
林子雨编著《数据采集与预处理(第2版)》教材在Windows系统下实验方法(访问第2版教材官网)
说明:第1版教材是在Windows系统进行实验,但是,一些高校老师在机房带学生上机实验时,遇到很多问题,主要是机房操作系统的管理员权限无法给学生,而教材实验需要获得管理员权限,导致一些实验无法顺利开展。因此,改版后的第2版教材,采用了在Linux系统中开展实验,学校机房只要安装Linux虚拟机,就可以一键导入教材配套实验环境,顺利开展实验,不会遇到管理员权限的问题。但是,一些高校有些专业学生只懂得用Windows系统,不会用Linux系统,老师仍然需要采用Windows系统进行授课。因此,作者撰写了本指南,指导教材使用者如何在Windows系统下开展实验。需要说明的是,在Linux系统和Windows系统中开展实验,其实没有本质差别,代码都是相同的,比如,Python代码,无论在哪种系统中,都是相同的运行方法。
教材中所有用到的软件可以从百度网盘下载:
链接: https://pan.baidu.com/s/1a9sPaOV-8fu0yiD_8Fe-Gg?pwd=ziyu 提取码:ziyu
第1章 概述
本章无实验内容
第2章 实验环境搭建
Python的安装和使用方法
安装Python
Python可以用于多种平台,包括Windows、Linux和macOS等。本书采用的操作系统是Windows 7或以上版本,第2版教材使用的Python版本是3.10.12。请到Python官方网站下载与自己计算机操作系统匹配的安装包,比如,64位Windows操作系统可以下载python-3.10.12-amd64.exe,也可以直接从本网页提供的百度网盘下载(但是,2026年2月作者去Python官网无法下载到该版本的安装包,所以,这里作者在这里给大家提供的是python-3.10.11-amd64.exe,对教材实验没有任何影响)。运行安装包开始安装,在安装过程中,要注意选中“Add python.exe to PATH”复选框,这样可以在安装过程中自动配置PATH环境变量,避免了手动配置的烦琐过程。
Python的使用方法
在Windows中启动进入Python环境的方法是,右键单击开始菜单,在弹出的菜单中点击“运行”,在弹出的对话框中输cmd,就可以打开cmd命令行窗口,在命令行窗口中输入如下命令启动进入Python解释器环境(在里面可以运行Python代码):
> cd C:\python310
> pythonC:\python310表示Python的安装目录,要替换成你自己的安装目录。
如果出现图下图所示信息,则说明Python已经安装成功。
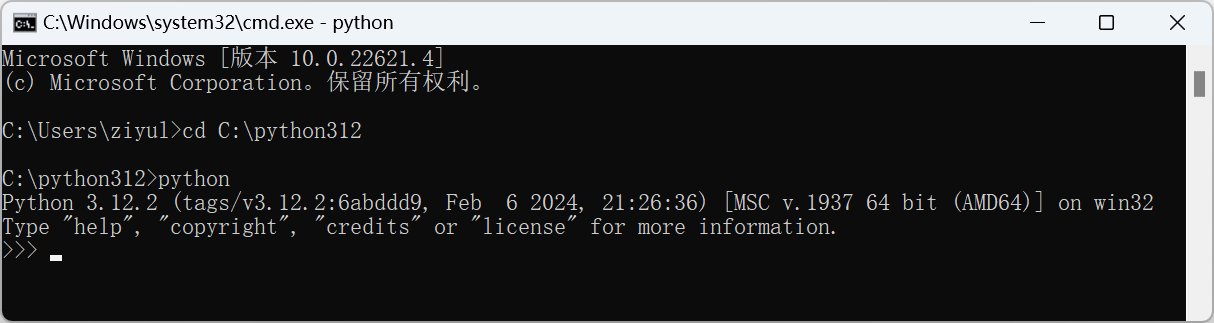
假设在Windows系统的C盘根目录下已经存在一个代码文件hello.py,该文件里面只有如下一行代码:
print("Hello World")
现在我们要运行这个代码文件。可以打开Windows系统的cmd命令界面,并在命令提示符后面输入如下语句:
> python C:\hello.pyPython的当前工作目录是指Python解释器当前正在使用的目录。当运行Python脚本或交互式解释器时,Python解释器会有一个默认的或设置好的当前工作目录,它会在此目录中查找文件或目录。例如,如果尝试打开一个文件而不指定其完整路径,Python解释器会在当前工作目录中查找该文件。
当我们在cmd命令界面中使用“python”命令打开Python解释器时,在哪个目录下执行“python”命令,该目录就会成为Python的当前工作目录,比如,在cmd命令界面中执行如下命令:
> cd C:\
> python这时,进入Python解释器以后,当前工作目录就是“C:\”。
再比如,在cmd命令界面中执行如下命令:
> cd C:\python312
> python这时,进入Python解释器以后,当前工作目录就是“C:\python312”。
进入Python解释器以后,可以使用Python的os模块来查看当前工作目录:
>>> import os
>>> print(os.getcwd())
C:\python312虽然Python的当前工作目录在大多数情况下都是有用的,但在编写可移植和可维护的代码时,最好使用绝对路径或相对于某个固定点的相对路径来引用文件,而不是依赖于当前工作目录。
Python安装成功以后,会自带一个集成式开发环境IDLE,它是一个Python Shell,程序开发人员可以利用Python Shell与Python交互。
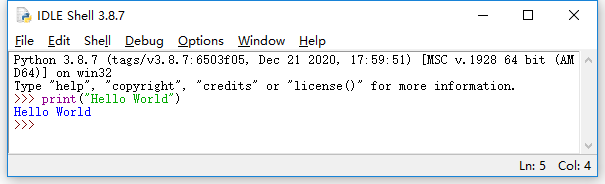
在Windows系统的“开始”菜单中找到“IDLE(Python 3.11 64-bit)”,打开进入IDLE主窗口(如下图所示,注意,下面图片是第1版教材的图片,用的是Python 3.8.7,虽然Python版本不同,但是,用法是一样的),窗口左侧会显示Python命令提示符“>>>”,可以在提示符后面输入Python代码,回车后就会立即执行并返回结果。
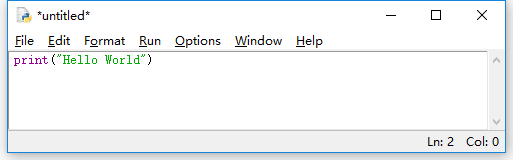
如果要创建一个代码文件,可以在IDLE主窗口的顶部菜单栏中选择“File->New File”,然后就会弹出如下图所示的文件窗口,可以在里面输入Python代码,然后,在顶部菜单栏中选择“File->Save As...”,把文件保存为hello.py。
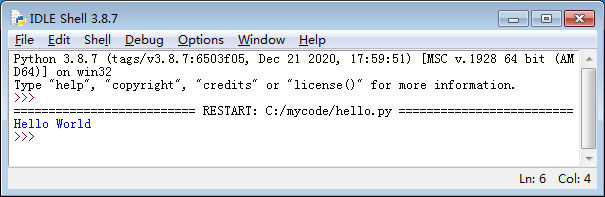
如果要运行代码文件hello.py,可以在IDLE的文件窗口的顶部菜单栏中,选择“Run->Run Module”,这时就会开始运行程序。程序运行结束后,会在IDLE Shell窗口显示执行结果(如下图所示)。
JDK的安装
JDK (Java Development Kit)是整个Java的核心,包括了Java运行环境(Java Runtime Environment)、Java工具和Java基础类库等。要想开发Java程序,就必须安装JDK,因为JDK里面包含了各种Java工具。要想在计算机上运行使用Java语言开发的应用程序,也必须安装JDK,因为JDK里面包含了Java运行环境。本教程中,Kafka、Flume、Hadoop等软件的运行都依赖于Java运行环境,因此,需要在计算机上安装JDK。
访问Oracle官网(https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html)下载JDK安装包(也可以从本网页提供的百度网盘下载),并完成安装。安装完成后需要设置Path环境变量,右键点击“我的电脑”->“高级系统设置”->“环境变量”,然后,在用户变量Path中加入类似如下的信息(百度网盘中的JDK版本应该是jdk1.8.0_281,不是jdk1.8.0_111,你要替换成jdk1.8.0_281):
C:\Program Files\Java\jdk1.8.0_111\bin
这个新添加的值和此前已经存在的值之间用英文分号隔开(如下图所示)。上面的“jdk1.8.0_111”是刚才已经安装的JDK的版本号。
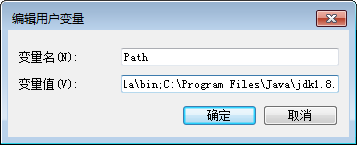
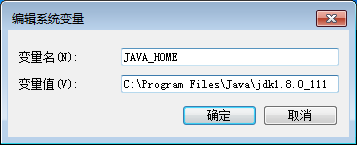
然后,再新建一个环境变量JAVA_HOME,把它的值设置为如下内容(如下图所示):
C:\Program Files\Java\jdk1.8.0_111
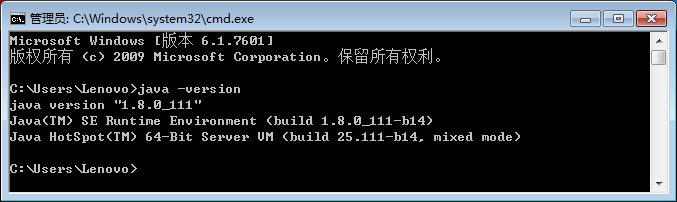
打开cmd窗口,输入“java -version”命令测试是否安装成功,如果安装成功,则会返回如下图所示信息。
安装MySQL数据库
访问如下MySQL官网地址下载安装包(也可以从本网页提供的百度网盘下载):
https://dev.mysql.com/downloads/windows/installer/8.0.html
使用安装包mysql-installer-community-8.0.23.0.msi开始安装,如果在安装过程中提示需要安装“.NET Framework 4.5.2”,则需要到如下网址下载.NET Framework 4.5.2的安装文件NDP452-KB2901907-x86-x64-AllOS-ENU.exe并安装:
https://www.microsoft.com/zh-CN/download/confirmation.aspx?id=42642
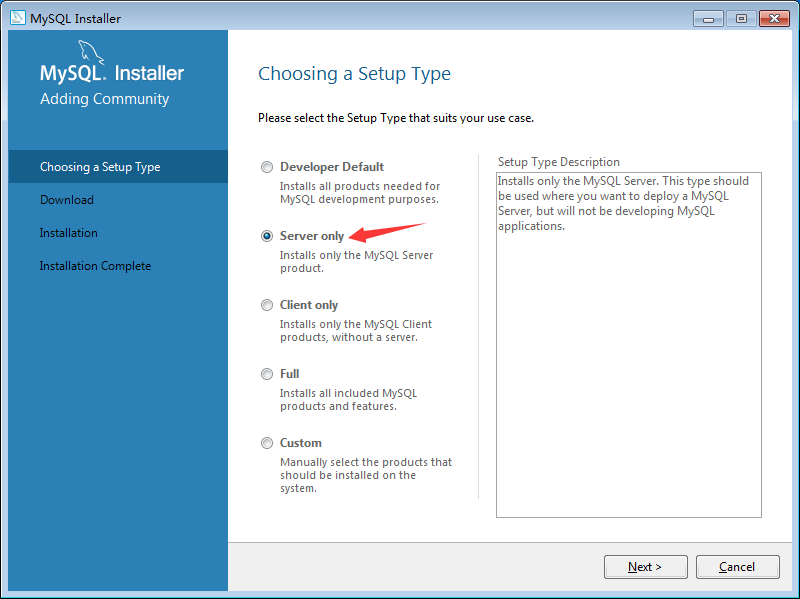
在安装MySQL过程中,当出现“Choosing a Setup Type”界面时,需要选择“Server only”(如下图所示)。
在安装MySQL过程中,如果提示需要安装“Microsoft Visual C++ 2015-2019 Redistributable (x64) – 14.28.29325”时,选择同意安装即可(如下图所示)。
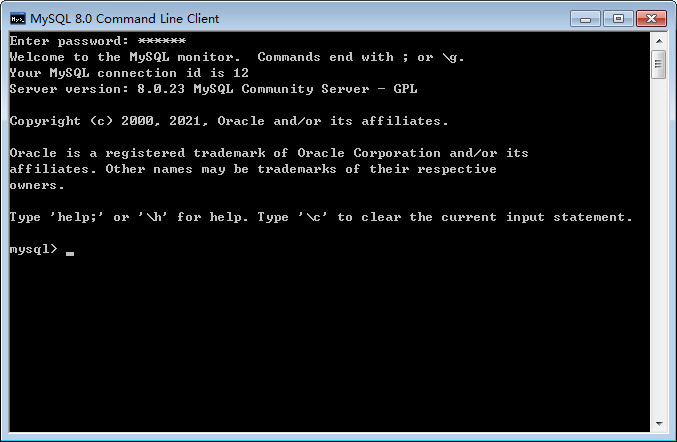
安装完成以后,MySQL数据库的后台服务进程已经被自动启动,这时就需要使用一个客户端工具来操作MySQL数据库,我们可以使用MySQL安装时自带的命令行界面作为客户端工具来操作数据库。具体方法是,在Windows7的开始菜单中点击“MySQL 8.0 Command Line Client”图标,然后输入数据库密码(这个密码是在安装MySQL的过程中用户自己设置的),就会出现如下图所示界面。可以在命令提示符“mysql>”后面输入SQL语句来执行数据库的各种操作。
Hadoop的安装
注意:第2版教材使用的是Hadoop3.3.5,但是,作者在2026年2月无法下载到与3.3.5版配套的winutils,因此,继续使用第1版教材的3.1.3版本Hadoop,不影响实验的正常开展。
这里介绍Hadoop伪分布式模式的安装方法。
到Hadoop官网(https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/)下载Hadoop3.1.3安装文件hadoop-3.1.3.tar.gz。(也可以直接到本网页提供的百度网盘下载)
由于Hadoop不直接支持Windows系统,因此,需要使用工具集winutils进行支持。到github.com网站(https://github.com/s911415/apache-hadoop-3.1.3-winutils)下载与Hadoop3.1.3配套的winutils。(也可以直接到本网页提供的百度网盘下载)
把Hadoop3.1.3安装文件hadoop-3.1.3.tar.gz解压缩到“C:\”(或者其他目录),使用winutils中的bin目录整个替换Hadoop中的bin目录。
在“C:\ hadoop-3.1.3”目录下新建tmp目录,再在tmp目录下新建两个子目录,分别是datanode和namenode。
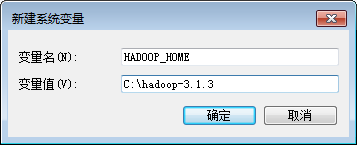
安装完成后需要设置Path环境变量,点击“我的电脑”->“高级系统设置”->“环境变量”,然后,在系统变量中新增一个名称为“HADOOP_HOME”的变量,设置其值为“C:\hadoop-3.1.3”(如下图所示)。
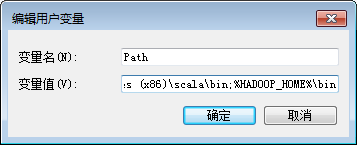
然后,再在用户变量Path中加入如下信息:
%HADOOP_HOME%\bin
注意,新增加的路径和Path中原来已有的路径之间要用英文分号隔开(如下图所示)。
对“C:\ hadoop-3.1.3\etc\hadoop”下面的3个配置文件进行修改。
把core-site.xml文件的配置修改为如下:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>把hdfs-site.xml文件的配置修改为如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/C:/hadoop-3.1.3/tmp/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/C:/hadoop-3.1.3/tmp/datanode</value>
</property>
</configuration>修改hadoop-env.cmd文件,找到如下一行:
set JAVA_HOME=%JAVA_HOME%把%JAVA_HOME%替换成JDK的绝对路径,比如(注意,你的jdk版本应该是jdk1.8.0_281,要替换成你的版本):
set JAVA_HOME=C:\ Java\jdk1.8.0_111需要注意的是,如果JDK路径中包含了空格,如果直接使用如下设置后面步骤会报错:
set JAVA_HOME= C:\Program Files\Java\jdk1.8.0_111如果采用这种带有空格的路径,后面运行“hdfs namenode -format”命令时就会报错,因为Program Files中存在空格。为了解决这个问题,可以使用下面两种方式之一进行处理:
(1)只需要用PROGRA~1 代替Program Files,即改为
C:\PROGRA~1\Java\jdk1.8.0_111(2)或是使用双引号,即改为
“C:\Program Files”\Java\jdk1.8.0_111然后,在Windows系统中打开一个cmd窗口,执行如下命令对Hadoop系统进行格式化:
> cd c:\hadoop-3.1.3\bin
> hdfs namenode -format上述命令执行以后,如果返回类似如下的信息则表示格式化成功:
\hadoop-3.1.3\tmp\namenode has been successfully formatted.执行如下命令启动
> cd c:\hadoop-3.1.3\sbin
> start-dfs.cmd执行该命令以后,会同时弹出另外2个cmd窗口,这2个新弹出的cmd窗口不要关闭,然后,在刚才执行start-dfs.cmd命令的cmd窗口内,继续执行JDK自带的命令jps查看Hadoop已经启动的进程:
> jps需要注意的是,这里在使用jps命令的时候,没有带上绝对路径,是因为已经把JDK添加到了Path环境变量中。
执行jps命令以后,如果能够看到“DataNode”和“NameNode”这两个进程,就说明Hadoop启动成功。
需要关闭Hadoop时,可以执行如下命令:
> cd c:\hadoop-3.1.3\sbin
> stop-dfs.cmdMonoDB的安装
下载MongoDB6.0安装包mongodb-windows-x86_64-6.0.4-signed.msi(可以到本网页提供的百度网盘下载),安装MongoDB数据库服务器。
下载MongoDB Shell安装包mongosh-1.10.6-win32-x64.zip(可以到本网页提供的百度网盘下载),安装MongoDB客户端,用来访问数据库服务器。
启动与验证
(1)作为服务运行:打开 Windows 服务管理器(方法是,右键单击开始菜单,在弹出的菜单中点击“运行”,在弹出的对话框中输入services.msc,点击‘确定’,就可以打开服务管理器),找到MongoDB Serve服务,确保其状态为“正在运行”。
(2)通过命令行运行:或者也可以以管理员身份打开命令提示符(方法是,右键单击开始菜单,在弹出的菜单中点击“运行”,在弹出的对话框中输cmd,就可以打开cmd命令行窗口),输入如下命令 启动数据库服务器:
> mongod --dbpath "C:\data\db"(3)连接数据库:打开新的命令提示符cmd窗口,输入如下命令连接到本地 MongoDB 实例:
mongoshRedis的安装
下载Redis7.0安装文件Redis-7.0.8-Windows-x64.tar.gz(可以到本网页提供的百度网盘下载),把压缩文件解压到到计算机中,得到一个目录Redis-7.0.8-Windows-x64,进入这个目录以后,双击redis-server.exe文件,就可以启动运行Redis数据库。
然后,打开一个cmd窗口(方法是,右键单击开始菜单,在弹出的菜单中点击“运行”,在弹出的对话框中输cmd,就可以打开cmd命令行窗口),输入如下命令启动Redis客户端:
> C:\Users\ziyul\Desktop\d\Redis-7.0.8-Windows-x64>redis-cli注意,上面的命令中,C:\Users\ziyul\Desktop\d\Redis-7.0.8-Windows-x64>,是作者在自己计算机上的Redis安装目录,你要替换成你的安装目录。
如果连接Redis数据库服务器成功,界面上会显示如下信息:
127.0.0.1:6379>你可以在>后面输入Redis操作命令来操作数据库。
第3章 网络数据采集
本章实验都是在Python环境中执行。对于Python代码,是不区分操作系统的,在Linux和Windows中都按照同样的方法执行代码即可。
第4章 分布式消息系统Kafka
安装Kafka
Kafka的运行需要Java环境的支持,因此,需要在Windows系统中安装JDK。请参照第2章内容完成JDK的安装。
访问Kafka官网(http://kafka.apache.org/downloads),下载Kafka3.6.1版本的安装文件kafka_2.12-3.6.1.tgz,解压缩到“C:\”下。
因为Kafka的运行需要依赖于Zookeeper,因此,需要下载并安装Zookeeper。当然,Kafka也内置了Zookeeper服务,因此,也可以不用额外安装Zookeeper,而是直接使用内置的Zookeeper服务。为了简单起见,这里直接使用Kafka内置的Zookeeper服务。
使用Kafka
在Windows系统中打开第1个cmd窗口(方法是,右键单击开始菜单,在弹出的菜单中点击“运行”,在弹出的对话框中输cmd,就可以打开cmd命令行窗口),启动Zookeeper服务:
> cd c:\kafka_2.12-3.6.1
> .\bin\windows\zookeeper-server-start.bat .\config\zookeeper.Properties注意,执行上面命令以后,cmd窗口会返回一堆信息,然后停住不动,没有回到命令提示符状态,这时,不要误以为是死机,而是Zookeeper服务器已经启动,正在处于服务状态。所以,不要关闭这个cmd窗口,一旦关闭,Zookeeper服务就会停止。
打开第2个cmd窗口,然后输入下面命令启动Kafka服务:
> cd c:\kafka_2.12-3.6.1
> .\bin\windows\kafka-server-start.bat .\config\server.properties执行上面命令以后,如果启动失败,并且出现提示信息“此时不应有 \QuickTime\QTSystem\QTJava.zip”,则需要把CLASSPATH环境变量的相关信息删除,具体方法是:右键点击“我的电脑”->“高级系统设置”->“环境变量”,然后,找到CLASSPATH环境变量,把类似如下的信息删除:
C:\Program Files (x86)\QuickTime\QTSystem\QTJava.zip然后重新启动计算机,让配置修改生效。重新启动计算机以后,再次按照上面方法启动Zookeeper和Kafka。
执行上面命令以后,如果启动成功,cmd窗口会返回一堆信息,然后就会停住不动,没有回到命令提示符状态,这时,同样不要误以为是死机,而是Kafka服务器已经启动,正在处于服务状态。所以,不要关闭这个cmd窗口,一旦关闭,Kafka服务就会停止。
为了测试Kafka,这里创建一个主题(Topic),名称为“topic_test”,包含一个分区,只有一个副本,在第3个cmd窗口中执行如下命令:
> cd c:\kafka_2.12-3.6.1
> .\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic topic_test可以继续执行如下命令,查看topic_test是否创建成功:
> .\bin\windows\kafka-topics.bat --list --zookeeper localhost:2181如果创建成功,就可以在执行结果中看到topic_test。
继续在第3个cmd窗口中执行如下命令创建一个生产者来产生消息:
> .\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic topic_test该命令执行以后,屏幕上的光标会一直在闪烁,这时,就可以用键盘输入一些内容,比如输入:
I love Kafka
Kafka is good新建第4个cmd窗口,执行如下命令来消费消息:
> cd c:\kafka_2.12-3.6.1
> .\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic topic_test --from-beginning该命令执行以后,就会在屏幕上看到刚才输入的语句“I love Kafka”和“Kafka is good”。
使用Python操作Kafka
在使用Python操作Kafka之前,需要安装第三方模块kafka-python,打开一个cmd窗口,执行如下命令:
> pip install kafka-python安装结束以后,可以使用如下命令查看已经安装的kafka-python的版本信息:
> pip list执行这个命令后会显示已经安装的Python第三方模块,以及每个模块的版本信息。
剩下的实验内容,和操作系统没有关系,在Linux和Windows系统下都是一样操作,按照教材编写代码进行实验即可。
第5章 日志采集系统Flume
Flume的安装
Flume的运行需要Java环境的支持,因此,需要在Windows系统中安装JDK。请参照第2章内容完成JDK的安装。
访问Flume官网(http://flume.apache.org/download.html),下载Flume安装文件apache-flume-1.11.0-bin.tar.gz。把安装文件解压缩到Windows系统的“C:\”目录下,然后,执行如下命令测试是否安装成功:
> cd c:\apache-flume-1.11.0-bin\bin
> flume-ng version如果能够返回类似如下的信息,则表示启动成功:
Flume 1.11.0
Source code repository: https://git.apache.org/repos/asf/flume.git
Revision: 1a15927e594fd0d05a59d804b90a9c31ec93f5e1
Compiled by rgoers on Sun Oct 16 14:44:15 MST 2022
From source with checksum bbbca682177262aac3a89defde369a37需要设置Flume运行时的日志显示级别。找到“c:\apache-flume-1.11.0-bin\conf\log4j2.xml”这个文件,用记事本打开这个文件,在文件中找到“
<Root level="INFO">
<AppenderRef ref="Console" />
<AppenderRef ref="LogFile" />
</Root>在上面的配置信息中,“
Flume的使用
1.实例1:采集NetCat数据显示到控制台
这里给出一个简单的实例,假设Source为NetCat类型,使用Telnet连接Source写入数据,产生日志数据输出到控制台(屏幕)。下面首先介绍操作系统Windows7中的操作方法,然后再介绍Windows10中的操作方法。
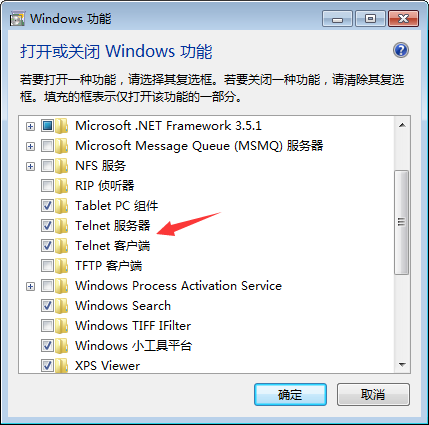
为了顺利完成后面的测试,首先开启Windows7的telnet服务。具体方法是,打开“控制面板”,进入“默认程序”,在出现的界面的左侧底部点击“程序和功能”,再在出现的界面的左侧顶部点击“打开或关闭Windows功能”,会出现如下图所示的界面,把“Telnet服务器”和“Telnet客户端”都选中,然后点击“确定”按钮。
在Flume安装目录的conf子目录下,新建一个名称为example.conf的配置文件,该文件的内容如下:
# 设置Agent上的各个组件名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 配置Source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 配置Sink
a1.sinks.k1.type = logger
# 配置Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 把Source和Sink绑定到Channel上
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1在这个配置文件中,设置了Source类型为netcat,Channel类型为memory,Sink的类型为logger。
然后,新建一个cmd窗口(称为“Flume窗口”),并执行如下命令:
> cd c:\apache-flume-1.9.0-bin
> .\bin\flume-ng agent --conf .\conf --conf-file .\conf\example.conf --name a1 -property flume.root.logger=INFO,console再新建一个cmd窗口,并执行如下命令:
> telnet localhost 44444这时就可以从键盘输入一些英文单词,比如“Hello World”,切换到Flume窗口,就可以看到屏幕上显示了“Hello World”(如下图所示),说明Flume成功地接收到了信息。

2.采集目录下的数据显示到控制台
假设Windows系统中有一个目录“C:\mylogs”,这个目录下不断有新的文件生成,使用Flume采集这个目录下的文件,并把文件内容显示到控制台(屏幕)。
在Flume安装目录的conf子目录下,新建一个名称为example1.conf的配置文件,该文件的内容如下:
#定义三大组件名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#定义Source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = C:/mylogs/
#定义Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 100
#定义Sink
a1.sinks.k1.type = logger
#组装Source、Channel、Sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1清空“C:\mylogs”目录(即删除该目录下的所有内容),然后新建一个cmd窗口(称为“Flume窗口”),并执行如下命令:
> cd c:\apache-flume-1.11.0-bin
> .\bin\flume-ng agent --conf .\conf --conf-file .\conf\example1.conf --name a1 -property flume.root.logger=INFO,console然后,在“C:\”目录下新建一个文件mylog.txt,里面输入一些内容,比如“I love Flume”,保存该文件,并把该文件复制到“C:\mylogs”目录下,可以看到,mylog.txt很快会变成mylog.txt.COMPLETED,这时,在Flume窗口中就可以看到mylog.txt中的内容,比如“I love Flume”。Flume和Kafka的组合使用
在Windows系统中打开第1个cmd窗口,执行如下命令启动Zookeeper服务:
> cd c:\kafka_2.12-2.4.0
> .\bin\windows\zookeeper-server-start.bat .\config\zookeeper.Properties打开第2个cmd窗口,然后执行下面命令启动Kafka服务:
> cd c:\kafka_2.12-2.4.0
> .\bin\windows\kafka-server-start.bat .\config\server.properties打开第3个cmd窗口,执行如下命令创建一个名为test的Topic:
> cd c:\kafka_2.12-2.4.0
> .\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test在Flume的安装目录的conf子目录下创建一个配置文件kafka.conf,内容如下:# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = test
a1.sinks.k1.kafka.bootstrap.servers = localhost:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.k1.kafka.producer.compression.type = snappy
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1打开第4个cmd窗口,执行如下命令启动Flume:
> cd c:\apache-flume-1.11.0-bin
> .\bin\flume-ng.cmd agent --conf ./conf --conf-file ./conf/kafka.conf --name a1 -property flume.root.logger=INFO,console打开第5个cmd窗口,执行如下命令:
> telnet localhost 44444执行上面命令以后,在该窗口内用键盘输入一些单词,比如“hadoop”。这个单词会发送给Flume,然后,Flume发送给Kafka。
打开第6个cmd窗口,执行如下命令:
> cd c:\kafka_2.12-3.6.1
> .\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning上面命令执行以后,就可以在屏幕上看到“hadoop”,说明Kafka成功接收到了数据。
采集目录到HDFS
采集需求是某服务器的某特定目录下(比如“C:\mylog”),会不断产生新的文件,每当有新文件出现,就需要把文件采集到HDFS中去。
在Flume安装目录的conf子目录下,编写一个配置文件spooldir_hdfs.conf,其内容如下:
#定义三大组件的名称
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
# 配置Source组件
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = C:/mylogs/
agent1.sources.source1.fileHeader = false
# 配置Sink组件
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path =hdfs://localhost:9000/weblog/%y-%m-%d/%H-%M
agent1.sinks.sink1.hdfs.filePrefix = access_log
