【版权声明】版权所有,严禁转载,严禁用于商业用途,侵权必究。
作者:厦门大学计算机科学与技术系2023级研究生 曾雯婷
指导老师:厦门大学数据库实验室 林子雨 博士/副教授
时间:2024年6月
相关教材:林子雨编著《Flink编程基础(Java版)》(访问教材官网)
相关案例:Flink大数据处理分析案例集锦
本案例使用Java语言编写Flink程序。使用Python语言进行数据清洗,保存到分布式文件系统HDFS中,接下来使用Java语言编写Flink程序进行数据分析,最后,利用python的matplotlib库完成可视化工作。
数据集和代码下载:从百度网盘下载本案例的代码和数据集。(提取码是ziyu)
一、环境配置
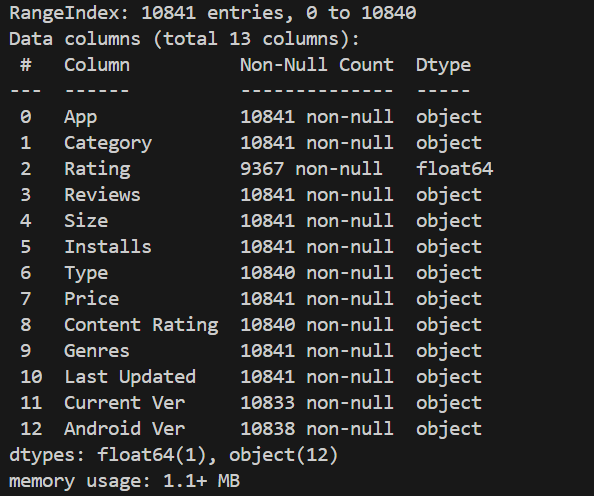
(1)Linux:Ubuntu 16.04
(2)Hadoop:3.3.5
(3)Flink:1.17.0
(4)Python:python3.9.18
(5)运行环境:VS Code、Idea、Anaconda3
(6) 编程语言:Java和Python
二、数据清洗
首先实验的数据集为:https://www.kaggle.com/datasets/lava18/google-play-store-apps
数据集相关信息:
这个数据集描述的是Google的App Store中应用的一些相关信息,包括下载信息、评分信息、是否付费等信息,整个数据集一共包含了10841条数据,每个数据由13个字段组成,具体字段的名称含义如下:
字段名称 字段含义
App 应用程序的名称
Category 应用程序所属的类型
Rating 用户对应用程序的评分
Reviews 应用程序的用户评论数量
Size 应用程序的大小
Installs 应用程序的用户下载/安装数量
Type 付费或免费
Price 应用程序的价格
Content Rating 该应用程序针对的年龄组 - 儿童/21 岁以上成年人/成人
Genres 应用程序所属于的多个类型(除了其主要类别)
Last Updated 最近更新日期
Current Ver 最新版本
Android Ver 安卓版本
1、数据预处理过程
在进行数据分析之前,将数据集导入,利用head()和info()函数查看数据集的状态,从而有利于进行数据清理操作。
由于数据可能存在许多不规范的部分,因此首先进行数据的预处理,包括空值处理、重复值处理、日期处理、合理性检查等内容,具体描述如下。
(1)空缺值处理
首先为了后面更好进行数据处理,将app字段中有“,”的记录设置为空值,然后存在空缺值的行利用dropna()进行处理,去除空值后的数据集长度变为8807。

(2)重复值处理
由于数据集中存在App字段相同的数据,因此App名称是唯一主键,将字段“App”存在重复的记录进行删除,只保存唯一一条记录:

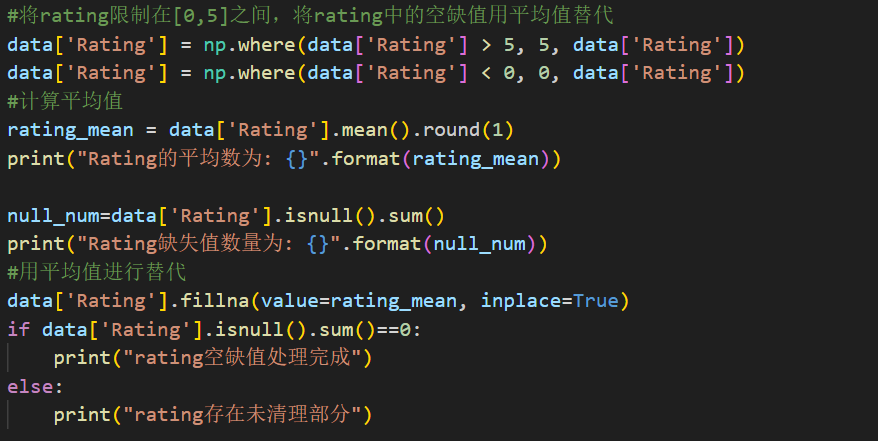
(3)Rating字段处理:
在Rating中限定其评分范围为[0,5]之间,将>5的评分用5替代,将<0的评分用0替代。除此之外,Rating中还存在着许多标记为NAN的空值,对于这些通过计算Rating列的平均值,用平均值替代缺失的部分:
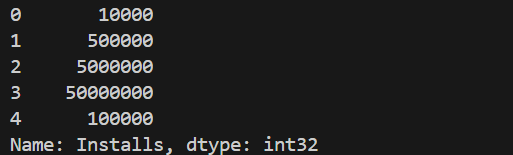
(4)Installs字段处理:
Intalls字段的写法为“10,000+”,这种情况下为了将该字段转化为数字,首先去除符号’,’和‘+’,在此基础上利用astype将其转化成int类型。

(5)Reviews字段处理:
将Reviews字段的数据类型修改为int,从而进行数据分析:

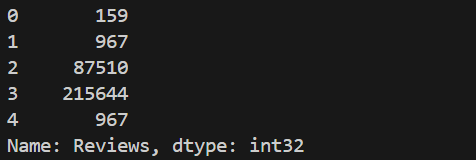
(6)Last Updated字段处理:
此字段代表的是软件的最近更新日期,因此将原来的String类型利用pandas中的to_datetime转化成日期格式:

(7)Type &Price字段处理:
如果Type为Free而Price为空值时,填充Price为0;如果Price为0而Type为空值时,填充Type为Free:

(8)Price字段处理:
Price字段中出现类似“$2.99”的格式,首先去除符号“$”,将字段的数据类型转化为float:

(9)Size字段处理:
包含两种类型的数据:以M为单位和以k为单位。首先统一单位,若字符串中包含'M'将其转换为‘k’(乘以1024),如果字符串中不包含'M'或'k',则返回NaN值。
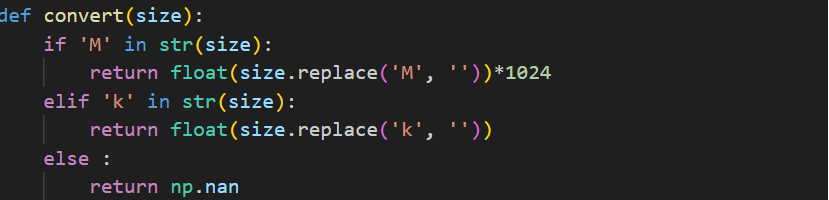
将convert函数应用到Size字段的每一个数据中,计算Size的平均值填入NaN的位置,最后将数据转化成int类型。
2、数据清理完成
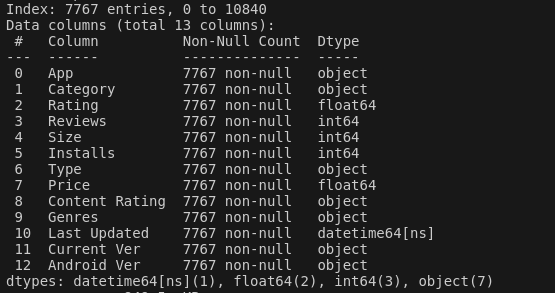
处理完成后输出info()查看目前数据集的相关信息,可以看到字段对应的数字类型已经得到了更改,并且清理之后数据集的记录个数变成了7767:
三、数据分析
1.文件创建及依赖配置
首先利用IDEA创建一个appanalysis的项目,在java目录下创建一个cn.edu.xmu.Analysis的文件,在这个文件中进行处理。
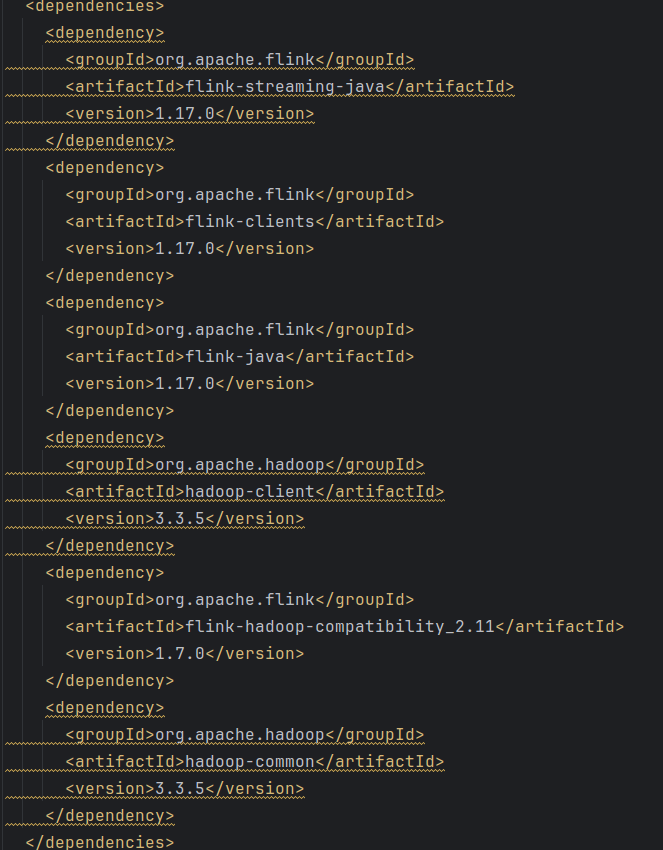
在相关的pom.xml文件中配置需要的flink依赖,版本为1.17.0,以及配置相关的hadoop依赖,版本为3.3.5。
2.读入数据
首先利用StreamExecutionEnvironment.getExecutionEnvironment创建一个实例用于配置和执行Flink流处理任务。启动Hadoop HDFS,读取hdfs的文件路径,将并行度设置为1,并将输入流转化成元组以便后续处理:

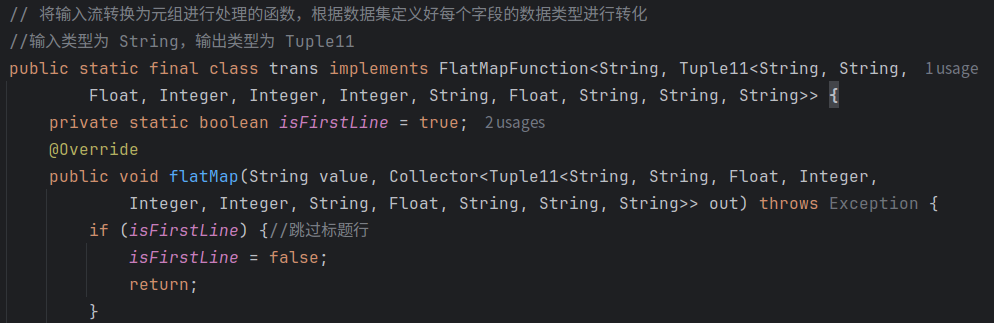
3.输入流转化为元组处理函数trans:
由于数据集共有11个字段,因此将数据集转化成对应的数据类型构成一个Tuple11,首先设置一个bool字段跳过标题行。
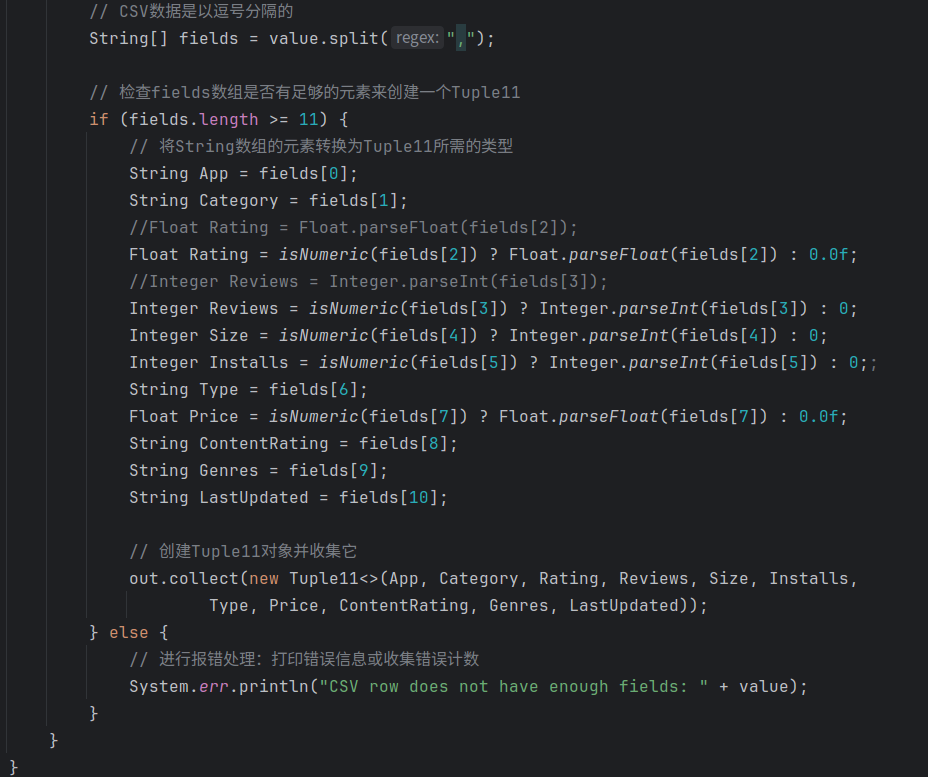
跳过之后,由于每个字段之间都是按照逗号分隔开的,因此按照逗号对读进来的每一行进行划分成11个字符串存进flields列表中。接着判断是否有足够的元素来创建tuple11,如果满足,则按照每一个字段的数据类型进行对应的类型转换,字符串字段则不需要进行处理,直接赋值即可,最后创建一个Tuple11的对象进行收集。否则就进行报错处理。
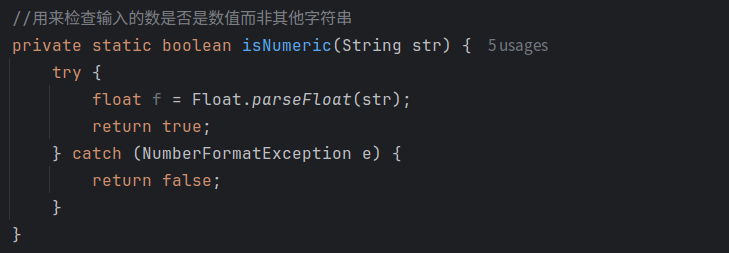
在trans函数的处理过程中可以看到调用了一个isNUmmeric函数,主要适用于检查输入的数是否是数值float类型,而非字符串类型:
4.排序函数
首先介绍后续数据分析操作需要用到的排序函数SortFunction和SortFunction1函数:
这两个函数整体上是类似的,区别在于SortFunction函数处理的是Tuple3<String,String, Long>元组,而SortFunction1函数处理的是Tuple4<String,String, Integer,Float>函数:
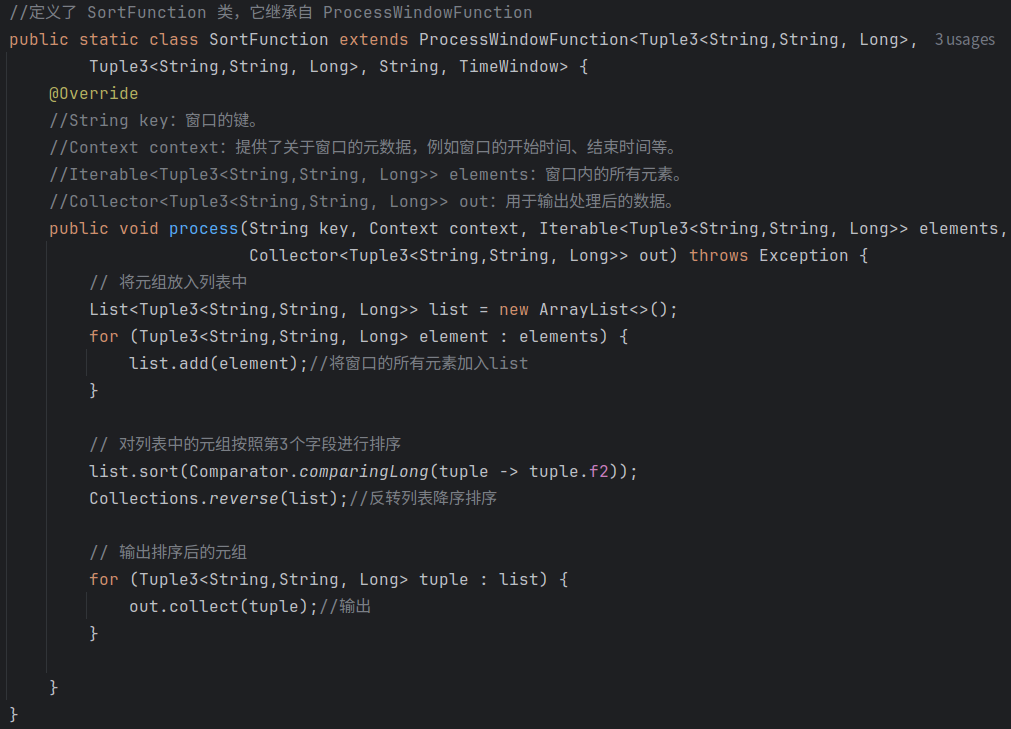
以SortFunction为例,通过集成自 ProcessWindowFunction,重写覆盖原有的接口中的方法,将输入的元组放入一个list列表中,对列表中的元组按照第三个字段进行排序,最后反转列表,则得到一个降序排列:
5.Flink数据分析:
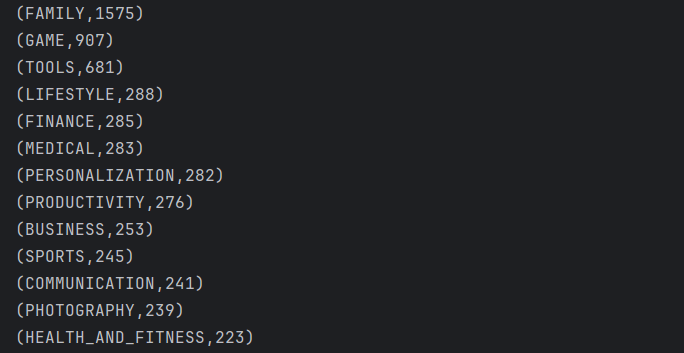
(1)统计不同category的应用数量并排序:category_counts.csv
首先声明了一个categoryCounts的数据流,处理的数据为Tuple2数据类型。对appstore数据流中的每一个元素映射到一个新的二元组:由value.f1(category)以及常量1L组成。通过.returns显示指定map操作返回类型,通过.keyby指定按照第一个字段f0(category)进行分组,最后利用.reduce函数对每个分组的数据实现累加操作,也就是得到了不同category的应用数量。
在此基础上声明一个category_counts_before的数据流,实现排序操作。因为datastream是按照分组进行操作的。所以要实现排序,我们可以设置一个固定字符串将其按照该字符串分在同一组。因此对每一个元素应用映射函数,创建一个新的三元组第一个字段为固定字符串s1,第二三个字段为原来元组的字段(category,数量),在此基础上利用keyby指定按照s1进行分组,也就将他们同一个分组,接着定义窗口大小为20s,调用SortFunction函数进行排序。
最后再次声明一个category_counts的数据流只保存后两列的内容,对于第一列全由s1组成的列只是辅助作用,因此不需要保存。
运行结果示例:
(2)统计不同category的应用的install平均数,最大值,最小值:install_stats.csv
和上述类似,首先声明一个installStats的数据流,利用.map将原appstore数据流中元素映射到一个二元组:一个是value.f1(category),另一个是包含了四个字段的元组类型,前三个初始化为vaule.f5(installs),最后一个初始化为常数1L。同样利用category进行分组,最后对每个类别的分组应用.reduce操作用于计算每个类别的总数量,最大数量,最小数量,总数量。
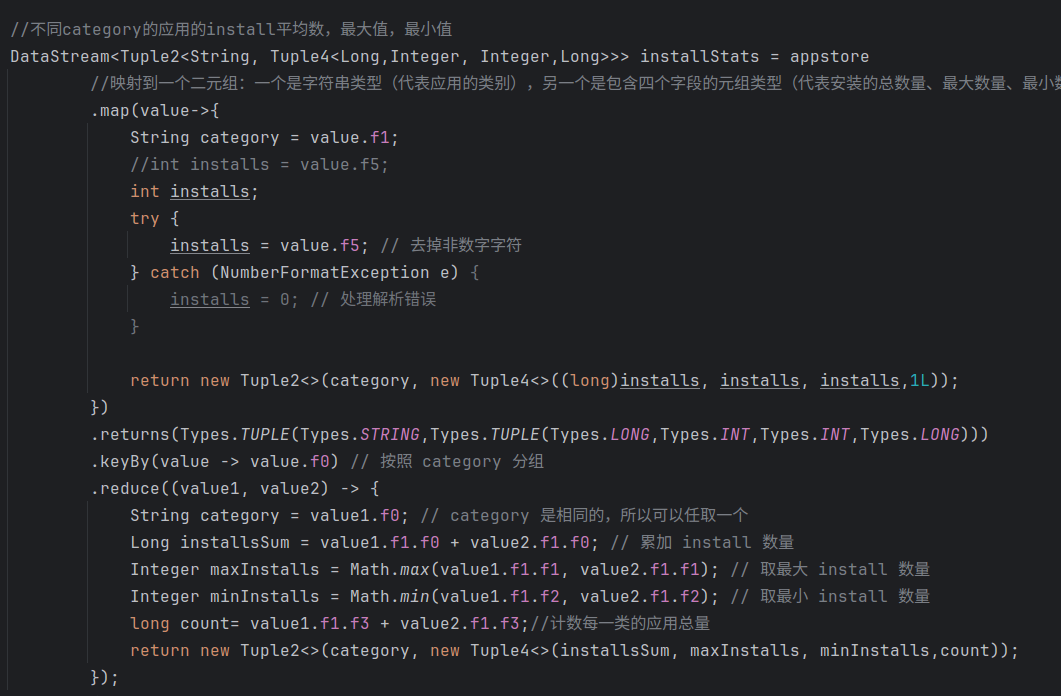
在此基础上再声明一个final_install数据流,利用前面计算得到的每个类别的安装总数量和安装总数计算平均安装量,最后返回一个新的四元组。
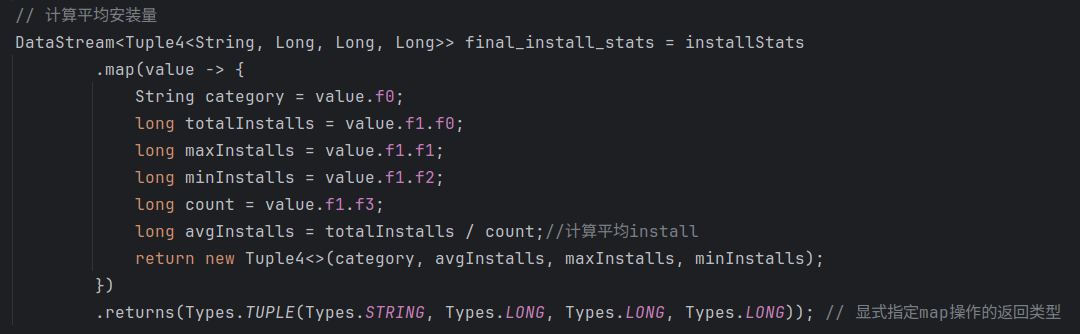
运行结果示例:
(3)统计不同rating区间的应用数量:rating_counts.csv
声明了一个rating_counts的数据流,首先声明了一个名为Range的字符串,根据每个记录的rating值将其分类为“Very Poor”,“Poor”,“Average”,“Good”,“Excellent”。利用.map对每个元素映射到一个包含range字段和常量1L的二元组。然后按照range分组并统计每个类别的数量。
运行结果:

(4)统计付费和免费软件的比例:free_or_paid.csv
声明一个free_paid的数据流,应用.map将每个元素映射到一个新的包含value.f6(type)和常量1L的的二元组,按照type字段进行分类,最后利用.reduce函数实现在不同type分类中进行累加操作。

运行结果:

(5)统计付费app的price分布:price_counts.csv
声明一个price_counts的数据流,对price字段进行处理,首先利用.filter过滤掉价格为0也就是免费的记录,在此基础上声明一个range字符串用来表示价格范围。并按照price字段 的值将range分类为“0-5”,“5-10”,“10-15”,“15-20”,“20-25”,“25-30”,利用.map映射到包含range和常量1L的新二元组,并按照range进行分类,统计不同分类的数量。
运行结果:

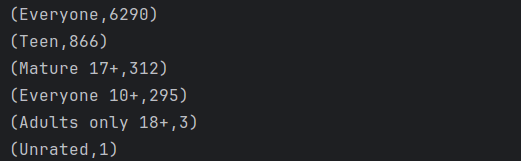
(6)不同内容评级的应用数量:统计不同内容评级(如Everyone、Teen等)下的应用数量并排序:content_rating.csv
声明一个contentrating的数据流,对appstore数据流利用.map映射到包含内容评级(conten rating)和常量1L的二元组,并且按照内容评级字段进行分组,利用.reduce统计不同分组的数量。
再声明一个content_rating_before的数据流,对上述数据流利用.map映射到包含固定字符串s2和原来两个字段的三元组,调用SortFunction函数进行从高到低排序,最后再声明一个content_rating 的数据流,由于第一列为s2字符串与结果无关,于是只保留后面两列。
运行结果:
(7)按照reviews排序,选择top 10对应的app名称:sorted_reviews.csv
声明一个sortedreviews的数据流,利用.map对appstore数据流中的元素映射到一个包含App、reviews、rating的三元组。
在此基础上声明一个sorted_reviews_before的数据流,固定字符串常量s3,利用.map对上述数据流中的元素映射到一个包含s3和原来三个字段的四元组,利用.keyby按照s3分类到同一组,调用窗口,利用SortFunction函数进行排序。最后声明一个sorted_reviews数据流只保存最后三列。
运行结果:
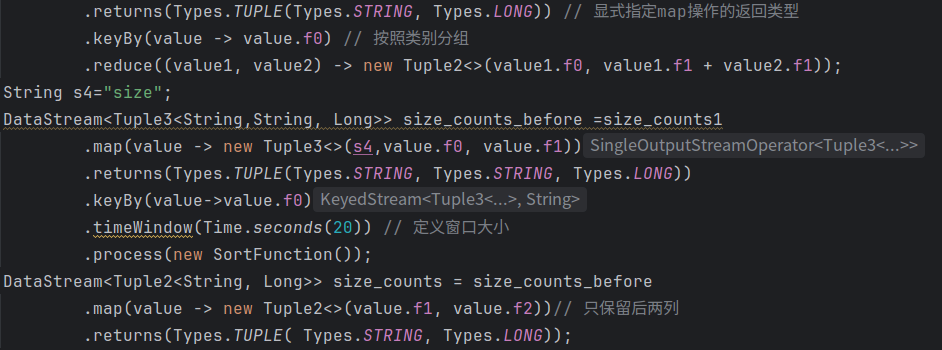
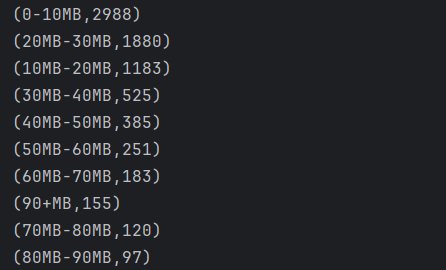
(8)统计不同size区间的应用数量:size_counts.csv
声明一个size_count1的数据流,先对size字段进行处理。声明一个range字符串,按照size对其分类,利用.map映射到range和常量1L的二元组,按照range进行分组统计数量,最后再次调用SortFunction函数进行排序。
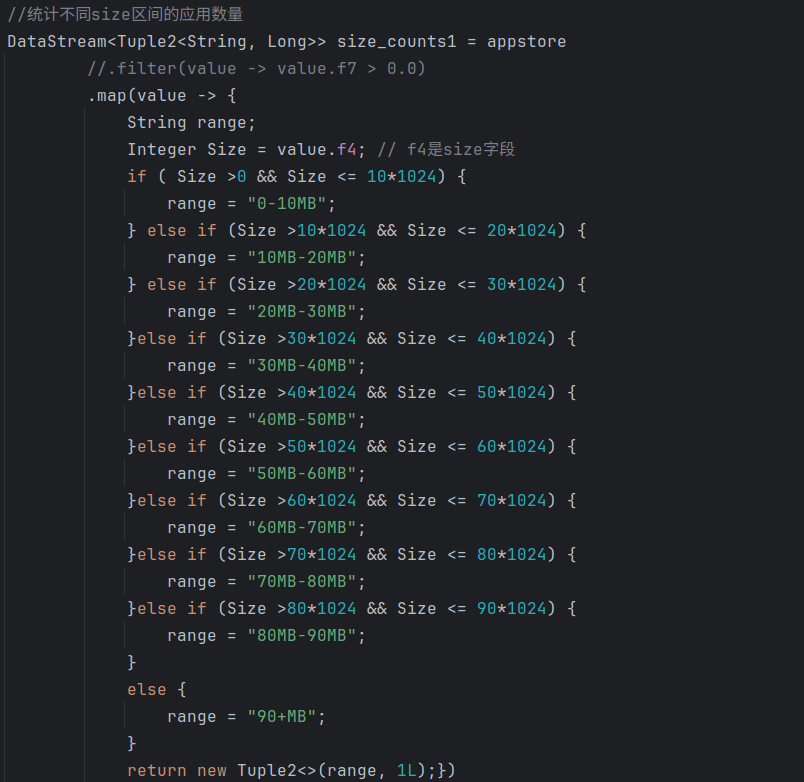
运行结果:
6.写入文件并执行

四、结果可视化及分析
得到8个数据分析结果后,利用python的matplotlib库完成可视化工作,并通过可视化结果进行分析,由于代码结构类似并且较长,在第一个会详细贴出代码,完整代码可在datavisualization.py中查看。
(1)不同category的应用数量
下图统计了Google App Store中不同类型的app数量并进行了排序。由图可以看出App数量前几名的类别为Family、Game、Tools这三类,剩下的类别在数量上和这三类有较大的差异,而Family类别的app数也比Game要多得多,可以看出如今在智慧化程度很高的时代涌现了很多和Family相关的App来改善人们的生活,而Game游戏作为一个一直以来受众范围都很广的一个类别,其应用数量多也是符合实际情况的。
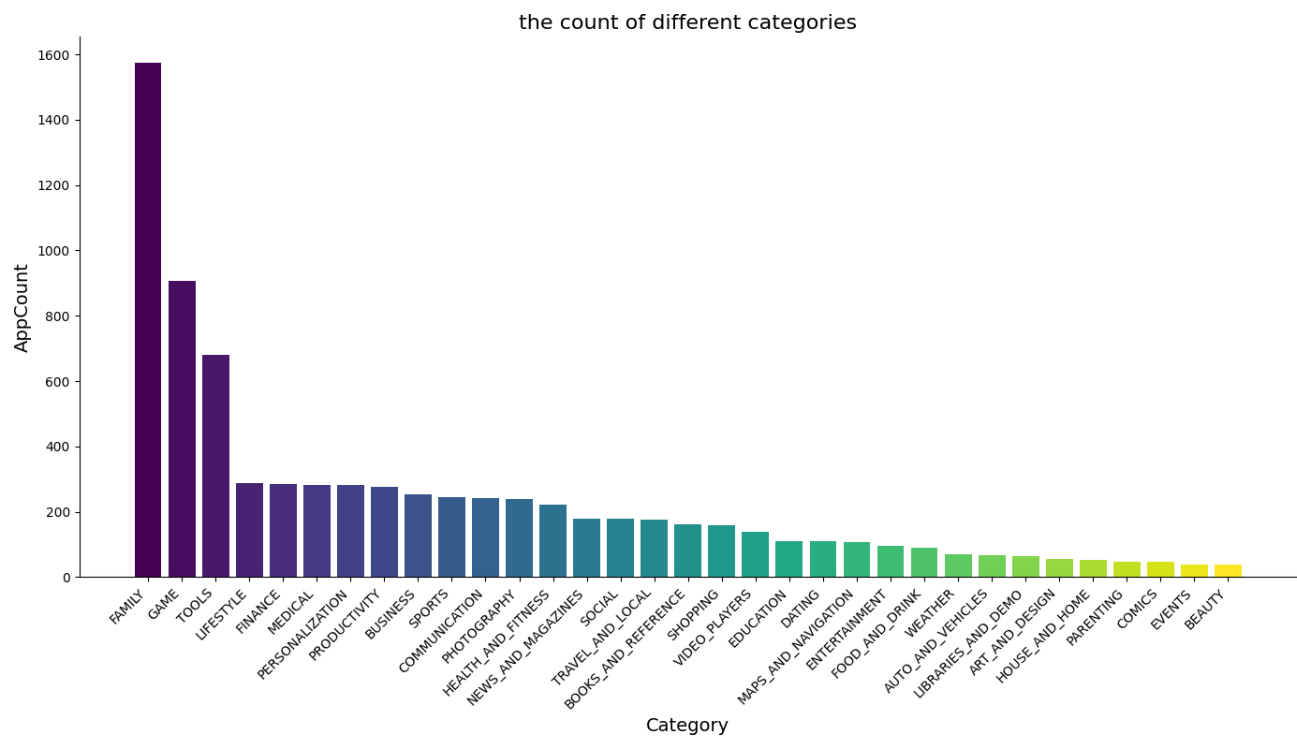
具体代码如下,首先将文件读进来,利用plt.bar绘制条形图,标注x,y轴标签,保存图片。
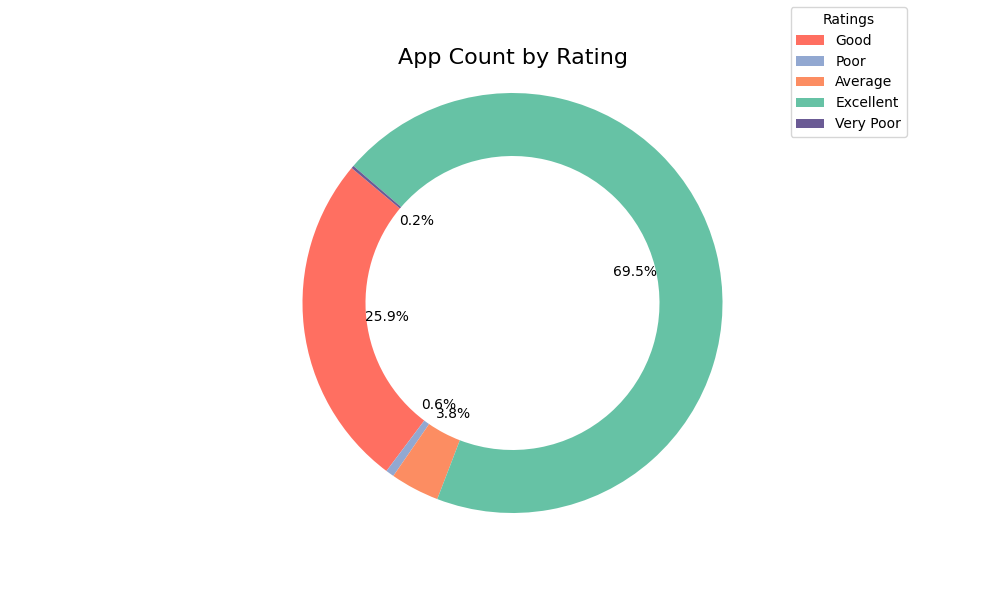
(2) 不同rating区间的应用数量
下图统计的是App的评分区间,其中Very Poor代表“0-1”,Poor代表“1-2”,Average代表“2-3”,Good代表“3-4”,Excellent代表“4-5”分,可以看到其中Excellent得分区间的应用程序占比最多为69.5%,而Poor和Very Poor的占比为0.2%,0.6%,可以看出Google App Store中的大多数应用的用户评价是比较高的,只存在很少部分应用评分较低。
其中比较关键的代码为绘制环形图的部分:
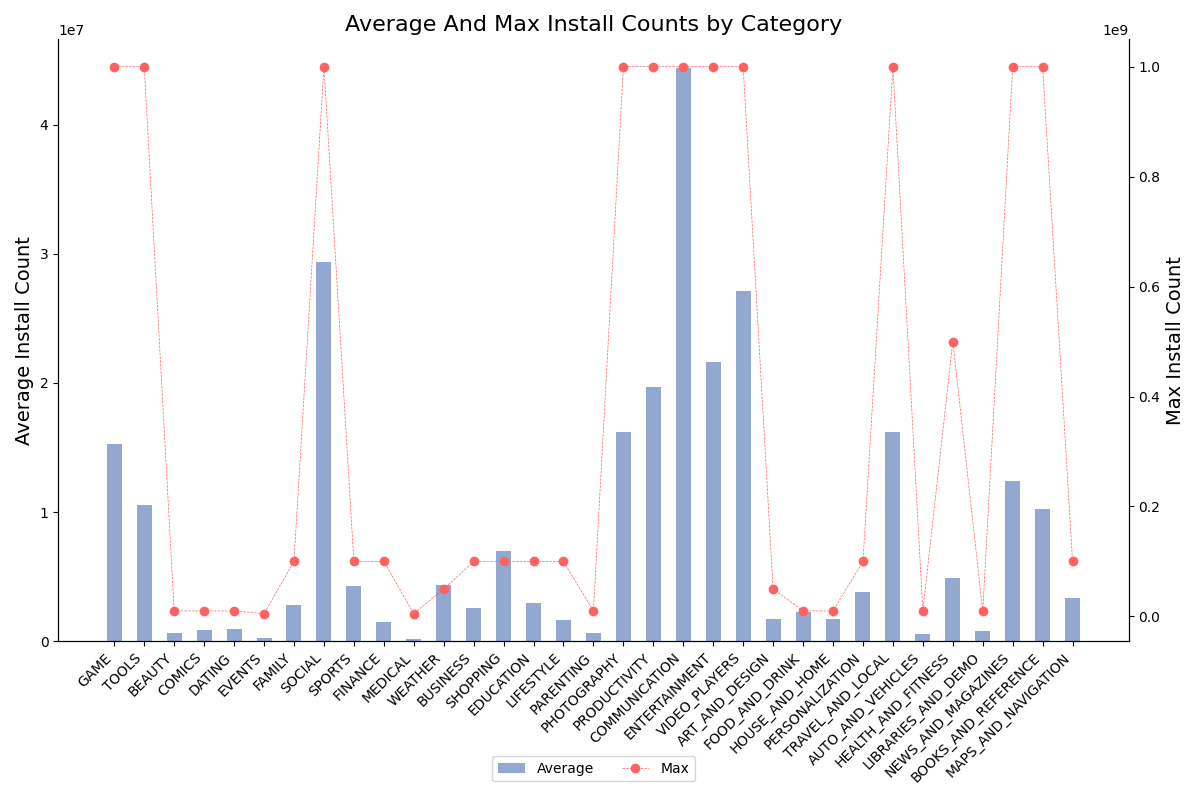
(3)不同category的应用的install平均数,最大值
下图条形图显示的是不同类型的应用软件的平均安装数量,折线图显示的是最大安装数。
对于平均安装量,可以看到Communication类型的软件平均安装数最多,Video_Players和Social的安装平均数也较高,这也反映了如今世界互联网兴起,大家网上交流互动活动增加,用户需求大,社交软件流行。同时Medical,Auto_And_Vehicles等类别的安装量少可能原因是用户需求范围比较小,或者使用门槛的限制导致安装量较少。
对于最大安装数来看,包括Game,Photography等在内的多个类型软件都存在最高接近1亿的安装量,证明这些领域都存在一些做得很好,在用户中很流行的应用。而那些平均安装量较低的软件自然其最高安装量也较低。
主要代码为条形图和折线图的绘制,首先利用bar创建条形图,在此基础上,利用ax1.twinx()创建第二个y轴坐标,利用plot绘制折线图。
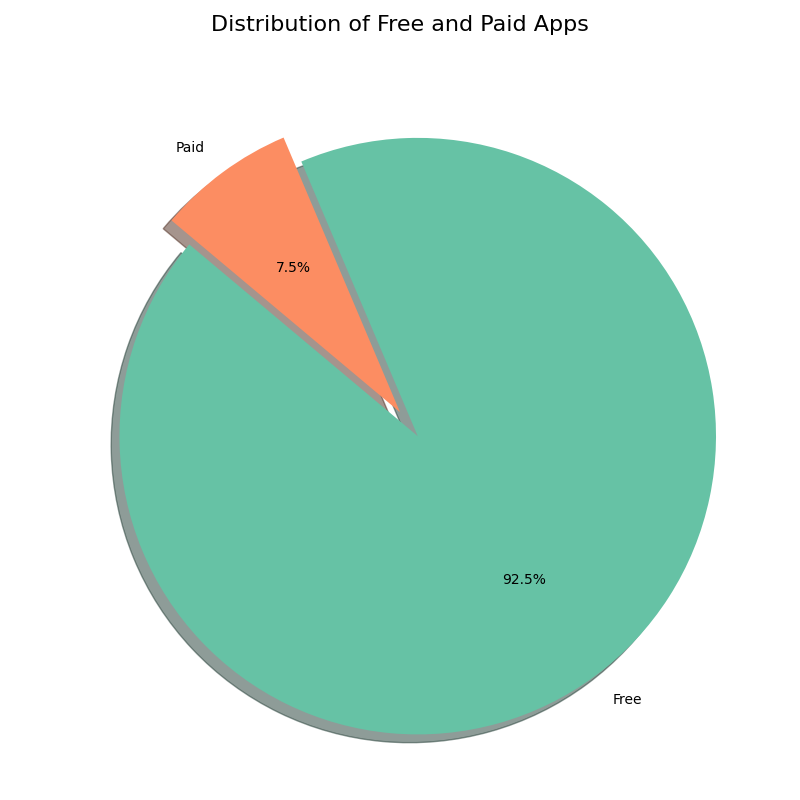
(4)统计付费和免费软件的比例
下图显示的是付费和免费应用的占比。可以看到绝大部分应用为免费的,只有7.5%的应用是需要付费的。
主要代码为利用pie创建饼图

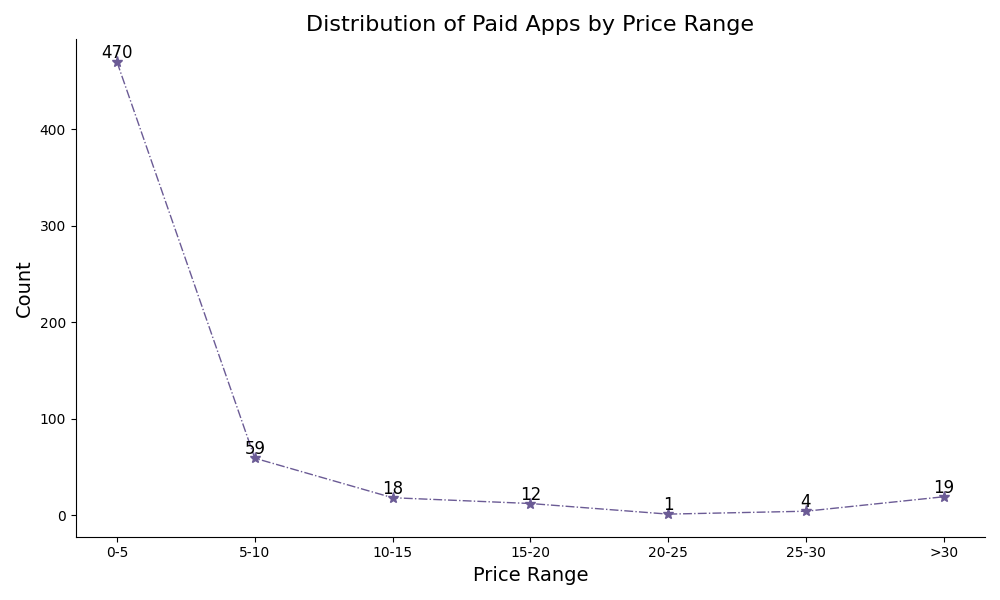
(5)统计付费软件的price分布
下图显示的是统计付费应用在不同价格区间的价格分布,可以看到有高达470个应用的价格在0-5美元之间,这也表明在付费应用中绝大多数价格是比较低的,这个价格区间是可以为用户接受的,是面向大众的。同时随着价格的上升,应用数目总体上呈下降趋势。
主要代码为由于文件中的价格顺序是乱序的,因此需要指定价格区间顺序,将Price列转化成带有指定顺序的类别,然后同样的利用plt.plot绘制散点图,通过指定连接点的线段类型来构建折线图。

(6)统计不同content rating的应用数量
下图显示的是App的内容评级分布情况。可以看到内容评级为Everyone也就是适合所有人的应用数最多为6290个,而其余有年龄限制的App数目占比很小,因此可以得出Google App商店中的应用绝大部分是面向所有年龄段的人使用的。
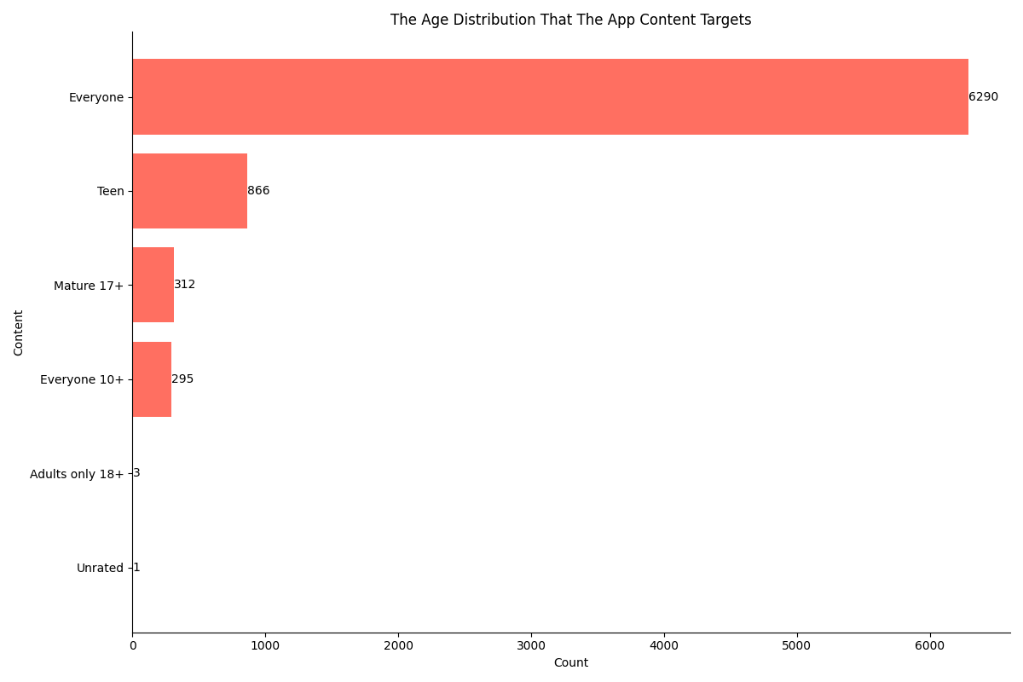
代码:plt.barh绘制水平条形图
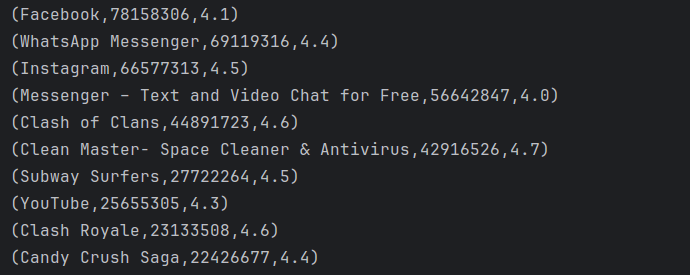
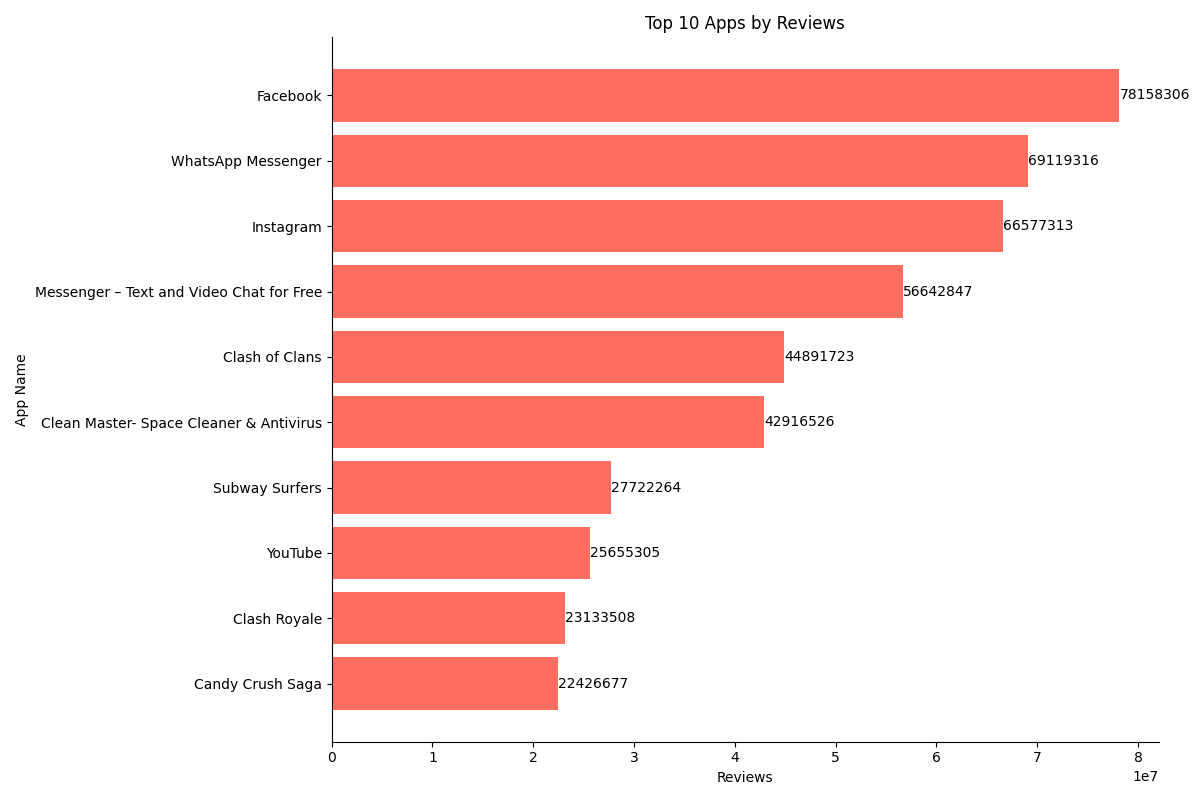
(7) 按照reviews对其进行排序,选择top 10对应的app名称
下图显示的是根据平均数排名前十的的App名称以及他们的平均数,可以看到排名第一的就是在全世界范围内都很出名的应用Facebook,其评论是高达78158306,除此之外还包括我们较为熟知的WhatsApp、Instagran以及YouTube等软件,可以看出社交类、游戏类,工具类应用是比较受欢迎的,评论数非常之多,这和前面分析的这几类软件的安装量高、应用数量多是情况一致的。绘制横向条形图代码和前面类似,此处不再赘述。
(8)统计不同size区间的应用数量
下图展示的根据应用的大小进行分区,统计不同Size区间的一个应用数量,采用的是用步进图来表示。可以看到有相当一部分应用的大小集中在0-10MB之间,也有一部分应用大小集中在20-30MB之间,总体上来说小型应用更为流行,用户更愿意选择中小型应用。随着应用大小的增加,应用数量总体上也是呈下降趋势,这也是因为较大的应用需要占据更大的内存空间,所需维护成本等也就增加,用户也更少选择需要占据存储空间大的应用。
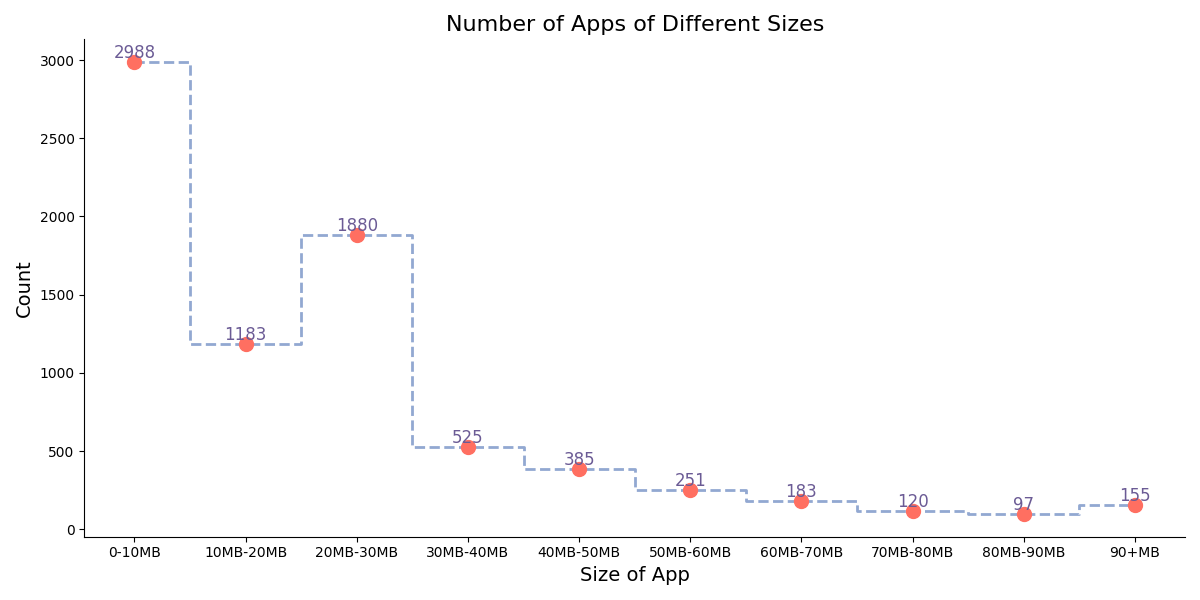
主要代码如下,利用plt.step绘制步进图,同时对于每一个Count数值绘制对应的圆点进行强调显示。
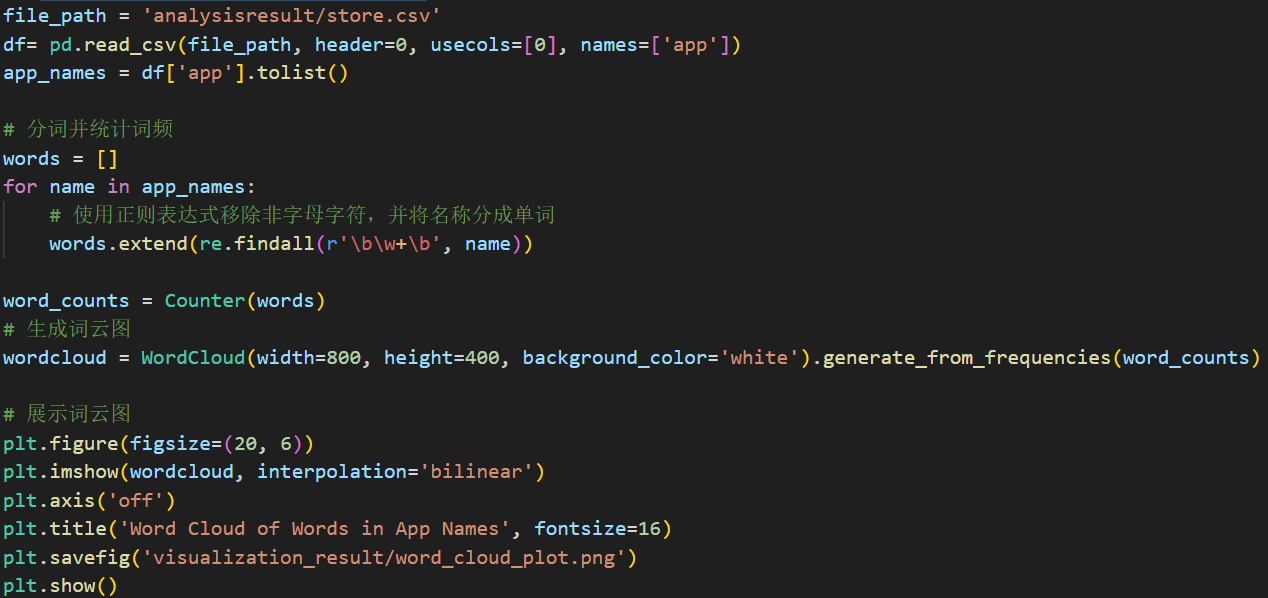
(9)词云统计:统计app名称中最常使用的单词
下图统计的是在app名称中开发者最喜欢用什么单词来为app取名,可以看到其中最常用的其实和For,Free,by,The,And,Mobile、Photo等词语,首先可以看到连词介词出现的概率很高,其次是直接表明app用途的比如Video、Photo等的出现概率也很大,这也告诉我们为app取名字时可以多使用让人可以立刻了解类型的名词,以及多使用连词。

主要代码如下,首先只选取app这一列进行操作,首先获取所有应用的名称,通过遍历将名称分为单词,然后进行统计,利用WordCloud生成词云图。