
【版权声明】版权所有,严禁转载,严禁用于商业用途,侵权必究。
作者:厦门大学计算机科学与技术系2023级研究生 全威
指导老师:厦门大学数据库实验室 林子雨 博士/副教授
时间:2024年6月
相关教材:林子雨、郑海山、赖永炫编著《Spark编程基础(Python版,第2版)》(访问教材官网)
相关案例:基于Python语言的Spark数据处理分析案例集锦(PySpark)
从百度网盘下载本案例数据集和代码。(提取码是ziyu)
1. 实验目的
英国航空(British Airways)是英国旗舰航空公司,总部位于伦敦希思罗机场,以其卓越的全球航线网络、高品质服务及作为寰宇一家航空联盟的创始成员而著称,连接世界各地的乘客与英国及全球各大目的地。在本实验中,我们旨在对英国航空的客户反馈数据进行深入研究。通过应用先进的大数据处理框架,如 Spark 和 Hadoop,以及强大的数据可视化技术,我们将对这些数据进行高效的存储、处理和分析。此外,我们还将利用机器学习算法,预测乘客对英国航空的总体评分。具体来说,本次作业的实现功能包括以下几个方面:
数据收集与预处理:获取并清洗英国航空客户反馈数据,处理缺失值和异常值,确保数据质量。
数据存储:利用 Hadoop 分布式文件系统(HDFS)实数据的高效存储,确保数据安全和可扩展性。
数据处理:使用 Spark 框架对数据进行快速批处理,快速筛选出热门航班,热门航线等,以应对大数据量和复杂的数据操作需求。
数据可视化:利用可视化工具(如 Matplotlib 和 Seaborn),生成直观的图表和报告,展示数据分析结果。
评分预测:构建并训练机器学习模型,预测乘客对英国航空的评分,评估模型的准确性和稳定性。
2. 实验环境搭建
(1) Linux:Ubuntu 22.04
(2) Hadoop:3.3.5
(3) Spark:3.2.0
(4) Python:3.8.19
(5) JDK:1.8
(6) 运行环境:Jupyter Notebook
此外,本实验画图用到的matplotlib,seaborn等工具包都已经详细地列在requirement.txt文件里。
3. 数据集介绍
本次实验采用的数据集是英国航空的客户反馈数据集,可在Kaggle网站下载(https://www.kaggle.com/datasets/chaudharyanshul/airline-reviews)。这份数据来自AirlineQuality,汇集了近十年来英国居民对英国航空的评价,囊括了航线、客舱等级、座椅舒适度、机舱服务、地面服务等多个关键方面。这一全面细致的评估为探索和了解英国航空提供了一道广阔而清晰的路径,为研究人员和数据爱好者提供了极具启发性的资源。该数据集的各个字段说明如下:
OverallRating: 客户给出的总体评分
ReviewHeader: 客户评论的标题或摘要
Name: 提供反馈的客户姓名
Datetime: 反馈发布的日期和时间
VerifiedReview: 是否为已验证的评论
ReviewBody: 客户详细的评论内容
TypeOfTraveller: 旅客类型(例如,商务旅行者,休闲旅行者)
SeatType: 客舱等级(例如,商务舱,经济舱)
Route: 客户乘坐的航班路线
DateFlown: 客户乘坐航班的日期
SeatComfort: 对座椅舒适度的评分
CabinStaffService: 对机舱乘务服务的评分
GroundService: 对地面服务的评分
ValueForMoney: 对性价比的评分
Recommended: 客户是否推荐英国航空公司
Aircraft: 乘坐的飞机型号
Food&Beverages: 对食品和饮料的评分
InflightEntertainment: 对机上娱乐设施的评分
Wifi&Connectivity: 对机上无线网络的评分
4. 数据预处理
4.1 手工处理
在拿到数据集后,观察到其存在两个亟需解决的问题:一是数据集存在错位;二是文本存在一些乱码。鉴于这些问题的复杂性,手工处理是必要的,以确保数据的完整性和准确性。
考虑到可能是由于'Name'特征的缺失导致后续特征错位,决定采用手工移动的方式进行处理。
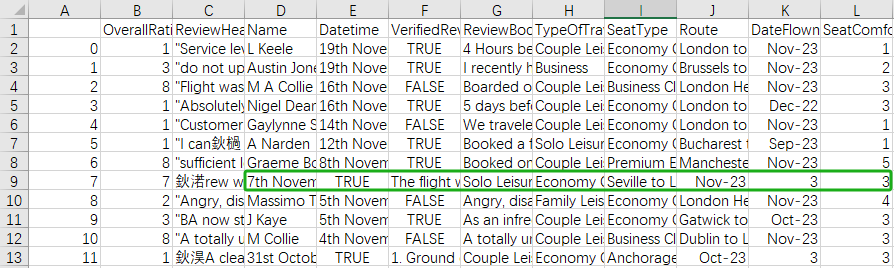
同时,借助Chat-GPT修正文本中的乱码。

4.2 数据集的导入和基本信息的查询
将.csv数据集读取到Jupyter里,并查看数据集的前几行内容。
检查一下数据集的大小。

4.3 数据清洗
4.3.1 删除无关特征
查看当前数据集所有的列名。

删除与本次实验无关的列,并观察删除后数据集的整体结构。
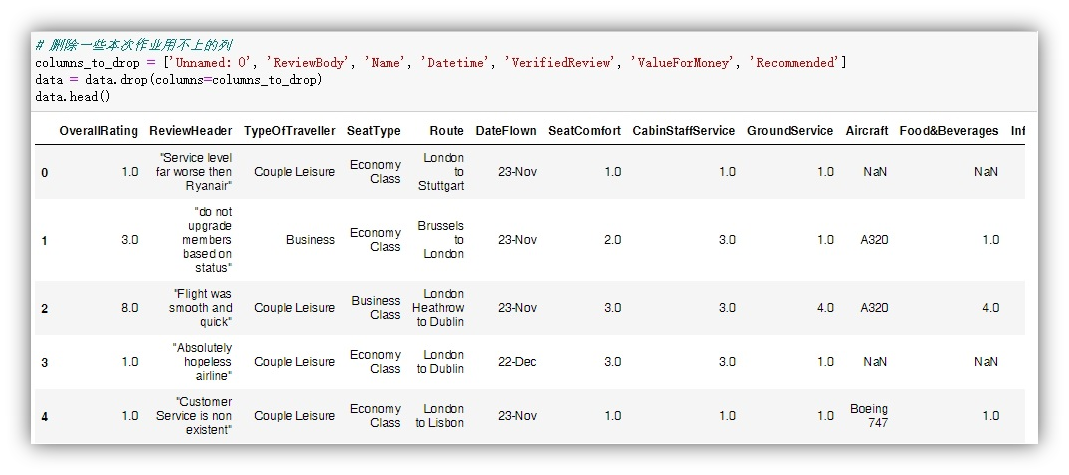
查看当前数据集的大小,可以看到已经删除了7列特征。

4.3.2 处理空缺值
本数据集包含3701条数据,属于相对充足的样本规模。鉴于这一点,本次实验采取直接删除缺失值的策略。首先,我们将检查每列特征的缺失率。
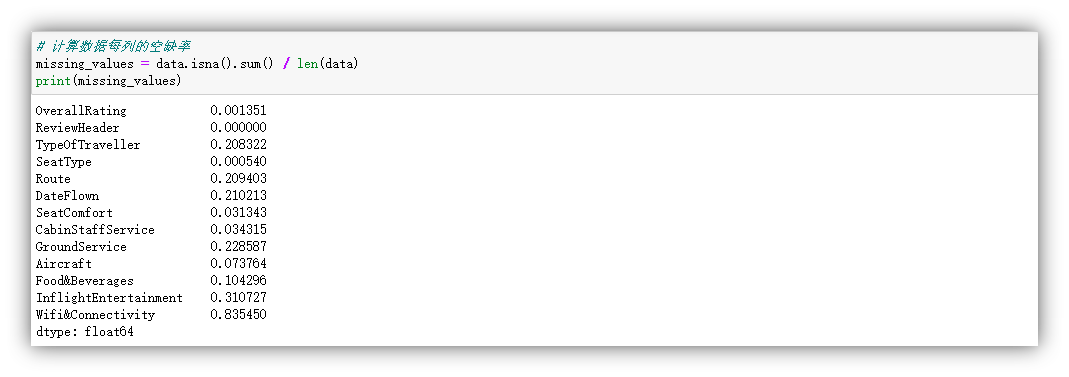
我们注意到'InflightEntertainment'和'Wifi&Connectivity'两列特征的缺失率较高,因此决定删除这两列特征。
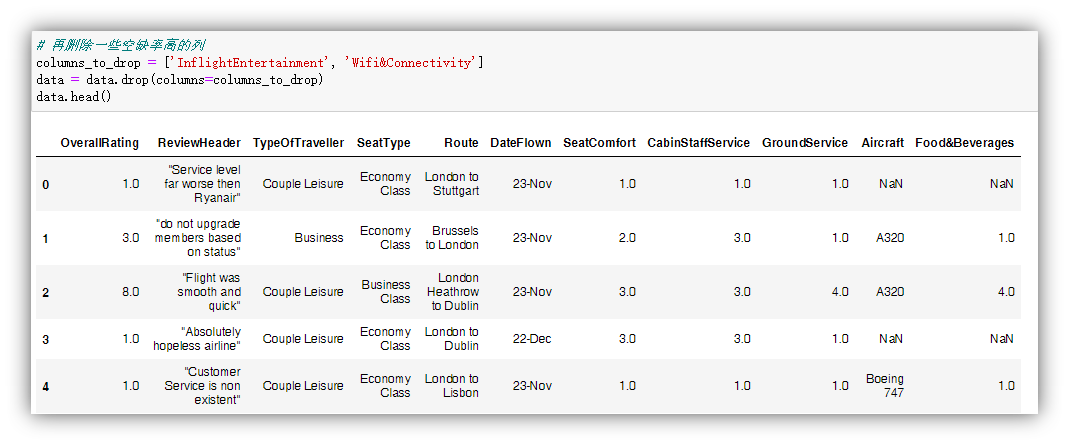
删除包含有空缺值的数据项。

验证所有空缺值是否已经被删除,并且再次检查当前数据集的大小。我们发现剩余2528条数据。

4.3.3 文本规范化
对'Aircraft'特征中存在的一些输入错误进行修正。

4.3.4 增加新字段
为了方便后续实验,对'DateFlown'特征进行处理,使其仅包含月份的缩写。
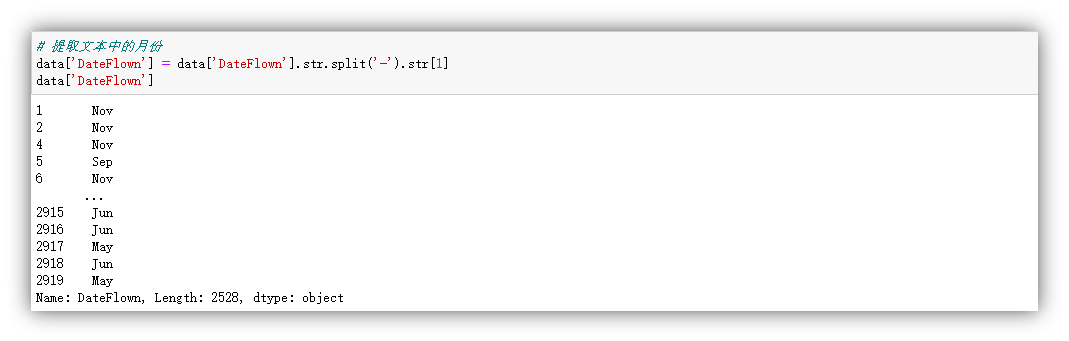
同样,鉴于'Route'特征中的'XXX to XXX'的格式不易利用,决定将其拆分为两个新特征:'Departure'和'Destination'。

此外,还观察到'Route'特征中同时包含一些机场的全称和缩写。因此,需要进一步处理,统一机场名称的表示方式,以确保数据的一致性和准确性。

再次检查数据集的大小和形状,以确保所有预处理步骤已正确执行。

4.4 用HDFS存储文件
启动Hadoop中的HDFS组件。
cd /usr/local/hadoop
./sbin/start-dfs.sh使用 HDFS 命令行工具创建目录。
cd /usr/local/hadoop
./bin/hdfs dfs -mkdir -p /user/airline把本地文件系统中的数据集processedData.csv上传到分布式文件系统HDFS中。
cd /usr/local/hadoop
./bin/hdfs dfs -put /home/hadoop/softwares/processedData.csv /user/airline验证数据是否上传成功。
cd /usr/local/hadoop
./bin/hdfs dfs -ls /user/airline5. 数据分析
在清洗数据集时,我们注意到该数据集涵盖了丰富的信息,具有较高的研究价值。鉴此,本实验将以乘客特征、情感分析、航线表现和飞机体验四个方面为切入点,对该数据集进行深入探究。
5.1 读取数据
由于数据以.csv格式存储,属于结构化数据,因此将其创建为DataFrame形式有助于进行更深入的分析和处理。这里定义了数据集的结构schema,并将其作为参数传递给spark.read.csv()函数,以确保CSV文件按照指定的结构解析加载到DataFrame中。

显示数据的结构化描述。
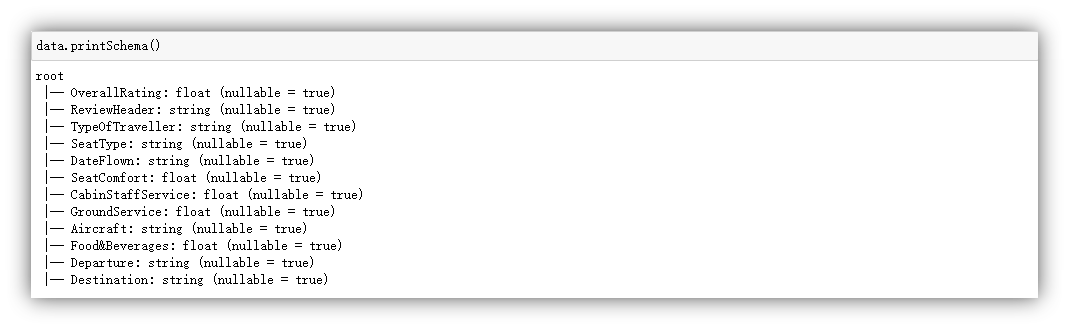
查看已经转化成DataFrame类型的数据的前5行。
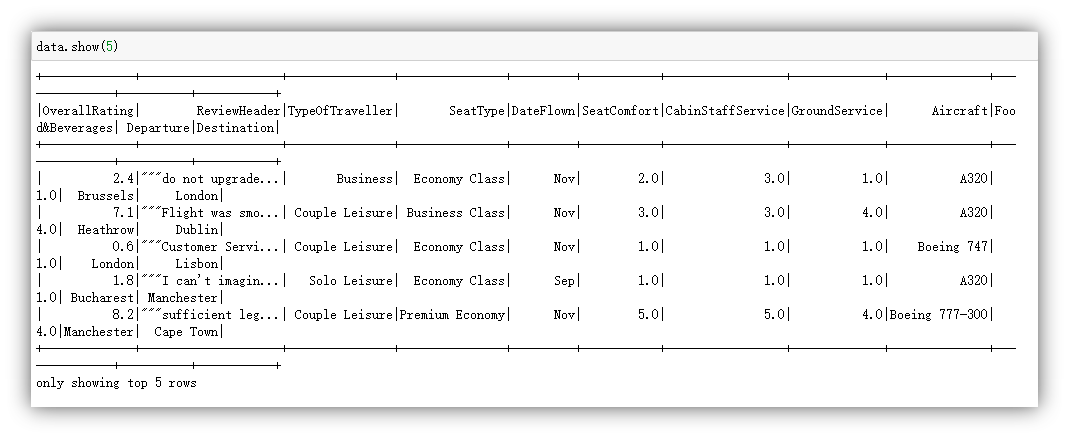
注意到在数据格式转换后数据集中存在少量的空缺值。推测可能是由于在转换过程中,部分数据的类型未能被正确识别而致其成为空值。鉴于空缺值数量不多,本实验决定采用直接删除的方式进行处理。首先,计算每列特征中的空缺值数量。

删除包含空缺值的数据行,并再次检查数据集是否还有空缺值。
5.2 乘客特征分析
5.2.1 分析不同类型乘客的占比
数据分析的思路如下:
1)对不同类型乘客的数量进行统计;
2)计算总共有多少乘客出行;
3)计算每类乘客的占比,并将结果单独存储在新的一列中。
实现的代码如下:

查看分析结果,在确认结果准确无误后,将其保存为.csv文件,以供后续可视化分析使用。

5.2.2 分析商务和休闲乘客数随时间的变化趋势
数据分析的思路如下:
1)从原始数据集中提取“TypeOfTraveller”和“DateFlown”两列,以便集中分析乘客类型及其出行日期;
2)对于“TypeOfTraveller”列,使用字符串匹配方法,将所有包含“Leisure”的子类型统一合并为“Leisure”类别;
3)对处理后的数据进行分组操作,按乘客类型和出行日期进行分组,并统计每个分组中的记录数,以表示每种类型的乘客每月的出行量;
4)对结果进行排序,按乘客类型和日期升序排列,以便于进一步分析。
实现的代码如下:

查看分析结果,在确认结果准确无误后,将其保存为.csv文件,以供后续可视化分析使用。
5.2.3 分析不同舱位乘客的评分分布
数据分析的思路如下:
1)从原始数据集中提取“SeatType”和“OverakkRating”两列,以便分析不同乘客舱位类型对应的评分分布。
实现的代码如下:

查看分析结果,在确认结果准确无误后,将其保存为.csv文件,以供后续可视化分析使用。
5.3 乘客情感分析
5.3.1 分析常见表扬词和常见批评词
数据分析的思路如下:
1)创建一个列表,包含常见的停用词,这些词在文本分析中通常被忽略,因为它们通常没有实际的语义价值;
2)将数据集“ReviewHeader”列中所有非字母和非数字的字符替换为空格,以确保后续的单词提取能够正常进行;
3)按照总评分是否大于等于6分将原始数据集拆分成两个DataFrame,这里假设给出总评分大于等于6分的乘客都是给出积极评论的人;而总评分小于6分的乘客都是给出消极评论的人;
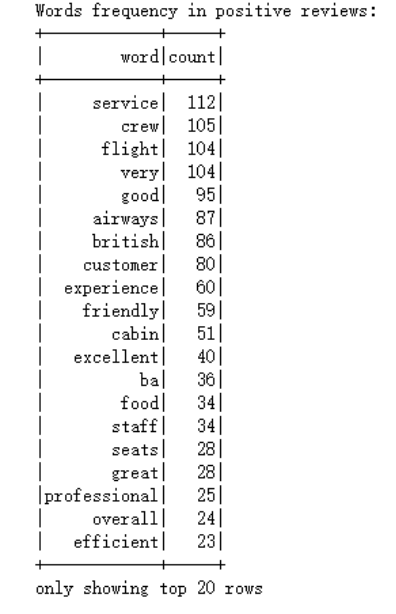
4)对负面评价数据集中的每条评论的“ReviewHeader”列进行拆分,将每个单词作为一个独立的词元,并且过滤掉在停用词列表中出现的词元,以排除常见的无意义词汇。对剩余的词元进行计数,统计每个词元在负面评价中出现的频率。最后,将词元按照出现频率降序排列,以便查看哪些词在负面评价中出现的频率较高。
5)类似地,对正面评价数据集中的每条评论的“ReviewHeader”列进行拆分,并过滤掉停用词列表中的词元。统计每个词元在正面评价中出现的频率,并将结果按照出现频率降序排列。
实现的代码如下:

查看分析结果,在确认结果准确无误后,将其保存为.csv文件,以供后续可视化分析使用。

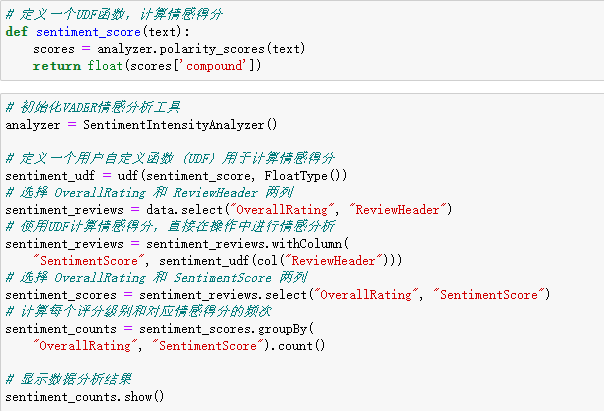
5.3.2 探究情感分析与总体评分的相关性
数据分析的思路如下:
1)创建一个函数,目的是对给定的文本进行情感分析,并返回一个表示情感分数的值。此函数需要使用一种情感分析算法,该算法可以计算文本的情感分数,并将该分数作为函数的输出。
2)创建一个用户定义函数,目的是将情感分数计算函数应用于DataFrame的列数据。这个UDF的功能是对DataFrame中的文本数据执行情感分析,并返回每个文本的情感分数。
3)使用户定义函数,将情感分数计算应用于评论标题列的每一行文本数据。这样就计算出了每个评论标题的情感分数,并将其保存到新的列中。
4)从情感分析结果中选择了总体评分和情感分数两列数据,以备后续统计分析使用。
5)将数据按照总体评分和情感分数两列进行分组。对每个分组(即每个总体评分和情感分数的组合)计算出现次数,以便了解不同情感分数在不同总体评分下的频次分布。
实现的代码如下:
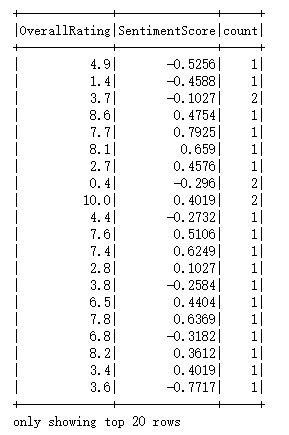
查看分析结果,在确认结果准确无误后,将其保存为.csv文件,以供后续可视化分析使用。
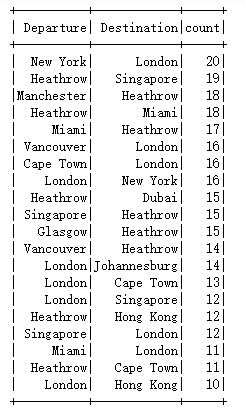
5.4 航线表现分析
5.4.1 统计Top10热门出发地&目的地的航线
数据分析的思路如下:
1)对数据中的’departure’列进行统计,计算每个出发地在数据中出现的频次;
2)对数据中的’destination’列进行统计,计算每个目的地在数据中出现的频次;
3)将出发地频次按照出现次数从高到低进行排序,选取出现次数排名前十的出发地,将前十名出发地的名称存储在一个列表中,以便后续筛选数据使用;
4)同理,将目的地频次按照出现次数从高到低进行排序,选取出现次数排名前十的目的地,将前十名目的地的名称存储在一个列表中,以便后续筛选数据使用;
5)从原始数据中筛选出出发地和目的地同时位于前十名列表中的行,得到常见航线数据。
实现的代码如下:

查看分析结果,在确认结果准确无误后,将其保存为.csv文件,以供后续可视化分析使用。
5.5 飞机体验分析
5.5.1 分析全部乘客的总体评分分布
数据分析的思路如下:
1)对“OverallRating”字段进行分组,我们可以将数据集划分成若干子集,每个子集对应一个特定的评分值。
2)在完成数据分组之后,用count()函数来统计每个评分值的频次。这一步的目的是计算每个评分组中的记录数量,从而了解不同评分在数据集中出现的频率。
实现的代码如下:

查看分析结果,在确认结果准确无误后,将其保存为.csv文件,以供后续可视化分析使用。

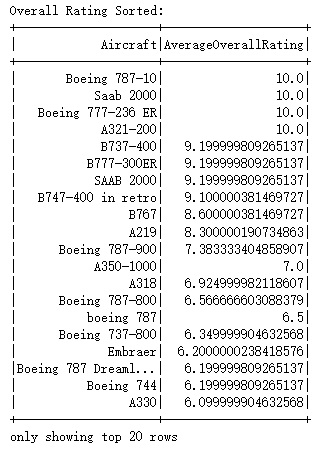
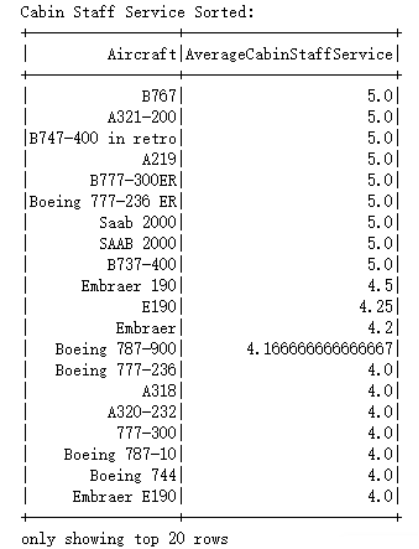
5.5.2 分析各项评分指标中排名最高的10款机型
数据分析的思路如下:
1)从原始数据集中选取了与航空公司评分相关的多个列,包括”Aircraft”, ”OverallRating”, ”SeatComfort”, ”CabinStaffService”, ”GroundService”和”Food&Beverages”。这些列的选择旨在全面评估各个飞机型号在不同服务方面的表现;
2)计算每个飞机型号每个评分项的平均值
3)对每个飞机型号的各项评分进行聚合计算;
4)对各评分项进行降序排序。这一步的目的是确定哪些飞机型号分别在这些评分项上表现最佳。
实现的代码如下:

查看分析结果,在确认结果准确无误后,将其保存为.csv文件,以供后续可视化分析使用。



5.5.3 分析热门机型中各项评分指标的分布
数据分析的思路如下:
1)统计每个飞机型号在数据集中出现的次数,根据飞机型号出现的次数降序排列,选取排名前五的飞机型号作为前五名飞机型号;
2)根据前一步得到的前五名飞机型号列表,从原始数据中筛选出对应的评价数据;
3)对筛选出的前五名飞机型号的评价数据进行分组,每个分组对应一个飞机型号,计算每个飞机型号的各项评分的平均值,其中总体评分因为其满分是10分,而评价项满分为5分,为了方便后面可视化,这里将其除以2;
4)对计算得到的前五名飞机型号的平均评分进行降序排序,就可以确定哪些飞机型号在各个评分项上表现最佳。
实现的代码如下:

查看分析结果,在确认结果准确无误后,将其保存为.csv文件,以供后续可视化分析使用。

5.5.4 基于spark MLlib组件的分析
5.5.4.1 数据处理
数据分析的思路如下:
1)从原始数据中选择了几个与航空公司评价相关的列,包括总体评分、乘客类型、座位类型、飞行日期以及座位舒适度、机舱服务、地面服务和食品饮料等评分;
2)将乘客类型列中的“Solo Leisure”、“Family Leisure”和“Couple Leisure”统一转换为“Leisure”,以简化数据集的分析和建模过程;
3)使用字符串索引器将乘客类型、座位类型和飞行日期等列转换为数值索引;
4)对数值索引进行独热编码,将分类特征转换为二进制向量,以便机器学习模型能够理解和处理;
5)对数值型特征和分类特征进行向量组合,形成模型训练所需的特征向量;
6)创建一个管道,将所有特征处理过程组合在一起,形成一个完整的数据处理流程,并且使用管道拟合原始数据集,对数据进行处理和转换;
7)将处理后的数据集划分为训练集和测试集,以便在模型训练和评估时使用;此外,还设置随机种子以确保每次划分的结果一致。
实现的代码如下:

查看分析结果,在确认结果准确无误后,将其保存为.csv文件,以供后续可视化分析使用。
{kind=link}
5.5.4.2 变量的相关性
数据分析的思路如下:
1)使用Spearman相关系数计算特征向量和目标变量之间的相关性;这一步骤生成了一个相关系数矩阵,其中包含了所有特征之间的相关性;
2)从相关系数矩阵中提取出相关系数数据,并将其转换为一个数组,这个数组将用于后续的分析和可视化。
实现的代码如下:

{kind=link}
5.5.4.3 回归评估器的训练
数据分析的思路如下:
1)使用给定的训练数据拟合指定的机器学习模型,并使用训练后的模型对测试数据进行预测,并使用评估器计算模型的性能指标;
2)从训练好的模型中提取特征重要性,并且将特征重要性转换为数组形式,并返回以供后续分析和可视化使用;
3)使用回归评估器创建一个评估器对象,用于评估模型的性能,这个评估器用于计算预测值与实际值之间的均方根误差;
4)调用训练和测试函数,分别使用决策树、随机森林和GBT模型进行训练和评估。
实现的代码如下:
查看分析结果,在确认结果准确无误后,将其保存为.csv文件,以供后续可视化分析使用。

6. 数据可视化
6.1 乘客特征分析可视化
6.1.1 不同类型乘客的占比可视化

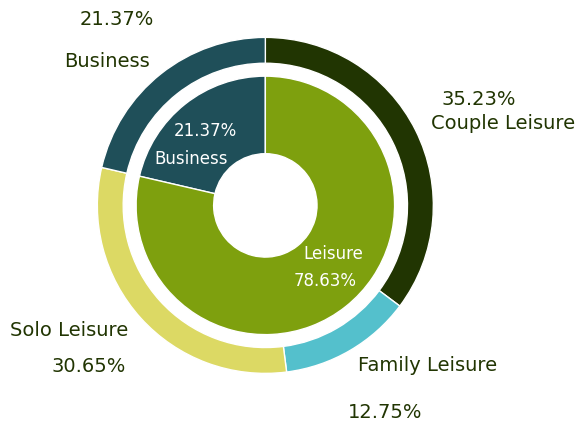
由上图可知,展示了不同类型的乘客在总人数中的比例。从图表中可以看出,休闲类的乘客占据了大部分,其中以情侣休闲为主,占比为35.23%;其次是个人休闲,占比为30.65%;家庭休闲则占了12.75%。商务旅行者的比例相对较小,仅为21.37%。
通过这张图表,我们可以了解到当前旅游市场的主流趋势是以休闲为主的旅行方式,尤其是情侣和个体游客的需求较大。同时,商务旅行虽然占比不高,但也是一个重要的市场细分领域。
6.1.2 商务和休闲乘客数随时间的变化趋势可视化

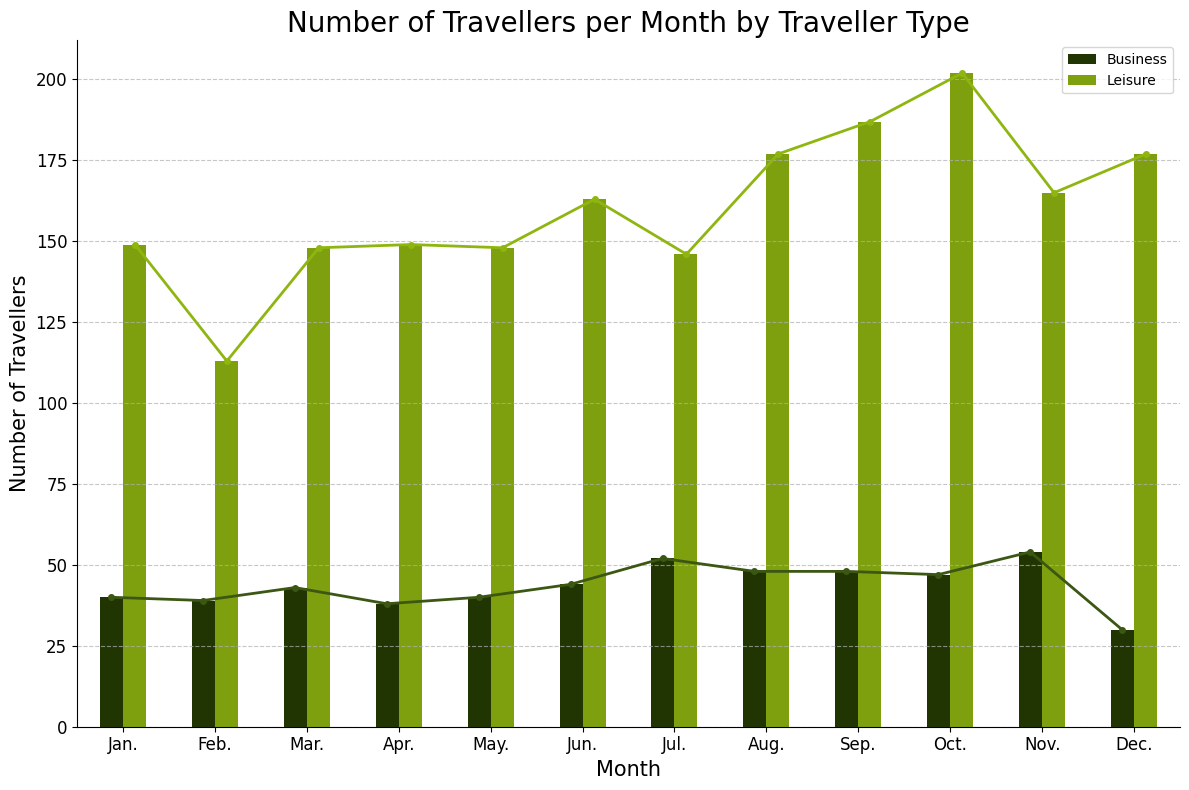
由上图可知,从整体上看,休闲旅行者的人数明显高于商务旅行者,这可能是因为休闲旅行更受大众欢迎,而且不受工作日程限制。另一方面,商务旅行通常与工作相关,因此其数量可能会受到季节性因素的影响。
其次,我们可以看到休闲旅行者的人数呈现出明显的季节性波动。一般来说,夏季(六月至八月)是休闲旅行的高峰期,这可能是由于学校假期和天气原因导致的。相反,冬季(十二月至二月)则是休闲旅行的低谷期,这可能是因为寒冷的天气和圣诞节等节日使得人们更倾向于待在家里。
对于商务旅行者来说,其人数也存在一定的季节性波动,但不如休闲旅行者那么显著。一般来说,春季(三月至五月)和秋季(九月至十一月)是商务旅行的高峰期,这可能是因为这些时期通常是商业活动较为活跃的时候。而夏季和冬季则是商务旅行的低谷期,这可能是因为许多公司在这两个时间段内会放长假或者减少业务活动。
6.1.3 不同舱位乘客的评分分布可视化

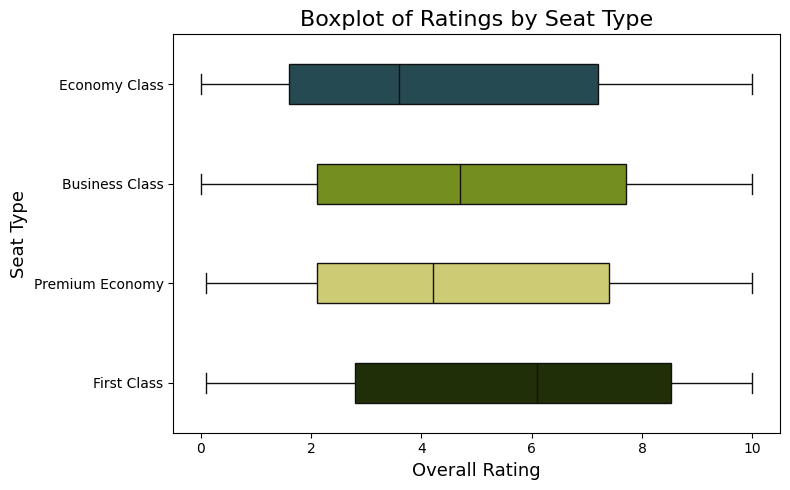
从图中可以看出,经济舱的平均评分为4,商务舱的评分为5.5,高级经济舱的评分为5.0,头等舱的评分为7.0。下面我们将分别探讨每个舱位的评分及其可能的原因。
首先,经济舱的评分最低,为4。这可能是因为经济舱座位空间有限,舒适度较差,且乘客经常面临拥挤的环境。此外,经济舱的餐饮质量一般,娱乐设施也不如其他舱位丰富。
其次,商务舱的评分为5.5,略高于经济舱。商务舱提供了更多的腿部空间和舒适的座椅,乘客还可以享受更好的餐饮和娱乐体验。此外,商务舱的乘客通常可以获得优先登机和行李处理的服务,这也是吸引高价值客户的卖点之一。
再来看高级经济舱,它的评分为5。高级经济舱介于经济舱和商务舱之间,提供比经济舱更大的座椅空间和额外的舒适设施,比如可调节的座椅靠背和脚踏板。然而,与商务舱相比,高级经济舱的餐饮和娱乐选项可能较少,因此评分稍低一些。
最后,头等舱的评分为最高,达到了7.0。头等舱提供最豪华的飞行体验,包括宽敞的私人包厢、定制的餐饮服务、丰富的娱乐选择以及个性化的管家服务。这些高端设施和优质服务使头等舱成为那些追求极致奢华和舒适体验的乘客首选。
总结起来,这张图表反映了不同舱位等级的乘客对英国航空公司的评价。经济舱的评分最低,而头等舱的评分最高。这表明随着舱位等级的提高,乘客的满意度也随之提高。为了提高整体评分,英国航空公司可以通过改善经济舱的舒适性和升级高级经济舱的设施来提高乘客的满意度。
6.2 乘客情感分析可视化
6.2.1 常见表扬词和常见批评词可视化

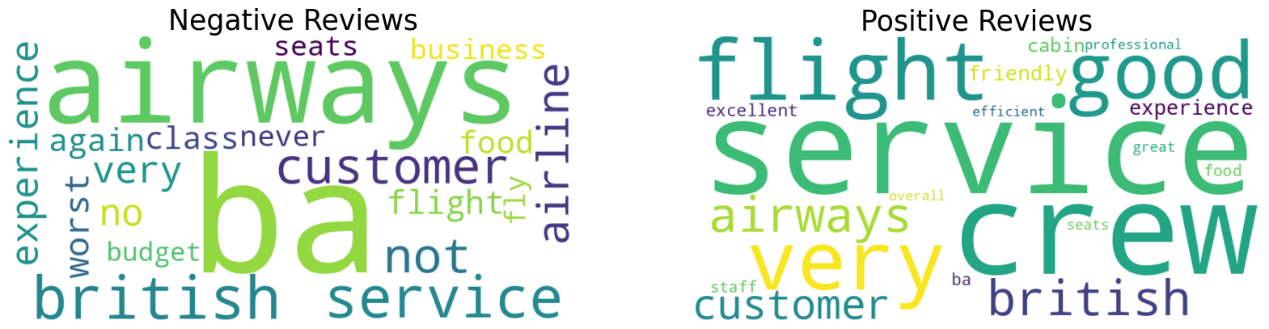
从图中可以看出,负面评论中出现频率最高的词汇包括"airways"、"british"、"customer"、"service"和"food"等。这些词汇暗示着乘客对英国航空公司的不满主要集中在服务质量、食物质量和客户服务等方面。
具体而言,"seats"和"class"的出现频率较高,可能意味着乘客对座位舒适度和舱位等级有所抱怨。"worst"和"experience"的频繁出现则表明有些乘客对他们的飞行经历感到失望。
另一方面,正面评论中的高频词汇包括"good"、"flight"、"very"、"service"和"staff"等。这些词汇反映出乘客对英国航空公司的积极反馈,特别是对其航班体验、员工服务态度和整体服务质量的认可。
有趣的是,"budget"这个词在正面评论中出现得较多,而在负面评论中却很少见到。这可能表明一些乘客认为英国航空公司的价格合理,性价比高。
总之,这张词云图为我们提供了一种快速了解英国航空公司在乘客眼中的形象的方法。通过对比正面和负面评论中的高频词汇,我们可以大致判断出哪些方面得到了乘客的好评,哪些方面有待改进。
6.2.2 情感分析与总体评分的相关性可视化


从图中可以看出,大多数点都分布在一条水平线上,这条线代表总体评分与情感分析得分之间的关系。这条线的斜率接近零,这意味着总体评分与情感分析得分之间并没有很强的相关性。
然而,也有一些点位于这条线的上方或下方。这些点的总体评分与情感分析得分之间存在较大的差距。这可能意味着某些用户对英国航空的评价受到了情绪的影响,而不是客观的事实描述。
进一步观察散点图,可以看到一些点聚集在一起形成了一个大的簇。这些点的总体评分和情感分析得分都非常接近,这可能意味着这些用户对英国航空的评价比较一致,即他们对英国航空的印象相似。
此外,还有一些点分散在整个散点图中,这些点的总体评分和情感分析得分相差较大。这可能意味着这些用户对英国航空的评价受到各种因素的影响,如个人喜好、经验、期望值等。
6.3 航线表现分析可视化
6.3.1 统计Top10热门出发地&目的地的航线



从图中可以看出,伦敦、纽约、香港等城市是热门的出发地和目的地。
首先,我们可以看到伦敦作为全球重要的金融中心之一,其航班数量非常大。这可能是因为伦敦拥有多个大型机场,如希思罗机场和盖特威克机场,这些机场提供了丰富的国际航班服务。此外,伦敦也是欧洲的重要交通枢纽,许多旅客选择在这里转机前往其他地区。
其次,纽约也是一个热门的出发地和目的地。纽约是美国最大的城市之一,也是全球最重要的商业和金融中心之一。因此,许多人需要前往纽约进行商务旅行或旅游活动。
再次,香港作为一个国际化的大都市,吸引了大量游客前来观光购物。同时,香港还是亚洲的重要金融中心之一,许多企业在此设立总部或分支机构。因此,香港的航班需求也非常高。
6.4 飞机体验分析可视化
6.4.1 全部乘客的总体评分分布可视化

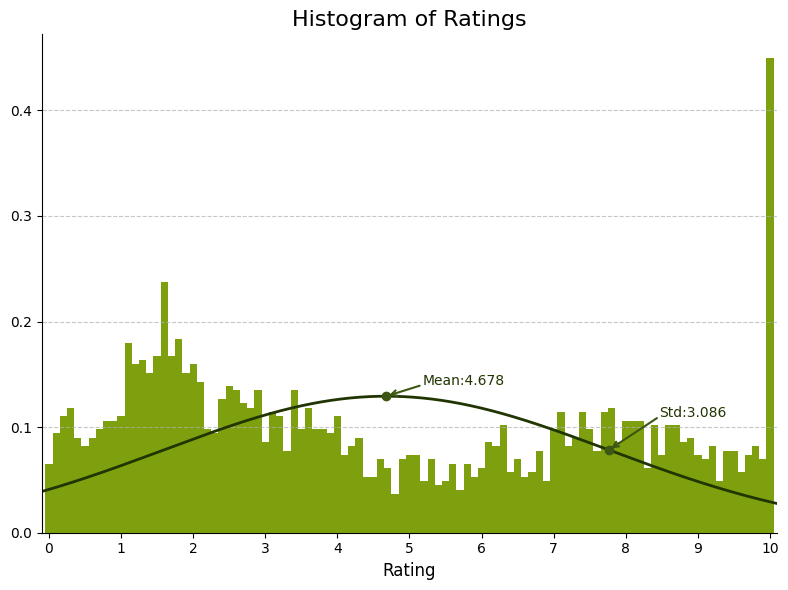
在这个条形图中,评分范围是从1到10,每一分都有相应的柱子表示有多少人给了这个评分。从图中可以看出,评分主要集中在1到3和7到9之间,这表明大部分乘客对英国航空的服务持负面态度或者非常正面的态度。同时,评分的平均值为4.678,标准差为3.086,这表明评分的分布比较分散,没有特别集中的趋势。
6.4.2 各项评分指标中排名最高的10款机型可视化

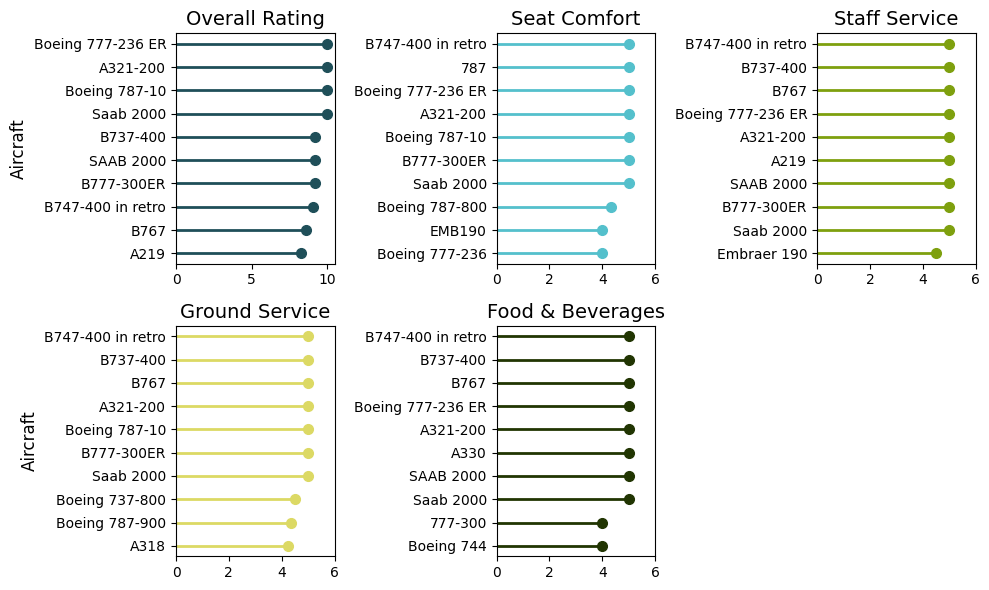
由上图知,可以得出以下几点发现:
波音777-236ER在多项评分中都表现突出,这表明它是一款综合性能优异的飞机,无论是在总体评分还是在具体服务领域,都得到了乘客的高度认可。
波音B737-400、波音B767和空客A321-200等飞机型号在不同评分项中均有出色的表现,这可能与其广泛的使用场景和适应性强的特点有关。
萨博2000和波音737-800等飞机型号在某些评分项中表现不俗,这可能与其特定的功能定位和用户群体有关。
不同类型的飞机在不同评分项中表现各异,这表明乘客的需求和期望在不同情境下有所不同,航空公司需根据不同需求优化服务。
6.4.3 热门机型中各项评分指标的分布可视化

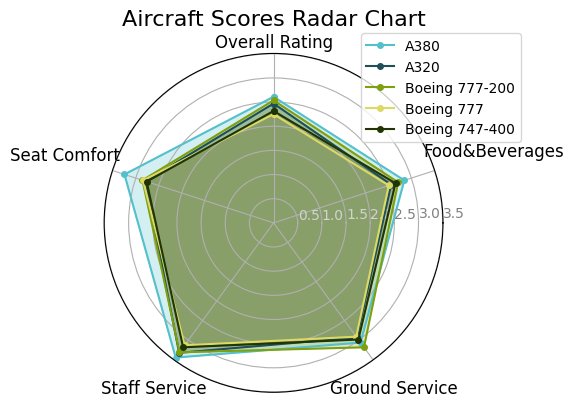
雷达图上看,这五架飞机在总体评分、座椅舒适度、工作人员服务、地面服务和食品及饮料五个维度上进行了评分。总体来看,这五架飞机在各个方面都有一定的表现,但在某些方面表现更为突出。
首先,从雷达图的颜色深浅可以看出,蓝色表示评分较高,绿色表示评分一般。总体评分方面,A380、A320和波音777-200的评分较高,而波音747-400的评分较低。这可能与飞机的新旧程度、设施更新等因素有关。
其次,座椅舒适度方面,A380的评分较高,而波音747-400的评分较低。这可能与飞机的座位布局、间距、座椅舒适度等因素有关。
再者,工作人员服务方面,A380、A320和波音777-200的评分较高,而波音747-400的评分较低。这可能与航空公司的人力资源管理、培训体系等因素有关。
在地面服务方面,波音777-200的评分较高,而波音777的评分较低。这可能与机场设施、地面保障能力、航空公司与机场的合作关系等因素有关。
最后,在食品及饮料方面,A380、A320和波音777-200的评分较高,而波音747-400的评分较低。这可能与飞机餐食的质量、种类、口味等因素有关。
6.4.4 基于spark MLlib组件的分析
6.4.4.1 变量的相关性可视化

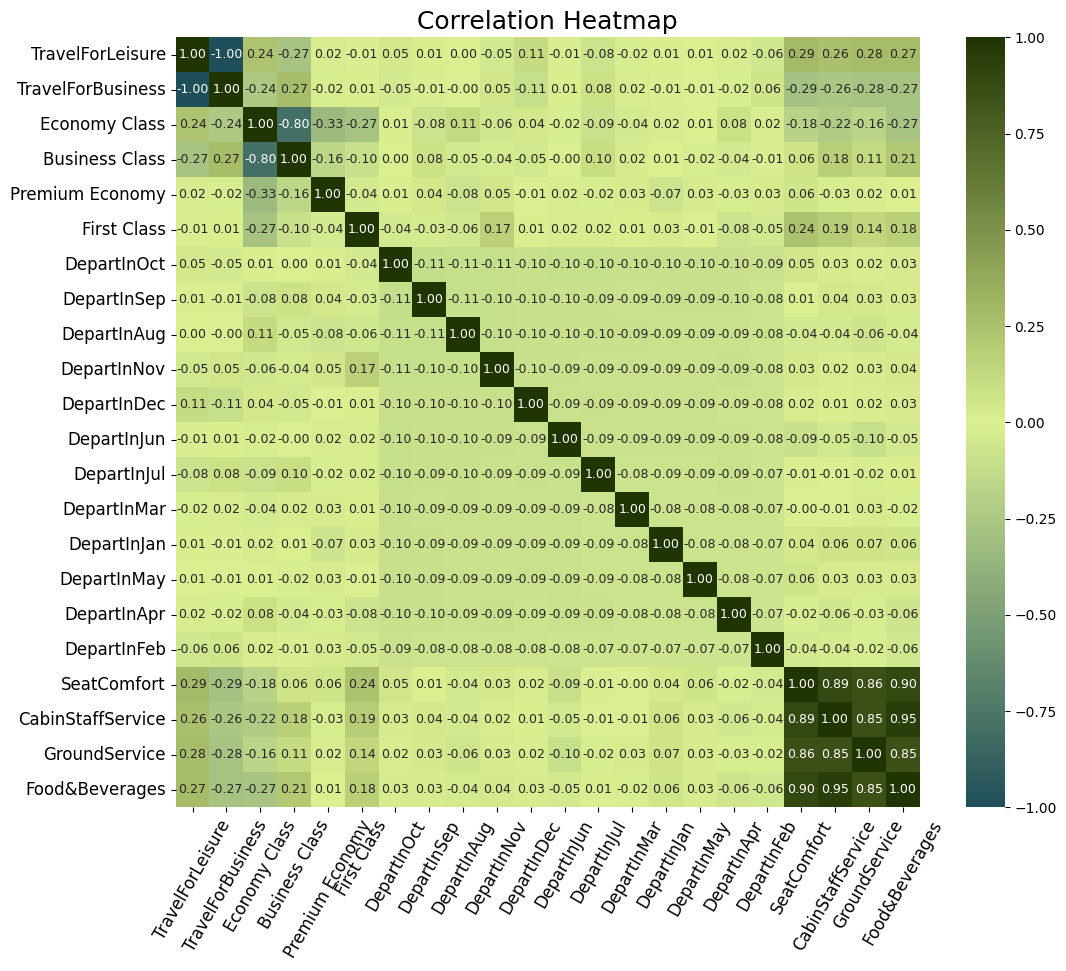
旅行目的、出发月份、座位舒适度、机舱等级、地勤服务、餐饮服务等因素与客户满意度高度相关。例如,旅行目的为休闲旅游的客户对座位舒适度的要求更高,而旅行目的为商务的客户对座位舒适度的要求相对较低。此外,出发月份也会影响客户对座位舒适度的要求,例如在九月和十月,客户对座位舒适度的要求较高。
另外,机舱等级也与客户满意度密切相关。例如,头等舱和商务舱的客户对座位舒适度和机舱等级本身的要求较高,而经济舱的客户对座位舒适度的要求相对较低。同时,机舱等级还与地面服务和餐饮服务紧密相连,例如,头等舱和商务舱的客户对地面服务和餐饮服务的要求较高。
此外,出发月份也与座位舒适度和机舱等级相关。例如,在八月和九月,客户对座位舒适度和机舱等级的要求较高。而在十二月,客户对座位舒适度和机舱等级的要求较低。
6.4.4.2 回归评估器的训练可视化

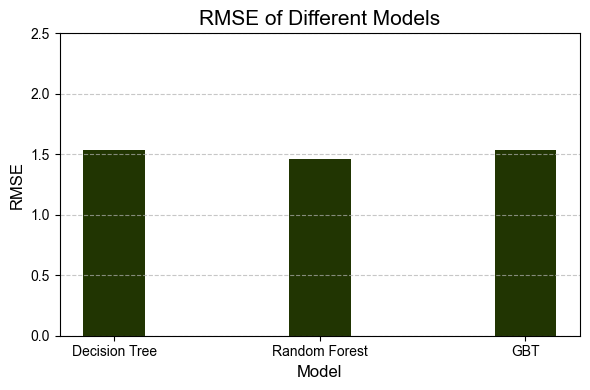
这个图表展示了三种不同模型(决策树、随机森林和梯度提升树)的均方根误差(RMSE)。可以看到,所有模型的RMSE值都在1.0左右,说明这些模型的表现都相当接近。
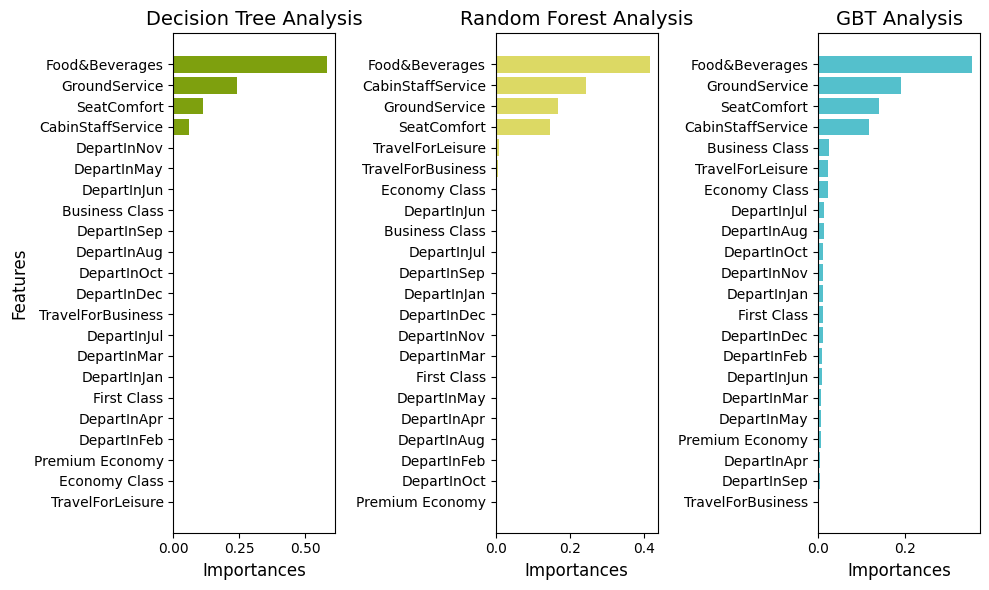
这张图展示了三个不同的分析方法——决策树分析、随机森林分析和GBT(梯度提升树)分析的结果。每个方法都对一系列的特征进行了重要性排序。
在决策树分析中,“Food&Beverages”、“GroundService”和“SeatComfort”是最重要的因素。“CabinStaffService”、“DepartinNov”和“DepartinMay”等其他因素也具有一定的影响力。
随机森林分析则显示,“Food&Beverages”、“GroundService”、“SeatComfort”和“CabinStaffService”是最关键的因素。此外,“TravelForLeisure”、“BusinessClass”和“EconomyClass”等因素也有一定的重要性。
最后,在GBT分析中,“Food&Beverages”、“GroundService”、“SeatComfort”和“CabinStaffService”仍然是最重要的因素。然而,“TravelForBusiness”、“FirstClass”和“PremiumEconomy”等其他因素的重要性有所提高。
总的来说,这些结果表明,“Food&Beverages”、“GroundService”和“SeatComfort”是影响决策的关键因素,无论使用哪种分析方法。这可能是因为这些因素直接关系到乘客的舒适度和满意度。同时,不同分析方法得出的结果存在差异,说明了选择合适的分析方法对于理解数据的重要性。

7. 遇到的问题与解决方法
在实验过程中,我们遇到了 Spark 和 Python 版本不兼容的问题。直接更改系统的 Python 版本可能导致其他依赖的崩溃,给环境管理带来麻烦。幸运的是,我们发现可以利用 Anaconda 虚拟环境来解决这个问题。通过在 Anaconda 中创建一个指定低版本 Python 的虚拟环境,我们能够完美适配 Spark 的版本需求,从而顺利进行实验。
8. 实验总结
通过本次实验,我们成功地对英国航空的客户反馈数据进行了系统性研究。利用大数据处理框架 Spark 和 Hadoop,我们实现了数据的高效存储和处理,并通过先进的数据可视化技术直观地展示了分析结果。借助机器学习模型,我们还能够预测乘客对英国航空的评分,从而为改进客户服务提供了有力的数据支持。
总之,本次实验展示了大数据技术和数据分析在实际应用中的巨大潜力,自己感觉也在本次实验中收获颇多。
附录
Data文件夹里存的是原始数据+中间结果
三个代码dataProcessing.ipynb对应数据预处理,dataAnalysis.ipynb对应数据分析,Visualization.ipynb对应可视化
Data文件夹里,BA_AirlineReviews.csv对应原始数据,processedData.csv对应数据预处理的结果,其余文件都为spark数据分析的中间结果。