

点击这里观看厦门大学林子雨老师主讲《大数据技术原理与应用》授课视频
【版权声明】博客内容由厦门大学数据库实验室拥有版权,未经允许,请勿转载!
[返回Spark教程首页]
学习Spark和Scala,需要安装相应的编程环境。可以选择在Windows操作系统中安装,也可以在Linux下安装。笔者建议在Linux操作系统下面进行学习,本教程的所有操作,都也是在Linux下完成的。但是,如果读者只是想简单快速学习一下Scala,还没有进入Spark学习,那么,在学习Scala的阶段,在Windows系统中调试Scala程序,也是可以的。因此,下面的教程,也提供了Windows中安装Scala的方法。
一、在Windows操作系统中安装Scala
Scala程序需要运行在JVM(Java虚拟机)上,因此,在安装Scala之前,需要在Windows系统中安装Java,然后,再安装Scala。
第1步:安装Java
Scala程序需要运行在JVM(Java虚拟机)上,因此,在安装Scala之前,需要在Windows系统中安装Java环境。可以到Java官网(官网)下载JDK,比如,笔者于2016年10月31日下载的是jdk-8u111-windows-x64.exe文件,然后,运行该程序就可以完成JDK的安装。
第2步:安装Scala
访问Scala官网(官网),下载Scala。登录后,官网会自动识别你的操作系统类型,如果是Windows操作系统,官网会自动提供.msi格式的安装包,比如,笔者于2016年10月31日登录官网,可以下载到scala-2.11.8.msi,在Windows操作系统中,可以运行这个安装包,安装Scala。
二、在Linux操作系统中安装Scala
Scala程序需要运行在JVM(Java虚拟机)上,因此,在安装Scala之前,需要在Linux系统中安装Java,然后,再安装Scala。
这里假设你已经安装好了Linux系统,如果你还没有安装Linux系统,请参考厦门大学数据库实验室的博客文章(查看),了解如何安装Linux操作系统。
请启动并进入Linux操作系统,并打开命令行终端(可以使用快捷键组合:ctrl+alt+t,打开终端窗口),进入shell环境。下面开始安装Java和Scala。
第1步:安装Java
请确保你的Linux系统中已经安装了Java JDK1.5或更高版本,并设置了JAVA_HOME环境变量,而且已经把JDK的bin目录添加到PATH变量。
Java环境可选择 Oracle 的 JDK,或是 OpenJDK。为图方便,这边直接通过命令安装 OpenJDK 7。
sudo apt-get install openjdk-7-jre openjdk-7-jdk
JRE和JDK的区别: JRE(Java Runtime Environment,Java运行环境),是运行 Java 所需的环境。JDK(Java Development Kit,Java软件开发工具包)即包括 JRE,还包括开发 Java 程序所需的工具和类库。
安装好 OpenJDK 后,需要找到相应的安装路径,这个路径是用于配置 JAVA_HOME 环境变量的。执行如下命令:
dpkg -L openjdk-7-jdk | grep '/bin/javac'
该命令会输出一个路径,除去路径末尾的 “/bin/javac”,剩下的就是正确的路径了。如输出路径为 /usr/lib/jvm/java-7-openjdk-amd64/bin/javac,则我们需要的路径为 /usr/lib/jvm/java-7-openjdk-amd64。
接着需要配置一下 JAVA_HOME 环境变量,为方便,我们在 ~/.bashrc 中进行设置(扩展阅读: 设置Linux环境变量的方法和区别):
vim ~/.bashrc
打开vim编辑器后,需要输入英文字母i,才会进入编辑状态,才可以修改里面的内容。
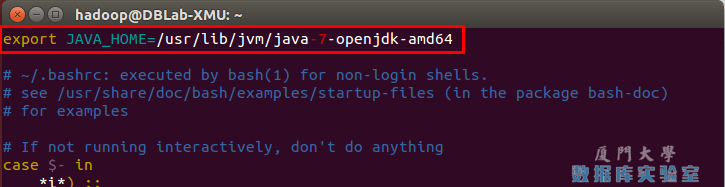
在文件最前面添加如下单独一行(注意 = 号前后不能有空格),将“JDK安装路径”改为上述命令得到的路径,并保存(在vim编辑器中完成修改后,保存文件并退出的方法是:首先按Esc键,退出编辑状态,然后键盘输入三个英文字符:wq,也就是输入冒号wq,然后,回车,就可以保存退出了。如果不想保存,则输入两个英文字符:q。如果要不保存并且强制退出,则输入三个英文字符:q!):
export JAVA_HOME=JDK安装路径
如下图所示(该文件原本可能不存在,内容为空,这不影响):
接着还需要让该环境变量生效,执行如下代码:
source ~/.bashrc # 使变量设置生效
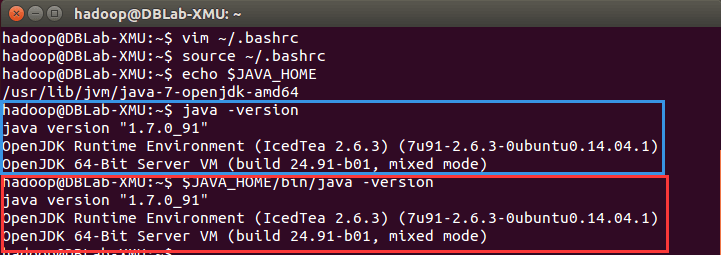
设置好后我们来检验一下是否设置正确:
echo $JAVA_HOME # 检验变量值
java -version
$JAVA_HOME/bin/java -version # 与直接执行 java -version 一样
如果设置正确的话,$JAVA_HOME/bin/java -version 会输出 java 的版本信息,且和 java -version 的输出结果一样,如下图所示:
这样,Scala所需的 Java 运行环境就安装好了。
安装Scala
访问Scala官网(官网),下载Scala。登录后,官网会自动识别你的操作系统类型,如果是Linux操作系统,官网会自动提供.tgz格式的安装包,比如,笔者于2016年10月31日登录官网,可以下载到scala-2.11.8.tgz(文件大小是27.3MB)。这里假设scala-2.11.8.tgz被下载到“~/下载/”目录下面,其中,“~”表示当前用户的工作目录,比如,如果当前你正在使用用户名hadoop登录Linux系统,那么,当前用户的工作目录就是“/home/hadoop/”。
在Linux操作系统中安装Scala的过程如下。
首先要指定Scala的安装目录,比如,这里我们选择安装在“/usr/local/”目录下,这里假设当前用户登录名是hadoop。
然后,把刚才下载的scala-2.11.8.tgz文件解压缩到“/usr/local/”目录下,修改文件夹名称,并为hadoop用户赋予权限,具体如下:
sudo tar -zxf ~/下载/scala-2.11.8.tgz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./scala-2.11.8/ ./scala # 将文件夹名改为scala
sudo chown -R hadoop ./scala # 修改文件权限,用hadoop用户拥有对scala目录的权限
接着需要把scala命令添加到path环境变量中。这里我们在 ~/.bashrc 中进行设置。可以采用vim编辑器打开.bashrc文件:
vim ~/.bashrc
打开vim编辑器以后,需要键盘敲击输入一个字母i,进入编辑状态,然后才能修改内容。
然后,在.bashrc文件的最开头位置,修改path环境变量设置,把scala命令所在的目录“/usr/local/scala/bin”增加到path中,具体如下:
export PATH=$PATH:/usr/local/scala/bin
注意,上面的PATH和等号之间,不要加入任何空格,否则会出错。
修改后,保存退出(方法是:首先,按键盘Esc键,退出vim的编辑状态,然后,敲击键盘输入“:wq”三个英文字母,然后回车,即可保存退出)。
接着还需要让该环境变量生效,执行如下代码:
source ~/.bashrc # 使变量设置生效
设置好后我们来检验一下是否设置正确,可以输入scala命令:
scala
输入scala命令以后,屏幕上显示scala和Java版本信息,并进入“scala>”提示符状态,就可以开始使用Scala解释器了,你就可以输入scala语句来调试程序代码了。
三、使用Scala解释器
按照上述步骤完成安装以后,如果是Windows系统,可以打开Windows系统的命令提示符界面(也就是运行命令行程序cmd.exe),然后,在界面中输入“scala”命令,就可以运行Scala解释器。如果是Linux系统,可以在命令提示符终端中,输入“scala”命令,就可以运行Scala解释器。
注意:由于前面的安装过程中,安装程序已经自动设置了path变量,所以,这不需要给出scala命令的路径全称,实际上,scala命令位于scala安装目录的bin目录下。
运行Scala解释器以后,就可以测试了,你可以输入一条语句,解释器会立即执行语句并返回结果,这就是我们所说的REPL(Read-Eval-Print Loop,交互式解释器),为我们提供了交互式执行环境,表达式计算完成就会输出结果,而不必等到整个程序运行完毕,因此可即时查看中间结果,并对程序进行修改,这样可以在很大程度上提升开发效率。
在命令提示符界面中输入“scala”命令后,会进入scala命令行提示符状态(即“scala>”),可以在后面输入命令:
scala> //可以在命令提示符后面输入命令
比如,下面在命令提示符后面输入一个表达式“8 * 2 + 5”,然后回车,就会立即得到结果:
scala> 8*2+5
res0: Int = 21
最后,可以使用命令“:quit”退出Scala解释器,如下所示:
scala>:quit
或者,也可以直接使用“Ctrl+D”组合键,退出Scala解释器。
到此,我们就顺利完成了Scala环境的安装,为我们后面学习Scala编程奠定了基础。
四、第一个Scala程序:Hello World
Scala融合了面向对象编程思想,所以,这里我们采用一个包含了main()方法的大家比较熟悉的JVM应用程序,这里以Hello World程序为例进行说明。
请登录Linux系统,打开命令行终端(可以使用Ctr+Alt+T组合键来打开终端)。现在请在Scala安装目录/usr/local/scala下面新建一个mycode文件夹,用于存放自己的练习代码文件(后面我们都会把练习代码文件放在/usr/local/scala/mycode这个目录下),创建目录的命令如下:
cd /usr/local/scala
mkdir mycode
使用下面命令到达mycode目录,并新建一个test.scala文件:
cd /usr/local/scala/mycode
vim test.scala
在test.scala文件中输入以下代码:
object HelloWorld {
def main(args: Array[String]){
println("Hello, World!")
}
}
关于上面代码,需要重点说明两点:
(1)在上面代码中,定义了程序的入口main()方法。可以看出,关于main()方法的定义,Java和Scala是不同的,在Java中是用静态方法(public static void main(String[] args)),而Scala中则必须使用对象方法,本例中,也就是HelloWorld对象中的main()方法。
(2)对象的命名HelloWorld可以不用和文件名称一致,这里对象名称是HelloWorld,而文件名称却是test.scala。这点和Java是不同的,按照Java的命名要求,这里的文件名称就必须起名为HelloWorld.scala,但是,在Scala中是没有这个一致性要求的。
(3)Scala是大小写敏感的,所以,不要输入错误,比如把小写开头的object输成大写开头的Object。文件名Test.scala和test.scala也是两个不同的文件。
下面我们用scalac命令编译test.scala代码文件,并用scala命令执行,如下:
scalac test.scala //编译的时候使用的是Scala文件名称
scala -classpath . HelloWorld //执行的时候使用的是HelloWorld对象名称
注意,上面命令中一定要加入"-classpath .",否则会出现“No such file or class on classpath: HelloWorld”。
上述命令执行后,会在屏幕上打印出“Hello, World!”。

