
作者:厦门大学计算机系林子雨副教授
E-mail: ziyulin@xmu.edu.cn
备注:本实验与林子雨编著《数字素养通识教程》和《人工智能通识教程》教材配套
Nano Banana 是谷歌于2024年推出的AI图像生成与编辑模型,正式名称为 Gemini 2.5 Flash Image 。其在权威的LMArena基准测试中综合评分超越众多竞品,标志着2025年AI 图像生成技术的重大突破。它基于Google DeepMind最新架构,采用原生多模态设计,统一处理文本理解、图像生成与编辑等功能,拥有32K上下文窗口,能进行复杂多轮对话和编辑,还内置丰富世界知识。其核心技术能力强大,不仅支持文本描述转图像,还具备深度语义理解能力,能理解物理规律、时间概念、逻辑推理等。例如输入 “这个披萨在 400 度烤箱里烤 2 小时”,能生成烤焦的披萨图像。Nano Banana 的智能图像编辑引擎可精准局部编辑,如面部美化、体型调整且保留细节;角色一致性保持算法能解决 AI 图像生成领域角色一致性难题,面部特征保留率达 99%。在速度方面,仅需 2.3 秒就能生成 1024×1024 的高质量图像 。
访问方法
注意:如果360浏览器无法访问该网站,建议使用谷歌Chrome浏览器,就可以正常访问了。
访问网站https://lmarena.ai/,在页面顶部点击“Battle”。
然后,点击下拉列表中的“Direct Chat”。
如下图所示,点击“图片”按钮。
如下图所示,上方的大模型要选择“gemini-2.5-flash-image-preview(nano-banama)”。
生成创意图片
如下图所示,点击“+”按钮,上传一张你的照片。
比如,这里上传如下照片(林子雨老师的高清照片):

照片上传成功以后,如下图所示,然后在对话框中输入提示词。
把照片转成角色手办,手办有底座,角色手办在底座上,在它身后放着一个印有改角色的手办盒子,盒子上的文字使用中文,盒子旁边有一个电脑,屏幕上显示blender建模过程,场景为书房办公桌场景输入提示词以后,如下图所示,点击箭头按钮提交。
这时,会弹出一个对话框,点击“Agree”(同意)就可以。
数字手办生成以后,会出现一个提示框,可以点击“Got it”(已经了解)。
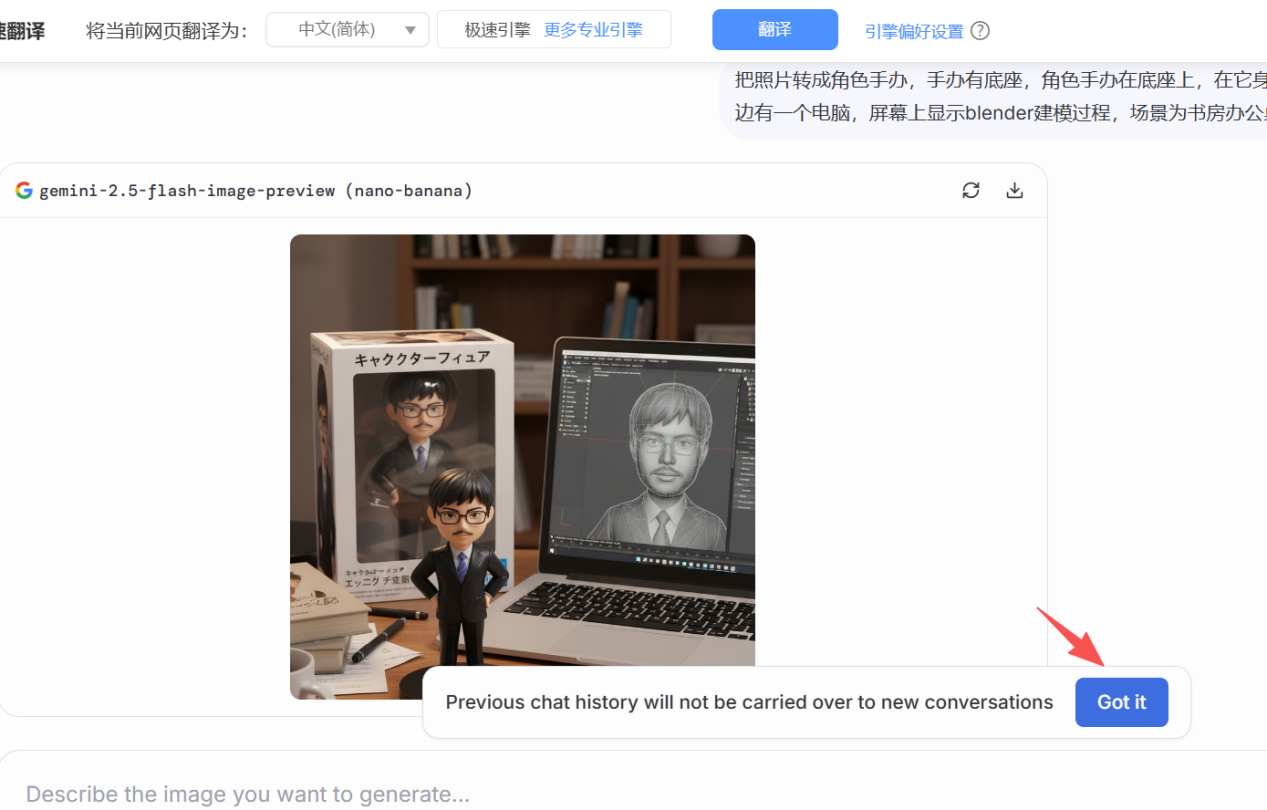
到这里,数字手办已经制作完成,可以点击右上角的下载按钮(如下图所示),把图片下载到本地。
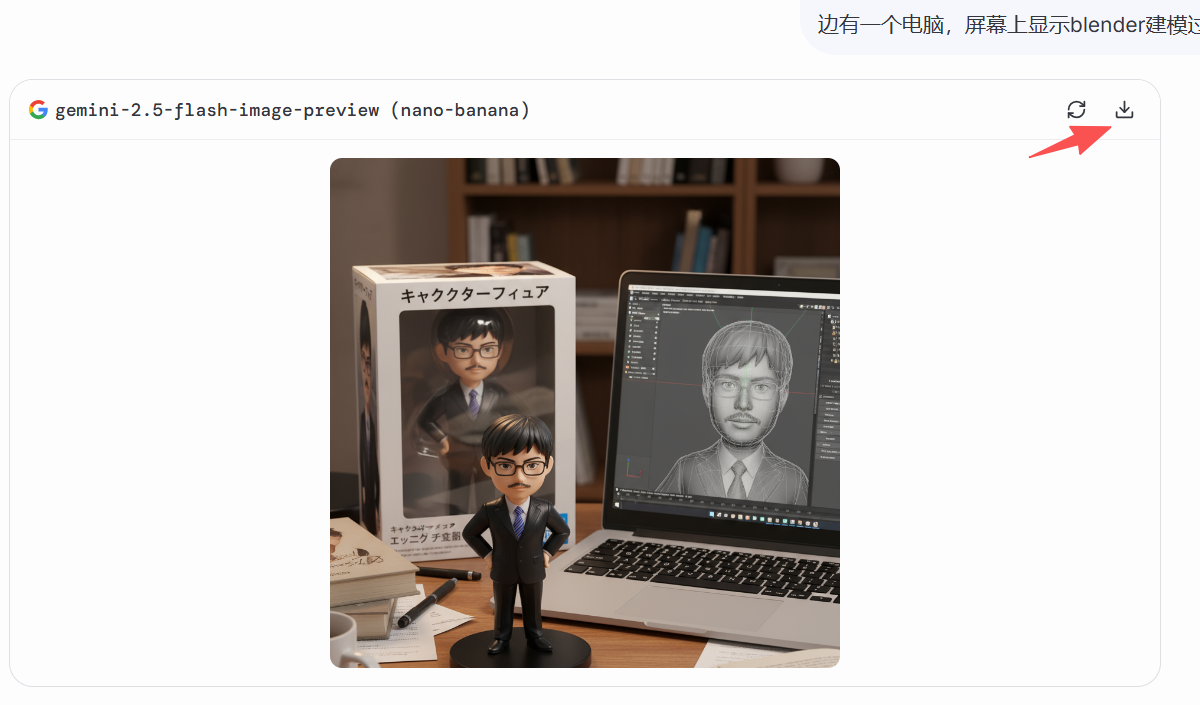
生成的数字手办下载到本地以后得图片效果如下:

还可以上传一张自己的照片(比如使用上面的林子雨老师个人高清照片),然后输入提示词“请生成一张我和美国总统特朗普的合影照片”,然后提交,15秒就可以生成合影照片了,生成的图片效果如下:

修改图片
再次点击下图中的“+”,上传一张自己的照片(比如上传林子雨老师的高清个人照片)。

然后,输入提示词“换一个更酷的姿势”。生成的新照片如下所示。

点击“+”,上传照片,在对话框中继续输入提示词“去掉这张照片中的人物的眼镜”,生成如下所示图片:

点击“+”,上传照片(这里上传林子雨照片),在对话框中继续输入提示词“让这张照片中的人物微笑”,生成如下所示图片:

点击“+”,上传照片,在对话框中继续输入提示词“把照片的背景更换成大草原”,生成如下所示图片:

下面准备一张黑白的老照片,如下所示:

点击“+”,上传这张黑白照片,在对话框中继续输入提示词“修复并上色这张照片”,生成如下所示图片:

点击“+”,上传一张骑摩托车的照片,如下所示:

在对话框中继续输入提示词“把图中的摩托车变成带着火焰的地域摩托车风格”,生成如下所示图片:

风格转换
点击“+”,上传一张女孩子的真人照片,如下所示:

在对话框中继续输入提示词“把图中的人物变成动漫人物”,生成如下所示图片:

电商出图
人物推销
点击“+”,上传一张古代人物照片和一张现代零食照片,如下所示:


在对话框中继续输入提示词“让这个古代人物介绍这包零食”,生成如下所示图片:

更换衣服
点击“+”,上传一张时装模特人物照片和一张女士长裙照片,如下所示:


在对话框中继续输入提示词“把图一人物的裙子更换成图二的裙子,保持图一的风格”,生成如下所示图片:

多个物体合成
点击“+”上传几张图片,包括女人、牛仔裙、墨镜、宠物狗、奶茶、女士包、运动鞋,图片如下:







上传后的效果如下:
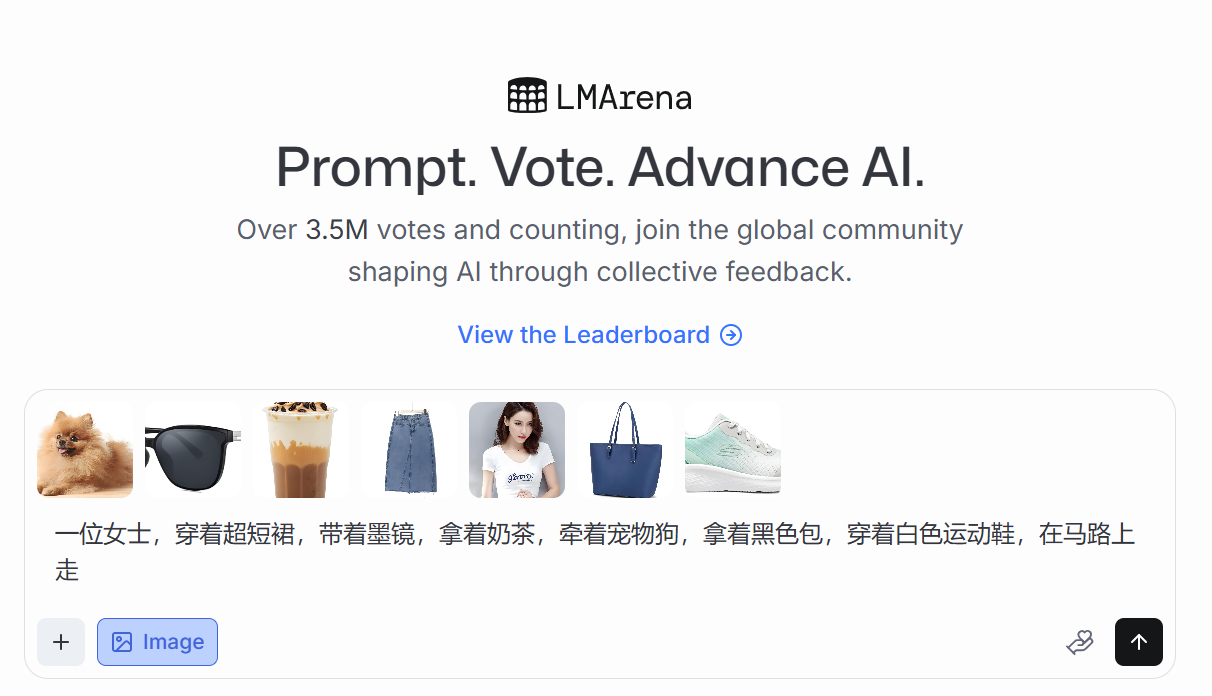
在对话框中输入提示词“一位女士,穿着超短裙,带着墨镜,拿着奶茶,牵着宠物狗,拿着黑色包,穿着白色运动鞋,在马路上走”,生成图片效果如下:

家装设计
点击“+”上传图片,是一个空房间的图片:

在对话框中输入提示词“在房间地面铺一块大面积米色地毯,给窗户装上乳白色窗帘,墙上挂一幅油画,是梵高的向日葵,在地面上放一个米色沙发和茶几,茶几上放一个绿色盆景”,生成的效果图如下:

推理能力
点击“+”上传一张没有成熟的果树的照片,如下:

在对话框中输入“生成一张该场景3个月以后的照片”,生成的图片效果如下:

点击“+”上传一张食材照片:

在对话框中输入提示词“这是一堆食材,帮我制作一道菜”,生成的效果图如下:

点击“+”上传两张照片,一个是拳击手,一个是人物打斗简笔画,如下所示:


在对话框中输入提示词“图一和他的分身,正在按照图二的动作和位置,进行激烈打斗,背景是拳击擂台”,生成的图片效果如下:

点击“+”上传两张照片,一个是女模特,一个是人物造型简笔画,如下所示:
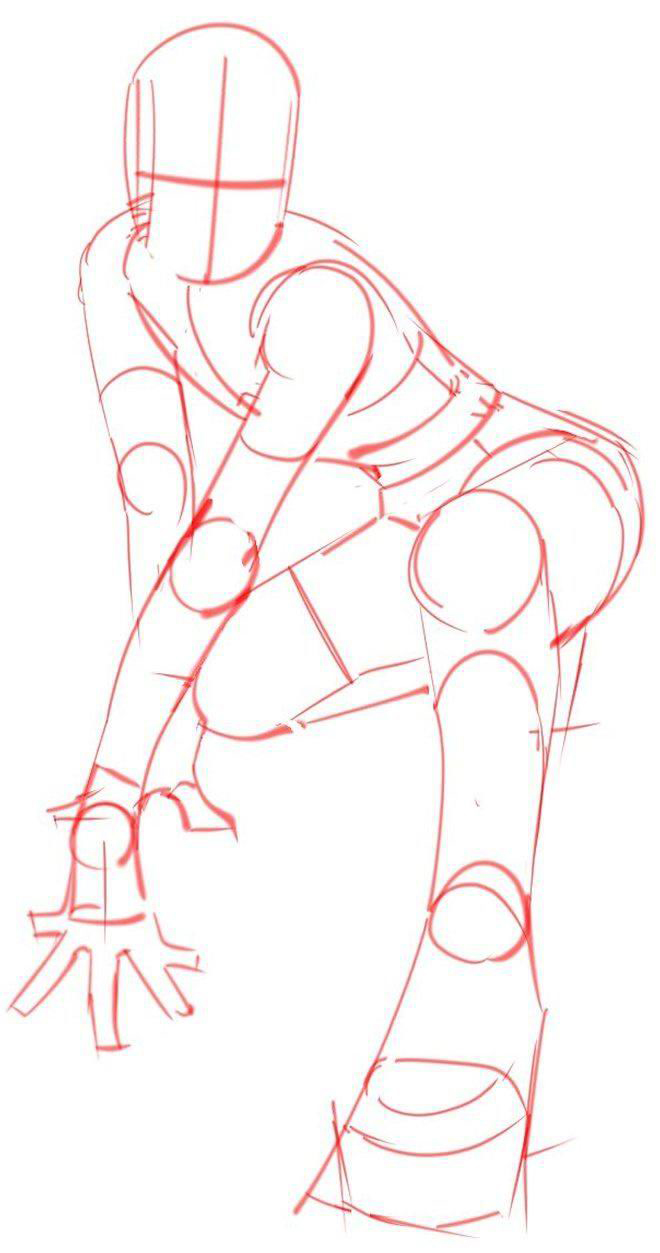
在对话框中输入提示词“按照图二的动作为图一的女孩子生成新的造型”,生成的图片效果如下:
