访问林子雨编著《数据采集与预处理》教材官网
在Linux系统中使用PyCharm编写Scrapy爬虫程序爬取古诗词网站,本节内容是林子雨编著《数据采集与预处理》教材第78页3.7.3 Scrapy框架应用实例。
首先,需要学习博客“在Linux系统中安装和使用PyCharm”,学习完以后再开始下面的实验内容。
1.新建工程
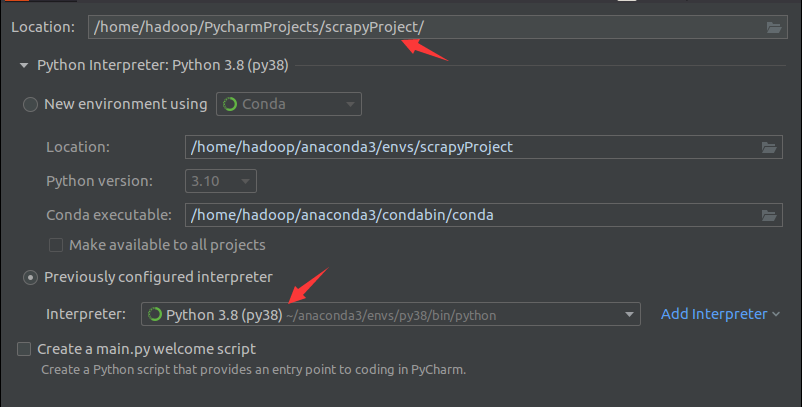
在PyCharm中新建一个名称为“scrapyProject”的工程,如下图所示,Python解释器就选择我们之前已经安装好的Anaconda中的Python3.8环境:
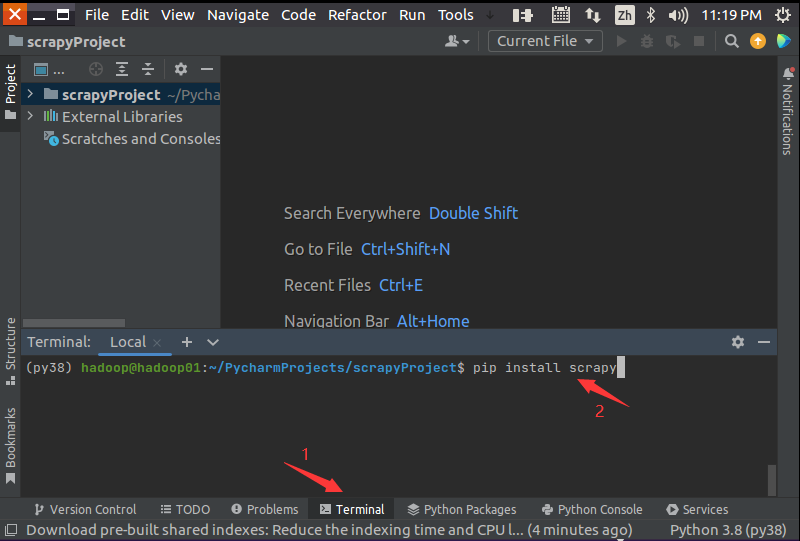
在“scrapyProject”工程底部打开Terminal窗口(如下图所示),在命令提示符后面输入命令“pip install scrapy”,下载Scrapy框架所需文件。
下载完成后,继续在Linux终端中输入命令“scrapy startproject poemScrapy”,创建Scrapy爬虫框架相关目录和文件。创建完成以后的具体目录结构如下图所示,这些目录和文件都是由Scrapy框架自动创建的,不需要手动创建。
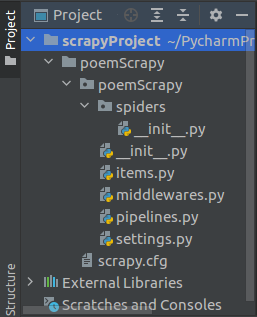
在Scrapy爬虫程序目录结构中,各个目录和文件的作用如下:
(1)Spiders目录:该目录下包含爬虫文件,需编码实现爬虫过程;
(2)init.py:为Python模块初始化目录,可以什么都不写,但是必须要有;
(3)items.py:模型文件,存放了需要爬取的字段;
(4)middlewares.py:中间件(爬虫中间件、下载中间件),本案例中不用此文件;
(5)pipelines.py:管道文件,用于配置数据持久化,例如写入数据库;
(6)settings.py:爬虫配置文件;
(7)scrapy.cfg:项目基础设置文件,设置爬虫启用功能等。在本案例中不用此文件。
2.编写代码文件items.py
在items.py中定义字段用于保存数据,items.py的具体代码内容如下:
import scrapy
class PoemscrapyItem(scrapy.Item):
# 名句
sentence = scrapy.Field()
# 出处
source = scrapy.Field()
# 全文链接
url = scrapy.Field()
# 名句详细信息
content = scrapy.Field()3.编写爬虫文件
在Terminal窗口输入命令“cd poemScrapy”,进入对应的爬虫工程中,再输入命令“scrapy genspider poemSpider gushiwen.cn”,这时,在spiders目录下会出现一个新的Python文件poemSpider.py,该文件就是我们要编写爬虫程序的位置。下面是poemSpider.py的具体代码:
import scrapy
from scrapy import Request
from ..items import PoemscrapyItem
class PoemspiderSpider(scrapy.Spider):
name = 'poemSpider' # 用于区别不同的爬虫
allowed_domains = ['gushiwen.cn'] # 允许访问的域
start_urls = ['http://so.gushiwen.cn/mingjus/'] # 爬取的地址
def parse(self, response):
# 先获每句名句的div
for box in response.xpath('//*[@id="html"]/body/div[2]/div[1]/div[2]/div'):
# 获取每句名句的链接
url = 'https://so.gushiwen.cn' + box.xpath('.//@href').get()
# 获取每句名句内容
sentence = box.xpath('.//a[1]/text()') .get()
# 获取每句名句出处
source = box.xpath('.//a[2]/text()') .get()
# 实例化容器
item = PoemscrapyItem()
# 将收集到的信息封装起来
item['url'] = url
item['sentence'] = sentence
item['source'] = source
# 处理子页
yield scrapy.Request(url=url, meta={'item': item}, callback=self.parse_detail)
# 翻页
next = response.xpath('//a[@class="amore"]/@href'). get()
if next is not None:
next_url = 'https://so.gushiwen.cn' + next
# 处理下一页内容
yield Request(next_url)
def parse_detail(self, response):
# 获取名句的详细信息
item = response.meta['item']
content_list = response.xpath('//div[@class="contson"]//text()').getall()
content = "".join(content_list).strip().replace('\n', '').replace('\u3000', '')
item['content'] = content
yield item4.编写代码文件pipelines.py
当我们成功获取需要的信息后,要对信息进行存储。在Scrapy爬虫框架中,当item被爬虫收集完后,将会被传递到pipelines。现在要将爬取到的数据保存到文本文件中,可以使用的pipelines.py代码:
import json
class PoemscrapyPipeline:
def __init__(self):
# 打开文件
self.file = open('data.txt', 'w', encoding='utf-8')
def process_item(self, item, spider):
# 读取item中的数据
line = json.dumps(dict(item), ensure_ascii=False) + '\n'
# 写入文件
self.file.write(line)
return item5.编写代码文件settings.py
settings.py的具体代码如下:
BOT_NAME = 'poemScrapy'
SPIDER_MODULES = ['poemScrapy.spiders']
NEWSPIDER_MODULE = 'poemScrapy.spiders'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4421.5 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# 设置日志打印的等级
LOG_LEVEL = 'WARNING'
ITEM_PIPELINES = {
'poemScrapy.pipelines.PoemscrapyPipeline': 1,
}6.运行程序
有两种执行Scrapy爬虫的方法,第一种是在Terminal窗口中输入命令“scrapy crawl poemSpider”,然后回车运行,等待几秒钟后即可完成数据的爬取。第二种是在poemScrapy目录下新建Python文件run.py(run.py应与scrapy.cfg文件在同一层目录下),并输入下面代码:
from scrapy import cmdline
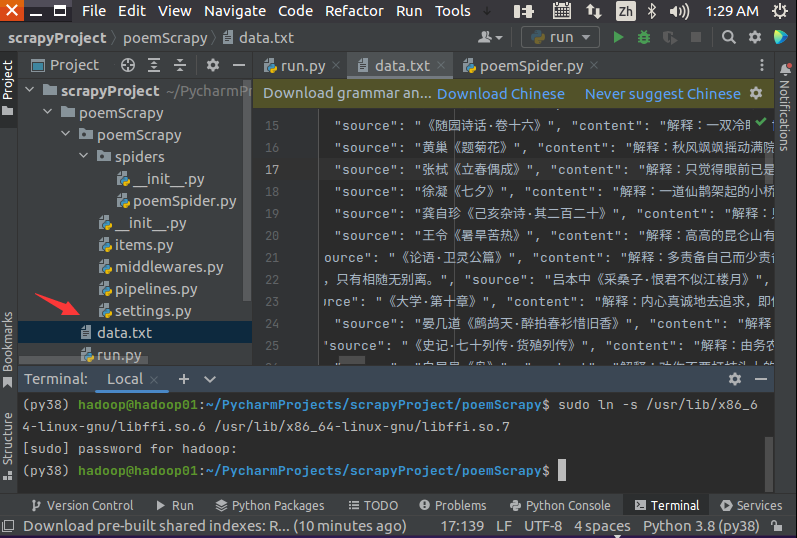
cmdline.execute("scrapy crawl poemSpider".split())在run.py代码区域点击鼠标右键,在弹出的菜单里选择“Run”运行代码,就可以执行Scrapy爬虫程序。执行成功以后,就可以看到生成的数据文件data.txt。
需要注意的是,上面程序运行可能会失败,可能会弹出如下错误消息:
ImportError: libffi.so.7: cannot open shared object file: No such file or direct解决这个问题的方法是,在Terminal窗口中输入如下命令:
find /usr/lib -name "libffi.so*"这时,你会发现,在系统的/usr/lib目录下确实不存在libffi.so.7,但是,有存在libffi.so.6,所以,我们可以执行如下命令建立一个软链接:
sudo ln -s /usr/lib/x86_64-linux-gnu/libffi.so.6 /usr/lib/x86_64-linux-gnu/libffi.so.7然后,再去执行爬虫程序,就可以成功了。
执行成功以后可以看到新生成一个data.txt文件,效果如下图所示: