
作者:厦门大学计算机系林子雨副教授
说明:本博客是与林子雨编著《数据采集与预处理》教材配套的教学资料。
版权声明:本博客内容,未经同意,禁止转载。
操作系统:Windows10
数据库:MySQL8.0
一、Flume简介
Flume 运行的核心是Agent。Flume以Agent为最小的独立运行单位,一个Agent就是一个JVM(Java Virtual Machine),它是一个完整的数据采集工具,包含三个核心组件,分别是数据源(Source)、数据通道(Channel)和数据槽(Sink)。通过这些组件,“事件”可以从一个地方流向另一个地方。每个组件的具体功能如下(如图1所示):
(1)数据源是数据的收集端,负责将数据捕获后进行特殊的格式化,将数据封装到事件(Event)里,然后将事件推入数据通道中。常用的数据源的类型包括Avro、Thrift、Exec、JMS、Spooling Directory、Taildir、Kafka、NetCat、Syslog、HTTP等。
(2)数据通道是连接数据源和数据槽的组件,可以将它看作一个数据的缓冲区(数据队列),它可以将事件暂存到内存中,也可以持久化到本地磁盘上,直到数据槽处理完该事件。常用的数据通道类型包括Memory、JDBC、Kafka、File、Custom等。
(3)数据槽取出数据通道中的数据,存储到文件系统和数据库,或者提交到远程服务器。常用的数据槽包括HDFS、Hive、Logger、Avro、Thrift、IRC、File Roll、HBase、ElasticSearch、Kafka、HTTP等。
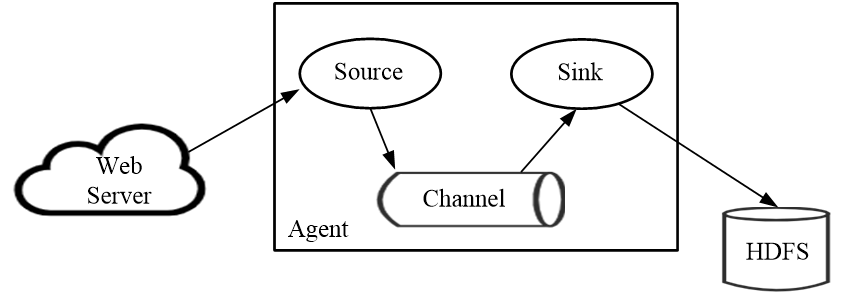
图1 Flume的技术架构
Flume提供了大量内置的数据源、数据通道和数据槽类型。不同类型的数据源、数据通道和数据槽可以自由组合。组合方式基于用户设置的配置文件,非常灵活。比如,数据通道可以把事件暂存在内存里,也可以持久化到本地硬盘上;数据槽可以把日志写入HDFS、HBase甚至是另外一个数据源等等。
二、Flume的安装
Flume的运行需要Java环境的支持,因此,需要在Windows系统中安装JDK。请参照第2章内容完成JDK的安装。
访问Flume官网(http://flume.apache.org/download.html ),下载Flume安装文件apache-flume-1.9.0-bin.tar.gz。把安装文件解压缩到Windows系统的“C:\”目录下,然后,打开一个cmd窗口,执行如下命令测试是否安装成功:
> cd c:\apache-flume-1.9.0-bin\bin
> flume-ng version如果能够返回类似如下的信息,则表示启动成功:
Flume 1.9.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: d4fcab4f501d41597bc616921329a4339f73585e
Compiled by fszabo on Mon Dec 17 20:45:25 CET 2018
From source with checksum 35db629a3bda49d23e9b3690c80737f9三、配置Flume
进入Flume安装目录下的conf子目录,在里面新建一个文件mysql_kafka.conf,在里面输入如下内容:
# 设置Agent上的各个组件名称
a1.channels = ch-1
a1.sources = src-1
a1.sinks = k1
#设置Source组件
a1.sources.src-1.type = org.keedio.flume.source.SQLSource
a1.sources.src-1.hibernate.connection.url = jdbc:mysql://localhost:3306/school
a1.sources.src-1.hibernate.connection.user = root
a1.sources.src-1.hibernate.connection.password = 123456
a1.sources.src-1.hibernate.connection.autocommit = true
a1.sources.src-1.table = student #数据库中的表名称
a1.sources.src-1.run.query.delay=5000
a1.sources.src-1.custom.query = select id, name,age,grade from student
a1.sources.src-1.status.file.path = C:/apache-flume-1.9.0-bin/
a1.sources.src-1.status.file.name = sql-source.status
# 配置Sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = testTopic
a1.sinks.k1.kafka.bootstrap.servers = localhost:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.k1.kafka.producer.compression.type = snappy
# 配置Channel
a1.channels.ch-1.type = memory
a1.channels.ch-1.capacity = 1000
a1.channels.ch-1.transactionCapacity = 100
# 把Source和Sink绑定到Channel上
a1.sources.src-1.channels = ch-1
a1.sinks.k1.channel = ch-1四、准备工作
在采集MySQL数据库中的数据到HDFS时,需要用到一个第三方JAR包,即flume-ng-sql-source-1.5.2.jar。这个JAR包可以直接从网络上下载,或者也可以到教材官网的“下载专区”的“软件”目录中下载。但是,直接下载的JAR包一般都不是最新的版本,或者可能与已经安装的Flume不兼容,因此,这里介绍自己下载源代码进行编译得到JAR包的方法。
为了对源代码进行编译,这里需要用到Maven工具,可以到Maven官网(https://maven.apache.org/download.cgi )下载安装包apache-maven-3.6.3-bin.zip,然后,解压缩到Windows系统的“C:\”目录下。
访问github网站(https://github.com/keedio/flume-ng-sql-source/tree/release/1.5.2 ),在出现的页面(如图2所示)中,点击右上角的“Code”按钮,在弹出的菜单中点击“Download ZIP”,就可以把压缩文件flume-ng-sql-source-release-1.5.2.zip下载到本地。然后,把文件解压缩到Windows系统的“C:\”目录下。
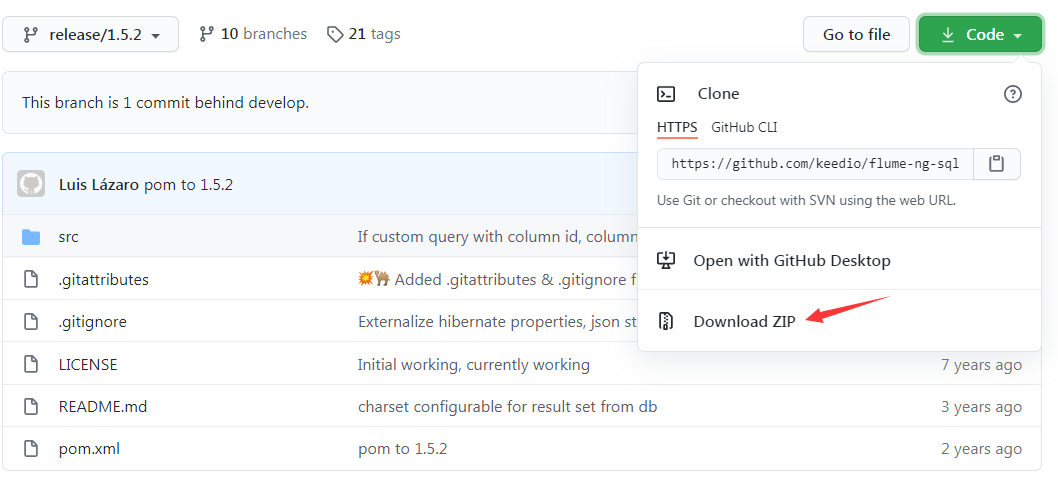
图2 github网站页面
打开一个cmd窗口,执行如下命令执行编译打包:
> cd C:\flume-ng-sql-source-release-1.5.2
> C:\apache-maven-3.6.3\bin\mvn package编译打包过程会持续一段时间,最终,如果编译打包成功,会返回类似如下的信息:
[INFO] Building jar: c:\flume-ng-sql-source-release-1.5.2\target\flume-ng-sql-source-1.5.2-javadoc.jar
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 04:27 min
[INFO] Finished at: 2023-02-12T09:21:13+08:00
[INFO] ------------------------------------------------------------------------这时,在“C:\flume-ng-sql-source-release-1.5.2\target”目录下,可以看到一个JAR包文件flume-ng-sql-source-1.5.2.jar,把这个文件复制到Flume安装目录的lib子目录下(比如“C:\apache-flume-1.9.0-bin\lib”)。
flume-ng-sql-source-1.5.2.jar文件也可以直接从林子雨编著《数据采集与预处理》教材官网的“下载专区”的“软件”目录下下载。
此外,为了让Flume能够顺利连接MySQL数据库,还需要用到一个连接驱动程序JAR包。可以访问MySQL官网(https://dev.mysql.com/downloads/connector/j/?os=26 )下载驱动程序压缩文件mysql-connector-java-8.0.23.tar.gz(也可以到林子雨编著《数据采集与预处理》教材官网的“下载专区”的“软件”目录下下载),然后,对该压缩文件进行解压缩,在解压后的目录中,找到文件mysql-connector-java-8.0.23.jar,把这个文件复制到Flume安装目录的lib子目录下(比如“C:\apache-flume-1.9.0-bin\lib”)。
五、创建MySQL数据库
参照林子雨编著《数据采集与预处理》教材第2章中关于MySQL数据库的内容,完成MySQL的安装,并学习其基本使用方法,这里假设读者已经成功安装了MySQL数据库并掌握了基本的使用方法。在Windows系统中,启动MySQL服务进程,然后,打开MySQL的命令行客户端,执行如下SQL语句创建数据库和表:
mysql>CREATE DATABASE school;
mysql> USE school;
mysql> CREATE TABLE student(
-> id INT NOT NULL,
-> name VARCHAR(40),
-> age INT,
-> grade INT,
-> PRIMARY KEY (id));
需要注意的是,在创建表的时候,一定要设置一个主键(比如,这里id是主键),否则后面Flume会捕捉数据失败。
六、使用Flume同步MySQL数据到Kafka
在Windows系统中打开第1个cmd窗口,执行如下命令启动Zookeeper服务:
> cd c:\kafka_2.12-2.4.0
> .\bin\windows\zookeeper-server-start.bat .\config\zookeeper.Properties打开第2个cmd窗口,然后执行下面命令启动Kafka服务:
> cd c:\kafka_2.12-2.4.0
> .\bin\windows\kafka-server-start.bat .\config\server.properties打开第3个cmd窗口,执行如下命令创建一个名为test的Topic:
> cd c:\kafka_2.12-2.4.0
> .\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testTopic执行如下命令查看testTopic是否创建成功:
> .\bin\windows\kafka-topics.bat --list --zookeeper localhost:2181打开第4个cmd窗口,执行如下命令启动Flume:
> cd c:\apache-flume-1.9.0-bin
> .\bin\flume-ng.cmd agent --conf ./conf --conf-file ./conf/mysql_kafka.conf --name a1 -property flume.root.logger=INFO,console然后,在MySQL命令行客户端中执行如下语句向MySQL数据库中插入数据:
mysql> insert into student(id,name,age,grade) values(1,'Xiaoming',23,98)
mysql> insert into student(id,name,age,grade) values(2,'Zhangsan',24,96);
mysql> insert into student(id,name,age,grade) values(3,'Lisi',24,93);打开第5个cmd窗口,执行如下命令:
> cd c:\kafka_2.12-2.4.0
> .\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic testTopic --from-beginning上面命令执行以后,就可以在屏幕上看到如图3所示数据。

图3 Kafka收到的数据