agent1.sinks.sink1.hdfs.maxOpenFiles = 5000
agent1.sinks.sink1.hdfs.batchSize= 100
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat =Text
agent1.sinks.sink1.hdfs.rollSize = 102400
agent1.sinks.sink1.hdfs.rollCount = 1000000
agent1.sinks.sink1.hdfs.rollInterval = 60
#agent1.sinks.sink1.hdfs.round = true
#agent1.sinks.sink1.hdfs.roundValue = 10
#agent1.sinks.sink1.hdfs.roundUnit = minute
agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
# 设置Channel
agent1.channels.channel1.type = memory
agent1.channels.channel1.keep-alive = 120
agent1.channels.channel1.capacity = 500000
agent1.channels.channel1.transactionCapacity = 600
# 把Source和Sink绑定到Channel上
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1为了让Flume能够顺利访问HDFS,需要把Flume安装目录下的lib子目录下的guava-11.0.2.jar文件删除,然后,把Hadoop安装目录下的“share\hadoop\common\lib”目录下的guava-27.0-jre.jar文件复制到Flume安装目录下的lib子目录下。
在Windows系统中,新建一个cmd窗口,使用如下命令启动Hadoop的HDFS:
> cd c:\hadoop-3.1.3\sbin
> start-dfs.cmd执行JDK自带的命令jps查看Hadoop已经启动的进程:
> jps需要注意的是,这里在使用jps命令的时候,没有带上绝对路径,是因为已经把JDK添加到了Path环境变量中。
执行jps命令以后,如果能够看到“DataNode”和“NameNode”这两个进程,就说明Hadoop启动成功。
再新建一个cmd窗口,执行如下命令启动Flume:
> cd c:\apache-flume-1.11.0-bin
> .\bin\flume-ng agent --conf .\conf --conf-file .\conf\spooldir_hdfs.conf --name agent1 -property flume.root.logger=INFO,console执行上述命令以后,Flume就被启动了,开始实时监控“C:/mylogs/”目录,只要这个目录下有新的文件生成,就会被Flume捕捉到,并把文件内容保存到HDFS中。在C盘根目录下新建一个文本文件mylog1.txt,里面写入一些句子,比如“This is mylog1”,然后,把mylog1.txt文件复制到“C:\mylog”目录下,过一会儿,就会看到mylog1.txt文件名被修改成了mylog4.txt.COMPLETED,说明该文件已经成功被Flume捕捉到。可以在HDFS的WEB管理页面中(http://localhost:9870)查看生成的文件及其内容。
采集文件到HDFS
采集需求是某服务器的某特定目录下的文件(比如“C:\mylog\log1.txt”),会不断发生更新,每当文件被更新时,就需要把更新的数据采集到HDFS中去。
在Flume安装目录的conf子目录下,编写一个配置文件exec_hdfs.conf,其内容如下:
#定义三大组件的名称
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
# 配置Source组件
agent1.sources.source1.type = exec
agent1.sources.source1.command = tail -F C:/mylogs/log1.txt
agent1.sources.source1.channels = channel1
# 配置Sink组件
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path =hdfs://localhost:9000/weblog/%y-%m-%d/%H-%M
agent1.sinks.sink1.hdfs.filePrefix = access_log
agent1.sinks.sink1.hdfs.maxOpenFiles = 5000
agent1.sinks.sink1.hdfs.batchSize= 100
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat =Text
agent1.sinks.sink1.hdfs.rollSize = 102400
agent1.sinks.sink1.hdfs.rollCount = 1000000
agent1.sinks.sink1.hdfs.rollInterval = 60
#agent1.sinks.sink1.hdfs.round = true
#agent1.sinks.sink1.hdfs.roundValue = 10
#agent1.sinks.sink1.hdfs.roundUnit = minute
agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
# 配置Channel组件
agent1.channels.channel1.type = memory
agent1.channels.channel1.keep-alive = 120
agent1.channels.channel1.capacity = 500000
agent1.channels.channel1.transactionCapacity = 600
# 把Source和Sink绑定到Channel
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1在上面的配置文件中,有一行内容如下:
agent1.sources.source1.command = tail -F C:/mylogs/log1.txt在这个配置信息中,使用了tail命令,Windows系统没有自带tail命令,因此,需要单独安装。可以到网络查找tail.exe文件,或者直接到教材官网的“下载专区”的“软件”目录中下载tail.zip文件,解压缩生成tail.exe文件,再把tail.exe文件复制到“C:\Windows\System32”目录下,然后,可以测试一下该命令的效果。首先新建一个文件“C:\mylog\log1.txt”,文件内容可以为空,然后,打开一个cmd窗口(这里称为“tail窗口”),输入如下命令:
> tail -f c:\mylogs\log1.txt然后,用记事本打开log1.txt,向里面输入一些内容(比如“I love Flume”)并且保存文件,这时,tail窗口内就会显示刚刚输入到log1.txt中的这些内容。
再新建一个cmd窗口,启动HDFS,然后执行如下命令启动Flume:
> cd c:\apache-flume-1.11.0-bin
> .\bin\flume-ng agent --conf .\conf --conf-file .\conf\exec_hdfs.conf --name agent1 -property flume.root.logger=INFO,console执行上述命令以后,Flume就被启动了,开始实时监控“C:/mylogs/log1.txt”文件,只要这个文件发生了内容更新,就会被Flume捕捉到,并把更新内容保存到HDFS中。作为测试,可以在log1.txt文件中输入一些内容,然后到HDFS的WEB管理页面中(http://localhost:9870)查看生成的文件及其内容。
采集MySQL数据到HDFS
准备工作
如果已经完成下面的准备工作,则不需要重复操作。
在采集MySQL数据库中的数据到MySQL时,需要用到一个第三方JAR包,即flume-ng-sql-source-1.5.3.jar。这个JAR包可以直接到本网页提供的百度网盘中下载。此外,为了让Flume能够顺利连接MySQL数据库,还需要用到一个连接驱动程序JAR包,可以直接到本书官网的“下载专区”的“软件”目录中下载mysql-connector-java-8.0.30.jar。然后,把flume-ng-sql-source-1.5.3.jar和mysql-connector-java-8.0.30.jar这两个文件复制到Flume安装目录的lib子目录下(比“C:\apache-flume-1.11.0-bin\lib”)。
此外,为了让Flume能够顺利连接MySQL数据库,还需要用到一个连接驱动程序JAR包。可以访问MySQL官网(https://dev.mysql.com/downloads/connector/j/?os=26)下载驱动程序压缩文件mysql-connector-java-8.0.30.tar.gz(也可以到教材官网下载),然后,对该压缩文件进行解压缩,在解压后的目录中,找到文件mysql-connector-java-8.0.30.jar,把这个文件复制到Flume安装目录的lib子目录下(比如“C:\apache-flume-1.11.0-bin\lib”)。
创建MySQL数据库
参照第2章中关于MySQL数据库的内容,完成MySQL的安装,并学习其基本使用方法,这里假设读者已经成功安装了MySQL数据库并掌握了基本的使用方法。在Windows系统中,启动MySQL服务进程,然后,打开MySQL的命令行客户端,执行如下SQL语句创建数据库和表:
mysql>CREATE DATABASE school;
mysql> USE school;
mysql> CREATE TABLE student(
-> id INT NOT NULL,
-> name VARCHAR(40),
-> age INT,
-> grade INT,
-> PRIMARY KEY (id));需要注意的是,在创建表的时候,一定要设置一个主键(比如,这里id是主键),否则后面Flume会捕捉数据失败。
创建好MySQL数据库以后,再执行如下命令启动Hadoop的HDFS:
> cd c:\hadoop-3.1.3\sbin
> start-dfs.cmd执行JDK自带的命令jps查看Hadoop已经启动的进程:
> jps执行jps命令以后,如果能够看到“DataNode”和“NameNode”这两个进程,就说明Hadoop启动成功。
配置和启动Flume
根据需求,首先定义以下3大要素:
Source:因为要监控MySQL数据库,所以Souce的类型是org.keedio.flume.source.SQLSource;
Sink:因为要把文件采集到HDFS中,所以,Sink的类型是hdfs;
Channel:Channel的类型可以设置为memory。
在Flume安装目录的conf子目录下,编写一个配置文件mysql_hdfs.conf,其内容如下:
#设置三大组件
agent1.channels = ch1
agent1.sinks = HDFS
agent1.sources = sql-source
#设置Source组件
agent1.sources.sql-source.type = org.keedio.flume.source.SQLSource
agent1.sources.sql-source.hibernate.connection.url = jdbc:mysql://localhost:3306/school
agent1.sources.sql-source.hibernate.connection.user = root #数据库用户名
agent1.sources.sql-source.hibernate.connection.password = 123456 #数据库密码
agent1.sources.sql-source.hibernate.connection.autocommit = true
agent1.sources.sql-source.table = student #数据库中的表名称
agent1.sources.sql-source.run.query.delay=5000
agent1.sources.sql-source.status.file.path = C:/apache-flume-1.9.0-bin/
agent1.sources.sql-source.status.file.name = sql-source.status
#设置Sink组件
agent1.sinks.HDFS.type = hdfs
agent1.sinks.HDFS.hdfs.path = hdfs://localhost:9000/flume/mysql
agent1.sinks.HDFS.hdfs.fileType = DataStream
agent1.sinks.HDFS.hdfs.writeFormat = Text
agent1.sinks.HDFS.hdfs.rollSize = 268435456
agent1.sinks.HDFS.hdfs.rollInterval = 0
agent1.sinks.HDFS.hdfs.rollCount = 0
#设置Channel
agent1.channels.ch1.type = memory
#把Source和Sink绑定到Channel
agent1.sinks.HDFS.channel = ch1
agent1.sources.sql-source.channels = ch1在配置文件mysql_hdfs.conf中,有如下两行:
agent1.sources.sql-source.status.file.path = C:/apache-flume-1.11.0-bin/
agent1.sources.sql-source.status.file.name = sql-source.status这两行设置了Flume状态信息的保存位置,即保存在“C:/apache-flume-1.11.0-bin/”目录下的“sql-source.status”这个文件中。需要重点强调的是,sql-source.status这个文件一定不要自己创建(如果自己创建,启动Flume时会报错),Flume在启动过程中会自动创建这个文件。如果已经存在sql-source.status这个文件,也要删除。
在配置文件mysql_hdfs.conf中,还有如下一行:
agent1.sinks.HDFS.hdfs.path = hdfs://localhost:9000/flume/mysql这行配置信息设置了数据在HDFS中的保存目录。需要注意的是,这个目录不需要自己创建,Flume会自动在HDFS中创建该目录。
下面执行如下命令启动Flume:
> cd c:\apache-flume-1.11.0-bin
> .\bin\flume-ng agent --conf .\conf --conf-file .\conf\mysql_hdfs.conf --name agent1 -property flume.root.logger=INFO,console执行上述命令以后,Flume就被启动了,一定要注意启动过程中的返回信息,看看是否有返回错误信息,当返回的信息中没有包含任何错误信息时,就表示启动成功了。
然后,在MySQL命令行客户端中执行如下语句向MySQL数据库中插入数据:
mysql> insert into student(id,name,age,grade) values(1,'Xiaoming',23,98)
mysql> insert into student(id,name,age,grade) values(2,'Zhangsan',24,96);
mysql> insert into student(id,name,age,grade) values(3,'Lisi',24,93);到“C:/apache-flume-1.11.0-bin/”目录下查看“sql-source.status”这个文件,这个文件会包含类似如下的信息:
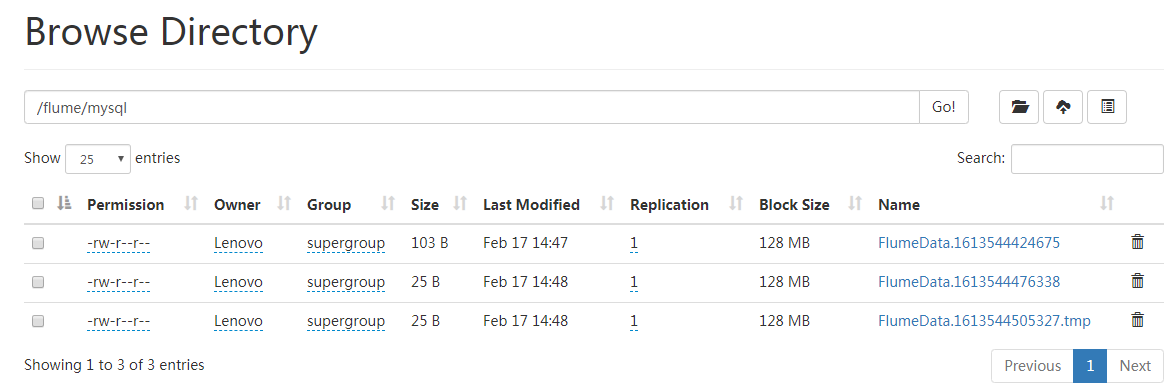
{"SourceName":"sql-source","URL":"jdbc:mysql:\/\/localhost:3306\/school","LastIndex":"3","ColumnsToSelect":"*","Table":"student"}在浏览器中输入网址“http://localhost:9870”打开Hadoop的WEB管理界面(如下图所示),就可以看到新生成的文件。
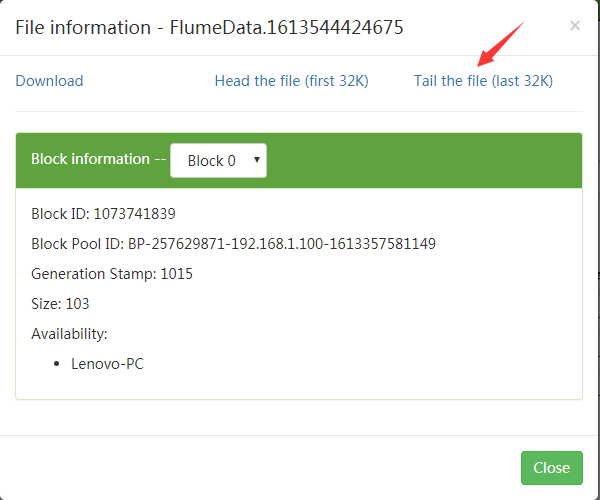
打开其中一个文件(如下图所示)。
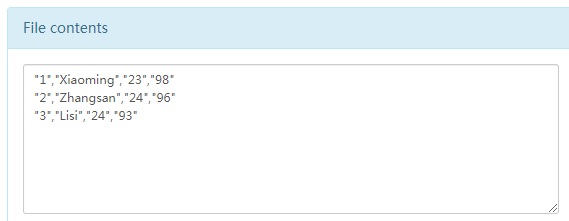
在出现的页面中点击“Tail the file(last 32K)”,就会显示文件的内容(如下图所示)。
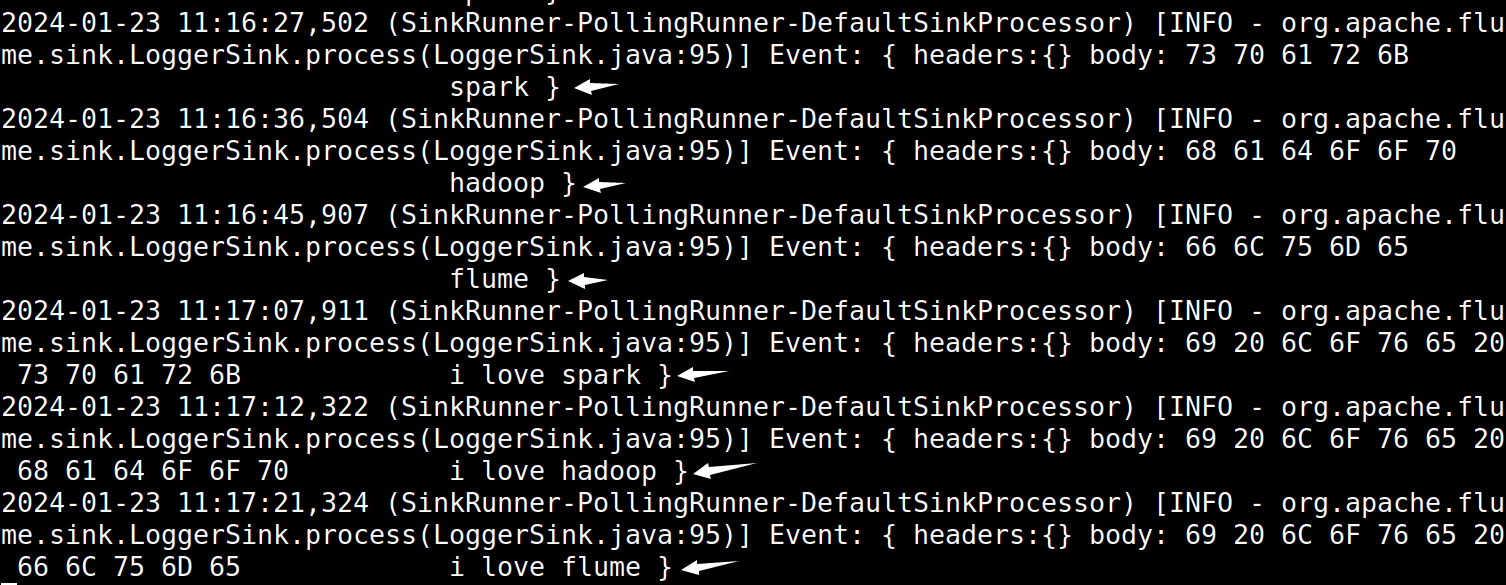
Flume多数据源应用实例
这个实验请自己参照上面的方法修改为Windows系统中可以跑通的代码。
第7章 ETL工具Kettle
在Windows系统中打开浏览器,访问Kettle官网(https://sourceforge.net/projects/pentaho/),下载Kettle安装文件pdi-ce-9.1.0.0-324.zip。或者,也可以直接到本网页提供的百度网盘中下载pdi-ce-9.1.0.0-324.zip文件。
把pdi-ce-9.1.0.0-324.zip解压缩到“D:\”目录下(或者也可以选择一个其他目录,比如“C:\”),会生成一个“data-integration”目录,该目录下就包含了Kettle。在data-integration目录里包含了Spoon的启动文件,即spoon.bat,双击该文件就可以启动Spoon,启动界面如图所示。
启动成功以后,操作方法和操作系统没有关系,在Windows和Linux系统中都是一样操作,按照第2版教材操作即可,需要注意的是,两种操作系统中,文件路径的表示方法不同,要注意修改文件路径的写法。
第8章 使用pandas进行数据清洗
第8章实验都是Python代码,和操作系统没有关系,在Windows和Linux系统中都是一样的代码,请按照第2版教材操作。