
【版权声明】版权所有,严禁转载,严禁用于商业用途,侵权必究。
作者:厦门大学计算机科学与技术系2023级研究生 田紫格
指导老师:厦门大学数据库实验室 林子雨 博士/副教授
时间:2024年6月
相关教材:林子雨编著《Flink编程基础(Java版)》(访问教材官网)
相关案例:Flink大数据处理分析案例集锦
本案例使用Java语言编写Flink程序。使用Python语言进行数据清洗,保存到分布式文件系统HDFS中,接下来使用Java语言编写Flink程序进行数据分析,使用Idea创建Maven项目,最后,利用python的matplotlib库完成可视化工作。
数据集和代码下载:从百度网盘下载本案例的代码和数据集。(提取码是ziyu)
一、实验环境
1 系统:Ubuntu 16.04
2 编程语言:Java,Python 3.8.0
3 Java环境:JDK 1.8.0_371
4 框架:Flink-1.17.0,Hadoop-3.3.5,Maven-3.9.2
5 开发工具:Jupyter Notebook,Idea-2024.1.1,Pycharm
二、数据集
数据集介绍:
这个数据集包含了一份销量超过100,000份的视频游戏列表。
字段包括:
排名(Rank)- 总销量排名
名称(Name)- 游戏名称
平台(Platform)- 游戏发布的平台(例如PC、PS4等)
年份(Year)- 游戏发布的年份
类型(Genre)- 游戏的类型
发行商(Publisher)- 游戏的发行商
NA销量(NA_Sales)- 北美地区的销售额(单位:百万)
EU销量(EU_Sales)- 欧洲地区的销售额(单位:百万)
JP销量(JP_Sales)- 日本地区的销售额(单位:百万)
其他地区销量(Other_Sales)- 世界其他地区的销售额(单位:百万)
全球销量(Global_Sales)- 全球总销售额
三、数据预处理
本节使用Jupyter Notebook,使用Python3。
首先导入包,读取原始数据,并查看:
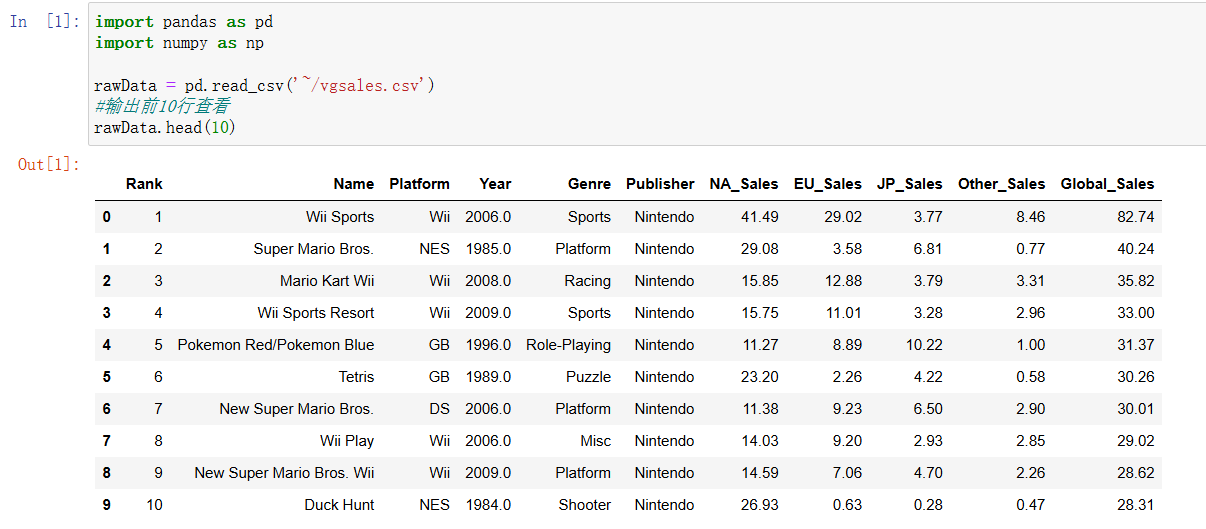
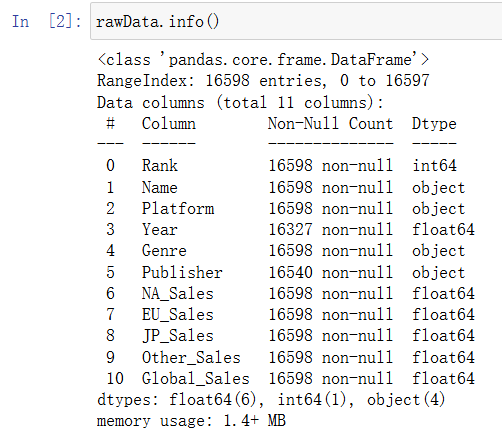
观察到有空值存在,并且Year字段的类型为object,首先进行去除空值和重复值处理:
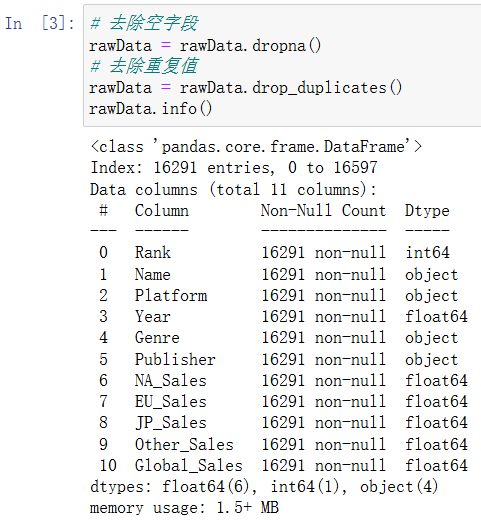
可以看到已经去除了空值和重复值,接着我们将Year字段改为Int类型,便于后续的处理和分析:
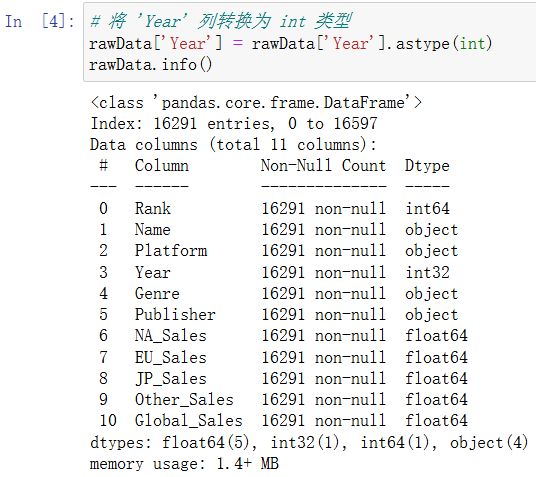
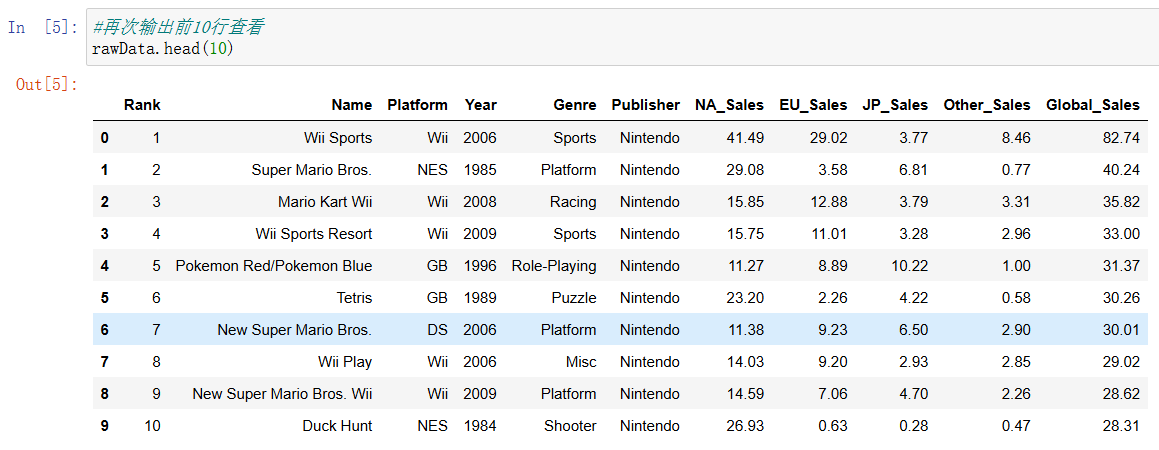
可以看到Year字段已经变为整数类型,最后我们将处理后的数据写入csv文件,这里为了后续读取数据的正确性,这里将分隔符设置为“|”,因为观察到部分游戏名字中含有“,”。

处理后的数据文件命名为“cleaned_vgsales.csv”,接着将其上传至HDFS,为使用Flink做数据处理做准备。在启动Hadoop后进行如下操作:
./bin/hdfs dfs -mkdir -p /user/hadoop
./bin/hdfs dfs -mkdir input
./bin/hdfs dfs -put /home/hadoop/桌面/dataset/cleaned_vgsales.csv input
./bin/hdfs dfs -ls /user/hadoop/input需要处理的数据文件已经上传至HDFS,存放目录为“/user/hadoop/input”。
四、数据处理
本节使用Idea创建Maven项目,Java环境为JDK 1.8.0_371。
数据处理主要分为一下几个任务进行:
1 统计每个游戏平台上的游戏数量和总销售额,以了解各平台的市场份额。
2 统计每个出版商发布的游戏数量和总销售额,以了解各出版商销售额情况。
3 计算不同游戏类型的数量及平均销售额,以了解各类型游戏市场表现和受欢迎程度。
4 统计每年发布的游戏数量和总销售额,以了解这几十年电子游戏的发展。
5 统计每年游戏数量最多游戏类型及其数量,以了解主流游戏类型随着时间推移的变化。
6 分别统计北美、欧洲、日本、全球销售前十的游戏及其类型,以了解不同地区的游戏偏好以及最受欢迎的游戏。
7 统计不同地区的总销售额,以了解不同地区占的市场份额。
8 统计每年总销售额最高的游戏,以了解每年的年度游戏。
(一)读取输入数据
在Idea上创建Maven项目工程,并为项目配置必要的依赖(Flink、Hadoop等)。
首先读取HDFS上的数据文件:
//创建一个 Flink 的流执行环境 env
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
//定义输入文件的 HDFS 路径和输出结果的本地文件系统路径
String HDFSInputPath="hdfs://localhost:9000/user/hadoop/input/cleaned_vgsales.csv";
String OutputPath="/home/hadoop/桌面/dataset/ResultData/";
//从 HDFS 中读取 CSV 文件,并转换输入数据为 Tuple 数据
DataStreamSource<String> InputData = env.readTextFile(HDFSInputPath);
DataStream<Tuple11<Integer, String, String, Integer, String, String, Float,
Float, Float, Float, Float>> vgsales =
InputData.flatMap(new ParseCsvToTuple());
//设置运行模式为批处理模式(BATCH)
env.setRuntimeMode(RuntimeExecutionMode.BATCH);ParseCsvToTuple 是一个实现了 FlatMapFunction 接口的静态内部类,用于将 CSV 文件中的每一行数据解析并转换为一个包含 11 个字段的 Tuple (Tuple11) 对象。该类的主要目的是处理从 CSV 文件读取的原始字符串数据,并将其转换为结构化的元组数据,以便后续的数据处理和分析。
public static final class ParseCsvToTuple implements FlatMapFunction<String,
Tuple11<Integer, String, String, Integer, String, String,
Float, Float, Float, Float, Float>> {
private static boolean isFirstLine = true;
@Override
public void flatMap(String value, Collector<Tuple11<Integer, String, String, Integer,
String, String, Float, Float, Float, Float, Float>> out) throws Exception {
if (isFirstLine) {//第一行不做处理
isFirstLine = false;
return; }
// CSV数据是以竖线分隔的
String[] fields = value.split("\\|");
// 检查fields数组是否有足够的元素来创建一个Tuple11
if (fields.length >= 11) {
// 将String数组的元素转换为Tuple11的类型
Integer Rank = Integer.parseInt(fields[0]);
String Name = fields[1];
String Platform = fields[2];
Integer Year = Integer.parseInt(fields[3]);
String Genre= fields[4];
String Publisher = fields[5];
Float NA_Sales = Float.parseFloat(fields[6]) ;
Float EU_Sales = Float.parseFloat(fields[7]) ;
Float JP_Sales = Float.parseFloat(fields[8]) ;
Float Other_Sales = Float.parseFloat(fields[9]) ;
Float Global_Sales = Float.parseFloat(fields[10]) ;
// 创建Tuple11对象并收集它
out.collect(new Tuple11<>(Rank, Name, Platform, Year, Genre, Publisher,
NA_Sales, EU_Sales, JP_Sales, Other_Sales, Global_Sales));
} else {
System.err.println("Does not have enough fields: " + value);
}
}
}输入数据:Tuple11<Rank, Name, Platform, Year, Genre, Publisher, NA_Sales, EU_Sales, JP_Sales, Other_Sales, Global_Sales>
(二)进行数据统计分析
输入数据按照游戏平台、出版商等划分,同一款游戏可能在多个平台上售卖,不同平台上同一款游戏的体验不尽相同,并且也是作为不同的游戏商品售卖单元,因此下面的数据处理当做不同的游戏商品统计。
1.统计每个游戏平台上的游戏数量和总销售额,并按销售额排序
//数据处理和汇总
DataStream<Tuple3<String, Long, Float>> PlatformSum = vgsales
.map(value -> new Tuple3<>(value.f2, 1L, value.f10))
.returns(Types.TUPLE(Types.STRING, Types.LONG, Types.FLOAT))
.keyBy(value -> value.f0)
.reduce((value1, value2) -> new Tuple3<>(value1.f0, value1.f1 + value2.f1,
value1.f2 + value2.f2)); 使用 map 操作将原始数据流 vgsales 转换为包含平台名称、计数(初始为1)和销售额的 Tuple3 数据流。使用 returns 方法显式指定 map 操作的返回类型为 Tuple3<String, Long, Float>。使用 keyBy 方法按平台名称(第一个字段)进行分组。使用 reduce 操作对每个平台的计数和销售额进行累加,得到每个平台的总销售数量和总销售额。
//用时间窗口排序
DataStream<Tuple3<String, Long, Float>> SortedPlatformSum =
PlatformSum.keyBy(value -> 1)
.window(TumblingProcessingTimeWindows.of(Time.seconds(20)))
.process(new SortProcessFunction());将汇总后的数据流 PlatformSum 再次进行分组,这次使用一个固定键(1)进行分组,以便将所有数据放在一个组中处理。使用 window 方法定义一个滑动时间窗口,窗口大小为20秒。使用 process 方法,并传入 SortProcessFunction 类,按销售额对每个窗口内的数据进行排序。
//输出结果 文件存储数据(平台,计数,销售额),并按降序排列。
SortedPlatformSum.writeAsCsv(OutputPath+"PlatformSum.csv").setParallelism(1);将排序后的数据流 SortedPlatformSum 输出为 CSV 文件,输出文件名为 "PlatformSum.csv"。使用 setParallelism(1) 方法设置并行度为1,确保输出结果按顺序写入文件。
SortProcessFunction 类继承自 ProcessWindowFunction。process 方法接收一个键(key)、上下文(context)、元素迭代器(elements)和收集器(out),并将元素排序后输出。具体操作为将元素添加到列表中,然后按销售额(第3个字段)进行排序。最后使用 Collections.reverse 方法将排序结果反转,以便按降序排列。
public static class SortProcessFunction extends ProcessWindowFunction<Tuple3<String, Long, Float>,
Tuple3<String, Long, Float>, Integer, TimeWindow> {
@Override
public void process(Integer key, Context context, Iterable<Tuple3<String, Long, Float>> elements,
Collector<Tuple3<String, Long, Float>> out) throws Exception {
// 将元组放入列表中
List<Tuple3<String, Long, Float>> list = new ArrayList<>();
for (Tuple3<String, Long, Float> element : elements) {
list.add(element);
//System.out.println(element);
}
// 对列表中的元组按照第3个字段进行排序
list.sort(Comparator.comparingDouble(tuple -> tuple.f2));
//System.out.println(list);
Collections.reverse(list);
// 输出排序后的元组
for (Tuple3<String, Long, Float> tuple : list) {
out.collect(tuple);
}
}
}2.统计每个出版商发布的游戏数量和总销售额,并按销售额排序
//按出版商进行统计
DataStream<Tuple3<String, Long, Float>> PublisherSum = vgsales
.map(value -> new Tuple3<>(value.f5, 1L, value.f10)) // 映射到类别和1
.returns(Types.TUPLE(Types.STRING, Types.LONG, Types.FLOAT))
.keyBy(value -> value.f0) // 按照类别分组
.reduce((value1, value2) -> new Tuple3<>(value1.f0, value1.f1 + value2.f1,
value1.f2 + value2.f2)); // 对计数字段进行累加
DataStream<Tuple3<String, Long, Float>> SortedPublisherSum=PublisherSum
.keyBy(value -> 1)
.window(TumblingProcessingTimeWindows.of(Time.seconds(20))) // 定义窗口大小
.process(new SortProcessFunction());
//文件存储数据(出版商,计数,销售额),并按降序排列。
SortedPublisherSum.writeAsCsv(OutputPath+"PublisherSum.csv").setParallelism(1);处理方法同上,这里的Tuple3第一个字段为出版商,进行数据汇总后调用上述静态类进行按销售额排序,然后输出结果文件。
3.计算不同游戏类型的数量及平均销售额,并按平均销售额降序排列
//按Genre进行数量和销售额汇总
