林子雨、郑海山、赖永炫编著《Spark编程基础(Python版)》(教材官网)教材中的代码,在纸质教材中的印刷效果,可能会影响读者对代码的理解,为了方便读者正确理解代码或者直接拷贝代码用于上机实验,这里提供全书配套的所有代码。
查看所有章节代码
继续阅读
林子雨编著《Spark编程基础(Python版)》教材第5章的命令行和代码
林子雨、郑海山、赖永炫编著《Spark编程基础(Python版)》(教材官网)教材中的代码,在纸质教材中的印刷效果,可能会影响读者对代码的理解,为了方便读者正确理解代码或者直接拷贝代码用于上机实验,这里提供全书配套的所有代码。
查看所有章节代码
继续阅读
林子雨编著《Spark编程基础(Python版)》教材第4章的命令行和代码
林子雨、郑海山、赖永炫编著《Spark编程基础(Python版)》(教材官网)教材中的代码,在纸质教材中的印刷效果,可能会影响读者对代码的理解,为了方便读者正确理解代码或者直接拷贝代码用于上机实验,这里提供全书配套的所有代码。
查看所有章节代码
继续阅读
教材代码-林子雨编著《Spark编程基础(Python版)》教材所有章节命令行和代码
林子雨、郑海山、赖永炫编著《Spark编程基础(Python版)》(教材官网)教材中的代码,在纸质教材中的印刷效果,可能会影响读者对代码的理解,为了方便读者正确理解代码或者直接拷贝代码用于上机实验,这里提供全书配套的所有代码。
继续阅读
林子雨编著《Spark编程基础(Python版)》教材第3章的命令行和代码
林子雨、郑海山、赖永炫编著《Spark编程基础(Python版)》(教材官网)教材中的代码,在纸质教材中的印刷效果,可能会影响读者对代码的理解,为了方便读者正确理解代码或者直接拷贝代码用于上机实验,这里提供全书配套的所有代码。
查看所有章节代码
继续阅读
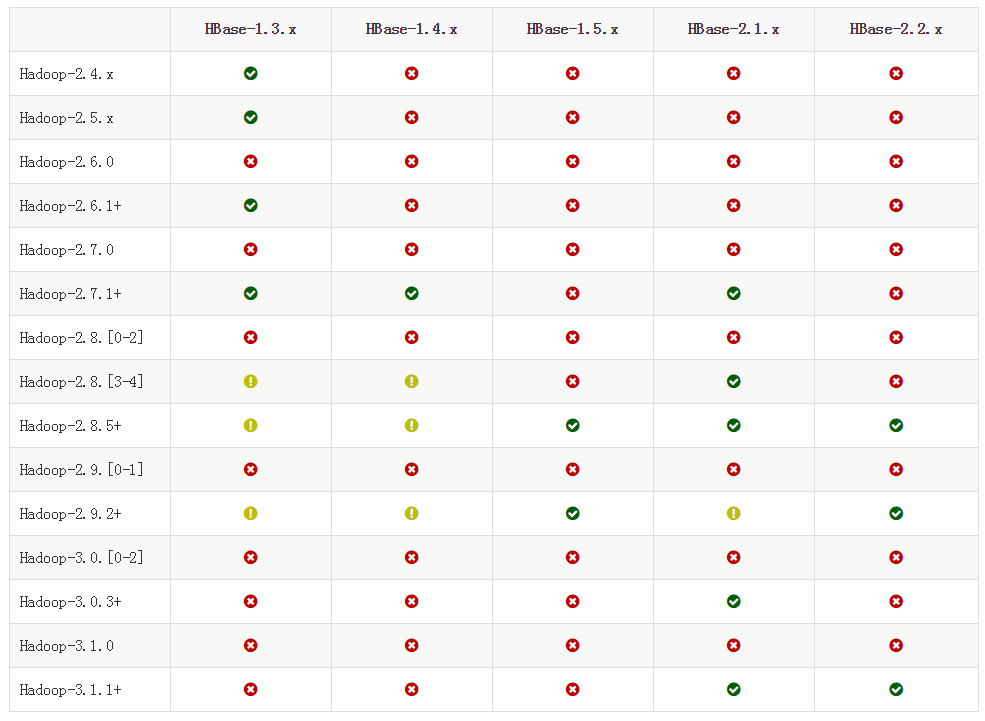
Hadoop与HBase的最新版本兼容性
Hadoop与HBase的最新版本兼容性
下面表格截图来自官网http://hbase.apache.org/book.html#supported.datatypes
基于 TMDB 数据集的电影数据分析
【版权声明】版权所有,严禁转载,严禁用于商业用途,侵权必究。
本案例由厦门大学计算机系2018级研究生王福泰同学制作,这里对他表示衷心的感谢!
相关教材:林子雨、郑海山、赖永炫编著《Spark编程基础(Python版)》(访问教材官网)
相关案例:基于Python语言的Spark数据处理分析案例集锦(PySpark)
使用IntelliJ IDEA和Python开发WordCount程序
IntelliJ IDEA(简称“IDEA”),是使用Java语言开发的集成开发环境,是被业界公认为最好的Java开发工具之一,尤其在智能代码助手、代码自动提示、重构、J2EE支持、各类版本工具(git、svn、github等)、JUnit、CVS整合、代码分析、创新的GUI设计等方面,具有非常好的特性。
本文将详细讲解IDEA的安装、Python插件的安装以及使用IDEA开发Python程序的方法。
继续阅读