返回本案例首页
查看前一步骤操作:步骤三:Spark Streaming实时处理数据
《Spark+Kafka构建实时分析Dashboard案例——步骤四:结果展示》
开发团队:厦门大学数据库实验室 联系人:林子雨老师ziyulin@xmu.edu.cn
版权声明:版权归厦门大学数据库实验室所有,请勿用于商业用途;未经授权,其他网站请勿转载
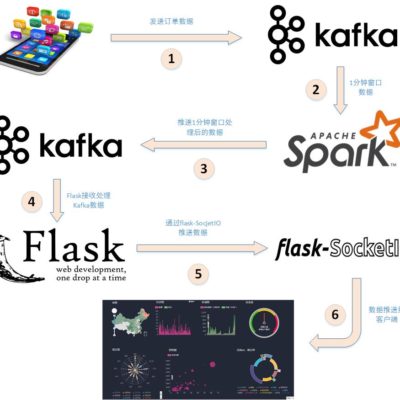
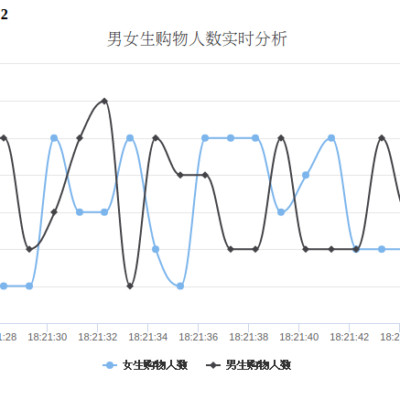
本教程介绍大数据课程实验案例“Spark+Kafka构建实时分析Dashboard”的第四个步骤,结果展示。在本篇博客中,将介绍如何利用Flask-SocketIO向客户端发送消息以及客户端如何利用highcharts.js展示数据。