【版权声明】版权所有,请勿转载!
【相关文章推荐】《大数据软件安装和基础编程实践指南》,详细指导VMWare、Ubuntu、Hadoop、HDFS、HBase、Hive、MapReduce、Spark、Flink的安装和基础编程
作者:厦门大学计算机系林子雨副教授
E-mail: ziyulin@xmu.edu.cn
-【版权声明:本指南为厦门大学林子雨编著的《大数据技术原理与应用(第4版)》教材配套学习资料,版权所有,转载请注明出处,请勿用于商业用途】
本指南介绍了HBase,并详细指引读者安装HBase. 前面的博客已经指导大家安装Linux操作系统,并安装配置了Hadoop,但是这只表明我们已经安装好了Hadoop分布式文件系统,而HBase需要另外下载安装,本指南就是详细指导大家安装并配置HBase,完成后大家可以结合厦门大学林子雨编著的《大数据技术原理与应用(第4版)》第4章节进行深入学习。
一、HBase介绍
HBase是一个分布式的、面向列的开源数据库,源于Google的一篇论文《BigTable:一个结构化数据的分布式存储系统》。HBase以表的形式存储数据,表有行和列组成,列划分为若干个列族/列簇(column family)。欲了解HBase的官方资讯,请访问[HBase官方网站](http://hbase.apache.org/)。
HBase的运行有三种模式:单机模式、伪分布式模式、分布式模式。
单机模式:在一台计算机上安装和使用HBase,不涉及数据的分布式存储;伪分布式模式:在一台计算机上模拟一个小的集群;分布式模式:使用多台计算机实现物理意义上的分布式存储。这里出于学习目的,我们只重点讨论单机模式和伪分布式模式。本教程运行环境是在Ubuntu-64位系统下(比如Ubuntu22.04,Ubuntu20.04或Ubuntu18.04或Ubuntu16.04),HBase版本为hbase-2.5.4,这是目前已经发行的已经编译好的稳定的版本,带有src的文件是未编译的版本,这里我们只要下载bin版本hbase-2.5.4-bin.tar.gz就好了。
- 如果读者是使用虚拟机方式安装Ubuntu系统的用户,请用虚拟机中的Ubuntu自带firefox浏览器访问本指南,再点击下面的地址,才能把HBase文件下载虚拟机Ubuntu中。请不要使用Windows系统下的浏览器下载,文件会被下载到Windows系统中,虚拟机中的Ubuntu无法访问外部Windows系统的文件,造成不必要的麻烦。
- 如果读者是使用双系统方式安装Ubuntu系统的用户,请运行Ubuntu系统,在Ubuntu系统打开firefox浏览器访问本指南,再点击下面的地址下载HBase下载地址
二、安装并配置HBase2.5.4
在安装HBase之前,请确保你的电脑已经安装了Hadoop3.3.5,由于HBase对Hadoop具有版本依赖性,所以,在安装HBase2.5.4时,一定要首先安装Hadoop3.3.5(查看安装方法)。
1. HBase2.5.4安装
点击下面的地址下载HBase2.5.4安装文件HBase官网下载地址
也可以直接点击这里从百度云盘下载软件(提取码:ziyu)。进入百度网盘后,进入“软件”目录,找到hbase-2.5.4-bin.tar.gz文件,下载到本地。
1.1 解压安装包hbase-2.5.4-bin.tar.gz至路径 /usr/local,命令如下:
cd ~
sudo tar -zxf ~/下载/hbase-2.5.4-bin.tar.gz -C /usr/local1.2 将解压的文件名hbase-2.5.4改为hbase,以方便使用,命令如下:
cd /usr/local
sudo mv ./hbase-2.5.4 ./hbase下面把hbase目录权限赋予给hadoop用户:
cd /usr/local
sudo chown -R hadoop ./hbase1.3 配置环境变量
将hbase下的bin目录添加到path中,这样,启动hbase就无需到/usr/local/hbase目录下,大大的方便了hbase的使用。教程下面的部分还是切换到了/usr/local/hbase目录操作,有助于初学者理解运行过程,熟练之后可以不必切换。
编辑~/.bashrc文件
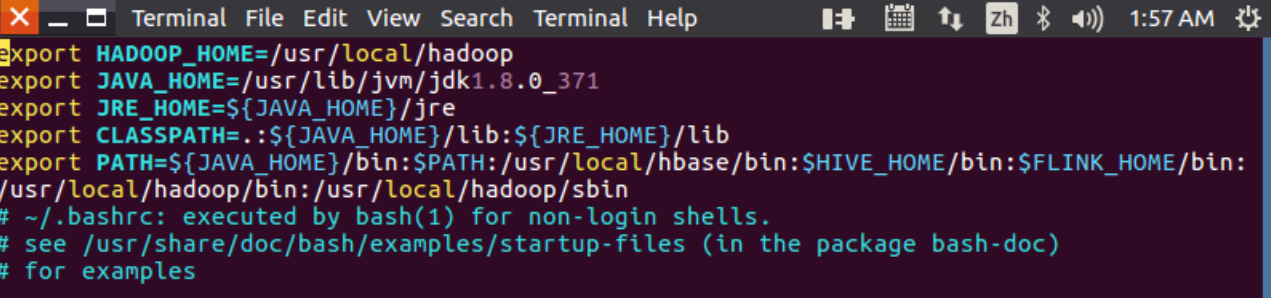
vim ~/.bashrc如果没有引入过PATH请在~/.bashrc文件尾行添加如下内容:
export PATH=$PATH:/usr/local/hbase/bin如果已经引入过PATH请在export PATH这行追加/usr/local/hbase/bin,这里的“:”是分隔符。如下图:
编辑完成后,再执行source命令使上述配置在当前终端立即生效,命令如下:
source ~/.bashrc扩展阅读: 设置Linux环境变量的方法和区别
1.4 添加HBase权限
cd /usr/local
sudo chown -R hadoop ./hbase #将hbase下的所有文件的所有者改为hadoop,hadoop是当前用户的用户名。1.5 查看HBase版本,确定hbase安装成功,命令如下:
/usr/local/hbase/bin/hbase version启动成功以后如下图所示:

看到输出版本消息表示HBase已经安装成功,接下来将分别进行HBase单机模式和伪分布式模式的配置。
2. HBase配置
HBase有三种运行模式,单机模式、伪分布式模式、分布式模式。作为学习,我们重点讨论单机模式和伪分布式模式。
以下先决条件很重要,比如没有配置JAVA_HOME环境变量,就会报错。
- jdk
- Hadoop( 单机模式不需要,伪分布式模式和分布式模式需要)
- SSH
以上三者如果没有安装,请回到Hadoop3.3.5的安装参考如何安装。
2.1单机模式配置
1. 配置/usr/local/hbase/conf/hbase-env.sh 。配置JAVA环境变量,并添加配置HBASE_MANAGES_ZK为true,用vi命令打开并编辑hbase-env.sh,命令如下:
vim /usr/local/hbase/conf/hbase-env.sh配置JAVA环境变量。如果你之前已经按照本网站Hadoop安装教程安装Hadoop3.3.5,则已经安装了JDK1.8。JDK的安装目录是/usr/lib/jvm/jdk1.8.0_371, 则JAVA _HOME =/usr/lib/jvm/jdk1.8.0_371;配置HBASE_MANAGES_ZK为true,表示由hbase自己管理zookeeper,不需要单独的zookeeper。hbase-env.sh中本来就存在这些变量的配置,大家只需要删除前面的#并修改配置内容即可(#代表注释):
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_371
export HBASE_MANAGES_ZK=true 添加完成后保存退出即可。
2. 配置/usr/local/hbase/conf/hbase-site.xml
打开并编辑hbase-site.xml,命令如下:
vim /usr/local/hbase/conf/hbase-site.xml在启动HBase前需要设置属性hbase.rootdir,用于指定HBase数据的存储位置,因为如果不设置的话,hbase.rootdir默认为/tmp/hbase-${user.name},这意味着每次重启系统都会丢失数据。此处设置为HBase安装目录下的hbase-tmp文件夹即(/usr/local/hbase/hbase-tmp),添加配置如下:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///usr/local/hbase/hbase-tmp</value>
</property>
</configuration>3. 接下来测试运行。首先切换目录至HBase安装目录/usr/local/hbase;再启动HBase。命令如下:
cd /usr/local/hbase
bin/start-hbase.sh
bin/hbase shell上述三条命令中,sudo bin/start-hbase.sh用于启动HBase,bin/hbase shell用于打开shell命令行模式,用户可以通过输入shell命令操作HBase数据库。
成功启动HBase,截图如下:

停止HBase运行,命令如下:
bin/stop-hbase.sh注意:如果在操作HBase的过程中发生错误,可以通过{HBASE_HOME}目录(/usr/local/hbase)下的logs子目录中的日志文件查看错误原因。
2.2 伪分布式模式配置
1.配置/usr/local/hbase/conf/hbase-env.sh。命令如下:
vim /usr/local/hbase/conf/hbase-env.sh配置JAVA_HOME,HBASE_CLASSPATH,HBASE_MANAGES_ZK.
HBASE_CLASSPATH设置为本机HBase安装目录下的conf目录(即/usr/local/hbase/conf)
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_371
export HBASE_CLASSPATH=/usr/local/hbase/conf
export HBASE_MANAGES_ZK=true2.配置/usr/local/hbase/conf/hbase-site.xml
用命令vi打开并编辑hbase-site.xml,命令如下:
vim /usr/local/hbase/conf/hbase-site.xml修改hbase.rootdir,指定HBase数据在HDFS上的存储路径;将属性hbase.cluter.distributed设置为true。假设当前Hadoop集群运行在伪分布式模式下,在本机上运行,且NameNode运行在9000端口。
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>hbase.rootdir指定HBase的存储目录;hbase.cluster.distributed设置集群处于分布式模式.
另外,上面配置文件中,hbase.unsafe.stream.capability.enforce这个属性的设置,是为了避免出现启动错误。也就是说,如果没有设置hbase.unsafe.stream.capability.enforce为false,那么,在启动HBase以后,会出现无法找到HMaster进程的错误,启动后查看系统启动日志(/usr/local/hbase/logs/hbase-hadoop-master-ubuntu.log),会发现如下错误:
2023-07-12 11:05:53,916 ERROR [master/localhost:16000:becomeActiveMaster] master.HMaster: Failed to become active master
java.lang.IllegalStateException: The procedure WAL relies on the ability to hsync for proper operation during component failures, but the underlying filesystem does not support doing so. Please check the config value of 'hbase.procedure.store.wal.use.hsync' to set the desired level of robustness and ensure the config value of 'hbase.wal.dir' points to a FileSystem mount that can provide it.3. 接下来测试运行HBase。
第一步:首先登陆ssh,之前设置了无密码登陆,因此这里不需要密码;再切换目录至/usr/local/hadoop ;再启动hadoop,如果已经启动hadoop请跳过此步骤。命令如下:
ssh localhost
cd /usr/local/hadoop
./sbin/start-dfs.sh输入命令jps,能看到NameNode,DataNode和SecondaryNameNode都已经成功启动,表示Hadoop启动成功.
第二步:切换目录至/usr/local/hbase;再启动HBase.命令如下:
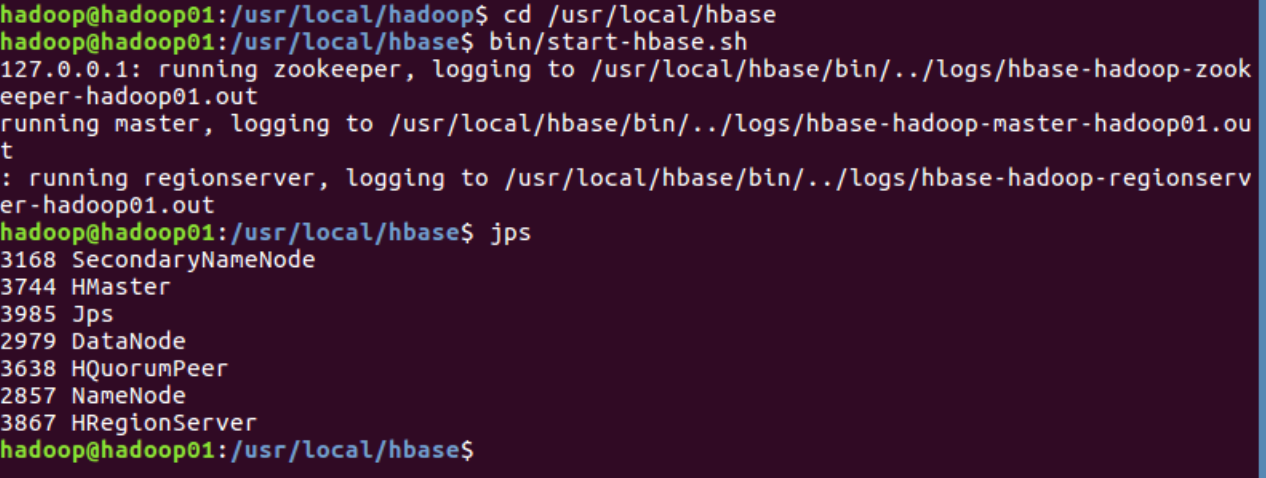
cd /usr/local/hbase
bin/start-hbase.sh启动成功,输入命令jps,看到以下界面说明hbase启动成功.
进入shell界面:
bin/hbase shell截图如下:
4.停止HBase运行,命令如下:
bin/stop-hbase.sh注意:如果在操作HBase的过程中发生错误,可以通过{HBASE_HOME}目录(/usr/local/hbase)下的logs子目录中的日志文件查看错误原因。
这里启动关闭Hadoop和HBase的顺序一定是:
启动Hadoop—>启动HBase—>关闭HBase—>关闭Hadoop
三、 编程实践
1. 利用Shell命令
1.1 HBase中创建表
HBase中用create命令创建表,具体如下:
create 'student','Sname','Ssex','Sage','Sdept','course'命令执行截图如下:

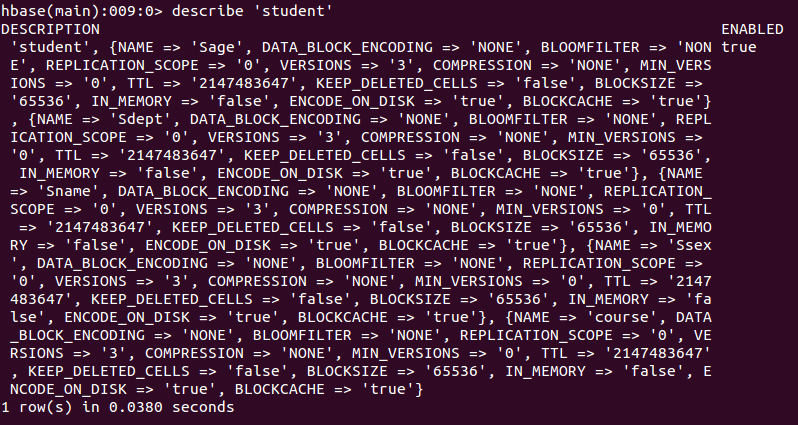
此时,即创建了一个“student”表,属性有:Sname,Ssex,Sage,Sdept,course。因为HBase的表中会有一个系统默认的属性作为行键,无需自行创建,默认为put命令操作中表名后第一个数据。创建完“student”表后,可通过describe命令查看“student”表的基本信息。命令执行截图如下:
1.2 HBase数据库基本操作
本小节主要介绍HBase的增、删、改、查操作。在添加数据时,HBase会自动为添加的数据添加一个时间戳,故在需要修改数据时,只需直接添加数据,HBase即会生成一个新的版本,从而完成“改”操作,旧的版本依旧保留,系统会定时回收垃圾数据,只留下最新的几个版本,保存的版本数可以在创建表的时候指定。
- 添加数据
HBase中用put命令添加数据,注意:一次只能为一个表的一行数据的一个列,也就是一个单元格添加一个数据,所以直接用shell命令插入数据效率很低,在实际应用中,一般都是利用编程操作数据。
当运行命令:put ‘student’,’95001’,’Sname’,’LiYing’时,即为student表添加了学号为95001,名字为LiYing的一行数据,其行键为95001。
put 'student','95001','Sname','LiYing'命令执行截图如下,即为student表添加了学号为95001,名字为LiYing的一行数据,其行键为95001。

put 'student','95001','course:math','80'命令执行截图如下,即为95001行下的course列族的math列添加了一个数据。

put 'student','95001','Ssex','Male'上面的命令为95001行下的Ssex列添加了一个数据。
- 删除数据
在HBase中用delete以及deleteall命令进行删除数据操作,它们的区别是:1. delete用于删除一个数据,是put的反向操作;2. deleteall操作用于删除一行数据。
1. delete命令
delete 'student','95001','Ssex:'注意,在HBase2.5.4版本中,上面的命令中列名'Ssex:'是有冒号的。
命令执行截图如下, 即删除了student表中95001行下的Ssex列的所有数据。
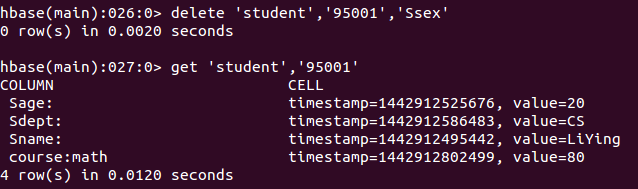
2. deleteall命令
deleteall 'student','95001'命令执行截图如下,即删除了student表中的95001行的全部数据。
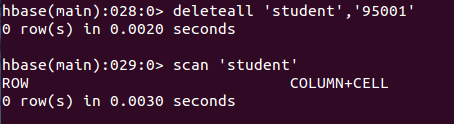
- 查看数据
HBase中有两个用于查看数据的命令:1. get命令,用于查看表的某一行数据;2. scan命令用于查看某个表的全部数据
1. get命令
get 'student','95001'命令执行截图如下, 返回的是‘student’表‘95001’行的数据。
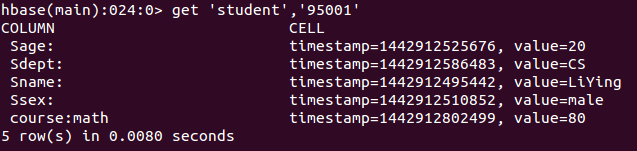
2. scan命令
scan 'student'命令执行截图如下, 返回的是‘student’表的全部数据。

- 删除表
删除表有两步,第一步先让该表不可用,第二步删除表。disable 'student' drop 'student'命令执行截图如下:
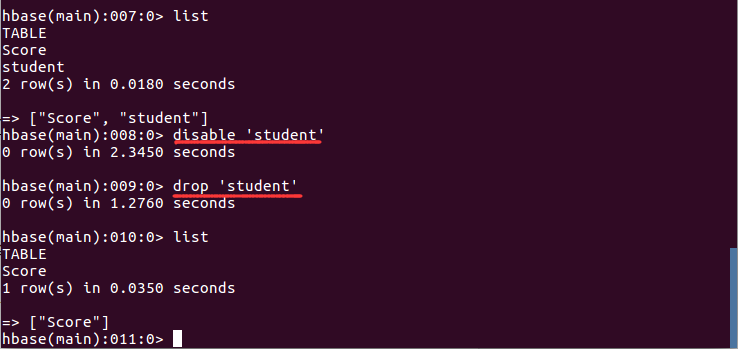
1.3 查询表历史数据
查询表的历史版本,需要两步。
1、在创建表的时候,指定保存的版本数(假设指定为5)create 'teacher',{NAME=>'username',VERSIONS=>5}2、插入数据然后更新数据,使其产生历史版本数据,注意:这里插入数据和更新数据都是用put命令
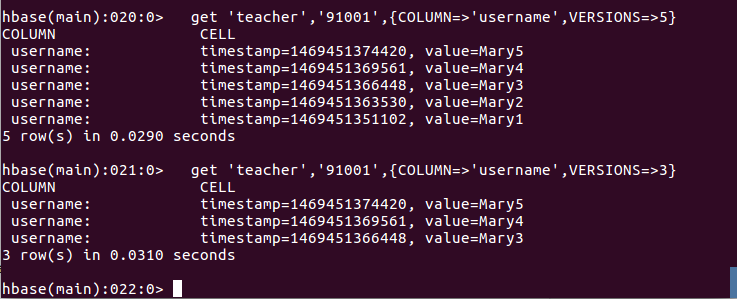
put 'teacher','91001','username','Mary' put 'teacher','91001','username','Mary1' put 'teacher','91001','username','Mary2' put 'teacher','91001','username','Mary3' put 'teacher','91001','username','Mary4' put 'teacher','91001','username','Mary5'3、查询时,指定查询的历史版本数。默认会查询出最新的数据。(有效取值为1到5)
get 'teacher','91001',{COLUMN=>'username',VERSIONS=>5}查询结果截图如下:
1.4 退出HBase数据库表操作
最后退出数据库操作,输入exit命令即可退出,注意:这里退出HBase数据库是退出对数据库表的操作,而不是停止启动HBase数据库后台运行。
exit
HBase Java API编程实践
本实例采用Eclipse开发工具。
启动Eclipse,启动以后,出现如下图所示界面,点击界面右下角的“Launch”按钮。

启动进入Eclipse以后的程序开发界面如下图所示。

点击界面顶部的“File”菜单,在弹出的子菜单(如下图所示)中选择“New”,再选择子菜单中的“Java Project”。

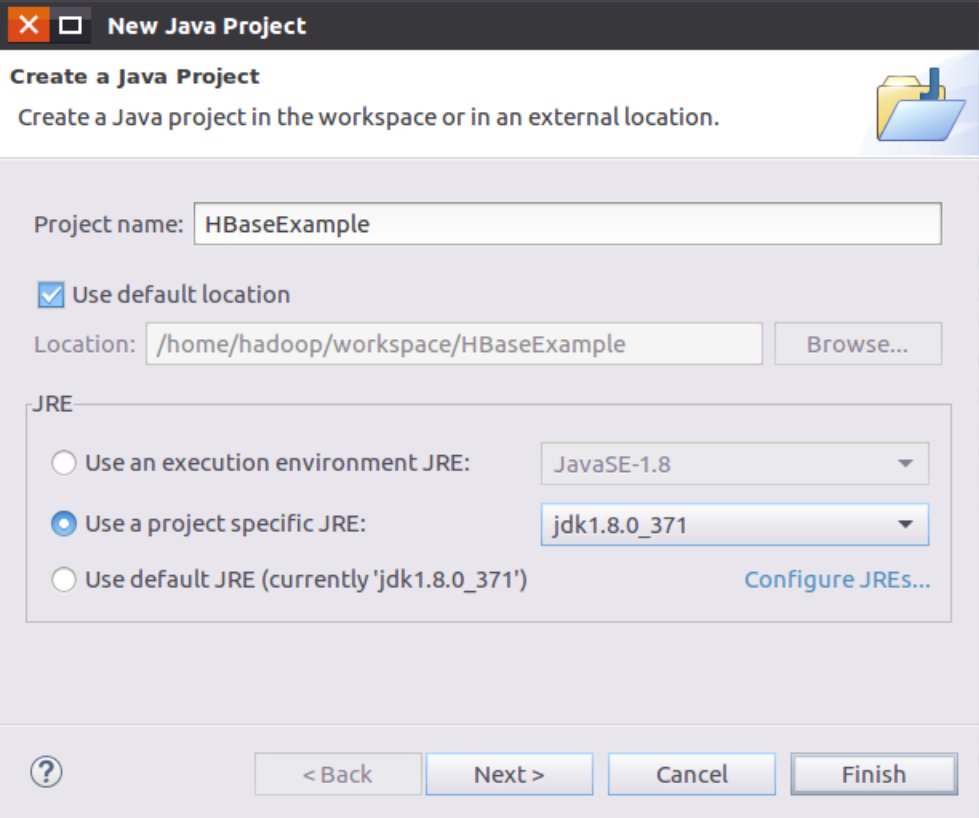
这时会弹出一个Java工程创建对话框(如下图所示),在“Project name”文本框中输入“HBaseExample”,在“JRE”选项卡中选中第2项“Use a project specific JRE”,然后点击界面底部的“Next”按钮。
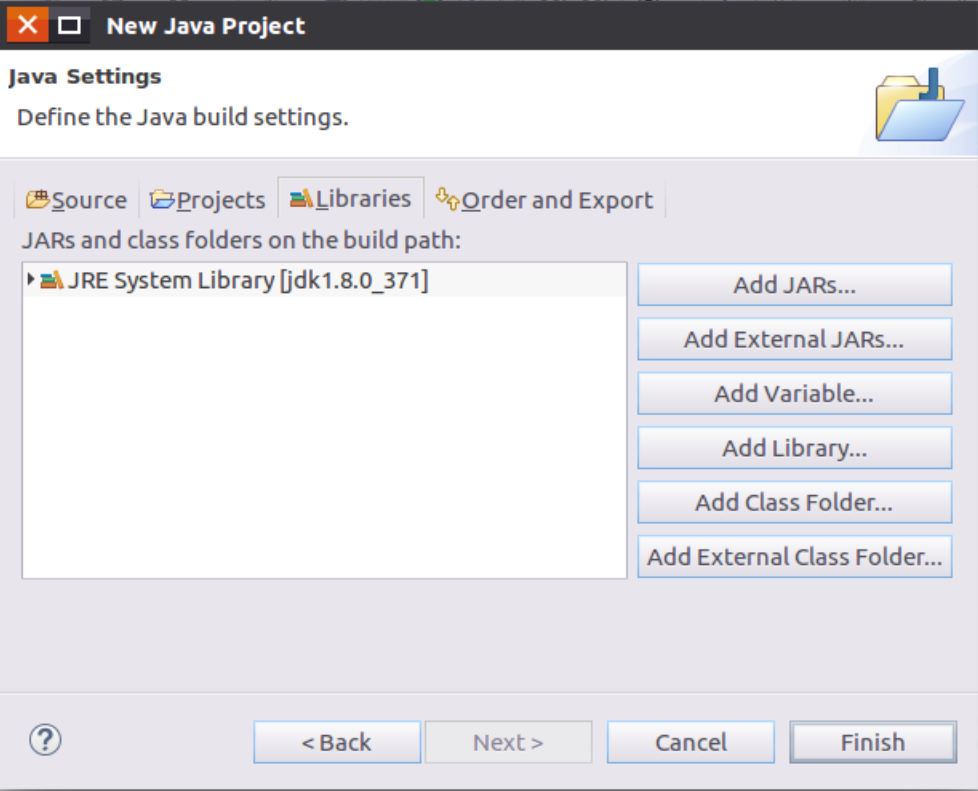
在弹出的界面中(如下图所示),用鼠标点击“Libraries”选项卡,然后,点击界面右侧的“Add External JARs...”按钮。
为了编写一个能够与HBase交互的Java应用程序,需要在这个界面中加载该Java工程所需要用到的JAR包,这些JAR包中包含了可以访问HBase的Java API。这些JAR包都位于Linux系统的HBase安装目录的lib目录下,也就是位于“/usr/local/hbase/lib”目录下。点击界面中的“Libraries”选项卡,然后,点击界面右侧的“Add External JARs…”按钮,弹出如下图所示界面。
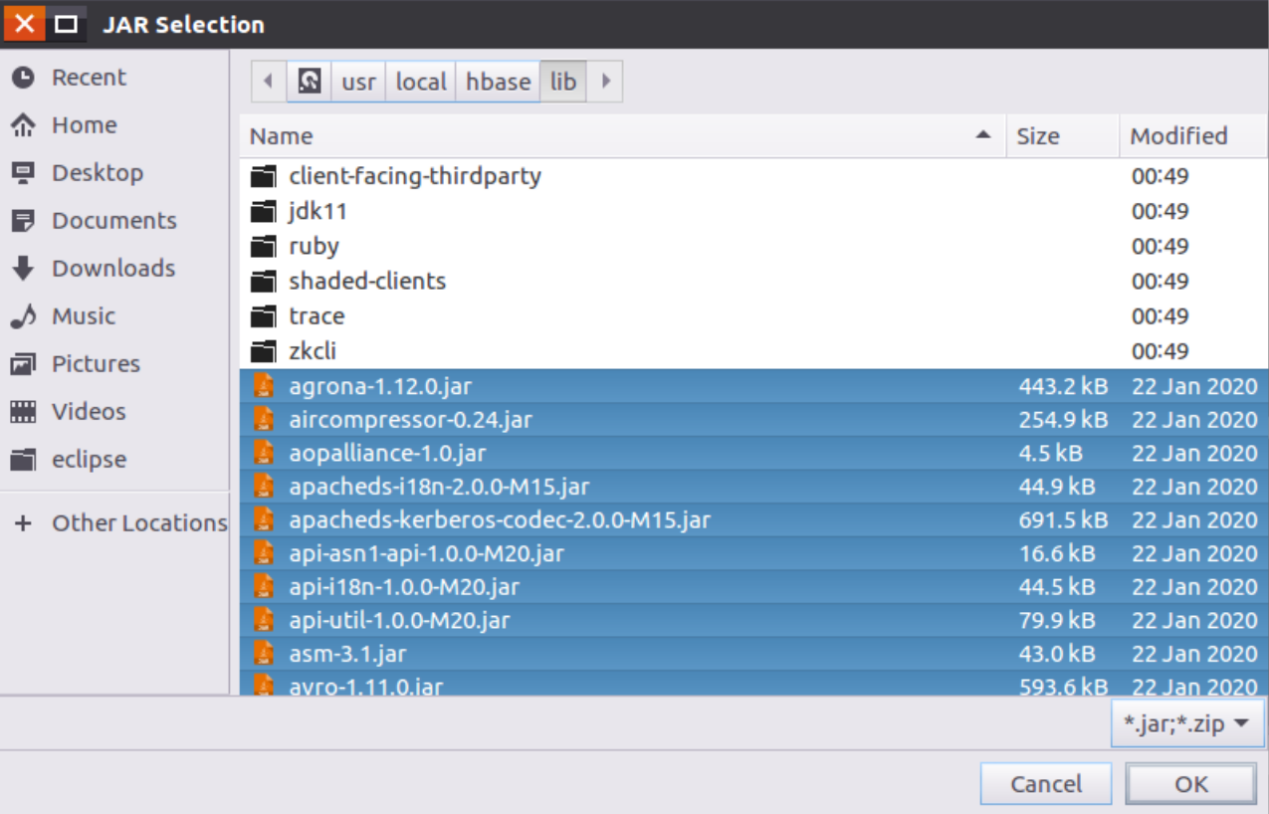
选中“/usr/local/hbase/lib”目录下的所有JAR包(注意,不要选中client-facing-thirdparty、jdk11、ruby、shaded-clients、trace和zkcli这六个目录),然后,点击界面右下角的“OK”按钮。
然后,再次此点击添加JAR包界面右侧的“Add External JARs…”按钮,继续添加JAR包。在“JAR Selection”界面中(如下图所示),点击进入到“client-facing-thirdparty”目录下。
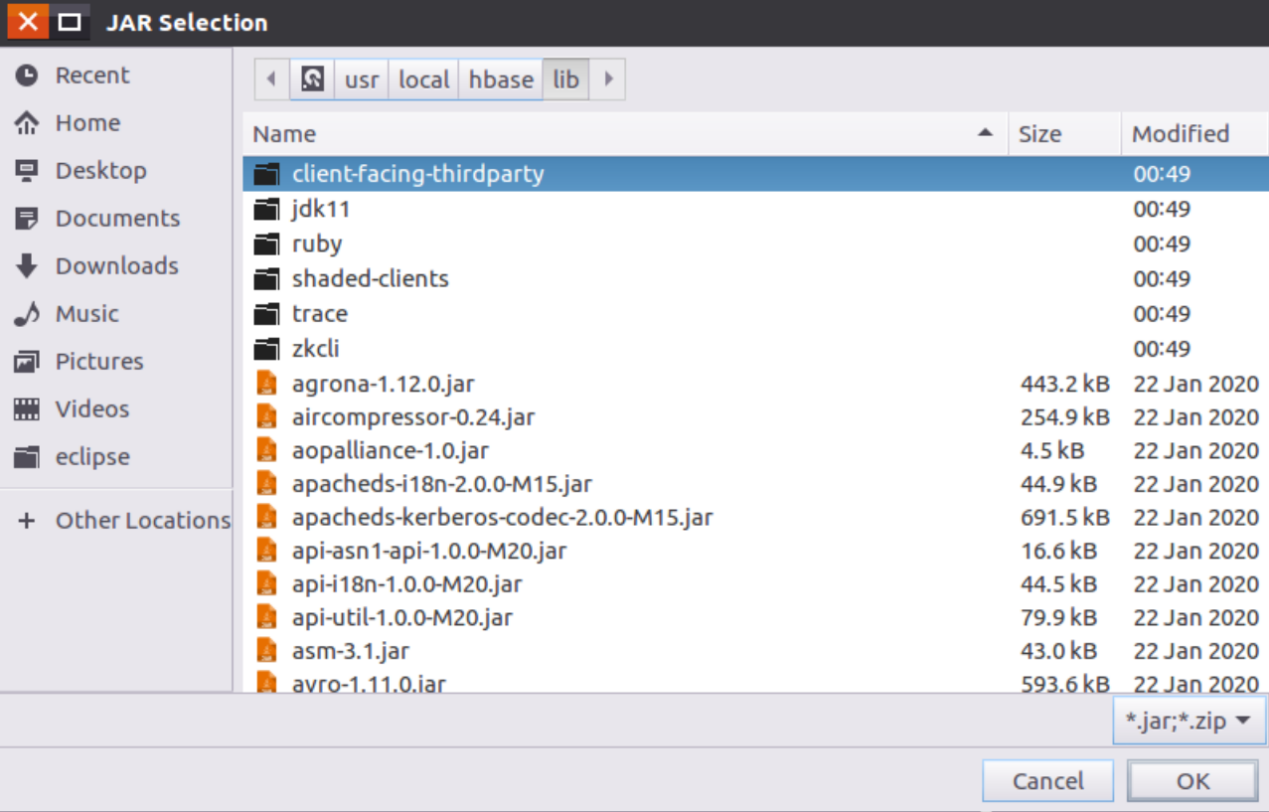
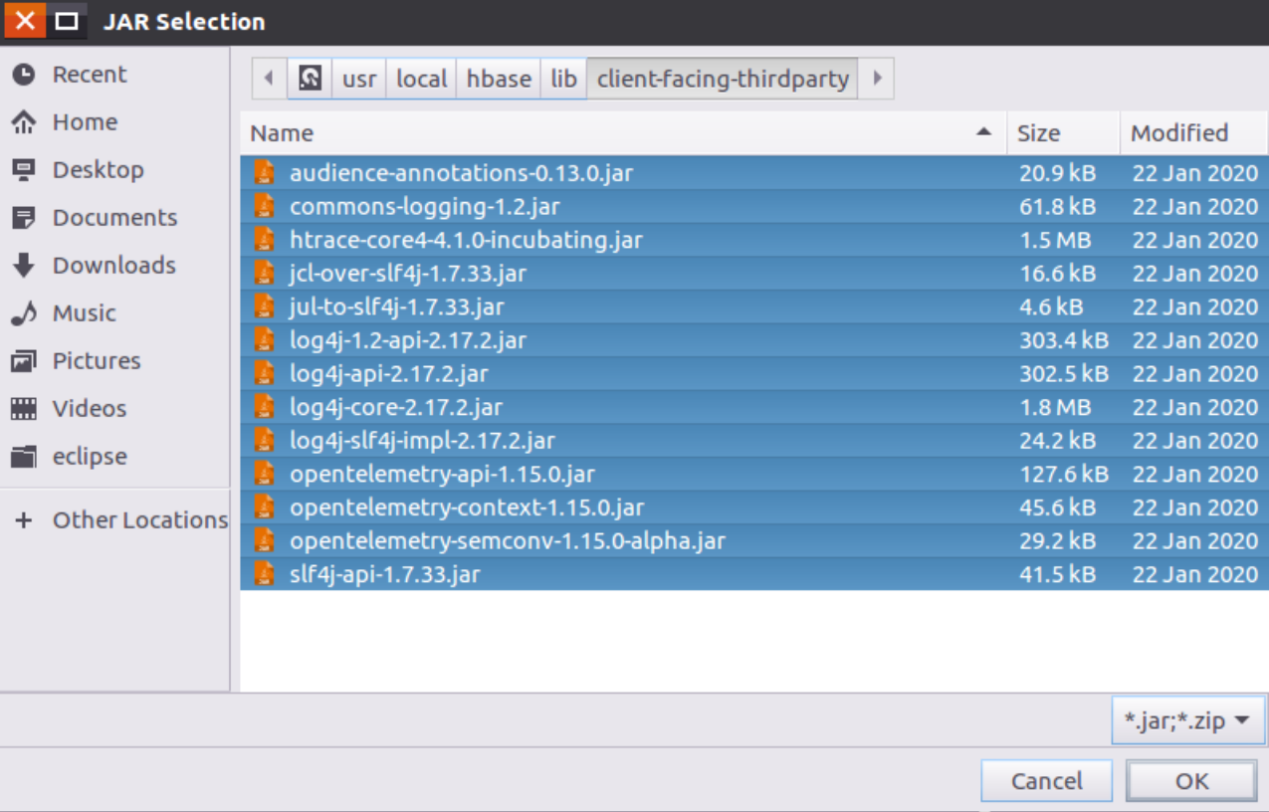
在“client-facing-thirdparty”目录下(如下图所示),选中所有jar文件,再点击界面底部的“OK”按钮。
添加完毕以后,就可以点击界面(如下图所示)右下角的“Finish”按钮,完成Java工程HBaseExample的创建。
在界面(如下图所示)左侧的“HBaseExample”工程名称上单击鼠标右键,在弹出的菜单中选择“New”,再在弹出的子菜单中选择“Class”。
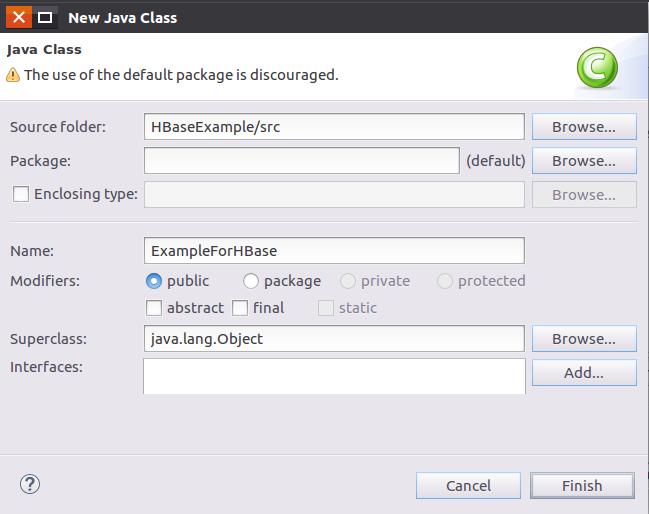
在弹出的“New Java Class”对话框(如下图所示)中,在“Name”文本框中输入“ExampleForHBase”,然后,点击界面底部的“Finish”按钮。
在代码窗口中(如下图所示),ExampleForHBase.java代码内容输入。
ExampleForHBase.java代码内容具体如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class ExampleForHBase {
public static Configuration configuration;
public static Connection connection;
public static Admin admin;
public static void main(String[] args)throws IOException{
init();
createTable("student",new String[]{"score"});
insertData("student","zhangsan","score","English","69");
insertData("student","zhangsan","score","Math","86");
insertData("student","zhangsan","score","Computer","77");
getData("student", "zhangsan", "score","English");
close();
}
public static void init(){
configuration = HBaseConfiguration.create();
configuration.set("hbase.rootdir","hdfs://localhost:9000/hbase");
try{
connection = ConnectionFactory.createConnection(configuration);
admin = connection.getAdmin();
}catch (IOException e){
e.printStackTrace();
}
}
public static void close(){
try{
if(admin != null){
admin.close();
}
if(null != connection){
connection.close();
}
}catch (IOException e){
e.printStackTrace();
}
}
public static void createTable(String myTableName,String[] colFamily) throws IOException {
TableName tableName = TableName.valueOf(myTableName);
if(admin.tableExists(tableName)){
System.out.println("talbe is exists!");
}else {
TableDescriptorBuilder tableDescriptor = TableDescriptorBuilder.newBuilder(tableName);
for(String str:colFamily){
ColumnFamilyDescriptor family =
ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(str)).build();
tableDescriptor.setColumnFamily(family);
}
admin.createTable(tableDescriptor.build());
}
}
public static void insertData(String tableName,String rowKey,String colFamily,String col,String val) throws IOException {
Table table = connection.getTable(TableName.valueOf(tableName));
Put put = new Put(rowKey.getBytes());
put.addColumn(colFamily.getBytes(),col.getBytes(), val.getBytes());
table.put(put);
table.close();
}
public static void getData(String tableName,String rowKey,String colFamily, String col)throws IOException{
Table table = connection.getTable(TableName.valueOf(tableName));
Get get = new Get(rowKey.getBytes());
get.addColumn(colFamily.getBytes(),col.getBytes());
Result result = table.get(get);
System.out.println(new String(result.getValue(colFamily.getBytes(),col==null?null:col.getBytes())));
table.close();
}
}在开始运行程序之前,需要启动HDFS和HBase。
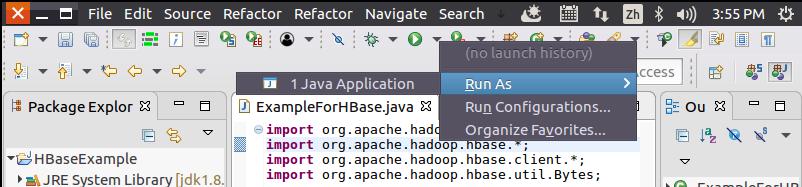
然后,如下图所示,点击界面中的运行图标右侧的“倒三角”,在弹出的菜单中选择“Run As”,再在弹出的菜单中点击“1 Java Application”,开始运行程序。
程序运行成功以后,如下图所示,会在运行结果中出现“69”。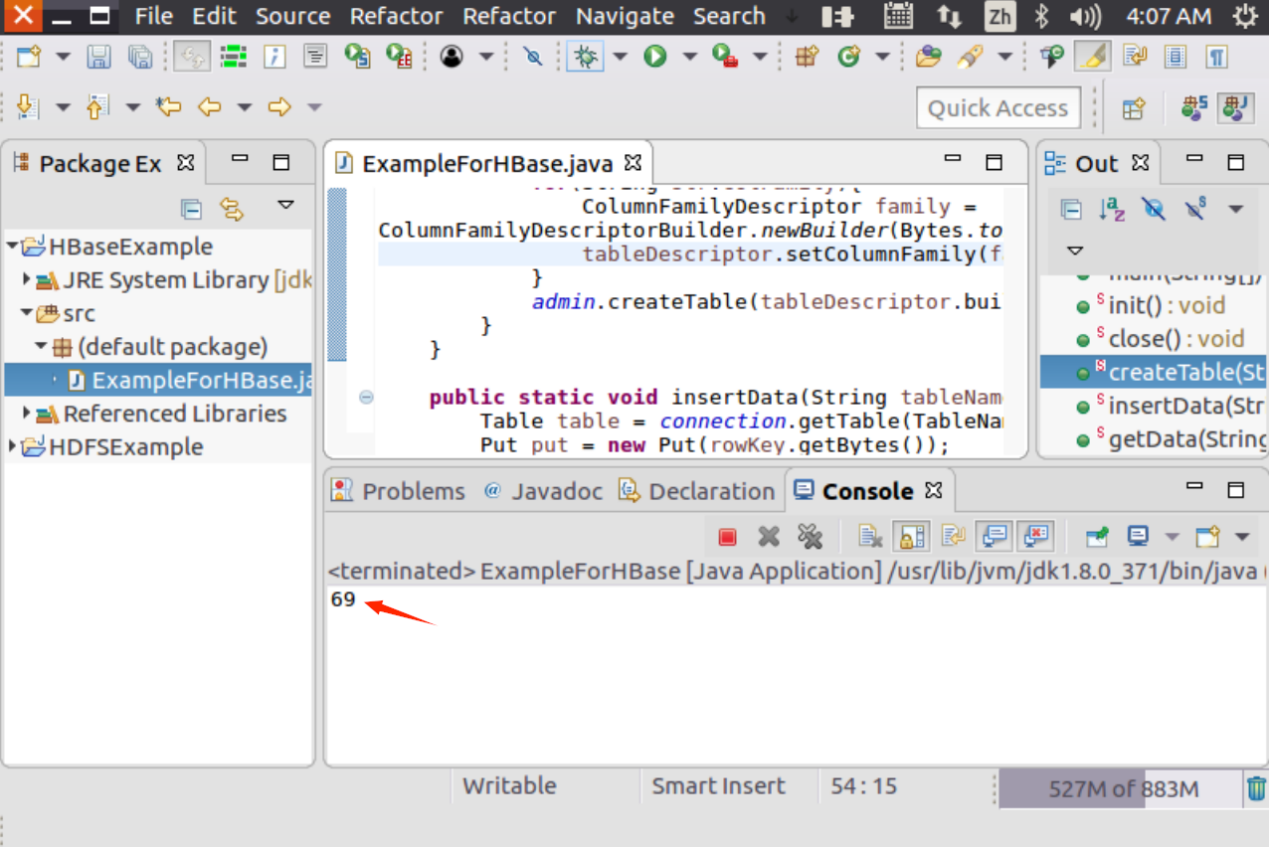
这时,可以到HBase Shell交互式环境中,使用如下命令查看student表是否创建成功:
hbase> list该命令执行效果如下图所示:

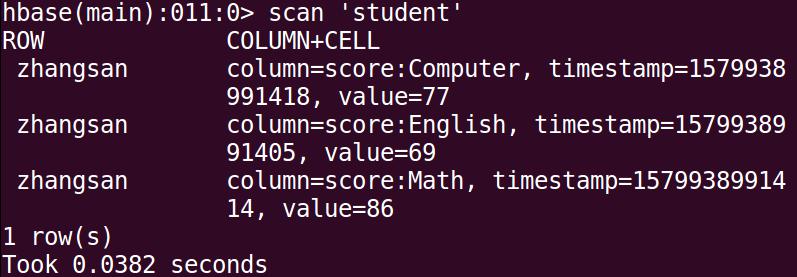
再在HBase Shell交互式环境中,使用如下命令查看student表中的数据:
hbase> scan ‘student’该命令执行效果如下图所示: