访问林子雨编著《数据采集与预处理》教材官网
《数据采集与预处理》教材中的所有实验是在Windows操作系统中完成的,但是,有些高校教师在使用教材过程中反馈了意见,现在有一些学生使用苹果电脑,不是Windows系统,无法顺利开展实验,因此,建议我们团队开发面向Linux系统的实验指南。为了满足这类需求,特制作本指南。
第2章 大数据实验环境搭建
2.1 安装Linux环境
(1)苹果Mac系统安装Linux系统,请自行搜索网络教程。
(2)在Windows操作系统中安装Linux虚拟机,请参考“在Windows中使用VirtualBox安装Ubuntu虚拟机”。如果不想使用VirtualBox,也可以使用VMWare虚拟机软件安装Linux虚拟机,安装过程比较简单,请自行搜索网络教程。
2.2 Python的安装和使用
(1)请访问Anaconda的下载和使用方法,在Linux系统中安装Anaconda。Anaconda是基于Python的数据处理和科学计算平台,它内置了Python和许多非常有用的第三方库。安装Anaconda,就相当于把Python和一些常用的库(如Numpy、pandas、MatplotLib等)自动安装好了。Linux系统中已经默认自带了Python环境,但是,没有关系,我们依然可以同时安装Anaconda,而且安装了Anaconda以后,也不会影响到Linux系统已经自带的Python。
需要注意的是,下载Anaconda安装包时,需要到(https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/)下载Anaconda3-2022.10-Linux-x86_64.sh。安装结束后,需要额外安装Python3.8,可以在Anaconda3目录下执行如下命令安装Python3.8:
conda create -n py38 python=3.8上面命令执行以后,实际上安装的是Python3.8.15,然后可以执行如下命令,把Python3.8激活为当前使用的Python环境:
conda activate py38这时,在任何目录下输入python命令,都会进入到Python3.8环境:
(base) hadoop@hadoop01:~$ conda env list
# conda environments:
#
base * /home/hadoop/anaconda3
py38 /home/hadoop/anaconda3/envs/py38
(base) hadoop@hadoop01:~$ python3
Python 3.9.13 (main, Aug 25 2022, 23:26:10)
[GCC 11.2.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> quit()
(base) hadoop@hadoop01:~$ conda activate py38
(py38) hadoop@hadoop01:~$ python
Python 3.8.15 (default, Nov 4 2022, 20:59:55)
[GCC 11.2.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> quit()
(py38) hadoop@hadoop01:~$ 另外,每次Linux启动时,都会自动进入Anaconda的base环境,命令提示符前面都会出现“(base)”这个前缀,可以执行如下命令取消这个前缀,也就是说,每次启动Linux时,不要自动进入Anaconda的base环境:
conda config --set auto_activate_base false这时,关闭当前终端,再次打开终端,命令提示符前面就不会出现“(base)”前缀了。
每次启动Linux以后,如果要进入Python3.8的交互式执行环境,可以执行如下命令:
cd ~/anaconda3/envs/py38/bin
./python32.3 PyCharm的安装和使用
在Linux系统中,可以使用PyCharm开发工具来编写和调试Python程序,具体请参考“在Linux系统中安装和使用PyCharm”。
2.4 MySQL数据库的安装和使用
请参考博客“在Linux中使用Python操作MySQL数据库”。
2.4 Hadoop的安装和使用
(1)在Linux系统中安装Hadoop,可以参考博客“Hadoop3.1.3安装教程_单机/伪分布式配置_Hadoop3.1.3/Ubuntu18.04(16.04)”
(2)分布式文件系统HDFS的使用方法,可以参考博客“HDFS编程实践(Hadoop3.1.3)”。
第3章 网络数据采集
3.1 用Python实现HTTP请求
打开Linux终端,执行如下命令进入Anaconda中安装的Python3.8环境:
cd ~/anaconda3/envs/py38/bin
./python3下面是通过urllib.request模块实现发送GET请求获取网页内容的实例:
>>> import urllib.request
>>> response=urllib.request.urlopen("http://www.baidu.com")
>>> html=response.read()
>>> print(html)3.2 urllib3模块
在使用urllib3之前,需要打开一个Linux终端窗口使用如下命令进行安装:
cd ~/anaconda3/envs/py38/bin
./pip3 install urllib3具体执行效果如下图所示:

下面是通过GET请求获取网页内容的实例:
>>> import urllib3
>>> #需要一个PoolManager实例来生成请求,由该实例对象处理与线程池的连接以及线程安全的所有细节,不需要任何人为操作
>>> http = urllib3.PoolManager()
>>> response = http.request('GET','http://www.baidu.com')
>>> print(response.status)
>>> print(response.data)3.3 requests模块
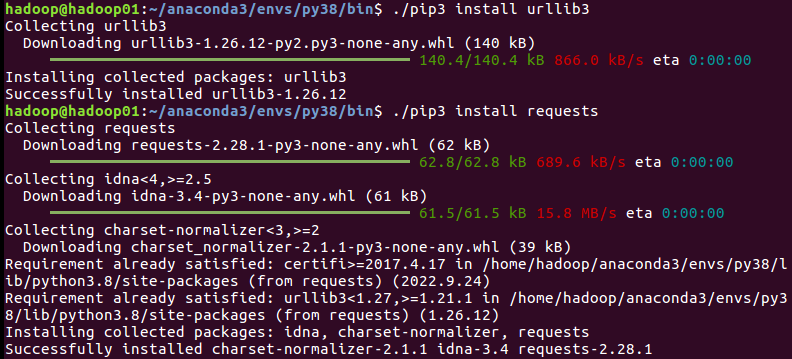
在使用requests之前,需要打开一个Linux终端窗口使用如下命令进行安装:
cd ~/anaconda3/envs/py38/bin
./pip3 install requests具体执行效果如下图所示:
以GET请求方式为例,打印多种请求信息的代码如下:
>>> import requests
>>> response = requests.get('http://www.baidu.com') #对需要爬取的网页发送请求
>>> print('状态码:',response.status_code) #打印状态码
>>> print('url:',response.url) #打印请求url
>>> print('header:',response.headers) #打印头部信息
>>> print('cookie:',response.cookies) #打印cookie信息
>>> print('text:',response.text) #以文本形式打印网页源码
>>> print('content:',response.content) #以字节流形式打印网页源码3.4 BeautifulSoup模块和lxml解析器
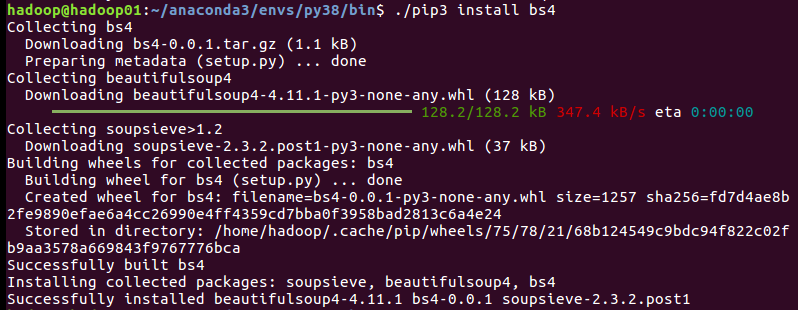
打开一个Linux终端窗口使用如下命令安装BeautifulSoup模块:
cd ~/anaconda3/envs/py38/bin
./pip3 install bs4具体执行效果如下图所示:
打开一个Linux终端窗口使用如下命令安装lxml解析器模块:
cd ~/anaconda3/envs/py38/bin
./pip3 install lxml具体执行效果如下图所示:

下面是实例代码:
>>> html_doc = """
<html><head><title>BigData Software</title></head>
<p class="title"><b>BigData Software</b></p>
<p class="bigdata">There are three famous bigdata softwares; and their names are
<a href="http://example.com/hadoop" class="software" id="link1">Hadoop</a>,
<a href="http://example.com/spark" class="software" id="link2">Spark</a> and
<a href="http://example.com/flink" class="software" id="link3">Flink</a>;
and they are widely used in real applications.</p>
<p class="bigdata">...</p>
"""
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html_doc,"lxml")
>>> content = soup.prettify()
>>> print(content)3.5 采集古诗文网站
教材第69页3.6.1节是一个采集古诗文网站的实例,由于网站的网页结构发生了变化,所以,教材中的代码已经无法使用,这里给出可以使用的最新代码如下:
# parse_poem.py
# --*-- encoding: utf-8 --*--
# @ModuleName: parse_poem
# @Function:
# @Author: dblab
# @Time: 2022/10/25 14:36
import requests
from bs4 import BeautifulSoup
import time
# 函数1:请求网页
def page_request(url, ua):
response = requests.get(url, headers=ua)
html = response.content.decode('utf-8')
return html
# 函数2:解析网页
def page_parse(html):
soup = BeautifulSoup(html, 'lxml')
title = soup('title')
# 诗句内容:诗句+出处+链接
info = soup.select('body > div.main3 > div.left > div.sons > div.cont')
# 诗句链接
sentence = soup.select('div.left > div.sons > div.cont > a:nth-of-type(1)')
sentence_list = []
href_list = []
for i in range(len(info)):
curInfo = info[i]
poemInfo = ''
poemInfo = poemInfo.join(curInfo.get_text().split('\n'))
sentence_list.append(poemInfo)
href = sentence[i].get('href')
href_list.append("https://so.gushiwen.org" + href)
# todo sentence 和 poet数量可能不符
# sentence = soup.select('div.left > div.sons > div.cont > a:nth-of-type(1)')
# poet = soup.select('div.left > div.sons > div.cont > a:nth-of-type(2)')
# for i in range(len(sentence)):
# temp = sentence[i].get_text() + "---" + poet[i].get_text()
# sentence_list.append(temp)
# href = sentence[i].get('href')
# href_list.append("https://so.gushiwen.org" + href)
return [href_list, sentence_list]
def save_txt(info_list):
import json
with open(r'sentence.txt', 'a', encoding='utf-8') as txt_file:
for element in info_list[1]:
txt_file.write(json.dumps(element, ensure_ascii=False) + '\n\n')
# 子网页处理函数:进入并解析子网页/请求子网页
def sub_page_request(info_list):
subpage_urls = info_list[0]
ua = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36'}
sub_html = []
for url in subpage_urls:
html = page_request(url, ua)
sub_html.append(html)
return sub_html
# 子网页处理函数:解析子网页,爬取诗句内容
def sub_page_parse(sub_html):
poem_list = []
for html in sub_html:
soup = BeautifulSoup(html, 'lxml')
poem = soup.select('div.left > div.sons > div.cont > div.contson')
if len(poem) == 0:
continue
poem = poem[0].get_text()
poem_list.append(poem.strip())
return poem_list
# 子网页处理函数:保存诗句到txt
def sub_page_save(poem_list):
import json
with open(r'poems.txt', 'a', encoding='utf-8') as txt_file:
for element in poem_list:
txt_file.write(json.dumps(element, ensure_ascii=False) + '\n\n')
if __name__ == '__main__':
print("**************开始爬取古诗文网站********************")
