
【版权声明】版权所有,严禁转载,严禁用于商业用途,侵权必究。
作者:厦门大学人工智能研究院2023级研究生 李旭东
指导老师:厦门大学数据库实验室 林子雨 博士/副教授
时间:2024年6月
相关教材:林子雨、郑海山、赖永炫编著《Spark编程基础(Python版,第2版)》(访问教材官网)
相关案例:基于Python语言的Spark数据处理分析案例集锦(PySpark)
本实验采用Python语言,使用大数据处理框架Spark对数据进行处理分析,并对分析结果进行可视化。
一、实验环境
(1)Linux: Ubuntu16.04
(2)Hadoop: 3.1.3
(3)Python: 3.7.6
(4)Spark: 3.2.0
(5)Jupyter Notebook
(6)VMware Workstation
(7)Java环境:JDK 1.8
此外还需要安装numpy, pandas来进行数据处理,安装scipy, matplotlib, senborn,plotly进行可视化或辅助可视化。具体来说,需要执行如下安装命令:pip instal numpy,pip install pandas,pip install matplotlib,pip install senborn
,pip install plotly
二、数据集介绍
本次项目使用的数据集来自知名数据网站Kaggle的NBA Players stats(2023 season)数据集,该数据集包含了2022-2023赛季球员的赛季的全面数据,共有539条数据(从百度网盘下载数据集和代码)(提取码是ziyu)。数据包含以下字段:
The name of the basketball player PName 篮球运动员的名字
The player's position in the game, including 'N/A' POS 球员在比赛中的位置
The abbreviation of the team the player is currently playing for this season Team 本赛季球员所效力球队
The age of the player Age 球员的年龄
The total number of games the player has played in this season GP 本赛季球员参加比赛总数
The total number of games won by the player W 球员赢得的比赛总数
The total number of games lost by the player L 球员输掉的比赛总数
The total minutes the player has played in this season Min 本赛季球员的总上场时间
The total points made by the player [target] PTS 球员得分总数(目标)
The total number of field goals made by the player FGM 球员投篮命中总数
The total number of field goals attempted by the player FGA 球员投篮出手总数
The percentage of successful field goals made by the player FG% 球员投篮命中率
The total number of 3-point field goals made by the player 3PM 球员三分球命中总数
The total number of 3-point field goals attempted by the player 3PA 球员三分球出手总数
The percentage of successful 3-point field goals made by the player 3P% 球员三分球命中率
The total number of free throws made by the player FTM 球员罚球命中总数
The total number of free throws attempted by the player FTA 球员罚球出手总数
The percentage of successful free throws made by the player FT% 球员罚球命中率
The total number of offensive rebounds made by the player OREB 球员进攻篮板总数
The total number of defensive rebounds made by the player DREB 球员防守篮板总数
The total number of rebounds (offensive + defensive) made by the player REB 球员篮板总数(进攻+防守)
The total number of assists made by the player AST 球员助攻总数
The total number of turnovers made by the player TOV 球员失误总数
The total number of steals made by the player STL 球员抢断总数
The total number of blocks made by the player BLK 球员盖帽总数
The total number of personal fouls made by the player PF 球员个人犯规总数
The total number of NBA fantasy points made by the player FP 球员的NBA梦幻积分总数
The total number of double-doubles made by the player DD2 球员的两双总数
The total number of triple-doubles made by the player TD3 球员的三双总数
The total difference between the player's team scoring and the opponents' scoring while the player is in the game +/- 球员在场时球队与对手得分的总差距
三、数据集处理
3.1 查看数据集基本信息
import pandas as pd
# 读取数据
file_path = '/home/hadoop/jupyternotebook/lxddashuju/data.csv'
df = pd.read_csv(file_path)
# 查看数据集信息
print(df.info())
# 显示数据的前几行
print(df.head())把csv文件读入,并查看数据集信息, 显示了每一个列的属性值,以及类型,可以看到共有30个属性值,一共539条数据。
3.2. 数据清洗
- 对数据进行清洗,检查并处理空值,处理完后的数据减少到了534条数据。
# 1. 去除空值 df.dropna(inplace=True) print(df.info())2.对数据进行清洗,检查并处理重复值
# 2. 去除重复值 df.drop_duplicates(inplace=True) print(df.info())3.对数据进行清洗,检查并处理异常值
# 3. 处理异常值 # 例如:得分(PTS)、篮板(REB)、助攻(AST)不能为负数 numeric_columns = ['GP', 'Min', 'PTS', 'FGM', 'FGA', 'FG%', '3PM', '3PA', '3P%', 'FTM', 'FTA', 'FT%', 'OREB', 'DREB', 'REB', 'AST', 'TOV', 'STL', 'BLK', 'PF', 'FP', 'DD2', 'TD3'] for col in numeric_columns: df = df[df[col] >= 0] print(df.info())4.标准化字段名称,即全部小写,方便后续分析
# 4. 标准化字段名称 df.columns = [col.lower() for col in df.columns]5.查看属性值的分布,排除不合适的不平衡的数据,这边以查看每个位置的球员数量为例:
# 查看每个位置的球员数量 pos_counts = df['pos'].value_counts() print(pos_counts) SG 96 C 78 SF 77 PG 77 PF 74 G 66 F 66 Name: pos, dtype: int64由于球员在不同位置的分布较为平均,因此我们不进行额外的数据清洗。
6.添加新特征,由于原始的特征不包含“得分效率”,为此我们引入了一个该属性,计算方式为球员的每分钟得分值:# 6. 添加新特征 # 添加一个新特征列,例如每分钟得分(PTS per minute) df['pts_per_minute'] = df['pts'] / df['min']7.保存清洗后的数据
# 保存清洗后的数据 cleaned_file_path = '/home/hadoop/jupyternotebook/lxddashuju/cleaned_data.csv' df.to_csv(cleaned_file_path, index=False) print(f"清洗后的数据已保存到 {cleaned_file_path}")
3.3使用HDFS存储文件
1.启动Hadoop。
cd /usr/local/hadoop
./sbin/start-dfs.sh2.在上传文件之前,在 HDFS 中创建一个目标目录(如果目标目录尚不存在):
cd /usr/local/hadoop
./bin/hdfs dfs -mkdir -p /usr/local/hadoop3.使用 hdfs dfs -put 命令将文件从本地文件系统上传到 HDFS:
cd /usr/local/hadoop
./bin/hdfs dfs -put /home/hadoop/jupyternotebook/dashujufinal/cleaned_data.csv /usr/local/hadoop/clean_data_final.csv4.验证文件是否已上传: 使用 hdfs dfs -ls 命令验证文件是否已成功上传到 HDFS:
cd /usr/local/hadoop
./bin/hdfs dfs -ls /usr/local/hadoop/clean_data_final.csv四、数据分析
4.1.读取数据
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg, sum, count, when
from pyspark.sql.window import Window
from pyspark.sql.functions import row_number
# 从 HDFS 读取数据
df = spark.read.option("header", True).option("inferSchema", True).csv("hdfs://localhost:9000/usr/local/hadoop/clean_data_final.csv")从HDFS中将文件读出,然后检查读出的数据是否无误。
df.show(3)4.2.分析每个球队的场均得分、篮板和助攻
1.首先计算每个球员的场均得分、篮板和助攻
# 计算每个球员的场均得分、篮板和助攻
df = df.withColumn('avg_points', col('pts') / col('gp')) \
.withColumn('avg_rebounds', col('reb') / col('gp')) \
.withColumn('avg_assists', col('ast') / col('gp')) \
.withColumn('avg_fg%', col('fg%') / 100) \
.withColumn('avg_3p%', col('3p%') / 100) \
.withColumn('win_rate', col('w') / col('gp')) \
.withColumn('lose_rate', col('l') / col('gp'))
# 将数据保存到本地文件
df.toPandas().to_csv('/home/hadoop/jupyternotebook/lxddashuju/result/processed_data.csv')2.接着计算计算每个球队的场均得分、篮板和助攻等统计数据,并将这些数据保存到CSV文件中。具体步骤如下:
使用groupBy按team列分组。
(1)计算每个球队的场均得分、篮板和助攻,分别用sum('pts')/82、sum('reb')/82和sum('ast')/82来计算,并给这些统计数据起别名。
(2)计算每个球队的平均投篮命中率(avg('avg_fg%'))、平均三分球命中率(avg('avg_3p%'))、胜率(avg('win_rate'))和败率(avg('lose_rate')),并分别起别名。
(3)按场均得分降序排列,并取前10名球队。
(4)将结果转换为Pandas DataFrame并保存为CSV文件到指定路径。在确认数据无误后,保存到csv文件,以便后面进行可视化。
# 1. 每个球队的场均得分、篮板和助攻
team_stats = df.groupBy('team').agg(
(sum('pts')/82).alias('team_avg_points'),
(sum('reb')/82).alias('team_avg_rebounds'),
(sum('ast')/82).alias('team_avg_assists'),
avg('avg_fg%').alias('team_avg_fg%'),
avg('avg_3p%').alias('team_avg_3p%'),
avg('win_rate').alias('team_win_rate'),
avg('lose_rate').alias('team_lose_rate')
).orderBy(col('team_avg_points').desc()).limit(10)
team_stats.toPandas().to_csv("/home/hadoop/jupyternotebook/lxddashuju/result/team_stats.csv", header=True)
team_stats.show()4.3.计算每个位置的场均得分、篮板和助攻,并包含命中率和三分命中率
这一分析旨在计算每个位置的场均得分、篮板和助攻等统计数据,并将这些数据保存到CSV文件中。具体步骤如下:
(1)使用groupBy按pos列分组。
(2)计算每个位置的场均得分、篮板和助攻,分别用avg('avg_points')、avg('avg_rebounds')和avg('avg_assists')来计算,并给这些统计数据起别名。
(3)计算每个位置的平均投篮命中率(avg('avg_fg%'))和平均三分球命中率(avg('avg_3p%')),并分别起别名。
(4)将结果转换为Pandas DataFrame并保存为CSV文件到指定路径。
(5)显示计算结果。在确认数据无误后,保存到csv文件,以便后面进行可视化。
# 2. 计算每个位置的场均得分、篮板和助攻,并包含命中率和三分命中率
pos_stats = df.groupBy('pos').agg(
avg('avg_points').alias('pos_avg_points'),
avg('avg_rebounds').alias('pos_avg_rebounds'),
avg('avg_assists').alias('pos_avg_assists'),
avg('avg_fg%').alias('pos_avg_fg%'),
avg('avg_3p%').alias('pos_avg_3p%')
)
pos_stats.toPandas().to_csv("/home/hadoop/jupyternotebook/lxddashuju/result/pos_stats.csv", header=True)
pos_stats.show()4.4.计算每个年龄段的场均得分、篮板和助攻,并包含命中率和三分命中率
计算每个年龄段的场均得分、篮板和助攻等统计数据,并将这些数据保存到CSV文件中。具体步骤如下:
(1)使用groupBy按age列分组。
(2)计算每个年龄段的场均得分、篮板和助攻,分别用avg('avg_points')、avg('avg_rebounds')和avg('avg_assists')来计算,并给这些统计数据起别名。
(3)计算每个年龄段的平均投篮命中率(avg('avg_fg%'))和平均三分球命中率(avg('avg_3p%')),并分别起别名。
将结果转换为Pandas DataFrame并保存为CSV文件到指定路径。
(5)显示计算结果。
(6)在确认数据无误后,保存到csv文件,以便后面进行可视化。
# 3. 计算每个年龄段的场均得分、篮板和助攻,并包含命中率和三分命中率
age_stats = df.groupBy('age').agg(
avg('avg_points').alias('age_avg_points'),
avg('avg_rebounds').alias('age_avg_rebounds'),
avg('avg_assists').alias('age_avg_assists'),
avg('avg_fg%').alias('age_avg_fg%'),
avg('avg_3p%').alias('age_avg_3p%')
)
age_stats.toPandas().to_csv("/home/hadoop/jupyternotebook/lxddashuju/result/age_stats.csv", header=True)
age_stats.show()4.5.找出每个球队场均得分最高的球员
(1)按球队分区,并按场均得分降序排序。
(2)为每个球队的球员按得分排名。
(3)筛选出每个球队中排名第一的球员。
(4)选择球队名、球员名和场均得分列。
(5)保存结果到CSV文件并显示。在确认数据无误后,保存到csv文件,以便后面进行可视化。
# 4. 找出每个球队场均得分最高的球员
windowSpec = Window.partitionBy('team').orderBy(col('avg_points').desc())
team_top_scorers = df.withColumn('rank', row_number().over(windowSpec)).filter(col('rank') == 1).select('team', 'pname', 'avg_points')
team_top_scorers.toPandas().to_csv("/home/hadoop/jupyternotebook/lxddashuju/result/team_top_scorers.csv", header=True)
team_top_scorers.show()4.6.找出每个位置场均得分最高的球员
(1)按球员位置分区,并按场均得分降序排序。
(2)为每个位置的球员按得分排名。
(3)筛选出每个位置中排名第一的球员。
(4)选择位置、球员名和场均得分列。
(5)保存结果到CSV文件并显示。在确认数据无误后,保存到csv文件,以便后面进行可视化。
# 5. 找出每个位置场均得分最高的球员
windowSpec = Window.partitionBy('pos').orderBy(col('avg_points').desc())
pos_top_scorers = df.withColumn('rank', row_number().over(windowSpec)).filter(col('rank') == 1).select('pos', 'pname', 'avg_points')
pos_top_scorers.toPandas().to_csv("/home/hadoop/jupyternotebook/lxddashuju/result/pos_top_scorers.csv", header=True)
pos_top_scorers.show()4.7.找出每个年龄段场均得分最高的球员
(1)按年龄段分区,并按场均得分降序排序。
(2)为每个年龄段的球员按得分排名。
(3)筛选出每个年龄段中排名第一的球员。
(4)选择年龄、球员名和场均得分列。
(5)保存结果到CSV文件并显示。
# 6. 找出每个年龄段场均得分最高的球员
windowSpec = Window.partitionBy('age').orderBy(col('avg_points').desc())
age_top_scorers = df.withColumn('rank', row_number().over(windowSpec)).filter(col('rank') == 1).select('age', 'pname', 'avg_points')
age_top_scorers.toPandas().to_csv("/home/hadoop/jupyternotebook/lxddashuju/result/age_top_scorers.csv", header=True)
age_top_scorers.show()4.8.找出场均得分最高的前 10 名球员
(1)按场均得分降序排列所有球员。
(2)取出排名前10的球员。
(3)选择球员名、场均得分、球队、位置、年龄、场均篮板、场均助攻、投篮命中率和三分球命中率列。
(4)保存结果到CSV文件并显示。
# 7. 找出场均得分最高的前 10 名球员
top_10_scorers = df.orderBy(col('avg_points').desc()).limit(10).select('pname', 'avg_points', 'team', 'pos', 'age', 'avg_rebounds', 'avg_assists', 'avg_fg%', 'avg_3p%')
top_10_scorers.toPandas().to_csv("/home/hadoop/jupyternotebook/lxddashuju/result/top_10_scorers.csv", header=True)
top_10_scorers.show()4.9.计算每个球员的场均篮板数
(1)计算每个球员的场均篮板数,并添加一个名为avg_rebounds的新列,计算方式是将总篮板数(reb)除以总比赛数(gp)。
(2)按场均篮板数降序排列所有球员。
(3)选择球员名和场均篮板数列。
(4)保存结果到CSV文件并显示。
# 8. 计算每个球员的场均篮板数
# 计算每个球员的场均篮板数
df = df.withColumn('avg_rebounds', col('reb') / col('gp'))
# 对球员的场均篮板数进行排序
player_avg_rebounds = df.orderBy(col('avg_rebounds').desc()).select('pname', 'avg_rebounds')
player_avg_rebounds.toPandas().to_csv("/home/hadoop/jupyternotebook/lxddashuju/result/player_avg_rebounds.csv", header=True)
player_avg_rebounds.show()4.10.计算每个球员的场均助攻数
(1)计算每个球员的场均助攻数,并添加一个名为avg_assists的新列,计算方式是将总助攻数(ast)除以总比赛数(gp)。
(2)按场均助攻数降序排列所有球员。
(3)选择球员名和场均助攻数列。
(4)显示计算结果。
(5)保存结果到CSV文件。
# 9. 计算每个球员的场均助攻数
player_avg_assists = df.withColumn('avg_assists', col('ast') / col('gp'))
player_avg_assists = df.orderBy(col('avg_assists').desc()).select('pname', 'avg_assists')
player_avg_assists.show()
player_avg_assists.toPandas().to_csv("/home/hadoop/jupyternotebook/lxddashuju/result/player_avg_assists.csv", header=True)4.11.计算每个球员的得分与时间的比率(得分/分钟)
(1)计算每个球员的得分与时间的比率,添加一个名为pts_per_minute的新列,计算方式是将总得分(pts)除以总上场时间(min)。
(2)按得分与时间的比率降序排列所有球员。
(3)选择球员名和得分与时间的比率列。
(4)显示计算结果。
(5)保存结果到CSV文件。
# 10. 计算每个球员的得分与时间的比率(得分/分钟)
player_pts_per_min = df.withColumn('pts_per_minute', col('pts') / col('min'))
player_pts_per_min = df.orderBy(col('pts_per_minute').desc()).select('pname', 'pts_per_minute')
player_pts_per_min.show()
player_pts_per_min.toPandas().to_csv("/home/hadoop/jupyternotebook/lxddashuju/result/player_pts_per_min.csv", header=True)4.12.分析球员的命中率和三分命中率
(1)选择球员名、平均命中率(avg_fg)和平均三分命中率(avg_3p)列。
(2)按平均命中率降序排列所有球员。
(3)显示计算结果。
(4)保存结果到CSV文件。
# 11. 分析球员的命中率和三分命中率
player_fg_3p_stats = df.select('pname', 'avg_fg%', 'avg_3p%').orderBy(col('avg_fg%').desc())
player_fg_3p_stats.toPandas().to_csv("/home/hadoop/jupyternotebook/lxddashuju/result/player_fg_3p_stats.csv", header=True)
player_fg_3p_stats.show()4.13.分析每个球队的胜率和输率
(1)按球队分组。
(2)计算每个球队的平均胜率(win_rate)和平均输率(lose_rate),并分别命名为team_win_rate和team_lose_rate。
(3)按平均胜率降序排列所有球队。
(4)显示计算结果。
(5)保存结果到CSV文件。
# 12. 分析每个球队的胜率和输率
team_win_lose_rate = df.groupBy('team').agg(
avg('win_rate').alias('team_win_rate'),
avg('lose_rate').alias('team_lose_rate')
).orderBy(col('team_win_rate').desc())
team_win_lose_rate.toPandas().to_csv("/home/hadoop/jupyternotebook/lxddashuju/result/team_win_lose_rate.csv", header=True)
team_win_lose_rate.show()五、使用Spark MLlib 组件进行进一步数据分析
5.1. MLlib线性回归模型
利用MLlib中的线性回归模型,分析篮板和胜利之间的关系,助攻和失误之间的关系,步骤如下:
- 加载数据:从指定路径加载数据。
- 数据准备:
①为篮板与胜利之间的分析准备数据:将篮板列("reb")组装成特征向量。
②为助攻与失误之间的分析准备数据:将助攻列("ast")组装成特征向量。
3.构建线性回归模型:
③构建篮板与胜利之间的线性回归模型。
④构建助攻与失误之间的线性回归模型。
4.进行预测:
⑤对篮板与胜利之间的模型进行预测。
⑥对助攻与失误之间的模型进行预测。
5.数据转换:
将预测结果转换为Pandas DataFrame,以便绘图。
6.绘图:
⑦绘制篮板与胜利之间的散点图和回归线。
⑧绘制助攻与失误之间的散点图和回归线。
7.显示结果:
⑨输出篮板与胜利之间的R平方和均方根误差(RMSE)。
⑩输出助攻与失误之间的R平方和RMSE。from pyspark.sql import SparkSession from pyspark.ml.feature import VectorAssembler from pyspark.ml.regression import LinearRegression
Load the data
data_path = "hdfs://localhost:9000/usr/local/hadoop/clean_data_final.csv"
data = spark.read.csv(data_path, header=True, inferSchema=True)
Prepare data for analysis of rebounds vs. victories
vector_assembler_rebounds = VectorAssembler(inputCols=["reb"], outputCol="features_rebounds")
data_rebounds = vector_assembler_rebounds.transform(data).select("features_rebounds", "w")
Prepare data for analysis of assists vs. turnovers
vector_assembler_assists = VectorAssembler(inputCols=["ast"], outputCol="features_assists")
data_assists = vector_assembler_assists.transform(data).select("features_assists", "tov")
Linear Regression model for rebounds vs. victories
lr_rebounds = LinearRegression(featuresCol="features_rebounds", labelCol="w")
lr_model_rebounds = lr_rebounds.fit(data_rebounds)
predictions_rebounds = lr_model_rebounds.transform(data_rebounds)
Linear Regression model for assists vs. turnovers
lr_assists = LinearRegression(featuresCol="features_assists", labelCol="tov")
lr_model_assists = lr_assists.fit(data_assists)
predictions_assists = lr_model_assists.transform(data_assists)
Convert Spark DataFrame to Pandas DataFrame for plotting
predictions_rebounds_pd = predictions_rebounds.select("features_rebounds", "w", "prediction").toPandas()
predictions_assists_pd = predictions_assists.select("features_assists", "tov", "prediction").toPandas()
Plotting Rebounds vs. Victories
plt.figure(figsize=(14, 7))
plt.subplot(1, 2, 1)
plt.scatter(predictions_rebounds_pd["features_rebounds"].apply(lambda x: x[0]), predictions_rebounds_pd["w"], label="Actual Values")
plt.plot(predictions_rebounds_pd["features_rebounds"].apply(lambda x: x[0]), predictions_rebounds_pd["prediction"], color='red', label="Regression Line")
plt.xlabel("Rebounds")
plt.ylabel("Victories")
plt.title("Rebounds vs. Victories")
plt.legend()
Plotting Assists vs. Turnovers
plt.subplot(1, 2, 2)
plt.scatter(predictions_assists_pd["features_assists"].apply(lambda x: x[0]), predictions_assists_pd["tov"], label="Actual Values")
plt.plot(predictions_assists_pd["features_assists"].apply(lambda x: x[0]), predictions_assists_pd["prediction"], color='red', label="Regression Line")
plt.xlabel("Assists")
plt.ylabel("Turnovers")
plt.title("Assists vs. Turnovers")
plt.legend()
plt.tight_layout()
plt.show()
Output the results
print(f"Rebounds vs. Victories - R2: {results_rebounds.r2}, RMSE: {results_rebounds.rootMeanSquaredError}")
print(f"Assists vs. Turnovers - R2: {results_assists.r2}, RMSE: {results_assists.rootMeanSquaredError}")
代码执行结果如下图所示:
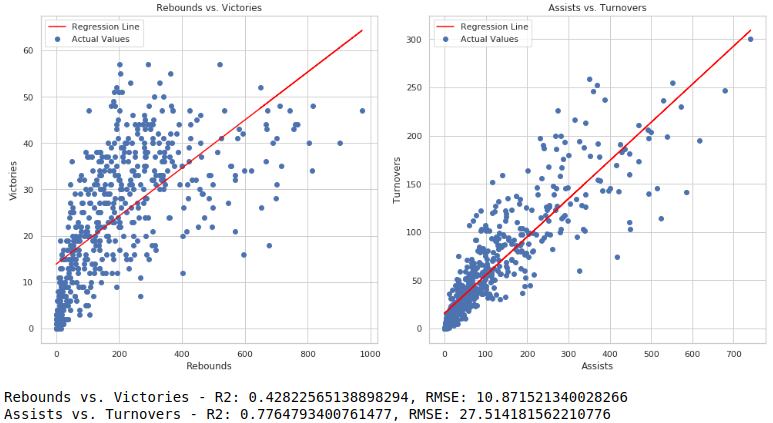
评价指标由模型拟合优度R2和均方根误差RMSE组成,从结果来看,篮板和球队的胜利具有很强的相关性,因为他的RMSE更低,但是线性拟合的效果不是很理想。对于助攻和失误,我们发现他们仍然是具有较强的正相关性,更多的助攻可能会带来更多的失误情况。
## 5.2. 相似性矩阵
计算属性间的相似性矩阵绘制热图,我们可以使用 Spark 将数据转换为 Pandas DataFrame,然后使用 Seaborn 和 Matplotlib 库来绘制热图。
```python
#计算属性间的相似性矩阵
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# Convert Spark DataFrame to Pandas DataFrame for correlation computation
df = data.toPandas()
# Compute the correlation matrix
corr = df.corr()
# Generate a mask for the upper triangle
mask = np.triu(np.ones_like(corr, dtype=bool))
# Set up the matplotlib figure
f, ax = plt.subplots(figsize=(11, 9))
# Generate a custom diverging colormap
cmap = sns.diverging_palette(230, 20, as_cmap=True)
# Draw the heatmap with the mask and correct aspect ratio
sns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0,
square=True, linewidths=.5, cbar_kws={"shrink": .5})
plt.show()运行结果如下图所示:
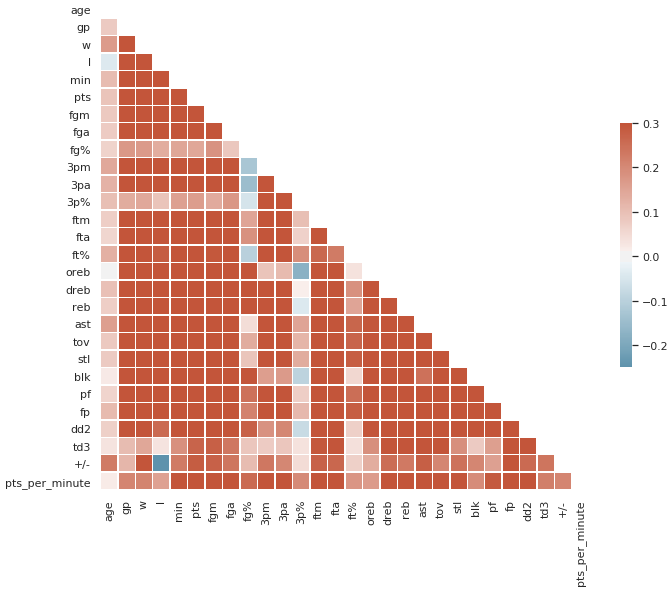
从结果来看,队员的正负值和球队的输球次数的负相关性很强,因为输球越多,场上的净失分也相应的越多,而三分球命中率跟大部分属性都没有很大的关系,跟球员的罚球命中率有很强的负相关性,因为大部分罚球命中高的球员可能是球队的内线,因此三分命中率比较低。
5.3. MLlib预测模型
利用MLlib中实现NBA球员表现的预测模型,步骤如下:
(1)创建新特征作为球员表现的分数(例如,每场比赛得分)。
(2)假设影响最后结果(球员总得分pts)的因素是除了球员得分、球员姓名、所属球队和位置以外的所有其他列组合成的一个特征向量。
(3)将数据分为训练集和测试集。
(4)选择一个合适的回归模型(线性回归)。
(5)在训练集上训练模型并在测试集进行预测。
(6)计算评估指标(MAE、MSE 和 R-squared)。
(7)定义一个函数 predict_points,用于预测特定球员的得分。
预测并输出特定球员(例如,Nikola Jokic)在下赛季的得分。
#NBA球员表现的预测模型
# 创建新特征(例如,每场比赛得分)。
# 删除 PName 列并对分类变量进行编码。
# 将数据分为训练集和测试集。
# 选择一个合适的回归模型(线性回归)。
# 在训练集上训练模型。
# 使用测试集进行预测。
# 计算评估指标(MAE、MSE 和 R-squared)。
# 定义一个函数 predict_points,用于预测特定球员的得分。
# 预测并输出特定球员(例如,Nikola Jokic)在下赛季的得分。
# Create new features
from pyspark.ml.feature import VectorAssembler, StringIndexer
from pyspark.ml.regression import LinearRegression
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml import Pipeline
# Create new features
data = data.withColumn("ppg", data["pts"] / data["gp"])
# Index categorical columns
team_indexer = StringIndexer(inputCol="team", outputCol="team_index")
pos_indexer = StringIndexer(inputCol="pos", outputCol="pos_index")
# Assemble features into a feature vector
assembler = VectorAssembler(inputCols=[col for col in data.columns if col not in ['pts', 'pname', 'team', 'pos']], outputCol="features")
# Define the Linear Regression model
lr = LinearRegression(featuresCol="features", labelCol="pts")
# Split the data into a training set and a test set
train_data, test_data = data.randomSplit([0.8, 0.2], seed=42)
# Create a Pipeline
pipeline = Pipeline(stages=[team_indexer, pos_indexer, assembler, lr])
# Train the model
model = pipeline.fit(train_data)
# Make predictions using the test set
predictions = model.transform(test_data)
# Convert predictions to Pandas DataFrame for visualization
predictions_pd = predictions.select("pts", "prediction").toPandas()
# Plotting actual vs predicted points
plt.figure(figsize=(14, 7))
sns.scatterplot(x=predictions_pd["pts"], y=predictions_pd["prediction"])
sns.lineplot(x=predictions_pd["pts"], y=predictions_pd["pts"], color="red", linestyle="--")
plt.xlabel("Actual Points")
plt.ylabel("Predicted Points")
plt.title("Actual vs Predicted Points")
plt.show()
# Evaluate the model
evaluator = RegressionEvaluator(labelCol="pts", predictionCol="prediction", metricName="mae")
mae = evaluator.evaluate(predictions)
evaluator = RegressionEvaluator(labelCol="pts", predictionCol="prediction", metricName="mse")
mse = evaluator.evaluate(predictions)
evaluator = RegressionEvaluator(labelCol="pts", predictionCol="prediction", metricName="r2")
r2 = evaluator.evaluate(predictions)
# Print the evaluation metrics
print(f'Mean Absolute Error (MAE): {mae}')
print(f'Mean Squared Error (MSE): {mse}')
print(f'R-squared: {r2}')
def predict_points(player_name):
# Get the player's data
player_data = data.filter(data['pname'] == player_name)
# Check if the player is in the dataset
if player_data.count() == 0:
print(f"No data available for player: {player_name}")
return None
# Transform the player's data
player_prediction = model.transform(player_data)
# Get the prediction
points_prediction = player_prediction.select("prediction").collect()[0][0]
return points_prediction
# Predict points for a specific player
player_name = "Nikola Jokic" # replace with the name of the player
predicted_points = predict_points(player_name)
if predicted_points is not None:
print(f"Player Name: {player_name}")
print(f"Predicted Points for {player_name} in the next season: {predicted_points:.2f}")
else:
print("Player not found in the dataset.")运行结果如下图所示:
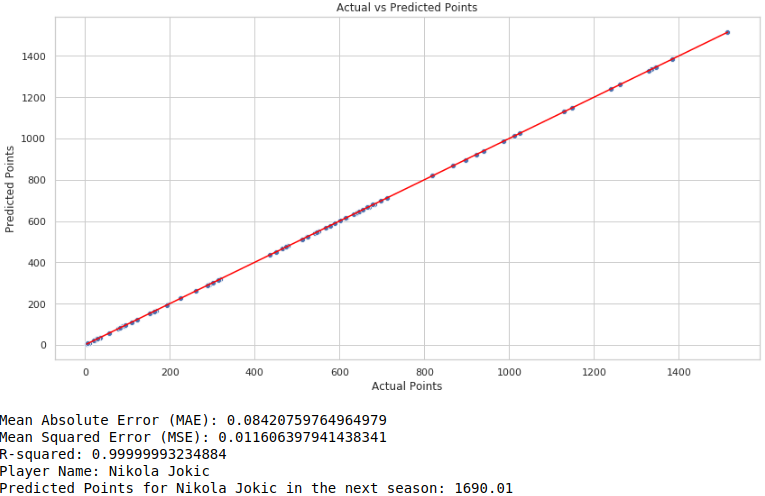
实验结果非常好,因为我们用于预测的特征非常丰富。评价指标是MSE和MAE,他们的值都非常小,意味着我们的预测非常接近真实值。
六、实验结果可视化
6.1. 每个球队的场均得分、篮板和助攻
import pandas as pd
# 使用 Pandas 读取 CSV 文件
team_stats = pd.read_csv("/home/hadoop/jupyternotebook/lxddashuju/result/team_stats.csv")
pos_stats = pd.read_csv("/home/hadoop/jupyternotebook/lxddashuju/result/pos_stats.csv")
age_stats = pd.read_csv("/home/hadoop/jupyternotebook/lxddashuju/result/age_stats.csv")
team_top_scorers = pd.read_csv("/home/hadoop/jupyternotebook/lxddashuju/result/team_top_scorers.csv")
pos_top_scorers = pd.read_csv("/home/hadoop/jupyternotebook/lxddashuju/result/pos_top_scorers.csv")
age_top_scorers = pd.read_csv("/home/hadoop/jupyternotebook/lxddashuju/result/age_top_scorers.csv")
top_10_scorers = pd.read_csv("/home/hadoop/jupyternotebook/lxddashuju/result/top_10_scorers.csv")
player_avg_rebounds = pd.read_csv("/home/hadoop/jupyternotebook/lxddashuju/result/player_avg_rebounds.csv")
player_avg_assists = pd.read_csv("/home/hadoop/jupyternotebook/lxddashuju/result/player_avg_assists.csv")
player_pts_per_min = pd.read_csv("/home/hadoop/jupyternotebook/lxddashuju/result/player_pts_per_min.csv")
player_fg_3p_stats = pd.read_csv("/home/hadoop/jupyternotebook/lxddashuju/result/player_fg_3p_stats.csv")
team_win_lose_rate = pd.read_csv("/home/hadoop/jupyternotebook/lxddashuju/result/team_win_lose_rate.csv")import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 设置图形样式
sns.set(style="whitegrid")
# 1.每个球队的场均得分、篮板和助攻的横着的柱状图
# 确保数据是数值类型
team_stats['team_avg_points'] = pd.to_numeric(team_stats['team_avg_points'], errors='coerce')
team_stats['team_avg_rebounds'] = pd.to_numeric(team_stats['team_avg_rebounds'], errors='coerce')
team_stats['team_avg_assists'] = pd.to_numeric(team_stats['team_avg_assists'], errors='coerce')
# 每个球队的场均得分、篮板和助攻的高斯分布图
plt.figure(figsize=(14, 7))
sns.kdeplot(team_stats['team_avg_points'], shade=True, label='Average Points')
sns.kdeplot(team_stats['team_avg_rebounds'], shade=True, label='Average Rebounds')
sns.kdeplot(team_stats['team_avg_assists'], shade=True, label='Average Assists')
plt.title('Distribution of Average Points, Rebounds, and Assists per Team')
plt.xlabel('Average')
plt.ylabel('Density')
plt.legend()
plt.show()运行结果如下:
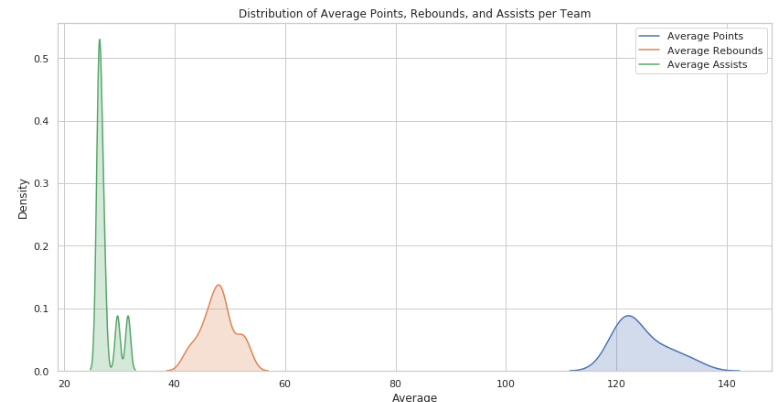
可以看到球队的场均得分分布在120分附近,场均助攻和篮板在30和50附近。
6.2. 计算每个位置的场均得分、篮板和助攻,并包含命中率和三分命中率
# 2.每个位置的场均得分、篮板和助攻的竖着的柱状图
plt.figure(figsize=(14, 7))
pos_stats_melted = pos_stats.melt(id_vars="pos", value_vars=["pos_avg_points", "pos_avg_rebounds", "pos_avg_assists"], var_name="Metric", value_name="Value")
sns.barplot(x='pos', y='Value', hue='Metric', data=pos_stats_melted)
plt.title('Average Points, Rebounds, and Assists per Position')
plt.xlabel('Position')
plt.ylabel('Average')
plt.legend()
plt.show()运行结果如下:
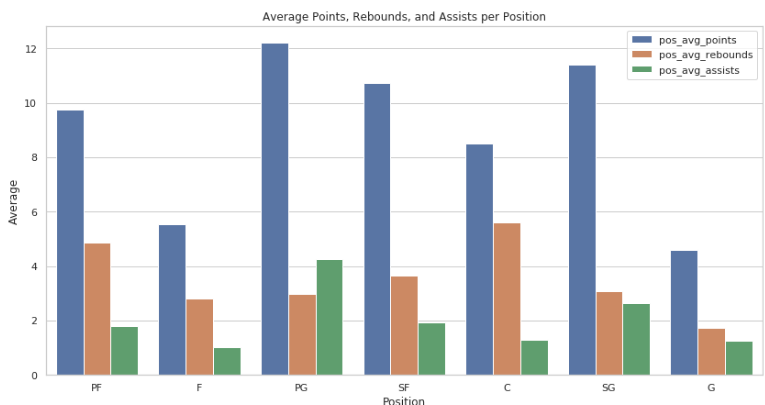
从结果可以看到,不同位置的表现各有千秋,以得分来说,一般是后卫PG或SG和小前锋SF所擅长的,同时控球后卫PG在传球这一数据上表现更为突出,而在篮板数上,表现最好的是中锋,但同时他的传球能力是相对较弱的。
尝试使用ECharts进行可视化:
import json
# 转换数据为 ECharts 格式
pos_stats_melted = pos_stats.melt(id_vars="pos", value_vars=["pos_avg_points", "pos_avg_rebounds", "pos_avg_assists"], var_name="Metric", value_name="Value")
# 准备数据
positions = pos_stats_melted['pos'].unique().tolist()
metrics = pos_stats_melted['Metric'].unique().tolist()
# 创建数据字典
data_dict = {metric: pos_stats_melted[pos_stats_melted['Metric'] == metric][['pos', 'Value']].set_index('pos').to_dict()['Value'] for metric in metrics}
# 生成 ECharts 数据
series_data = []
for metric in metrics:
series_data.append({
"name": metric,
"type": "bar",
"data": [data_dict[metric].get(pos, 0) for pos in positions]
})
# 创建 ECharts 配置
echarts_config = {
"title": {
"text": 'Average Points, Rebounds, and Assists per Position'
},
"tooltip": {
"trigger": 'axis',
"axisPointer": {
"type": 'shadow'
}
},
"legend": {
"data": metrics
},
"grid": {
"left": '3%',
"right": '4%',
"bottom": '3%',
"containLabel": True
},
"xAxis": {
"type": 'category',
"data": positions
},
"yAxis": {
"type": 'value'
},
"series": series_data
}
# 将 ECharts 配置写入 HTML 文件
html_content = f"""
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>ECharts</title>
<script src="https://cdn.jsdelivr.net/npm/echarts@5.2.2/dist/echarts.min.js"></script>
</head>
<body>
<div id="main" style="width: 100%; height: 600px;"></div>
<script type="text/javascript">
var chartDom = document.getElementById('main');
var myChart = echarts.init(chartDom);
var option = {json.dumps(echarts_config, indent=4)};
myChart.setOption(option);
</script>
</body>
</html>
"""
# 将 HTML 内容写入文件
with open("/home/hadoop/jupyternotebook/lxddashuju/result/pos_stats_echarts.html", "w") as f:
f.write(html_content)
print("ECharts 可视化已生成并保存为 pos_stats_echarts.html")运行结果如下:
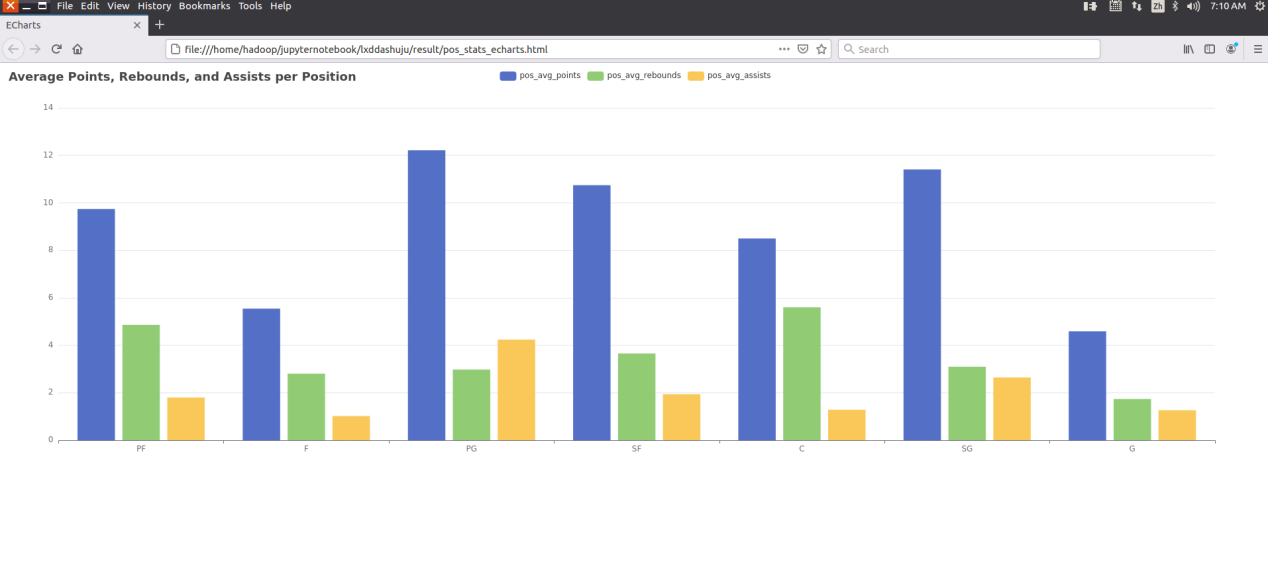
我们额外尝试了利用ECharts可视化将可视化结果保存在了网页当中,具体而言,将 pos_stats 数据转换为 ECharts 格式,并生成一个 HTML 文件,用于可视化每个位置的平均得分、篮板和助攻。首先,将数据转换为长格式,提取唯一的位置和指标,创建数据字典。接着,生成每个指标的柱状图数据,并创建 ECharts 的配置文件,包括标题、工具提示、图例、坐标轴和数据系列。最后,将配置嵌入 HTML 模板中,并通过 ECharts 库初始化图表,将生成的 HTML 内容写入文件并保存,输出确认信息表示文件已生成。
6.3. 每个年龄段的场均得分、篮板和助攻,并包含命中率和三分命中率
# 3. 每个年龄段的场均得分、篮板和助攻的条形图
plt.figure(figsize=(12, 6))
sns.barplot(x='age', y='age_avg_points', data=age_stats, color='blue', label='Points')
sns.barplot(x='age', y='age_avg_rebounds', data=age_stats, color='green', label='Rebounds')
sns.barplot(x='age', y='age_avg_assists', data=age_stats, color='red', label='Assists')
plt.title('Average Points, Rebounds, and Assists per Age Group')
plt.xlabel('Age')
plt.ylabel('Average')
plt.legend()
plt.show()运行结果如下:
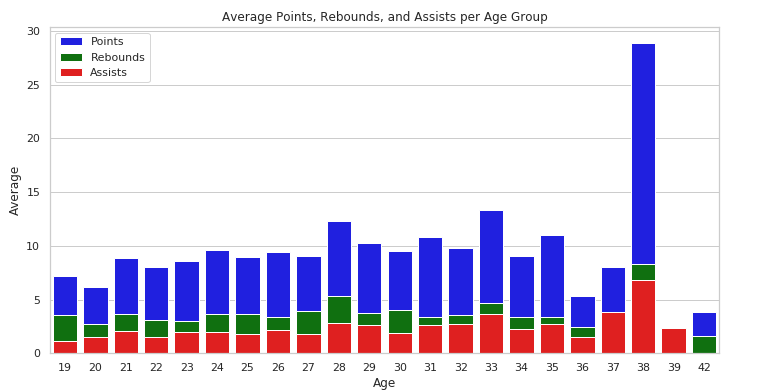
从结果来看,38岁年龄段的数据特别突出,结果校验发现,38岁只有勒布朗詹姆斯一名球员,作为这一代篮球的巨星,这一豪华数据,也不足以为奇了。
6.4. 每个球队场均得分最高的球员
# 4. 每个球队得分最高的球员
# 每个球队场均得分最高的球员的竖着的柱状图
# 确保数据是数值类型
team_top_scorers['avg_points'] = pd.to_numeric(team_top_scorers['avg_points'], errors='coerce')
# 每个球队得分最高的球员的柱状图
plt.figure(figsize=(14, 7))
colors = sns.color_palette("husl", len(team_top_scorers)) # 使用不同的颜色
sns.barplot(x='team', y='avg_points', data=team_top_scorers, palette=colors)
plt.title('Top Scorers per Team')
plt.xlabel('Team')
plt.ylabel('Average Points')
plt.xticks(rotation=90)
plt.show()运行结果如下:
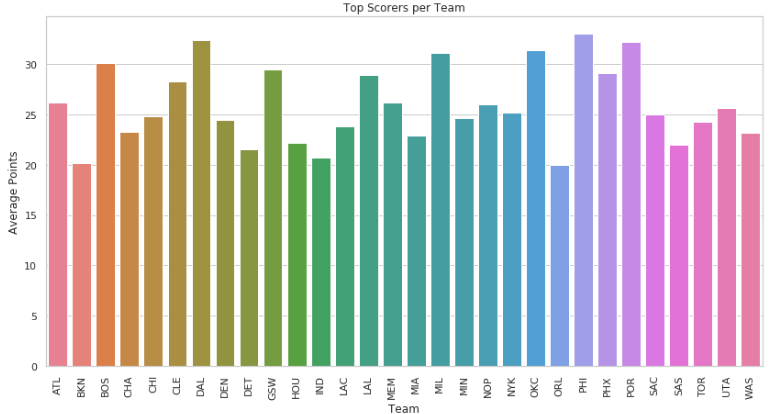
所结果来看,一些排名靠前的球队,例如76人PHI,太阳PHX,雄鹿MIL他们的得分最高的球员都尤为突出,这也说明了当家球星对于球队战绩的重要性。
6.5. 找出每个位置场均得分最高的球员
# 5. 每个位置得分最高的球员
# 确保数据是数值类型
pos_top_scorers['avg_points'] = pd.to_numeric(pos_top_scorers['avg_points'], errors='coerce')
# 每个位置得分最高的球员的柱状图
plt.figure(figsize=(12, 6))
colors = sns.color_palette("Set2", len(pos_top_scorers)) # 使用不同的颜色
sns.barplot(x='pos', y='avg_points', data=pos_top_scorers, palette=colors)
plt.title('Top Scorers per Position')
plt.xlabel('Position')
plt.ylabel('Average Points')
plt.show()运行结果如下:
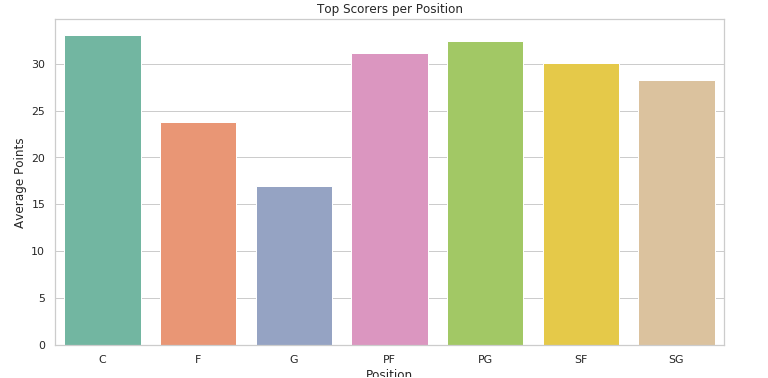
从结果来看,得分最高的是来自中锋,因为2022~2023年的得分王是来自76人的中分恩比德,紧随其后,PG,SF和PF具有很强的竞争力。
6.6. 找出每个年龄段场均得分最高的球员
# 6. 每个年龄段得分最高的球员
# 每个年龄段场均得分最高的球员的竖着的柱状图
plt.figure(figsize=(14, 7))
sns.barplot(x='age', y='avg_points', data=age_top_scorers, color='blue')
plt.title('Top Scorers per Age Group')
plt.xlabel('Age')
plt.ylabel('Average Points')
plt.show()运行结果如下:
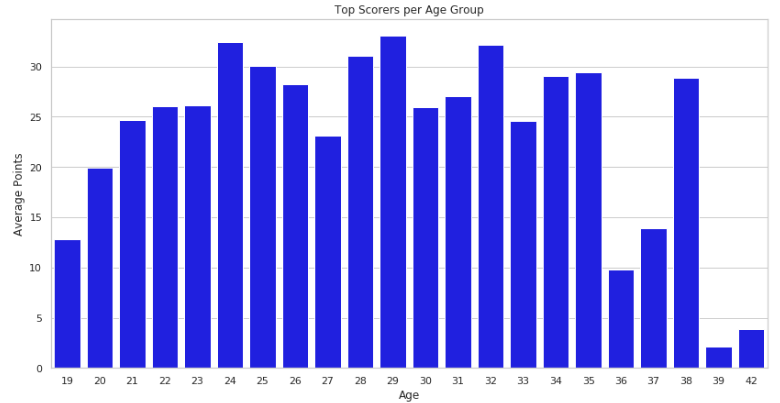
从结果来看,年纪在24~32岁之间的得分普遍更高,说明球员的上升期和巅峰期也常常处在这个时期。
6.7. 找出场均得分最高的前 10 名球员
# 7. 场均得分最高的前 10 名球员
# 场均得分最高的前 10 名球员的高斯分布图
# 确保数据是数值类型
top_10_scorers['avg_points'] = pd.to_numeric(top_10_scorers['avg_points'][0:10], errors='coerce')
# 场均得分最高的前10名球员的柱状图
plt.figure(figsize=(14, 7))
sns.barplot(x='pname', y='avg_points', data=top_10_scorers[0:10], color='purple')
plt.title('Top 10 Scorers')
plt.xlabel('Player Name')
plt.ylabel('Average Points')
plt.xticks(rotation=90)
plt.show()运行结果如下:
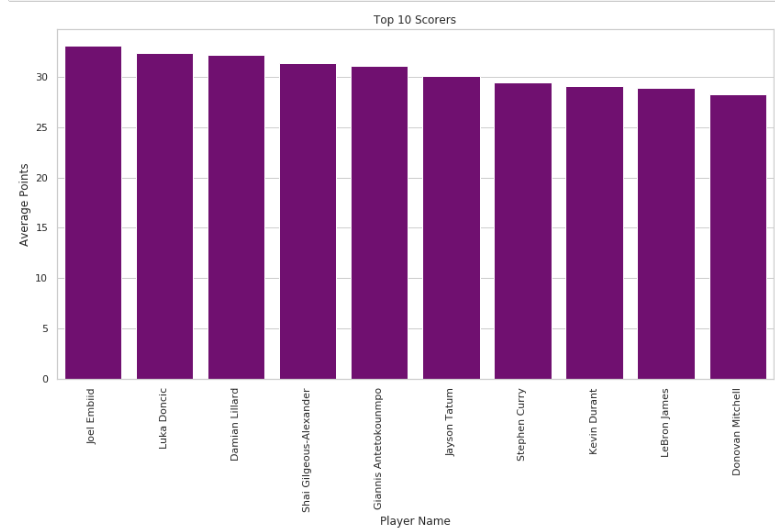
从结果来看,他们分别是恩比德,东契奇,利拉德,亚历山大,字母哥,塔图姆,库里,杜兰特,詹姆斯,米切尔。
6.8. 每个球员的场均篮板数
# 8. 每个球员的场均篮板数
# 确保数据是数值类型
player_avg_rebounds['avg_rebounds'] = pd.to_numeric(player_avg_rebounds['avg_rebounds'], errors='coerce')
# 统计场均篮板数在不同区间段的个数
bins_rebounds = [0, 2, 4, 6, 8, 10, float('inf')]
labels_rebounds = ['0-2', '2-4', '4-6', '6-8', '8-10', '10+']
player_avg_rebounds['rebounds_range'] = pd.cut(player_avg_rebounds['avg_rebounds'], bins=bins_rebounds, labels=labels_rebounds, right=False)
rebounds_counts = player_avg_rebounds['rebounds_range'].value_counts().sort_index()
# 每个球员的场均篮板数的扇形图
plt.figure(figsize=(8, 8))
plt.pie(rebounds_counts, labels=rebounds_counts.index, autopct='%1.1f%%', startangle=140, colors=sns.color_palette("Set3"))
plt.title('Distribution of Average Rebounds per Player')
plt.show()运行结果如下:
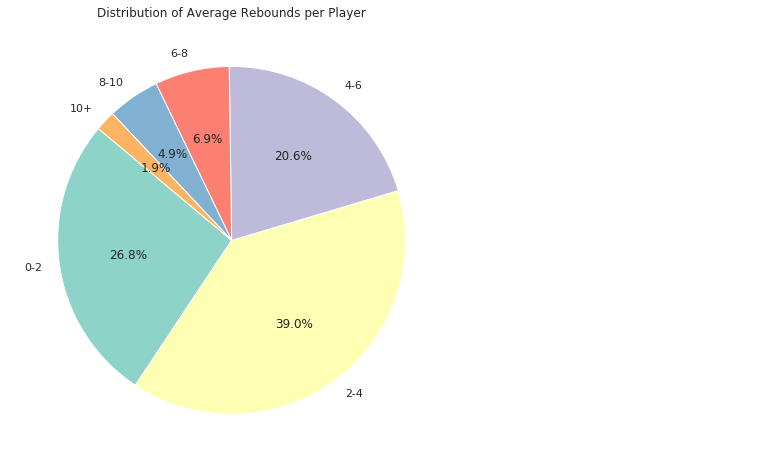
从结果来看,大部分球员的篮板数集中在2~4个,其次是0~2个,当有场均4~6个时,可以达到nba的平均篮板水平。
6.9. 每个球员的场均助攻数
# 9. 每个球员的场均助攻数
# 确保数据是数值类型
player_avg_assists['avg_assists'] = pd.to_numeric(player_avg_assists['avg_assists'], errors='coerce')
# 统计场均助攻数在不同区间段的个数
bins_assists = [0, 2, 4, 6, 8, 10, float('inf')]
labels_assists = ['0-2', '2-4', '4-6', '6-8', '8-10', '10+']
player_avg_assists['assists_range'] = pd.cut(player_avg_assists['avg_assists'], bins=bins_assists, labels=labels_assists, right=False)
assists_counts = player_avg_assists['assists_range'].value_counts().sort_index()
# 每个球员的场均助攻数的扇形图
plt.figure(figsize=(8, 8))
plt.pie(assists_counts, labels=assists_counts.index, autopct='%1.1f%%', startangle=140, colors=sns.color_palette("Set2"))
plt.title('Distribution of Average Assists per Player')
plt.show()运行结果如下:

从结果来看,大部分球员的助攻数集中在0~2个,可以达到nba的平均助攻水平,其次是2~4个,普遍的数据都很低,这意味着助攻是一个需要天赋,运气,经验等综合因素决定的。
6.10. 每个球员的得分与时间的比率(得分/分钟)
# 10. 每个球员的得分与时间的比率(得分/分钟)
# 确保数据是数值类型
player_pts_per_min['pts_per_minute'] = pd.to_numeric(player_pts_per_min['pts_per_minute'], errors='coerce')
# 统计得分与时间的比率在不同区间段的个数
bins_pts_per_min = [0, 0.2, 0.4, 0.6, 0.8, 1, float('inf')]
labels_pts_per_min = ['0-0.2', '0.2-0.4', '0.4-0.6', '0.6-0.8', '0.8-1', '1+']
player_pts_per_min['pts_per_minute_range'] = pd.cut(player_pts_per_min['pts_per_minute'], bins=bins_pts_per_min, labels=labels_pts_per_min, right=False)
pts_per_minute_counts = player_pts_per_min['pts_per_minute_range'].value_counts().sort_index()
# 每个球员的得分与时间的比率(得分/分钟)的扇形图
plt.figure(figsize=(8, 8))
plt.pie(pts_per_minute_counts, labels=pts_per_minute_counts.index, autopct='%1.1f%%', startangle=140, colors=sns.color_palette("Set1"))
plt.title('Distribution of Points per Minute per Player')
plt.show()运行结果如下:
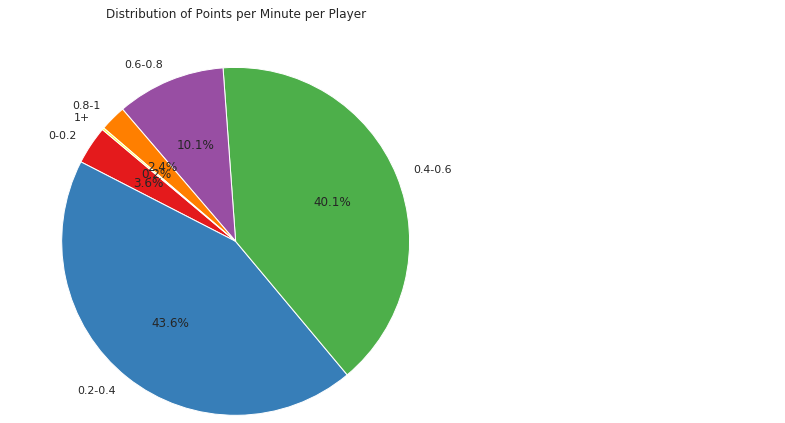
从结果来看,大部分球员的得分效率集中在0.2~0.4,也是nba的平均效率水平,其次是0.4~0.6个,很少有球员的效率可以超过1。
6.11. 每个球队的胜率和输率
# 确保数据是数值类型
team_win_lose_rate['team_win_rate'] = pd.to_numeric(team_win_lose_rate['team_win_rate'], errors='coerce')
team_win_lose_rate['team_lose_rate'] = pd.to_numeric(team_win_lose_rate['team_lose_rate'], errors='coerce')
# 分析每个球队的胜率和输率的柱状图
plt.figure(figsize=(14, 7))
team_win_lose_rate_melted = team_win_lose_rate.melt(id_vars="team", value_vars=["team_win_rate", "team_lose_rate"], var_name="Metric", value_name="Value")
sns.barplot(x='team', y='Value', hue='Metric', data=team_win_lose_rate_melted)
plt.title('Win Rate and Lose Rate per Team')
plt.xlabel('Team')
plt.ylabel('Rate')
plt.legend()
plt.xticks(rotation=90)
plt.show()运行结果如下:
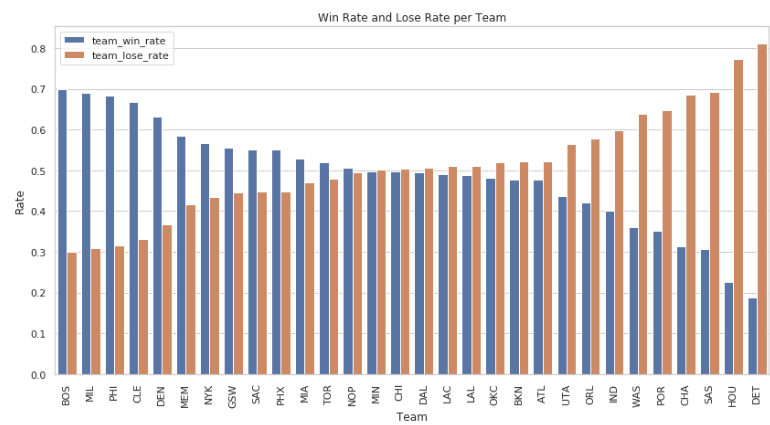
从结果来看,胜率从高到低的顺序为凯尔特人,雄鹿,76人,骑士,掘金,灰熊,值得注意的是排名前几的都是东部球队的球员,从结果也可以看出东部球队的实力悬殊较大。
6.12. 统计数据进行聚类可视化
对NBA球员的统计数据进行聚类分析,根据球员的平均得分、平均篮板和平均助攻将球员分为不同的群体,并使用可视化工具展示了聚类结果。
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import seaborn as sns
# 读取处理后的数据
player_stats = pd.read_csv('/home/hadoop/jupyternotebook/dashujulxd/processed_nba_players_stats.csv')
# 选择特征进行聚类
features = player_stats[['avg_points', 'avg_rebounds', 'avg_assists']]
# 数据标准化
scaler = StandardScaler()
scaled_features = scaler.fit_transform(features)
# 使用 K-means 进行聚类
kmeans = KMeans(n_clusters=3, random_state=42)
clusters = kmeans.fit_predict(scaled_features)
# 将聚类结果添加到数据集中
player_stats['cluster'] = clusters
# 可视化聚类结果
plt.figure(figsize=(14, 7))
sns.scatterplot(x='avg_points', y='avg_rebounds', hue='cluster', palette='viridis', data=player_stats, s=100)
plt.title('K-means Clustering of Players based on Points and Rebounds')
plt.xlabel('Average Points')
plt.ylabel('Average Rebounds')
plt.legend(title='Cluster')
plt.show()
plt.figure(figsize=(14, 7))
sns.scatterplot(x='avg_points', y='avg_assists', hue='cluster', palette='viridis', data=player_stats, s=100)
plt.title('K-means Clustering of Players based on Points and Assists')
plt.xlabel('Average Points')
plt.ylabel('Average Assists')
plt.legend(title='Cluster')
plt.show()运行结果如下:

从结果可以看出,聚类分为了3个群体,,第一个群体可能是一些替补球员,他们的场均得分和助攻以及篮板都相对较少,第二个群里可能包含蓝领和一些有潜力的年轻球员,第三个群体大多包含了已经兑现了天赋的球星。
6.13. 场均命中率和场均三分命中率的聚类和可视化
根据球员的平均命中率和平均三分命中率将球员分为不同的群体。
# 场均命中率和场均三分命中率的聚类和可视化
# 选择新的特征进行聚类
new_features = player_stats[['avg_fg%', 'avg_3p%']]
# 数据标准化
new_scaled_features = scaler.fit_transform(new_features)
# 使用 K-means 进行聚类
new_kmeans = KMeans(n_clusters=3, random_state=42)
new_clusters = new_kmeans.fit_predict(new_scaled_features)
# 将聚类结果添加到数据集中
player_stats['new_cluster'] = new_clusters
# 可视化新的聚类结果
plt.figure(figsize=(14, 7))
sns.scatterplot(x='avg_fg%', y='avg_3p%', hue='new_cluster', palette='coolwarm', data=player_stats, s=100)
plt.title('K-means Clustering of Players based on FG% and 3P%')
plt.xlabel('Field Goal Percentage')
plt.ylabel('3-Point Percentage')
plt.legend(title='Cluster')
plt.show()运行结果如下:
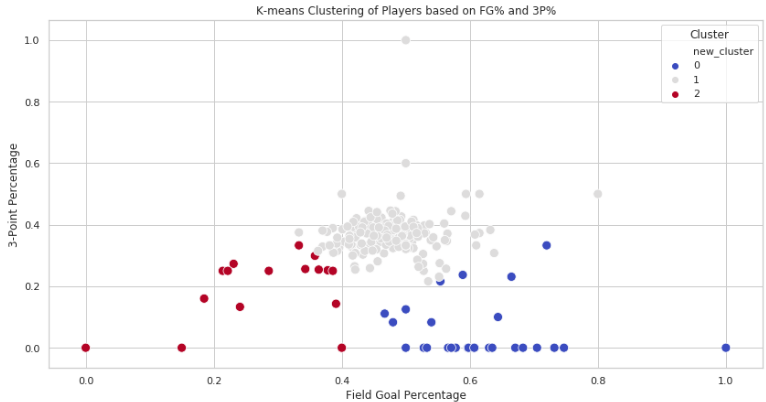
从结果来看,大概可以分为:1.内线球员,2.全能型选手,3.投手。全能型选手群体中大部分都具有相似的三分命中率和平均命中率,第二类部分群体可能是3D投手,比较追求远程的3分,很少突破内线得分,另一部分可能是内线群体,他们几乎不投三分或者具有很弱的3分能力,专注于内线的得分。
七、总结
本次实验通过使用Spark对NBA球员数据进行了全面分析,涵盖了数据清洗、特征提取、统计分析和可视化展示等多个环节。以下是本次实验的主要成果和重要发现:
1.数据清洗与处理:我们对Kaggle提供的NBA球员数据集进行了清洗,包括处理空值、重复值和异常值,并标准化了字段名称,确保数据的准确性和一致性。数据清洗后,我们引入了新的特征如“得分效率”。
2.数据存储:清洗后的数据被存储在HDFS中,确保大数据处理的高效性和可靠性。
3.统计分析:对每个球队、位置和年龄段的球员进行了统计分析,计算了场均得分、篮板和助攻等关键指标。结果显示,球队和球员位置之间的表现存在显著差异,特定球队的明星球员对其战绩有重要影响。
4.可视化展示:使用Matplotlib和Seaborn等工具,我们对统计结果进行了可视化。每个球队和位置的场均得分、篮板和助攻等数据被展示出来,为理解数据提供了直观的支持。
5.线性回归模型:使用MLlib,我们构建了线性回归模型,分析篮板与胜利、助攻与失误之间的关系。结果显示篮板与胜利之间具有较强的相关性,但线性拟合效果一般。助攻与失误之间也表现出较强的正相关性。
6.预测模型:利用丰富的特征数据,我们构建了NBA球员表现的预测模型。模型在预测球员得分方面表现出色,评价指标如MSE和MAE均显示预测误差较小。
7.聚类分析:对球员的统计数据进行聚类分析,将球员分为不同群体。结果表明,球员可以根据得分、篮板和助攻等指标分为替补球员、潜力球员和明星球员等群体。
8.综合分析:进一步分析了球员命中率和三分命中率,以及每个球队的胜率和输率。结果显示,球队胜率与球员表现密切相关,东部球队在本赛季表现尤为突出。
总而言之,本次实验展示了大数据处理和分析技术在体育数据中的应用,通过系统化的数据清洗、特征提取和建模,得到了有价值的洞见,为NBA球队和球员的表现提供了可靠的数据支持。未来可以继续优化模型,探索更多数据特征,提高预测准确度,从而更好地服务于体育数据分析和决策。