOR算法计算IOD和OR的一个实例.jpg)
图[FOR] 采用FOR算法计算IOD和OR的一个实例
图[FOR]显示了采用FOR算法计算IOD和OR的一个实例,图中的操作链表显示了一系列针对不同的页的读写操作。对于某个操作e而言,ORe就是位于表头和e之间的所有不同操作的数量,比如对于操作序列中的第一个操作e0而言,是对页A的写操作,这时,LRU链表只有一个元素e0,ORe0的值为0和IODe0为空(NULL),当操作序列中的第二个操作(对页C的读操作)e1到达以后,LRU链表的表头变成e1,表尾是e0,因为从表头到操作e0之间的所有不同操作就只有e1,因此,ORe0的值就变为1,由于此时还没有再次出现和e0、e1相同的操作,因此,这时不需要计算e0和e1的IOD值。当操作e2到达时,ORe0的值变成2,ORe1的值变成1。可以看出,每个新操作到达后,之前操作的OR值都会增加1,OR的值越大,表示这个操作越老。依此类推,每操作e4到达时,这个操作是针对页A的再次写操作,即e4和e0是针对同一个页A的两个同样的操作,因此,这时就可以计算IODe4的值,由于操作e0和e4之间所包含的所有不同操作是e1、e2和e3,因此,IODe4的值就是3,同时还要更新e3、e2、e1和e0的OR值。依此类推,每当一个新的操作到达时,都可以去调整相应的OR或IOD的值。当e7到达时,可以计算得到IODe7的值为5,因为e7和e1都是针对页C的读操作,属于针对同一个页面的相同操作,e7和e1之间间隔了e2、e3、e4、e5和e6共5个操作。当e8到达时,可以计算得到e8的IOD值为2,因为,e5和e8都是针对页E的写操作,属于针对同一个页面的相同操作,e5和e8之间包括e6和e7共计2个操作。当最近的一个操作e9到达时,当前各个操作的IOD值是:IODe0=NULL,IODe1=NULL,IODe2=NULL,IODe3=NULL,IODe4=3,IODe5=NULL,IODe6=NULL,IODe7=5、IODe8=2,IODe9=NULL;当前各个操作的OR值是:ORe0=9,ORe1=8,ORe2=7,ORe3=6,ORe4=5,ORe5=4,ORe6=3,ORe7=2,ORe8=1,ORe9=0。
IOD和OR在衡量相关页的热度方面是互补的,需要综合考虑。OR只反映这个页操作的新颖度,而忽略了长期负载模式。而只使用IOD也是有问题的,因为,没有包含最近的操作信息。因此,针对一个操作e,综合考虑IOD和OR后,计算得到操作e的操作热度He是:
He = α* IODe + (1−α)∗ORe
其中,α是加权系数,用来调整IODe和ORe的相对重要性。
FOR克服了CCF-LRU的明显缺陷。CCF-LRU在设计上的一个不足之处就是无法探测热干净页。相反,FOR则不存在这个问题,因为即使在该页被驱逐以后,算法仍然通过IOD和OR值来维护着与它相关的操作信息。因此,对于FOR而言,当一个干净页再次被读取的时候,它就有机会成为热页。
6.3.7 CASA
文献[OuH10]指出,其他算法都是通过优先替换干净页来减少替换脏页引起的物理写操作开销,因为,闪存的写代价明显高于读代价,但是,这些算法都没有充分考虑不同闪存设备具有不同读写代价比的情况,无法保证在不同的闪存设备上都可以获得较好的性能。因此,文献[OuH10]在设计面向闪存的缓冲区替换策略时,充分考虑了不同闪存设备的读、写代价比,以此适应不同读、写代价比的闪存设备。
现有的面向闪存的缓冲区替换算法都是优先替换干净页,让脏页有更多的机会驻留缓冲区。但是,这些算法都没有充分考虑不同闪存设备具有不同读写代价比的情况,无法保证在不同的闪存设备上都可以获得较好的性能。对于不同的设备而言,读、写代价的比例差异很大。当把以上方法应用于读、写代价差异较小的闪存时,在不考虑干净页操作代价的情况下就无条件优先置换干净页是不合理的,甚至可能出现性能下降的问题,从而无法适用于不同种类的闪存磁盘。
文献[OuH10]提出了一种基于代价的自适应缓冲区替换策略,该策略能够适用于不同读、写代价比的闪存设备。CASA算法的主要思想如下:(1)将缓冲区分为干净页链表(clean list C)和脏页链表(dirty list D),干净页链表和脏页链表的大小是动态调整的;(2)维护干净页链表的目标大小(τ),如果干净页链表的目标大小大于实际大小(|C|),就在干净页链表中选择驱逐页,否则,在脏页链表中选择驱逐页,以此来动态调整干净页链表和脏页链表的大小;(3)在干净页链表和脏页链表中都使用LRU算法选择驱逐页;(4)根据数据的访问模式和闪存的读、写代价比共同决定τ值的变化。在CASA算法中,当缓冲区满时,干净页链表的大小(|C|)和脏页链表的大小(|D|)满足如下等式:|C|+|D|=b(缓冲区的容量),0 ≤ |C| ≤ b,0≤|D|≤b。如图所示:
![图[CASA]CASA算法的数据结构](https://dblab.xmu.edu.cn/wp-content/uploads/2015/09/图CASACASA算法的数据结构-680x355.jpg)
图[CASA] CASA算法的数据结构
在CASA算法中,τ为干净页链表的目标大小,且有0≤τ≤b,|C|为干净页链表的实际大小;b–τ为脏页链表的目标大小,|D|为脏页链表的实际大小。CASA算法选择驱逐页的过程如下:先判断干净页的实际大小是否大于目标大小,如果干净页的实际大小大于目标大小,即满足|C|>τ,则在干净页链表中选择驱逐页,否则,就在脏页链表中选择驱逐页(此时有|D|>b-τ)。
CASA算法的自适应性主要体现在能够动态调整干净页链表的目标大小τ的值,并通过τ的值确定在干净页链表中选择驱逐页还是在脏页链表中选择驱逐页,以此来控制干净页链表和脏页链表的实际大小。该算法通过相对成本收益(relative cost effectiveness)适应不同的工作负载,通过归一化闪存的读、写代价,适应不同读、写代价比的闪存设备。
根据相对成本收益适应不同的工作负载的原理如下:请求页在干净页链表中命中时,说明对于当前的工作负载,对干净页的操作更多,就增加干净页链表的目标大小,即增加τ的值。此时的相对成本收益为|D|÷|C|。同理,当脏页命中时,说明对于当前工作负载,脏页的操作更多,则减少τ的值,此时的相对成本收益为|C|÷|D|。相对成本收益决定了每次调整τ值的多少,当干净页链表很小时,|D|÷|C|是一个很大的值,则此时会迅速增加τ的值,当干净页链表很大时,|D|÷|C|是一个很小的值,此时就微调τ的值。同理,在脏页链表中命中时,需要减少τ的值,也受到脏页链表的相对成本收益|C|÷|D|的控制。
CASA算法通过归一化闪存的读、写代价来控制τ值,以此适应不同读、写代价比的闪存设备。该算法通过归一化闪存的读代价(CR)和写代价(CW),使得CR+CW等于1。读写代价比和相对成本收益共同决定了τ值的调整。当请求页在干净页链表中命中时,CASA算法增加τ的值,且每次增加CR*(|D|÷|C|);当请求页在脏页链表中命中时,CASA算法减少τ的值,且每次减少CW*(|C|÷|D|)。
CASA算法引入了相对成本收益的概念,所以能够避免干净页链表或脏页链表为空的极端情况。比例,在一段时间内,算法持续只读操作,那么缓冲区中命中的页都是干净页。干净页的持续命中会导致τ值的持续增加,τ增加以后会有干净页链表的实际大小大于目标大小,即|C|<τ,这将导致接下来的替换操作一直发生在脏页链表中,从而使得干净页链表越来越大,脏页链表越来越少,即干净页链表占据缓冲区的大部分空间,此时,干净页链表的实际大小|C|是一个很大的值,脏页链表的实际大小|D|是一个很小的值。当脏页链表很小时,就会出现最近刚被访问的脏页马上就被替换的情况,从而降低了命中率。但是,CASA算法能够快速的恢复到混合工作负载模式。假设在持续一段时间的只读操作以后,干净页链表占据了缓冲区的大部分空间,此时如果有一个脏页命中,就会使得τ值减少,且减少Cw*(|C|÷|D|),因为此时干净页链表占据了缓冲区中大部分空间,即|C|比|D|大很多,所以|C|÷|D|是一个很大的值,因此,Cw*(|C|÷|D|)也是一个很大的值,当τ的值减少Cw*(|C|÷|D|)以后,τ就恢复到一个适当大小的值,即算法快速地恢复到了混合工作负载的状态,避免脏页链表太小而导致最近刚使用的脏页马上就被替换的情况。同理,算法在持续一段只写操作以后,也能够快速地恢复到混合工作模式的状态。
CASA算法充分考虑了不同闪存设备的读、写代价比,以及不同工作负载的读写比例,所以能够适应于不同的工作负载和不同读、写代价的闪存设备。该算法的主要缺陷是没有考虑页的访问频度,每个页的访问频度是不同的,任何缓冲区替换策略都应该尽可能将访问频度高的页保留在缓冲区中,以获得较高的命中率。
6.3.8 综合实例
图[replace-example]展示了不同的缓冲区替换算法选择驱逐页的过程,包括CFLRU、CFDC、LRU-WSR、CCF-LRU和AD-LRU。在这个例子中,假设缓冲区最多只能同时容纳8个页,它们最后的访问顺序是P0,P1,P2,P3 ,P4 ,P5 ,P6 ,P7。其中,P0和P5是冷脏页,P1和P4是热干净页,P2和P6是冷干净页,P3和P7是热脏页。假设此时一个访问P8的请求到达,由于缓冲区已满,所以需要将缓冲区中的一个页驱逐出去,以腾出空间存放P8。
图[replace-example] (a)展示了CFLRU、CFDC和LRU-WSR算法选择驱逐页的结果。CFLRU算法将缓冲区分为工作区域和干净优先区域,该算法在选择驱逐页时,总是在干净优先区域中优先选择干净页,如果干净页优先区域中没有干净页,则选择LRU位置的数据页为驱逐页。在本例中,CFLRU算法将选择热干净页P1为驱逐页。CFLRU算法选择一个热页作为驱逐页,是因为该算法没有考虑数据访问的频度,虽然P1是热页,但是它是干净优先区域中最旧的干净页,所以被CFLRU选择为驱逐页。
CFDC算法是对CFLRU算法的改进。相对于CFLRU算法而言,CFDC有以下三方面的优势:(1)能够以更快的速度选择驱逐页;(2)通过页簇技术,减少脏页回写代价;(3)能够避免一次扫描操作对缓冲区的污染。CFDC中的页簇技术只有在替换脏页时有效,在本例中,CFDC的选择和CFLRU一样,即选择热干净页P1为驱逐页(如图[replace-example] (a)所示)。
LRU-WSR算法相对于CFLRU有了进一步的改进,该算法考虑了脏页的访问频度,使得热脏页能够更长时间地驻留缓冲区,因此,提高了缓冲区命中率,减少了写操作次数,从而获得了整体性能的提升。LRU-WSR算法在选择驱逐页时,先获取LRU位置的数据页:(1)如果该页是冷标记位为0的脏页,则认为该页是热脏页,就给该页第二次机会,将其冷标记位设置为1,并转移到MRU位置,然后,再次选择LRU位置的数据页进行判断;(2)如果选择的数据页是冷标记位为1的脏页或干净页,就直接替换。根据上述替换过程,在本例中,LRU-WSR算法会选择冷脏页P0为驱逐页(如图[replace-example] (a)所示)。
![图[replace-example]缓冲区替换算法的一个综合实例](https://dblab.xmu.edu.cn/wp-content/uploads/2015/09/图replace-example缓冲区替换算法的一个综合实例-574x680.jpg)
图[replace-example] 缓冲区替换算法的一个综合实例
图[replace-example] (b)展示了CCF-LRU算法选择驱逐页的结果。CCF-LRU算法将缓冲区分为ML链表(Mixed LRU List)和CCL链表(Cold Clean LRU List),其中,ML链表中存放热干净页和脏页,CCL中存放冷干净页。CCF-LRU算法总是优先替换CCL链表中的页,只有CCL链表为空时,才会在ML链表中选择驱逐页,在本例中CCF-LRU会选择冷干净页P2为驱逐页。
图[replace-example] (c)显示了AD-LRU算法的选择驱逐页的过程。AD-LRU将缓冲区分为热区(Hot LRU)和冷区(Cold LRU),热区中存放至少访问过两次的页,冷区中存放只访问过一次的页。AD-LRU算法无论在冷区还是热区,总是优先替换干净页,当冷区中没有干净页时,其他页的替换顺序与LRU算法一样,当热区中没有干净页时,则使用二次机会策略替换其他页。在本例中,AD-LRU算法会在冷区选择冷脏页P2为驱逐页。
根据前文所述,在面向闪存的缓冲区替换算法中,数据页的替换代价有如下关系:Cost(CC) < Cost(CD) < Cost(HC) < Cost(HD)。所以,一个好的缓冲区替换算法应该优先替换冷干净页,在不存在冷干净页时,再替换冷脏页,并尽可能让热数据页更长时间地驻留内存。根据这个判断标准,在本例中,数据页被替换的先后顺序依次是P2,P6,P0,P5,P1,P4,P3和P7,即P2应该最先被替换,P7应该最后被替换。由此可以看出,CF-LRU和CFDC作出了最差选择,而CCF-LRU和AD-LRU作出了最优的选择。
6.4 本章小结
本章内容首先给出了缓冲区管理策略概述,描述了最具有代表性的LRU算法的基本原理;然后,指出了重新设计面向闪存的缓冲区替换策略的必要性,因为,闪存和磁盘具有截然不同的技术特性,面向磁盘特性开发的缓冲区替换算法无法在闪存设备上获得好的性能;接下来,分别介绍了设计面向闪存的缓冲区替换策略的考虑因素和关键技术;最后,介绍了闪存数据库的缓冲区管理方面的代表性方法,包括CFLRU、CFDC、LRU-WSR、CCF-LRU、AD-LRU、FOR、CASA等,并给出了一个综合实例。
6.5 习题
- 说明重新设计面向闪存的缓冲区替换策略的必要性。
- 阐述设计面向闪存的缓冲区替换策略的考虑因素。