
作者:厦门大学计算机系林子雨副教授
说明:本博客是与林子雨编著《数据采集与预处理》教材配套的教学资料。
版权声明:本博客内容,未经同意,禁止转载。
操作系统:Windows10
Flume:1.9.0
Kafka:kafka_2.12-2.4.0
一、任务描述
设置两个Agent,即Agent1和Agent2,二者的组件配置如下:
(1)agent1: Exec Source + Memory Channel + Avro Sink
(2)agent2: Avro Source + Memory Channel + Kafka Sink
在Agent1中,各个组件的功能如下:
(1)Exec Source:实施监控一个文件的内容是否有增加;
(2)Avro Sink:一般用于跨节点传输,把捕捉到的数据传递给agent2。
在Agent2中,各个组件的功能如下:
(1)Avro Source:接收来自agent1的数据;
(2)Kafka Sink:消费数据。
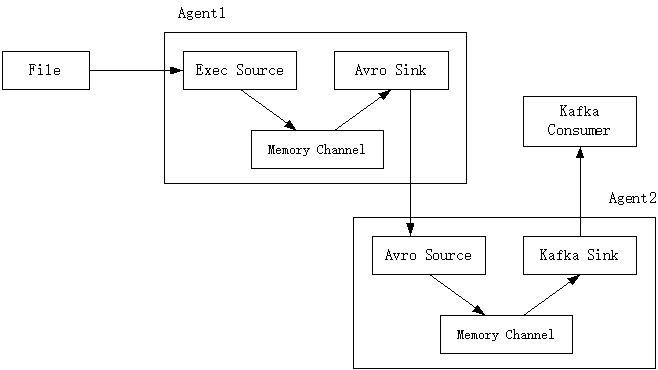
图1 Agent的配置
二、配置Flume
为Agent1创建一个配置文件flume_kafka1.conf,其内容如下:
# 设置各组件名称
a1.sources = exec-source
a1.sinks = avro-sink
a1.channels = memory-channel
#配置Source
a1.sources.exec-source.type = exec
a1.sources.exec-source.command = tail -f C:/apache-flume-1.9.0-bin/data.txt
#配置Sink
a1.sinks.avro-sink.type = avro
a1.sinks.avro-sink.hostname = localhost
a1.sinks.avro-sink.port = 44444
#配置Channel
a1.channels.memory-channel.type = memory
a1.channels.memory-channel.capacity = 1000
a1.channels.memory-channel.transactionCapacity = 100
#把Source和Sink绑定到Channel
a1.sources.exec-source.channels = memory-channel
a1.sinks.avro-sink.channel = memory-channel为Agent2创建一个配置文件flume_kafka2.conf,其内容如下:
#设置各组件名称
a2.sources = avro-source
a2.sinks = kafka-sink
a2.channels = memory-channel
#配置Source
a2.sources.avro-source.type = avro
a2.sources.avro-source.bind = localhost
a2.sources.avro-source.port = 44444
# 配置Sink
a2.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
a2.sinks.kafka-sink.kafka.bootstrap.servers = localhost:9092
a2.sinks.kafka-sink.kafka.topic = myTestTopic
a2.sinks.kafka-sink.serializer.class = kafka.serializer.StringEncoder
a2.sinks.kafka-sink.kafka.producer.acks = 1
a2.xinks.kafka-sink.custom.encoding = UTF-8
a2.sinks.kafka-sink.flumeBatchSize=1
# 配置Channel
a2.channels.memory-channel.type = memory
a2.channels.memory-channel.capacity = 1000
a2.channels.memory-channel.transactionCapacity = 100
# 把Source和Sink绑定到Channel
a2.sources.avro-source.channels = memory-channel
a2.sinks.kafka-sink.channel = memory-channel三、执行过程
在Windows系统中打开第1个cmd窗口,执行如下命令启动Zookeeper服务:
> cd c:\kafka_2.12-2.4.0
> .\bin\windows\zookeeper-server-start.bat .\config\zookeeper.Properties打开第2个cmd窗口,然后执行下面命令启动Kafka服务:
> cd c:\kafka_2.12-2.4.0
> .\bin\windows\kafka-server-start.bat .\config\server.properties打开第3个cmd窗口,执行如下命令创建一个名为myTestTopic的Topic:
> cd c:\kafka_2.12-2.4.0
> .\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic myTestTopic执行如下命令查看myTestTopic是否创建成功:
> .\bin\windows\kafka-topics.bat --list --zookeeper localhost:2181下面需要启动两个Agent,需要先启动Agent2,再启动Agent1,否则,Agent1启动会被拒绝连接。
打开第4个cmd窗口,执行如下命令启动Agent2:
> cd c:\apache-flume-1.9.0-bin
> .\bin\flume-ng.cmd agent --conf ./conf --conf-file ./conf/flume_kafka2.conf --name a2 -property flume.root.logger=INFO,console打开第5个cmd窗口,执行如下命令启动Agent1:
> cd c:\apache-flume-1.9.0-bin
> .\bin\flume-ng.cmd agent --conf ./conf --conf-file ./conf/flume_kafka1.conf --name a1 -property flume.root.logger=INFO,console打开第6个cmd窗口,执行如下命令启动Kafka消费者消费数据:
> cd c:\kafka_2.12-2.4.0
> .\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic myTestTopic --from-beginning打开第7个cmd窗口,输入如下命令向data.txt文件追加数据:
> echo spark >> "C:\apache-flume-1.9.0-bin\data.txt"
> echo hadoop >> "C:\apache-flume-1.9.0-bin\data.txt"
> echo hdfs >> "C:\apache-flume-1.9.0-bin\data.txt"这时,在第6个cmd窗口内,就可以看到捕捉到的数据(如图2所示)。

图2 Kafka消费数据