ua = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36'}
poemCount = 0
for i in range(1, 5):
# todo 链接错误
# url = 'https://so.gushiwen.org/mingju/default.aspx?p=%d&c=&t=' % (i)
url = 'https://so.gushiwen.cn/mingjus/default.aspx?page=%d' % i
print(url)
# time.sleep(1)
html = page_request(url, ua)
info_list = page_parse(html)
save_txt(info_list)
# 开始处理子网页
print("开始解析第%d" % i + "页")
# 开始解析名句子网页
sub_html = sub_page_request(info_list)
poem_list = sub_page_parse(sub_html)
sub_page_save(poem_list)
poemCount += len(info_list[0])
print("****************爬取完成***********************")
print("共爬取%d" % poemCount + "个古诗词名句")
print("共爬取%d" % poemCount + "个古诗词")可以在PyCharm中调试上面的代码。我们在第2章已经学习过如何在Linux系统中安装和使用PyCharm,这里不再赘述,可以参考博客“在Linux系统中安装和使用PyCharm”。
3.6 编写Scrapy爬虫程序爬取古诗词网站
请参考博客“在Linux系统中使用PyCharm编写Scrapy爬虫程序爬取古诗词网站”。
第4章 分布式消息系统Kafka
4.1 Kafka的安装和使用方法
请参考博客“在Linux系统中安装和使用Kafka”
然后,只要把教材中在Windows中运行的代码直接搬到Linux下运行即可。
第5章 日志采集系统Flume
5.1 Flume的安装和使用方法
请参考博客“日志采集工具Flume的安装与使用方法”。
然后,只要把教材中在Windows中运行的代码直接搬到Linux下运行即可。
第7章 ETL工具Kettle
请参考博客“Kettle的安装和使用”。
第8章 使用pandas进行数据清洗
8.1 进入Python交互式执行环境
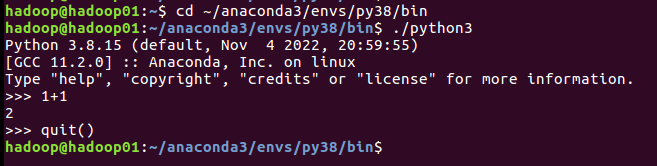
打开Linux终端,执行如下命令进入Anaconda中安装的Python3.8环境:
cd ~/anaconda3/envs/py38/bin
./python3这时就会进入到Python3.8交互式执行环境,可以在Python命令提示符“>>>”后面输入Python语句去执行。如果要退出Python交互式执行环境,可以执行如下命令:
>>> quit()具体执行效果如下图所示:
8.2 安装NumPy模块
在Linux终端中执行如下命令安装NumPy模块:
cd ~/anaconda3/envs/py38/bin
./pip3 install numpy具体执行效果如下图所示:

现在就可以引入NumPy模块,代码如下:
cd ~/anaconda3/envs/py38/bin
./python3>>> import numpy as np
>>> a = [1,2,3,4,5] # 创建简单的列表
>>> b = np.array(a) # 将列表转换为数组
>>> b
array([1, 2, 3, 4, 5])具体执行效果如下图所示:
8.3 安装pandas模块
在Linux终端中执行如下命令安装pandas模块:
cd ~/anaconda3/envs/py38/bin
./pip3 install pandas具体执行效果如下图所示:

现在就可以引入pandas模块编写代码了:
>>> import numpy as np
>>> import pandas as pd
>>> from pandas import Series,DataFrame
>>> obj=Series([3,5,6,8,9,2])
>>> obj
0 3
1 5
2 6
3 8
4 9
5 2
dtype: int64具体执行效果如下图所示:

8.4 安装Matplotlib模块
在Linux终端中执行如下命令安装pandas模块:
cd ~/anaconda3/envs/py38/bin
./pip3 install matplotlit具体执行效果如下图所示:

现在就可以引入matplotlib模块编写代码了:
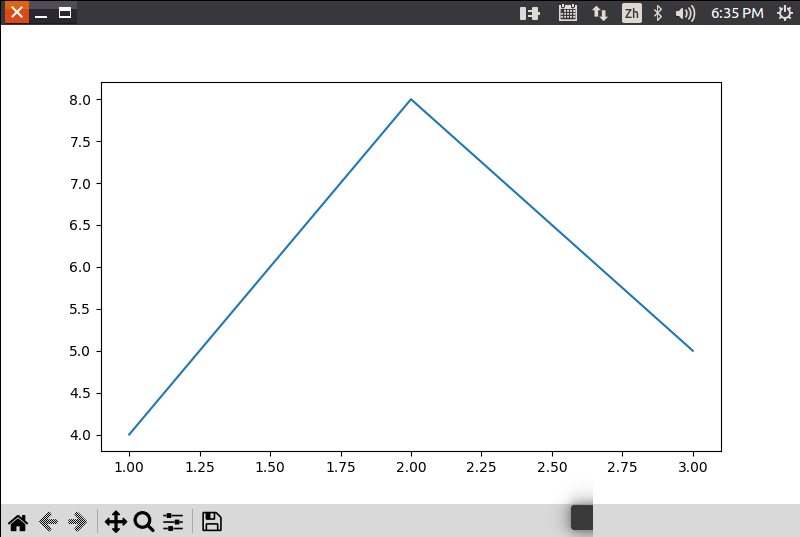
>>> import matplotlib.pyplot as plt
>>> plt.plot([1,2,3],[4,8,5])
>>> plt.show()这时,会出现一张图片,具体执行效果如下图所示: