
【版权声明】版权所有,严禁转载,严禁用于商业用途,侵权必究。
作者:厦门大学计算机科学与技术系2023级研究生 黄万嘉
指导老师:厦门大学数据库实验室 林子雨 博士/副教授
时间:2024年6月
相关教材:林子雨、郑海山、赖永炫编著《Spark编程基础(Python版,第2版)》(访问教材官网)
相关案例:基于Python语言的Spark数据处理分析案例集锦(PySpark)
数据集和代码下载:从百度网盘下载本案例数据集和代码。(提取码是ziyu)
一、实验目的
本实验旨在通过应用大数据处理技术,对Kaggle社区提供的PUBG游戏统计数据集进行深入分析。实验的主要目标包括:
1.在Ubuntu 18.04操作系统上部署Hadoop 3.1.3和Spark 2.4.0环境,为大数据处理提供基础设施。
- 下载并预处理PUBG Finish Placement Prediction数据集,以适应实验需求并准备数据进行分析。
- 利用Python编程语言和Spark框架,对处理后的数据集进行探索性数据分析,以理解玩家在游戏中的表现和行为模式。
- 分析玩家击杀数、伤害量、移动行为和物品使用情况等关键指标,以及它们与比赛结果之间的关系。
- 通过数据可视化技术,将分析结果以图形化的方式展现出来,帮助更直观地理解PUBG玩家的行为特征和游戏模式。
二、实验环境
(1)Linux:Ubuntu 18.04
(2)Hadoop3.1.3
(3)Python:3.7
(4)Spark:3.4.0三、数据集
3.1 数据集下载
本次实验数据集来源Kaggle社区的“PUBG Finish Placement Prediction”数据集,下载链接为:数据集源自PUBG游戏的统计数据,旨在构建一个模型来预测玩家在每场比赛中的最终排名。数据集包含了从个人玩家到整个团队的详细游戏后统计信息,格式为CSV文件,每个玩家的统计信息占据一行。下面是数据集各字段的含义:
DBNOs - 击倒敌人玩家的数量。示例:3, 5。
assists - 对队友击杀敌人有助攻的次数。示例:1, 0。
boosts - 使用的增益物品数量。示例:2, 5。
damageDealt - 造成的总伤害量(扣除了对自身的伤害)。示例:500, 300。
headshotKills - 爆头击杀敌人的数量。示例:2, 1。
heals - 使用的治疗物品数量。示例:3, 1。
Id - 玩家的唯一标识符。示例:101, 202。
killPlace - 根据击杀敌人数量的排名。示例:5, 1。
killPoints - 基于击杀的排名分数(如果rankPoints不是-1,则0应视为“无”)。示例:120, -1。
killStreaks - 最大连杀数。示例:3, 1。
kills - 击杀敌人的总数。示例:3, 7。
longestKill - 击杀时与敌人的最远距离。示例:200米,100米。
matchDuration - 比赛持续的时间(秒)。示例:1800, 2400。
matchId - 比赛的唯一标识符。示例:match_101, match_202。
matchType - 比赛模式,如“solo”、“duo”、“squad”。示例:solo, squad。
rankPoints - Elo评分系统中的排名分数(-1表示“无”)。示例:240, -1。
revives - 复活队友的次数。示例:1, 0。
rideDistance - 乘坐载具的总距离(米)。示例:500米,1000米。
roadKills - 在载具中击杀敌人的数量。示例:2, 0。
swimDistance - 游泳的总距离(米)。示例:20米,50米。
teamKills - 意外击杀队友的次数。示例:0, 1。
vehicleDestroys - 摧毁的载具数量。示例:1, 3。
walkDistance - 步行的总距离(米)。示例:1000米,800米。
weaponsAcquired - 拾取的武器数量。示例:4, 6。
winPoints - 基于胜利的排名分数(如果rankPoints不是-1,则0应视为“无”)。示例:100, -1。
groupId - 队伍的唯一标识符。示例:group_101, group_202。
numGroups - 比赛中记录的参赛队伍数量。示例:20, 30。
maxPlace - 比赛中记录的最差排名。示例:21, 35。
winPlacePerc - 预测目标,即比赛的百分位排名,1代表第一名,0代表最后一名。示例:0.95, 0.5。
3.2 数据预处理
本次实验采用pandas库对数据进行预处理,由于实验要求限制,原数据集(628MB)不符合数据集要求,采用随机删减数据的方式,缩减数据集规模,使用的代码shuffle.py如下:
import pandas as pd
# 加载CSV文件
df = pd.read_csv('train.csv')
# 计算需要删除的行数
current_size = 600 # 当前文件大小(MB)
target_size = 50 # 目标文件大小(MB)
rows_to_delete = len(df) * (current_size - target_size) / current_size
# 随机选择行进行删除
rows_to_delete = int(rows_to_delete)
if rows_to_delete > 0:
df_to_drop = df.sample(n=rows_to_delete, random_state=1)
df = df.drop(df_to_drop.index)
# 保存新的CSV文件
df.to_csv('smaller_train.csv', index=False)删减完成后,对数据集进行预处理。在数据预处理中,对数据集进行重复值处理及缺失值处理,之后保存数据集:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('smaller_train.csv')
# 检查重复值
print("检查重复值")
print(df[df.duplicated()])
# 缺失值处理
# 检查缺失值
print(df.isnull().sum())
# 填充缺失值,这里使用列的均值来填充数值型数据
df.fillna(df.mean(), inplace=True)
# 对于非数值型数据,使用众数来填充
df.fillna(df.mode().iloc[0], inplace=True)
df.to_csv("train_final.csv")得到清洗完成的数据集,将其写入HDFS中:
# 启动Hadoop
cd /usr/local/hadoop
./sbin/start-dfs.sh
# 在HDFS文件系统中创建目录
./bin/hdfs dfs -mkdir /data
# 上传文件到HDFS文件系统中
./bin/hdfs dfs -put ~/PycharmProjects/PUBG/train_final.csv /data/data.csv
四、使用Spark对数据处理分析
我将采用Python编程语言和Spark大数据框架对数据集“data.csv”进行处理分析,具体步骤如下:
1.分析玩家在游戏中的击杀数
对于PUBG游戏而言,玩家的击杀数是很重要的数据,可以直观反映玩家的游戏水平。因此先分析平均击杀/最高击杀/99%玩家的击杀数,代码如下:
from pyspark import SparkContext
from pyspark.sql import SparkSession, SQLContext
from pyspark.sql.functions import percentile_approx, mean, max
from pyspark.sql.types import IntegerType
import matplotlib.pyplot as plt
import seaborn as sns
# 初始化SparkContext和SparkSession
sc = SparkContext('local', 'spark_project')
sc.setLogLevel('WARN') # 减少不必要的 LOG 输出
sqlContext = SQLContext(sc)
spark = SparkSession(sc)
# 读取CSV文件并创建Dataframe
df = spark.read \
.format("csv") \
.option("header", "true") \
.load("hdfs://localhost:9000/data/data_train.csv")
print(df.schema)
df.show(5)
df = df.withColumn("kills", df["kills"].cast(IntegerType())) # 确保kills列是整数类型
# 统计平均击杀
average_kills = df.select(mean("kills")).collect()[0][0]
# 统计最多击杀
max_kills = df.select(max("kills")).collect()[0][0]
# 统计99%玩家的击杀数
kills_99th_percentile = df.selectExpr("percentile_approx(kills, 0.99)").collect()[0][0]
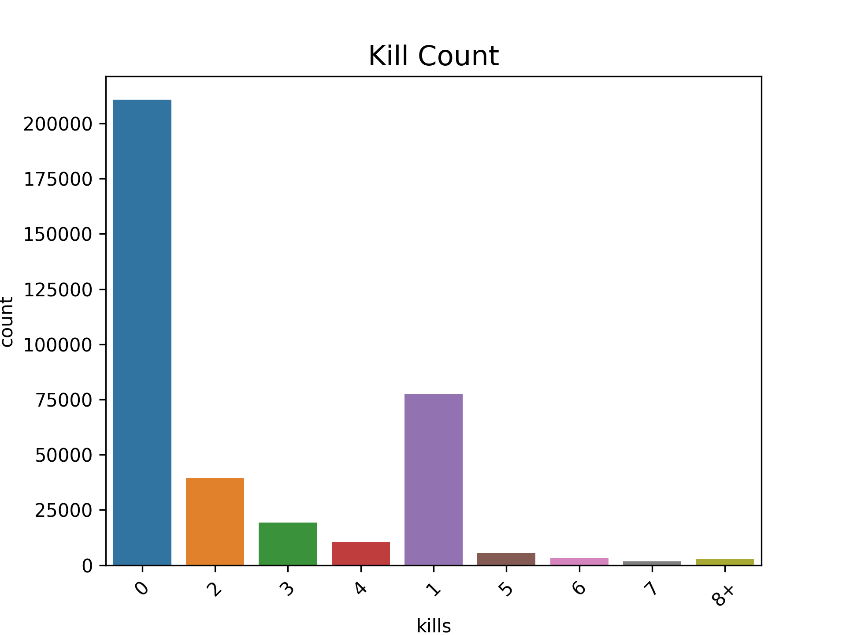
print(f"平均击杀为 {average_kills:.4f} , 99% 的玩家击杀了 {kills_99th_percentile} 或以下, 最高的击杀记录为 {max_kills}.")
# 将Spark DataFrame转换为Pandas DataFrame
pandas_df = df.select("kills").toPandas()
# 使用apply方法替换超过99%分位数的击杀数为'8+'
pandas_df['kills'] = pandas_df['kills'].apply(lambda x: '8+' if x > kills_99th_percentile else x)
# 使用Seaborn进行绘图
# 由于kills列现在包含字符串,我们需要将其转换为字符串类型以确保正确绘图
sns.countplot(x=pandas_df['kills'].astype(str))
plt.title("Kill Count", fontsize=15)
plt.xticks(rotation=45)
plt.savefig('kill_count_plot.png', format='png', dpi=300)
plt.show()输出结果为:平均击杀为 0.9228 , 99% 的玩家击杀了 7 或以下,最高的击杀记录为 56。输出的图片结果如下,可以看到,大部分人在比赛里没有击杀,其次是击杀了一个人,这也很好的反应了该款游戏的难度。
既然大部分玩家在一局对局里面无法实现一次击杀,我们继续分析他们是否造成了伤害。
df = df.withColumn("damageDealt", df["damageDealt"].cast(FloatType()))
# 过滤出kills为0的行
df_zero_kills = df.filter(df["kills"] == 0)
# 将过滤后的Spark DataFrame转换为Pandas DataFrame
pandas_df_zero_kills = df_zero_kills.select("damageDealt").toPandas()
# 使用Seaborn进行分布图绘制
plt.figure(figsize=(15,10))
plt.title("Damage Dealt by 0 Killers", fontsize=15)
sns.histplot(pandas_df_zero_kills['damageDealt'], kde=False) # 使用histplot代替distplot,因为distplot在新版Seaborn中已被弃用
plt.xlabel("Damage Dealt")
plt.ylabel("Frequency")
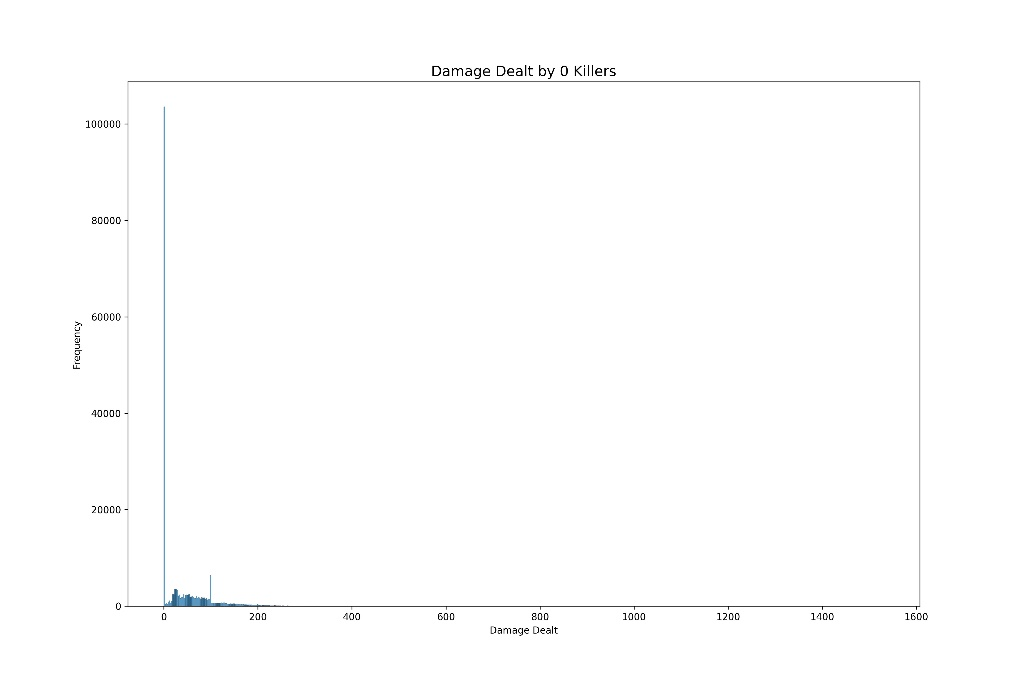
plt.savefig('damage_dealt_by_0_killers.png', format='png', dpi=300)结果如下图所示,可以看到,大部分0击杀的玩家,造成了0伤害,也就是一枪不开或者开了都没中,就被击败。
2.分析玩家在游戏中的移动行为
PUBG游戏中,玩家可以步行或者使用载具,我们先来分析玩家在每局游戏中的步行行为。代码如下:
df = df.withColumn("walkDistance", df["walkDistance"].cast(FloatType())) # 确保walkDistance列是浮点数类型
# 计算walkDistance的99%分位数
walkDistance_99th_percentile = df.selectExpr("percentile_approx(walkDistance, 0.99)").collect()[0][0]
# 筛选出walkDistance小于99%分位数的行
df_walkDistance_less_99th = df.filter(col("walkDistance") < walkDistance_99th_percentile)
# 将筛选后的Spark DataFrame转换为Pandas DataFrame
pandas_df_walkDistance = df_walkDistance_less_99th.select("walkDistance").toPandas()
# 使用matplotlib和seaborn进行分布图绘制
plt.figure(figsize=(15,10))
plt.title("Walking Distance Distribution", fontsize=15)
sns.histplot(pandas_df_walkDistance['walkDistance'], kde=False) # 使用histplot代替distplot,因为distplot在新版Seaborn中已被弃用
plt.xlabel("Walking Distance")
plt.ylabel("Frequency")
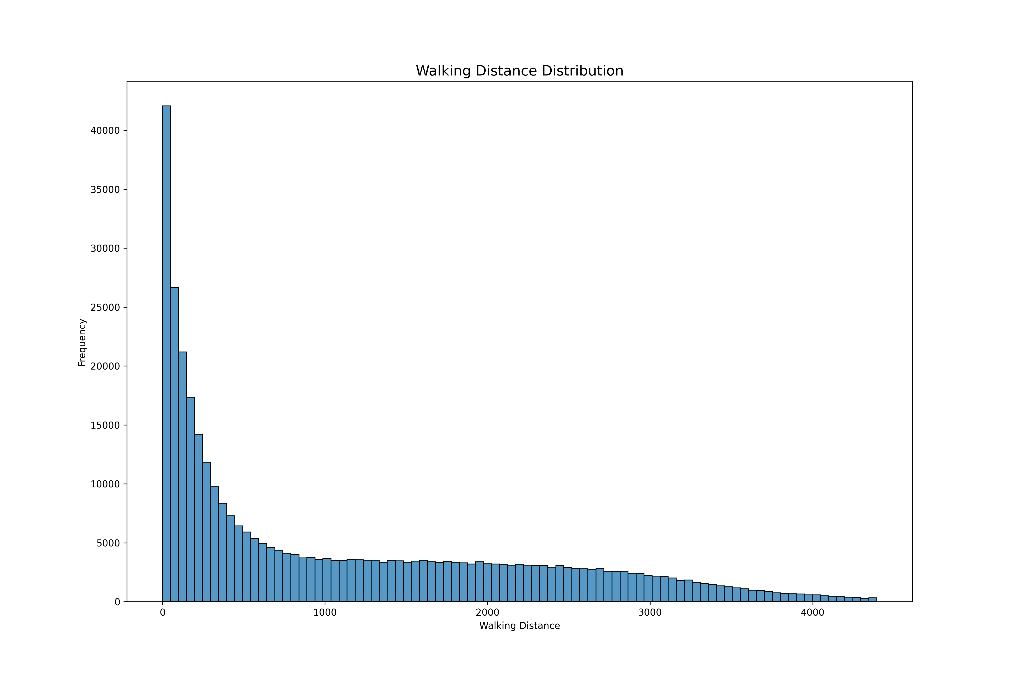
plt.savefig('walking_distance_distribution.png', format='png', dpi=300)得到下图,可以看出相当一部分玩家步行距离 < 100m,表明他们跳伞落地就被击杀或者直接就挂机了。
分析玩家的载具行为,代码如下:
# 计算rideDistance的平均值、99%分位数和最大值
average_ride_distance = df.select(mean("rideDistance")).collect()[0][0]
ride_distance_99th_percentile = df.selectExpr("percentile_approx(rideDistance, 0.99)").collect()[0][0]
max_ride_distance = df.select(max("rideDistance")).collect()[0][0]
# 打印统计信息
print(f"平均载具行驶距离为 {average_ride_distance:.1f}m, 99% 的玩家行驶了 {ride_distance_99th_percentile}m 或更少, 行驶距离最远的玩家行驶 {max_ride_distance}m.")
# 筛选出rideDistance小于99%分位数的行
df_ride_distance_less_99th = df.filter(df["rideDistance"] < ride_distance_99th_percentile)
# 将筛选后的Spark DataFrame转换为Pandas DataFrame
pandas_df_ride_distance = df_ride_distance_less_99th.select("rideDistance").toPandas()
plt.figure(figsize=(15,10))
plt.title("Ride Distance Distribution", fontsize=15)
sns.histplot(pandas_df_ride_distance['rideDistance'], kde=False)
plt.xlabel("Ride Distance (m)")
plt.ylabel("Frequency")
plt.savefig('ridding_distacne.png', format='png', dpi=300)
plt.show()
# 计算rideDistance为0的人数及其占总人数的百分比
count_zero_ride_distance = df.filter(df["rideDistance"] == 0).count()
total_count = df.count()
percentage_zero_ride_distance = (count_zero_ride_distance / total_count) * 100
print(f"{count_zero_ride_distance} 位玩家 ({percentage_zero_ride_distance:.4f}%) 行驶了 0 米. 他们本局游戏没有使用过载具.")得到如下输出和图片:
平均载具行驶距离为 606.6m, 99% 的玩家行驶了 7005.0m 或更少, 行驶距离最远的玩家行驶 27410.0m.
275812 位玩家 (74.4269%) 行驶了 0 米. 他们本局游戏没有使用过载具.
由上述输出和图片,玩家们在游戏中大部分没有机会使用到载具,这可能和载具获取难度有关,同时,载具的平均行驶距离为606.6m,这也表明一旦玩家有机会使用载具,他们会持续使用载具进行移动。
3.分析玩家的物品使用情况
PUBG中提供了种类繁多的物品,分为治疗物品(医疗包、医疗箱、绷带)和增益物品(能量饮料、止疼药),分析物品的使用情况可以侧面反映游戏的激烈程度,分析代码如下:
df = df.withColumn("heals", df["heals"].cast(IntegerType()))
df = df.withColumn("boosts", df["boosts"].cast(IntegerType()))
# 计算heals和boosts的平均值、99%分位数和最大值
average_heals = df.select(mean("heals")).collect()[0][0]
heals_99th_percentile = df.selectExpr("percentile_approx(heals, 0.99)").collect()[0][0]
max_heals = df.select(max("heals")).collect()[0][0]
average_boosts = df.select(mean("boosts")).collect()[0][0]
boosts_99th_percentile = df.selectExpr("percentile_approx(boosts, 0.99)").collect()[0][0]
max_boosts = df.select(max("boosts")).collect()[0][0]
# 打印统计信息
print(f"平均每个人使用 {average_heals:.1f} 个治疗物品,99%的人使用 {heals_99th_percentile} 或更少,而最多的人使用了 {max_heals} 个。")
print(f"平均每个人使用 {average_boosts:.1f} 个增益物品,99%的人使用 {boosts_99th_percentile} 或更少,而最多的人使用了 {max_boosts} 个。")
# 筛选出heals和boosts小于99%分位数的行
df_filtered = df.filter((df["heals"] < heals_99th_percentile) & (df["boosts"] < boosts_99th_percentile))
# 将筛选后的Spark DataFrame转换为Pandas DataFrame
pandas_df_filtered = df_filtered.select("heals", "boosts", "winPlacePerc").toPandas()
# 使用matplotlib和seaborn进行点图绘制
f, ax1 = plt.subplots(figsize=(20,10))
sns.pointplot(x='heals', y='winPlacePerc', data=pandas_df_filtered, color='lime', alpha=0.8)
sns.pointplot(x='boosts', y='winPlacePerc', data=pandas_df_filtered, color='blue', alpha=0.8)
plt.text(4, 0.6, 'Heals', color='lime', fontsize=17, style='italic')
plt.text(4, 0.55, 'Boosts', color='blue', fontsize=17, style='italic')
plt.xlabel('Number of heal/boost items', fontsize=15, color='blue')
plt.ylabel('Win Percentage', fontsize=15, color='blue')
plt.title('Heals vs Boosts', fontsize=20, color='blue')
plt.grid()
plt.savefig('heal.png', format='png', dpi=300)
plt.show()可以得到以下的输出和图片:
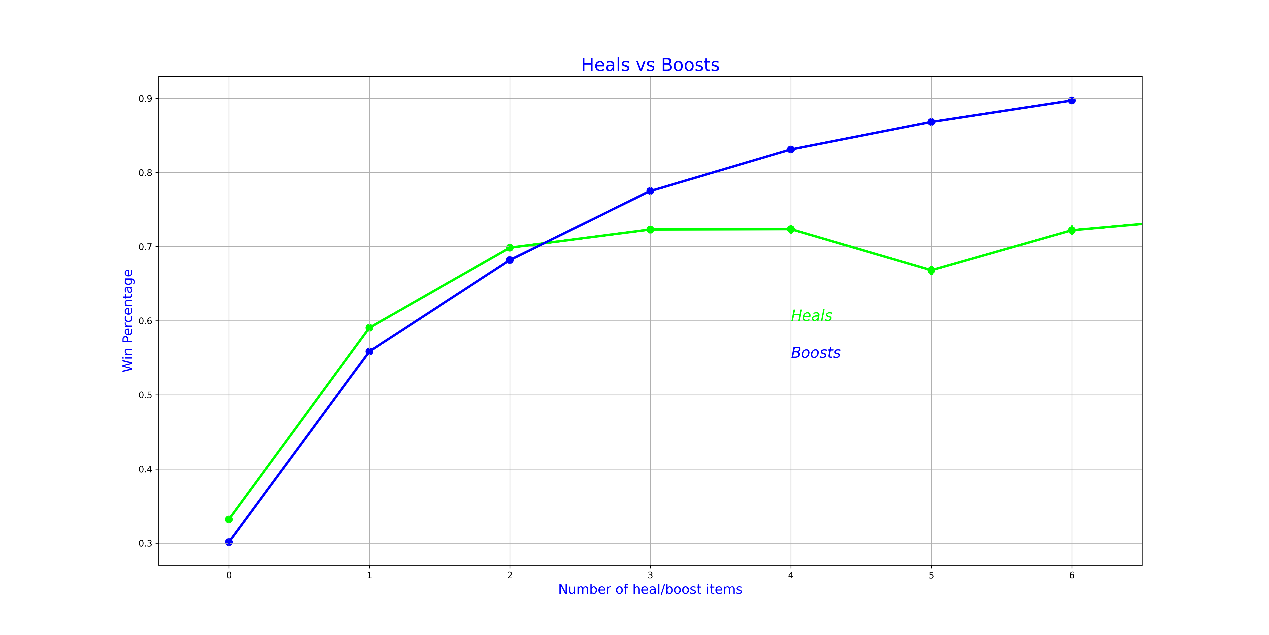
平均每个人使用 1.4 个治疗物品,99%的人使用 12 或更少,而最多的人使用了 54 个。
平均每个人使用 1.1 个增益物品,99%的人使用 7 或更少,而最多的人使用了 22 个。
根据输出的图片,可以粗略判断出治疗物品和增益物品的数量似乎与获胜百分比(Win Percentage)有一定的关联。图中显示,随着治疗物品或增益物品数量的增加,获胜百分比也有所提高。
4.分析玩家的组队情况
PUBG游戏中有3种游戏模式。一个人可以单独玩,也可以与朋友(二人组)一起玩,也可以与其他 3 个朋友(小队)一起玩。100 名玩家加入同一服务器,因此在双人组的情况下,最大团队为 50 个,在小队的情况下,最大团队为 25 个。原始数据并没有这个特征,因此需要我们自己分析
代码如下:
solos = df.filter(col("numGroups") > 50)
duos = df.filter((col("numGroups") > 25) & (col("numGroups") <= 50))
squads = df.filter(col("numGroups") <= 25)
# 计算每种游戏模式的数量及其百分比
total_games = df.count()
solo_count = solos.count()
duo_count = duos.count()
squad_count = squads.count()
solo_percentage = (solo_count / total_games) * 100
duo_percentage = (duo_count / total_games) * 100
squad_percentage = (squad_count / total_games) * 100
# 打印游戏模式的数量及其百分比(中文输出)
print(f"共有 {solo_count} 场({solo_percentage:.2f}%)单人游戏,{duo_count} 场({duo_percentage:.2f}%)双人游戏,以及 {squad_count} 场({squad_percentage:.2f}%)组队游戏。")
# 将筛选后的Spark DataFrame转换为Pandas DataFrame以进行绘图
pandas_solos = solos.select("kills", "winPlacePerc").toPandas()
pandas_duos = duos.select("kills", "winPlacePerc").toPandas()
pandas_squads = squads.select("kills", "winPlacePerc").toPandas()
# 使用matplotlib和seaborn进行点图绘制
f, ax1 = plt.subplots(figsize=(20,10))
sns.pointplot(x='kills', y='winPlacePerc', data=pandas_solos, color='black')
sns.pointplot(x='kills', y='winPlacePerc', data=pandas_duos, color='#CC0000')
sns.pointplot(x='kills', y='winPlacePerc', data=pandas_squads, color='#3399FF')
plt.text(37, 0.6, 'Solos', color='black', fontsize=17, style='italic')
plt.text(37, 0.55, 'Duos', color='#CC0000', fontsize=17, style='italic')
plt.text(37, 0.5, 'Squads', color='#3399FF', fontsize=17, style='italic')
plt.xlabel('Number of kills', fontsize=15, color='blue')
plt.ylabel('Win Percentage', fontsize=15, color='blue')
plt.title('Solo vs Duo vs Squad Kills', fontsize=20, color='blue')
plt.grid()
plt.savefig('mode_with_win_rate.png', format='png', dpi=300)
plt.show()输出及图片如下:
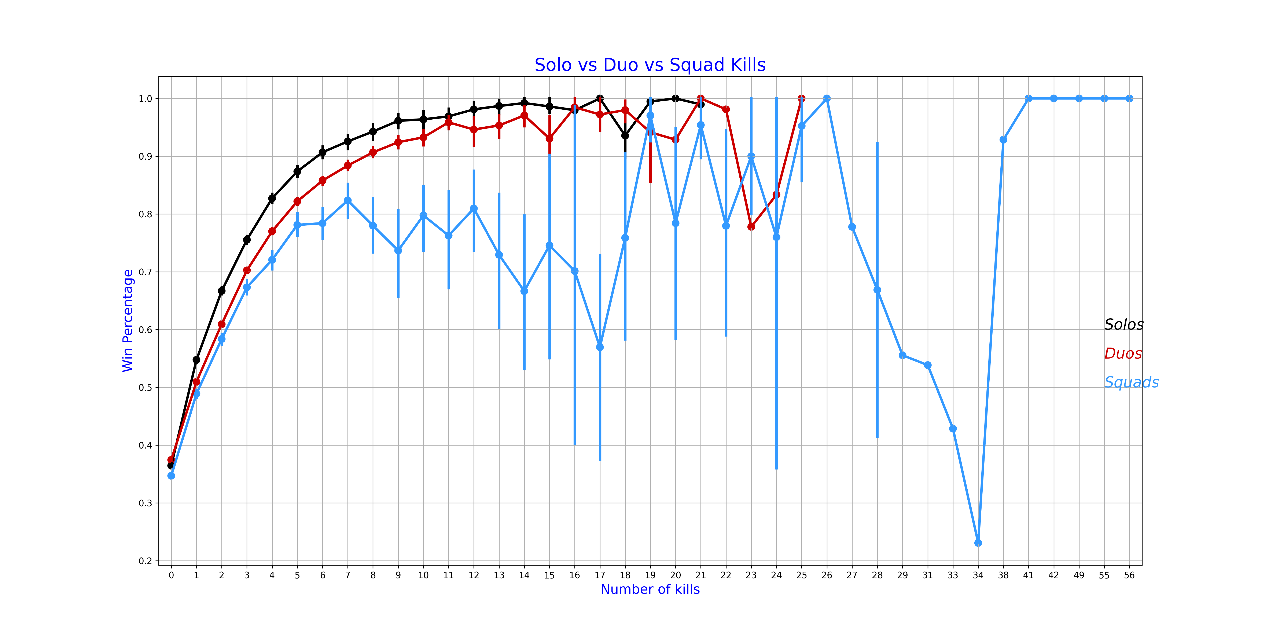
共有 59261 场(15.99%)单人游戏,274568 场(74.09%)双人游戏,以及 36752 场(9.92%)组队游戏。
可以看出在不同游戏模式下,随着击杀数的增加,获胜百分比大致呈上升趋势。此外,单人模式在较高击杀数时的获胜百分比似乎高于双人和组队模式,这可能表明在获得较多击杀后,单人模式的玩家胜率提升更为显著。
五、实验总结
本次实验经过一系列的数据处理和分析,得出以下结论:
- 数据预处理:成功地对原始数据集进行了清洗和缩减,删除了重复和缺失的数据,为数据分析阶段准备了高质量的数据集。
- 玩家行为分析:通过对击杀数、伤害量、步行距离和载具使用等数据的分析,揭示了PUBG玩家在比赛中的行为模式。大部分玩家在比赛中难以实现击杀,且有相当一部分玩家步行距离较短,表明他们可能很快就被淘汰或选择挂机。
- 物品使用情况:分析表明,治疗物品和增益物品的使用与玩家的获胜百分比存在一定的关联,使用这些物品数量的增加似乎能提高获胜的机会。
- 组队情况分析:根据不同的游戏模式(单人、双人、组队),分析了玩家的组队情况和获胜百分比的关系。结果显示,单人模式在获得较多击杀后胜率提升更为显著。
- 数据可视化:利用matplotlib和seaborn等工具,将分析结果进行了直观的可视化展示,包括击杀数分布、伤害量分布、步行距离和载具使用距离的分布图。
最后,在实验过程中,加深了我对Hadoop和Spark大数据技术的理解,掌握了使用这些工具进行数据处理、分析和可视化的方法。同时实验的分析结果也可以为PUBG游戏设计提供了数据支持,例如,通过了解玩家行为模式,游戏开发者可以对游戏机制进行调整,以提升玩家的游戏体验和满意度。