
【版权声明】博客内容由厦门大学数据库实验室拥有版权,未经允许,请勿转载!
一、方法简介
协同过滤是一种基于一组兴趣相同的用户或项目进行的推荐,它根据邻居用户(与目标用户兴趣相似的用户)的偏好信息产生对目标用户的推荐列表。
关于协同过滤的一个经典的例子就是看电影。如果你不知道哪一部电影是自己喜欢的或者评分比较高的,那么通常的做法就是问问周围的朋友,看看最近有什么好的电影推荐。而在问的时候,肯定都习惯于问跟自己口味差不多的朋友,这就是协同过滤的核心思想。因此,协同过滤是在海量数据中挖掘出小部分与你品味类似的用户,在协同过滤中,这些用户成为邻居,然后根据他们喜欢的东西组织成一个排序的目录推荐给你(如下图所示)。
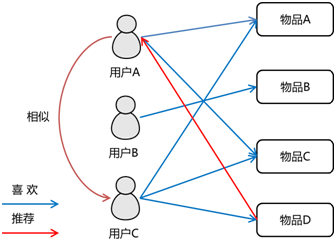
协同过滤算法主要分为基于用户的协同过滤算法和基于项目的协同过滤算法。MLlib当前支持基于模型的协同过滤,其中用户和商品通过一小组隐语义因子进行表达,并且这些因子也用于预测缺失的元素。Spark MLlib实现了 交替最小二乘法 (ALS) 来学习这些隐性语义因子。
二、隐性反馈 vs 显性反馈
显性反馈行为包括用户明确表示对物品喜好的行为,隐性反馈行为指的是那些不能明确反应用户喜好的行为。在许多的现实生活中的很多场景中,我们常常只能接触到隐性的反馈,例如页面游览,点击,购买,喜欢,分享等等。
基于矩阵分解的协同过滤的标准方法,一般将用户商品矩阵中的元素作为用户对商品的显性偏好。在 MLlib 中所用到的处理这种数据的方法来源于文献: Collaborative Filtering for Implicit Feedback Datasets 。 本质上,这个方法将数据作为二元偏好值和偏好强度的一个结合,而不是对评分矩阵直接进行建模。因此,评价就不是与用户对商品的显性评分,而是与所观察到的用户偏好强度关联起来。然后,这个模型将尝试找到隐语义因子来预估一个用户对一个商品的偏好。
示例
下面的例子中,我们将获取MovieLens数据集,其中每行包含一个用户、一个电影、一个该用户对该电影的评分以及时间戳。我们使用默认的ALS.train() 方法,即显性反馈(默认implicitPrefs 为false)来构建推荐模型并根据模型对评分预测的均方根误差来对模型进行评估。
1. 导入需要的包:
import org.apache.spark.ml.evaluation.RegressionEvaluator
import org.apache.spark.ml.recommendation.ALS
2. 根据数据结构创建读取规范:
创建一个Rating类型,即[Int, Int, Float, Long];然后建造一个把数据中每一行转化成Rating类的函数。
scala> case class Rating(userId: Int, movieId: Int, rating: Float, timestamp: Long)
defined class Rating
scala> def parseRating(str: String): Rating = {
| val fields = str.split("::")
| assert(fields.size == 4)
| Rating(fields(0).toInt, fields(1).toInt, fields(2).toFloat, fields(3).toLong)
| }
parseRating: (str: String)Rating
3. 读取数据:
导入implicits,读取MovieLens数据集,把数据转化成Rating类型;
scala> import spark.implicits._
import spark.implicits._
scala> val ratings = spark.sparkContext.textFile("file:///usr/local/spark/data/mllib/als/sample_movielens_ratings.txt").map(parseRating).toDF()
ratings: org.apache.spark.sql.DataFrame = [userId: int, movieId: int ... 2 more fields]
然后,我们把数据打印看一下:
scala> ratings.show()
+------+-------+------+----------+
|userId|movieId|rating| timestamp|
+------+-------+------+----------+
| 0| 2| 3.0|1424380312|
| 0| 3| 1.0|1424380312|
| 0| 5| 2.0|1424380312|
| 0| 9| 4.0|1424380312|
| 0| 11| 1.0|1424380312|
| 0| 12| 2.0|1424380312|
| 0| 15| 1.0|1424380312|
| 0| 17| 1.0|1424380312|
| 0| 19| 1.0|1424380312|
| 0| 21| 1.0|1424380312|
| 0| 23| 1.0|1424380312|
| 0| 26| 3.0|1424380312|
| 0| 27| 1.0|1424380312|
| 0| 28| 1.0|1424380312|
| 0| 29| 1.0|1424380312|
| 0| 30| 1.0|1424380312|
| 0| 31| 1.0|1424380312|
| 0| 34| 1.0|1424380312|
| 0| 37| 1.0|1424380312|
| 0| 41| 2.0|1424380312|
+------+-------+------+----------+
only showing top 20 rows
3. 构建模型
把MovieLens数据集划分训练集和测试集
scala> val Array(training, test) = ratings.randomSplit(Array(0.8, 0.2))
training: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [userId: int, movieId: int... 2 more fields]
test: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [userId: int, movieId: int ... 2 more fields]
使用ALS来建立推荐模型,这里我们构建了两个模型,一个是显性反馈,一个是隐性反馈
scala> val alsExplicit = new ALS().setMaxIter(5).setRegParam(0.01).setUserCol("userId"). setItemCol("movieId").setRatingCol("rating")
alsExplicit: org.apache.spark.ml.recommendation.ALS = als_05fe5d65ffc3
scala> val alsImplicit = new ALS().setMaxIter(5).setRegParam(0.01).setImplicitPrefs(true). setUserCol("userId").setItemCol("movieId").setRatingCol("rating")
alsImplicit: org.apache.spark.ml.recommendation.ALS = als_7e9b959fbdae
在 ML 中的实现有如下的参数:
numBlocks是用于并行化计算的用户和商品的分块个数 (默认为10)。rank是模型中隐语义因子的个数(默认为10)。maxIter是迭代的次数(默认为10)。regParam是ALS的正则化参数(默认为1.0)。implicitPrefs决定了是用显性反馈ALS的版本还是用适用隐性反馈数据集的版本(默认是false,即用显性反馈)。alpha是一个针对于隐性反馈 ALS 版本的参数,这个参数决定了偏好行为强度的基准(默认为1.0)。nonnegative决定是否对最小二乘法使用非负的限制(默认为false)。
可以调整这些参数,不断优化结果,使均方差变小。比如:imaxIter越大,regParam越 小,均方差会越小,推荐结果较优。
接下来,把推荐模型放在训练数据上训练:
scala> val modelExplicit = alsExplicit.fit(training)
modelExplicit: org.apache.spark.ml.recommendation.ALSModel = als_05fe5d65ffc3
scala> val modelImplicit = alsImplicit.fit(training)
modelImplicit: org.apache.spark.ml.recommendation.ALSModel = als_7e9b959fbdae
4. 模型预测
使用训练好的推荐模型对测试集中的用户商品进行预测评分,得到预测评分的数据集
scala> val predictionsExplicit = modelExplicit.transform(test)
predictionsExplicit: org.apache.spark.sql.DataFrame = [userId: int, movieId: int ... 3 more fields]
scala> val predictionsImplicit = modelImplicit.transform(test)
predictionsImplicit: org.apache.spark.sql.DataFrame = [userId: int, movieId: int ... 3 more fields]
我们把结果输出,对比一下真实结果与预测结果:
scala> predictionsExplicit.show()
+------+-------+------+----------+------------+
|userId|movieId|rating| timestamp| prediction|
+------+-------+------+----------+------------+
| 13| 31| 1.0|1424380312| 0.86262053|
| 5| 31| 1.0|1424380312|-0.033763513|
| 24| 31| 1.0|1424380312| 2.3084288|
| 29| 31| 1.0|1424380312| 1.9081671|
| 0| 31| 1.0|1424380312| 1.6470298|
| 28| 85| 1.0|1424380312| 5.7112412|
| 13| 85| 1.0|1424380312| 2.4970412|
| 20| 85| 2.0|1424380312| 1.9727222|
| 4| 85| 1.0|1424380312| 1.8414592|
| 8| 85| 5.0|1424380312| 3.2290685|
| 7| 85| 4.0|1424380312| 2.8074787|
| 29| 85| 1.0|1424380312| 0.7150749|
| 19| 65| 1.0|1424380312| 1.7827456|
| 4| 65| 1.0|1424380312| 2.3001173|
| 2| 65| 1.0|1424380312| 4.8762875|
| 12| 53| 1.0|1424380312| 1.5465991|
| 20| 53| 3.0|1424380312| 1.903692|
| 19| 53| 2.0|1424380312| 2.6036916|
| 8| 53| 5.0|1424380312| 3.1105173|
| 23| 53| 1.0|1424380312| 1.0042696|
+------+-------+------+----------+------------+
only showing top 20 rows
scala> predictionsImplicit.show()
+------+-------+------+----------+-----------+
|userId|movieId|rating| timestamp| prediction|
+------+-------+------+----------+-----------+
| 13| 31| 1.0|1424380312| 0.33150947|
| 5| 31| 1.0|1424380312|-0.24669354|
| 24| 31| 1.0|1424380312|-0.22434244|
| 29| 31| 1.0|1424380312| 0.15776125|
| 0| 31| 1.0|1424380312| 0.51940984|
| 28| 85| 1.0|1424380312| 0.88610375|
| 13| 85| 1.0|1424380312| 0.15872183|
| 20| 85| 2.0|1424380312| 0.64086926|
| 4| 85| 1.0|1424380312|-0.06314563|
| 8| 85| 5.0|1424380312| 0.2783457|
| 7| 85| 4.0|1424380312| 0.1618208|
| 29| 85| 1.0|1424380312|-0.19970453|
| 19| 65| 1.0|1424380312| 0.11606887|
| 4| 65| 1.0|1424380312|0.068018675|
| 2| 65| 1.0|1424380312| 0.28533924|
| 12| 53| 1.0|1424380312| 0.42327875|
| 20| 53| 3.0|1424380312| 0.17345423|
| 19| 53| 2.0|1424380312| 0.33321634|
| 8| 53| 5.0|1424380312| 0.10090684|
| 23| 53| 1.0|1424380312| 0.06724724|
+------+-------+------+----------+-----------+
only showing top 20 rows
5. 模型评估
通过计算模型的均方根误差来对模型进行评估,均方根误差越小,模型越准确:
scala> val evaluator = new RegressionEvaluator().setMetricName("rmse").setLabelCol("rating"). setPredictionCol("prediction")
evaluator: org.apache.spark.ml.evaluation.RegressionEvaluator = regEval_bc9d91ae7b1a
scala> val rmseExplicit = evaluator.evaluate(predictionsExplicit)
rmseExplicit: Double = 1.6995189118765517
scala> val rmseImplicit = evaluator.evaluate(predictionsImplicit)
rmseImplicit: Double = 1.8011620822359165
打印出两个模型的均方根误差 :
scala> println(s"Explicit:Root-mean-square error = $rmseExplicit")
Explicit:Root-mean-square error = 1.6995189118765517
scala> println(s"Implicit:Root-mean-square error = $rmseImplicit")
Implicit:Root-mean-square error = 1.8011620822359165
可以看到打分的均方差值为1.69和1.80左右。由于本例的数据量很少,预测的结果和实际相比有一定的差距。

