
【版权声明】版权所有,严禁转载,严禁用于商业用途,侵权必究。
作者:厦门大学计算机科学与技术系2024级研究生 陈增辉
指导老师:厦门大学数据库实验室 林子雨 博士/副教授
时间:2025年6月
相关教材:林子雨、郑海山、赖永炫编著《Spark编程基础(Python版,第2版)》(访问教材官网)
相关案例:基于Python语言的Spark数据处理分析案例集锦(PySpark)
数据集和代码下载:从百度网盘下载本案例数据集和代码。(提取码是ziyu)
1.作业选题
基于Spark 和大模型的B站数据处理与分析。
2.实验环境
Device: MacBook Air 13 M3 24G
Linux: Ubuntu 22.04
Hadoop: 3.3.5
Spark: 3.4.0
Python:
JDK: 1.8
编程开发工具及大模型工具: Visual Studio Code with Github Copilot and other plugins (地表最强 IDE!)、ChatGPT、大模型 API 调用工具 ChatWise
3.实现过程
3.1安装 VMWare 以及 Ubuntu 22.04
参考教程《在VMWare中安装Linux虚拟机(2023年7月版本)》,Mac OS 下使用 VMWare Fusion,官网可下载。
此处没有提供可供我的设备使用的 iso 镜像,询问 AI,具体可见4.2 Ubuntu 不提供 arm64 镜像,参考 AI 的回答,先安装 live-server,再安装桌面环境。
在 VMWare Fusion 中安装虚拟机的 live server 版本,直接点击软件左上角的 “+”号,选择“从光盘或映像中安装”即可。
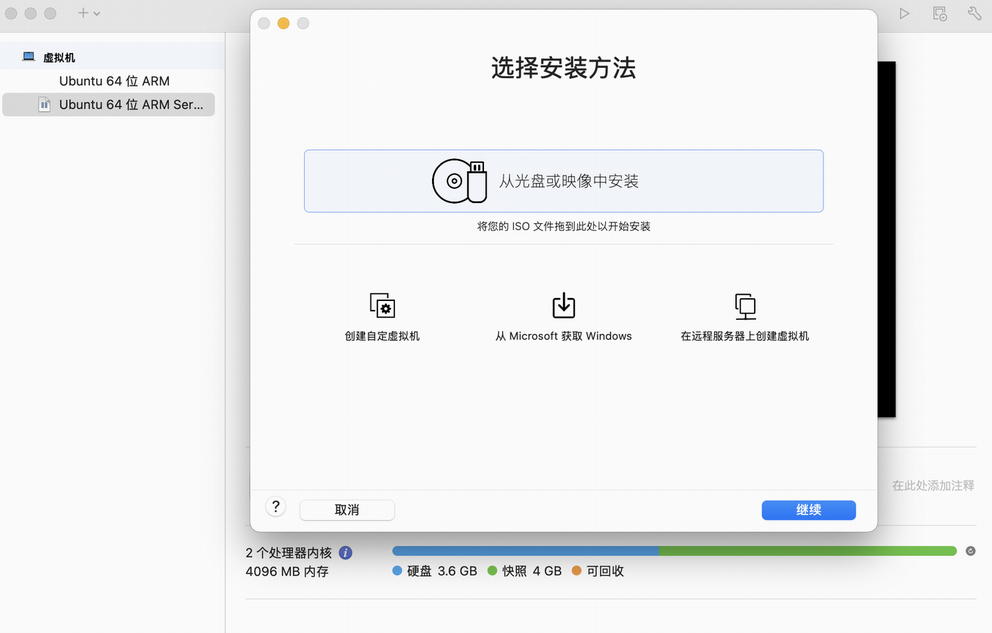
如下文中图片安装过程与网站上相似,区别是选择完镜像后会直接打开虚拟机的页面,需要点击左上角的螺丝刀来进一步配置,这边配置 4 核 16 G 运存。
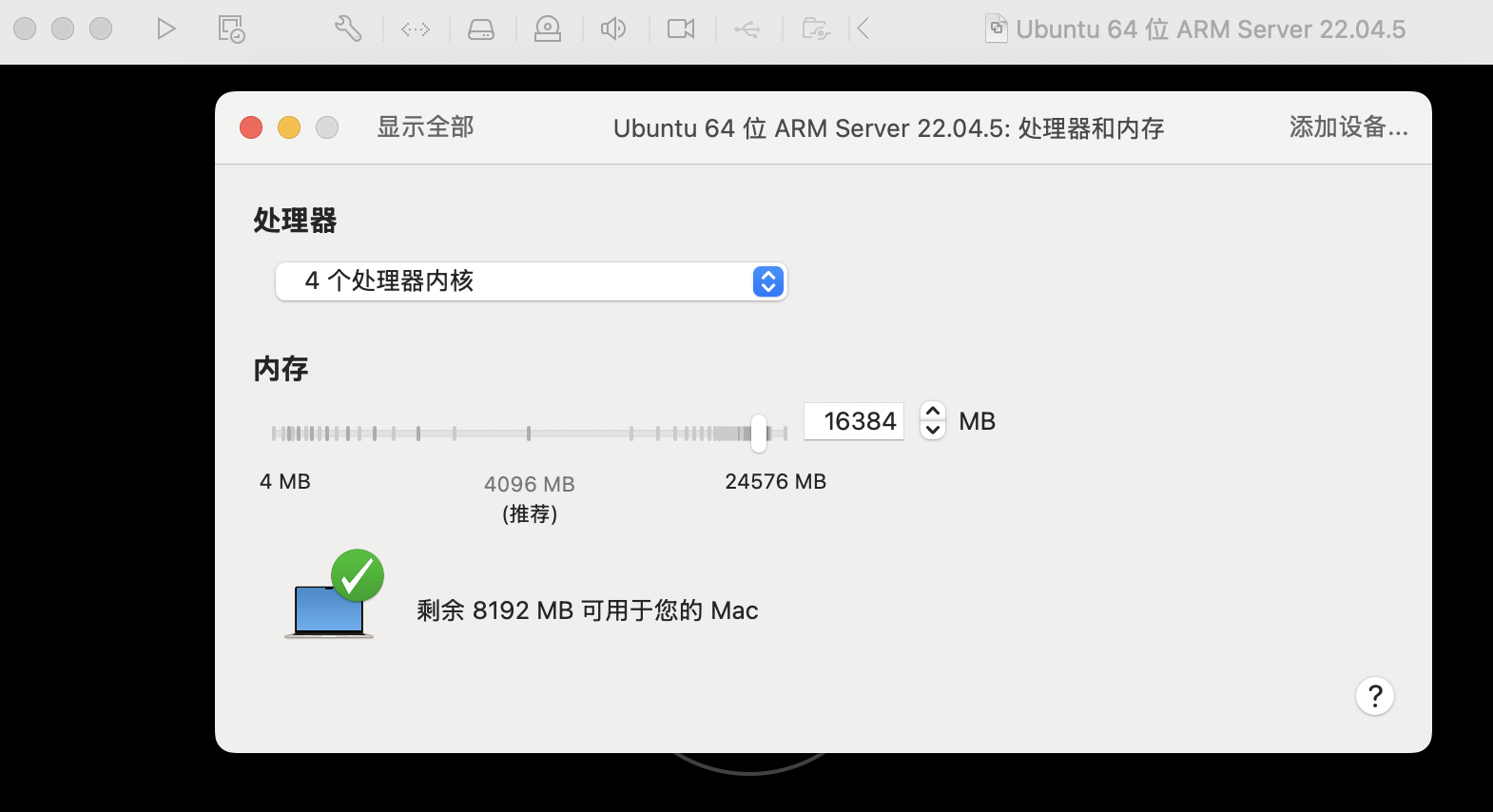
配置完后可以直接进入系统,会开始安装,与网站上不同,会需要选择配置,全部选择默认就可以,用户名密码配置与网站上相同。
而后需要重启一次,重启后使用用户名密码登录系统,输入以下命令安装桌面环境。
sudo apt update
sudo apt install ubuntu-desktop
sudo reboot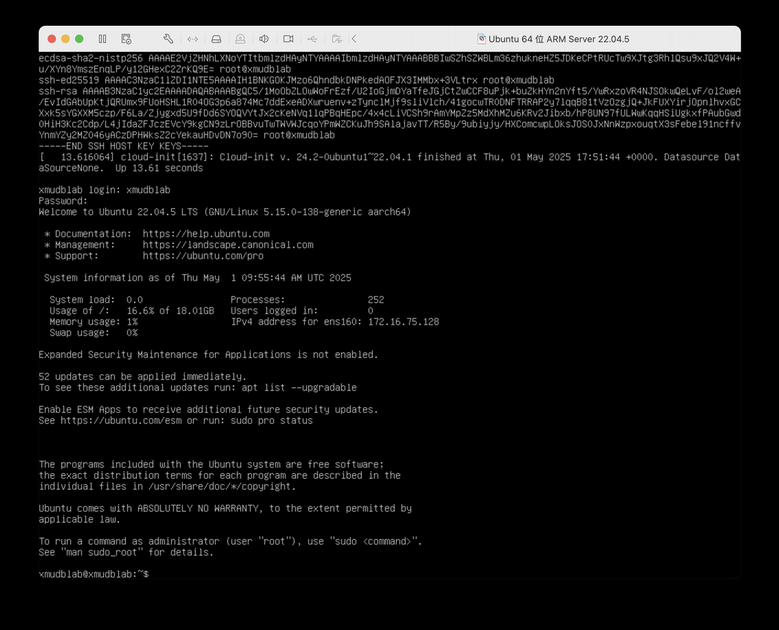
成功进入到 Ubuntu 桌面。

3.2安装 Hadoop 3.3.5
参考教程Hadoop3.3.5安装教程_单机/伪分布式配置,先创建 hadoop 用户,此处使用 VSCode ssh 连接到 Linux 进行操作,ssh 配置在教学网站可以找到,终端中使用下列命令获得 Linux 的 IP 地址信息。
sudo apt install net-tools
ifconfig可以看到 IP 地址,打开 VSCode,一般情况下初始界面如下。选择“连接到”-“连接到主机”-“添加新的 SSH 主机”,根据前面的 ip 地址,输入命令如下:
ssh xmudblab@172.16.75.128
选择默认选项,完成后会在软件右下角显示连接提醒框,点击“连接”,会要求输入密码,输入密码,等待 VSCode 服务下载完成后就连接到 Linux 了,可以按照终端的使用方法进行使用和管理文件。
在软件导航栏的终端中选择“新建终端”,打开一个新的终端,就可以开始使用了。
后续操作与教学网站相同,不再赘述。区别点在于,
1.不需要注销,仅需使用 hadoop 用户建立一个新的 ssh 连接。
2.JDK 需要安装 arm64 版本,我从 zulu-jdk 进行下载,下载完成后可以直接使用 VSCode 将文件拖动到相应目录。同时需要注意 Mac OS 下 Safari 会将 gz 文件解压为 tar。
Hadoop 也要安装 arm64 版本,到镜像站下载hadoop-3.3.5-aarch64.tar.gz。
3.3安装 Spark 3.4.0
同样参考教程Spark安装和编程实践(Spark3.4.0),过程与教程完全一致。
由于课上有提到 Spark 与 Python 版本兼容性问题,因此本步骤有使用 ChatGPT 的联网搜索功能获得相关信息,详情见4.4 Spark 与 Python 兼容性。
3.4采集数据集
3.4.1获取采集接口
注:此处选择数据集的时候有使用 ChatGPT 帮助选题,见推荐爬取的网站,虽然已经限制了让其推荐“中国青少年熟悉的”网站,但他提供的平台我都不熟悉,唯一有用过的小红书也不感兴趣。只得放弃,最后选择爬取个人的 Bilibili (简称b站,后文也使用 b 站) 默认收藏夹,只需更改相应参数即可提供给其他人日常使用。
进入收藏页,打开浏览器开发者工具,进入“网络”标签页(打开开发者工具后需要刷新一下网页,使得网站重新请求数据并被开发者工具监听)。筛选所有请求,保留“XHR/FETCH”,一般网站请求的数据都是依靠 AJAX 通过 XHR 或者 FETCH 请求进行。可以看到几个叫做 list 的 api 请求,其中一个如下所示。
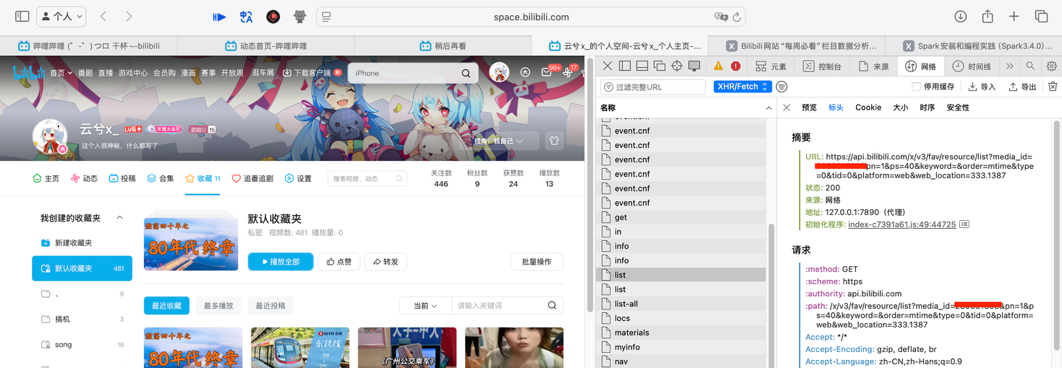
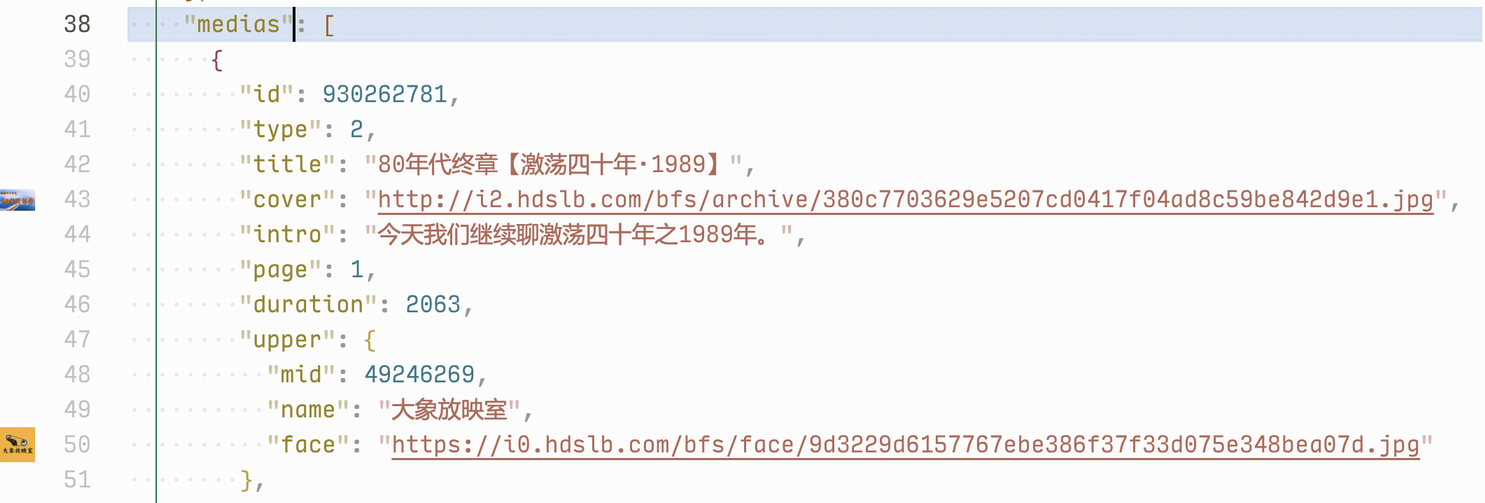
使用 VSCode 在项目文件夹下新建一个 json 文件,如此处的 assets/list.json,将 api 接口的返回结果复制到这个文件中。安装相应插件的前提下,IDE 会自动对 json 进行格式化,如下图,可以看到 data 字段下存放了一个 info 对象和一个 medias 数组,info 对象里面是这个收藏夹的信息,包括 title、cover 等;medias 里面包含不大于 40 个的视频(api 参数设置 ps 为 40)。
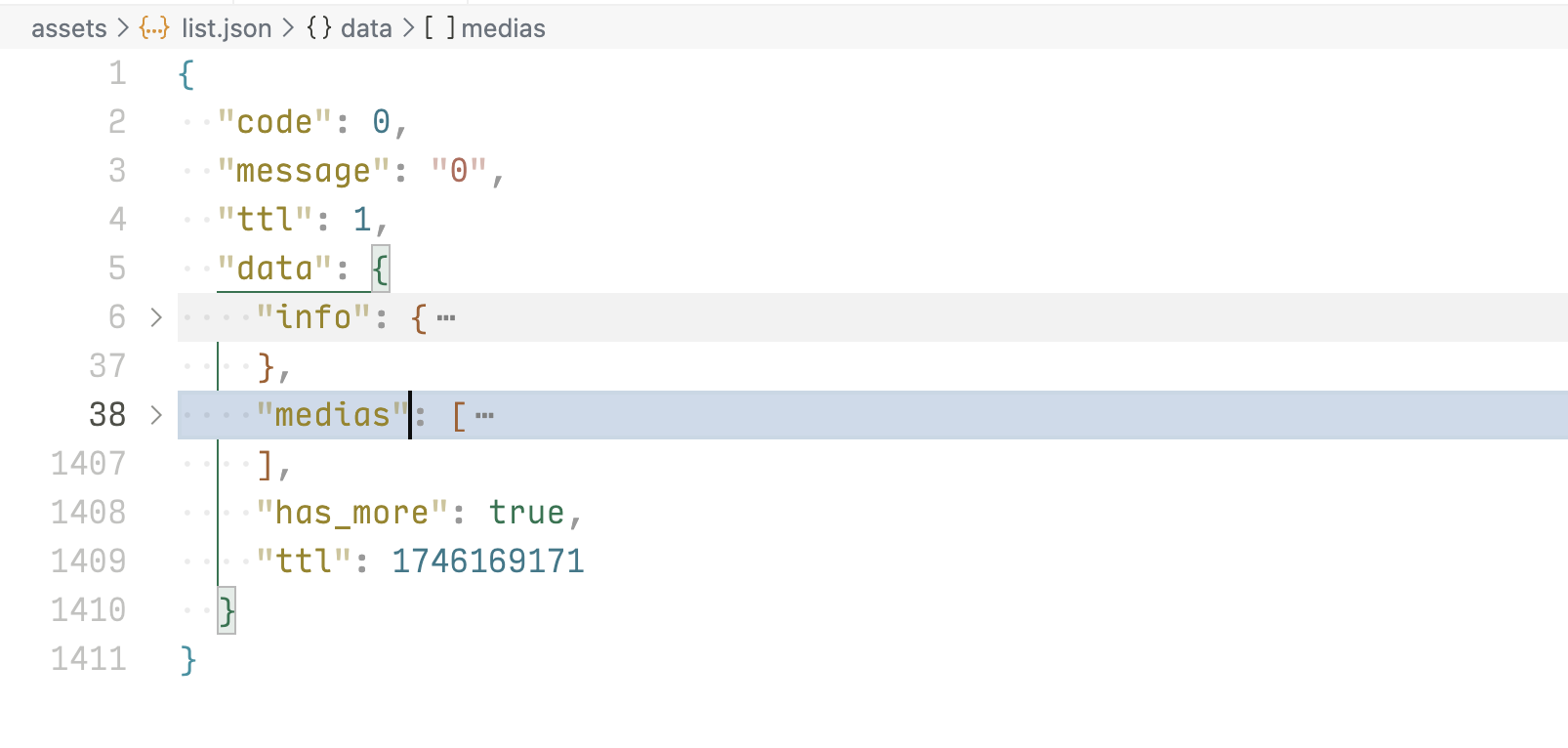
如果在 VSCode 中安装了对应插件(这边使用的是 Image preview),还能在 IDE 中实时预览 medias 数组中的封面图,对于调试接口时预览数据非常友好。
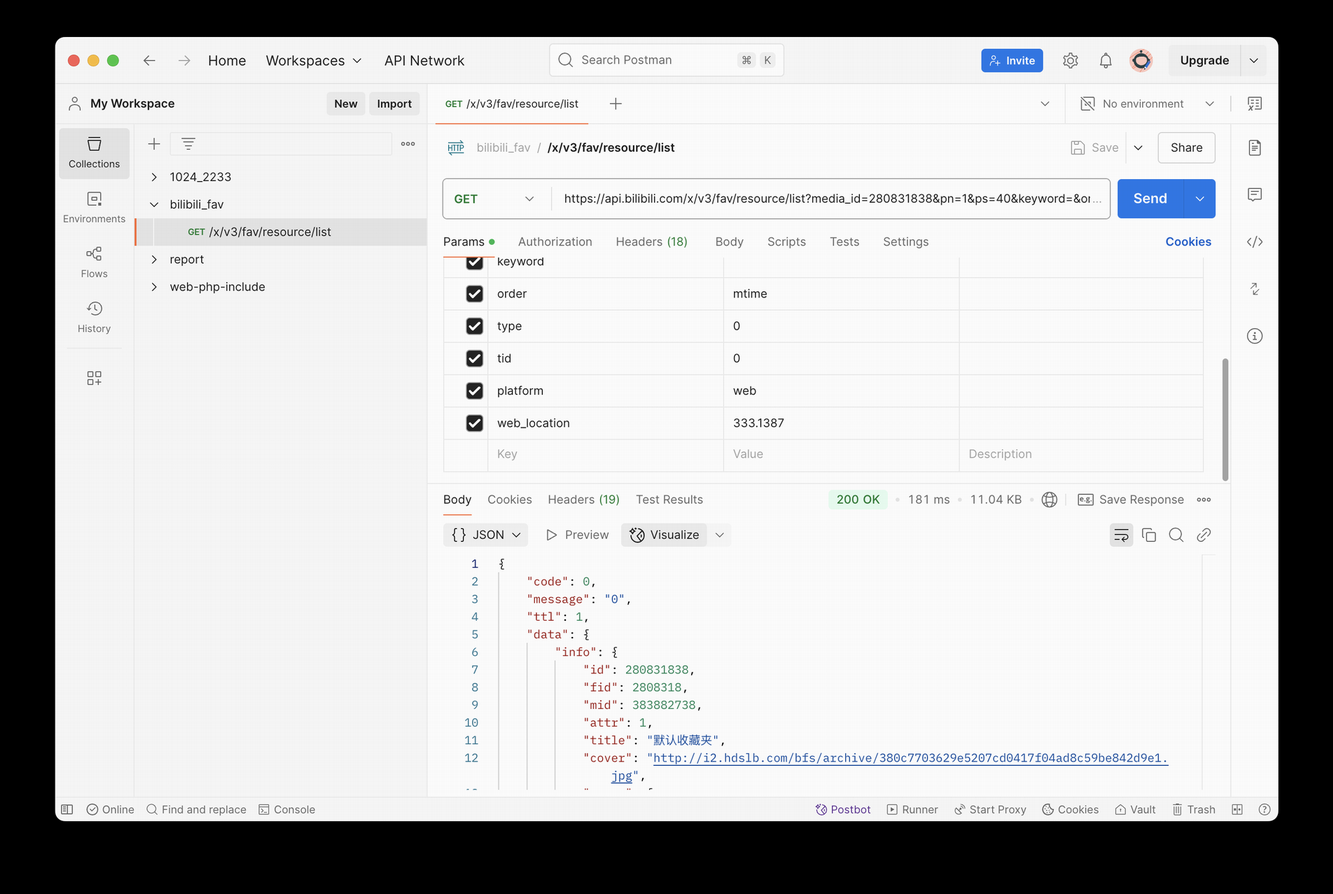
将此接口拷贝成 curl,复制到 Postman 中可以对接口进行进一步调试,这个爬虫是涉及到用户识别的,找到判断用户信息的接口就非常关键(原本可以使用 AI 分析接口,但有 Postman 这一成熟工具更加方便快捷)。也可以使用它的生成代码功能,但此处没有使用。
3.4.2 代码组织
采集的代码结构如下所示:
1.每个脚本/模块都有一个对应的 type 模块,使用 TypedDict、Union 等定义较为复杂的或者可复用的数据类型,如接口的请求、相应等。
2.utils 下为抽离出的模块,主要与请求相关。
3.crawl_bilibili_fav.py 和 crawl_bilibili_bv_info.py 为主要采集代码,分别用于采集收藏夹和视频详情。
4.data 目录存放采集结果,assets 目录存放供测试的静态文件,如接口在 Postman 中的返回,在 IDE 中方便查看。
├── __init__.py
├── assets
│ ├── list.json
│ ├── tags.json
│ └── view.json
├── crawl_bilibili_bv_info_type.py
├── crawl_bilibili_bv_info.py
├── crawl_bilibili_fav_type.py
├── crawl_bilibili_fav.py
├── data
│ ├── fav_list
│ ├── media_info_list
│ └── media_list
├── pd_bilibili_bv_info_type.py
├── pd_bilibili_bv_info.py
├── utils
│ ├── __init__.py
│ ├── __pycache__
│ ├── request_bv_type.py
│ └── request_bv.py
└── 实验报告.docx3.4.3 编写收藏夹采集代码
进入写代码环节后,对于 AI 的使用可以说是无处不在了,可见Copliot 代码补全进行爬虫代码编写。本次需要爬取的数据中,使用收藏夹列表的 api 接口返回的数据没有全面显示视频的基本信息,需要依次爬取每个视频的基本信息。而b站在进入每个视频的播放页时,直接返回带有相关信息的 html 文本,没有调用相关接口获取视频信息。此刻使用 ChatGPT 的联网搜索功能,见ChatGPT 联网搜索 b 站 api 接口文档,推荐到网页整理的 Github 开源仓库哔哩哔哩-API收集整理【不断更新中....】查阅。
请求收藏夹列表:
@retry()
def get_fav_json(url: str, params: FavRequestParams, cookie: str):
"""
Get the favorite list from the given URL.
"""
random_UA = UserAgent().random
headers = {
"User-Agent": random_UA,
"Cookie": cookie,
}
response = requests.get(url, params=params, headers=headers)
response.raise_for_status()
return response.json()接口有要求三个字段,ps 表示 pageSize,每次获取的数据量;pn 表示 page Number,当前页数,从1开始计算;media_id 为收藏夹的 id,在浏览器中寻找接口时已经获得。此外,还需要让请求携带 Cookie,也是在寻找接口时获得,需要换成自己的 Cookie。代码如下,每次爬取结果存放到一个文件中,而后抽取其中的 medias 数组,组合成新的 json 文件:
def main():
"""
Main function to get the favorite list.
"""
url = "https://api.bilibili.com/x/v3/fav/resource/list"
basic_params = {
"pn": 1,
"ps": 40,
"order": "mtime",
"keyword": "",
"type": 0,
"tid": 0,
"platform": "web",
"web_location": web_location
}
pn = 1
medias = []
while True:
params = FavRequestParams(**basic_params)
params["media_id"] = media_id
params["pn"] = pn
fav_json = get_fav_json(url, params, cookie)
fav_response = FavResponse(**fav_json)
beautified_json = json.dumps(fav_response, indent=2, ensure_ascii=False)
# Save the response to a file
fav_list_dir = f"{data_base_dir}/fav_list"
if not os.path.exists(fav_list_dir):
os.makedirs(fav_list_dir)
fav_list_file = f"{fav_list_dir}/{media_id}-{params['pn']}.json"
with open(fav_list_file, 'w', encoding='utf-8') as f:
f.write(beautified_json)
print(f"Favorite list {pn} saved to: {fav_list_file}")
# Extend the media list
medias.extend(fav_response["data"]["medias"])
print(f"Fetched page: {pn}, total medias: {len(fav_response['data']['medias'])}")
if not fav_response["data"]["has_more"]:
break
pn += 1
print(f"Total medias fetched: {len(medias)}")
# Save the media list to a file
media_list_dir = f"{data_base_dir}/media_list"
if not os.path.exists(media_list_dir):
os.makedirs(media_list_dir)
media_list_file = f"{media_list_dir}/{media_id}.json"
with open(media_list_file, 'w', encoding='utf-8') as f:
f.write(json.dumps(medias, indent=2, ensure_ascii=False))
print(f"Media list saved to: {media_list_file}")3.4.4加量采集收藏夹中每个视频的信息
取出采集到的所有视频,根据 dvid 字段,调用 https://api.bilibili.com/x/tag/archive/tags 和 https://api.bilibili.com/x/web-interface/view 两个接口分别采集视频的标签和基本信息,接口文档见视频基本信息和视频标签,均来自上文中 Github 仓库。代码为对对象(Python 中为 Dict)进行简单的处理,此处不展示,可参见源码。
爬虫中对于函数的返回都进行定义,如下图对于收藏夹采集流程的定义,放置在对应的 type 模块内,虽然这不是 Python 推荐的写法,出于个人使用 TypeScript 的习惯。
3.5数据预处理
3.5.1筛选有用字段
经过筛选,对本次作业有用的数据如下:
class PdBvInfo(TypedDict):
"""
Information about the Bilibili video.
"""
bvid: Optional[str] # 视频的 bvid
title: Optional[str] # 视频标题
intro: Optional[str] # 视频简介
duration: Optional[int] # 音频/视频时长
upper_mid: Optional[int] # UP 主的 mid
upper_name: Optional[str] # UP 主的名称
view: Optional[int] # 播放数
danmaku: Optional[int] # 弹幕数
reply: Optional[int] # 评论数
favorite: Optional[int] # 收藏数
coin: Optional[int] # 硬币数
share: Optional[int] # 分享数
his_rank: Optional[int] # 历史最高排名
like: Optional[int] # 点赞数
dislike: Optional[int] # 点踩数
evaluation: Optional[str] # 视频评分
ctime: Optional[int] # 投稿时间
pubtime: Optional[int] # 发布时间
fav_time: Optional[int] # 收藏时间
tname: Optional[str] # 分区名称
dynamic: Optional[str] # 视频同步发布的的动态的文字内容
is_upower_exclusive: Optional[bool] # 是否为充电专属视频
tags: list[str] # 视频标签编写代码将爬取下来的复杂数据转换为以上类型,筛选有用字段并进行初步处理。
def map_media_info_to_pd_bv_info(media_info: MediaInfo) -> PdBvInfo:
"""
Optimized mapping from MediaInfo to PdBvInfo.
"""
base_fields = [
'bvid', 'title', 'intro', 'duration', 'ctime', 'pubtime', 'fav_time'
]
data = {key: media_info.get(key) for key in base_fields}
upper = media_info.get('upper', {})
data.update({
'upper_mid': upper.get('mid'),
'upper_name': upper.get('name')
})
view = media_info.get('view', {})
stat = view.get('stat', {})
cnt_info = media_info.get('cnt_info', {})
data['danmaku'] = cnt_info.get('danmaku') or stat.get('danmaku')
stat_fields = [
'view', 'reply', 'favorite', 'coin', 'share',
'his_rank', 'like', 'dislike', 'evaluation'
]
data.update({key: stat.get(key) for key in stat_fields})
data.update({
'dynamic': view.get('dynamic'),
'is_upower_exclusive': view.get('is_upower_exclusive'),
'tname': view.get('tname_v2') or view.get('tname')
})
tags = media_info.get('tags', [])
data['tags'] = [tag.get('tag_name') for tag in tags]
return PdBvInfo(data)3.5.2使用 pandas,去除空字段,去除重复值
# Map the MediaInfo to PdBvInfo
pd_bv_info_list = [map_media_info_to_pd_bv_info(media) for media in media_list]
pd_bv_info_df = pd.DataFrame(pd_bv_info_list)
print(f"PdBvInfo DataFrame created with {len(pd_bv_info_df)} rows")
# 删除掉具有空值的行
pd_bv_info_df.dropna(how='any', axis=0, inplace=True)
print(f"PdBvInfo DataFrame after dropping rows with NaN values: {len(pd_bv_info_df)} rows")
# 删除重复数据,dvid 相同视为重复
pd_bv_info_df = pd_bv_info_df.drop_duplicates(subset=['bvid'], keep='first')
print(f"PdBvInfo DataFrame after dropping duplicate rows: {len(pd_bv_info_df)} rows")实际运行时,没有字段在上文因为没有获取到而被设为 None。某些视频因为版权或者其他原因,变为无效的视频,这部分视频在前面的信息采集中无法获取视频的相关信息,故这部分相关字段为 None,使用 pandas 的这两个功能可以去除这部分视频。

3.5.3 保存到文本文件,并上传到 HDFS
保存到文件代码,保存一份带有表头的 csv 供查看,同时一份不带表头的 txt 用于实际使用。
pd_bv_info_df.to_csv(output_file, header=True, index=False, encoding='utf-8') # 不输出表头,不输出序号
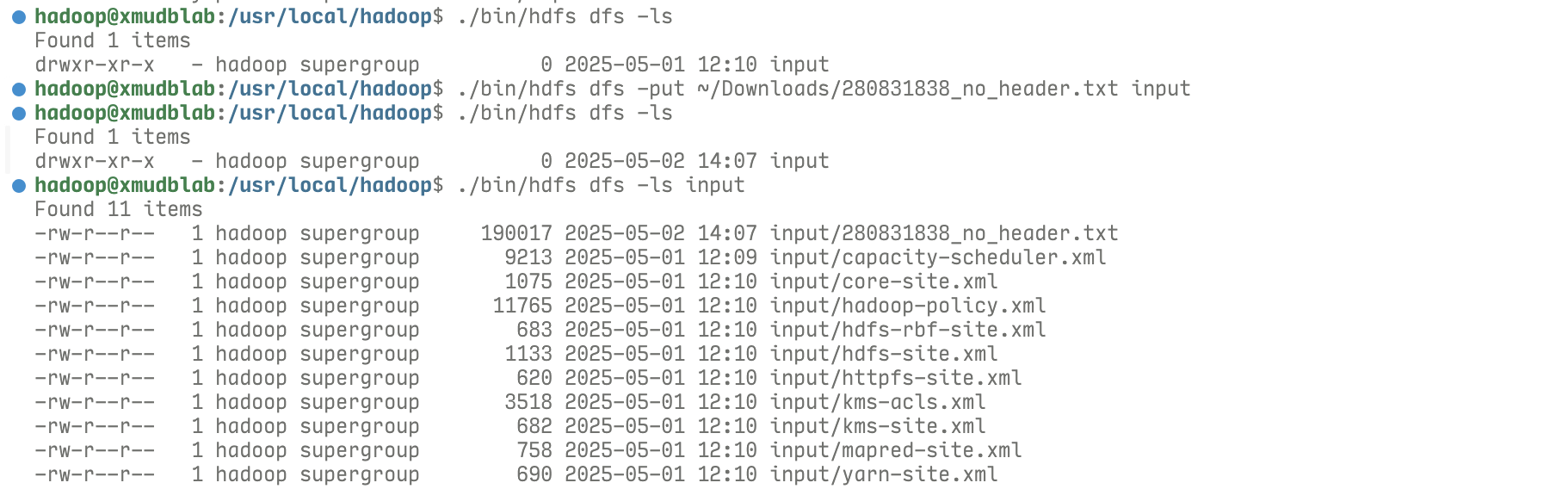
pd_bv_info_df.to_csv(output_file_without_header, header=False, index=False, encoding='utf-8')启动 Hadoop:

上传文件到 Linux 中的 Downloads 文件夹,而后复制到 HDFS,此处复制文件 280831838_no_header.txt.
3.5.4 增加对于主分区信息的处理
在进行数据分析的时候,发现 b 站只提供了视频的子分区信息 tid,b 站的分区有番剧、动画、游戏等10个左右常见主分区,每个主分区下细分为多个子分区。如果只凭借子分区信息,在数据量较小的收藏夹是没有办法统计出有价值的信息的,因此需要获得每个视频的主分区信息。
在项目中,分区信息是通过 markdown 文本的方式实现的,此处使用了 AI 提取文档中信息生成一个统一数据结构的 json 文件,具体可见提取 markdown 文档中分区信息,整理成统一数据结构。使用的数据结构如下,其中以 tid 作为键方便进行对应,每个键的值设为一个对象,存储分区的详细信息:
class TidInfo(TypedDict):
"""
Information about the Bilibili video.
"""
tid: Optional[int] # 视频的 tid
tname: Optional[str] # 视频的分区名称
ptname: Optional[str] # 视频的大分区名称
nickname: Optional[str] # 视频的分区代号
url: Optional[str] # 视频的分区链接
desc: Optional[str] # 视频的分区简介而后,重新运行 pandas 处理数据的代码,增加ptname字段。
3.6 数据分析
3.6.1 重新使用json存储视频数据
使用 Spark 前,由于不了解,认为 Spark 不支持 json 的读写,对于 tags 字段使用逗号分隔的方式,不方便进行数据分析。而 Spark 支持将字段存储为数组,故此处将文件重新导出为 json,并上传到 HDFS。
pd_bv_info_df.to_json(output_file_json, orient='records', indent=2, force_ascii=False)3.6.2 Spark 的初始化以及前期准备
代码:spark_analyse.py。首先需要读取 json 文件,并构建 DataFrame,DataFrame 是后续查询的基础。
def init(file_path):
"""
Initialize the Spark session and load the data from the given file path.
"""
# Create a Spark session
spark: SparkSession = SparkSession.builder \
.appName("Data Analysis") \
.getOrCreate()
# Load the data
df: DataFrame = spark.read.json(file_path)
df.cache() # Cache the DataFrame for performance
df.count() # Trigger the loading of the DataFrame
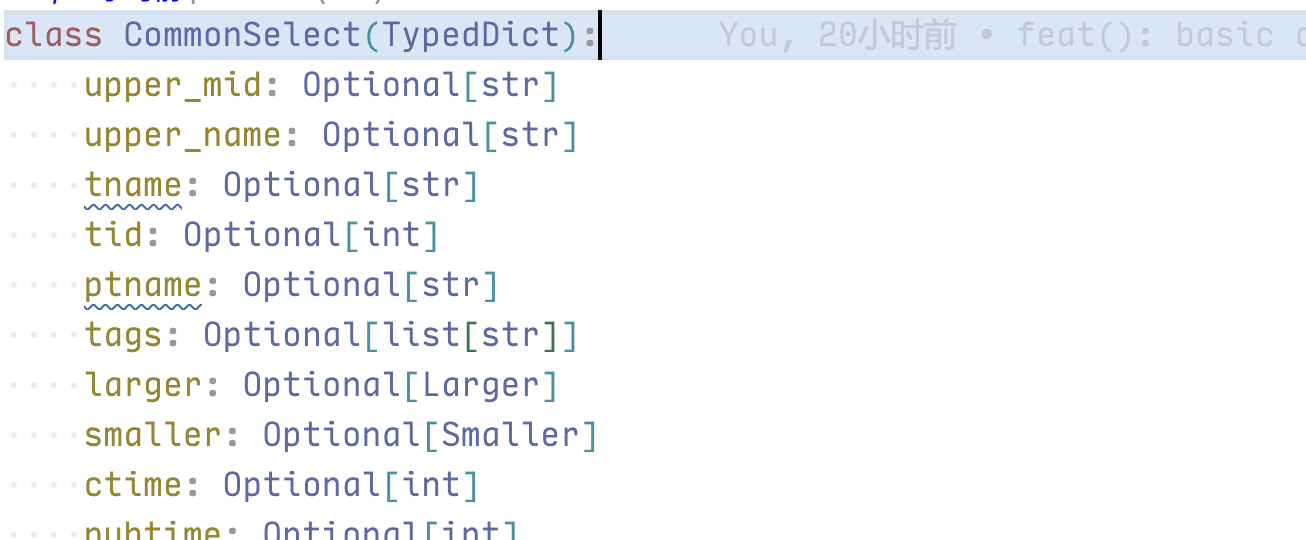
return spark, df为了方便代码编写,我定义了一个 CommonSelect 数据结构,里面包含所有的字段以及 larger、smaller 两个包含所有数字字段的字典,用于查询时 IDE 进行提示,CommonSelect 的一部分如下图。
而后,使用一个 SelectParams 对象,根据这一类型,通过 init、equal、larger、small 方法生成符合这一数据结构的查询参数,SelectParams 类的定义如下。

在调用时,先新建一个对象,而后调用对象的 3 个参数来构建简单的查询,最后通过 get 获取构建完成的查询参数,例如:
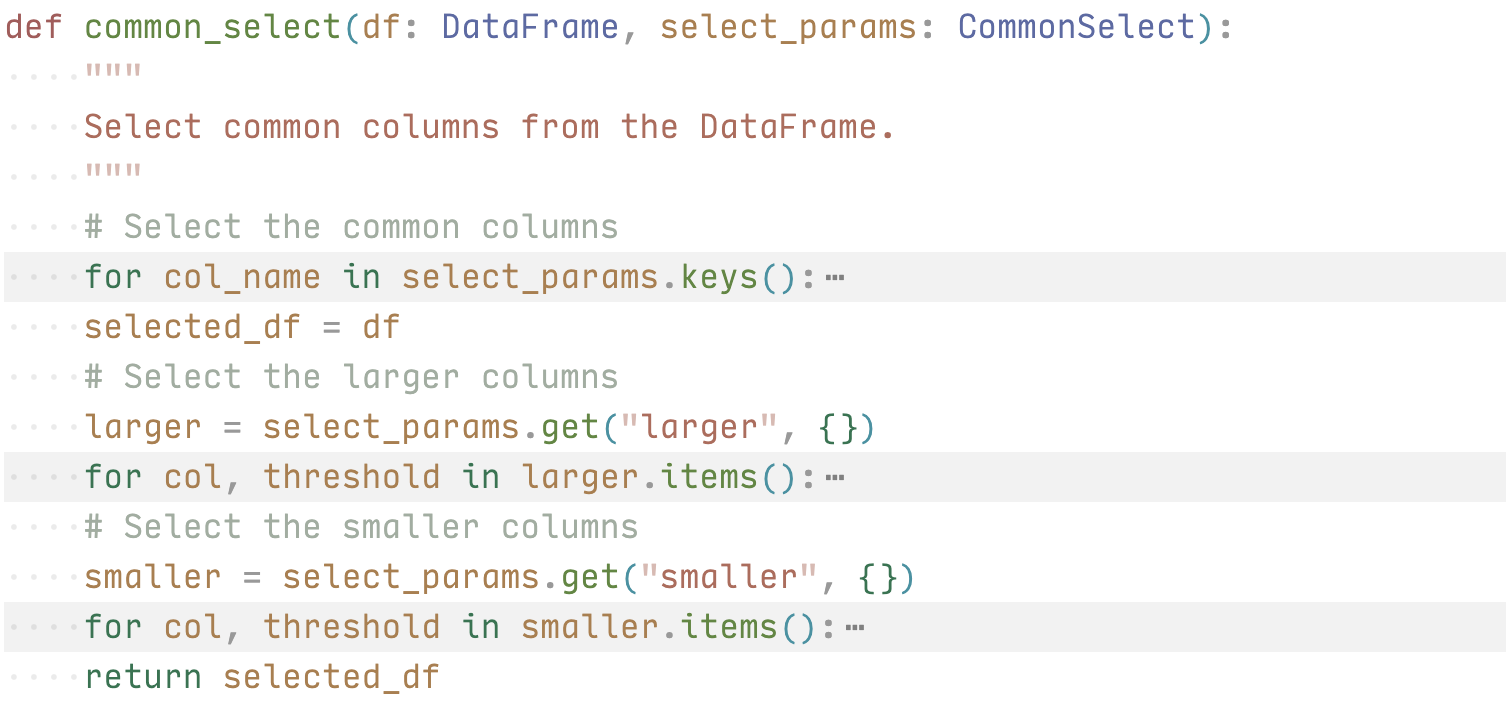
SelectParms().equal("ptname", ptname_val).get()这样写的好处是在输入 eaual 时 IDE 会有字段提示,在你输入双引号后,IDE 的语法补全就会列出所有定义好的字段。不过实现较为简单,只支持了简单的查询功能。而后通过将定义好的数据结构传入 common_select 函数,这个函数会根据传入的 params,构建对应的查询,返回查询结果。
最后完整的查询可以这样编写:
common_select(df, SelectParms().equal("ptname", ptname_val).get())一个统一的保存函数,将查询到的内容保存为 3 种格式的文件。
def save(df: DataFrame, file_base: str, file_name: str):
"""
Save the DataFrame to the given file path in 3 formats.
"""
df.write.json(f"{file_base}/{file_name}.json", mode="overwrite")
df.write.parquet(f"{file_base}/{file_name}.parquet", mode="overwrite")
df.write.csv(f"{file_base}/{file_name}.csv", mode="overwrite")一个基于 Python Logger 库的二次封装,可以方便地输出日志到文件,这是在其他项目中与队友合作完成的,此处直接复用了。
3.6.3通过查询获取所需要的数据
1.查询出现最多次的视频标签
视频标签能方便使用 b 站时检索视频,同时也能比标题更准确地用文字反映视频内容,但每个视频的标签具有多个,无法通过简单的查询统计。此处通过 explode 将 tags 数据拆分,再根据文字(此处不使用标签的 id,因为只需要文字相同就认为标签相同)分组,统计每组的数量。
def top_tags(df: DataFrame):
"""
Get the top 10 tags from the DataFrame. And storage the result in HDFS with json.
"""
logger.debug(f"Processing top tags DataFrame...")
# Explode the tags column to get individual tags
exploded_df = df.select(F.explode("tags").alias("tag"))
# Count the occurrences of each tag
tag_counts = exploded_df.groupBy("tag").count()
# Get the top 10 tags
top_tags = tag_counts.orderBy(F.desc("count")).limit(30)
# Show the top 10 tags
top_tags.show()
return top_tags2.查询每年关注的视频中出现最多次的标签
每一年兴趣爱好很可能会有所改变,统计每一个最关注的标签,可以了解那一年关注的话题变化。此处先生成一个包含每年第一天时间戳的字典:
year_dict = {}
for year in range(2017, datetime.datetime.now().year + 2):
year_dict[year] = get_time_timestamp(f"{year}-01-01 00:00:00")然后遍历这个字典,通过前文Spark 的初始化以及前期准备的 common_select 系列工具筛选出每一年的对应数据,获得每一年标签出现次数的信息。
for year, timestamp in year_dict.items():
if year == 2026:
break
logger.info(f"Processing year {year} top tags and bilibili ups...")
select_params = SelectParms().larger("fav_time", timestamp).smaller("fav_time", year_dict[year + 1]).get()
selected_df = common_select(df, select_params)
year_top_tags_df = top_tags(selected_df)
save(year_top_tags_df, output_media_base_dir, f"year_top_tags_{year}")
year_up_df = all_bilibili_up(selected_df)
save(year_up_df, output_media_base_dir, f"year_all_bilibili_up_{year}")3.通过此方法,还统计了每年收藏数最多的 up 主
4.获取分区相关信息
获取收藏数最多的分区的方法如上,在做这个板块时,发现对于“生活”、“游戏”、“科技”、“知识”这四个主分区较为关注,于是针对这四个主分区,又分析了它的子分区信息。
categories = {
"生活": "all_tname_in_ptname_life",
"游戏": "all_tname_in_ptname_game",
"科技": "all_tname_in_ptname_tech",
"知识": "all_tname_in_ptname_knowledge"
}
for ptname_val, file_suffix in categories.items():
logger.info(f"Processing tname for ptname: {ptname_val}...")
tname_df = all_tname(common_select(df, SelectParms().equal("ptname", ptname_val).get()))
save(tname_df, output_media_base_dir, file_suffix)5.排行榜信息
根据收藏夹中视频的数据信息,可以知道自己收藏了哪些传播度较广的视频,这里通过一个 top_30 函数,统计了收藏夹中视频的历史最高排名、收藏、投币、分享、点赞、点踩、观看、弹幕、评论信息,top_30 函数如下:
def top_30(df: DataFrame, col_name: str, esc: bool = False):
"""
Get the top 30 views from the DataFrame.
"""
logger.debug(f"Dealing top 30 col_name: {col_name}, esc: {esc}")
# Select the relevant columns
views_df = df.select("title", col_name, "upper_mid", "upper_name")
# Sort the DataFrame by the specified column
views_df = views_df.sort(F.desc(col_name) if not esc else F.asc(col_name))
# Show the top 30 views
views_df.show(30)
return views_df调用时,由于 b 站会将没有进入热门的视频的 his_rank 设为 0,因此此处需要先筛选出有效数据,干脆直接所有数据加一个筛选。代码中先列出一个参数矩阵,而后根据参数矩阵,获得字段名、筛选条件、是否升序排列、保存的文件名信息。
# Get the top 30 views
metrics = [
# (column name, lower threshold, sort_ascending, output filename)
("his_rank", 1, True, "top_30_his_rank"),
("favorite", 0, False, "top_30_favorate"),
("coin", 0, False, "top_30_coin"),
("share", 0, False, "top_30_share"),
("like", 0, False, "top_30_like"),
("dislike", 0, False, "top_30_dislike"),
("view", 0, False, "top_30_view"),
("danmaku", 0, False, "top_30_danmaku"),
("reply", 0, False, "top_30_reply")
]
for col, threshold, asc_order, file_suffix in metrics:
logger.info(f"Processing top 30 {col} DataFrame...")
filtered_df = common_select(df, SelectParms().larger(col, threshold).get())
result_df = top_30(filtered_df, col, esc=asc_order)
save(result_df, output_media_base_dir, file_suffix)3.6.4使用 Spark MLib 实现收藏夹推荐功能
在尝试探索获得收藏夹数据的价值时,想到通过分析数据,在准备收藏一个新视频时,根据收藏夹的内容预测会被放入哪个收藏夹,进行推荐。刚好我的账号中有两个收藏夹(默认收藏夹、学习)。实现此功能需要按照之前的流程重新爬取第二个收藏夹的数据,数据已经完成爬取并放在数据集目录下。而后,需要使用 pandas 合并两份数据,并将它们按照收藏夹打上标签,代码见 pd_label_data.py。打上标签后数据放入 HDFS,使用 Spark 读取。
机器学习的代码位于 spark_ml.py,选取字段("title", "view", "like", "reply", "favorite", "coin", "share", "dislike", "danmaku", "duration", "upper_mid", "tid", "ctime", "pubtime")进行训练,其中 title 是文本数据,需要对标题进行分词处理,再使用 TF-IDF 提取文本特征。
tokenizer = Tokenizer(inputCol="title", outputCol="words")
remover = StopWordsRemover(inputCol="words", outputCol="filtered_words")
hashingTF = HashingTF(inputCol="filtered_words", outputCol="raw_features", numFeatures=10000)
idf = IDF(inputCol="raw_features", outputCol="text_features")转化为特征向量并划分数据集进行训练。
# 数值特征组合
assembler = VectorAssembler(
inputCols=[
"text_features",
# "intro_features",
"view", "like", "reply",
"favorite", "coin",
"share", "dislike", "danmaku", "duration", "upper_mid", "tid", "ctime", "pubtime"
],
outputCol="features",
handleInvalid="skip" # 添加此行,跳过包含 null 的行
)
# 分类模型
lr = LogisticRegression(featuresCol="features", labelCol="label")
# 构建 Pipeline
pipeline = Pipeline(stages=[
tokenizer, remover, hashingTF, idf,
# tokenizer_intro, remover_intro, hashingTF_intro, idf_intro,
assembler, lr])
# 划分数据集
train_data, test_data = data.randomSplit([0.8, 0.2], seed=42)
# 训练模型
model = pipeline.fit(train_data)保存模型供后续使用。
model.write().overwrite().save("data/saved_model")3.7数据可视化
3.7.1新建 web 前端项目
使用开源的模版进行开发,在数据处理项目下克隆并新建项目。
npx degit antfu-collective/vitesse-lite echart-page进入项目并安装依赖,此项目需要使用到 pnpm 进行开发,需要先安装 npm,然后通过 npm 全局安装 pnpm。
# Ubuntu 安装 node js 环境
# Download and install nvm:
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.3/install.sh | bash
# in lieu of restarting the shell
\. "$HOME/.nvm/nvm.sh"
# Download and install Node.js:
nvm install 22
# Verify the Node.js version:
node -v # Should print "v22.15.0".
nvm current # Should print "v22.15.0".
# Download and install pnpm:
corepack enable pnpm
# Verify pnpm version:
pnpm -v
# 初始化项目
cd echart-page
pnpm i3.7.2读取数据
为了方便读取数据,因为数据量较小,在 Spark 处理的过程中将保存的分区数设置为1,并将文件进行重命名处理。实际使用中可将分区数不限制,然后拼接文件。
def save(df: DataFrame, file_base: str, file_name: str):
"""
Save the DataFrame to the given file path in 3 formats.
"""
df.coalesce(1).write.csv(f"{file_base}/{file_name}.csvfolder", mode="overwrite", header=True)
for filename in os.listdir(f"{file_base}/{file_name}.csvfolder"):
if filename.startswith("part-") and filename.endswith(".csv"):
final_filename = f"{file_name}.csv"
shutil.move(os.path.join(f"{file_base}/{file_name}.csvfolder", filename), os.path.join(file_base, final_filename))
break3.7.3简易页面编写
在完成上述处理后,将结果移动到前端项目的 public 目录下,方便读取。由于前端使用的技术栈较为复杂,此处不具体描写实现过程,项目已经完成配置,仅需按照上文安装好 nodejs、pnpm,运行 pnpm i 安装依赖,而后运行下述命令即可启动项目,点击对应链接打开页面。
npm run dev --host
数据图表模块设置了三个选择器(数据、图表类型、排序),可以动态展示分析完成的数据。在数据选择器中已经设置了所有待展示数据,可自由切换。

不同数据展示时使用不同的图表会有不同的效果,提供了切换按钮在柱状图和饼图之间切换。

3.7.4 图表模块展示
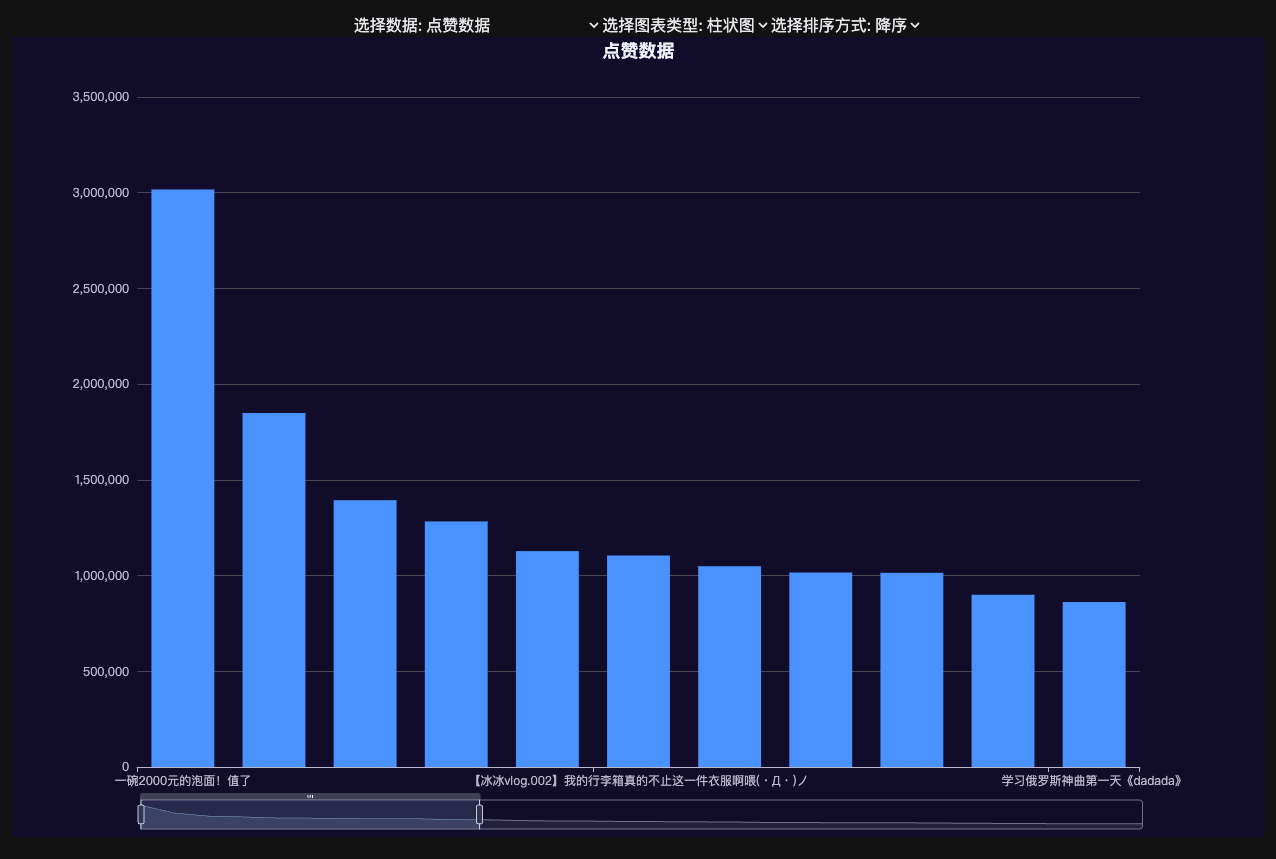
收藏中点赞最多的视频。
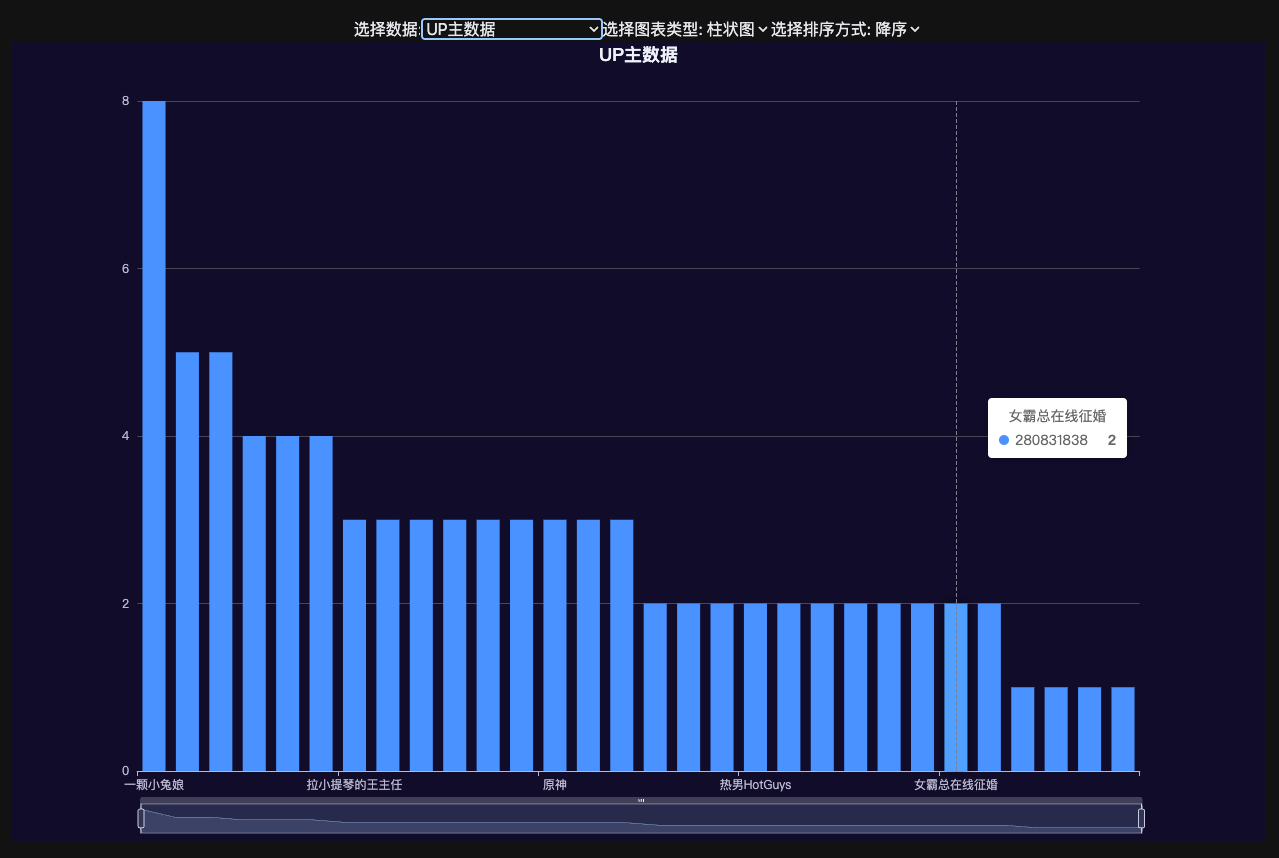
收藏视频最多的 up 主。
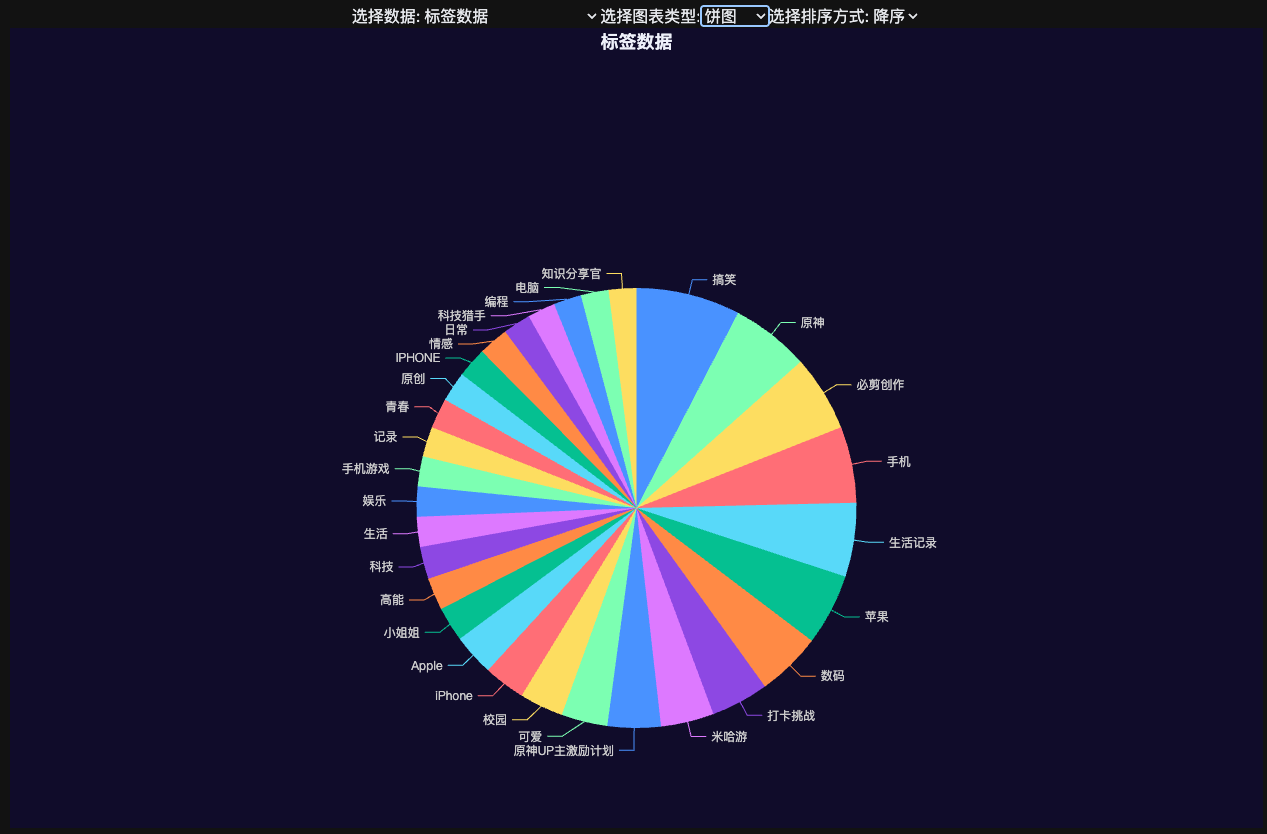
还有其他类似评论、投币等数据报告中不展示。收藏视频的标签分布图。
收藏视频中分区的分布。
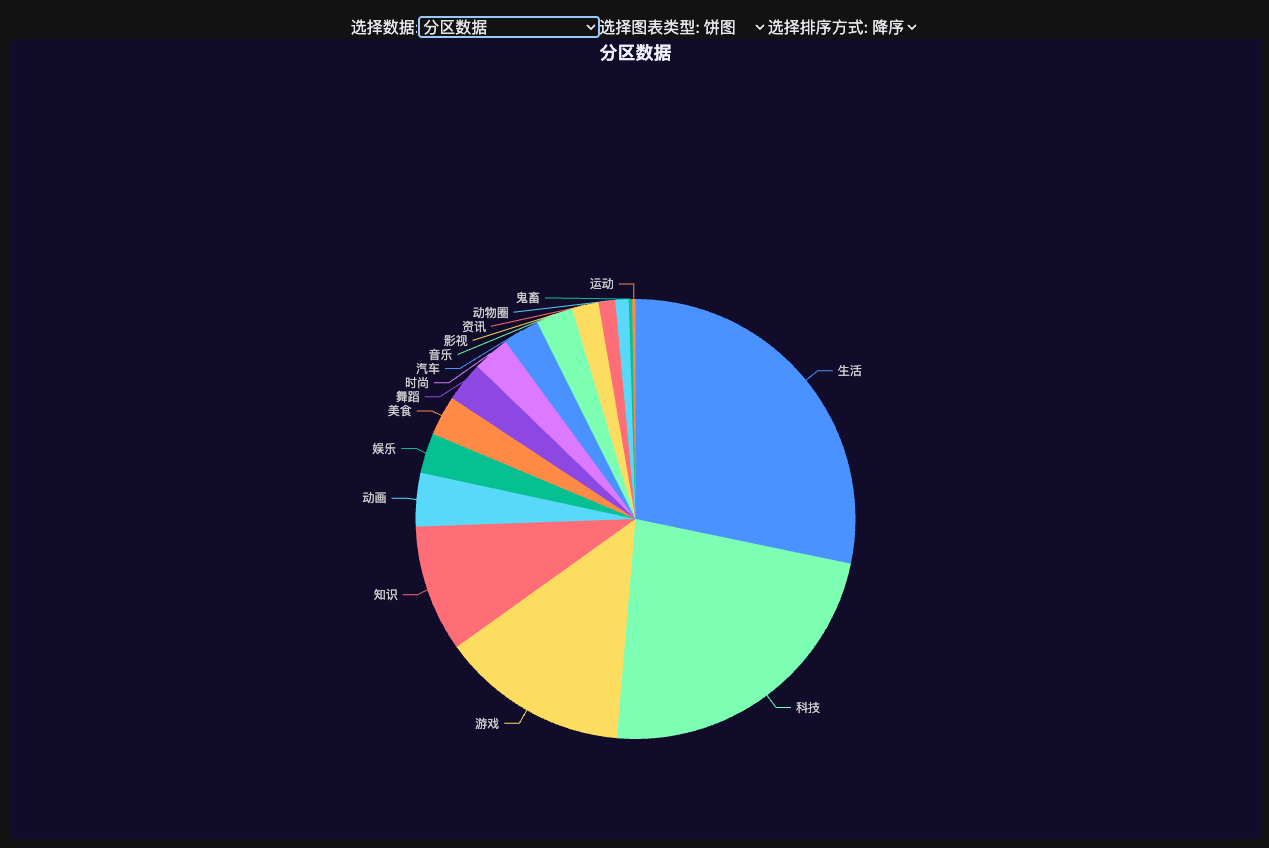
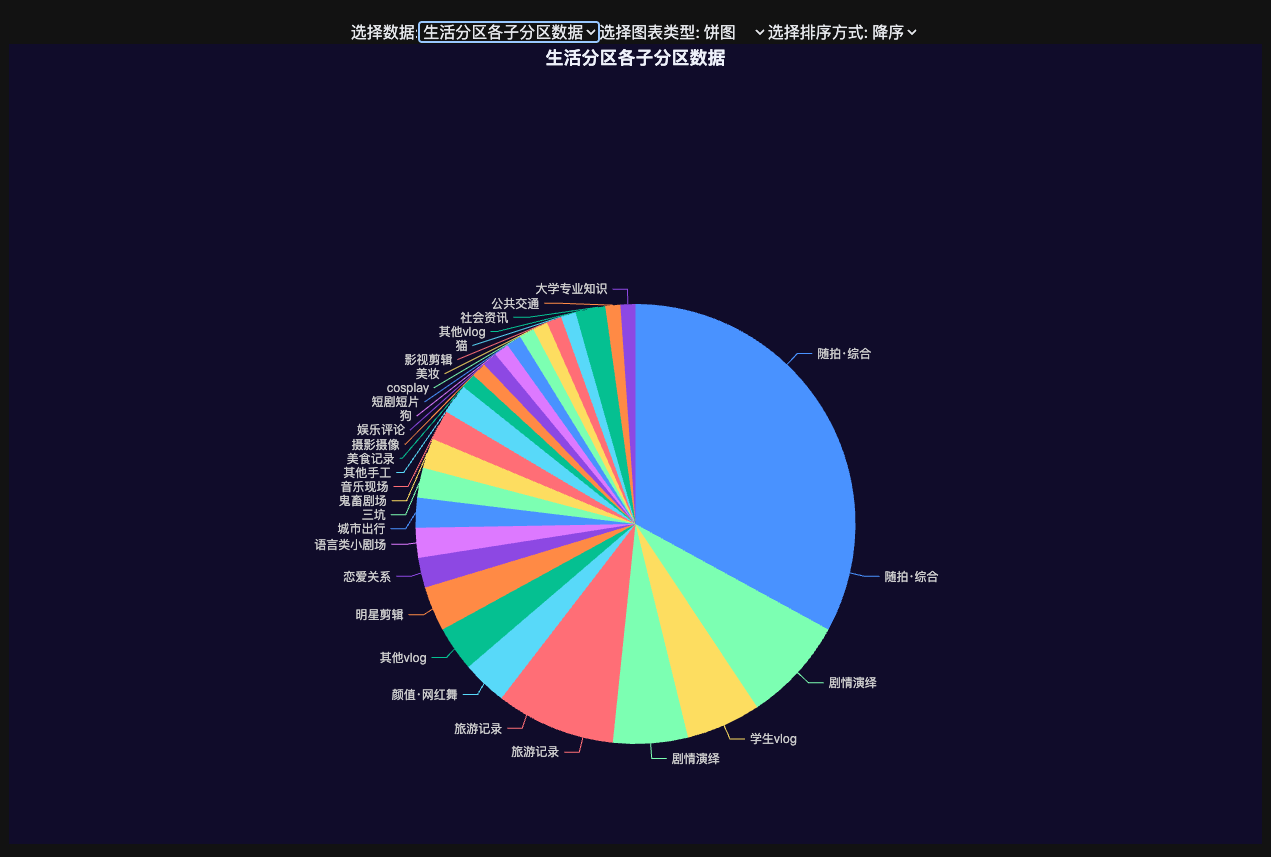
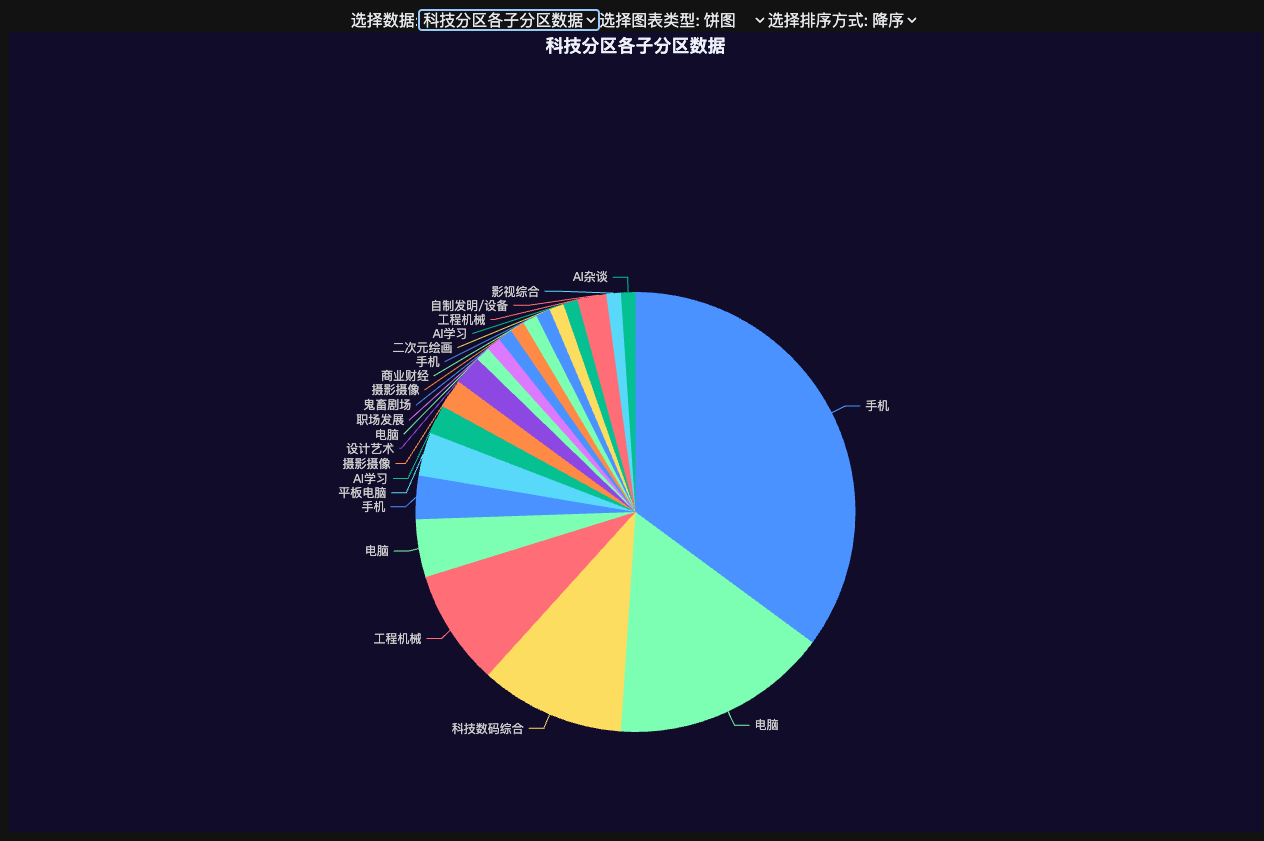
选择最大的两个分区,生活和游戏,计算具体子分区的分布。
3.7.5收藏夹预测系统
需要使用 python 构建一个简单的服务器,供展示系统进行交互,代码见 ml_server.py。使用 Flask 编写服务,接受一个参数 bvid,首先爬取视频的基础信息,然后加载模型进行预测,将预测结果返回。
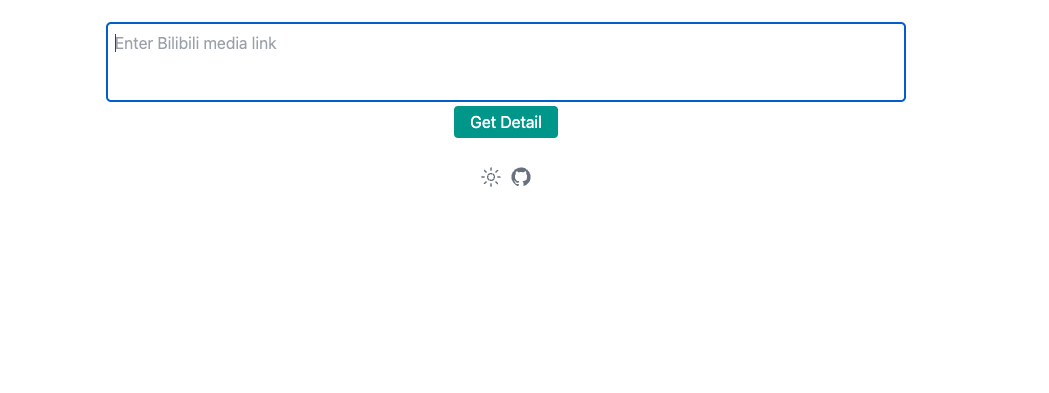
3.7.6收藏夹预测系统展示
使用前需要先运行代码 ml_server.py,点击首页的收藏夹预测进入预测页面,到 b 站的某个视频播放页复制分享链接,粘贴到网站上,网站会正则匹配出视频的 bvid,传给 flask 后台进行处理,返回相应的结果。
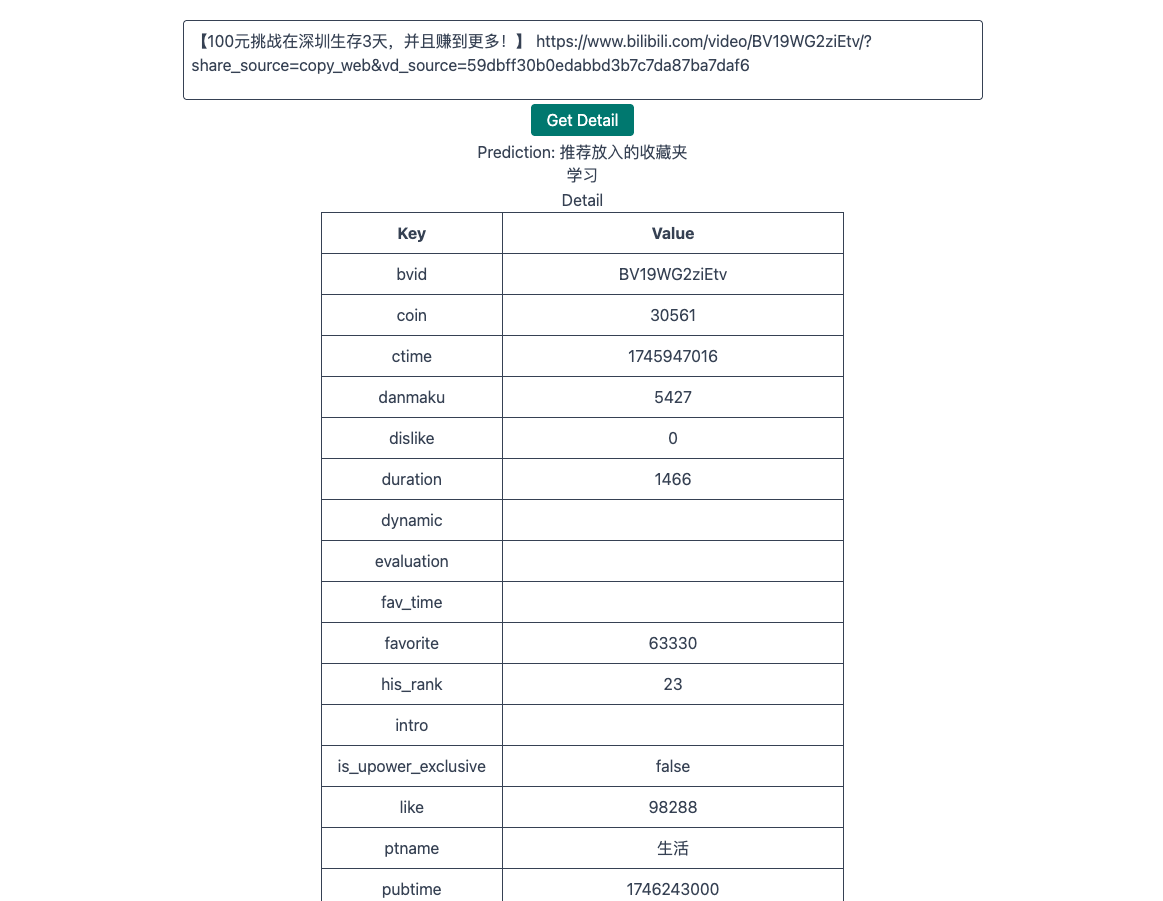
4.大模型使用
4.1 在 WORD 文档中自动创建目录
位置:作业选题
由于长期使用 Markdown完成报告,对 WORD 已经比较生疏。使用 ChatGPT 解决了“word 文档创建自动目录”、“ word 文档目录页独占一页”、“ 中文使用宋体,英文自动使用 time new roman”、“ word 超链接”四个问题,均得到了较好的解答。
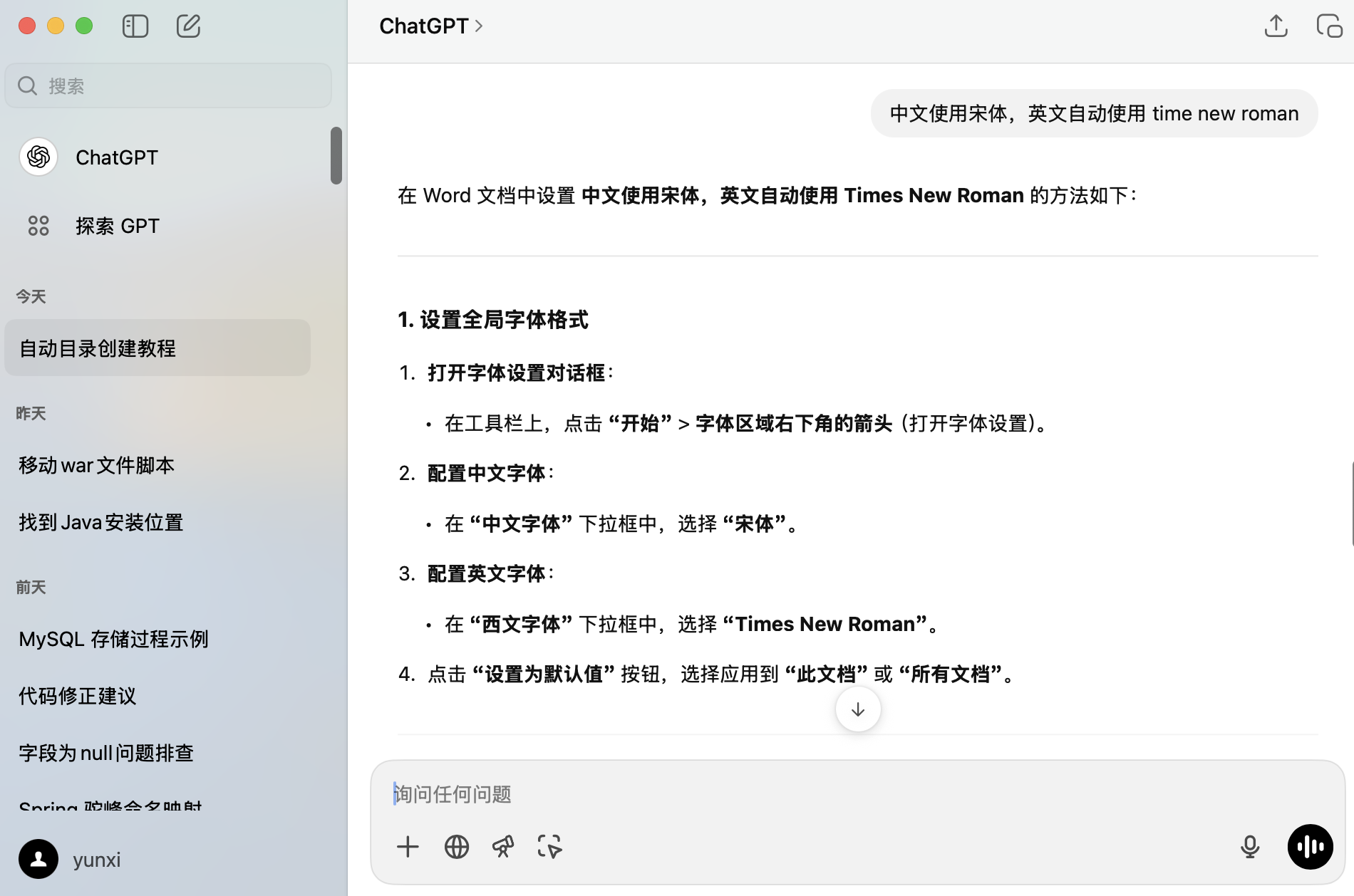
4.2 Ubuntu 22.04 不提供 arm64 镜像
位置:安装 VMWare 以及 Ubuntu 22.04
询问 ChatGPT 两个问题,开启联网搜索功能,“ubnuntu 22.04 desktop iso 下载链接”、“arm”,依次询问,等待答复即可。
ChatGPT 会联网搜索镜像下载地址,同时给出先下载 arm64 的 server 镜像再安装桌面环境的解决思路。同时提示我“如果你能提供具体的设备型号,我可以为你提供更详细的安装建议。”,但已解决问题,无需继续追问。
4.3WORD 文档中插入代码
位置: 安装 Hadoop 3.3.5
问题:“word 中如何优雅地插入代码快”(询问时错别字)。
回答: 如下为按照 ChatGPT 提供的一种方法制作的可以复制的代码块。
### 方法 5:创建自定义样式
1. 在 Word 中,打开 样式 面板。
2. 创建新样式,命名为“代码”。
3. 设置以下属性:
* 字体:Consolas、Courier New 或其他等宽字体。
* 字号:稍小于正文(如 10 或 11)。
* 背景色:浅灰色。
* 行距:单倍。
4. 每次插入代码时,应用此样式。选择以上任一种方法后,可以根据需求调整细节以实现更优雅的代码展示效果。
4.4 Spark 与 Python 兼容性
位置:安装 Spark 3.4.0
问题:“spark 与 python 版本3”(这里不小心按了回车,导致提示词没有输完)。
回答: 经过与提供的来源网站 Apache Spark 3.4 Requirements 比对,网站显示需要 Python 3.7 以上,说明 ChatGPT 提供的 Spark 3.4.0 的兼容性是较为可信的。
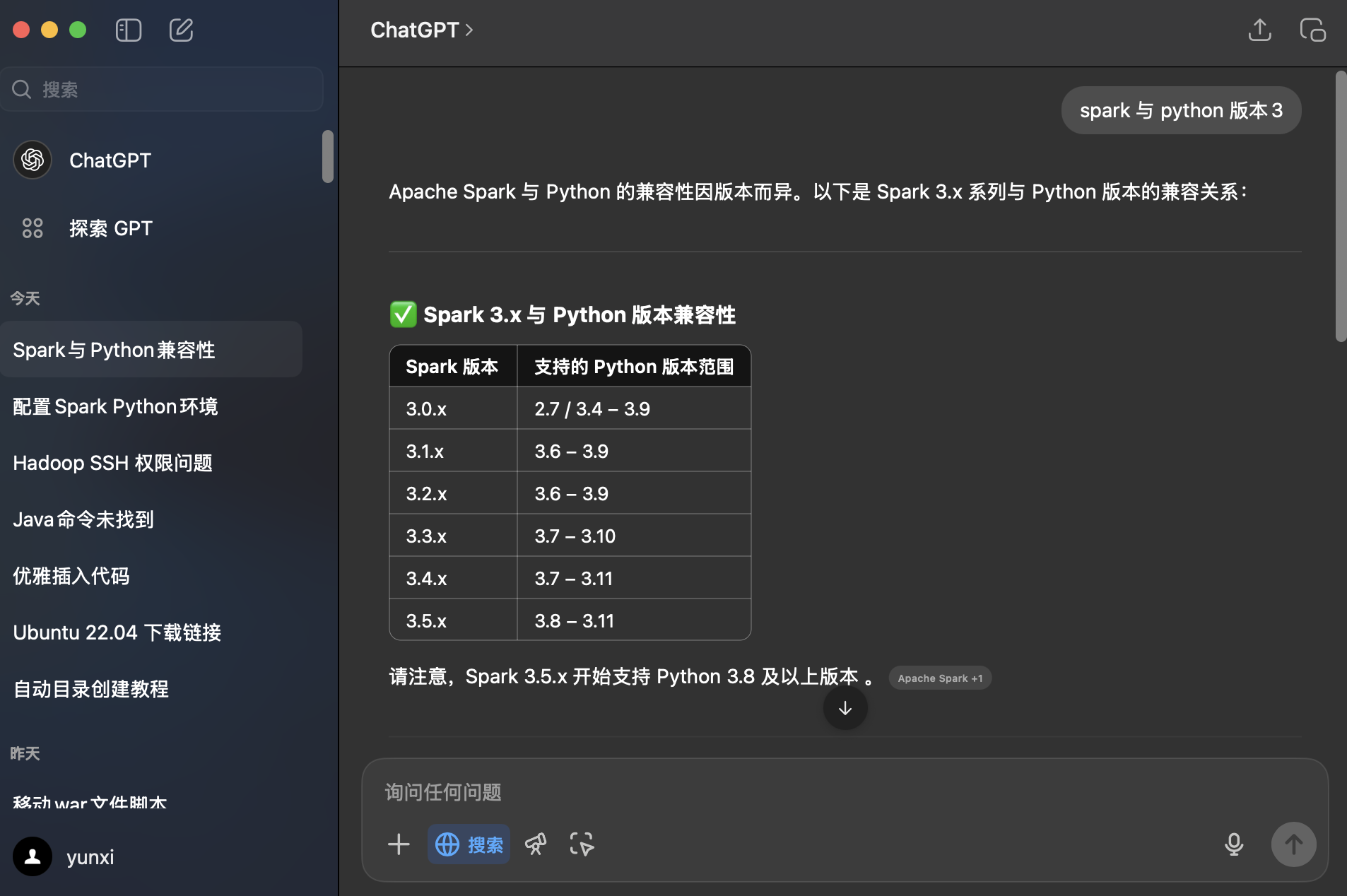
查看 Linux 中现有 Python 版本,为 Python 3.10.12,兼容 Spark 3.4.0。
python3 –version # Python 3.10.12实际编写 Python 脚本测试,输出 1,使用如下命令运行:
./bin/spark-submit ~/Documents/ziyu-db/test.py输出结果如下,可见 Python 脚本正常运行:
hadoop@xmudblab:/usr/local/spark$./bin/spark-submit ~/Documents/ziyu-db/test.py
2025-05-01 12:52:56,579 WARN util.Utils: Your hostname, xmudblab resolves to a loopback address: 127.0.1.1; using 172.16.75.128 instead (on interface ens160)
2025-05-01 12:52:56,579 WARN util.Utils: Set SPARK_LOCAL_IP if you need to bind to another address
1
2025-05-01 12:52:58,849 INFO util.ShutdownHookManager: Shutdown hook called
2025-05-01 12:52:58,849 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-1f47a65b-0ea5-41f3-9dcf-c559ee6cd8aa4.5 推荐爬取的网站
位置:采集数据集
问题:
完整实现数据分析全流程,具体如下:
(1) 从网络寻找一个网站,使用 Python 语言编写网络爬虫采集数据集(数据集不要
太大,建议控制在 50MB 以内) ;
基于这个要求,帮我几个有意义的、中国青少年熟悉的、提供可分析数据的网站,同时大致介绍一下它的数据分析需求回答(适度简略):
以下是几个适合中国青少年、数据可获取且具有分析价值的网站,供你在数据分析全流程项目中选择使用:
⸻
1. 百度指数
• 简介:百度指数是基于百度搜索行为数据的分析平台,提供关键词搜索趋势、用户画像、地域分布等信息。 
• 数据分析需求:
• 趋势分析:分析特定关键词在不同时间段的搜索热度变化。
• 地域分布:了解某一关键词在不同地区的关注度。
• 人群画像:获取搜索某关键词用户的性别、年龄等信息。
• 适用场景:适合分析青少年对某一话题(如“高考”、“电竞”等)的关注度变化,了解其兴趣趋势。
⸻
2. 小红书
• 简介:。。。
⸻
3. 易班
• 。。。
⸻
4. 中国家庭追踪调查(CFPS)
• 。。。
⸻
5. Weibo-COV 数据集
• 。。。
⸻
6. 腾讯青少年互联网使用情况调查报告
• 。。。
⸻
建议的选题方向
根据上述网站和数据源,以下是几个可能的选题方向:
1. 青少年对特定话题的关注度分析:利用百度指数,分析青少年对“高考”、“电竞”等关键词的关注度变化趋势。
2. 社交平台上的青少年行为研究:通过小红书或易班的数据,研究青少年的内容创作、互动行为等,了解其社交网络结构和兴趣点。
3. 疫情期间青少年的情绪变化分析:利用Weibo-COV数据集,分析青少年在疫情期间的情绪波动和信息传播行为。
4. 青少年网络素养评估:基于腾讯的调查报告,评估青少年的网络素养水平,提出提升建议。
5. 家庭背景对青少年发展的影响:利用CFPS数据,研究家庭经济状况、教育资源等对青少年成长的影响。
如果你有兴趣深入某一方向,我可以进一步协助你制定数据采集、预处理、分析、可视化等各个阶段的具体方案。4.6 Copliot 代码补全进行爬虫代码编写
位置:编写收藏夹采集代码
直至今日,对比众多 MCP、Builder 等等各大 AI IDE 主推的时髦功能,最为稳定、高效、可信任的 AI 代码功能仍然是 AI 代码补全。
以下是在编写爬虫代码时的例子,下图代码是使用 Python 的 TypedDict 类来规定爬虫时像接口发出请求使用的参数类型。
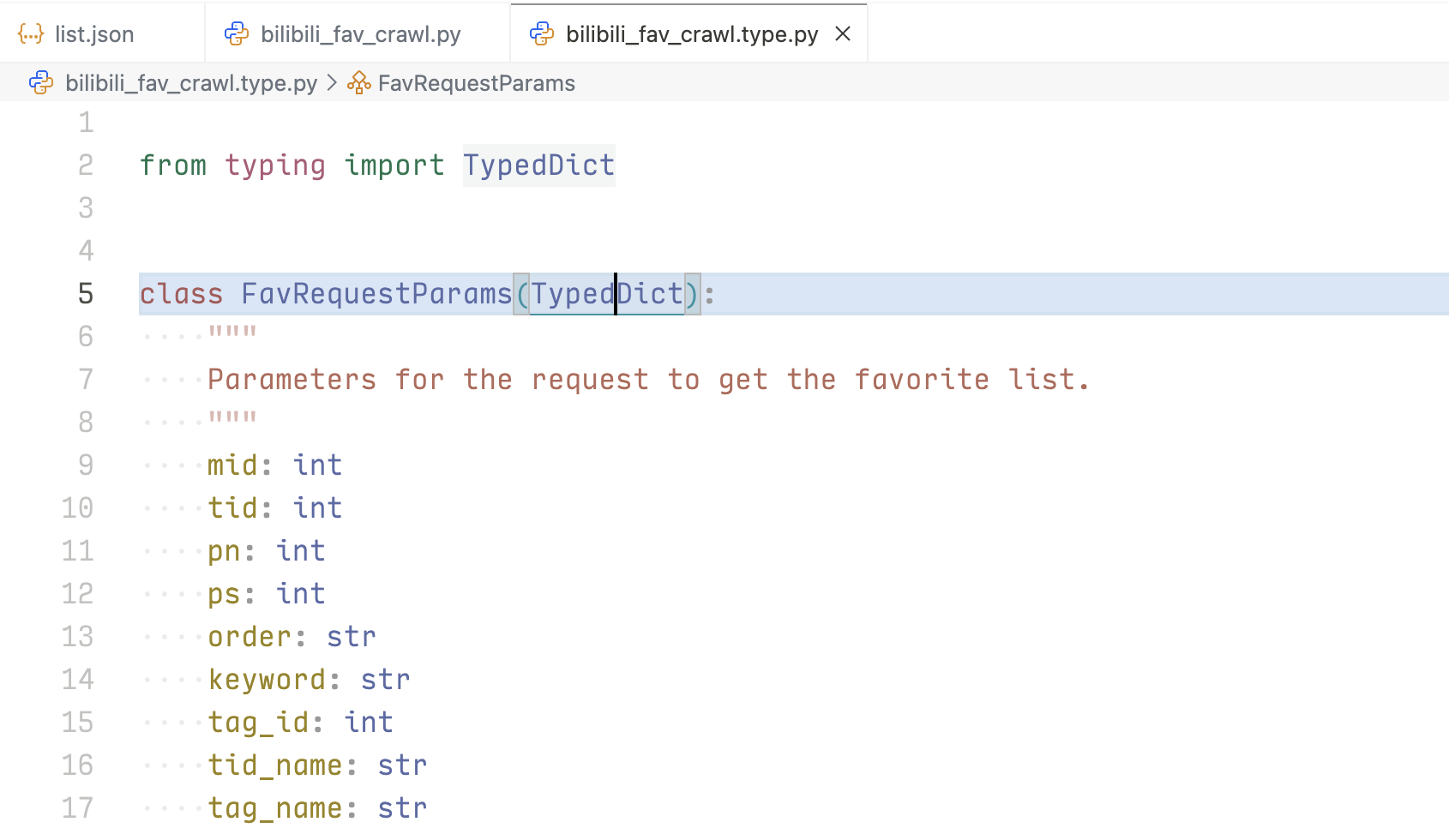
代码是平平无奇的,但这份代码的编写过程中,人工操作的部分只有:新建一个 bilibili_fav_crawl.type.py;输入 class FavRequestParams(TypedDict)。在我输入完这行代码时(甚至还没输冒号),IDE 已经给出后面的所有代码,虽然有小错误。这期间,我没有给出任何指令,没有在这个项目中输入任何跟这个接口相关的描述,只有一个包含接口的返回结果的 json 文件。同时也可以看出 b 站的这个接口调用量是不低的。
同时,在修改这个请求参数时,AI 也会不断给出提示,比如需要将 mid 改为 media_id,在我删除这一行,输入 “med” 后,AI 已经给出了这一行全部代码,只需按下 tab 键即可确认,对工作效率的提升是显而易见的。
4.7ChatGPT 联网搜索 b 站 api 接口文档
位置:加量采集收藏夹中每个视频的信息
问题:获取 b 站视频基本信息 api
回答:

4.8提取 markdown 文档中分区信息,整理成统一数据结构
位置:增加对于主分区信息的处理
问题:
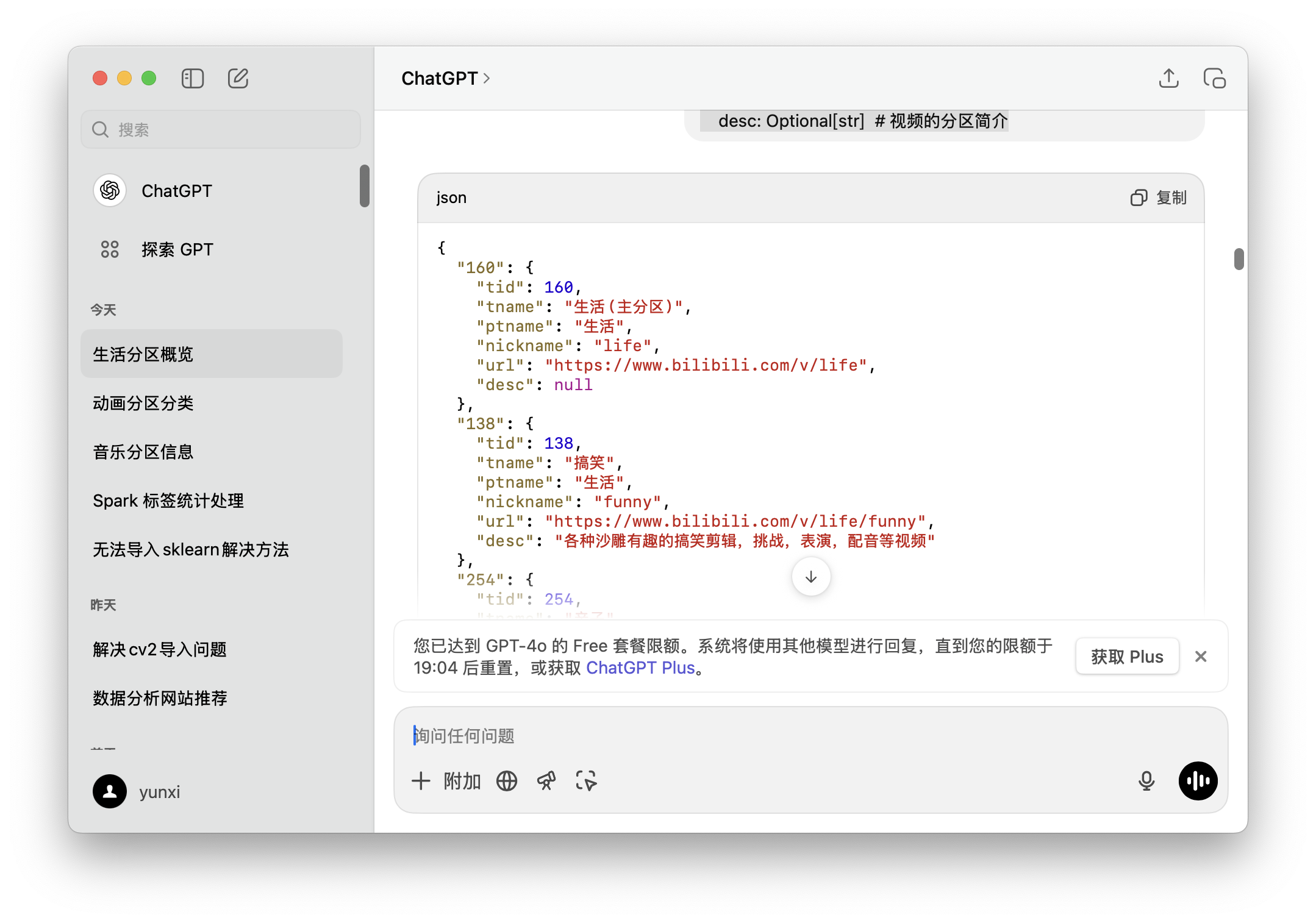
(先给出 markdown 文本,由于太长,实际操作时分块提问)
以上为b站视频分区信息,二级标题为大分区,表格中为子分区,请根据这个生成一个包含每个子分区信息的 json,直接给我 json,每个子分区的tid作为key,value设为如下类型class TidInfo(TypedDict):
"""
Information about the Bilibili video.
"""
tid: Optional[int] # 视频的 tid
tname: Optional[str] # 视频的分区名称
ptname: Optional[str] # 视频的大分区名称
nickname: Optional[str] # 视频的分区代号
url: Optional[str] # 视频的分区链接
desc: Optional[str] # 视频的分区简介回答:
4.9其他
还有非常多代码编写的地方,依靠 IDE 的 AI 功能无时无刻不辅助进行。