DataStream<Tuple3<String, Long, Float>> GenreSum = vgsales
.map(value -> new Tuple3<>(value.f4, 1L, value.f10)) // 映射到类别和1
.returns(Types.TUPLE(Types.STRING, Types.LONG, Types.FLOAT))
.keyBy(value -> value.f0) // 按照类别分组
.reduce((value1, value2) -> new Tuple3<>(value1.f0, value1.f1 + value2.f1,
value1.f2 + value2.f2)); // 对计数字段进行累加
//根据汇总结果计算平均每款游戏商品的销售额
DataStream<Tuple3<String, Long, Float>> GenreAverage = GenreSum
.map(value -> new Tuple3<>(value.f0, value.f1, value.f2 / value.f1))
.returns(Types.TUPLE(Types.STRING, Types.LONG, Types.FLOAT)); // 计算平均值
DataStream<Tuple3<String, Long, Float>> SortedGenreAverage=GenreAverage.keyBy(value->1)
.window(TumblingProcessingTimeWindows.of(Time.seconds(20)))
.process(new SortProcessFunction());
//文件存储数据(类型,计数,平均销售额),并按降序排列。
SortedGenreAverage.writeAsCsv(OutputPath+"GenreAverage.csv").setParallelism(1);处理方法大致与前面的汇总方法相似,这里的Tuple3第一个字段为游戏类型,在进行汇总后进行平均销售额的计算,最终进行排序并且输出的为平均销售额。这是为了排除游戏数量的影响,以观察游戏类型的受欢迎程度。
4.统计每年发布的游戏数量和总销售额
//按年份汇总销售数据
DataStream<Tuple3<Integer, Long, Float>> YearSum = vgsales
.map(value -> new Tuple3<>(value.f3, 1L, value.f10)) // 映射到类别和1
.returns(Types.TUPLE(Types.INT, Types.LONG, Types.FLOAT))
.keyBy(value -> value.f0) // 按照类别分组
.reduce((value1, value2) -> new Tuple3<>(value1.f0, value1.f1 + value2.f1, value1.f2 + value2.f2)); // 对计数字段进行累加
//输出结果,文件存储数据(年份,计数,销售额),结果自动按年份(整型)排序
YearSum.writeAsCsv(OutputPath+"YearSum.csv").setParallelism(1);map 操作将原始数据流 vgsales 转换为包含年份(value.f3)、计数(1)和总销售额(value.f10)的 Tuple3 数据流。returns 方法显式指定 map 操作的返回类型为 Tuple3<Integer, Long, Float>。keyBy 方法按年份(第一个字段)进行分组。reduce 操作对每个分组内的计数和销售额进行累加,得到每年的总销售数量和总销售额。然后将累加后的数据流 YearSum 输出为 CSV 文件,文件名为"YearSum.csv"。
5.统计每年发布各游戏类型的游戏数量,记录每年最多游戏数的游戏类型
//每年游戏商品最多的游戏类型
DataStream<Tuple3<Integer, String, Long>> yearlyGameGenre = vgsales
.map(value -> new Tuple3<>(value.f3, value.f4, 1L)) // 映射到类别和1
.returns(Types.TUPLE(Types.INT, Types.STRING, Types.LONG))
.keyBy(new KeySelector<Tuple3<Integer, String, Long>, Tuple2<Integer, String>>() {
@Override
public Tuple2<Integer, String> getKey(Tuple3<Integer, String, Long> value) throws Exception {
return new Tuple2<>(value.f0, value.f1); // Group by genre }
}) // Group by (Year, Genre)
.reduce((value1, value2) -> new Tuple3<>(value1.f0, value1.f1, value1.f2 + value2.f2))
.keyBy(0)
.maxBy(2);
//输出结果,文件存储数据(年份,最多游戏数量的游戏类型,此年份该类型游戏个数),结果自动按年份(整型)排序
yearlyGameGenre.writeAsCsv(OutputPath+"yearlyGameGenre.csv").setParallelism(1);map 操作:将原始数据流 vgsales 转换为包含年份(value.f3)、类别(value.f4)和计数(1)的 Tuple3 数据流。returns 方法:显式指定 map 操作的返回类型为 Tuple3<Integer, String, Long>。keyBy 方法:定义一个 KeySelector,按年份和类别(Tuple2<Integer, String>)分组。reduce 操作:对每个(年份,类别)分组内的计数进行累加。
再次分组和排序:按年份(第一个字段)再次分组,并使用 maxBy 选择每个分组中计数最多的类别。最后将处理后的数据流 yearlyGameGenre 输出为 CSV 文件,文件名"yearlyGameGenre.csv"。
6.分别统计北美、欧洲、日本、全球销售前十的游戏及其类型
1)北美、欧洲、日本地区销售前十
以下代码通过三个主要步骤对北美、欧洲和日本地区的游戏销售数据进行汇总分析,并找出每个地区销售额最高的前10个游戏。自定义的 TopNProcessFunction 类使用最小堆和降序排序来实现对窗口内元素的排序。最终的处理结果输出为三个 CSV 文件,分别保存不同地区的分析结果。
//统计北美销售前十的游戏单品,输出数据存储(游戏,类型,销售额)
DataStream<Tuple3<String, String, Float>> NA_sales = vgsales
.map(value -> new Tuple3<>(value.f1, value.f4, value.f6)) // 映射到类别和1
.returns(Types.TUPLE(Types.STRING, Types.STRING, Types.FLOAT));
DataStream<Tuple3<String, String, Float>> Top10NA_sales= NA_sales
.keyBy(value -> 1) // 所有数据进入同一个组
.window(TumblingProcessingTimeWindows.of(Time.minutes(1)))
.process(new TopNProcessFunction(10)); // 自定义处理函数,找到最大的N个元素
Top10NA_sales.writeAsCsv(OutputPath+"Top10NA_sales.csv").setParallelism(1);
//统计欧洲销售前十的游戏单品,输出数据存储(游戏,类型,销售额)
DataStream<Tuple3<String, String, Float>> EU_sales = vgsales
.map(value -> new Tuple3<>(value.f1, value.f4, value.f7)) // 映射到类别和1
.returns(Types.TUPLE(Types.STRING, Types.STRING, Types.FLOAT));
DataStream<Tuple3<String, String, Float>> Top10EU_sales=EU_sales.keyBy(value -> 1)
.window(TumblingProcessingTimeWindows.of(Time.minutes(1)))
.process(new TopNProcessFunction(10)); // 自定义处理函数,找到最大的N个元素
Top10EU_sales.writeAsCsv(OutputPath+"Top10EU_sales.csv").setParallelism(1);
//统计日本销售前十的游戏单品,输出数据存储(游戏,类型,销售额)
DataStream<Tuple3<String, String, Float>> JP_sales = vgsales
.map(value -> new Tuple3<>(value.f1, value.f4, value.f8)) // 映射到类别和1
.returns(Types.TUPLE(Types.STRING, Types.STRING, Types.FLOAT));
DataStream<Tuple3<String, String, Float>> Top10JP_sales=JP_sales.keyBy(value -> 1)
.window(TumblingProcessingTimeWindows.of(Time.minutes(1)))
.process(new TopNProcessFunction(10)); // 自定义处理函数,找到最大的N个元素
Top10JP_sales.writeAsCsv(OutputPath+"Top10JP_sales.csv").setParallelism(1);map 操作:分别将原始数据流 vgsales 转换为包含游戏名称(value.f1)、类别(value.f4)和各地区销售额(北美:value.f6 欧洲:value.f7 日本:value.f8)的 Tuple3 数据流。returns 方法:显式指定 map 操作的返回类型为 Tuple3<String, String, Float>。keyBy 方法:使用固定键(1)将所有数据分到同一个组。window 方法:定义一个1分钟的滚动窗口。process 方法:使用自定义的 TopNProcessFunction 找出销售额最高的前10个游戏。输出结果:将前10个游戏的销售数据输出为 CSV 文件,对应各自的销售前十游戏输出文件名称。
TopNProcessFunction 类继承自 ProcessWindowFunction,用于处理窗口内的元素,找到销售额最高的前 N 个游戏。topSize 字段存储前 N 个游戏的数量。构造函数接受一个 topSize 参数,用于初始化前 N 个游戏的数量。process 方法接收一个键(key)、上下文(context)、元素迭代器(input)和收集器(out),并找到销售额最高的前 N 个游戏。
这里使用 PriorityQueue(最小堆)来维护最大的 N 个元素。将输入元素添加到堆中,如果堆的大小超过 topSize,则移除堆顶元素。最后堆中的元素按降序排序并输出即为前N个元素
public static class TopNProcessFunction extends ProcessWindowFunction<Tuple3<String, String, Float>,Tuple3<String, String, Float>, Integer, TimeWindow> {
private final int topSize;
public TopNProcessFunction(int topSize) {this.topSize = topSize;}
@Override
public void process(Integer key, Context context, Iterable<Tuple3<String, String, Float>> input,
Collector<Tuple3<String, String, Float>> out) throws Exception {
// 使用最小堆来维护最大的N个元素
PriorityQueue<Tuple3<String, String, Float>> priorityQueue =
new PriorityQueue<>(Comparator.comparing(t -> t.f2));
// 加载当前状态中的元素到最小堆
for (Tuple3<String, String, Float> item : input) {
priorityQueue.offer(item);
}
// 如果堆的大小超过topSize,则移除堆顶元素
while (priorityQueue.size() > topSize) {
priorityQueue.poll();}
// 输出当前的Top N
List<Tuple3<String, String, Float>> topN = new ArrayList<>(priorityQueue);
topN.sort(Comparator.comparing(t -> -t.f2)); // 按降序排序
for (Tuple3<String, String, Float> tuple : topN){
out.collect(tuple);
}
}
}2)全球销售前十
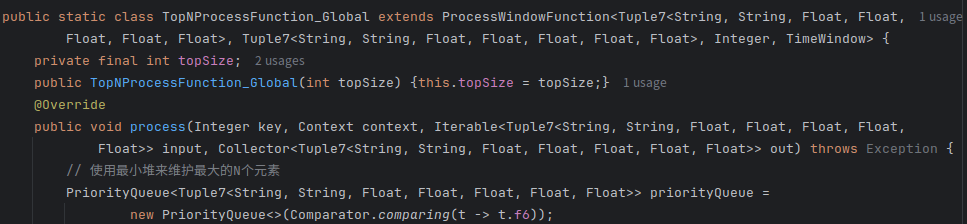
由于统计全球销售前十数据时希望记录下各个地区的市场份额,这里对前面寻找单个地区销售前十的方法进行了扩展,多记录了四个Float数据(NA_Sales, EU_Sales, JP_Sales, Other_Sales),同时由于记录数据格式的改变,process方法里面的参数也需要进行对应的调整,因此按照TopNProcessFunction 的方法定义了TopNProcessFunction_Global类以得到全球销售前十的完整销售数据。TopNProcessFunction_Global类同样继承自ProcessWindowFunction,与TopNProcessFunction的唯一不同是处理元素由之前的Tuple3<String, String, Float>变为Tuple7<String, String, Float, Float, Float, Float, Float>,这里的排序逻辑仍然相同,用来排序的值仅为最后一个Float数据(全球销售额),单个地区的销售额作为信息保存即可。

TopNProcessFunction_Global类定义部分代码:
7.统计不同地区的总销售额
//计算北美(NA)、欧洲(EU)、日本(JP)和其他地区的总销售额
DataStream<Tuple4<Float ,Float, Float, Float>> Sales_Sum = vgsales
.map(value -> new Tuple4<>(value.f6, value.f7, value.f8, value.f9)) // 映射到类别和1
.returns(Types.TUPLE(Types.FLOAT, Types.FLOAT, Types.FLOAT, Types.FLOAT))
.keyBy(value -> 1) // 按照类别分组
.reduce((value1, value2) -> new Tuple4<>(value1.f0 + value2.f0, value1.f1 + value2.f1, value1.f2 + value2.f2, value1.f3 + value2.f3)); // 对计数字段进行累加
//输出结果,文件存储(北美销售总额,欧洲销售总额,日本销售总额,其他地区销售总额)
Sales_Sum.writeAsCsv(OutputPath+"Sales_Sum.csv").setParallelism(1); // 设置为1以保证文件顺序map 操作:将原始数据流 vgsales 转换为包含北美(value.f6)、欧洲(value.f7)、日本(value.f8)和其他地区销售额(value.f9)的 Tuple4 数据流。keyBy 方法:使用固定键(1)将所有数据分到同一个组,这样所有的销售数据会被累加到一起。reduce 方法:对每个分组内的 Tuple4 元素进行累加操作,得到每个地区的总销售额。
value1.f0 + value2.f0:累加北美销售额。
value1.f1 + value2.f1:累加欧洲销售额。
value1.f2 + value2.f2:累加日本销售额。
value1.f3 + value2.f3:累加其他地区销售额。
8.统计每年总销售额最高的游戏
//每年销售额最高的游戏商品
DataStream<Tuple3<Integer, String, Float>> yearlyGame = vgsales
.map(value -> new Tuple3<>(value.f3, value.f1, value.f10)) // 映射到类别和1
.returns(Types.TUPLE(Types.INT, Types.STRING, Types.FLOAT))
.keyBy(0)
.maxBy(2);
//输出结果,文件存储数据(年份,单品最高销售额的游戏,此年份该游戏商品销售额),结果自动按年份(整型)排序
yearlyGame.writeAsCsv(OutputPath+"yearlyGame.csv").setParallelism(1);map 操作:将原始数据流 vgsales 转换为包含年份(value.f3)、游戏名称(value.f1)和销售额(value.f10)的 Tuple3 数据流。returns 方法:显式指定 map 操作的返回类型为 Tuple3<Integer, String, Float>。
keyBy 方法:按年份(第一个字段)分组。maxBy 操作:选择每个分组中销售额最高的游戏。最后将处理后的数据流 yearlyGame 输出为 CSV 文件,文件名为"yearlyGame.csv"。
运行以上所有代码可得到实验处理结果,存放在“OutputPath”目录(/home/hadoop/桌面/dataset/ResultData):

五、实验结果可视化
本节使用Pycharm创建Python项目,语言版本为Python3.8.0。
使用到的包如下:
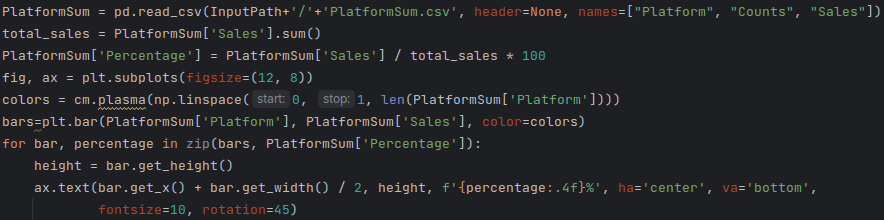
(1)各游戏平台的市场份额。
读取 CSV 文件中的平台销售数据,计算每个平台销售额占总销售额的百分比,并绘制柱状图来可视化销售数据。
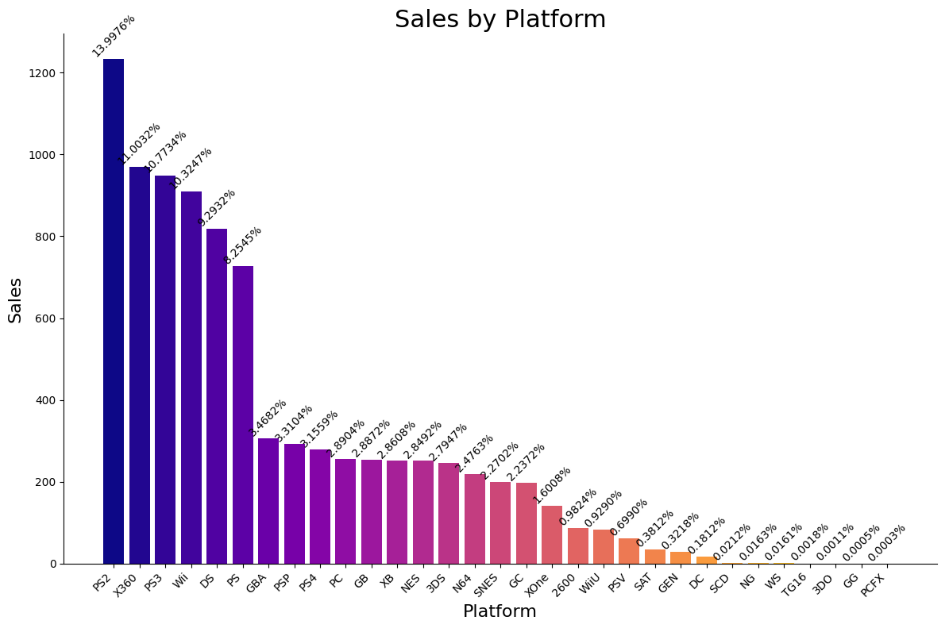
主流平台:PS2、X360、PS3、Wii 和 DS 这些平台占据了大部分市场份额,销售额分别占总销售额的 14%、11%、10.8%、10.3% 和 9.3%。
次主流平台:PS、GBA、PSP、PS4 和 PC 也具有较大的市场份额,销售额占比分别为 8.25%、3.47%、3.31%、3.16% 和 2.89%。
其他平台:其他平台的市场份额相对较小,特别是一些较老的或者不太流行的平台(如 GG 和 PCFX)几乎可以忽略不计。
(2)各出版商销售额情况
绘制各出版商销售额的柱状图,游戏出版商有五百多个,这里选取销售额排名前50的出版商数据进行可视化,便于分析。

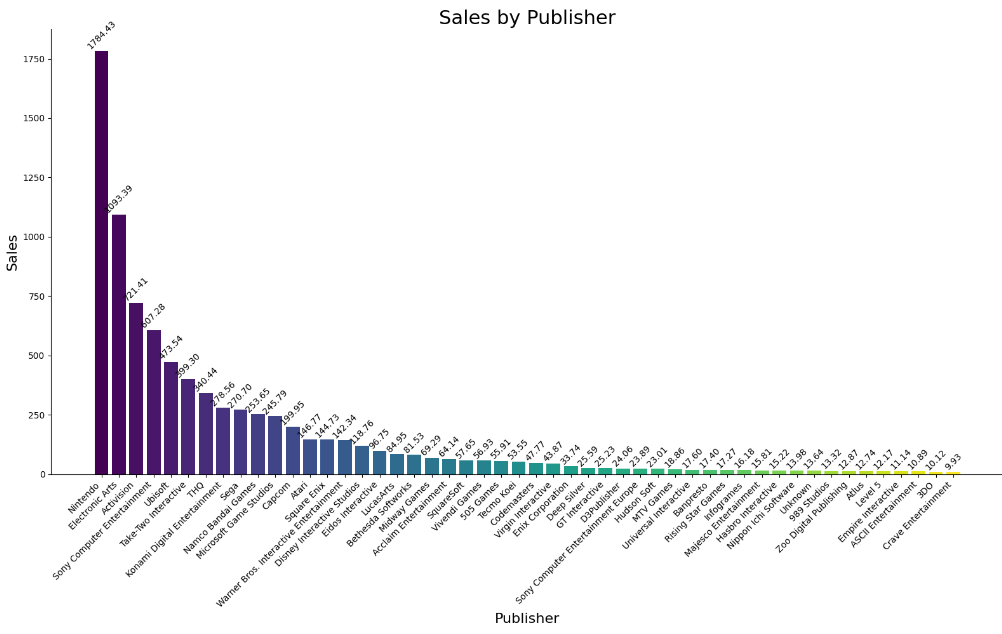
Nintendo 以1784.43百万美元的销售额遥遥领先,成为游戏市场的主导者。Electronic Arts 以1093.39百万美元的销售额位居第二,表现强劲。
前面几个出版商(Nintendo、Electronic Arts、Activision、Sony Computer Entertainment、Ubisoft等)占据了大部分市场份额,显示出市场的高度集中化。其余出版商则共同分享剩余的市场份额,竞争激烈。
(3)各游戏类型游戏数和平均销售额
绘制不同类型的游戏数量环形图,这里突出显示游戏数超过1300的游戏类型。
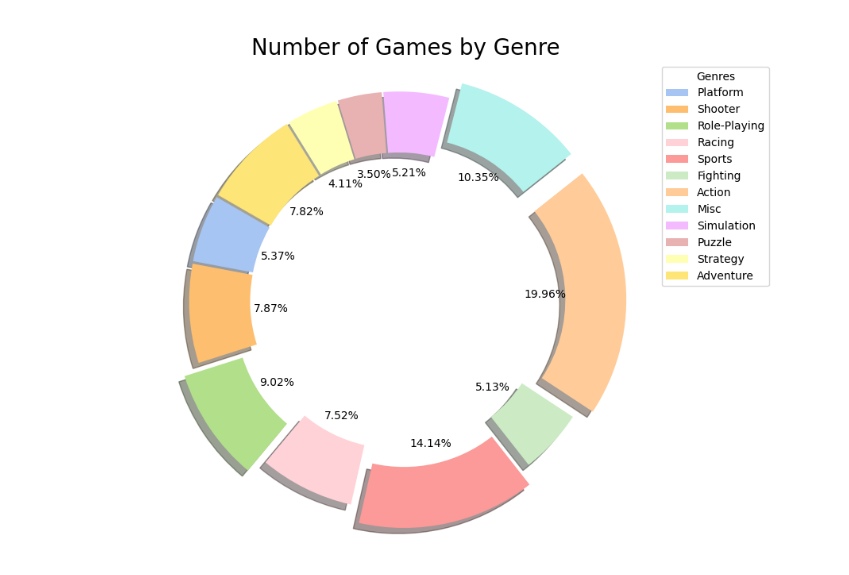
Action、Sports 和 Misc、Fighting类别拥有数量最多的游戏,分别占据了游戏总数的19.96%、14.14%、10.35%、9.02%,显示出这些类别在游戏市场中的活跃程度。总体来看,游戏数量分布呈现出一定的不均衡性,部分类别拥有大量游戏,而另一些类别则较少。
绘制不同类型的游戏平均销售额的柱状图

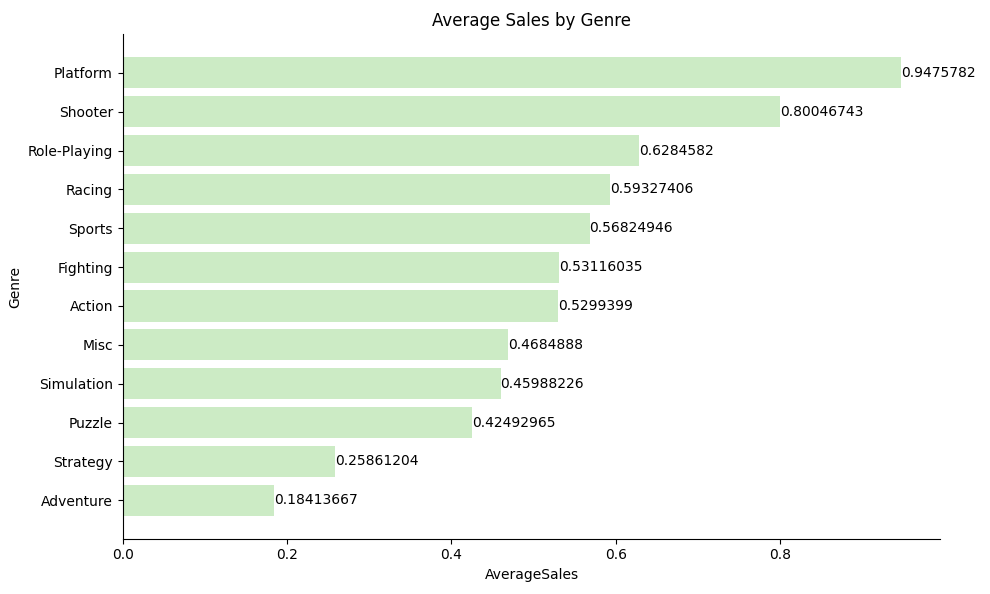
Platform 和 Shooter 类别的游戏市场表现最佳,平均销售额最高。这表明这些类别在玩家中具有更高的吸引力和市场需求。而 Adventure 类别的游戏市场表现较差,平均销售额最低,显示出该类别在市场中的受欢迎程度较低。其他类别如 Role-Playing、Racing 和 Sports 等则处于中等水平。
(4)每年发布的游戏数量和总销售额
绘制的折线图,展示从 1980 年到 2020 年期间游戏数量和销售额的发展趋势。

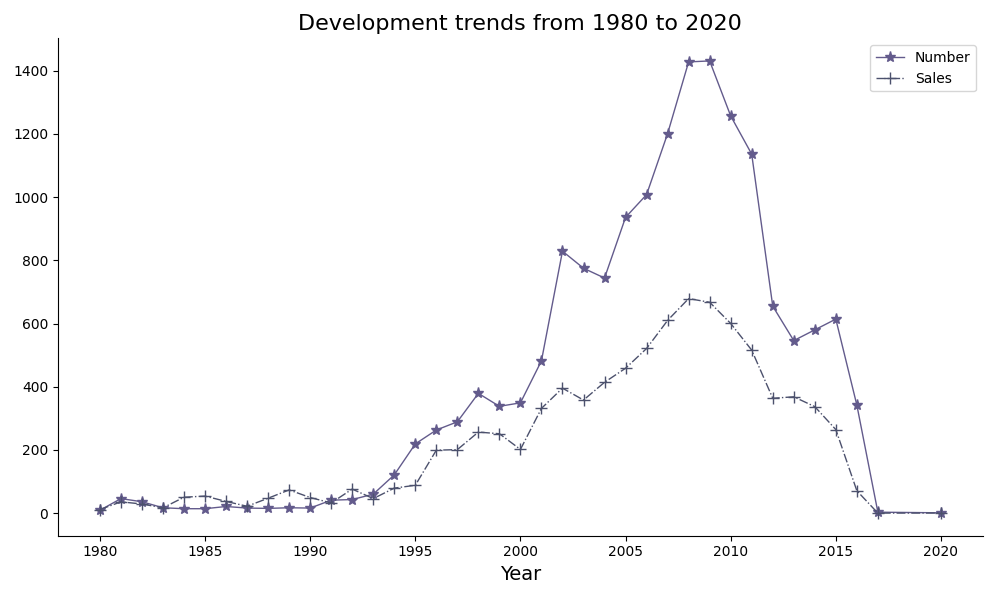
从 1980 年到 2009 年,游戏数量呈现稳步增长的趋势,特别是在 1990 年代末至 2000 年代初和 2005 年至 2008 年间,增长速度较快。2010 年后,虽然游戏数量有所下降,但总体仍保持在较高水平。数据集中缺少了2017年及其之后的数据,因此图中这段时间的趋势没有意义,不做分析。销售额的增长趋势与游戏数量大致相符。从 1994 年至 2008 年是游戏产业的黄金时期,游戏数量和销售额都达到了相对高的水平,这一时期被认为是游戏产业快速发展的阶段。
(5)每年游戏数量最多游戏类型及其数量
绘制气泡图,展示每年最多游戏数的游戏类型和游戏数量。将数据根据游戏类型分组,这样不同颜色的气泡代表不同的游戏类型,气泡大小代表游戏数量。

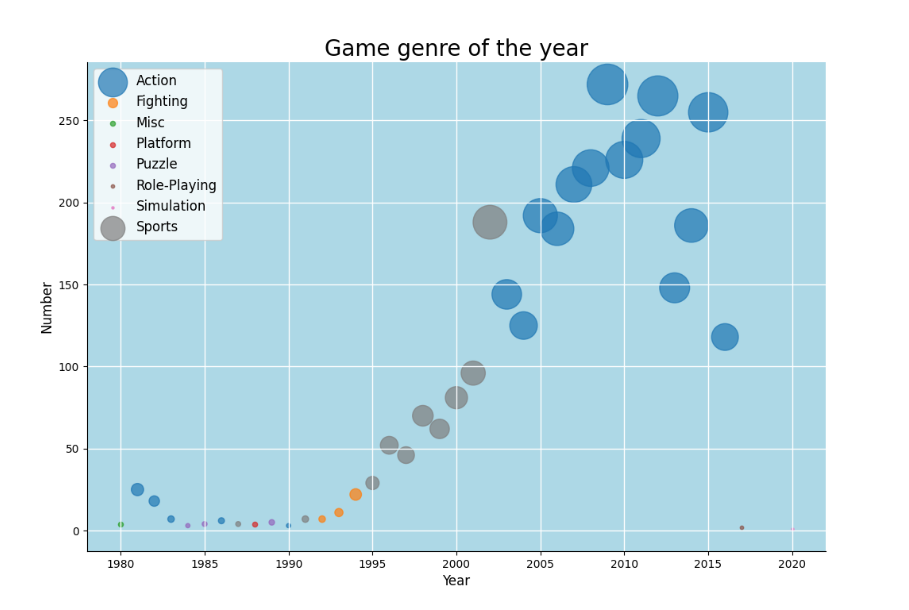
Sports 类型游戏在1990年代后期至2000年代初期经历了快速增长,并在此后的几年中保持了较高水平。Action 类型游戏在2000年代初期至2010年代初期也经历了迅速增长,并在2010年代中期后仍然保持了较高水平。Fighting、Platform、Puzzle 等类型在早期发展阶段较为突出,但随着时间的推移,其不再是主流游戏类型,而被 Sports 和 Action 等类型所取代。
可以看出随着时间的推移,游戏市场的主流类型逐渐发生变化,但是 Action 和 Sports 类型一直是持续受欢迎的游戏类型。
(6)北美、欧洲、日本、全球销售前十的游戏及其类型。
绘制一个堆叠条形图,展示全球销量前十的游戏在不同地区(北美、欧洲、日本、其他地区)的销售情况。每个游戏以及其所属的游戏类型(Genre)作为 x 轴标签,而不同地区的销售额则以堆叠的方式呈现在每个游戏条形上。这样可以直观地比较不同地区对于全球销量前十游戏的贡献情况。

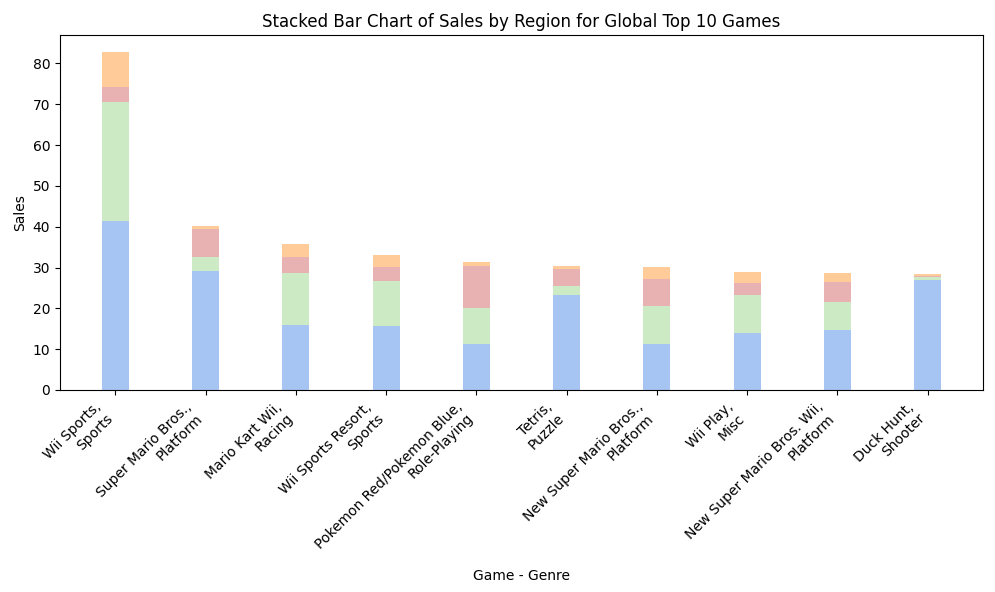
在全球销量前十的游戏中,涵盖了多种不同类型的游戏,包括体育(Sports)、平台(Platform)、竞速(Racing)、角色扮演(Role-Playing)、益智(Puzzle)、杂项(Misc)等。
观察各款游戏在不同地区的销售额,可以发现销售额最高的地区是北美(NA),其次是欧洲(EU),日本(JP)和其他地区的销售额相对较低。
"Wii Sports"在北美和欧洲的销售额较高,占据了全球销量榜首;"Super Mario Bros."和"Mario Kart Wii"等任天堂旗下的游戏也在全球范围内表现突出;"Pokemon Red/Pokemon Blue"在日本市场表现较好,显示了对日本玩家的吸引力;"Duck Hunt"则在北美市场表现突出,体现了射击类游戏在该地区的受欢迎程度。
接下来将三个地区(北美、欧洲、日本)的销售前十游戏数据合并,并绘制出点状图以比较它们的销售情况和在不同游戏类型上的分布情况。直观地观察不同地区最受欢迎游戏的分布,帮助分析不同地区的游戏偏好及销售情况。
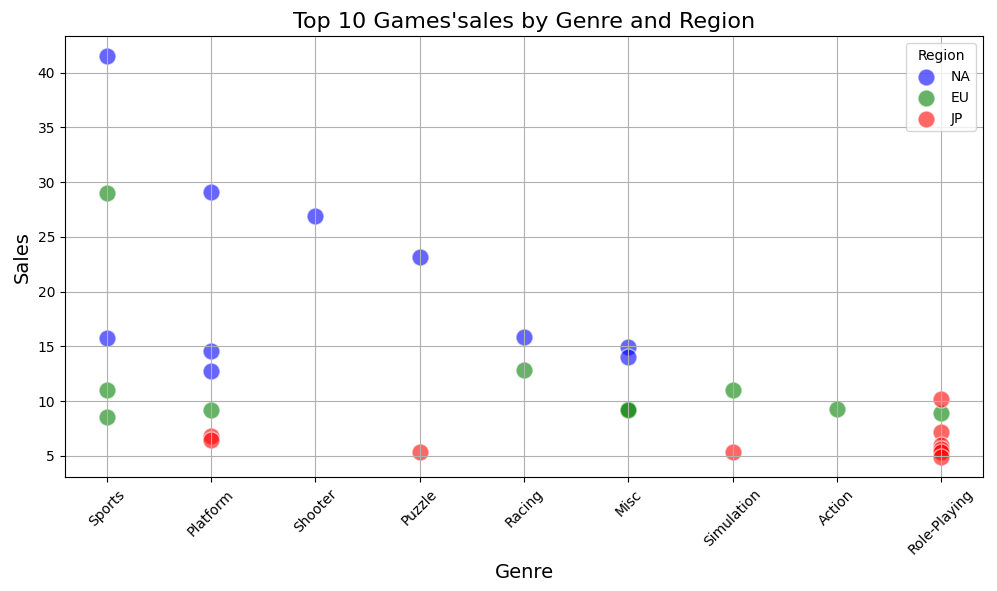
根据销售额来看,各地区Top10游戏的销售额上北美仍然明显高于其他地区,这是因为北美地区是全球最大的视频游戏市场之一,拥有庞大的游戏玩家群体和高度发达的游戏产业。在北美地区,前十名中的游戏类型涵盖了多种类型,包括体育类(Sports)、平台类(Platform)和射击类(Shooter)等。这表明北美地区玩家对游戏类型的需求比较广泛。欧洲地区的前十名游戏中,体育类游戏的销售情况依然很好,也有其他类型的游戏进入了前十名,如竞速类游戏(Racing)和模拟类游戏(Simulation)。日本地区的前十名游戏主要集中在角色扮演类游戏,这与日本地区玩家对日本特色游戏的偏爱有关。
(7)不同地区的总销售额
绘制饼图来展示不同地区(北美、欧洲、日本、其他地区)的总销售额分布情况

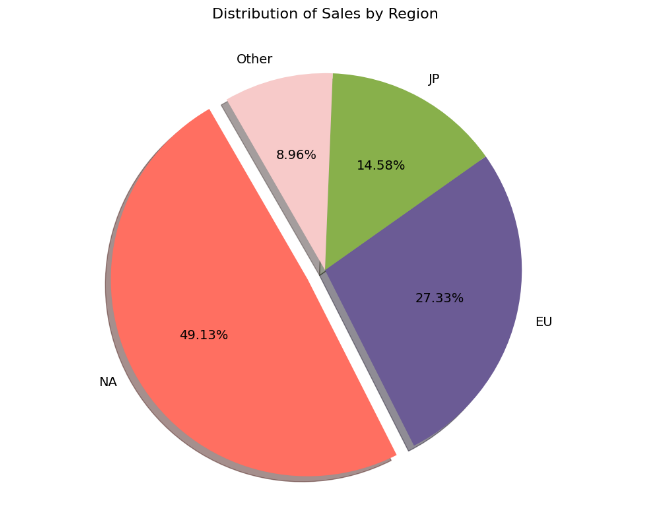
从数据中可以看出,北美地区的销售额最高,占比超过了一半,表明北美市场对于游戏销售的贡献最大。这可能与北美地区的游戏文化、经济实力等因素有关。欧洲和日本紧随其后,但销售额相对较低。这反映了欧洲和日本在视频游戏产业中的重要性,也反映了当地玩家对游戏的热情和消费能力。其他地区的销售额较少,对总销售额的贡献相对较小。这些地区可能包括非洲、拉丁美洲和亚洲一些次要市场,尽管销售额不及北美、欧洲和日本,但随着全球经济发展和游戏产业的普及,这些地区的销售额可能会逐渐增加。
(8)每年总销售额最高的游戏
为所有的年度销量最高游戏绘制词云
可以看到Super Mario、Zelda、Pokemon、Wii、Grand Theft等流行游戏的名字词汇。
六、总结
本实验对1980-2020年(清洗后的数据缺少2017年及其之后的数据)电子游戏销售数据集进行了处理分析。具体操作有对原始数据集进行清洗,去除空值、重复值等。接着使用Flink对清洗后的数据进行处理分析,主要进行了分类汇总、排序筛选等处理,然后将结果输出为CSV文件。最后使用Python的matplotlib等库对处理数据进行可视化,对结果进行了分析总结,给出了从游戏数据中得到的信息。