【版权声明】版权所有,严禁转载,严禁用于商业用途,侵权必究。
作者:厦门大学计算机科学与技术系2023级研究生 吴聪霞
指导老师:厦门大学数据库实验室 林子雨 博士/副教授
时间:2024年6月
相关教材:林子雨、郑海山、赖永炫编著《Spark编程基础(Python版,第2版)》(访问教材官网)
相关案例:基于Python语言的Spark数据处理分析案例集锦(PySpark)
数据集和代码下载:从百度网盘下载本案例数据集和代码。(提取码是ziyu)
本案例数据集来自Kaggle的书籍推荐数据集。采用pandas对数据进行清洗,采用分布式文件系统HDFS进行数据存储,采用Python编写Spark程序进行数据分析,使用Matplotlib进行数据可视化。
一、环境配置和数据集
Linux: Ubuntu16.04 及以上版本
Hadoop: 3.3.5
Spark:3.2.0
Python:3.6.4
开发工具:VScode
数据集来源:
https://www.kaggle.com/datasets/imtkaggleteam/book-recommendation-good-book-api
一共包含11127行数据,有12个属性列:
bookID — 图书的 ID
title — 书名
authors — 作者姓名
average_rating — 读者的平均评分
isbn — 国际标准书号 (ISBN) 是一种数字商业图书标识符,旨在是唯一的
isbn13 — 13 位 ISBN
language_code — 每本书的书面语言
num_pages — 主书页数
ratings_count — 收到的唯一评分数量
text_reviews_count — 该书收到的书面文本评论总数。
publication_date — 出版日期
publisher — 出版社/出版人
二、数据预处理
1.使用pandas读取csv文件
代码:导入相关的库,读取原始数据集csv文件
import pandas as pd
import numpy as np
dataFrame = pd.read_csv('Dataset/books.csv')报错:说明存在多余的值
解决:增加error_bad_lines=False跳过有多余属性的行
输出结果:如图跳过了3350,4704,5879,8981行(数据集本身只有12列,这几行有13个属性值,跳过了就不会读取)

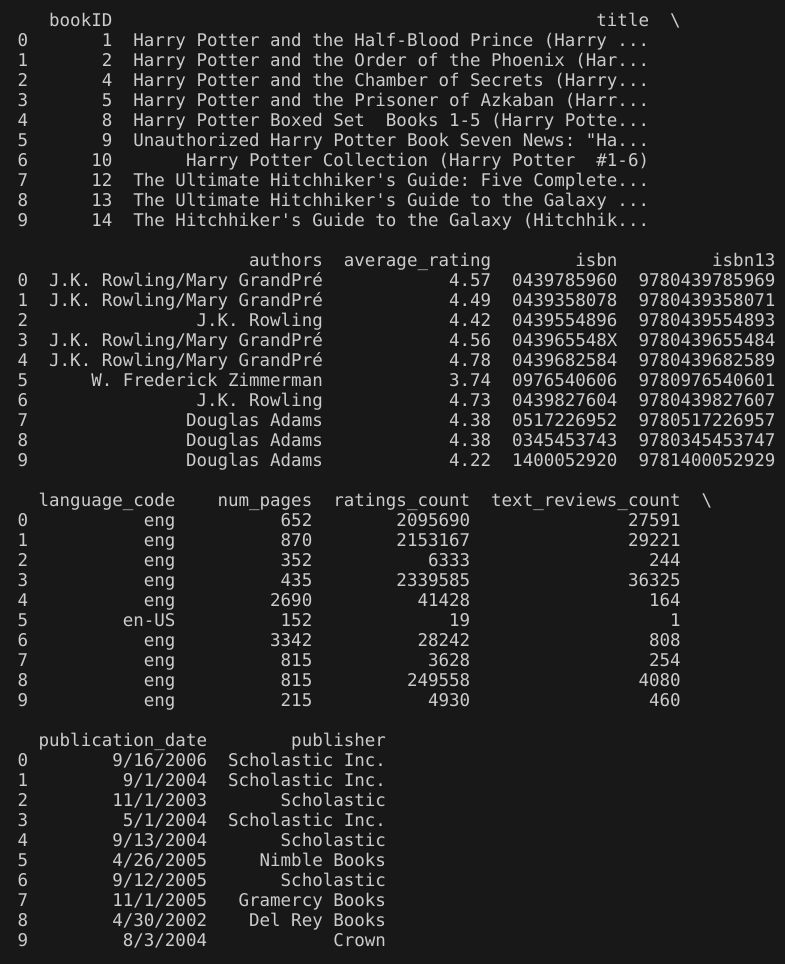
输出前10行的信息如下:
2.打开数据集文件发现有的列名前后有空格,这里做了空格去除操作,并查看了数据集的相关信息
代码:

输出结果:数据集一共有11123行,包含12个属性列。且属性列中有1个float64类型、5个int64,6个object类型。
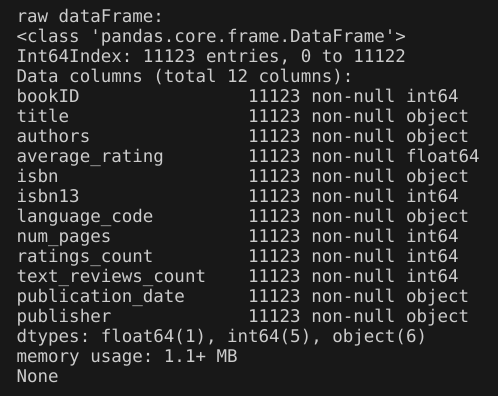
3.删除空值
代码:

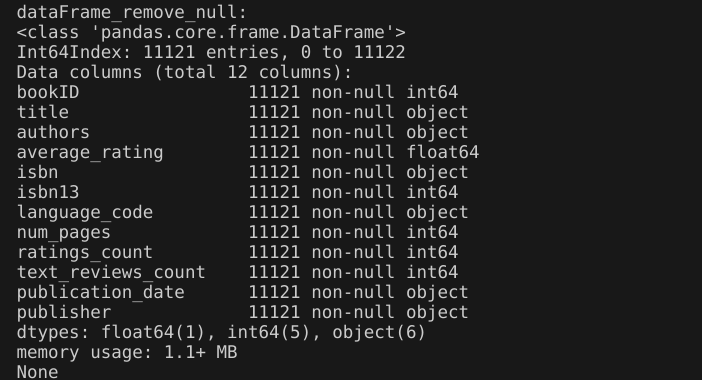
输出结果:删除空值后的数据集信息和原始数据集信息相同,说明原始数据集不存在空值。
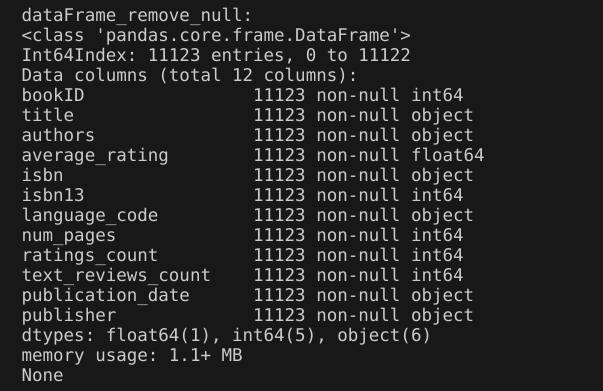
4.删除重复值
代码:

输出结果:删除重复值后的数据集信息和原始数据集信息相同,说明原始数据集不存在重复值(也就是不存在重复的行)。
5.格式化时间列,由9/16/2006变成2006-9-16,并且再做一次删除空值操作
代码:
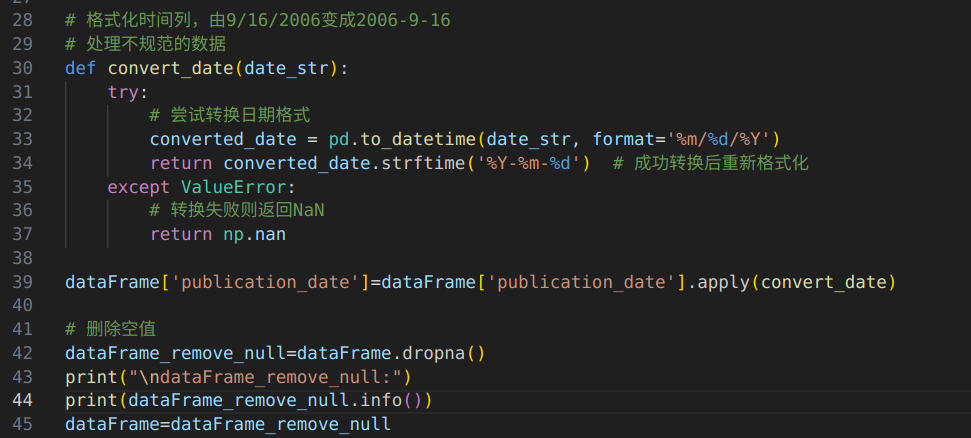
输出结果:与原始数据集相比,格式化时间后的数据集多了两个空值,这里删去了。
6.查看language_code的数据有没有异常值
代码:

输出结果:这些全部都是语言代码,例如eng代表English。无异常值。

7.将处理后的数据写入新的csv文件中
代码:

使用vscode预览数据集发现时间格式转换成功:

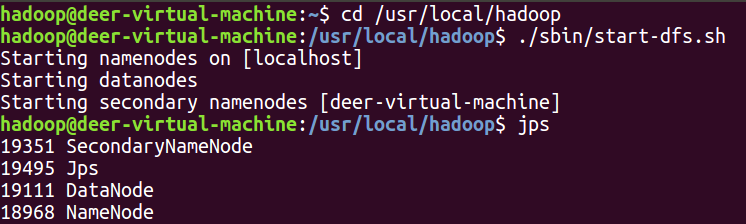
8.将数据上传到hdfs中
首先启动hadoop,使用jps命令查看是否启动成功。
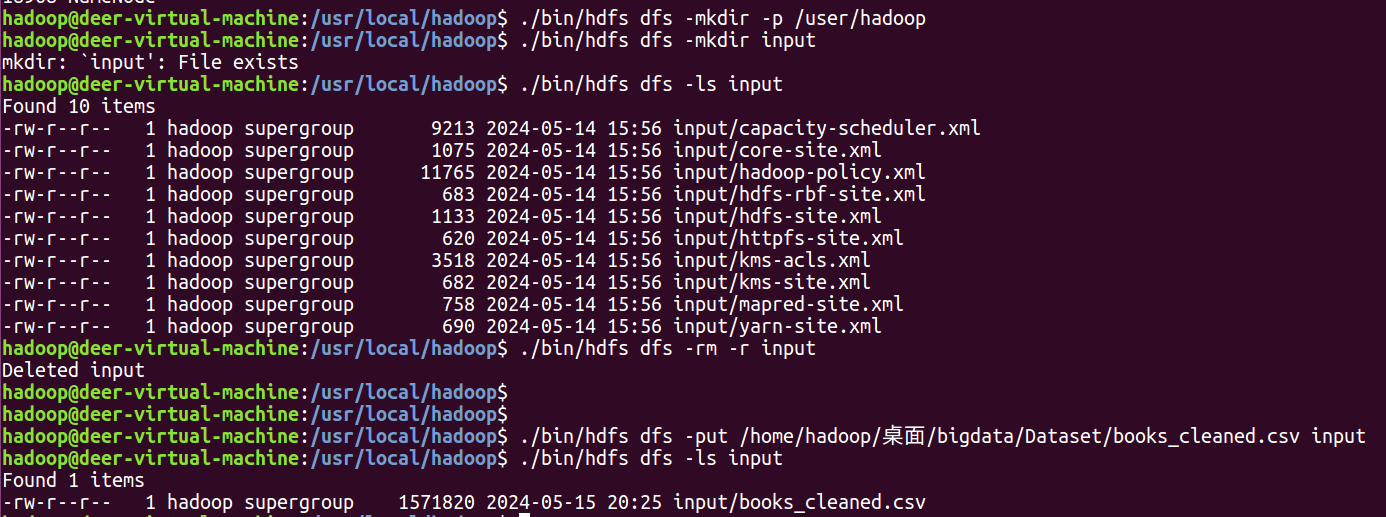
创建input目录,将文件上传到hdfs中。如果原本有input目录可以先删除。

三、数据分析
代码:引入相关库,使用spark读取csv文件,创建dataframe,根据dataframe创建视图books。
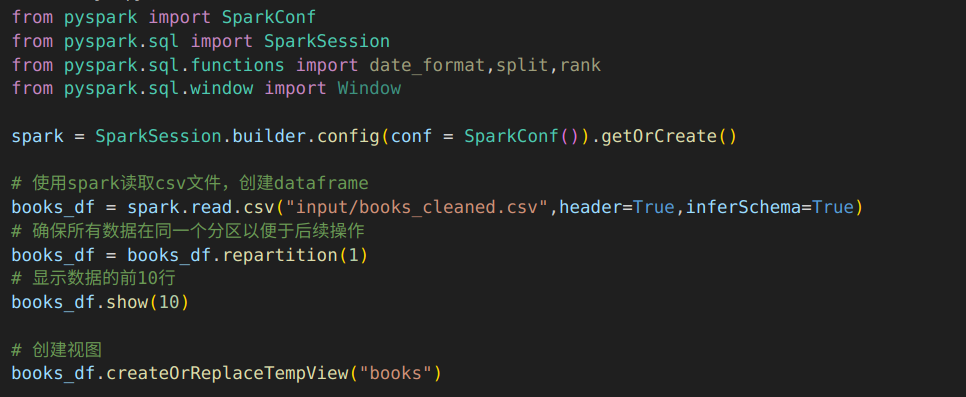
输出结果:下图是读取数据集的前10行。

3.1 概览
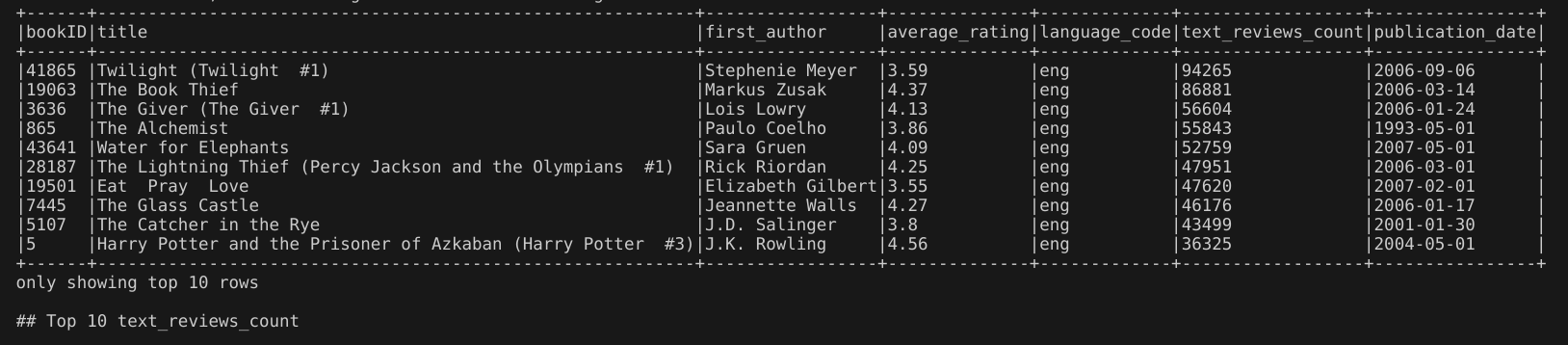
1.前10本最受关注的书籍(text_reviews_count)
代码:通过spark.sql()方法执行SQL查询,构建的sql语句使用order by根据text_reviews_count(该书收到的书面文本评论总数)排序,设置DESC使其降序排列。然后使用show方法展示结果的前10行,即前10本最受关注的书籍,truncate=False表示不截断显示,长字符串也会完全显示出来,不会被缩短。最后使用DataFrame.write.csv()方法将结果保存到hdfs的result目录,设置mode='overwrite'表示如果目标文件已存在则覆盖原有的文件。

输出结果:输出了前10本书的信息。
2.前10本最长篇幅的书籍(num_pages)
代码:通过spark.sql()方法执行SQL查询,构建的sql语句使用order by根据num_pages(该书收到的书面文本评论总数)排序,设置DESC使其降序排列。然后使用show方法展示结果的前10行,即前10本最长篇幅的书籍。最后使用DataFrame.write.csv()方法将结果保存到hdfs的result目录。

输出结果:输出了前10本书的信息。

3.不同出版社出版的书籍数量
代码:通过spark.sql()方法执行SQL查询,构建的sql语句使用GROUP BY来根据publisher(出版社)进行分组,使用sql聚集函数COUNT计算每个分组里书的数量books_num,并使用ORDER BY根据书的数量降序排序。
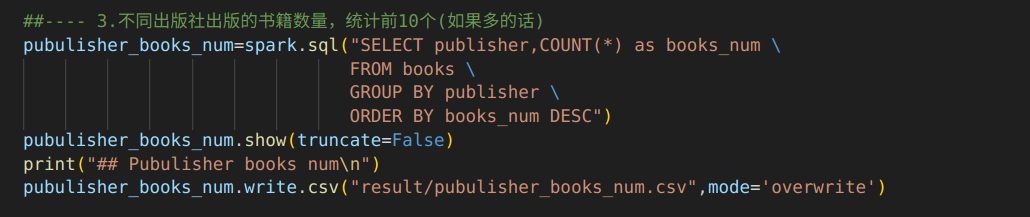
输出结果:输出了20条结果信息。
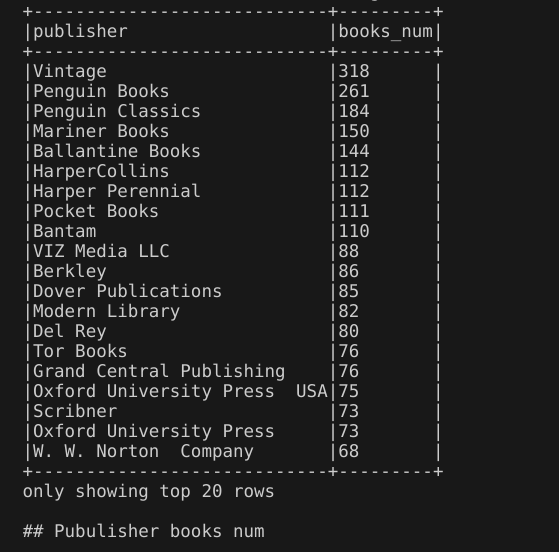
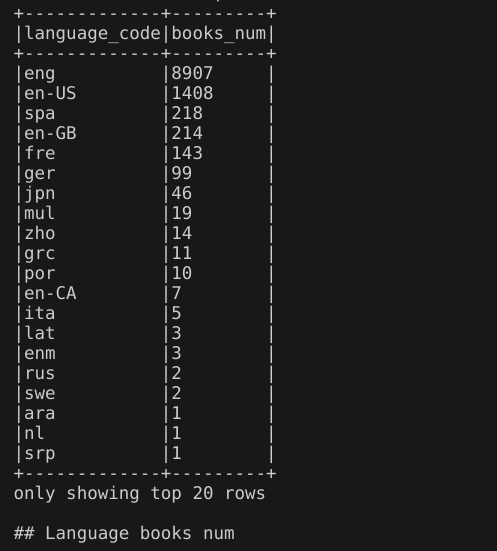
4.不同语言的书籍数量
代码:通过spark.sql()方法执行SQL查询,构建的sql语句使用GROUP BY子句,对视图books根据language_code(语言代码)进行分组,使用sql聚集函数COUNT计算每个分组里书的数量books_num,并使用ORDER BY根据书的数量降序排序。

输出结果:输出了20条结果信息。
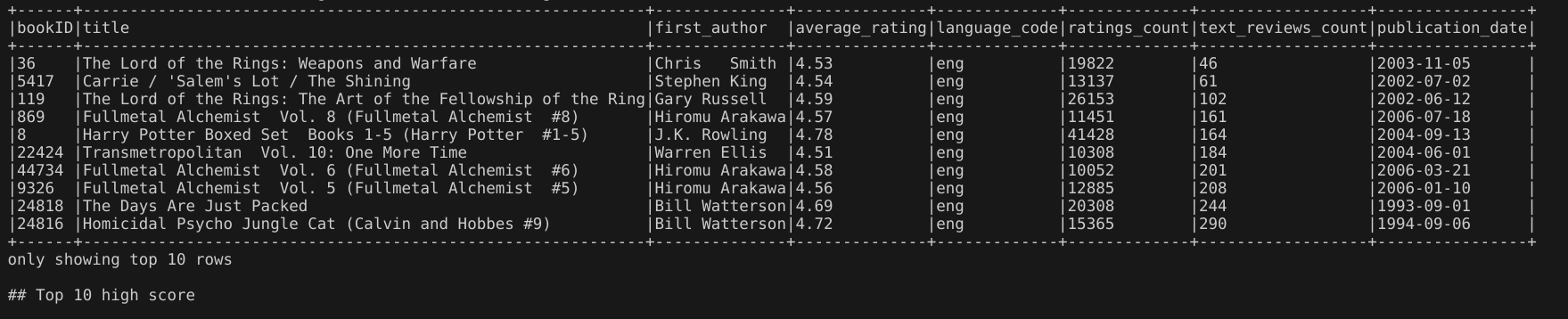
5.前10本最不受关注的高分书籍(评分在4.5分以上,评分人数超过1万,评论数少于200) —— 冷门高分书籍
代码:通过spark.sql()方法执行SQL查询,构建的sql语句使用了SUBSTRING_INDEX(authors, '/', 1) 来提取第一作者的信息,使用where子句设置了查询条件,使用ORDER by子句使其根据评论数升序排序。

输出结果:输出了10条书籍信息。
3.2 关系
6.出版书籍的数量与时间(年份)的关系
代码:由于books视图中书籍的出版如期包含年月日,这里首先创建了一个新的视图books_with_year,对于出版日期提取年份并创建一个新列year。然后通过spark.sql()方法执行SQL查询,构建的sql语句使用GROUP BY子句对视图books_with_year分组,使其根据年份分组,再使用COUNT函数计算每个分组的书籍的数量,并使用ORDER BY子句使结果按照年份升序排序。
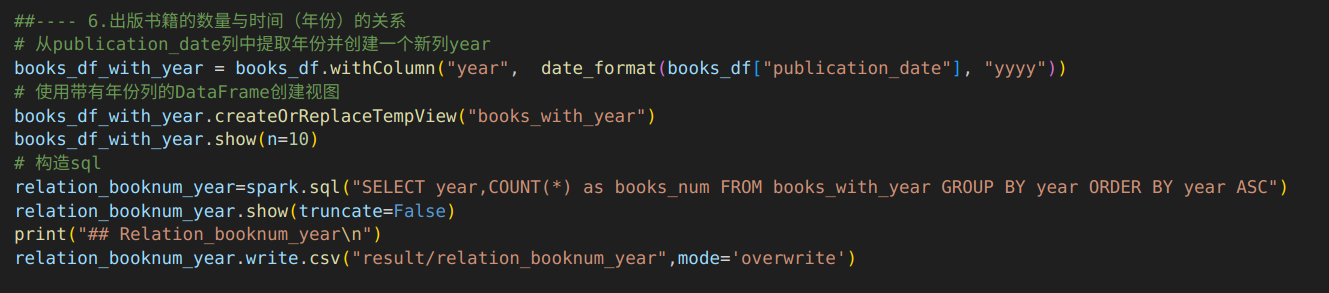
输出结果:输出了出版书籍的数量与时间(年份)的关系前20条结果信息。
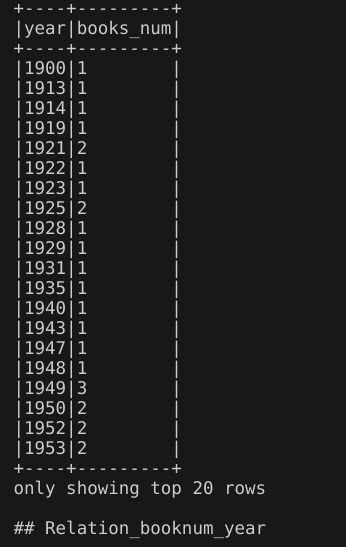
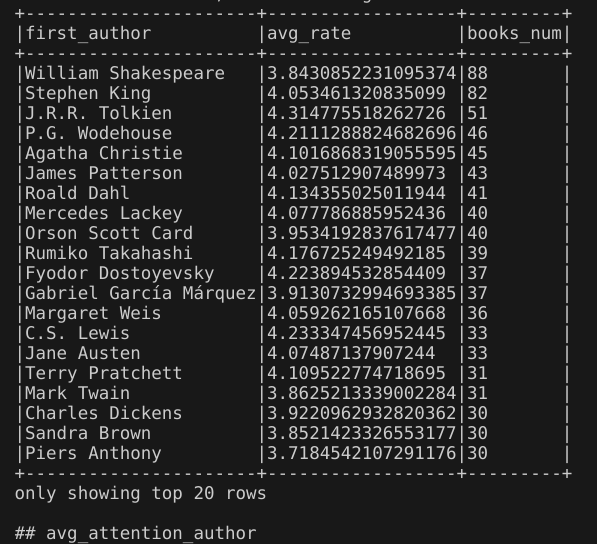
7.不同作者的书的平均评分
代码:提取第一作者创建新视图books_df_with_first_author。然后通过spark.sql()方法执行SQL查询,构建的sql语句使用GROUP BY对视图books_df_with_first_author进行分组,使其根据第一作者first_author进行分组,使用COUNT计算每个分组书籍的数量,使用聚集函数SUM来构造平均评分的计算(也就是平均评分×收到的唯一评分数量/收到的唯一评分数量)=(sum(average_rating*ratings_count)/sum(ratings_count)),并使用ORDER BY子句使结果根据书的数量(降序)、平均评分(降序)排序。
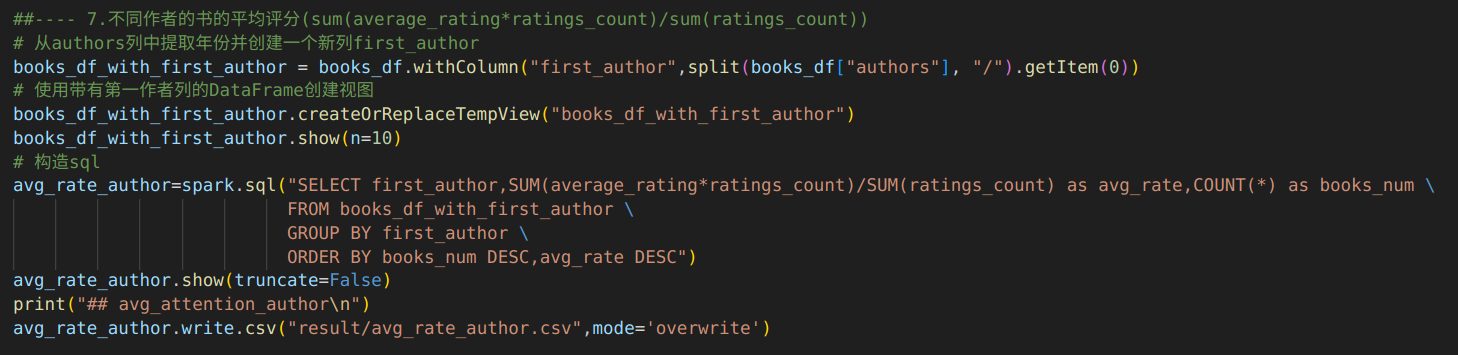
输出结果:输出了新视图books_df_with_first_author前10条信息。

输出了不同作者的书的平均评分的前20条结果。
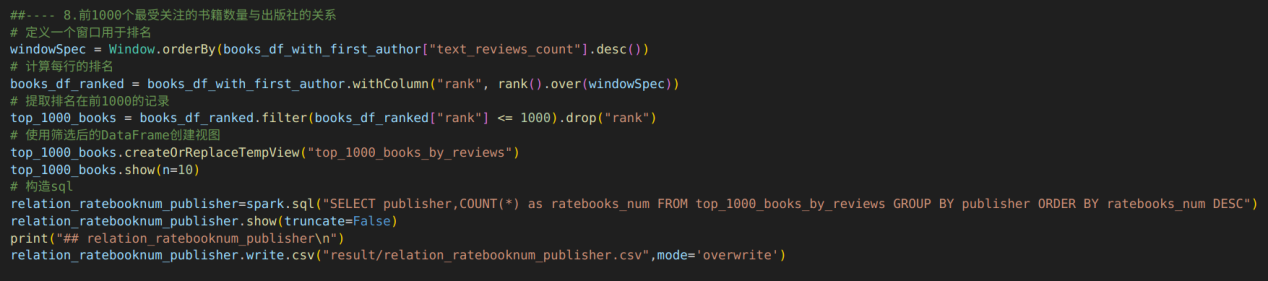
8.前1000个最受关注的书籍数量与出版社的关系
代码:
根据视图books_df_with_first_author创建新视图top_1000_books_by_reviews,首先定义了一个滑动窗口WindowSpec,用于后续的排名计算。窗口按照text_reviews_count列(每本书的文本评论数量)降序排列。然后在books_df_with_first_author上新增一列rank,该列存储了每本书基于之前定义的窗口中的排名,使用rank()函数实现这一功能。最后筛选出排名列值小于等于1000的记录,并且从结果中移除rank列,因为后续分析不需要。
通过spark.sql()方法执行SQL查询,构建的sql语句使用GROUP BY对视图top_1000_books_by_reviews进行分组,使用COUNT函数计算每个分组的书籍数量,并使用ORDER BY使结果根据书籍数量排序。
输出结果:
视图top_1000_books_by_reviews的前10条结果。

输出了前1000个最受关注的书籍中出版社对应的书籍数量,展示了20条结果。
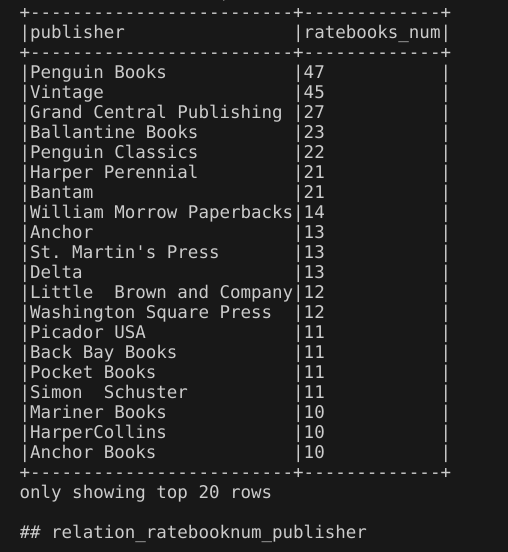
9.前1000个最受关注的书籍数量与语言的关系
代码:沿用前面的视图top_1000_books_by_reviews,通过spark.sql()方法执行SQL查询,构建的sql语句使用GROUP BY对视图进行分组,使其根据语言代码(language_code)进行分组,使用COUNT计算每个分组的书籍数量,并使用ORDER BY使结果按照书籍数量降序排序。
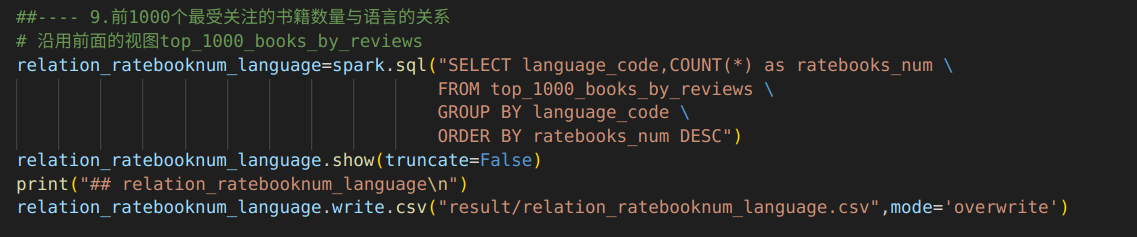
输出结果:输出了前1000个最受关注的书籍中语言代码对应的书籍数量。
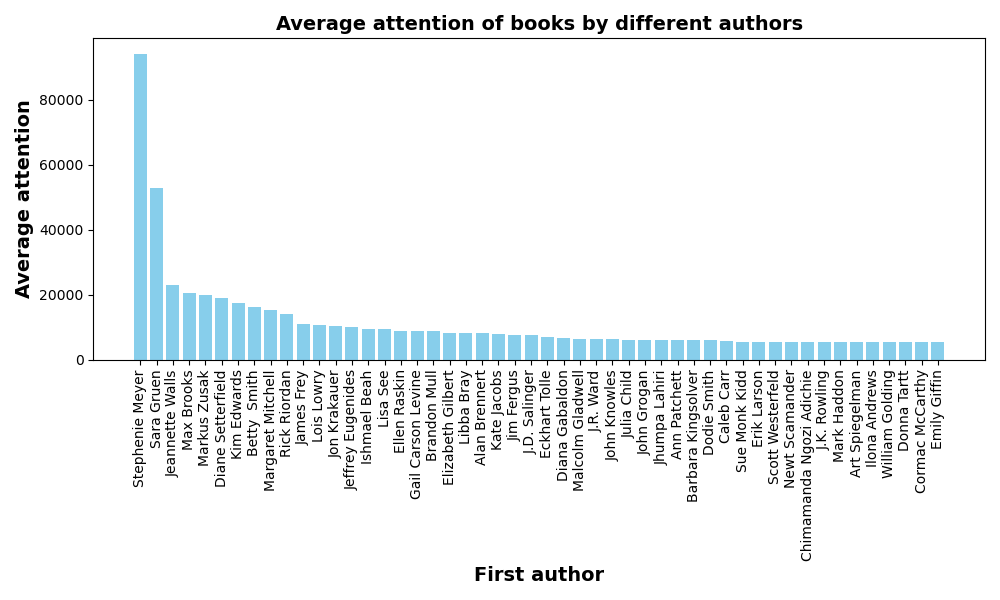
10.不同作者的书的平均受关注程度
代码:沿用前面的视图books_df_with_first_author,通过spark.sql()方法执行SQL查询,构建的sql语句使用GROUP BY对视图books_df_with_first_author进行分组,使其根据第一作者first_author进行分组,使用COUNT计算每个分组书籍的数量,使用聚集函数SUM来构造平均受关注程度的计算(也就是评论总数/书籍数量)=(sum(text_reviews_count)/COUNT(*)),并使用ORDER BY子句使结果根据平均受关注程度(降序)、书的数量(降序)排序。

输出结果:输出了不同作者的书的平均受关注程度前20条结果。

四、数据可视化
将上一步分析的数据结果文件从hdfs复制到本地进行数据可视化。

1.前10本最受关注的书籍
代码:
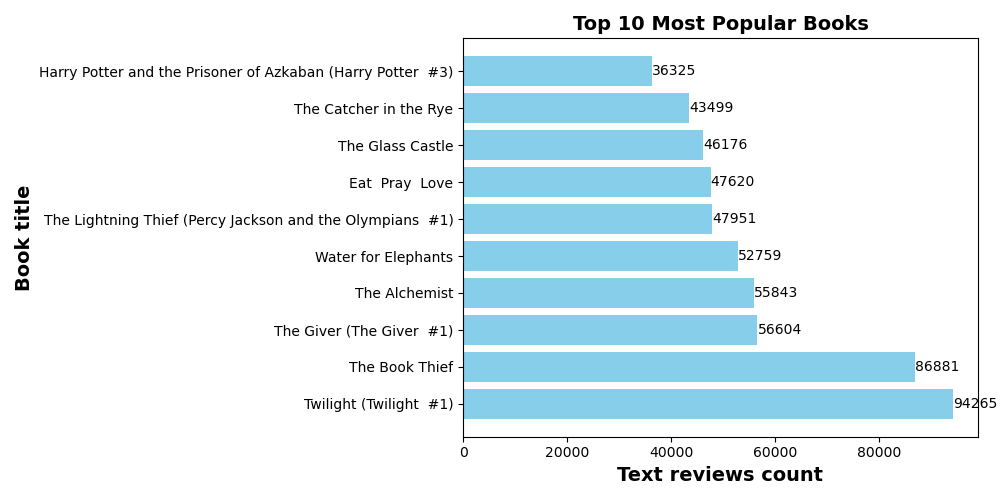
输出结果:最受关注的书是Twilight。
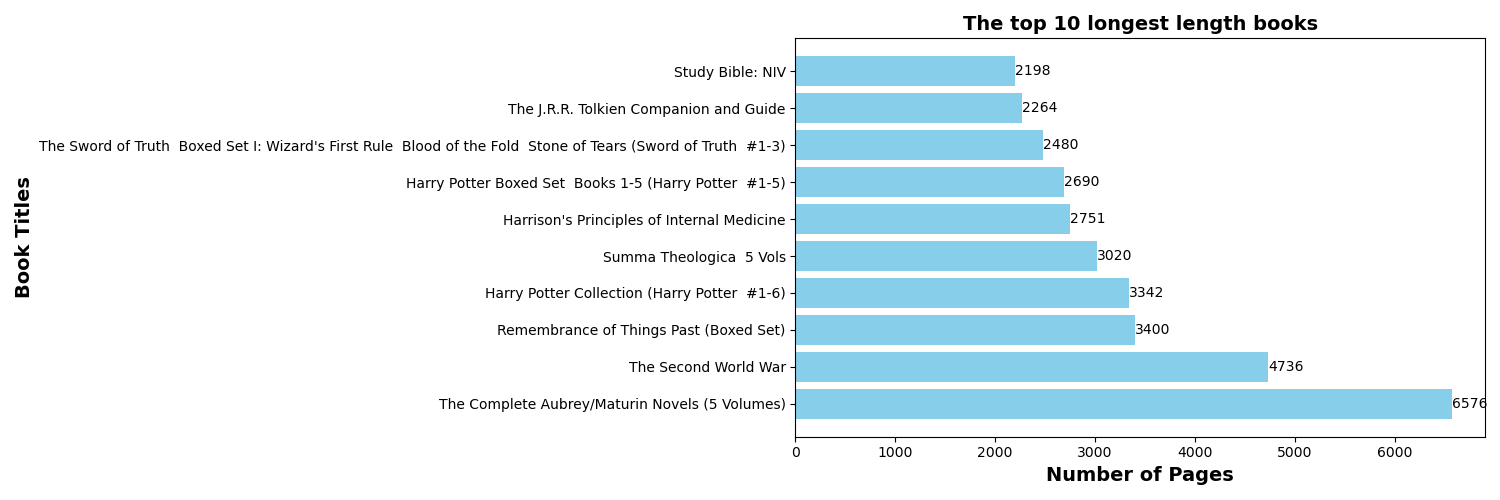
2.前10个最长篇幅的书籍(num_pages)
代码:
输出结果:最长篇幅的书是The Complete Aubrey/Maturin Novels。
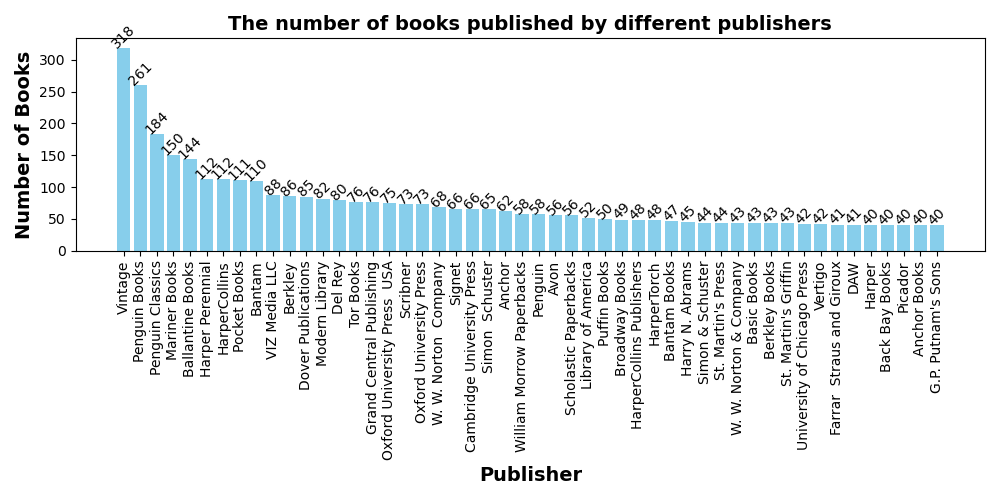
3.不同出版社出版的书籍数量,统计前50个
代码:
输出结果:出版最多书的出版社是Vintage,一共出版了318本。
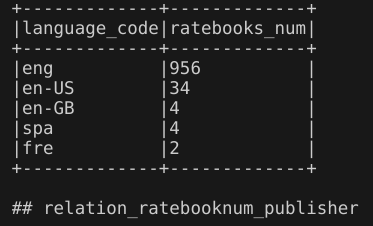
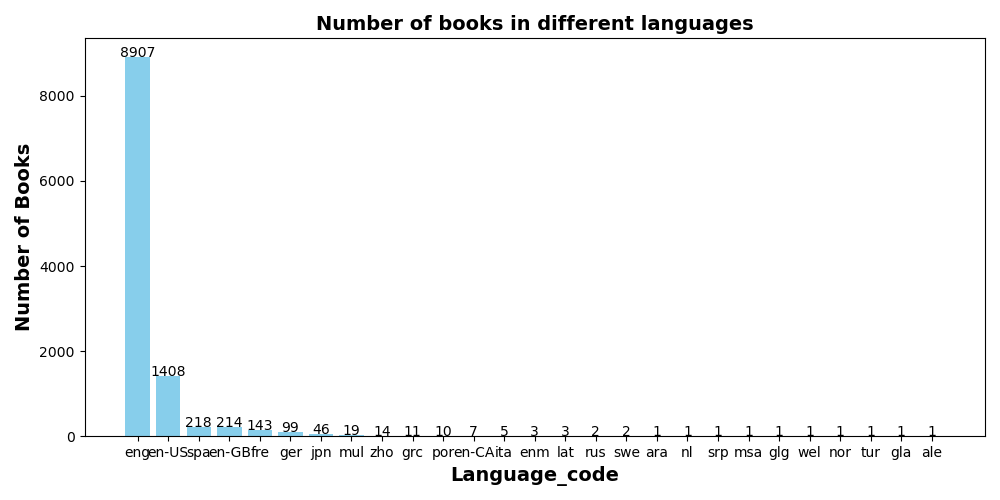
4.不同语言的书籍数量
代码:
输出结果:这些书籍的书面语言大部分是eng(English)语言,一共有8907本。
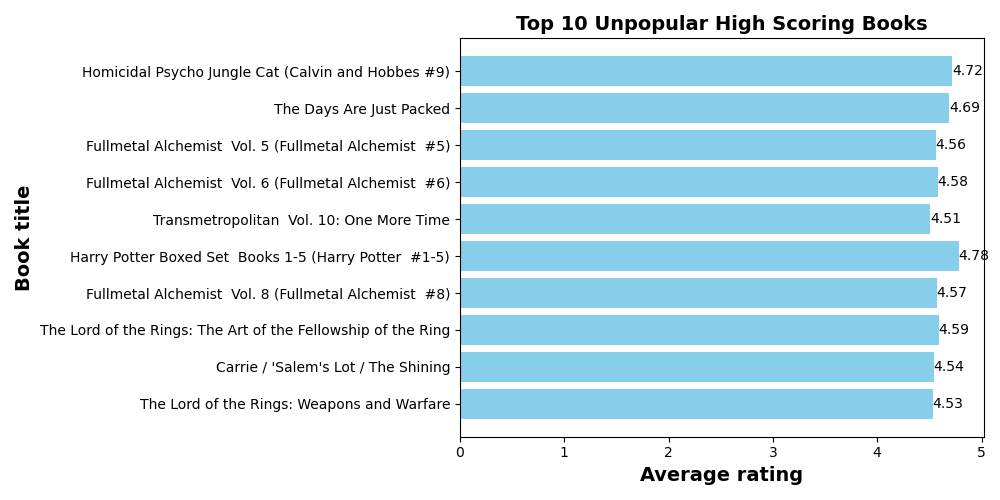
5.前10本最不受关注的高分书籍(评分在4.5分以上,评分人数超过1万,评论数少于200) —— 冷门高分书籍
代码:
输出结果:冷门高分书籍中,评分最高的是Harry Potter Boxed Set Books 1-5。
6.出版书籍的数量与时间(年份)的关系
代码:
输出结果:出版书籍的数量主要集中在2000年和2020年之间,在2000年开始迅速增长。
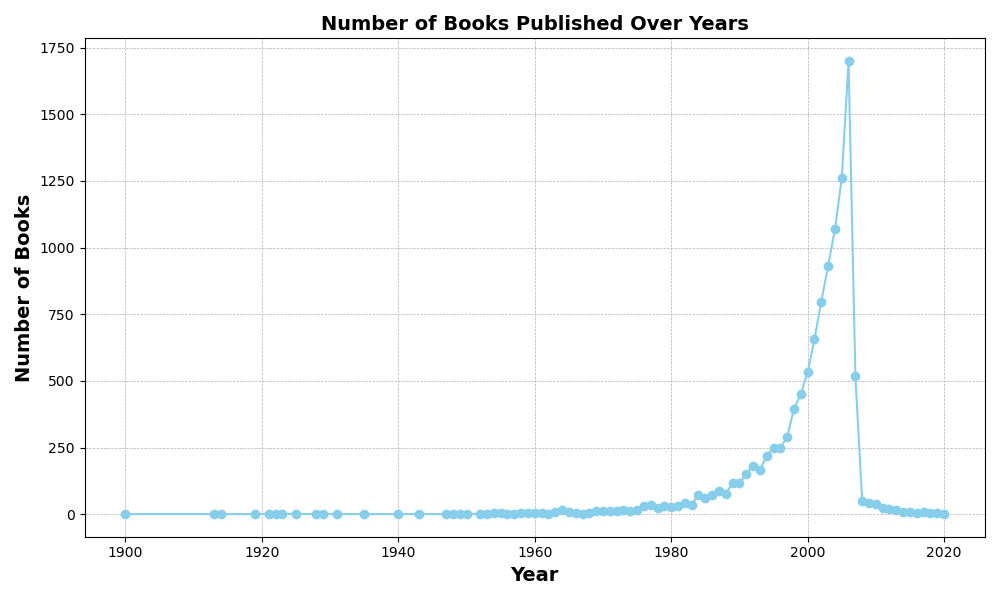
7.不同作者的书的平均评分
代码:
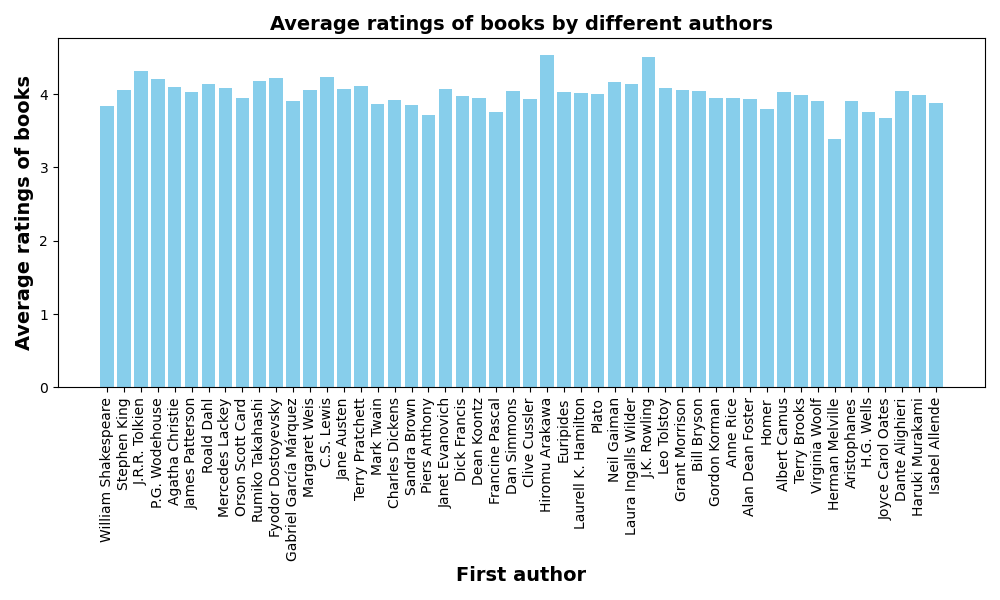
输出结果:前50个结果中,不同作者的书的平均评分大多集中在4分左右。
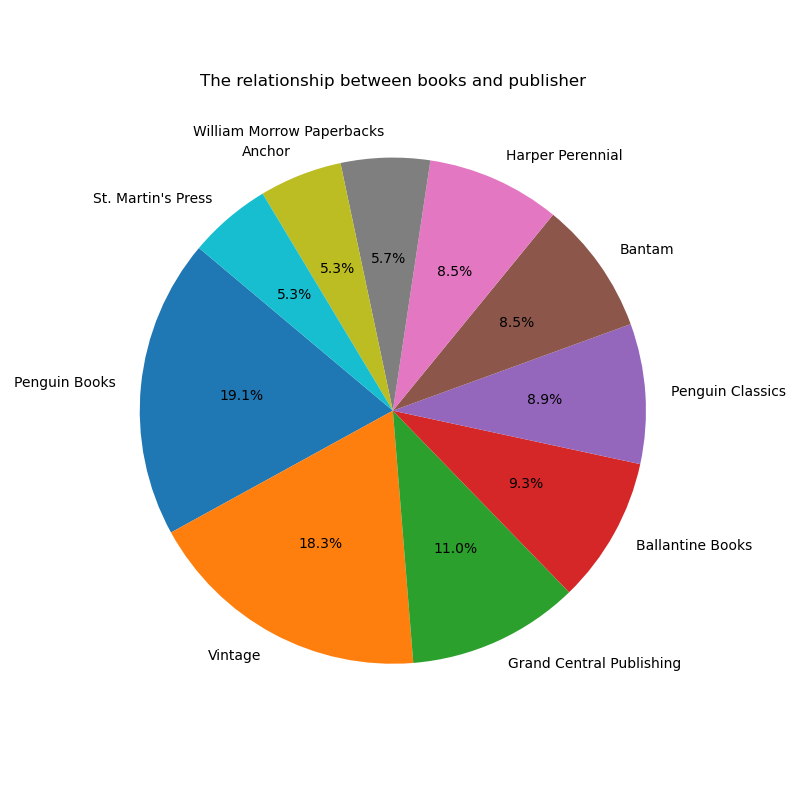
8.前1000个最受关注的书籍数量与出版社的关系
代码:

输出结果:前10个出版社的书籍占比相差不会太远,但受关注的书籍数量最高的出版社是Penguin Books。
9.前1000个最受关注的书籍数量与语言的关系
代码:
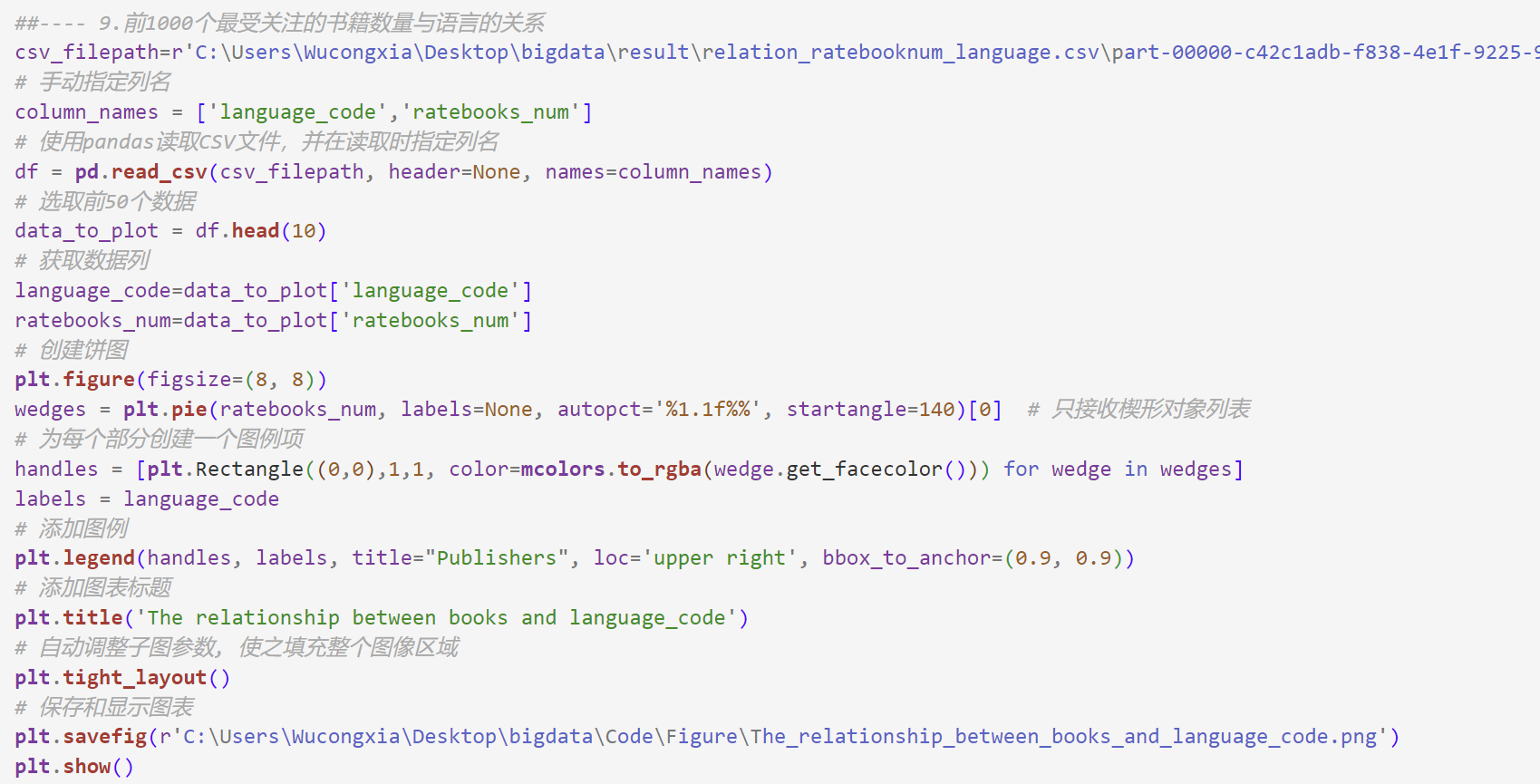
输出结果:受关注的书籍的书面语言几乎都是eng(English),其余语言占比较低。
10.不同作者的书的平均受关注程度(sum(text_reviews_count)/COUNT(*))
代码:

输出结果:前50个结果中, Stephenie Meyer出版的书受关注程度最高。