
【版权声明】版权所有,严禁转载,严禁用于商业用途,侵权必究。
作者:厦门大学人工智能研究院2023级研究生 谢万城
指导老师:厦门大学数据库实验室 林子雨 博士/副教授
时间:2024年6月
相关教材:林子雨编著《Flink编程基础(Java版)》(访问教材官网)
相关案例:Flink大数据处理分析案例集锦
相关案例:基于Python语言的Spark数据处理分析案例集锦(PySpark)
1.任务描述
基于Python和Flink工具,针对真实的气象站点所采集到的空气质量时序数据,计算全国多个城市的8小时移动平均空气质量信息(包括AQI空气质量指数、PM2.5、SO2等信息),更新空气质量榜单,并进行详细的数据可视化。
操作环境为:Ubuntu18.04,Flink1.17.0,Hadoop 3.3.5,Python3.8.10,bash命令行,utf-8编码,Pandas1.3.5,Pycharm 2024.1。
本案例使用Java语言编写Flink程序。使用Python语言编写网络爬虫程序,从链家网站爬取厦门二手房数据,然后进行数据清洗,保存到分布式文件系统HDFS中,接下来使用Java语言编写Flink程序进行数据分析,最后,采用PyECharts和网页形式进行数据可视化。
2.数据处理
2.1数据集信息
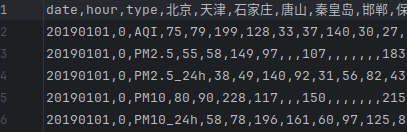
数据集采用南京信息工程大学第十五届数学建模赛题附件1-附件1的2019年数据(从百度网盘下载数据集和代码)(提取码是ziyu),其中每个csv文件的每一行表示全国300多个城市的某一指标数据,存在数据缺失,包含AQI、PM2.5、SO2、NO等指标的每小时实时值与8小时移动平均值,列名如下图所示:
2.2数据清洗
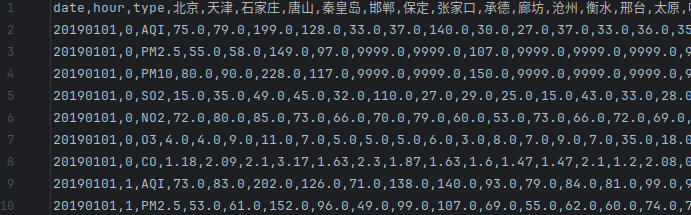
采用Pandas读取1月份csv文件,去重,填充缺失值为9999,仅保留实时值,去除已经计算好的8小时移动平均值,按照时间顺序排列数据,最终整合得到data2019_dist.csv文件如下图所示:
编写data_clean.sh脚本,安装必要依赖,创建HDFS目录,并使用hdfs dfs -put 命令将数据集文件上传到HDFS如下:
alias python=python3
pip install pyhdfs
pip install apache-flink==1.17.0
python data_clean.py
echo --------------上传数据文件至HDFS-----------------
hdfs dfs -mkdir -p 36920231153246xwc/数据集
hdfs dfs -put -f 数据集/data2019_dist.csv 36920231153246xwc/数据集
hdfs dfs -put -f 数据集/citylist.txt 36920231153246xwc/数据集
echo --------------已上传数据文件至HDFS-----------------3.基于PyFlink的流计算框架
3.1总体框架
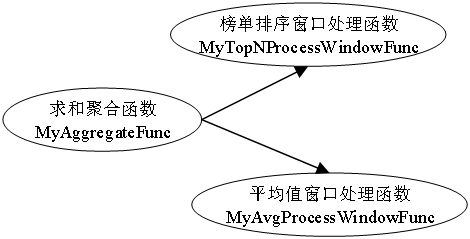
针对空气质量数据的基于PyFlink的流计算总体框架如下图所示,首先从HDFS数据源获取数据,并定义数据格式,得到原始Datastream流,然后对原始Datastream进行格式转换,并定义水位线生成策略,将日期与小时作为事件时间,通过filter选取指定的几个空气质量指标,得到带事件时间的Datastream。随后定义窗口算子,包括聚合函数与窗口处理函数,从而执行得到各个分支下的数据报表,包括8小时移动平均数据,榜单数据等,最后进行可视化。
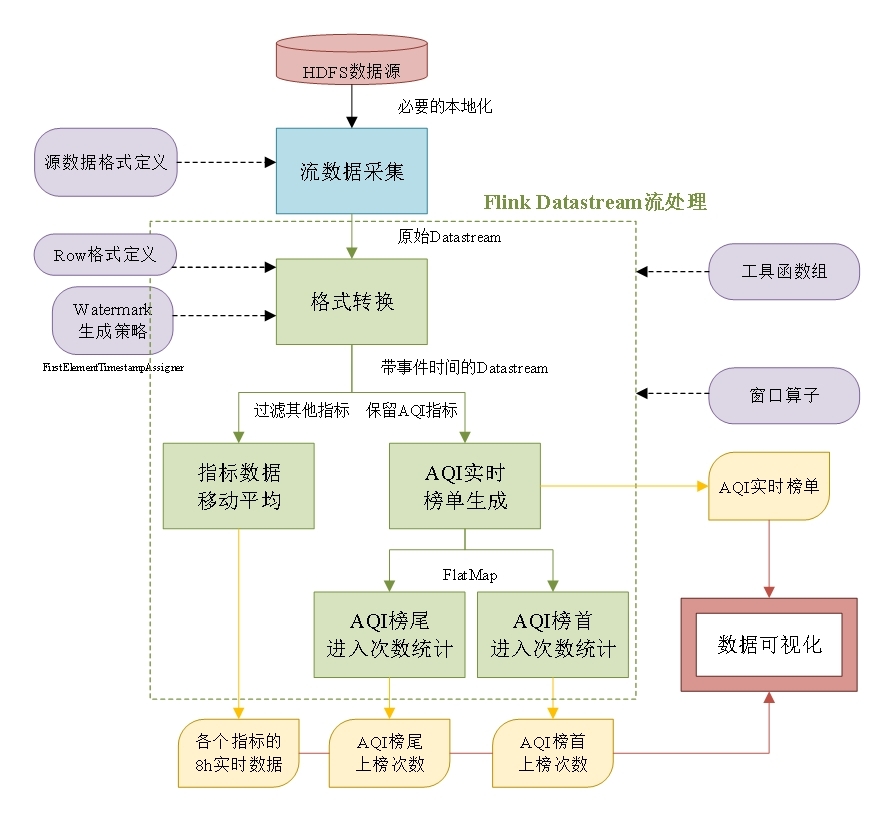
下面将具体介绍该框架的实现,包括思路与代码实现。
3.2数据的采集与转换
本步骤将csv源数据定义为可使用算子进行计算的Datastream。定义数据源FileSource后,首先定义表CsvSchema,包括定义每一列的数据类型,分隔符等,然后构造csv的FileSource与原始Datastream。为保持程序扩展性,将数据集文件与HDFS进行同步,并读取HDFS文件,若读取失败则读取本地文件。接着将原始Datastream映射为指定格式的Row类型,分配事件时间与水位线策略,代码实现如下:
class FirstElementTimestampAssigner(TimestampAssigner):
def extract_timestamp(self, value, record_timestamp):
return value[0] * 1000 # !!!!!!!!实测需要乘以1000
.......
new_row_types = [Types.LONG(), Types.STRING()] + [Types.FLOAT() for _ in range(num_cities)]
watermark_strategy=WatermarkStrategy.for_bounded_out_of_orderness(Duration.of_seconds(0)).with_timestamp_assigner(FirstElementTimestampAssigner())
data_stream = env.from_source(csv_source, watermark_strategy, "csv-source")
# 将时间戳转换为datetime,定义时间戳
processed_stream = data_stream \
.map(parse_row, output_type=Types.ROW(new_row_types)) \
.assign_timestamps_and_watermarks(watermark_strategy)需要注意的是事件时间的定义部分需要将时间戳乘以1000,并要使用算子assign_timestamps_and_watermarks来为Datastream分配时间戳。将输出类型定义为Row相较于Tuple的好处是可以支持25个字段以上的表。
3.38h移动平均数据计算
通过filter算子过滤掉不考虑的指标后,使用key_by算子定义键名,以分别对不同指标进行聚合。然后设置长度为8小时,步长1小时的滑动窗口,定义aggregate聚合算子,结合聚合函数AggregateFunction与窗口处理函数ProcessWindowFunction来分别完成计数求和与平均的操作。需要注意,空值被设置为9999,因此计算时需要跳过。
求和聚合函数MyAggregateFunc需要维护一个累加器,用于统计有效数据的个数与求和,
平均值窗口处理函数MyAvgProcessWindowFunc用于计算平均值,并格式化输出为csv的单行的字符串形式,使用FileSink持久化为csv文件。代码实现如下:
def avg(elements):
# convert "%Y-%m-%d %H:%M:%S" to "%Y-%m-%d_%H_%M_%S"
res=[datetime.fromtimestamp((datetime.strptime(elements[0][0], "%Y-%m-%d %H:%M:%S")).timestamp()).strftime("%Y-%m-%d_%H_%M_%S")]
for value in elements:
res.append(value[1]) # key
for c in range(NUM_CITIES):
value[2][c] = value[2][c] / value[3][c] if value[3][c] != 0 else INVALID_VAL
res.append(value[2][c])
return res
class MyAggregateFunc(AggregateFunction): # 把原始的row聚合为一个accumulator
def create_accumulator(self):
return ["", "", [0 for _ in range(NUM_CITIES)], [0 for _ in range(NUM_CITIES)]]
def add(self, value, accumulator):
for i, v in enumerate(value[2:]):
if v != INVALID_VAL:
accumulator[2][i] += v
accumulator[3][i] += 1
accumulator[0] = datetime.fromtimestamp(value[0]).strftime("%Y-%m-%d %H:%M:%S")
accumulator[1] = value[1]
return accumulator
def get_result(self, accumulator):
return accumulator
def merge(self, acc_a, acc_b):
return None
class MyAvgProcessWindowFunc(ProcessWindowFunction): # only prints the window content
def process(self, key, context, elements):
res = avg(elements)
yield ",".join([str(r) for r in res])
for indicator in indicators:
indicator_filter = (lambda row: row[1] in indicators) if not GROUP_BY_INDICATOR else lambda row: row[1] == indicator
file_sink = FileSink.for_row_format(f"output/cities_{indicator if GROUP_BY_INDICATOR else ''}", Encoder.simple_string_encoder()) \
.with_output_file_config(OutputFileConfig.builder().with_part_prefix("slide_output").with_part_suffix(".csv").build()) \
.build()
final_streams = processed_stream.filter(indicator_filter)
final_streams.process(TimestampAssignerProcessFunctionAdapter())
#
final_streams \
.key_by(lambda row: row[1]) \
.window(SlidingEventTimeWindows.of(size=Time.hours(8), slide=Time.hours(1))) \
.aggregate(MyAggregateFunc(), MyAvgProcessWindowFunc()) \
.map(lambda x: x, output_type=Types.STRING()) \
.sink_to(file_sink)
if not GROUP_BY_INDICATOR:
break3.4AQI榜单计算
首先使用格式转换后得到的Datastream,过滤仅保留AQI条目,通过24小时滚动窗口进行求和与排序,得到包含榜首与榜尾城市列表的日更新数据,并持久化为csv。
随后,使用flat_map算子分别对榜首数据与榜尾数据的城市的出现次数进行统计,得到本月中每个城市的上榜次数。具体实现如下:
class MyTopNProcessWindowFunc(ProcessWindowFunction):
def process(self, key, context, elements):
res = avg(elements)
if random.random()<0.01:
print("更新城市AQI榜单中............")
top_k_curr = min(TOP_K_CITY, len(res[2:]))
botN = sorted(zip(res[2:], range(NUM_CITIES)), key=lambda x: x[0], reverse=True)
# drop invalid values
botN = [x for x in botN if x[0] != INVALID_VAL][:top_k_curr] # 极大值9999
botN, botN_inds = zip(*botN)
topN = sorted(zip(res[2:], range(NUM_CITIES)), key=lambda x: x[0])[:top_k_curr]
topN, topN_inds = zip(*topN)
res = [l2s(res[0:1]),
l2s([cities[CITIES_SELECTED_inds[i]] for i in topN_inds], " "),
l2s([cities[CITIES_SELECTED_inds[i]] for i in botN_inds], " "),
l2s(topN, " "),
l2s(botN, " "),
]
# print("Aggregated TopN elements: ", topN_inds, topN)
yield l2s(res)
aqi_stream = processed_stream.filter(lambda row: row[1] == "AQI")
res1 = aqi_stream \
.key_by(lambda row: row[1]) \
.window(TumblingEventTimeWindows.of(Time.hours(24))) \
.aggregate(MyAggregateFunc(), MyTopNProcessWindowFunc()) \
.filter(lambda x: datetime.strptime(x.split(",")[0], "%Y-%m-%d_%H_%M_%S").hour != 23)
res1.map(lambda x: x, output_type=Types.STRING()) \
.sink_to(FileSink.for_row_format(f"output/cities_AQI_topN", Encoder.simple_string_encoder())
.with_output_file_config(OutputFileConfig.builder().with_part_prefix("aqi_output").with_part_suffix(".csv").build())
.build())
def flat_mapper1(row):
return splitter(splitter(row)[1], " ")
def flat_mapper2(row):
return splitter(splitter(row)[2], " ")
# -------------统计每个城市在榜首和榜尾的出现次数----------------
# 分流
res1 \
.flat_map(flat_mapper1).map(lambda x: (x, 1), output_type=Types.TUPLE([Types.STRING(), Types.INT()])) \
.key_by(lambda row: row[0]) \
.sum(1) \
.map(lambda x: f'{x[0]},{x[1]}', output_type=Types.STRING()) \
.sink_to(FileSink.for_row_format(f"output/cities_AQI_topN_count", Encoder.simple_string_encoder())
.with_output_file_config(OutputFileConfig.builder().with_part_prefix("topN_count").with_part_suffix(".csv").build())
.build())
res1 \
.flat_map(flat_mapper2)其中需要注意的是末尾一天会多余一个23时的数据,应当滤除。
最后需要调用env.execute执行流计算,然后更新HDFS的流数据。此处需要选取修改时间最新的文件作为可视化的数据来源。
各个窗口算子的依赖关系或执行流程如下,其中两个ProcessWindowFunction复用一个AggregateFunction:
4.流计算结果展示
4.1运行步骤
本任务从300个城市中随机选取40个城市。首先使用chmod total.sh 777 命令为total.sh分配执行权限,然后执行./total.sh进行该实验全流程的运行。该脚本会自动安装所需依赖,包括pip、pyhdfs、apache-pyflink==1.17.0,Pandas=1.3.5。如遇到报错请检查环境变量与python必要依赖,例如HADOOP_HOME、JAVA_HOME是否设置,PATH环境是否包含$HADOOP_HOME/bin目录。如不使用HDFS,请将flink_process.py中USE_HDFS改False。请确保hadoop3.3.5守护进程已经通过sbin目录中的start-all.sh运行,并关闭代理服务。total.sh内容如下:
sudo apt-get install python3-pip
echo -------------修改CLASSPATH保证hadoop依赖完整-----------------
export HADOOP_CLASSPATH=`hadoop classpath`
export HADOOP_CLASSPATH=`${HADOOP_HOME}/bin/hadoop classpath`
pip config set global.index-url --site https://mirror.sjtu.edu.cn/pypi/web/simple/
sudo ln -s /usr/bin/python3 /usr/bin/python
pip install pandas==1.3.5 matplotlib
chmod 777 data_clean.sh
./data_clean.sh
python flink_process.py
python visualize.py其中,data_clean.sh的代码如下:
alias python=python3
pip install pyhdfs
pip install apache-flink==1.17.0
python data_clean.py
echo --------------上传数据文件至HDFS-----------------
hdfs dfs -mkdir -p 36920231153246xwc/数据集
hdfs dfs -put -f 数据集/data2019_dist.csv 36920231153246xwc/数据集
hdfs dfs -put -f 数据集/citylist.txt 36920231153246xwc/数据集
echo --------------已上传数据文件至HDFS-----------------其中,data_clean.py的代码如下:
import pandas as pd
import os
def del_files(path):
for i in os.listdir(path):
if os.path.isdir(os.path.join(path, i)):
del_files(os.path.join(path, i))
os.remove(os.path.join(path, i))
print("-----------------数据清洗中---------------------")
data_tmp_path = "数据集/data2019_tmp"
data_path = "数据集/data2019"
os.makedirs(data_tmp_path, exist_ok=True)
files = os.listdir(data_path)
days = 31 # 筛选的天数
files = sorted(files)
for file in files[:days]:
data = pd.read_csv(f"{data_path}/" + file)
data = data.drop_duplicates() # 去除重复
data = data.reset_index(drop=True) # 重置索引
data = data[~data["type"].str.contains("_")] # 去除数据集已经计算好的移动平均结果用于演示
data.to_csv(data_tmp_path + "/" + file, index=False)
print(file + "处理完成")
# 合并
data_dist = pd.DataFrame()
for file in os.listdir(data_tmp_path):
data = pd.read_csv(data_tmp_path + "/" + file)
data_dist = pd.concat([data_dist, data], ignore_index=True)
data_dist.fillna(9999, inplace=True) # 空值填充
data_dist = data_dist.sort_values(by=['date', 'hour']) # 根据日期排序
data_dist.to_csv("数据集/data2019_dist.csv", index=False)
del_files(data_tmp_path)
os.removedirs(data_tmp_path)
print("-----------------数据清洗完成---------------------")其中,flink_process.py的代码如下:
import glob
import os
import pwd
import random
import time
import shutil
from pyflink.common import Types, WatermarkStrategy, Time, Duration, Instant, Row
from pyflink.common.watermark_strategy import TimestampAssigner
from pyflink.datastream import StreamExecutionEnvironment, TimeCharacteristic, ProcessWindowFunction
from pyflink.table import DataTypes
from pyflink.datastream.connectors.file_system import FileSource, FileSink, OutputFileConfig
from pyflink.datastream.formats.csv import CsvSchema, CsvReaderFormat, CsvSchemaBuilder
from pyflink.datastream.window import SlidingEventTimeWindows, TimeWindow
from pyflink.common.serialization import Encoder
from pyflink.datastream.window import TumblingEventTimeWindows
from datetime import datetime
from pyflink.datastream.functions import AggregateFunction, ProcessFunction, AllWindowFunction
import pyhdfs
USE_HDFS = True
OS_USERNAME = pwd.getpwuid(os.getuid())[0]
HDFS_ROOT = '36920231153246xwc' # 个人作业文件上传位置
HDFS_PORT = 9870
DATA_CSV_HDFS_PATH = "数据集/data2019_dist.csv"
CSV_FILE_PATH = "数据集/data2019_dist.csv"
CITY_LIST_PATH = "数据集/citylist.txt"
if not USE_HDFS:
with open(CITY_LIST_PATH, "r", encoding="utf-8") as f:
cities = f.read().splitlines()[0].split(",")
else:
fs = pyhdfs.HdfsClient(hosts=f"localhost:{HDFS_PORT}", user_name=OS_USERNAME)
HOME = fs.get_home_directory()
with fs.open(f"{HOME}/{HDFS_ROOT}/{CITY_LIST_PATH}") as f:
cities = f.read().decode("utf-8").splitlines()[0].split(",")
dataset_path = f"{HOME}/{HDFS_ROOT}/{DATA_CSV_HDFS_PATH}"
fs.copy_to_local(f"{HOME}/{HDFS_ROOT}/{DATA_CSV_HDFS_PATH}", CSV_FILE_PATH)
print("-------------数据集下载完成----------------")
CITIES_SELECTED_inds = []
NUM_CITIES = 40 # 由于java的元组只支持25个元素,所以这里只取20个城市
INVALID_VAL = 9999.0
DEBUG = False
GROUP_BY_INDICATOR = False # 是否按指标分文件
TOP_K_CITY = 5 # 查看空气质量排名前几位的城市
if os.getenv('HADOOP_CLASSPATH') is None:
DIRECT_HDFS=False
else:
DIRECT_HDFS=True
os.system(r"export HADOOP_CLASSPATH=`hadoop classpath`")
os.system(r"export HADOOP_CLASSPATH=`${HADOOP_HOME}/bin/hadoop classpath`")
random.seed(2)
def sort_file_by_mtime(files, ascending=False):
stats = list(map(lambda x: os.stat(x).st_mtime, files))
return list(list(zip(*sorted(zip(stats, files), key=lambda x: x[0], reverse=not ascending)))[1])
def parse_row(row): # 对原始csv
# 转换日期和时间为 datetime 对象并生成时间戳
dt = datetime.strptime(f"{row[0]} {row[1]}", "%Y%m%d %H")
tmp = row[3:]
res = [int(dt.timestamp())] + [row[2]] + [tmp[i] for i in CITIES_SELECTED_inds]
return Row(*res)
def filter_empty_values(row):
# 将9999.0替换为None,并返回过滤后的行
return [row[0]] + [None if val == 9999.0 else val for val in row[1:]]
def avg(elements):
res = [datetime.fromtimestamp((datetime.strptime(elements[0][0], "%Y-%m-%d %H:%M:%S")).timestamp()).strftime(
"%Y-%m-%d_%H_%M_%S")]
for value in elements:
res.append(value[1]) # key
for c in range(NUM_CITIES):
value[2][c] = value[2][c] / value[3][c] if value[3][c] != 0 else INVALID_VAL
res.append(value[2][c])
return res
def l2s(l, sep=','):
return sep.join([str(i) for i in l])
def splitter(row, sep=","):
return row.split(sep)
class FirstElementTimestampAssigner(TimestampAssigner):
def extract_timestamp(self, value, record_timestamp): # 自定义时间戳提取器
return value[0] * 1000 # !!!!!!!!
class MyDebugWindowFunc(AllWindowFunction[tuple, tuple, TimeWindow]):
def apply(self, window, inputs):
if DEBUG:
out = "**************************WindowFunc**************************" \
"\nwindow: start:{} end:{} \ninputs: {}" \
"\n**************************WindowFunc**************************" \
.format(Instant.of_epoch_milli(window.start), Instant.of_epoch_milli(window.end), inputs)
print(out)
avg = [0 for _ in range(NUM_CITIES)]
count = [0 for _ in range(NUM_CITIES)]
# 移动平均
for value in inputs:
print("datetime: ", datetime.fromtimestamp(value[0]), "value: ", value[1:]) if DEBUG else None
# yield (value, Instant.of_epoch_milli(window.start), Instant.of_epoch_milli(window.end))
for i in range(NUM_CITIES):
if value[i + 2] != INVALID_VAL:
avg[i] += value[i + 2]
count[i] += 1
for i in range(NUM_CITIES):
avg[i] /= count[i]
print("------------", datetime.fromtimestamp(window.start / 1000).strftime("%Y-%m-%d %H:%M:%S"), avg)
yield f'{datetime.fromtimestamp(window.start / 1000).strftime("%Y-%m-%d %H:%M:%S")}, {avg}'
class MyAggregateFunc(AggregateFunction): # 把原始的row聚合为一个accumulator
def create_accumulator(self):
return ["", "", [0 for _ in range(NUM_CITIES)], [0 for _ in range(NUM_CITIES)]]
def add(self, value, accumulator):
for i, v in enumerate(value[2:]):
if v != INVALID_VAL:
accumulator[2][i] += v
accumulator[3][i] += 1
accumulator[0] = datetime.fromtimestamp(value[0]).strftime("%Y-%m-%d %H:%M:%S")
accumulator[1] = value[1]
return accumulator
def get_result(self, accumulator):
return accumulator
def merge(self, acc_a, acc_b):
return None
class MyTopNProcessWindowFunc(ProcessWindowFunction):
def process(self, key, context, elements):
res = avg(elements)
if random.random()<0.1:
print("更新城市AQI榜单中............")
top_k_curr = min(TOP_K_CITY, len(res[2:]))
botN = sorted(zip(res[2:], range(NUM_CITIES)), key=lambda x: x[0], reverse=True)
# drop invalid values
botN = [x for x in botN if x[0] != INVALID_VAL][:top_k_curr] # 极大值9999
botN, botN_inds = zip(*botN)
topN = sorted(zip(res[2:], range(NUM_CITIES)), key=lambda x: x[0])[:top_k_curr]
topN, topN_inds = zip(*topN)
res = [l2s(res[0:1]),
l2s([cities[CITIES_SELECTED_inds[i]] for i in topN_inds], " "),
l2s([cities[CITIES_SELECTED_inds[i]] for i in botN_inds], " "),
l2s(topN, " "),
l2s(botN, " "),
]
# print("Aggregated TopN elements: ", topN_inds, topN)
yield l2s(res)
class MyAvgProcessWindowFunc(ProcessWindowFunction): # only prints the window content
def process(self, key, context, elements):
# convert "%Y-%m-%d %H:%M:%S" to "%Y-%m-%d_%H_%M_%S"
res = avg(elements)
# print("Aggregated elements: ", res)
yield ",".join([str(r) for r in res])
class TimestampAssignerProcessFunctionAdapter(ProcessFunction):
def process_element(self, value, ctx: 'ProcessFunction.Context'):
if DEBUG:
out_put = "-----------------------TimestampAssignerProcessFunctionAdapter {}-----------------------" \
"\nvalue: {} \ttimestamp: {} \tcurrent_processing_time: {} \tcurrent_watermark: {}" \
"\n-----------------------TimestampAssignerProcessFunctionAdapter-----------------------" \
.format(int(time.time()), value, Instant.of_epoch_milli(ctx.timestamp()),
Instant.of_epoch_milli(ctx.timer_service().current_processing_time()),
Instant.of_epoch_milli(ctx.timer_service().current_watermark()))
print(out_put)
print("eventdatetime: ", datetime.fromtimestamp(value[0]))
yield (value, Instant.of_epoch_milli(ctx.timestamp()),
Instant.of_epoch_milli(ctx.timer_service().current_processing_time()),
Instant.of_epoch_milli(ctx.timer_service().current_watermark()))
def main():
global CITIES_SELECTED_inds
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
env.set_stream_time_characteristic(TimeCharacteristic.EventTime)
num_cities = NUM_CITIES
CITIES_SELECTED_inds = random.sample(range(len(cities)), num_cities)
print("Selected cities: ", [cities[i] for i in CITIES_SELECTED_inds])
# 定义输入数据格式
field_names = ["date", "hour", "type"] + cities
field_types = [Types.STRING, Types.STRING, Types.STRING] + [Types.FLOAT for _ in range(len(cities))] # 所有城市
schema = CsvSchema.builder()
for name, type in zip(field_names, field_types):
# 要加number type 否则默认是Long
schema = schema.add_number_column(name,
number_type=DataTypes.FLOAT()) if type == Types.FLOAT else schema.add_string_column(
name)
schema = schema \
.set_use_header(False) \
.set_skip_first_data_row(True) \
.set_column_separator(",").build()
if DIRECT_HDFS:
csv_source = FileSource.for_record_stream_format(CsvReaderFormat.for_schema(schema), f"hdfs://localhost:9000/{HOME}/{HDFS_ROOT}/{CSV_FILE_PATH}").build()
print("读取HDFS中的文件成功!!!!!!")
else:
print("使用下载至本地的文件!!!!!!")
csv_source = FileSource.for_record_stream_format(CsvReaderFormat.for_schema(schema), f"{CSV_FILE_PATH}").build()
new_row_types = [Types.LONG(), Types.STRING()] + [Types.FLOAT() for _ in range(num_cities)]
watermark_strategy = WatermarkStrategy.for_bounded_out_of_orderness(Duration.of_seconds(0)).with_timestamp_assigner(
FirstElementTimestampAssigner())
data_stream = env.from_source(csv_source, watermark_strategy, "csv-source")
# 将时间戳转换为datetime,定义时间戳
processed_stream = data_stream \
.map(parse_row, output_type=Types.ROW(new_row_types)) \
.assign_timestamps_and_watermarks(watermark_strategy)
# 筛选各个城市的部分指标数据
indicators = ["PM2.5", "SO2", "PM10", "AQI"]
final_streams = {}
# ------------------ 计算8小时移动平均------------------
for indicator in indicators:
indicator_filter = (lambda row: row[1] in indicators) if not GROUP_BY_INDICATOR else lambda row: row[1] == indicator
file_sink = FileSink.for_row_format(f"output/cities_{indicator if GROUP_BY_INDICATOR else ''}", Encoder.simple_string_encoder()) \
.with_output_file_config(OutputFileConfig.builder().with_part_prefix("slide_output").with_part_suffix(".csv").build()) \
.build()
final_streams = processed_stream.filter(indicator_filter)
final_streams.process(TimestampAssignerProcessFunctionAdapter())
#
final_streams \
.key_by(lambda row: row[1]) \
.window(SlidingEventTimeWindows.of(size=Time.hours(8), slide=Time.hours(1))) \
.aggregate(MyAggregateFunc(), MyAvgProcessWindowFunc()) \
.map(lambda x: x, output_type=Types.STRING()) \
.sink_to(file_sink)
env.execute("Processing AQI data")
if not GROUP_BY_INDICATOR:
break
# ------------------ AQI的TopN------------------
aqi_stream = processed_stream.filter(lambda row: row[1] == "AQI")
aqi_stream.process(TimestampAssignerProcessFunctionAdapter())
res1 = aqi_stream \
.key_by(lambda row: row[1]) \
.window(TumblingEventTimeWindows.of(Time.hours(24))) \
.aggregate(MyAggregateFunc(), MyTopNProcessWindowFunc()) \
.filter(lambda x: datetime.strptime(x.split(",")[0], "%Y-%m-%d_%H_%M_%S").hour != 23)
res1.map(lambda x: x, output_type=Types.STRING()) \
.sink_to(FileSink.for_row_format(f"output/cities_AQI_topN", Encoder.simple_string_encoder())
.with_output_file_config(OutputFileConfig.builder().with_part_prefix("aqi_output").with_part_suffix(".csv").build())
.build())
def flat_mapper1(row):
return splitter(splitter(row)[1], " ")
def flat_mapper2(row):
return splitter(splitter(row)[2], " ")
# -------------统计每个城市在榜首和榜尾的出现次数----------------
# 分流
res1 \
.flat_map(flat_mapper1).map(lambda x: (x, 1), output_type=Types.TUPLE([Types.STRING(), Types.INT()])) \
.key_by(lambda row: row[0]) \
.sum(1) \
.map(lambda x: f'{x[0]},{x[1]}', output_type=Types.STRING()) \
.sink_to(FileSink.for_row_format(f"output/cities_AQI_topN_count", Encoder.simple_string_encoder())
.with_output_file_config(OutputFileConfig.builder().with_part_prefix("topN_count").with_part_suffix(".csv").build())
.build())
res1 \
.flat_map(flat_mapper2).map(lambda x: (x, 1), output_type=Types.TUPLE([Types.STRING(), Types.INT()])) \
.key_by(lambda row: row[0]) \
.sum(1) \
.map(lambda x: f'{x[0]},{x[1]}', output_type=Types.STRING()) \
.sink_to(FileSink.for_row_format(f"output/cities_AQI_botN_count", Encoder.simple_string_encoder())
.with_output_file_config(OutputFileConfig.builder().with_part_prefix("botN_count").with_part_suffix(".csv").build())
.build())
env.execute("Processing AQI data")
with open("cities_selected.txt", 'w') as f:
f.write(l2s([cities[i] for i in CITIES_SELECTED_inds], " "))
if not GROUP_BY_INDICATOR:
res = sort_file_by_mtime(glob.glob('output/cities_/*/slide_output*.csv'))
shutil.copy(res[0], 'output/slide_output.csv')
print(f"Copy {res[0]}")
res = sort_file_by_mtime(glob.glob('output/cities_AQI_topN/*/aqi_output*.csv'))
shutil.copy(res[0], 'output/aqi_output.csv')
print(f"Copy {res[-1]}")
res = sort_file_by_mtime(glob.glob('output/cities_AQI_topN_count/*/topN_count*.csv'))
shutil.copy(res[-1], 'output/topN_count.csv')
print(f"Copy {res[-1]}")
res = sort_file_by_mtime(glob.glob('output/cities_AQI_botN_count/*/botN_count*.csv'))
shutil.copy(res[-1], 'output/botN_count.csv')
print(f"Copy {res[-1]}")
try:
if USE_HDFS: # 将结果上传到HDFS
fs.copy_from_local("cities_selected.txt", f"{HOME}/{HDFS_ROOT}/cities_selected.txt", overwrite=True)
fs.mkdirs(f"{HOME}/{HDFS_ROOT}/output")
os.system(f'hdfs dfs -put -f output {HOME}/{HDFS_ROOT}/output')
print("上传结果至HDFS成功")
except Exception as e:
print("尝试$HADOOP_HOME/bin/hdfs,请检查系统环境变量$PATH")
try:
os.system(f'$HADOOP_HOME/bin/hdfs dfs -put -f output {HOME}/{HDFS_ROOT}/output')
print("上传结果至HDFS成功")
except:
pass
print("Flink处理完毕!!!!")
if __name__ == "__main__":
main()其中,visualize.py的代码如下:
import random
import warnings
import matplotlib
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
plt.ioff()
def set_legend_font(font):
ls = plt.legend().get_texts()
try:
[l.set_fontproperties(font) for l in ls]
except Exception as e:
print(e)
sliding_data_path = r"output/slide_output.csv"
aqi_data_path = r"output/aqi_output.csv"
cities_topN_count_path = r"output/topN_count.csv"
cities_botN_count_path = r"output/botN_count.csv"
location_data_path = r"locations.csv"
# 避免中文乱码
myfont = matplotlib.font_manager.FontProperties(fname="微软雅黑.ttf")
matplotlib.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
random.seed(1125)
# 首行为数据
sliding_data = pd.read_csv(sliding_data_path, header=None)
aqi_data = pd.read_csv(aqi_data_path, header=None)
cities_topN_count = pd.read_csv(cities_topN_count_path, header=None)
cities_botN_count = pd.read_csv(cities_botN_count_path, header=None)
location_data = pd.read_csv(location_data_path, header=0)
with open("cities_selected.txt", "r") as f:
cities_selected = f.read().split(" ")
# 将9999替换为NaN
cities_draw = random.sample(cities_selected, 5)+['厦门']
for indicator in ["PM2.5", "PM10", "SO2"]:
sliding_data = sliding_data.replace(9999, float("nan"))
aqi_data = aqi_data.replace(9999, float("nan"))
sliding_data.fillna(method="ffill", inplace=True)
aqi_data.fillna(method="ffill", inplace=True)
sliding_data.columns = ["hour", "type"] + cities_selected
sliding_data[sliding_data["type"] == indicator][cities_draw].reset_index(drop=True).plot()
set_legend_font(myfont)
plt.xticks(np.arange(0, 24 * 31, 48), rotation=30, labels=[f"{i}日" for i in range(1, 32, 2)], fontproperties=myfont)
plt.ylabel(f"{indicator}指数", fontproperties=myfont)
set_legend_font(myfont)
plt.savefig(f"1月份部分城市{indicator}指数的8h移动平均变化趋势.png", dpi=300)
# plt.show()
# 画出所有城市PM2.5的箱线图
plt.figure()
sliding_data[sliding_data["type"] == indicator][cities_draw].boxplot()
plt.xticks(fontproperties=myfont)
plt.ylabel(f"{indicator}指数", fontproperties=myfont)
plt.savefig(f"1月份部分城市{indicator}指数的箱线图.png", dpi=300)
# plt.show()
# 画出AQI的TopN城市
def split(x):
return np.mean(list(map(float, x.split(" "))))
aqi_data.columns = ["hour", "topNName", "botNName", "topN", "botN"]
aqi_data["topN_mean"] = aqi_data["topN"].apply(split)
aqi_data["botN_mean"] = aqi_data["botN"].apply(split)
aqi_data["botN_std"] = aqi_data["botN"].apply(lambda x: np.std(list(map(float, x.split(" ")))))
aqi_data["topN_std"] = aqi_data["topN"].apply(lambda x: np.std(list(map(float, x.split(" ")))))
aqi_data[["topN_mean", "botN_mean"]].plot()
plt.fill_between(aqi_data.index, aqi_data["topN_mean"] - aqi_data["topN_std"],
aqi_data["topN_mean"] + aqi_data["topN_std"], alpha=0.5)
plt.fill_between(aqi_data.index, aqi_data["botN_mean"] - aqi_data["botN_std"],
aqi_data["botN_mean"] + aqi_data["botN_std"], alpha=0.5)
plt.xlabel("日期", fontproperties=myfont)
plt.ylabel("空气质量榜首和榜尾城市的AQI变化趋势", fontproperties=myfont)
plt.title("24h平均AQI指数", fontproperties=myfont)
plt.savefig("空气质量榜首和榜尾城市的24h平均AQI指数.png", dpi=300)
# plt.show()
plt.figure()
cities_botN_count.columns = ["city", "空气质量(AQI)位于榜尾次数"]
cities_topN_count.columns = ["city", "空气质量(AQI)达到榜首次数"]
cities_botN_count = cities_botN_count.groupby("city").max().reset_index()
cities_topN_count = cities_topN_count.groupby("city").max().reset_index()
cities_botN_count = cities_botN_count.sort_values(by="空气质量(AQI)位于榜尾次数", ascending=False)
cities_topN_count = cities_topN_count.sort_values(by="空气质量(AQI)达到榜首次数", ascending=False)
cities_topN_botN = cities_botN_count.merge(cities_topN_count, on="city", how="outer")
cities_topN_botN.fillna(0, inplace=True)
cities_topN_botN.plot(kind="bar", x="city", y=["空气质量(AQI)达到榜首次数", "空气质量(AQI)位于榜尾次数"])
set_legend_font(myfont)
plt.xticks(rotation=-90, fontproperties=myfont, size=8)
plt.ylabel("空气质量(AQI)位于榜首或榜尾次数", fontproperties=myfont)
plt.savefig("各个城市在空气质量Top榜单和Bottom榜单的出现次数.png", dpi=300)
# plt.show()
plt.figure()
cities_2char = [c if len(c) == 2 else c[:2] for c in cities_selected]
cities_3char = [c if len(c) <= 3 else c[:3] for c in cities_selected]
location_data.dropna(inplace=True)
# 画出城市的位置
location_data["纬度(度分)"] /= 100
location_data["经度(度分)"] /= 100
# 针对城市名称与不一致的情况
isin = location_data["站名"].isin(cities_2char) | location_data["站名"].isin(cities_selected) | location_data["站名"].isin(cities_3char)
sliding_data_mean = sliding_data[sliding_data["type"] == "AQI"].mean(0).reset_index()
sliding_data_mean["2char"] = cities_2char
sliding_data_mean["3char"] = cities_3char
isin_rev = sliding_data_mean["index"].isin(location_data["站名"]) | sliding_data_mean["2char"].isin(location_data["站名"]) | sliding_data_mean["3char"].isin(location_data["站名"])
sz = sliding_data[sliding_data["type"] == "AQI"].mean(0).reset_index()[isin_rev]
sz = sz.sort_values(by='index').reset_index(drop=True)
loc_selected = location_data.loc[isin].sort_values(by="站名").reset_index()
try:
plt.scatter(loc_selected["经度(度分)"], loc_selected["纬度(度分)"], s=sz[0])
except:
warnings.warn("城市名称匹配能力有限,无法画出散点大小")
plt.scatter(location_data.loc[isin, "经度(度分)"], location_data.loc[isin, "纬度(度分)"])
# text
location_data_aqi_selected = loc_selected
location_data_aqi_selected['AQI'] = sz[0]
location_data_aqi_selected.apply(lambda x: plt.text(x["经度(度分)"] + 0.5, x["纬度(度分)"] + 0.5 - (x["纬度(度分)"] > 40), x["站名"] + ' ' + "{:.1f}".format(x['AQI']), size=8, fontproperties=myfont),
axis=1)
plt.xlabel("经度", fontproperties=myfont)
plt.ylabel("纬度", fontproperties=myfont)
plt.title("不同地理位置城市的AQI指数", fontproperties=myfont)
plt.savefig("不同地理位置的AQI可视化.png", dpi=800)
# plt.show()
plt.figure()
sz.columns = ['city', '1月AQI指数平均值']
sz.sort_values(by='1月AQI指数平均值', ascending=True).plot(kind='bar', x="city", y=['1月AQI指数平均值'], color='gray')
set_legend_font(myfont)
plt.ylabel("1月AQI指数平均值", fontproperties=myfont)
plt.xticks(fontproperties=myfont, size=8)
sz_sorted = sz.sort_values(by='1月AQI指数平均值', ascending=True)
for i in range(len(sz)):
plt.text(i - 0.5, 3 + sz_sorted.iloc[i, 1], "{:3.0f}".format(sz_sorted.iloc[i, 1]), size=6)
plt.savefig("1月AQI指数平均值对比.png", dpi=300)
# plt.show()
print("可视化运行完毕,全流程成功结束!")执行./total.sh 运行结果如下:
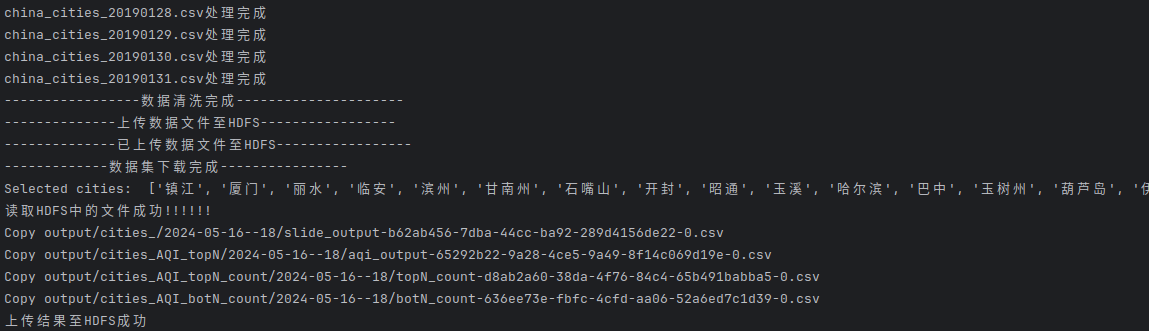
得到的部分csv结果如下,从左至右分别为8h移动平均值、AQI指数榜单榜首上榜次数与每24h的榜首和榜尾城市以及对应的AQI值。

最后,基于matplotlib编写的visualize.py可得到可视化结果的png图像。中文微软雅黑字体已经随代码提供并在画图时适配中文文字,无需设置matplotlib.rc。
4.2结果分析
首先展示了部分城市的PM2.5、PM10、SO2三种指标的8小时移动平均变化趋势与箱线图。从下组图表中可以看出,三种指标的变化趋势一致性较高,有部分城市的变化趋势也呈现一致性,直观上石嘴山、平度、德州等地的2019年1月的污染较高,其中石嘴山的SO2指数高于其他城市。右列箱线图中部分城市存在较多的离群点,且箱体长度较大,说明这些污染指标可能波动较大,出现了某几天的极端污染天气。
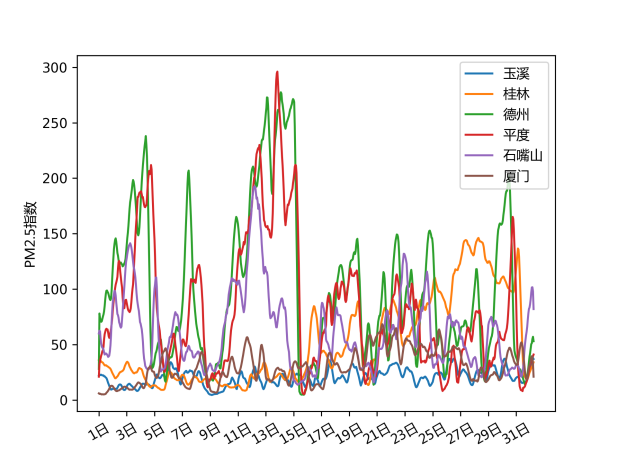
图 6 部分城市PM2.5指数的变化趋势
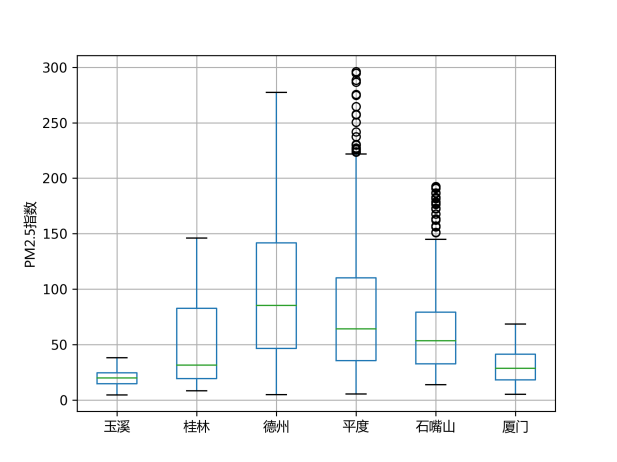
图 7 部分城市PM2.5指数的箱线图
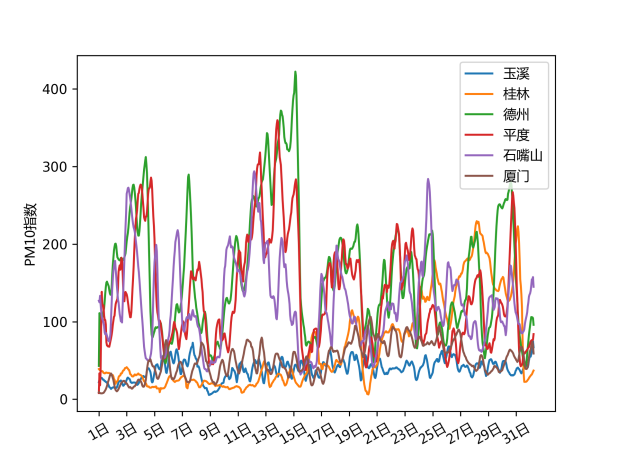
图 8 部分城市PM10指数的变化趋势
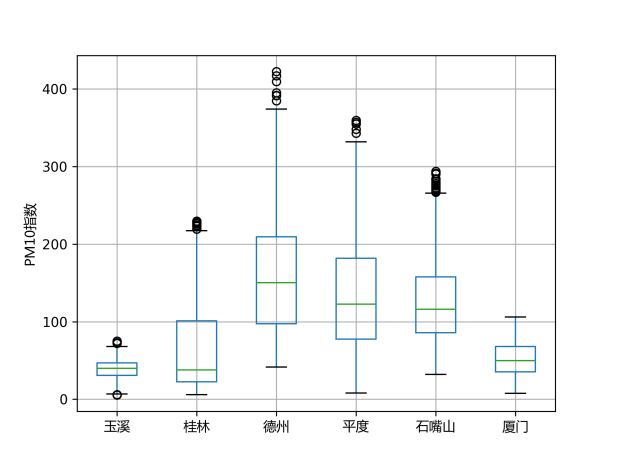
图 9 部分城市PM10指数的箱线图
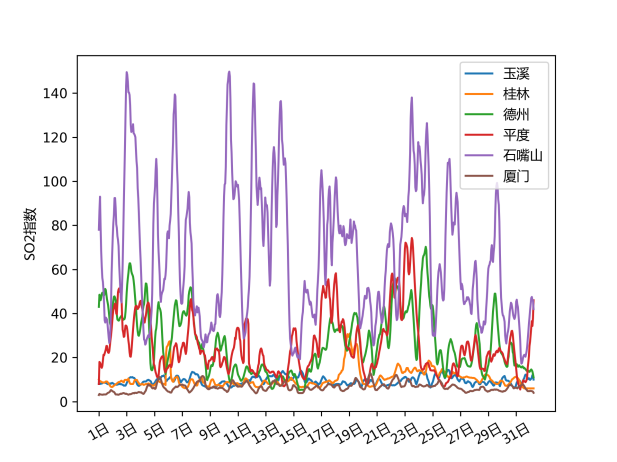
图 10 部分城市SO2指数的变化趋势
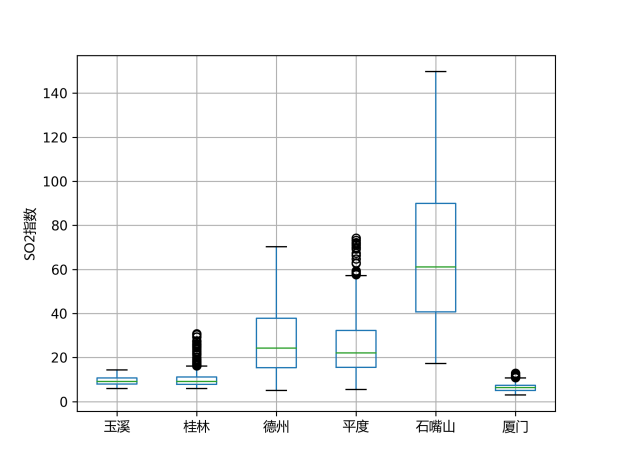
图 11 部分城市SO2指数的箱线图
随后展示了依照地理位置排序的AQI指数如图 11所示。AQI指数越高表示污染程度越高,越低表示空气质量越好。可以看出华中、华北地区的污染程度相对较高,包括厦门在内的沿海城市与高原地区空气质量较好。
图 12展示了各个城市的AQI指数的平均值对比,可以看出所选取的城市中,青海玉树在2019年1月的空气质量最好,河南漯河的空气质量最差。
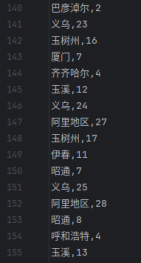
图 13展示了每24h的空气质量榜单中,每个城市出现在榜首和榜尾的天数。其中空气质量榜单根据24h的平均AQI指数升序排列。可以看出,漯河、西安、邢台等城市位于AQI榜单榜尾的次数最多,西藏阿里地区、义乌、玉树州出现在榜首次数最高,厦门2019年1月有将近10天位于空气质量榜首城市中。
图 14描述了榜首与榜尾城市的平均AQI值的变化,其中阴影部分表示标准差。可以看出本月空气质量较差的几个城市的AQI值在200左右,空气质量较好的5个城市的AQI值通常位于50以下。
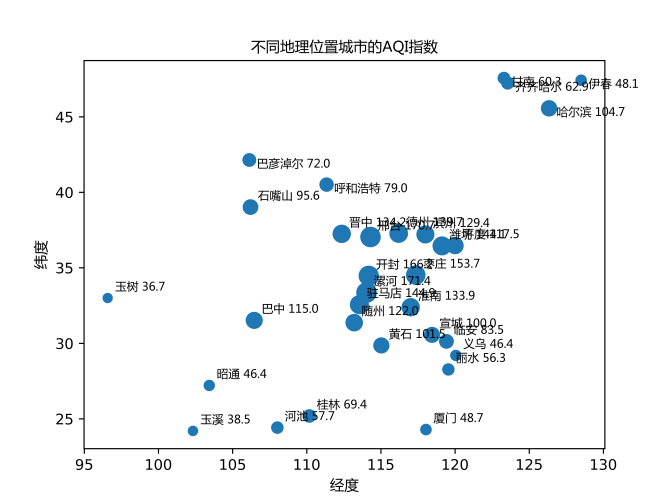
图 12 不同地理位置的城市的AQI指数
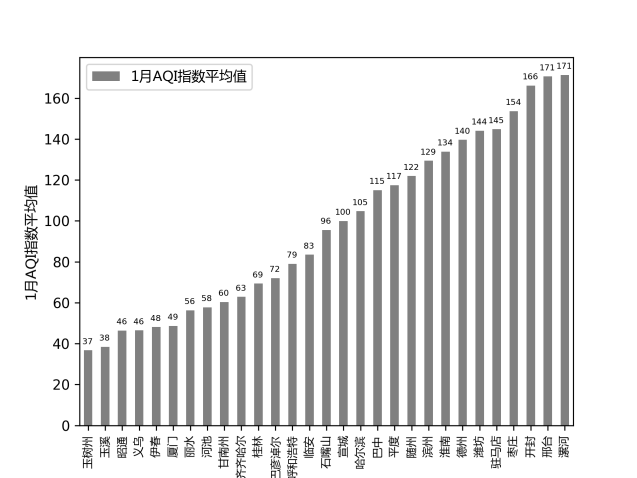
图 13 城市平均AQI指数对比
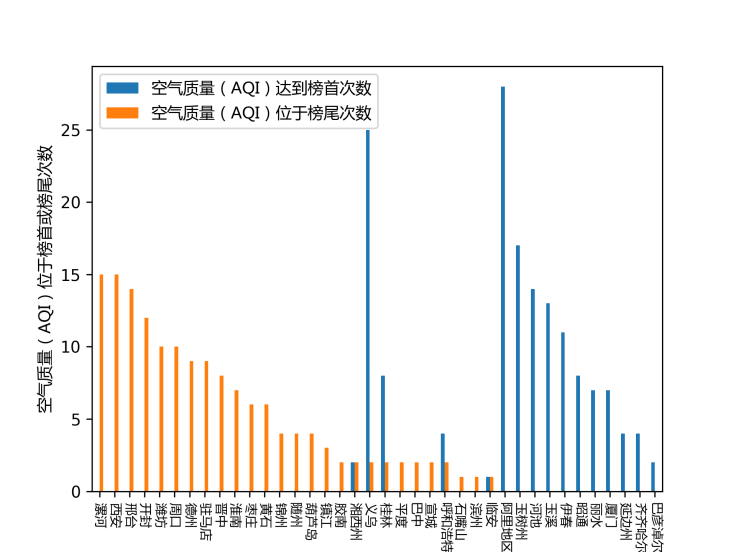
图 14 各个城市空气质量出现在榜首与榜尾的次数对比
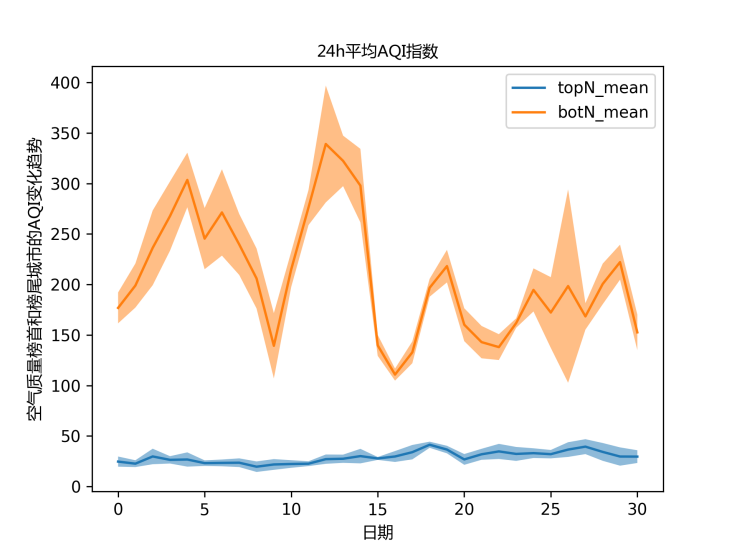
图 15 24h平均空气质量榜首城市与榜尾城市的1月份AQI值变化趋势
5.总结
难点:由于PyFlink是对java的调用,出现错误时无法定位准确的断点,也难以进行输出调试,因而对初学者来说调试较难,报错信息有时很模糊,例如数据类型对齐、时间戳分配方面。对于PyFlink的博客与文档相对较少,需要大量参考官方文档。很多函数的参数传递与调用需要不断摸索与参考,例如事件时间分配策略的配置方面比较繁杂,确定选用哪种算子并编写聚合函数进行窗口的计算也是需要考虑的问题。此外,考虑可重复性时需要编写shell脚本来设置各类环境变量,尽可能考虑所有出错点,实现一键运行的自动化流程。
亮点:采用真实的空气质量流数据,具有一定的现实意义与参考价值。基于Python脚本与Flink,自动化执行程度良好。为保持程序扩展性,将数据集文件与HDFS进行同步,并读取HDFS文件,若读取HDFS失败则读取本地文件。通过窗口计算移动平均值,代码扩展性与可读性良好,并从横向比较、纵向比较、时间、空间等角度进行了不同视角的可视化。