
【版权声明】版权所有,严禁转载,严禁用于商业用途,侵权必究。
作者:厦门大学信息学院2022级研究生 赖芹
指导老师:厦门大学数据库实验室 林子雨 博士/副教授 ziyulin@xmu.edu.cn
相关教材:林子雨、郑海山、赖永炫编著《Spark编程基础(Python版)》(访问教材官网)
相关案例:基于Python语言的Spark数据处理分析案例集锦(PySpark)
可以从百度网盘下载本实验的数据集和源代码。(点击这里访问百度网盘下载数据集和源代码)(提取码是ziyu)。
1.实验环境搭建
(1)Linux:Ubuntu 22.04
(2)Hadoop:3.1.3
(3)Spark:3.2.0
(4)Python:3.8
(5)运行环境:Jupyter Notebook(参考博客:使用Jupyter Notebook调试PySpark程序)
此外还需要安装numpy, pandas来进行数据处理,安装scipy, matplotlib, senborn,plotly进行可视化或辅助可视化。具体来说,需要执行如下安装命令:
pip instal numpy
pip install pandas
pip install matplotlib
pip install senborn
pip install plotly2.数据集介绍
本次项目使用的数据集是Kaggle的Netflix Movies and TV Shows数据集,该数据集包含大约5000部电影的相关数据。本次实验使用数据集中有关电影的数据表 netflix_titles.csv 进行实验。这个数据集包含了从2008年到2020年间Netflix平台上的电影和电视节目的详细信息(访问百度网盘下载数据集)(提取码是ziyu)。
以下是该数据集的一些关键特征和字段包括:
show_id:唯一标识每个节目的ID。
type:节目的类型,包括电影(Movie)和电视剧(TV Show)。
title:节目的标题或名称。
director:导演的姓名。
cast:主要演员的姓名。
country:节目的制作国家或地区。
date_added:节目添加到Netflix平台的日期。
release_year:节目的发布年份。
rating:节目的评级(适宜观众群体)。
duration:节目的持续时长。
listed_in:节目所属的类型或类别。
description:节目的简要描述。
3.数据预处理
3.1.查看数据集基本信息
把csv文件读入,并显示前几行数据,然后查看数据集的大小,摘要等基本信息。
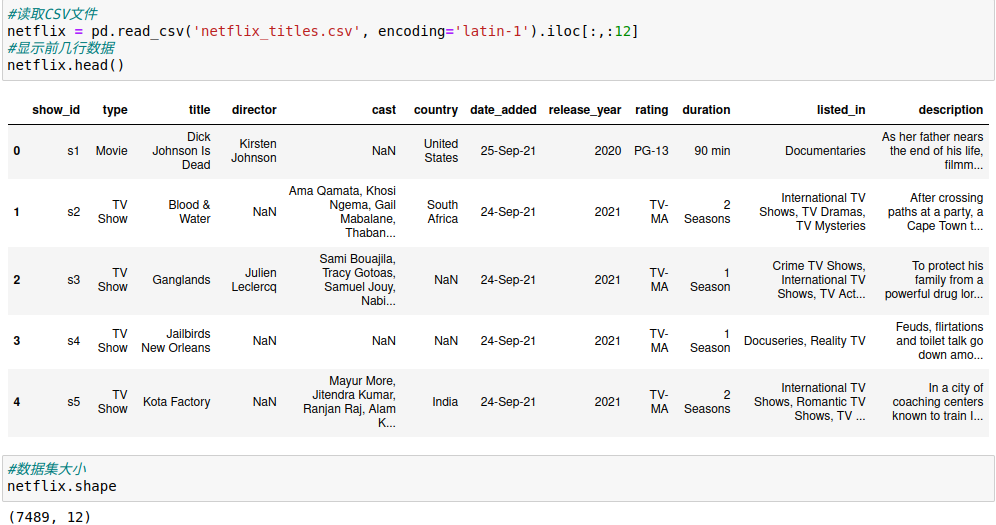
3.2.检查和处理空值
对数据进行清洗,检查并处理空值。

3.3.增加新字段
增加新字段,便于后续的数据分析。
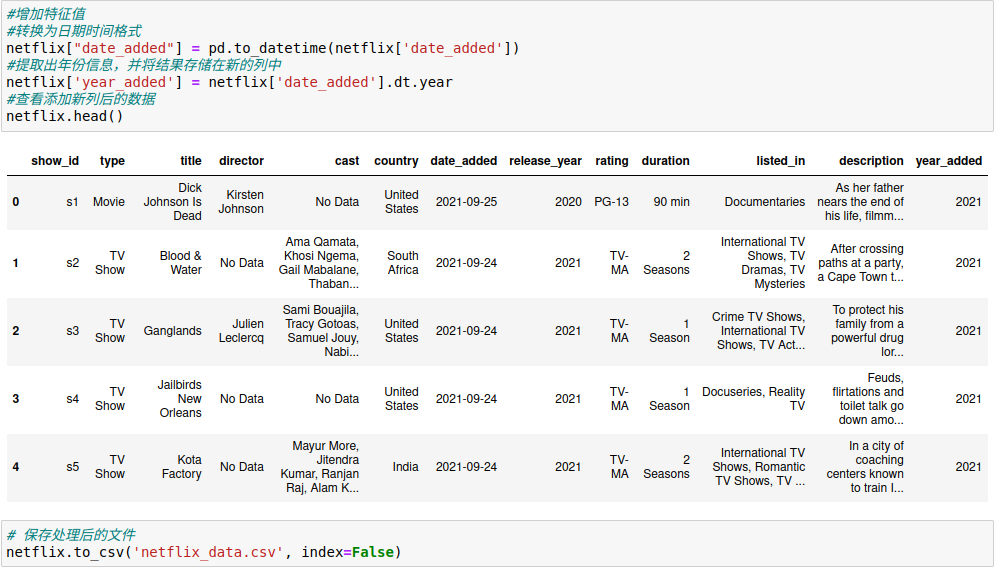
3.4.使用HDFS存储文件
启动Hadoop。

将预处理后的csv文件上传到HDFS。

4.数据分析
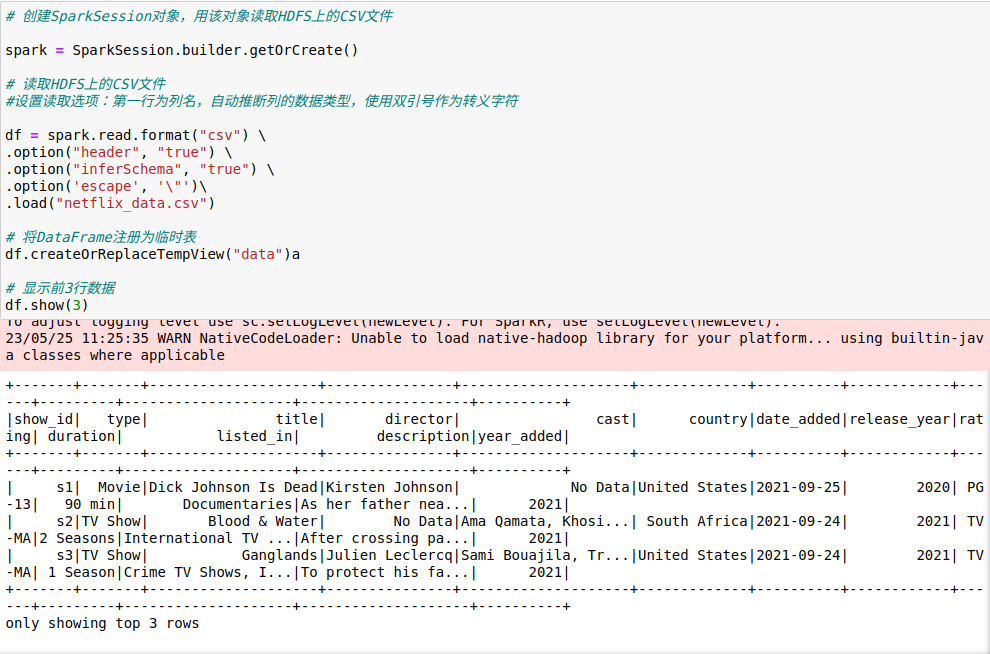
4.1.读取数据
从HDFS中将文件读出,然后检查读出的数据是否无误。
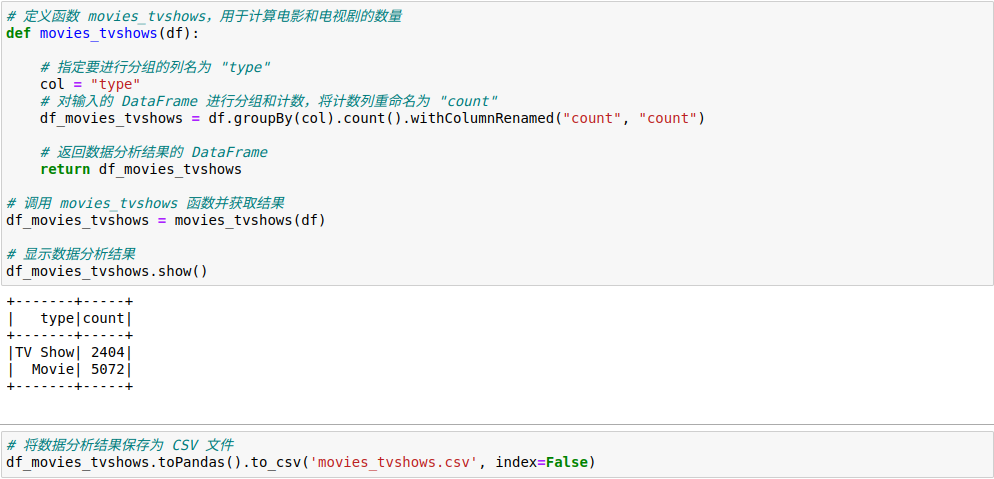
4.2.分析电影和电视剧的占比情况
选择type列,然后按照里面的类别进行分组计数,计算出电影和电视剧的数量。
在确认数据无误后,保存到csv文件,以便后面进行可视化。
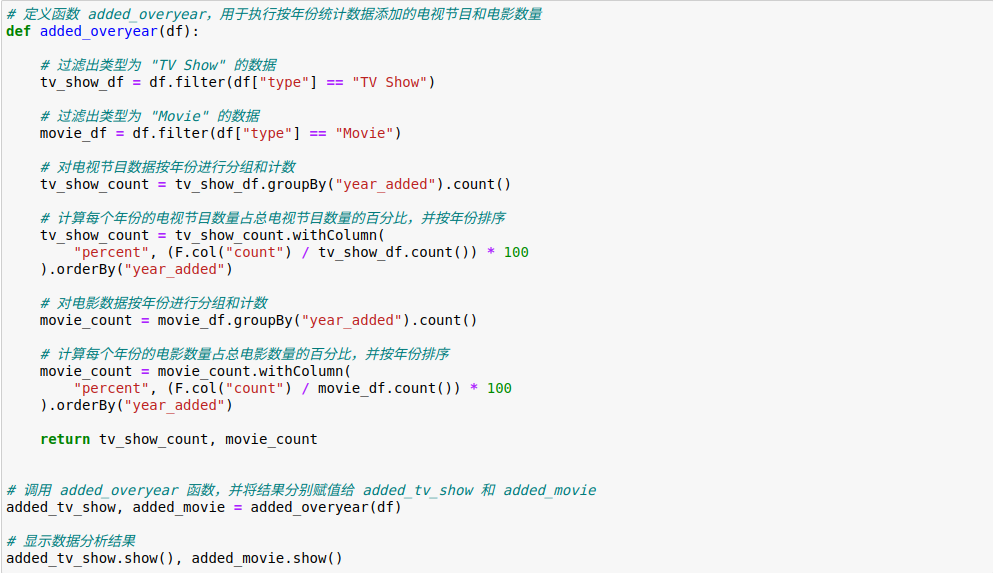
4.3.按年份统计添加的电视节目和电影数量
按年份统计电视节目和电影的数量,并计算它们在各年份的占比。
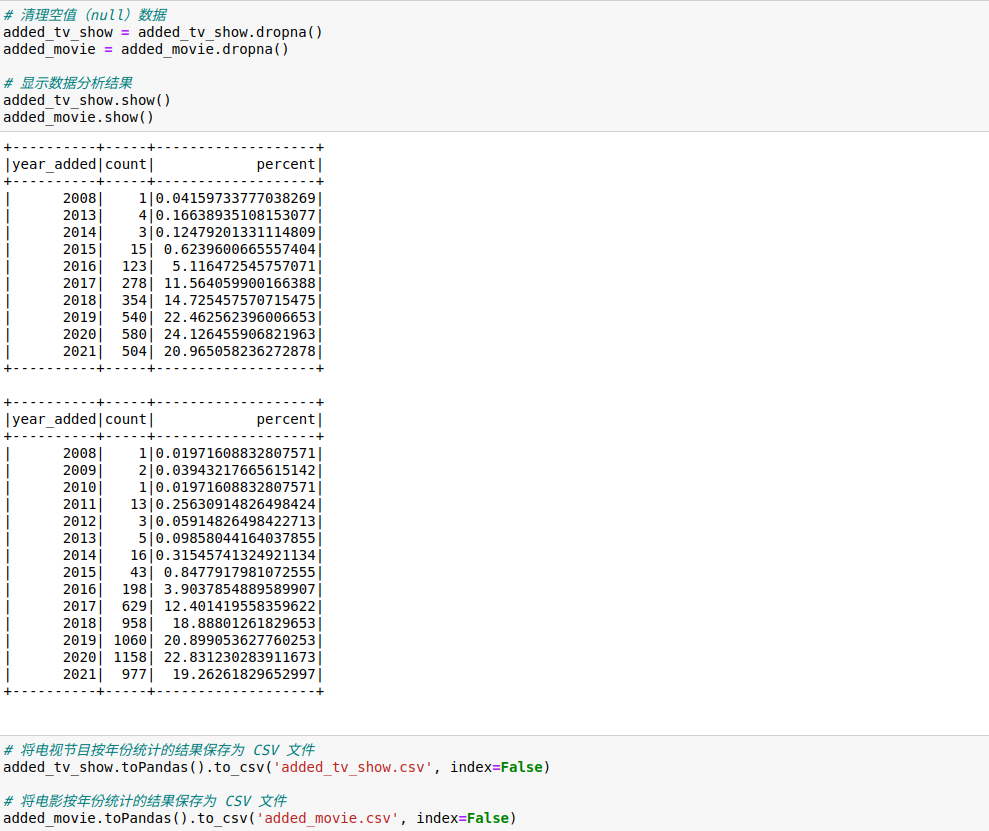
查看数据发现有null值,清楚空值后查看数据,在确认数据无误后,保存到csv文件,以便后面进行可视化。
4.4.按年份统计发布的电视节目和电影数量
按年份统计发布的电视节目和电影的数量,并计算它们在各年份的占比。
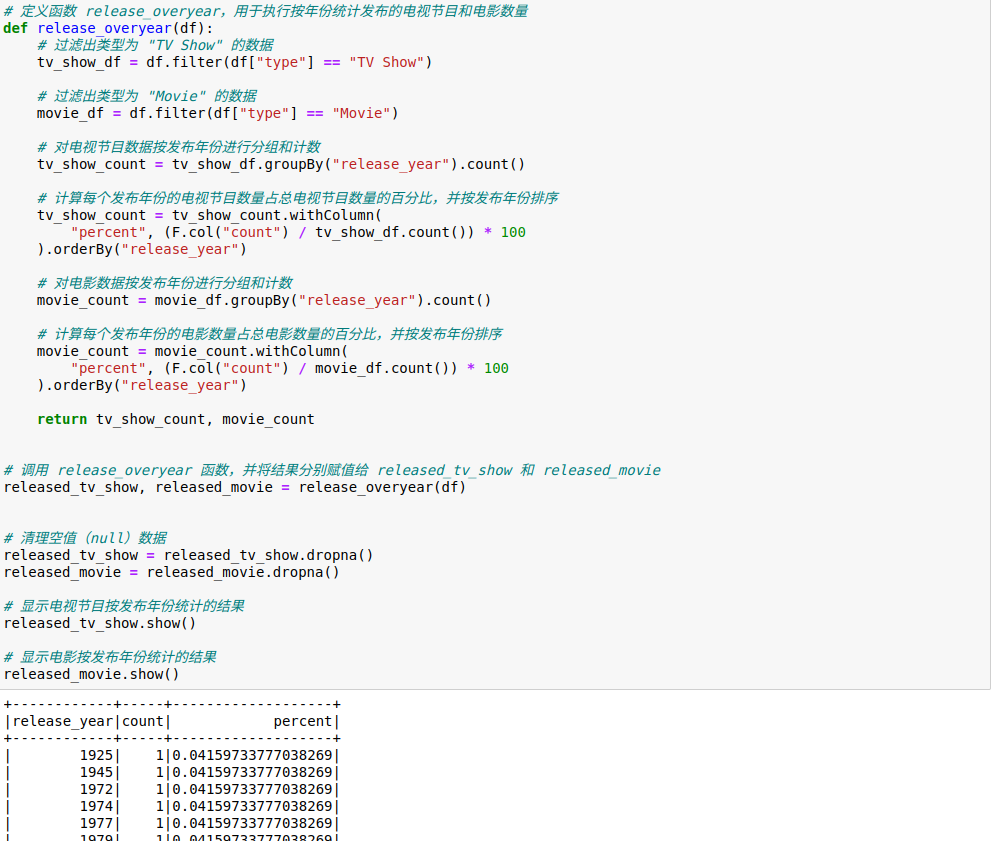
在确认数据无误后,保存到csv文件,以便后面进行可视化。
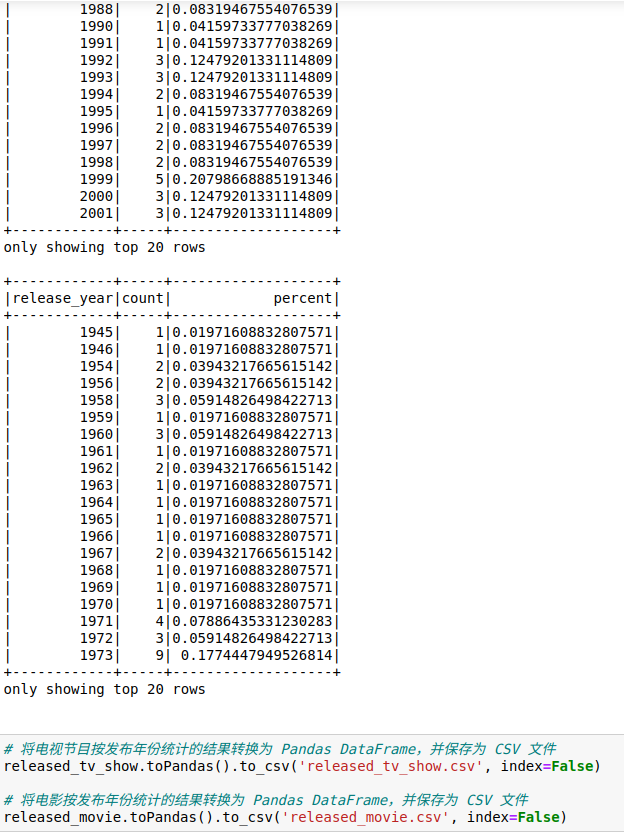
4.5.统计不同国家的影视剧总量
先对country列做数据清理,然后进行分组计数,将包含国家和计数的数据转换为字典形式。然后调用函数返回数据进行查看,在确认数据无误后,保存到csv文件,以便后面进行可视化。
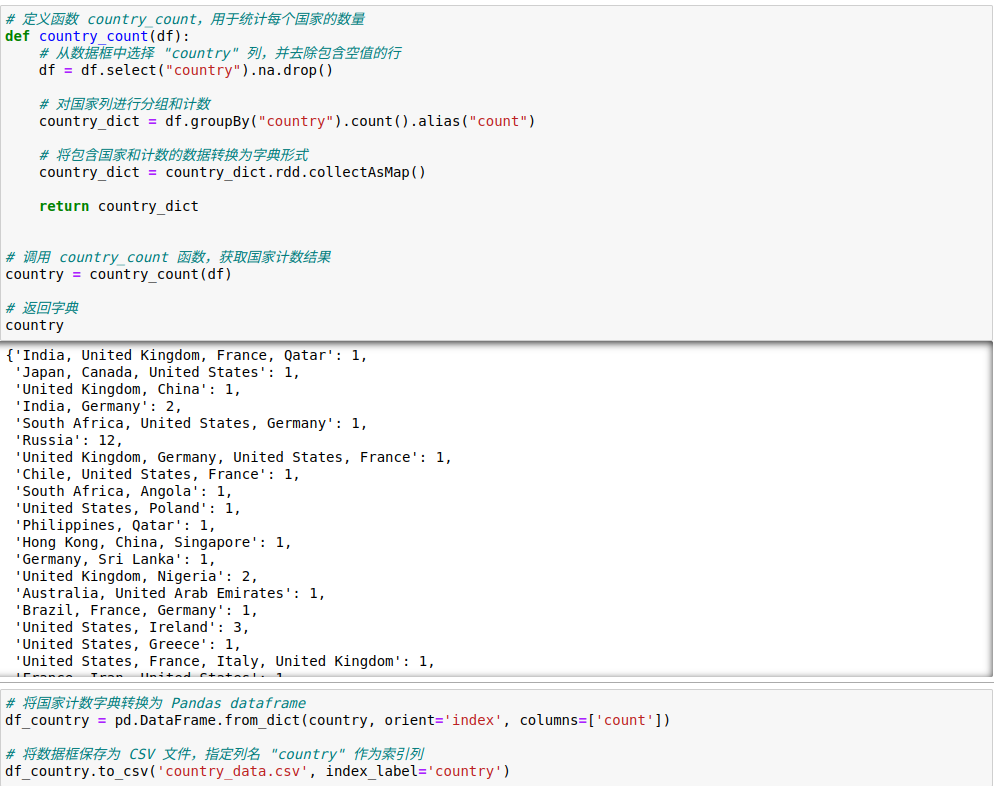
4.6.分析不同国家的电影和电视剧占比
数据分析的思路如下:
1.首先,统计每个国家在数据集中的出现次数,得到一个包含国家和对应出现次数的 DataFrame。
2.然后,根据出现次数,选取出现次数最多的前10个国家。
3.将原始数据与出现次数最多的国家进行内连接,得到一个包含只有出现次数最多的国家的原始数据 DataFrame。
4.统计每个国家中各类型(电影/电视剧)的出现次数,得到一个包含国家、类型和对应出现次数的 DataFrame。
5.使用窗口函数计算每个国家的总出现次数,将总出现次数添加为新的列到 DataFrame 中。
6.计算每个国家中各类型的比例,将比例计算结果添加为新的列到 DataFrame 中。
7.筛选出电影和电视剧类型的数据,去除其他类型的数据。
8.使用透视表将数据按国家进行汇总,并计算各类型的比例总和,缺失值用0填充,得到最终的结果。

调用函数返回数据进行查看,在确认数据无误后,保存到csv文件,以便后面进行可视化。

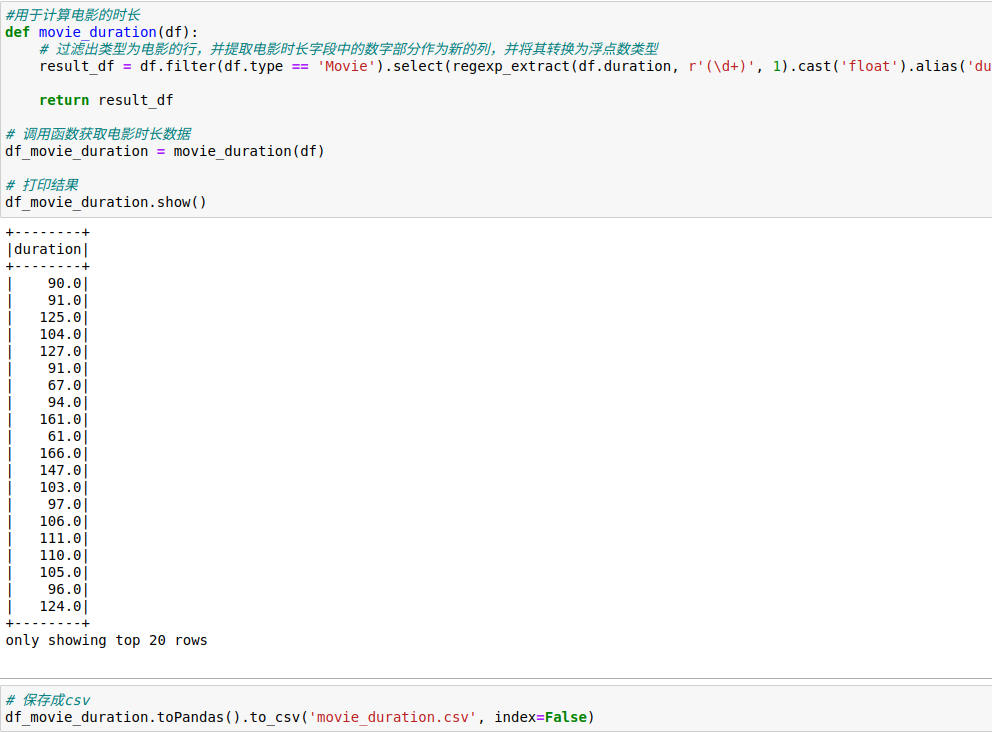
4.7.分析电影时长的分布
数据分析的思路如下:
1.通过筛选出类型为电影的行,使用 filter 方法,保留数据集中电影类型的行。
2.提取电影时长字段中的数字部分,使用正则表达式和 regexp_extract方法,提取匹配的数字部分作为新的列。
3.将提取的数字部分转换为浮点数类型,使用 cast('float') 方法。
4.最终,选择提取和转换后的时长数据作为结果 DataFrame的列,并将其命名为 'duration'。
调用函数返回数据进行查看,在确认数据无误后,保存到csv文件,以便后面进行可视化。
4.8.分析电视剧和电影的评分分布
数据分析的思路如下:
1.根据类型为"TV Show"的行进行分组,并统计每个评分的数量,按评分进行排序,得到 DataFrame vc1。
2.重命名 vc1 中的列名为"index"和"count_tvshow",分别表示评分和对应的数量。
3.使用聚合函数计算"TV Show"的总数量,存储在变量 total_count_tvshow 中。
4.计算"TV Show"每个评分的百分比,将结果存储在新列"percent_tvshow"中,表示每个评分在总数量中的占比。
5.根据类型为"Movie"的行进行分组,并统计每个评分的数量,按评分进行排序,得到 DataFrame vc2。
6.重命名 vc2 中的列名为"index"和"count_movie",分别表示评分和对应的数量。
7.使用聚合函数计算"Movie"的总数量,存储在变量 total_count_movie 中。
8.计算"Movie"每个评分的百分比,将结果存储在新列"percent_movie"中,表示每个评分在总数量中的占比。
返回两个 DataFrame vc1 和 vc2,分别表示"TV Show"和"Movie"的评分分布数据。
调用函数返回数据进行查看,在确认数据无误后,保存到csv文件,以便后面进行可视化。
4.9.分析电影和电视剧的题材分布
数据分析的思路如下:
1.首先,从DataFrame中提取所有的"listed_in"列数据。
2.清理和处理分类数据,包括去除空值、去除空格并按逗号分割。
3.使用Counter函数统计分类的频次,并选取出现频次最高的50个分类,得到一个计数结果的列表counter_list。
4.从counter_list中分别提取标签和计数的列表,分别存储在labels和values中。
5.创建一个包含标签和计数的Pandas DataFrame,命名为categories_pd。
6.将categories_pd作为结果返回。
调用函数返回数据进行查看,在确认数据无误后,保存到csv文件,以便后面进行可视化。
4.10.分析6个国家最受欢迎的电影明星
数据分析的思路如下:
1.首先定义了一个名为top_actors的函数,用于计算每个国家的热门演员数据。该函数接受两个参数:df表示输入的DataFrame,country_name表示要计算的国家名称。
2.在函数内部,通过使用withColumn函数添加一个名为from_country的列,判断电影是否来自所选国家,并将判断结果转换为整数类型。这样可以在DataFrame中添加一个新的列来表示电影是否来自指定国家。
3.接下来,使用filter函数筛选出来自所选国家的电影数据集。条件包括:from_country列的值为1(表示来自指定国家)、duration列不为空、cast列不为"No Data"。
4.从筛选后的数据集中提取演员信息,使用split函数将cast列中的演员信息按逗号分隔,并使用explode函数将每个演员拆分为单独的行。
5.对演员进行分组统计,使用groupBy和count函数按演员进行分组,并计算每个演员出现的频次。然后按频次降序排序,使用orderBy函数。
6.过滤掉演员为空的行,使用filter函数将actor列不为空的行保留下来。
7.将结果转换为Pandas DataFrame,使用limit函数限制结果为前25个演员,并使用toPandas函数将结果转换为Pandas DataFrame。
8.提取演员和频次的数据,存储在labels和values变量中。
9.创建水平柱状图对象actor,使用go.Bar函数创建水平柱状图对象,设置演员为y轴标签,频次为x轴数据,颜色为"#ea97ad"。
10.最后,将水平柱状图对象actor作为函数的返回值。
使用top_actors_titles列表定义要生成水平柱状图的标题列表,包含了多个国家的名称。
然后,通过遍历标题列表,调用top_actors函数生成对应国家的水平柱状图,并将结果存储在actors列表中。
最后,查看前3个水平柱状图数据,即actors[:3],可以得到前3个国家的热门演员数据的水平柱状图对象列表。
调用函数返回数据进行查看,在确认数据无误后,保存到csv文件,以便后面进行可视化。
4.11.分析不同特征列对影视剧分类的效果
数据分析的思路如下:
1.classification函数接受一个DataFrame和特征列列表作为输入。
2.针对每个特征列,首先创建一个StringIndexer来将分类标签转换为数值索引。
3.根据特征列的唯一值数量,决定是否使用OneHotEncoder进行独热编码。如果唯一值数量大于2,则使用OneHotEncoder进行独热编码。
4.创建VectorAssembler将特征列组合为一个特征向量。
5.创建RandomForestClassifier作为分类器。
6.根据特征列的唯一值数量,选择合适的Pipeline阶段。如果唯一值数量大于2,则包含label_indexer、string_indexer、onehot_encoder、assembler和classifier阶段;否则,包含label_indexer、string_indexer、assembler和classifier阶段。
7.将所有的Pipeline添加到pipelines列表中。
8.将数据集随机拆分为训练集和测试集。
9.对于每个特征列,训练模型并对测试集进行预测。
10.使用MulticlassClassificationEvaluator计算预测结果的准确率。
11.将准确率存储在accuracies列表中,并打印出使用不同特征列的准确率。
12.找到最高准确率及其对应的特征列。
13.打印出具有最高准确率的特征列和最高准确率。
14.返回准确率列表和特征列列表。

调用函数返回数据进行查看,在确认数据无误后,保存到csv文件,以便后面进行可视化。

5.数据可视化
5.1.分析电影和电视剧的占比情况可视化

从上述图表可以看出,可以看出电影的占比远大于电视剧。
Netflix电影占比远大于电视剧的原因可能有以下几点:
- 内容采购策略:Netflix可能更倾向于采购和制作电影内容,以吸引更广泛的受众。电影通常是一个相对独立的故事,可以在较短的时间内提供完整的观看体验,适合各种类型的观众。而电视剧通常需要连续的剧集来讲述故事,观众需要更长时间的投入,可能会限制一部分观众的选择。
- 内容消费趋势:观众的消费习惯可能对Netflix的内容供应产生影响。在快节奏的现代社会中,观众可能更倾向于观看电影,因为它们通常可以在相对较短的时间内提供完整的故事,不需要连续追剧。观众可以根据自己的时间安排选择观看电影,而不必担心错过连续剧的情节发展。
- 授权和版权限制:Netflix在获取内容时可能受到一些授权和版权限制的影响。电视剧通常会在各个国家和地区拥有独立的播放权,而且可能与其他电视台或流媒体平台存在竞争。这可能导致Netflix在获取电视剧内容时面临更多的限制和竞争,而电影可能更容易获得独家或全球发行权。
- 观众需求和市场趋势:Netflix可能根据观众需求和市场趋势来决定其内容投入。如果市场上对电影内容的需求更高,或者观众更倾向于观看电影,那么Netflix可能会更加注重电影内容的采购和制作,以满足观众的需求并保持竞争力。
5.2.按年份统计添加的电视节目和电影数量可视化
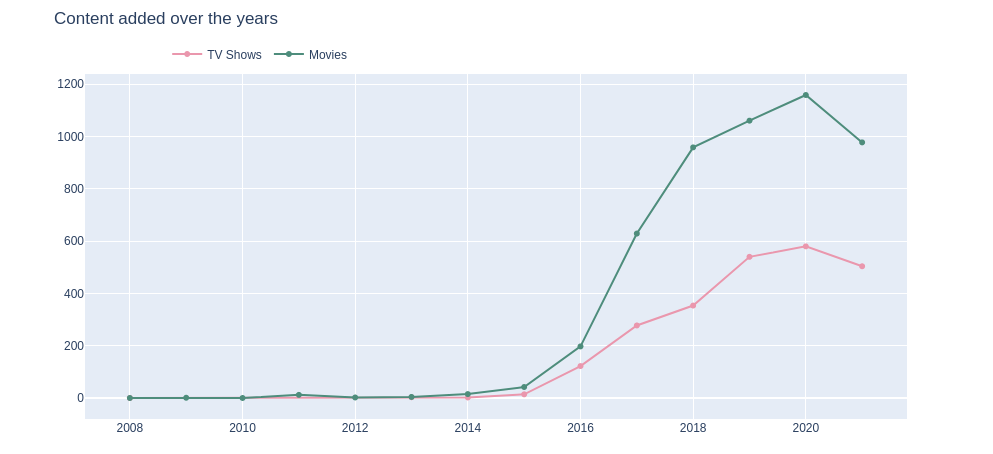
从上述图表可以看出,可以看出从2014年之前,电视剧和电影的添加量是持平的,从2014年开始,电影添加量逐渐超过了电视剧的添加量。
而Netflix的电影添加量逐渐超过电视剧添加量可能是由于观众需求的变化、市场竞争、授权和制作成本以及内容供应商的变化等因素影响。5.3.按年份统计发布的电视节目和电影数量可视化
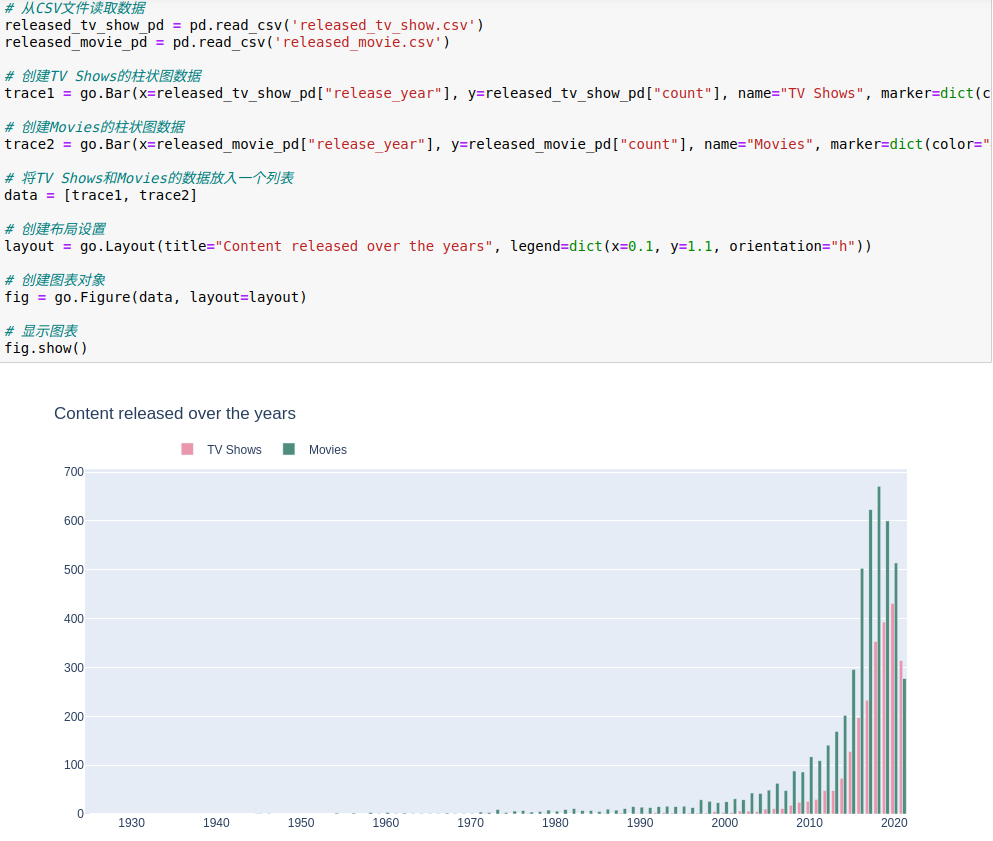
从上述图表可以看出,在2020年前Netflix的电影发布量一直高于电视剧的发布量,且电影发布量和电视剧的发布量都在持续上升,但是在2020年发布量都有一定幅度的下降,同时电影发布量要低于电视剧的发布量。
造成这个影响的原因可能是疫情代来的影响,2020年是全球范围内新冠疫情暴发的年份,许多电影和电视剧的制作和发布受到了限制和延迟。电视剧的制作可能更容易在疫情期间进行,而电影的制作可能受到了更大的影响。5.4.统计不同国家的影视剧总量可视化
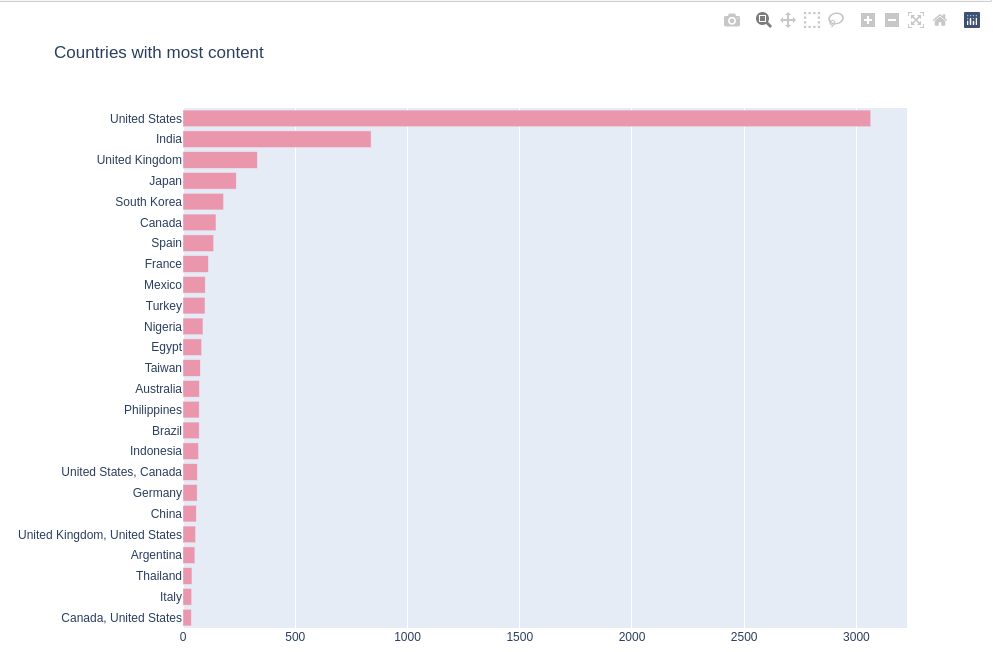
从上述图表可以看出,影视剧数量排名前5的国家分别是美国,印度,英国,日本,韩国,其中美国远远超过其他国家。
这些国家在Netflix影视剧数量排名前五的原因可能是:
1.美国:美国在Netflix影视剧数量排名前5的国家中占据主导地位,可能是因为,美国是Netflix总部所在地,同时还是全球影视产业的重要中心,拥有丰富的电影和电视剧制作资源,以及众多知名的制作公司和电影人才。
2.印度:印度是全球最大的电影产业之一,被称为"Bollywood",其电影和电视剧在印度国内享有广泛的受欢迎程度。Netflix积极扩大在印度市场的影响力,并与当地的制作公司合作,推出了大量的印度原创内容。
3.英国:英国是世界闻名的电影和电视剧制作国家,拥有深厚的电影历史和优秀的创作人才。英国的剧集在全球范围内备受瞩目。
4.日本:日本拥有独特而多样化的电影和动漫文化,其电影和电视剧作品在全球范围内有着广泛的影响力。
韩国:韩国的影视剧,尤其是韩剧,在全球范围内享有巨大的受欢迎程度,其独特的叙事和情感表达方式吸引了观众的关注。
5.5.分析不同国家的电影和电视剧占比可视化

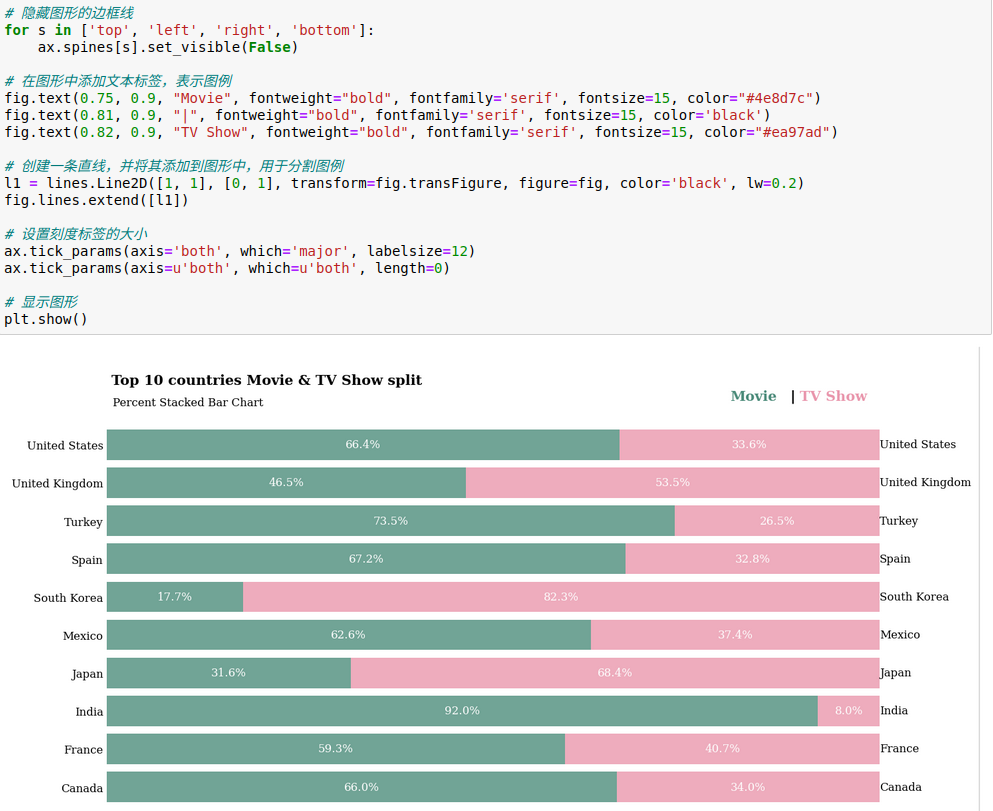
从上述图表可以看出,可以观察到以下趋势,并猜测造成其特点的原因
1.印度的电影比例最高(约为92%),而电视剧比例相对较低(约为8%)。这可能是因为印度电影产业庞大且历史悠久,导致大量电影供Netflix收录。此外,印度观众可能更倾向于观看电影而非电视剧。
2.韩国的电视剧比例最高(约为82%),电影比例相对较低(约为18%)。这可能与韩国的电视剧在全球范围内的流行有关。韩剧在许多国家具有广泛的吸引力,为Netflix带来了大量观众。
3.日本的电视剧比例也相对较高(约为68%),而电影比例约为32%。这可能与日本的动画产业在全球的影响力有关。日本动画往往是连载形式的电视剧,为Netflix带来了观众。
4.法国、加拿大、墨西哥和西班牙的电影比例相对较高(分别约为59%、66%、63%和67%)。这可能表明这些国家在电影产业方面具有相对较强的影响力。虽然各国的电影产量不同,但这些电影在Netflix上的收录比例相对较高。
5.英国和美国的电影和电视剧比例较为接近。对于英国,电视剧比例略高于电影(约为53%与47%)。而对于美国,电影比例略高于电视剧(约为66%与34%)。这可能反映了这两个国家在电影和电视剧产业方面均具有很强的影响力。
根据这些趋势,我们可以得出结论,不同国家的观众可能对电影和电视剧有着不同的喜好。对于印度和韩国等国家,其文化和产业特点在很大程度上决定了他们在Netflix上的内容比例。同时,这也反映了Netflix在全球范围内的内容策略,即提供广泛多样的电影和电视剧内容以吸引全球观众。
5.6.分析电影时长的分布可视化
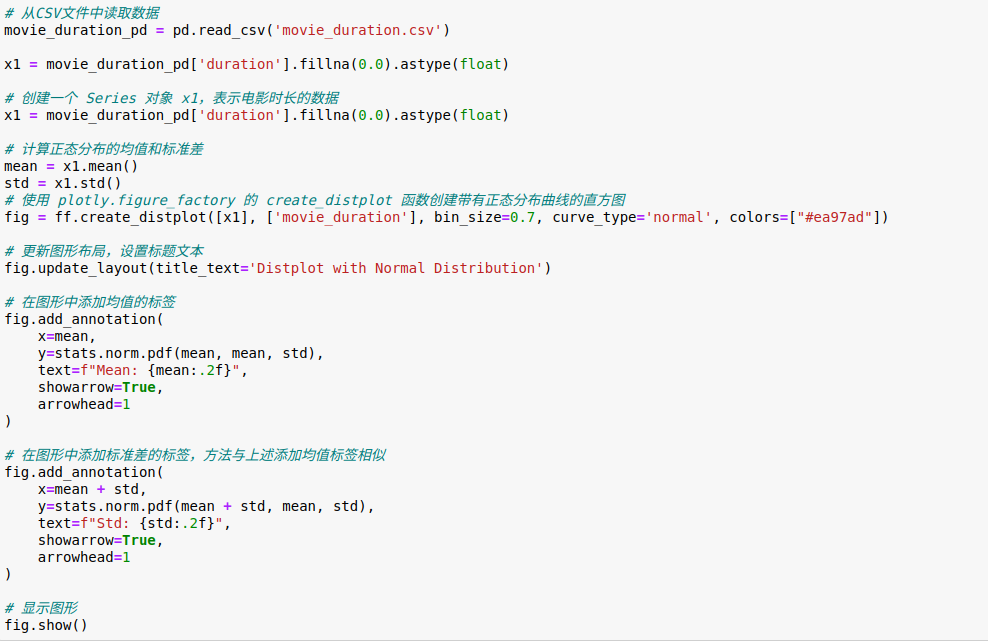
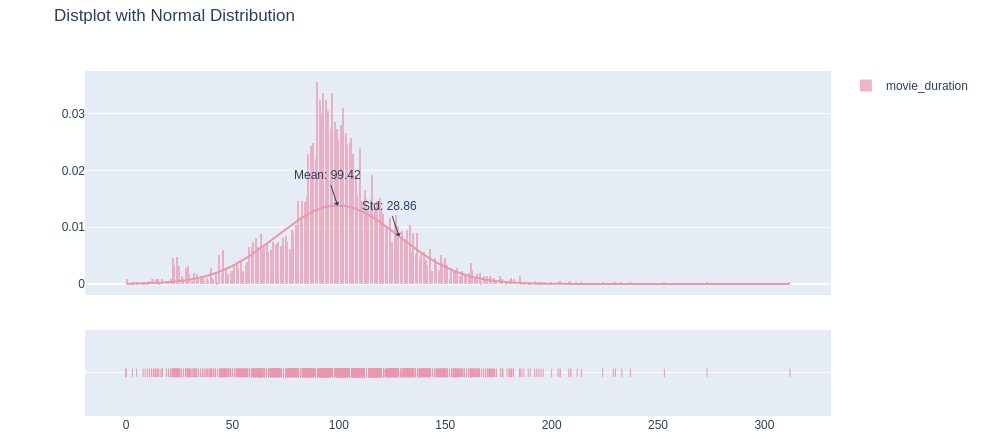
从上述图表可以看出,电影时长的均值为99.42分钟,标准差为28.86分钟,表明电影时长变化范围比较大,有些电影的时长可能明显偏离均值。影响电影时长分布的因素有多种,首先是电影制作的多种因素,例如故事情节、演员表演和特效等等,所以不同类型电影的平均时长和标准差可能会不同。
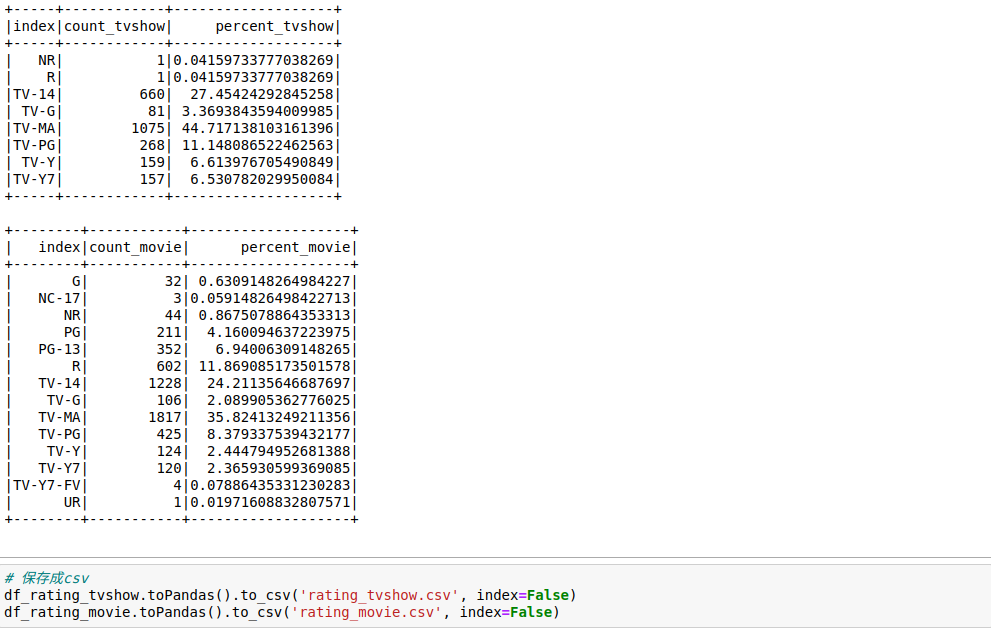
5.7.分析电视剧和电影的评级分布可视化
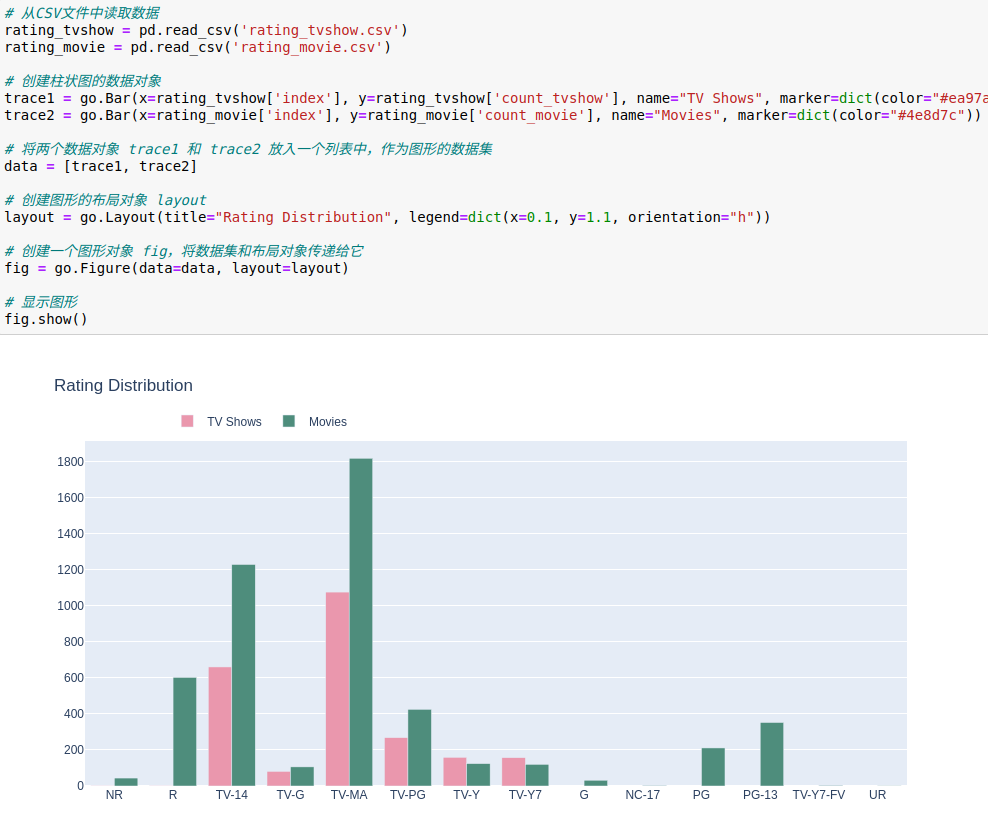
从上述图表可以看出,电视剧和电影的评级分布有以下特点
电视剧特点:
1.最常见的等级是"TV-MA",占比约为44.7%。"TV-MA"等级意味着只适合成年观众。
2.其他常见的等级包括"TV-14"(占比约为27.5%)和"TV-PG"(占比约为11.1%)。
3.较少见的等级包括"TV-Y7"、"TV-Y"、"TV-G"等,占比较低。
电影特点:
1.最常见的等级是"TV-MA",占比约为35.8%。与电视剧相同,"TV-MA"等级的电影也适合成年观众。
2.其他常见的等级包括"TV-14"(占比约为24.2%)和"R"(占比约为11.9%)。
3.较少见的等级包括"PG-13"、"TV-PG"、"PG"等,占比较低。
根据以上特点,可以猜测造成这些特点的原因可能有以下几个方面:
1.目标受众群体:Netflix可能针对不同年龄段和观众群体推出不同等级的内容。"TV-MA"等级的电视剧和电影可能是为了满足成年观众的需求,而"TV-14"等级可能是为了吸引青少年观众。
2.剧情类型和题材:某些类型的剧集和电影可能更适合于成人观众,因此更倾向于被分为"TV-MA"等级。同时,Netflix可能也有一些面向家庭观众的内容,如"TV-G"和"TV-Y"等级的电视剧和电影。
3.目标市场和受众口味:Netflix的目标市场和主要受众可能在成年观众中占据较大比例,因此更多地推出了"TV-MA"等级的内容来满足需求。
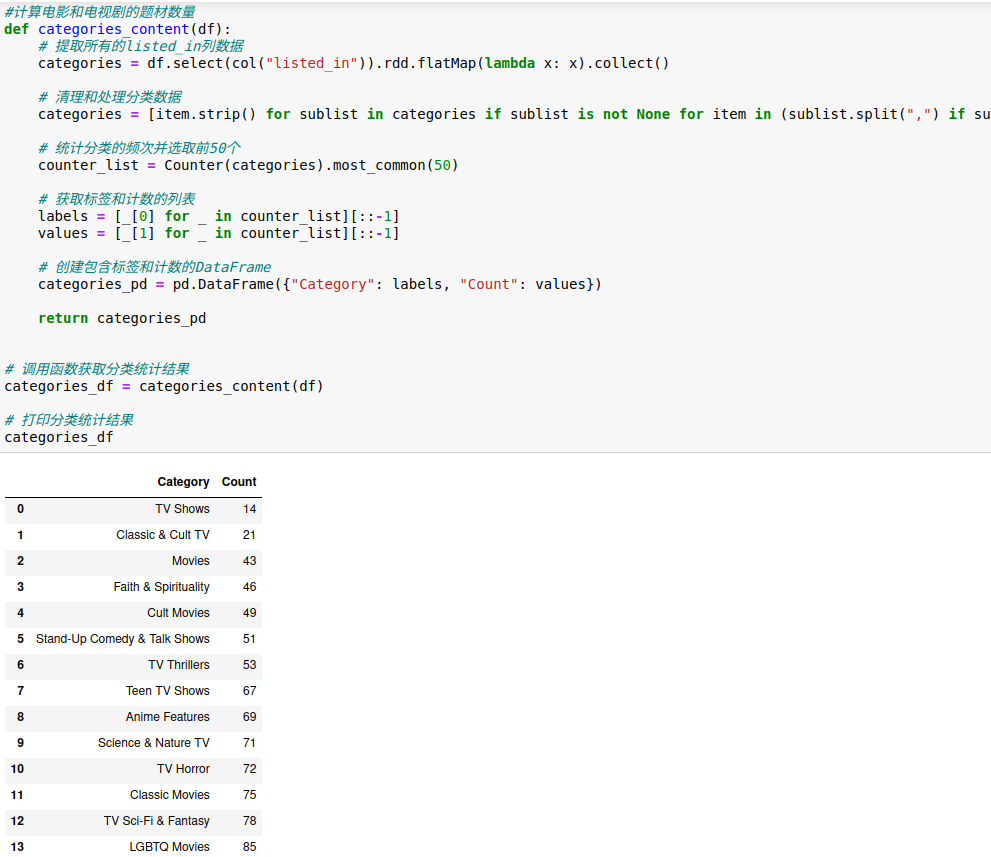
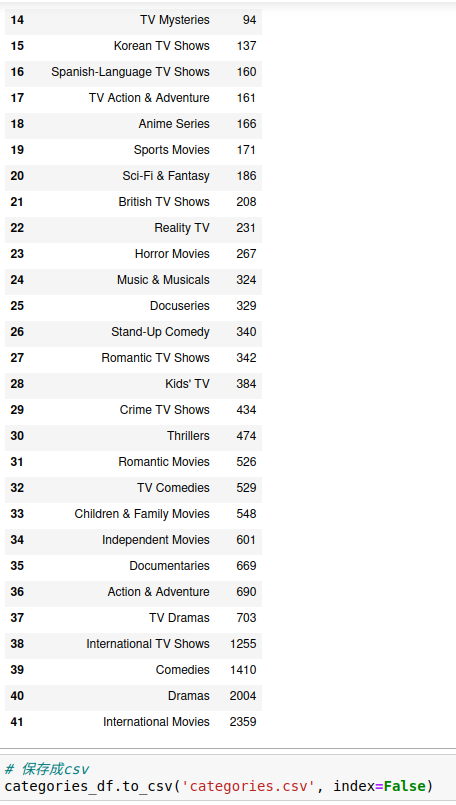
5.8.分析电影和电视剧的题材分布可视化

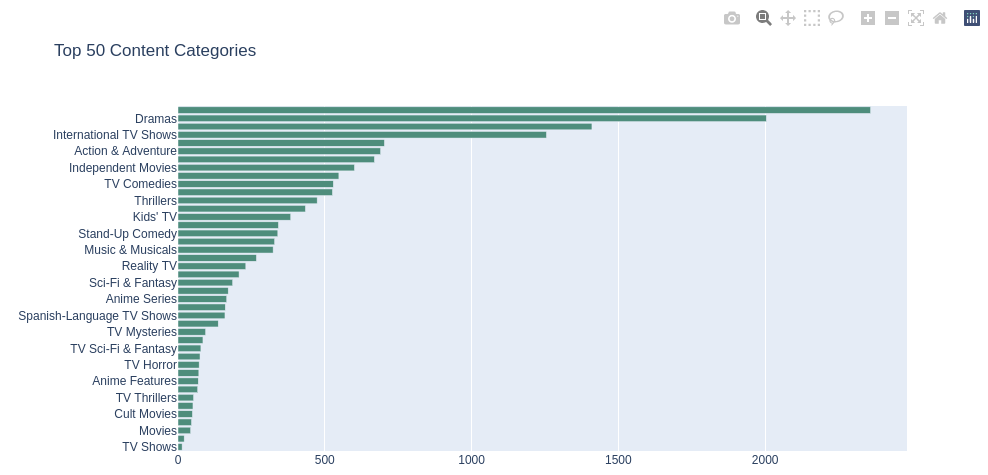
从上述图表可以看出,电影和电视剧的题材分布有以下特点:
1.影视剧题材种类众多:Netflix 提供了广泛的影视剧题材,涵盖了各种类型的内容,包括电视剧、电影、纪录片、喜剧、动作冒险、科幻奇幻等。
2.数量排名前三的影视剧题材分别"Dramas"(剧情片)2004部,"International TV Shows"(国际电视剧)1255部,"Action & Adventure"(动作冒险片)690部
造成这些特点的原因可能是:
1.多样化:Netflix 是一家全球性的流媒体平台,为了迎合不同国家和地区的观众口味和文化偏好,Netflix 加大了对国际影视剧的投资和推广,使得影视剧题材呈现出多样性和国际化特点。
2.剧情片:通常涵盖了各种情感、人生故事和人物角色的发展,能够吸引观众的关注和共鸣。
3.国际电视剧:Netflix 在全球范围内推广本地化内容的努力,以吸引不同地区观众的关注,并满足他们对本土和国际电视剧的喜爱
4.动作冒险片:这类影视剧通常包含了精彩的动作场面、刺激的冒险情节和紧张的剧情发展,在观众中很受欢迎。
5.9.分析6个国家最受欢迎的电影明星可视化


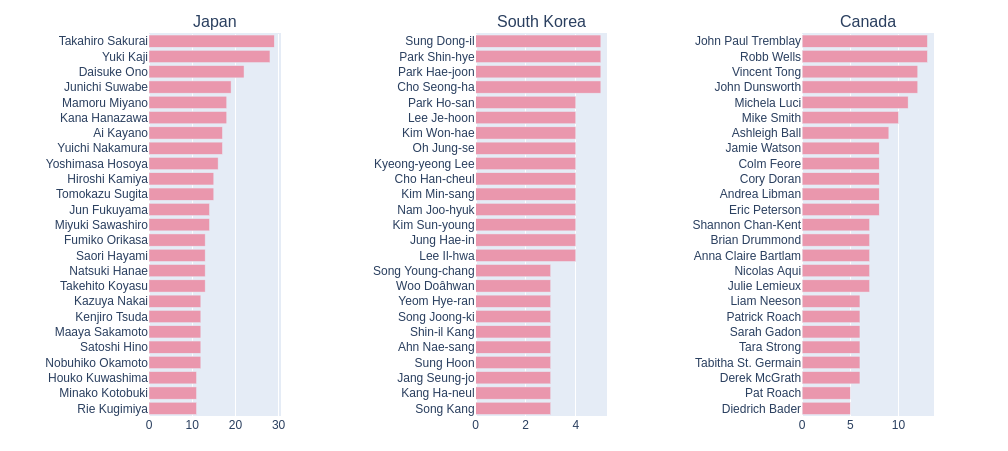
从上述图表可以看出,6个国家最受欢迎的电影明星分布有以下特点
1.明星的差异性:不同国家的最受欢迎明星存在一定的差异。每个国家的排名中出现了一些独特的明星,说明不同国家的观众对明星的喜好有所差异。
2.地域偏好:可以观察到在不同国家的明星排名中,有些明星在特定的地区更受欢迎。例如,在第一个国家的数据中,Mike Epps、Kristen Stewart和Maya Rudolph位居前三,而在第二个国家的数据中,Manoj Bajpayee、Priyanka Chopra和Sanjay Dutt排名前三。这可能反映了地域偏好和文化差异对明星的影响。
3.多样性:在每个国家的明星排名中,涵盖了不同类型和领域的明星,包括电影演员、配音演员和电视演员。这显示出Netflix受众的多样性和对不同类型明星的兴趣。
这些特点的原因可能是观众的个人偏好、地域文化影响、推广活动以及Netflix平台上不同类型内容的推荐和曝光程度等因素的综合作用。
5.10.分析不同特征列对影视剧分类的效果可视化

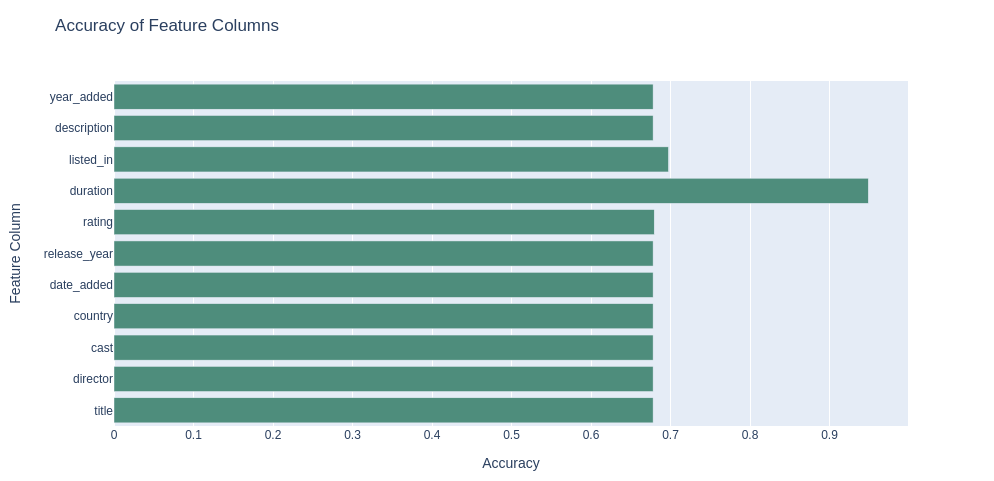
从上述图表可以看出,可以看出多个特征列的准确率相同(约为0.678),其中只有'rating'列的准确率稍高(0.6795),而'duration'列的准确率最高(0.9488)。多个特征列的准确率相同可能是因为它们的信息量相似或相关性较低。这可能意味着在进行分类预测时,这些特征列对结果的影响相对较小。'rating'列略微高于其他特征列的准确率可能是因为该特征对于分类任务有一定的预测能力。可能是因为'rating'反映了内容的受众群体,不同的受众群体可能对电影和电视剧的喜好程度不同。'duration'列具有最高的准确率,这意味着影片的时长可能对分类任务的预测起着重要作用。