
【版权声明】版权所有,严禁转载,严禁用于商业用途,侵权必究。
作者:厦门大学信息学院2022级研究生 张金璐
指导老师:厦门大学数据库实验室 林子雨 博士/副教授
相关教材:林子雨、郑海山、赖永炫编著《Spark编程基础(Python版)》(访问教材官网)
相关案例:基于Python语言的Spark数据处理分析案例集锦(PySpark)
一、实验目的
Bilibili(简称b站) 是中国年轻人高度聚集的文化社区和视频平台,人们可以通过弹幕、评论、点赞或收藏等方式来与视频发布者(称为up主)来进行互动。《每周必看》是b站的一个栏目, b站会对新一周发布的视频根据不同条件进行筛选,将热门的、有趣的、有价值的视频收录在该栏目中推荐给用户观看。这次实验中,希望对被收录在b站《每周必看》视频与up主的数据信息进行研究,通过运用大数据处理框架 Spark、Hadoop 及数据可视化技术,对这些数据进行存储、处理和分析,并对每个收录视频能否进入热搜榜前10进行分类。具体来说本次作业实现功能如下:
(1)采用爬虫技术,编写代码收集截止至5月20日b站所有《每周必看》栏目的数据;
(2)对原始数据进行清洗,包括有价值字段的选择、异常数据的删除以及文本数据的修正等,最后数据保存为txt文件并上传至HDFS;
(3)使用spark sql组件对HDFS的数据进行分析,主要统计各收录视频的基本播放情况以及up主的累计数据;
(4)使用spark MLlib组件对HDFS的数据进行分析,研究视频点赞数、播放量、互动热度等之间的关系,并训练机器学习模型对视频能否进入热搜榜前十进行分类;
(5)使用pyecharts工具对分析结果进行可视化。
二、实验环境
本次实验在Linux虚拟机中用Pycharm平台python语言实现,主要环境如下,点击链接可跳转至相应安装教程,其他需要的第三方库及对应版本可见requirement.txt:
(1)Linux: Ubuntu 22.04.2 LTS amd64
(2)Python: 3.8.16
(3)Hadoop: 3.1.3
(4)Spark: 3.2.0
(5)Anaconda: 4.10.1
三、操作流程
1、数据集收集
爬虫代码在bilibili_week.py文件中,可在Pycharm中直接执行。b站提供了API接口以便开发者获得每一期《每周必看》的视频数据(https://api.bilibili.com/x/web-interface/popular/series/one?number={},花括号内填入要收集数据的期数),直接使用requests库发送请求并将得到的响应进行保存即可,在发送请求时还添加了headers将其伪装为浏览器访问。
但是重复使用相同的user-agent很容易被网站识别为爬虫程序,借助python中fake_useragent第三方模块,在每一次发送请求时随机使用一个UA,并且设置retry让每一次的代码等到成功运行当前数据的爬虫后才能进行下一步操作。爬取后的数据直接转为json格式并保存下来,最终的爬虫主要代码如下:
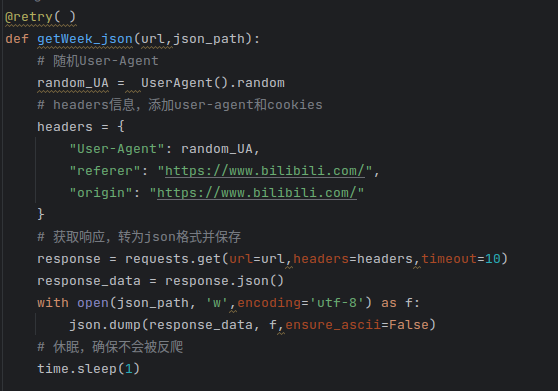
B站截止至2023年5月19日一共有217期《每周必看》,因此设置共爬取217期,爬取的所有json文件都保存至当前目录的./data目录下。
可以点击这里从百度网盘下载爬取到的B站数据集和本案例的所有代码。
2、数据预处理
数据预处理阶段包括了有效数据的选择、异常数据与空白数据的处理、文本数据的处理,这一步的代码在data_preprocess.py中,可在Pycharm中直接执行。。
(1)数据选择:打开上一步爬虫得到的其中一个json数据文件,借助菜鸟工具提供的json格式化工具,查看爬取到的数据格式,返回的信息包含在data中:
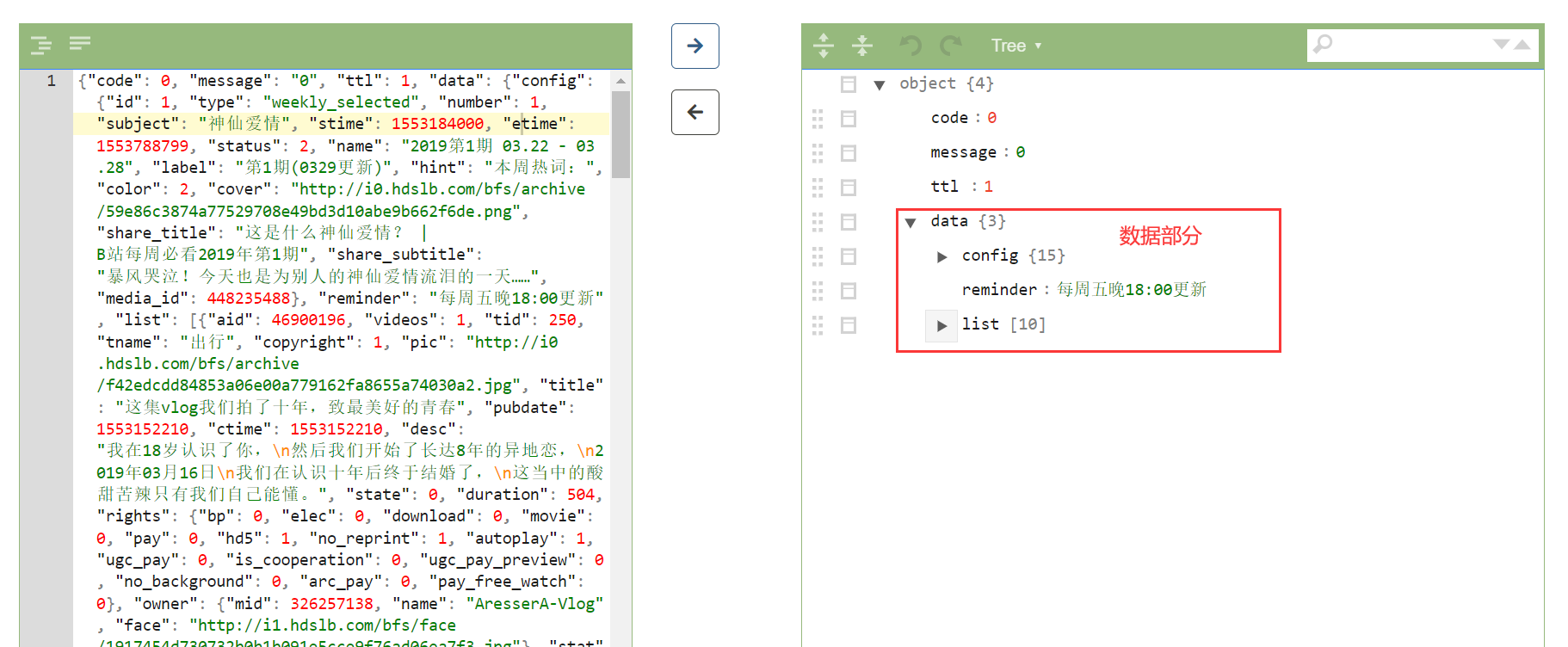
data包括3个部分的信息,其中config包括这一期视频栏目的整体信息,包括期数、时间、封面视屏内容等,其中config.name记录每一个视频的所属期数。

