
【版权声明】版权所有,严禁转载,严禁用于商业用途,侵权必究。
作者:厦门大学人工智能研究院2023级研究生 黄峻杰
指导老师:厦门大学数据库实验室 林子雨 博士/副教授
时间:2024年6月
相关教材:林子雨、郑海山、赖永炫编著《Spark编程基础(Python版,第2版)》(访问教材官网)
相关案例:基于Python语言的Spark数据处理分析案例集锦(PySpark)
数据集和代码下载:从百度网盘下载本案例数据集和代码。(提取码是ziyu)
本案例采用的数据集是贵州茅台公司从2004年1月1日到2024年5月10日期间的每日股票行情数据。使用pandas读取数据并且进行数据收集和预处理。使用Spark进行数据分析(编程语言使用Python),并利用大语言模型(LLM)进行数据分析。通过matplotlib实现数据可视化。
一、实验环境
Ubuntu 16.04
Hadoop 3.3.5
Spark 3.2.0
Python 3.8
JDK 1.8
大语言模型的环境如下:
CUDA 11.4
Pytorch 1.12.1
Transformers 4.35.2
Bitsandbytes 0.42.0
Sqlparse 0.5.0
二、数据预处理
2.1数据集简介
本次实验采用的数据集是贵州茅台公司从2004年1月1日到2024年5月10日期间的每日股票行情数据,使用开源股票数据接口Tushare和Baostock获得。该数据集的各个字段说明如下:

2.2数据集处理
本次实验使用pandas读取数据并且进行数据收集和预处理。具体步骤如下:
1.开源股票数据接口所提供的数据并不齐全,并存在数据缺失的现象,因此本次实验结合两个开源股票数据接口来获得数据,两个数据接口各自特点如下:(1)Tushare:常规数据(例如开盘价、交易量等)齐全,其在服务端已经过手工调整,数据中不存在缺失的现象,但所提供的数据种类不够丰富。(2)Baostock:数据种类更加丰富,包括peTTM等扩展数据,但其数据中存在较多缺失及错误。我们调用两个接口分别获取字段,对于常规数据使用Tushare的结果,并进一步使用Baostock获取更丰富的数据,如peTTM、pbMRQ、psTTM、pcfNcfTTM字段。
2.接下来我们需要使用pandas将两种数据来源的结果进行合并,在两种数据集中日期格式表示不一致,前者为存数字的20240516形式,而后者为2024-05-16形式,这里首先使用pandas的to_datetime和匿名函数进行转换,再用pandas的merge功能按照日期进行合并,代码如下:
# 使用pandas进行格式化统一不同数据来源的日期格式以便下一步合并DataFrame
k_data_df['date'] = pd.to_datetime(k_data_df['date'])
k_data_df['trade_date'] = k_data_df['date'].apply(lambda x: x.strftime('%Y%m%d'))
k_data_df = k_data_df.drop(['date', 'code'], axis=1)
# 使用pandas合并两个DataFrame
# 将每日K线数据和每日滚动市盈率、滚动市销率合并到一个DataFrame中
hist_data = pd.merge(hist_data, k_data_df, on='trade_date')3.由于合并后的数据在部分字段存在数据缺失现象,我们按照实际分析股票的思路,使用前值填充的方式对数据进行补全。注意到数据中还存在异常的0值(某些字段的数值是不能为0的),我们同样使用pandas对这些值进行处理。代码如下:
# 部分字段存在缺失现象,根据股票数据的特点,使用前值填充的方式填充缺失值
hist_data['peTTM'].fillna(method='ffill', inplace=True)
hist_data['pbMRQ'].fillna(method='ffill', inplace=True)
hist_data['psTTM'].fillna(method='ffill', inplace=True)
hist_data['pcfNcfTTM'].fillna(method='ffill', inplace=True)
# 部分股票数据存在异常0值(这些值不应该为0),仍使用前值填充的方式填充0值
hist_data['peTTM'].replace(0, method='ffill', inplace=True)
hist_data['pbMRQ'].replace(0, method='ffill', inplace=True)
hist_data['psTTM'].replace(0, method='ffill', inplace=True)
hist_data['pcfNcfTTM'].replace(0, method='ffill', inplace=True)4.处理后的数据样例如下:

5.上传数据到HDFS:首先./bin/hadoop dfs -mkdir stock创建一个目录用于存储股票数据,然后使用./bin/hadoop dfs -put /home2/hadoop/stock_everyday_data.csv stock上传本地数据集到HDFS,使用ls命令查看上传结果:

三、数据分析
本次实验我们使用Spark进行数据分析(编程语言使用Python),首先我们使用pyspark库读取数据并创建视图(以利用 SQL 来进行数据分析),通过show(3)我们可以验证数据是否读取成功:

1.分析每年贵州茅台股票的平均交易量
首先使用spark的year函数提取所有条目对应的年份,并增添新的一列保存年份。接下来,使用groupBy方法按年份对DataFrame进行分组,并使用agg方法对每个组(即每一年)应用聚合函数。在这种情况下,聚合函数是avg,用于计算每年交易量的平均值。最后,结果按年份排序,以便从最早到最近的顺序显示每年的平均交易量。
代码如下:
# 将日期字段转换为年份
df = df.withColumn("year", year("trade_date"))
# 计算每年的平均交易量
yearly_avg_volume = df.groupBy("year").agg({"vol": "avg"}).orderBy("year")
# 显示结果
print("每年的平均交易量:")
yearly_avg_volume.show(100)
#保存在文件中
yearly_avg_volume.toPandas().to_csv("result/yearly_avg_volume.csv", index=True)计算结果如下:

2.分析股票收盘价的波动:
使用 select 方法选择收盘价列,并使用 avg 和 stddev 聚合函数计算收盘价的平均值和标准差。
代码如下:
# 计算收盘价的平均值和标准差
closing_stats = df.select(avg("close").alias("avg_close"), stddev("close").alias("stddev_close"))
# 显示结果
print("平均收盘价和标准差:")
closing_stats.show()分析结果如下:

3.分析涨跌幅与各数据的相关性:
联合使用 select 方法和 corr 函数计算涨跌幅与成交量、涨跌幅、peTTM、pbMRQ、psTTM 和 pcfNcfTTM 的相关性。结果将被合并到一张表中,以便比较股价涨跌幅与不同数据之间的相关性。
代码如下:
# 计算涨跌幅与成交量的相关性
chg_volume_corr = df.select(corr("pct_chg", "vol").alias("chg_volume_corr"))
# 计算涨跌幅和peTTM的相关性
chg_pe_corr = df.select(corr("pct_chg", "peTTM").alias("chg_pe_corr"))
# 计算涨跌幅和pbMRQ的相关性
chg_pb_corr = df.select(corr("pct_chg", "pbMRQ").alias("chg_pb_corr"))
# 计算涨跌幅和psTTM的相关性
chg_ps_corr = df.select(corr("pct_chg", "psTTM").alias("chg_ps_corr"))
# 计算涨跌幅和pcfNcfTTM的相关性
chg_pcf_corr = df.select(corr("pct_chg", "pcfNcfTTM").alias("chg_pcf_corr"))
#合并上述结果在一张表中
correlation = chg_volume_corr.crossJoin(chg_pe_corr).crossJoin(chg_pb_corr).crossJoin(chg_ps_corr).crossJoin(chg_pcf_corr)
#显示结果
print("涨跌幅与各数据的相关性:")
correlation.show()
#保存在文件
correlation.toPandas().to_csv("result/correlation.csv", index=True分析结果如下:

可以看出股价与每日成交量具有一定的相关性,并且和pcfNcfTTM负相关,投资者在进行决策时可主要参考成交量指标。
4.计算各个月份股票的涨停和跌停次数:
首先使用spark的month函数提取所有条目对应的月份,并增添新的一列保存月份。接下来,使用groupBy方法按月份对DataFrame进行分组,并使用agg方法对每个组应用聚合函数。在每一组中,首先使用when判断是否涨跌停,仅当涨跌停时值为1,使用sum函数计算1的数量从而实现对涨跌停次数的计算。
代码如下:
# 将日期字段转换为月份
df = df.withColumn("month", month("trade_date"))
df = df.withColumn("pct_chg", df["pct_chg"].cast("float"))
df.show(3)
# 计算每月涨停和跌停的次数
monthly_limit_up_down = df.groupBy("month").agg(sum(when((df["pct_chg"] >= 10) | (df["pct_chg"] <= -10), 1).otherwise(0)).alias("limit_up_down_count"))
