【版权声明】版权所有,严禁转载,严禁用于商业用途,侵权必究。
作者:厦门大学信息学院智能科学系2019级研究生 王颖敏
指导老师:厦门大学数据库实验室 林子雨 博士/副教授
相关教材:林子雨、郑海山、赖永炫编著《Spark编程基础(Python版)》(访问教材官网)
相关案例:基于Python语言的Spark数据处理分析案例集锦(PySpark)
本实验采用Python语言,使用大数据处理框架Spark对数据进行处理分析,并对分析结果进行可视化。
一、实验环境
(1)Linux: Ubuntu 16.04
(2)Python: 3.6
(3)Spark: 2.4.0 (查看安装教程)
(4)Jupyter Notebook (查看安装和使用方法教程)
安装完上述环境以后,为了支持Python可视化分析,还需要执行如下命令安装新的组件:
pip install matplotlib
sudo apt-get install python3-tk
二、数据集
本次实验数使用的数据集是来自Kaggle的Yelp数据集。这里选择了其中的yelp_academic_dataset_business.json数据集。
数据集下载链接为:https://www.kaggle.com/yelp-dataset/yelp-dataset
或百度网盘地址1:https://pan.baidu.com/s/1FmUO1NWC0DTLZKG6ih6TYQ (提取码:mber),
或百度网盘地址2:https://pan.baidu.com/s/1I2MBR7nYDKFOLe2FW96zTQ (提取码:61im)
数据集为json 格式,每个数据包含以下字段:
字段名称 含义 数据格式 例子
business_id 商家ID string "business_id": "tnhfDv5Il8EaGSXZGiuQGg"
name 商家名称 string "name": "Garaje"
address 商家地址 string "address": "475 3rd St"
city 商家所在城市 string "city": "San Francisco"
state 商家所在洲 string "state": "CA"
postal code 邮编 string "postal code": "94107"
latitude 维度 float "latitude": 37.7817529521
longitude 经度 float "longitude": -122.39612197
stars 星级评分 float "stars": 4.5
review_count 评论个数 integer "review_count": 1198
is_open 商家是否营业
0:关闭, 1:营业 integer "is_open": 1
attributes 商家业务(外卖,business parking) object "attributes": {
"RestaurantsTakeOut": true,
"BusinessParking": {
"garage": false,
"street": true,
"validated": false,
"lot": false,
"valet": false
},
}
categories 商家所属类别 array "categories": [
"Mexican",
"Burgers",
"Gastropubs"
]
hours 商家营业时间 dict "hours": {
"Monday": "10:00-21:00",
"Tuesday": "10:00-21:00",
"Friday": "10:00-21:00",
"Wednesday": "10:00-21:00",
"Thursday": "10:00-21:00",
"Sunday": "11:00-18:00",
"Saturday": "10:00-21:00"
}
三、步骤概述
(1)第1步:使用代码文件business_process.py, 对数据进行预处理,剔除异常值。
(2)第2步:使用代码文件business_analysis.py, 对处理后的数据进行数据分析。
(3)第3步:使用代码文件business_visual.py, 对分析结果进行可视化。
四、详细代码
1.数据预处理
使用代码文件business_process.py, 对数据进行预处理,剔除异常值。business_process.py的代码内容如下:
from pyspark import SparkConf
from pyspark.sql import SparkSession
import pyspark.sql.functions as f
def data_process(raw_data_path):
spark = SparkSession.builder.config(conf=SparkConf()).getOrCreate()
business = spark.read.json(raw_data_path)
split_col = f.split(business['categories'], ',')
business = business.withColumn("categories", split_col).filter(business["city"] != "").dropna()
business.createOrReplaceTempView("business")
b_etl = spark.sql("SELECT business_id, name, city, state, latitude, longitude, stars, review_count, is_open, categories, attributes FROM business").cache()
b_etl.createOrReplaceTempView("b_etl")
outlier = spark.sql(
"SELECT b1.business_id, SQRT(POWER(b1.latitude - b2.avg_lat, 2) + POWER(b1.longitude - b2.avg_long, 2)) \
as dist FROM b_etl b1 INNER JOIN (SELECT state, AVG(latitude) as avg_lat, AVG(longitude) as avg_long \
FROM b_etl GROUP BY state) b2 ON b1.state = b2.state ORDER BY dist DESC")
outlier.createOrReplaceTempView("outlier")
joined = spark.sql("SELECT b.* FROM b_etl b INNER JOIN outlier o ON b.business_id = o.business_id WHERE o.dist<10")
joined.write.parquet("file:///home/hadoop/wangyingmin/yelp-etl/business_etl", mode="overwrite")
if __name__ == "__main__":
raw_hdfs_path = 'file:///home/hadoop/wangyingmin/yelp_academic_dataset_business.json'
print("Start cleaning raw data!")
data_process(raw_hdfs_path)
print("Successfully done")
在上述代码中,使用“距离洲内商家平均位置的欧式距离”来除去离群值。
2.数据分析
使用代码文件business_analysis.py, 对处理后的数据进行数据分析。
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
import pyspark.sql.functions as f
import os
def attribute_score(attribute):
att = spark.sql("SELECT attributes.{attr} as {attr}, category, stars FROM for_att".format(attr=attribute)).dropna()
att.createOrReplaceTempView("att")
att_group = spark.sql("SELECT {attr}, AVG(stars) AS stars FROM att GROUP BY {attr} ORDER BY stars".format(attr=attribute))
att_group.show()
att_group.write.json("file:///usr/local/spark/yelp/analysis/{attr}".format(attr=attribute), mode='overwrite')
def analysis(data_path):
spark = SparkSession.builder.config(conf=SparkConf()).getOrCreate()
business = spark.read.parquet(data_path).cache()
business.createOrReplaceTempView("business")
part_business = spark.sql("SELECT state, city, stars, review_count, explode(categories) AS category FROM business").cache()
part_business.show()
part_business.createOrReplaceTempView('part_business_1')
part_business = spark.sql("SELECT state, city, stars, review_count, REPLACE(category, ' ','')as new_category FROM part_business_1")
part_business.createOrReplaceTempView('part_business')
print("## All distinct categories")
all_categories = spark.sql("SELECT business_id, explode(categories) AS category FROM business")
all_categories.createOrReplaceTempView('all_categories')
distinct = spark.sql("SELECT COUNT(DISTINCT(new_category)) FROM part_business")
distinct.show()
print("## Top 10 business categories")
top_cat = spark.sql("SELECT new_category, COUNT(*) as freq FROM part_business GROUP BY new_category ORDER BY freq DESC")
top_cat.show(10)
top_cat.write.json("file:///usr/local/spark/yelp/analysis/top_category", mode='overwrite')
print("## Top business categories - in every city")
top_cat_city = spark.sql("SELECT city, new_category, COUNT(*) as freq FROM part_business GROUP BY city, new_category ORDER BY freq DESC")
top_cat_city.show()
top_cat.write.json("file:///usr/local/spark/yelp/analysis/top_category_city", mode='overwrite')
print("## Cities with most businesses")
bus_city = spark.sql("SELECT city, COUNT(business_id) as no_of_bus FROM business GROUP BY city ORDER BY no_of_bus DESC")
bus_city.show(10)
bus_city.write.json("file:///usr/local/spark/yelp/analysis/top_business_city", mode='overwrite')
print("## Average review count by category")
avg_city = spark.sql(
"SELECT new_category, AVG(review_count)as avg_review_count FROM part_business GROUP BY new_category ORDER BY avg_review_count DESC")
avg_city.show()
avg_city.write.json("file:///usr/local/spark/yelp/analysis/average_review_category", mode='overwrite')
print("## Average stars by category")
avg_state = spark.sql(
"SELECT new_category, AVG(stars) as avg_stars FROM part_business GROUP BY new_category ORDER BY avg_stars DESC")
avg_state.show()
avg_state.write.json("file:///usr/local/spark/yelp/analysis/average_stars_category", mode='overwrite')
print("## Data based on Attribute")
for_att = spark.sql("SELECT attributes, stars, explode(categories) AS category FROM business")
for_att.createOrReplaceTempView("for_att")
attribute = 'RestaurantsTakeout'
attribute_score(attribute)
if __name__ == "__main__":
business_data_path = 'file:///home/hadoop/wangyingmin/yelp-etl/business_etl'
print("Start analysis data!")
analysis(business_data_path)
print("Analysis done")
在上述代码中,主要进行了以下方面的分析:
(1)商业类别
该项利用distinct() 函数从表 part_business 筛选出不同的商业类别,再利用count()函数计算出所有类别的个数。对应的代码如下:
distinct = spark.sql("SELECT COUNT(DISTINCT(new_category)) FROM part_business")
(2)美国10种主要的商业类别
该项利用group by对商业类别进行聚合并统计出每个类别的数量, 然后利用order by根据统计数量的数量进行排序, 最后展示出数量最多的10个商业类别。对应的代码如下:
top_cat = spark.sql("SELECT new_category, COUNT(*) as freq FROM \ part_business GROUP BY new_category ORDER BY freq DESC")
top_cat.show(10)
(3)每个城市各种商业类型的商家数量
该项利用group by对城市,商业类别进行聚合并统计出每个城市每种商业类别的数量, 然后利用order by根据统计数量的数量进行排序, 最后展示出每个城市各种商业类型的商家数量。对应的代码如下:
top_cat_city = spark.sql("SELECT city, new_category, COUNT(*) as freq \
FROM part_business GROUP BY city, new_category ORDER BY freq DESC")
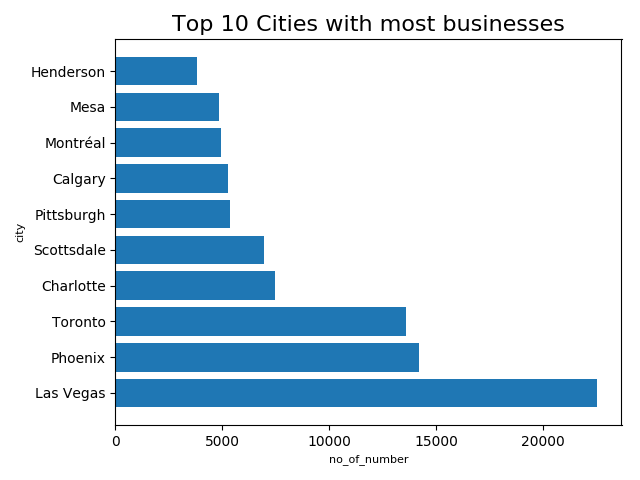
(4)商家数量最多的10个城市
因为每个business_id对应每一家店,所以我们利用count()函数对business_id进行统计,得到每个城市的店家数量,利用order by对每个城市的商家数量进行排序,得到商家数量最多的10个城市。对应的代码如下:
bus_city = spark.sql("SELECT city, COUNT(business_id) as no_of_bus FROM \ business GROUP BY city ORDER BY no_of_bus DESC")
bus_city.show(10)
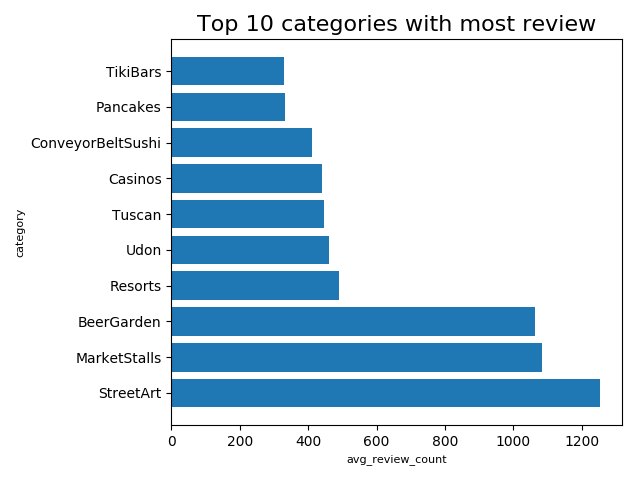
(5)消费者评价最多的10种商业类别
该项利用group by 对商业类别进行聚合, 同时利用avg()函数统计消费者对每个商业类别的平均评价数量,最后利用order by对平均评价数量进行排序,可以得到评价最多的10种商业类别.对应的代码如下:
avg_city = spark.sql(
"SELECT new_category, AVG(review_count)as avg_review_count FROM \ part_business GROUP BY new_category ORDER BY avg_review_count DESC")
(6)最受消费者喜欢的前10种商业类型
该项利用group by 对商业类别进行聚合, 同时利用avg()函数统计每个商业类别的平均星级评分,最后利用order by对平均星级评分进行排序,可以得到星级评分最高的10种商业类别,即最受消费者喜欢的商业类型.对应的代码如下:
avg_state = spark.sql(
"SELECT new_category, AVG(stars) as avg_stars FROM part_business \
GROUP BY new_category ORDER BY avg_stars DESC")
avg_state.show()
(7)商业额外业务的评价情况
由于字段 attribute 中的RestaurantsTakeout可能NULL的情况,所以需要利用dropna()处理缺失值的问题。该项对商家是否有’Take out’服务进行分析,统计出两种不同情况的商家的平均星级评分.对应的代码如下:
def attribute_score(attribute):
att = spark.sql("SELECT attributes.{attr} as {attr}, category, stars \
FROM for_att".format(attr=attribute)).dropna()
att.createOrReplaceTempView("att")
att_group = spark.sql("SELECT {attr}, AVG(stars) AS stars FROM att \
GROUP BY {attr} ORDER BY stars".format(attr=attribute))
att_group.show()
3.数据可视化
使用代码文件business_visual.py, 对分析结果进行可视化。
import json
import os
import pandas as pd
import matplotlib.pyplot as plt
AVE_REVIEW_CATEGORY = '/usr/local/spark/yelp/analysis/average_review_category'
OPEN_CLOSE = '/usr/local/spark/yelp/analysis/open_close'
TOP_CATEGORY_CITY = '/usr/local/spark/yelp/analysis/top_category_city'
TOP_BUSINESS_CITY = '/usr/local/spark/yelp/analysis/top_business_city'
TOP_CATEGORY = '/usr/local/spark/yelp/analysis/top_category'
AVE_STARS_CATEGORY = '/usr/local/spark/yelp/analysis/average_stars_category'
TAKEOUT = '/usr/local/spark/yelp/analysis/RestaurantsTakeout'
def read_json(file_path):
json_path_names = os.listdir(file_path)
data = []
for idx in range(len(json_path_names)):
json_path = file_path + '/' + json_path_names[idx]
if json_path.endswith('.json'):
with open(json_path) as f:
for line in f:
data.append(json.loads(line))
return data
if __name__ == '__main__':
ave_review_category_list = read_json(AVE_REVIEW_CATEGORY)
open_close_list = read_json(OPEN_CLOSE)
top_category_city_list = read_json(TOP_CATEGORY_CITY)
top_business_city_list = read_json(TOP_BUSINESS_CITY)
top_category_list = read_json(TOP_CATEGORY)
ave_stars_category_list = read_json(AVE_STARS_CATEGORY)
takeout_list = read_json(TAKEOUT)
top_category_list.sort(key=lambda x: x['freq'], reverse=True)
top_category_key = []
top_category_value = []
for idx in range(10):
one = top_category_list[idx]
top_category_key.append(one['new_category'])
top_category_value.append(one['freq'])
plt.barh(top_category_key[:10], top_category_value[:10], tick_label=top_category_key[:10])
plt.title('Top 10 Categories', size = 16)
plt.xlabel('Frequency',size =8, color = 'Black')
plt.ylabel('Category',size = 8, color = 'Black')
plt.tight_layout()
top_business_city_list.sort(key=lambda x: x['no_of_bus'], reverse=True)
top_business_city_key = []
top_business_city_value = []
for idx in range(10):
one = top_business_city_list[idx]
top_business_city_key.append(one['no_of_bus'])
top_business_city_value.append(one['city'])
"""
plt.barh(top_business_city_value[:10], top_business_city_key[:10], tick_label=top_business_city_value[:10])
plt.title('Top 10 Cities with most businesses', size = 16)
plt.xlabel('no_of_number',size =8, color = 'Black')
plt.ylabel('city',size = 8, color = 'Black')
plt.tight_layout()
"""
ave_review_category_list.sort(key=lambda x: x['avg_review_count'], reverse=True)
ave_review_category_key = []
ave_review_category_value = []
for idx in range(10):
one = ave_review_category_list[idx]
ave_review_category_key.append(one['avg_review_count'])
ave_review_category_value.append(one['new_category'])
"""
plt.barh(ave_review_category_value[:10], ave_review_category_key[:10], tick_label=ave_review_category_value[:10])
plt.title('Top 10 categories with most review', size=16)
plt.xlabel('avg_review_count', size=8, color='Black')
plt.ylabel('category', size=8, color='Black')
plt.tight_layout()
"""
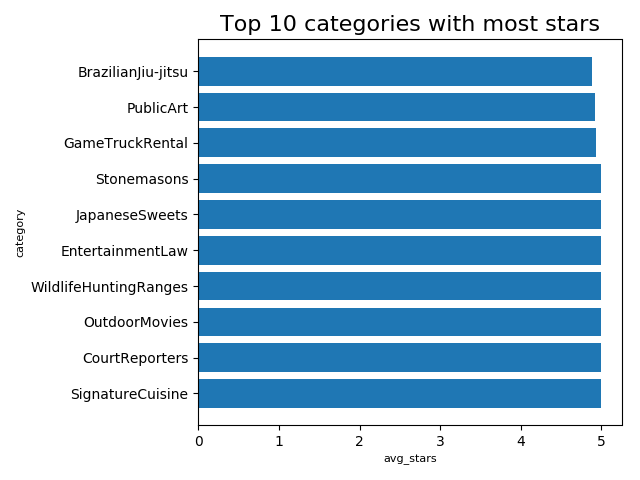
ave_stars_category_list.sort(key=lambda x: x['avg_stars'], reverse=True)
ave_stars_category_key = []
ave_stars_category_value = []
for idx in range(10):
one = ave_stars_category_list[idx]
ave_stars_category_key.append(one['avg_stars'])
ave_stars_category_value.append(one['new_category'])
"""
plt.barh(ave_stars_category_value[:10], ave_stars_category_key[:10], tick_label=ave_stars_category_value[:10])
plt.title('Top 10 categories with most stars', size=16)
plt.xlabel('avg_stars', size=8, color='Black')
plt.ylabel('category', size=8, color='Black')
plt.tight_layout()
"""
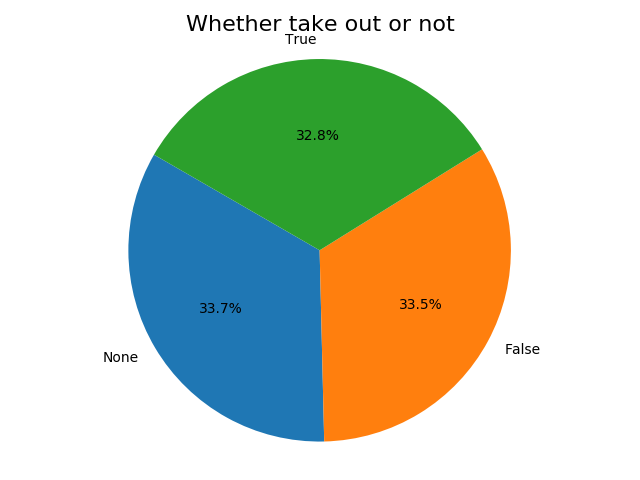
takeout_list.sort(key=lambda x: x['stars'], reverse=True)
takeout_key = []
takeout_value = []
for idx in range(len(takeout_list)):
one = takeout_list[idx]
takeout_key.append(one['stars'])
takeout_value.append(one['RestaurantsTakeout'])
"""
explode = (0,0,0)
plt.pie(takeout_key,explode=explode,labels=takeout_value, autopct='%1.1f%%',shadow=False, startangle=150)
plt.title('Whether take out or not', size=16)
plt.axis('equal')
plt.tight_layout()
"""
plt.show()
下面是可视化的效果。