list则是这一期栏目每一个收录视频的具体情况,包括视频的标题、描述以及推荐理由:
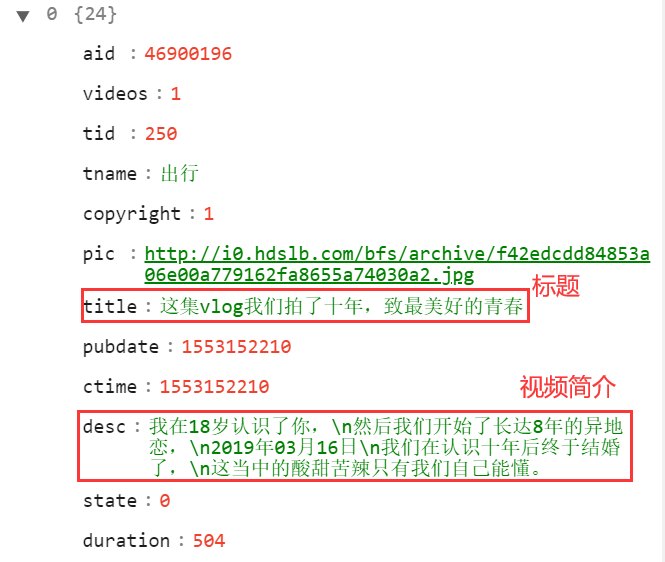

发布者的信息则包含在元素的owner部分:
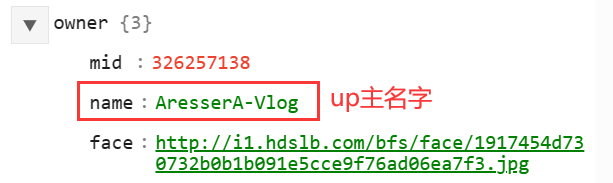
视频的观看次数、弹幕数、转发数等则包含在stat中:

除了这些信息,其余数据在本项目中无意义,因此对单个json文件,选取上述几个字段,将有用的信息保存在dataframe:
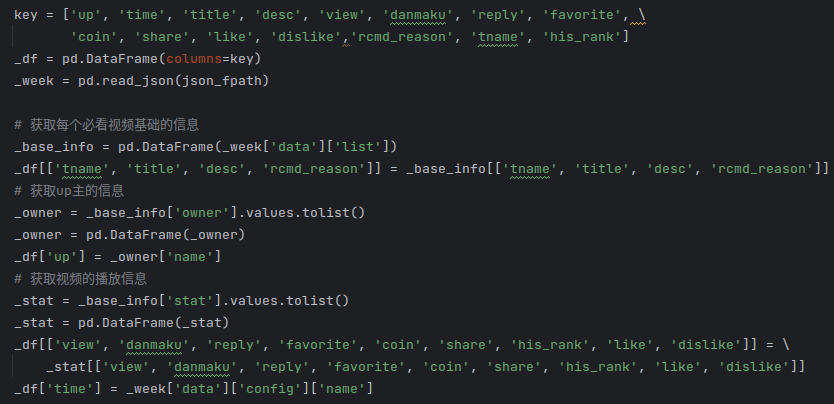
(2)异常数据的处理:
首先删除包含空值和重复的数据,其中当up主名字和视频标题相同视为重复;认为观看数view、弹幕数danmaku、评论数reply、收藏数favorite、投币数coin、分享次数share、点赞人数like、历史排名his_rank小于或等于0,不喜欢的人数dislike超过0的数据为异常数据,一并删除。上述数据删除之后,dislike字段也无意义,同样删除。这一步骤的代码如下:

(3)文本数据的处理:
入选栏目的某些视频描述desc和推荐理由rcmd_reason为空,使用视频的标题对其进行填充,并且为了最后数据保存的规范性,对一些特殊符号例如换行符、Tab等进行处理:


(4)数据合并与上传
对每一个文件重复进行上述操作,并不断合并得到的dataframe,最后将数据去除表头,保存为文本文件,命名bilibili_week.txt:

在Linux 终端输入./bin/hdfs dfs -put /home/Hadoop/PycharmProjects/BigData/bilibili_week.txt /user/hadoop,将该文件上传至HDFS,通过ls命令和网页浏览,可以验证数据成功上传:


至此,数据清洗完成。
3、数据分析
进行数据分析前,需要将HDFS上的数据加载成RDD,然后再由RDD转为Dataframe。这一步的实现步骤为:①创建SparkSession和SparkContext对象,并用textFile函数读取HDFS上的文本数据,并将其存储为RDD;
②用map函数对RDD的每个元素进行切割并转化为包含多个字段的Row对象;
③定义数据集的结构schema,为Dataframe建立表头,将RDD转化为一个Dataframe。
④在使用sql组件的时候还需要将DataFrame注册为Spark SQL中的临时视图。
以上操作对应的代码如下:

(1)基于spark sql组件的分析
这一部分的代码都在data_analysize1.py文件中,通过spark-submit data_analysize1.py 执行代码。
①统计视频收录次数最多的up主
b站up主的名字不可以重复,因此每个up主由字段’up’唯一标识,数据中up主视频被收录的总次数为count(up),要求得到的结果根据名字up分组并按照入选的次数降序排序,筛选出10个视频入选次数最多的up,得到的popular_up为spark.DataFrame类型,再使用toPandas将其转为pandas.Dataframe并通过to_csv函数把结果保存在csv文件中。这一过程的代码如下:

②统计入选次数最多的视频分类
与①类似,tname表示入选视频的视频分区,count(tname)表示属于该种分区视频的收录次数,要求得到的结果根据tname分组并按照入选的次数降序排序,筛选出10个收录次数最多的视频分区,得到的popular_subject用toPandas将其转为pandas.Dataframe并通过to_csv函数把结果保存在csv文件中。这一过程代码如下:

③播放量数据统计
对于视频播放量的统计,选取视频标题title和播放量view的字段,对查询结果按照view字段进行降序排序并筛选播放量最多的10个视频,将其转为Pandas.dataframe并保存在csv文件中,对应代码如下:

对于up主所有收录视频的累计播放量统计,选取up主名字up并计算每个up主的总播放量sum(view),对查询结果按照up的名称进行分组,并按照总播放量sum(view)降序排序并筛选总次数最多的10个up主名字,查询结果同样通过toPandas()和to_csv()保存在csv文件中,代码如下:

弹幕数、视频回复量、收藏次数、投币数、分享次数和点赞次数最多的前10个视频和up主的数据统计与上述操作类似,只需要修改sql语句中select相应的字段,这里就不再展开。
④词频统计
为了研究标题、视频简介、推荐理由等常用词,需要进行词频统计,以视频标题分析为例,对视频标题的词频分析步骤如下:

上面的代码首先通过sql语句查询data视图中的title字段,返回一个DataFrame对象,然后通过rdd.flatMap(lambda line: pretty_cut(line['title']))将DataFrame转换为RDD,并且RDD的title字段通过pretty_cut进行分词,并将结果展平为一个新的RDD。其中pretty_cut的代码如下,该函数使用jieba对每个中文语句进行分词,并去除停用词:
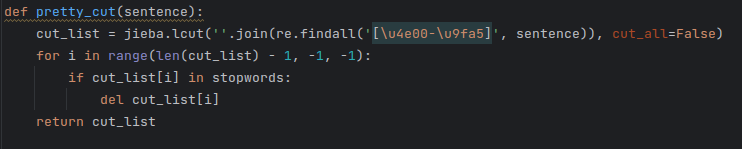
每一行数据分词之后,再通过map(lambda word: (word, 1)) 将每个词映射为一个键值对,key是单词,1表示单词出现的次数是1,reduceByKey(lambda a, b: a + b)则对RDD中的每个键值对进行聚合,将相同键的值相加,得到每个单词出现的总次数。repartition将RDD的分区数设置为1, sortBy会按照每个单词出现的次数进行降序排序,得到出现频率最高的单词。
简单起见,在将RDD转为Dataframe后,只选取词频前300且不为空的词语,最后保存为csv文件:

视频简介、入选推荐理由的文本数据分析操作同上,这里也不再展开。
最后main函数依次执行上述的函数,得到的结果保存在static文件中:

(2)基于spark MLlib组件的分析
这一部分的代码都在data_analysize2.py文件中,通过spark-submit data_analysize2.py 执行代码。
①数据处理
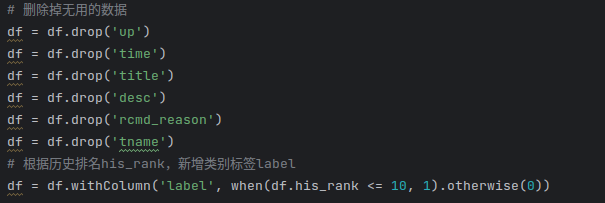
读取到HDFS数据之后,选择其中几组字段:['view','danmaku','reply','favorite','coin','share','like']进行分析,研究这几组变量与当周历史排名his_rank之间的关系。通常情况下人们比较关心热搜榜前10的数据,因此将数据划分为两类并新增label标签:1说明该条视频曾经进入b站热搜榜前10,0说明该视频不曾进入热搜榜前十。数据筛选和新增对应代码如下:
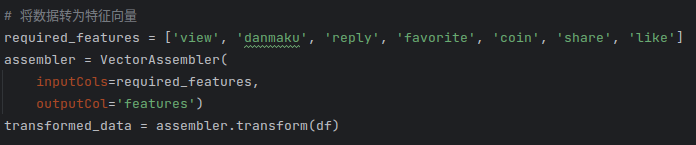
为了方便后续使用机器学习模型进行训练和验证,使用VectorAssembler类将数据转化为特征向量:
最后对数据按照8:2划分训练集和验证集:

此时训练集与验证集的样本数为:

②变量的相关性
使用pyspark.ml.stat中的Correlation,计算特征之间的斯皮尔曼系数,并将结果保存在csv文件中:

③分类器的训练
根据['view','danmaku','reply','favorite','coin','share','like']和label标签,训练分类器,让分类器根据视频的播放量、评论数等判断它是否可以进入热搜榜前10。pyspark.ml.classification提供多种封装好的分类模型,在这次实验中选择逻辑回归、决策树、随机森林和GBT进行实验。
以逻辑回归分类器为例,首先定义分类器:设置标签列为label,特征列为features,并且逻辑回归最大迭代15次。

使用训练集进行训练后,对验证集进行测试:

为了研究分类器的性能,使用MulticlassClassificationEvaluator统计模型在验证集上的分类正确率,使用BinaryClassificationEvaluator得到模型二分类的auc。这两个数值越高,说明模型性能越好。

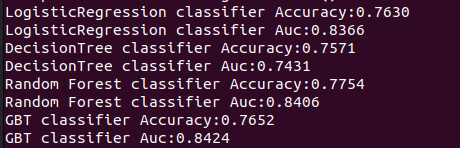
其余三种分类器(决策树算法、随机森林算法和GBT)的训练与验证过程和上述操作类似,这里不再赘述。这四种分类器依次训练:各自正确率和AUC的结果如下,该数据也会保存在csv文件中:
4、可视化
Pyecharts是一款将python与echarts结合的数据可视化工具,本项目使用pyecharts来对第3步得到的分析结果进行可视化,代码均在echarts_show.py中,可在Pycharm中直接执行。(1)播放量最多的数据可视化
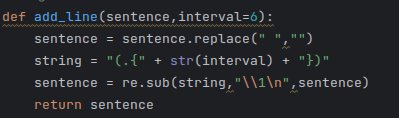
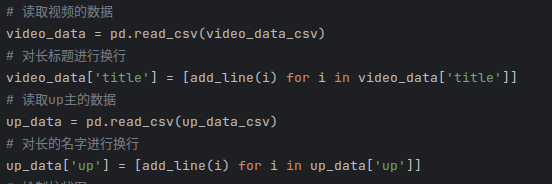
首先分别从存放视频播放量次数和up总播放次数的两个csv文件中读取数据,为了最后布局的美观,对每一行字数较多的文本中使用add_line函数插入一些换行符:
接着对视频和up主数据分别绘制柱状图,其中Bar()表示用柱状图可视化数据,add_xaxis设置横坐标,add_yaxis设置纵坐标,set_global_opts设置例如标题、字体大小等的全局变量:


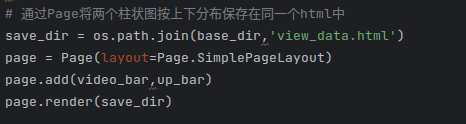
最后通过Page()类将两个柱状图按照上下排列的顺序布局在同一个页面中,渲染成html文件:
有关投币数、弹幕数、收藏数、点赞数、回复数的数据可视化流程如上,最终可视化结果会保存在各自的html文件中:
(2)收录次数可视化
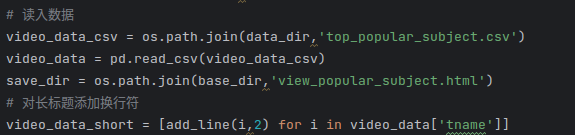
对收录进《每周必看》栏目次数最多的视频分区主题分布进行可视化,首先从csv文件中读入数据,同样对长标题添加换行符:
按照每种分区的收录次数,绘制柱状图:
根据分区收录的次数,绘制富文本饼图:
最后通过Grid()类将两个柱状图按照左右排列的顺序布局在同一个页面中,渲染成html文件:

有关收录次数最多的up主数据可视化流程同上,各自的结果都保留在html目录:

(3)词频信息可视化
从csv文件中读出标题的词频信息,并将结果转为list,方便后续的处理:

使用pyecharts提供的WordCloud类绘制词云图:

视频简介与推荐理由的操作类似,最后得到的三个词云再通过Page()类,按照上中下的顺序布局在同一个页面中,渲染成html文件:

(4) 机器学习库分析结果可视化
变量之间的相关性可通过热力图来呈现,首先从csv文件中读取相关矩阵:
把数据处理为列表格式,列表中每一个元素[i,j,value]表示变量i与变量j之间的相关性为value:

绘制热力图:

而分类器的性能对比可通过双柱状图来表示,同样,首先从csv文件中读取各个分类器的性能,并对分类器的名称与Acc、Auc进行操作,确保可视化结果的美观:

绘制双柱状图,通过两次add_yaxis将Acc与Auc的数据添加到图上:
最后再通过Page()类将两个结果按照上下的顺序布局,渲染成html文件:

main函数依次执行上述操作,所有html文件均保存在/html目录中,代码如下:
最后,为了方便可视化结果的查看,在/html目录下编写index.html文件,通过按键超链接,设置不同可视化结果的跳转,index.html的主要代码如下:

四、可视化结果
1、打开工程目录下/html/index.html的页面如下, 点击文字,既可实现各个页面的跳转:

2、投币数据可视化


视频《回村三天,二舅治好了我的精神内耗》得到的硬币数量最多,up主老番茄得到的总投币量最多。
3、弹幕数据可视化
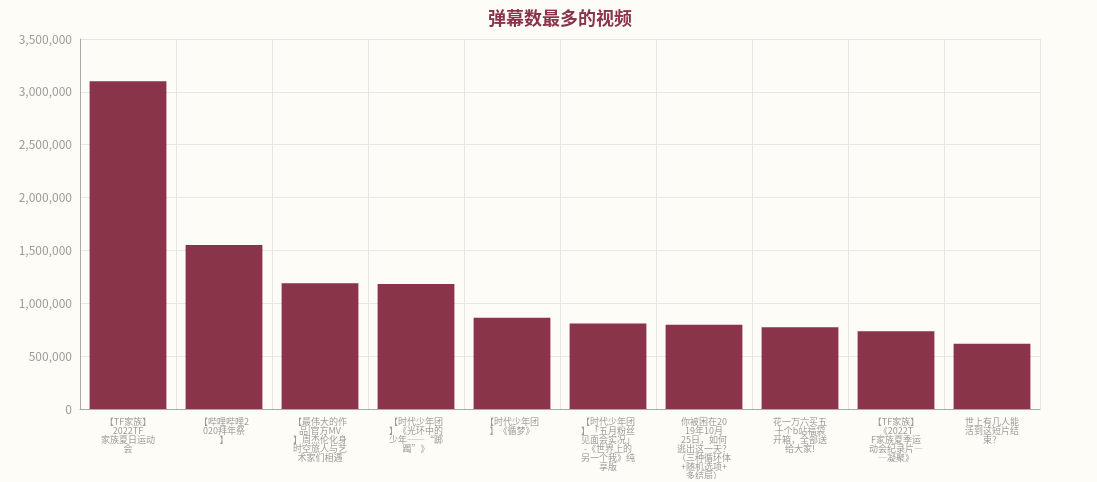

在弹幕数据中,《【TF家族】2022TF家族夏日运动会》以及up主TF家族发布的视频有最多的弹幕。
4、收藏数据可视化
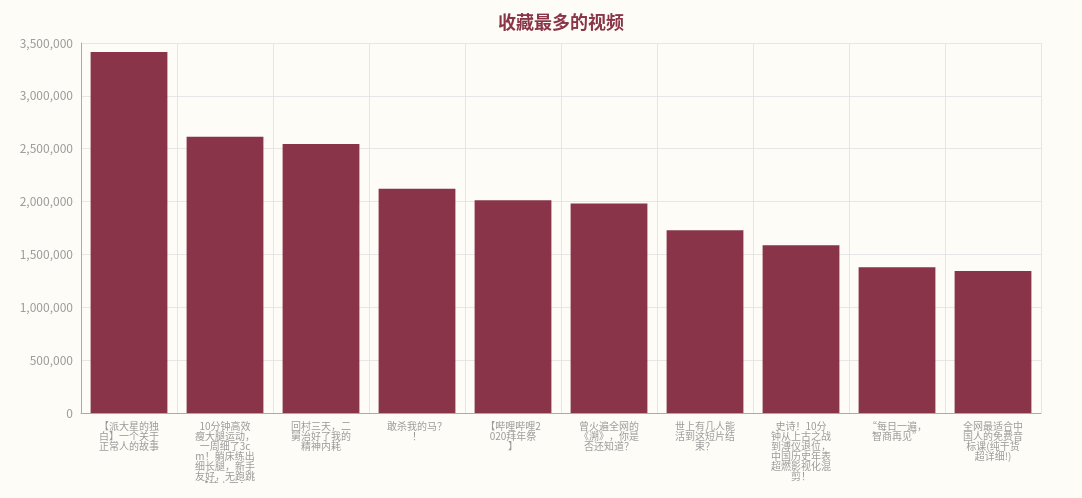
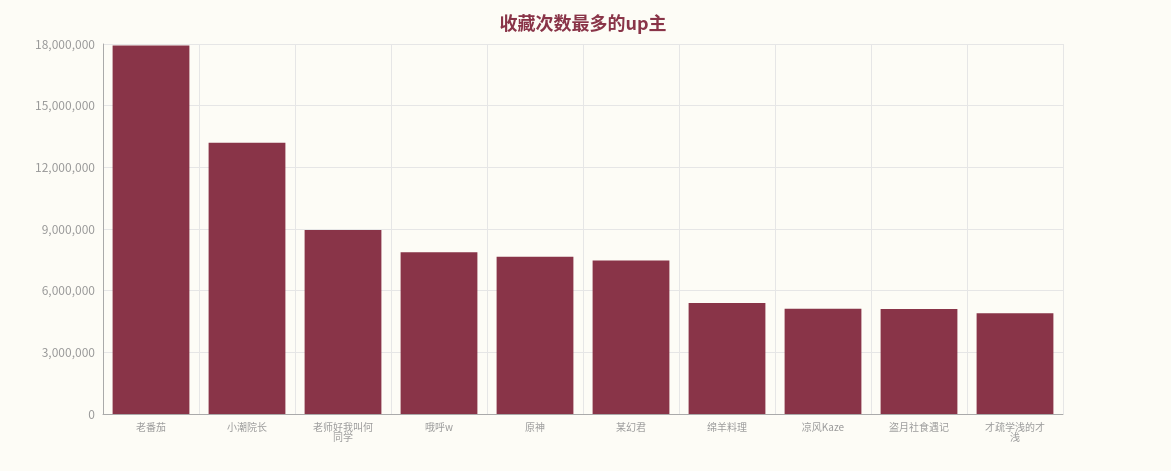
有关视频的收藏数据,《【派大星的独白】一个关于正常人的故事》和up主老番茄有着最多的收藏数。
5、点赞数据可视化
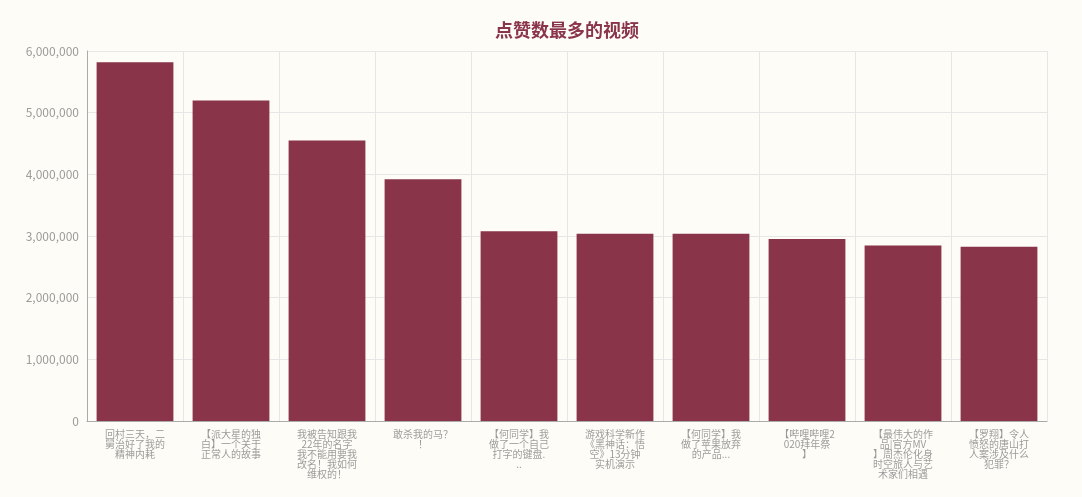

在点赞数据中,视频《回村三天,二舅治好了我的精神内耗》得到的最多点赞,在各up主中,老番茄的视频得到最多点赞。
6、评论数据可视化

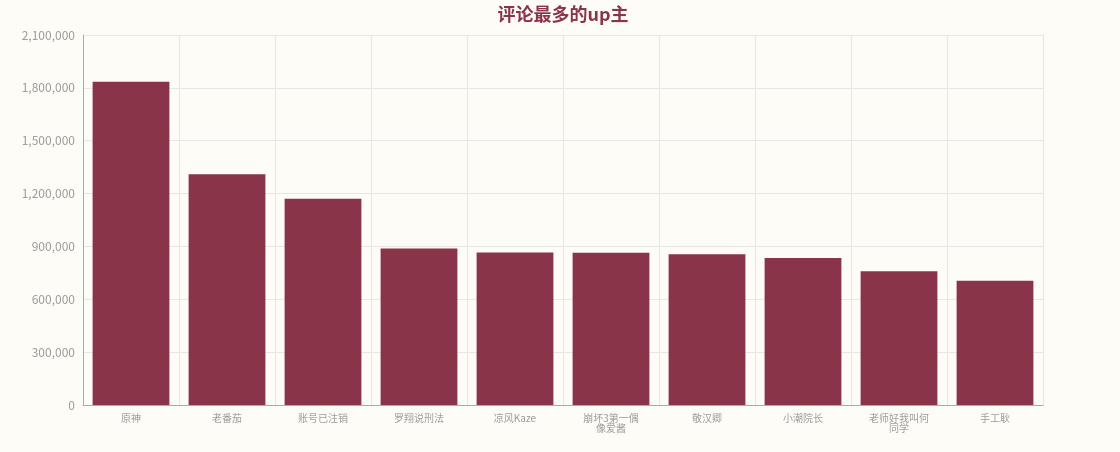
【A-SOUL/贝&珈&嘉】太潮啦!师徒三人演绎《隔岸 (DJ)》视频得到最多的评论,而账号原神发布的视频得到评论最多。
7、转发次数可视化
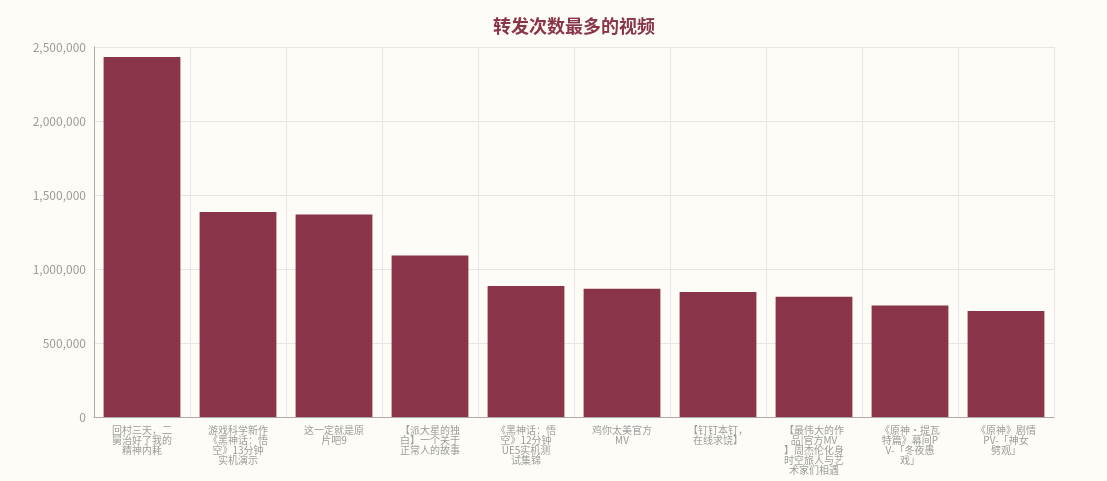

在转发的数据中,视频《回村三天,二舅治好了我的精神内耗》的分享次数最多,原神发布的视频分享总数最多。
8、播放量数据可视化
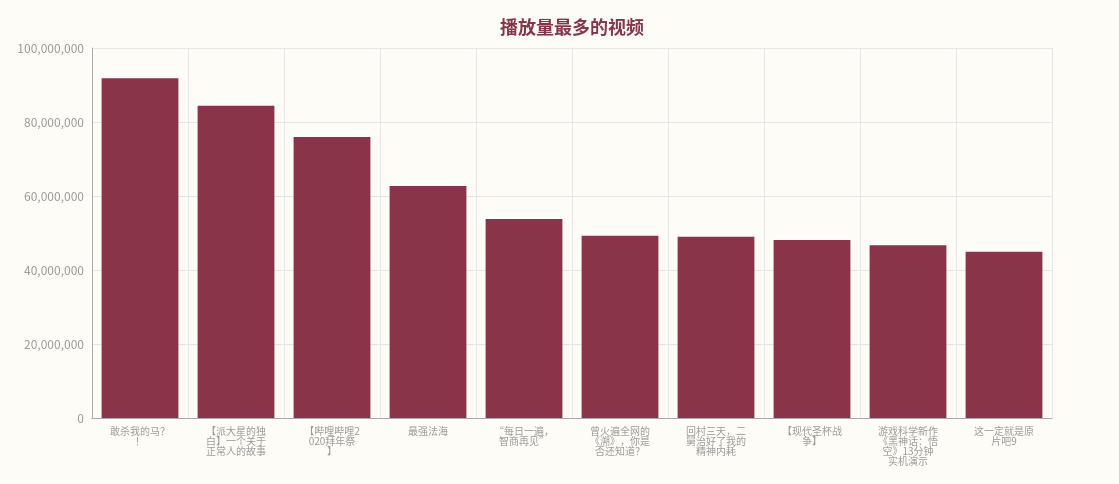

在视频的播放量方面,视频《敢杀我的马?》播放量最多,up主小潮院长的播放量累计最大。
9、视频分区占比可视化

10、up占比可视化
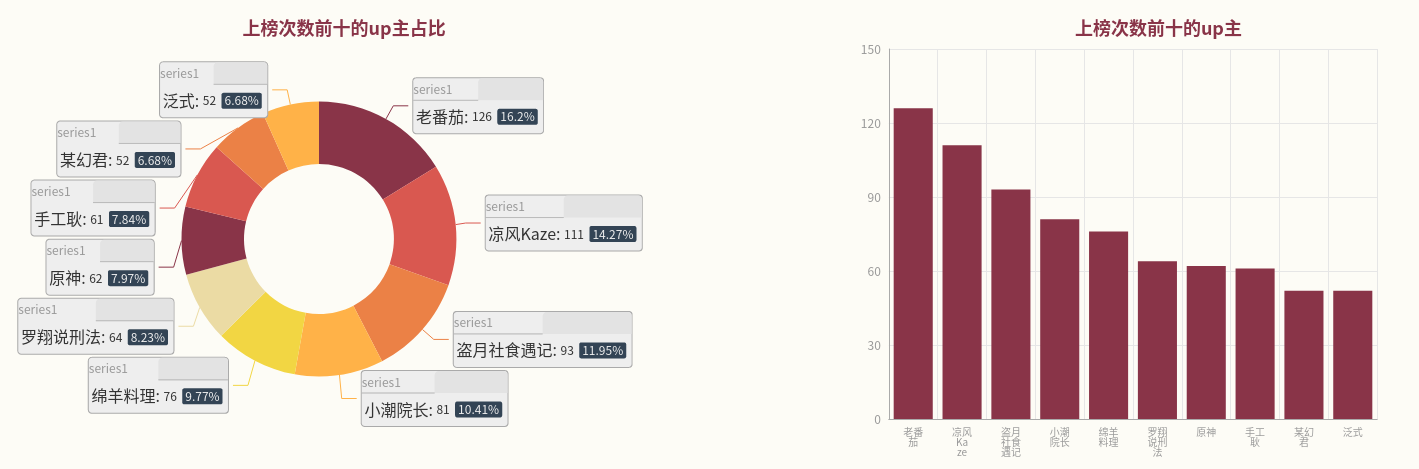
11、词频统计结果



从上面三个词云,可以看到b站的语言文字以口语化、诙谐化为主,并且游戏领域例如原神等更受欢迎。
12、机器学习可视化结果
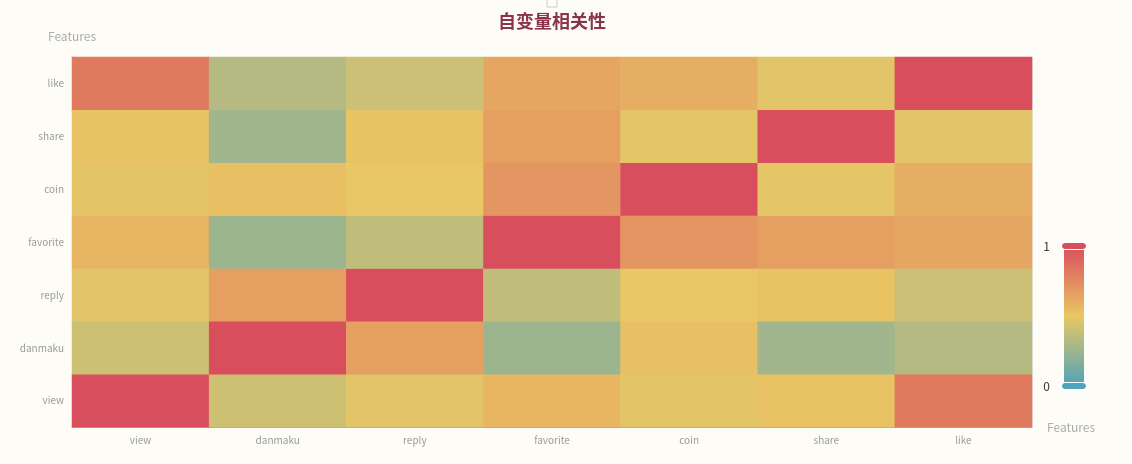
从热力图来看,几个变量之间的关系基本符合预期:观看次数越多的视频,得到的收藏和点赞可能越多,它们之间的相关性越大;而弹幕数和评论数也有较大的相关性,因为这两个数据都是反应视频与观众的互动性。

从几个分类器的性能来看,仅通过视频的播放量、评论数、弹幕数等可以初步对它们的热搜排名进行一个分类,但是这种分类准确率还有进一步的提升空间,可能还需要再考虑到发布视频up的粉丝数量、题材等等的信息。
五、遇到的问题与解决方法
1、关于spark的版本,项目是在conda里新建了一个虚拟环境,虚拟环境里面需要安装pyspark,安装成功后实际使用的spark版本和pyspark的版本一致,而与虚拟机上安装的spark无关。因此使用python+虚拟环境完成作业时,可以直接在虚拟环境里pip install pyspark==3.2.0解决spark的安装,这样更加简便快捷。
2、关于爬虫的代码,在windows系统下总是会出现奇奇怪怪的问题,比如“未能连接”或者“拒绝请求”,需要反复执行代码才有几率成功执行,但是反而在Linux环境下爬虫不会出现这些错误,因此最后数据的爬取也是在虚拟机中进行。
3、b站每个视频的数据,比如播放量、评论数、弹幕数等等都是会不断更新的,因此每一次运行代码得到的结果例如播放量、转发次数等都会不同,报告及可视化中的结果显示的是截止至5月26日各个视频的数据情况。但就整体而言,短时间内微小的变化量不影响整体的分析结果。
六、实验总结
这次实验我粗略体验了大数据分析的流程,就本次使用的数据集和分析结果来看, b站作为一个以娱乐为主的视频平台,搞笑、明星、游戏等相关视频会更受用户的喜爱,但是也不难看出,一些日常生活类的视频例如《二舅》等,通过讲述日常或身边的人物故事,思考生活的意义与本质,容易与年轻人产生共鸣,同样也受到较高的关注度。整个分析思考过程中,我学会了如何爬虫、如何根据自己的目标选择合适的数据并对其进行清洗,如何使用hadoop和spark工具对数据进行分析以及最后如何把分析得到的结果进行可视化,收获颇丰。补充说明
1、代码文件目录为BigData,数据集也包含在其中。文件目录格式如下:
data:存放爬虫得到json文件的路径,因该数据过大,提交时代码时把它删除;
html:存放可视化结果的路径,其中index.html集合了其他各个网页的跳转链接;
static:使用spark得到的分析结果;
bilibili_week.txt:对爬虫数据清洗后的数据集,也是最终上传到HDFS的数据集;
bilibili_weekly.py:爬虫代码;
chineseStopWords.txt:中文停用词,用于对文本进行分词;
data_analysize1.py:使用spark sql组件分析的代码;
data_analysize2.py:使用spark MLlib组件分析的代码;
data_process.py:数据处理代码;
echarts_show.py:可视化代码;
requirements.txt:代码所需的第三方库。
2、参考资料
(1)b站爬虫代码参考:
https://www.heywhale.com/mw/project/6059c0f0c910a9001581c98b
(2)python spark数据分析案例:https://dblab.xmu.edu.cn/blog/2738/
(3)pyecharts可视化文档:https://pyecharts.org/#/zh-cn/intro