# 显示结果
print("各个月份涨停和跌停的次数:")
monthly_limit_up_down.orderBy("month").show()
#保存在文件中
monthly_limit_up_down.orderBy("month").toPandas().to_csv("result/monthly_limit_up_down.csv", index=True)分析结果如下:

可以看见在3、4、5月份该股票常更容易出现涨跌停现象,风险厌恶型的投资者可以避免在该时段购买该股票以规避股价波动。
5.分析不同市场环境下的股票数据:
首先将涨跌幅字段转换为数值型,以便进行条件判断。使用 withColumn 方法根据涨跌幅的大小,定义市场环境规则并分类数据为“牛市”、“熊市”和“波动市”,添加对应列“market_condition”。
使用 groupBy 方法按市场环境对 DataFrame 进行分组,使用 agg 方法统计不同市场环境下的股票数据,包括交易天数、总交易量和总 peTTM。进一步计算每个市场环境下的平均交易量和平均 peTTM。
代码如下:
#将涨跌幅字段转换为数值型
df = df.withColumn("pct_chg", df["pct_chg"].cast("float"))
# 定义市场环境规则并分类数据
df = df.withColumn("market_condition",
when(df["pct_chg"] > 2, "牛市")
.when(df["pct_chg"] < -2, "熊市")
.otherwise("波动市"))
# 统计不同市场环境下的股票数据
market_summary = df.groupBy("market_condition")\
.agg({"trade_date": "count", "vol": "sum","peTTM":"sum"})\
.withColumnRenamed("count(trade_date)", "num_of_days")\
.withColumnRenamed("sum(vol)", "total_volume")\
.withColumnRenamed("sum(peTTM)", "total_peTTM")
# 计算每个市场环境下的平均交易量
market_summary = market_summary.withColumn("avg_volume", col("total_volume") / col("num_of_days"))
# 计算平均peTTM
market_summary = market_summary.withColumn("avg_peTTM", col("total_peTTM") / col("num_of_days"))
# 显示结果
print("不同市场环境下的股票数据:")
market_summary.show()
#保存在文件中
market_summary.toPandas().to_csv("result/market_summary.csv", index=True)分析结果:

可以看见在牛市或熊市,即股价有大幅度波动时,成交额比起波动环境会有显著增加,说明投资者们更偏好在股市有巨大波动时进行交易。
6.分析贵州茅台近20年的最高股价和最低股价:
直接使用 SQL 查询获取贵州茅台最高股价和最低股价对应的日期和数值,并使用 orderBy 方法对结果进行排序。这里注意需要把close转换为数值以确保正确比较。
代码如下:
sql_result = spark.sql("""SELECT trade_date, CAST(high AS DECIMAL) AS high_numeric
FROM stock_data
ORDER BY high_numeric DESC
LIMIT 1;""")
print("20年来贵州茅台最高股价:")
sql_result.show()
sql_result = spark.sql("""SELECT trade_date, CAST(low AS DECIMAL) AS low_numeric
FROM stock_data
ORDER BY low_numeric ASC
LIMIT 1;""")
print("20年来贵州茅台最低股价:")
sql_result.show()分析结果如下:

可见在数据集中的最高股价出现在2021年2月18日,为2628元;而最低股价出现在2004年1月2日,为25元。
7.计算上周的平均涨幅:
使用 SQL 查询计算上周的平均涨幅,通过 AVG 函数实现,同时结合 BETWEEN 条件来筛选上周的日期范围。
代码如下:
sql_result = spark.sql("""SELECT AVG(pct_chg) AS avg_chg
FROM stock_data
WHERE trade_date BETWEEN '20240505' AND '20240510';
""")
print("上周平均涨幅:")
sql_result.show()分析结果如下:

可知在20240505至20240510期间贵州茅台的每日平均涨幅约为0.4%。
8.统计每年上涨和下跌天数
使用 groupBy 方法按年份对 DataFrame 进行分组。使用 agg 方法计算每年上涨和下跌天数,通过 sum 和 when 函数实现,并添加列计算上涨和下跌天数占总天数的比值。
代码如下:
# 计算每月涨停和跌停的次数
year_up_days = df.groupBy("year").agg(sum(when((df["pct_chg"] >= 0), 1).otherwise(0)).alias("up_count"))
year_down_days = df.groupBy("year").agg(sum(when((df["pct_chg"] < 0), 1).otherwise(0)).alias("down_count"))
#合并在同一张表并按年份排序
year_up_down_days = year_up_days.join(year_down_days, "year").orderBy("year")
#添加列:上涨天数占总天数的比值
year_up_down_days = year_up_down_days.withColumn("up_ratio", col("up_count") / (col("up_count") + col("down_count")))
#添加列:下跌天数占总天数的比值
year_up_down_days = year_up_down_days.withColumn("down_ratio", col("down_count") / (col("up_count") + col("down_count")))
print("每年上涨和下跌天数:")
year_up_down_days.show(100)
#保存在文件中
year_up_down_days.toPandas().to_csv("result/year_up_down_days.csv", index=True)分析结果如下:
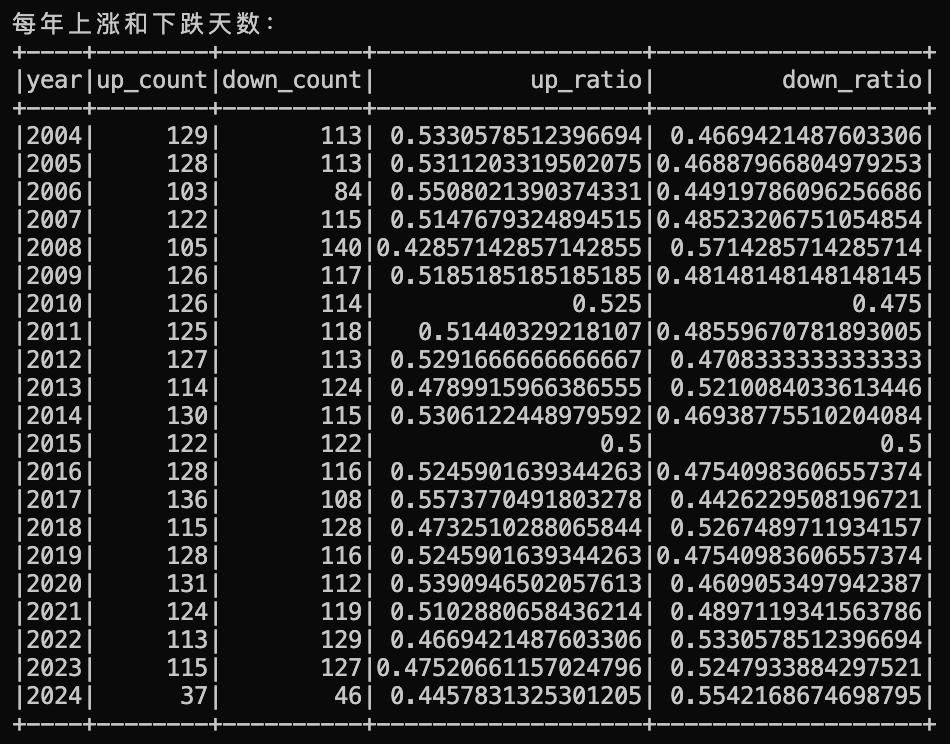
可知贵州茅台每一年的涨跌状况,可以看见近几年其股票呈下跌趋势。
四、利用大语言模型(LLM)进行数据分析
近年来,大型语言模型(Large Language Model, LLM)备受瞩目,其主要优势在于能够理解用户的自然语言指令并据此完成任务。然而,由于大型语言模型本质上是概率模型,在回答问题时可能存在“幻觉”,即出现随意编造内容的情况。特别是在需要回答准确数据的任务中,大型语言模型往往无法满足要求。此外,由于训练大型语言模型需要耗费大量时间和资源,其所学习到的知识可能滞后于现实,并且难以实时更新,因此容易提供过时的数据和知识。
相比之下,数据库具有多样化的查询方法,并且能够实时更新数据,因此可以提供准确的信息。然而,数据库也存在一个缺点,即普通用户缺乏对SQL语句等数据库操作工具的掌握,因此难以直接与数据库交互。
因此,本次实验旨在结合大型语言模型与数据库的优势,以弥补各自的不足,制作一个面向普通用户的数据分析方法。
4.1方法
为了实现LLM与数据库的交互,本实验采用SQL查询语句作为纽带,即LLM接收用户的自然语言查询输入,例如“2024年哪一天股价最高”,大语言模型基于该输入生成SQL查询语句:
SELECT MAX(s.high) AS max_high_price_date
FROM a_stock_everyday_data s
WHERE s.trade_date BETWEEN 20240101 AND 20241231
该SQL查询语句用于查询数据库并返回结果给用户,其流程可归纳为下图:

LLM通常以预训练-微调的范式进行应用,预训练后的LLM通常拥有了通用能力,能对用户的输入进行响应,为了进一步让LLM完成本实验的任务要求,我们需要让其学会以文字问题作为输入,并输出SQL查询语句(即Text2SQL任务)。
我们选择sqlcoder-7b-2作为语言模型,其在大量Text2SQL语料上进行了微调,可很好的实现生成SQL查询语句的任务,以下网址为该模型的Demo:https://defog.ai/sqlcoder-demo/
4.2具体代码实现
本实验在本地构建了LLM与数据库的结合的pipeline,接下来是详细的介绍。
首先我们读入HDFS的文件,对其进行数据格式的转换,并构建视图用于SQL查询,代码如下:
spark = SparkSession.builder.getOrCreate()
df = spark.read.csv("stock_everyday_data.csv",header=True)
#将a_stock_everyday_data中除了trade_date的字符串都转换为数值,以确保使用sql语句时能正常比较
for col in df.columns:
if col != "trade_date":
df = df.withColumn(col, df[col].cast("float"))
df.createOrReplaceTempView("a_stock_everyday_data")接下来,我们需要在本地加载LLM,模型参数量为7B,大约占用17G显存,这里使用Transformers库进行便捷部署:
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "defog/sqlcoder-7b-2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True,
torch_dtype=torch.float16,
#load_in_4bit=True,
device_map="auto",
use_cache=True,
)在输入大语言模型时,需要一同给出我们的数据库结构,以便LLM能给出正确的SQL查询语句,因此我们需要构建Prompt模版,指明表格结构,在接收到用户的问题后,替换模版中的{question}内容,从而输入大语言模型,代码如下:
prompt = """<|begin_of_text|><|start_header_id|>user<|end_header_id|>
Generate a SQL query to answer this question: `{question}`
DDL statements:
CREATE TABLE a_stock_everyday_data (
trade_date DATE, -- Trading date交易日期,以纯数字形式给出,例如20240515
open DECIMAL(10,2), -- Opening price开盘价
high DECIMAL(10,2), -- Highest price当日最高价
low DECIMAL(10,2), -- Lowest price当日最低价
close DECIMAL(10,2), -- Closing price收盘价
pre_close DECIMAL(10,2), -- Previous closing price前一天的收盘价
change DECIMAL(10,2), -- Price change股价变化
pct_chg DECIMAL(10,2), -- Price change percentage股价变化率
vol BIGINT, -- Trading volume成交额
amount DECIMAL(15,2), -- Trading amount成交量
);
<|eot_id|><|start_header_id|>assistant<|end_header_id|>
The following SQL query best answers the question `{question}`:
```sql
"""构建完成模型输入后,我们需要调用LLM并生成对应结果,在LLM输出结果后,还需要进行解析和格式化处理,为了便于代码复用,我们将调用流程封装为以下函数:
def generate_query(question):
updated_prompt = prompt.format(question=question)
inputs = tokenizer(updated_prompt, return_tensors="pt").to("cuda")
# 生成SQL语句的参数,确保do_sample=False以保证生成的SQL语句是确定性的并且可复现
generated_ids = model.generate(
**inputs,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.eos_token_id,
max_new_tokens=400,
do_sample=False,
num_beams=1,
)
outputs = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
torch.cuda.empty_cache()
torch.cuda.synchronize()
return outputs[0].split("```sql")[1].split(";")[0]最后,是接收用户输入并调用模型获取SQL查询语句,在通过spark进行SQL查询的代码:
while(True):
question = input("请输入一个问题:")
if question == "exit":
break
generated_sql = generate_query(question)
print("->LLM生成的SQL语句为:",end='')
print(sqlparse.format(generated_sql, reindent=True))
sql_result = spark.sql(generated_sql)
print("->查询结果为:")
sql_result.show()4.2实验结果
1.查询2024年股价最高的日子
LLM针对问题生成SQL查询语句,该语句直接被用与查询数据库。

2.查询20年来最高的开盘价

3.查询某一天的数据

五、数据可视化
为了使分析结果更加直观,本次实验还根据不同的分析项目设计了不同可视化结果。可视化主要通过matplotlib实现。
1.可视化每年股票的平均交易量
这里使用柱状图展示每年股票的平均交易量,可以直观体现出每一年的交易活跃度,其中2015年为整个市场的牛市,交易量显著高于其它年份。
代码如下:
#读取文件
yearly_avg_volume = pd.read_csv("result/yearly_avg_volume.csv", index_col=0)
# 绘制柱状图
plt.figure(figsize=(12, 6))
plt.bar(yearly_avg_volume['year'], yearly_avg_volume['avg(vol)'], color='b', label='Average Volume')
# 设置图表标题和标签
plt.title('Yearly Average Stock Volume')
plt.xlabel('Year')
plt.ylabel('Average Volume')
plt.savefig("result/yearly_avg_volume.png")
2.可视化收盘价与各数据的的相关性
同样使用柱状图展示,代码如下:
#读取文件
correlation = pd.read_csv("result/correlation.csv", index_col=0)
# 绘制柱状图
plt.figure(figsize=(12, 6))
plt.bar(correlation.columns, correlation.iloc[0], color='b', label='Correlation')
# 设置图表标题和标签
plt.title('Correlation between Closing Price and Other Data')
plt.xlabel('Data')
plt.ylabel('Correlation')
plt.savefig("result/correlation.png")
3.可视化每年股票上涨和下跌天数的比例
为了直观展示各年之间上涨的下跌天数的对比,这里采用堆叠的柱状图进行可视化,并以绿色和红色直观的代表上涨和下跌。
代码如下:
# 将下跌天数变为负值
year_up_down_days['down_ratio'] = -year_up_down_days['down_ratio']
# 绘制柱状图,对齐红绿交界处
plt.figure(figsize=(12, 6))
plt.bar(year_up_down_days['year'], year_up_down_days['up_ratio'], color='g', label='Up Days Ratio')
plt.bar(year_up_down_days['year'], year_up_down_days['down_ratio'], color='r', label='Down Days Ratio')
# 设置图表标题和标签
plt.title('Yearly Stock Up and Down Days Ratio')
plt.xlabel('Year')
plt.ylabel('Ratio')
plt.savefig("result/year_up_down_days_ratio.png")
可以看见,在近几年绿色柱逐渐变小,而红色柱逐年增长,说明了下跌天数的占比逐渐变高,贵州茅台股票的行情转弱。
4.可视化每个月涨跌停次数
为了体现出涨跌停与月度关系,并体现出其相关性,这里采用饼状图展示。
# 绘制饼状图
plt.figure(figsize=(12, 12))
#部分月份为0,删去
month_limit_up_down = month_limit_up_down[month_limit_up_down['limit_up_down_count'] != 0]
plt.pie(month_limit_up_down['limit_up_down_count'], labels=month_limit_up_down.index, autopct='%1.1f%%', startangle=90)
plt.title('Monthly Limit Up and Down Days Count')
plt.savefig("result/monthly_limit_up_down.png")
可以直观看出大多数涨跌停出现在三、四月份,说明三四月份贵州茅台行情波动大。
5.可视化不同市场环境下的股票数据
为了体现出不同环境下各个指标的区别,这里选择簇状柱状图进行可视化,同时,考虑到各个指标的数据量级不一样,还需要进行适当放缩,以便其在同一张图上显示。
# 创建图表和坐标轴
fig, ax = plt.subplots(figsize=(12, 6))
# 指标名称
indicators = ['total_peTTM', 'total_volume', 'num_of_days', 'avg_volume', 'avg_peTTM']
# 对某些指标进行缩放
scale_factors = {'total_peTTM': 1e-5, 'total_volume': 1e-8, 'num_of_days': 1e-3, 'avg_volume': 1e-5, 'avg_peTTM': 1e-1}
# 数据准备
n_groups = len(indicators)
index = np.arange(n_groups) # 指标数量
bar_width = 0.25
opacity = 0.8
# 循环绘制每个市场状态
condition_name = ['sideway','bull','bear']
for i, condition in enumerate(market_env.index):
values = market_env.loc[condition, indicators] * pd.Series(scale_factors)
plt.bar(index + i * bar_width, values, bar_width,
alpha=opacity, label=f'Market Condition: {condition_name[i]}')
# 设置图表标题和标签
plt.title('Comparison of Market Conditions Across Different Indicators')
plt.xlabel('Indicators')
plt.ylabel('Scaled Values')
plt.xticks(index + bar_width, indicators)
可见波动的市场占据大多数天数,并且在波动的市场下,平均交易量和peTTM都会更低。
6.可视化贵州茅台的股票价格趋势
当需要反映数据趋势时,通常选择折线图,股价的波动也适合用折线图来表示。
# 获取最大和最小的收盘价
max_close = pandas_df['close'].max()
min_close = pandas_df['close'].min()
# 把pandas_df['trade_date']转换为list
trade_date_list = pandas_df['trade_date'].tolist()
close_list = pandas_df['close'].tolist()
# 绘制折线图
plt.figure(figsize=(25, 12))
plt.plot(trade_date_list, close_list, marker='o', linestyle='-', color='royalblue', markersize=1, linewidth=2, label='Close Price')
plt.title('Price Trend', fontsize=30)
plt.xlabel('Trade Date', fontsize=20)
plt.ylabel('Closing Price', fontsize=20)
plt.xticks(rotation=45)
plt.grid(True, linestyle='--', linewidth=0.5)
plt.tick_params(axis='both', labelsize=14)
plt.ylim(min_close * 0.9, max_close * 1.1)
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
plt.gca().xaxis.set_major_locator(mdates.AutoDateLocator())
plt.tight_layout() # 自动调整布局20年来股价变化趋势:

近一年股价变化趋势:

六、总结
本次实验在Ubuntu 16.04操作系统上,利用Hadoop 3.3.5和Spark 3.2.0框架,结合Python 3.8和JDK 1.8,对贵州茅台公司自2004年1月1日至今的每日股票行情数据进行了深入分析。实验首先通过Tushare和Baostock两个开源接口获取数据,并使用pandas库进行数据预处理,处理了数据缺失和异常值,然后将清洗后的数据上传至HDFS。
数据分析阶段,我们运用Spark和Python对数据进行了多维度的分析,包括计算年均交易量、收盘价波动性、涨跌幅与其他财务指标的相关性、月份涨跌停次数、不同市场环境下的股票表现等。此外,还查询了特定时间段内的最高和最低股价,计算了平均涨幅,并统计了每年的上涨和下跌天数。
为了提高数据分析的准确性和用户交互的便捷性,本实验引入了大型语言模型(LLM),通过生成SQL查询语句,将用户的自然语言问题转化为数据库查询,再通过Spark执行并展示结果。所选模型sqlcoder-7b-2在Text2SQL任务上进行了微调,有效提升了查询的准确性和效率。
数据可视化方面,实验采用了matplotlib库,通过柱状图、饼状图、簇状柱状图和折线图等多种形式,直观展示了分析结果。这些图表不仅增强了数据的可读性,也帮助用户更直观地理解股票市场的趋势和模式。
总结来说,本次实验成功地展示了如何综合运用大数据技术、人工智能和数据可视化工具,对股票市场数据进行高效处理和深入分析。实验结果不仅为投资者提供了有价值的市场洞察,也证明了结合大数据分析和LLM在提升用户体验和数据处理能力方面的潜力。通过本次实验,我也加深了对大数据处理流程的理解,并提高了在实际问题中应用数据分析技术的能力。