
使用Jupyter Notebook调试PySpark程序
厦门大学计算机科学系数据库实验室 林子雨 博士/副教授 ziyulin@xmu.edu.cn
相关教材:林子雨、郑海山、赖永炫编著《Spark编程基础(Python版)》,访问教材官网(http://dblab.xmu.edu.cn/post/spark-python/)
一、Jupyter Notebook简介
名称 Jupyter 是由Julia、Python和R三个单词组合而成的。Jupyter Notebook是一种Web应用,它能让用户将说明文本、数学方程、代码和可视化内容全部组合到一个易于共享的文档中,非常方便研究和教学。Jupyter Notebook特别适合做数据处理,其用途可以包括数据清理和探索、可视化、机器学习和大数据分析。
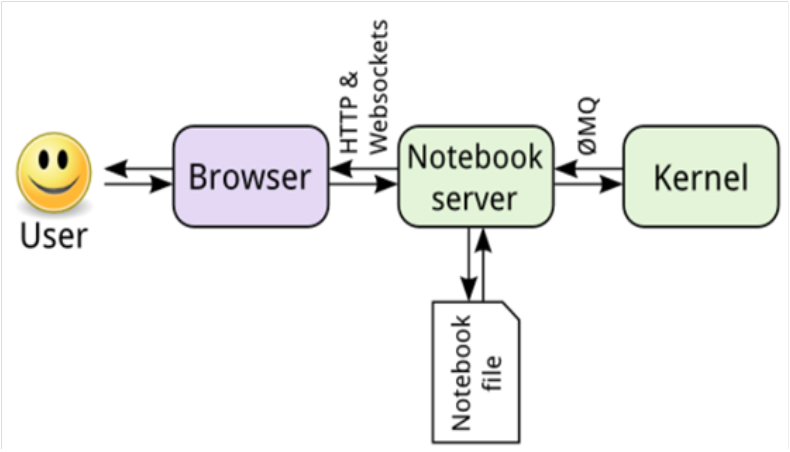
Jupyter notebook 的核心是 Notebook 的服务器。用户通过浏览器连接到该服务器,而 Notebook呈现为Web应用。用户在Web应用中编写的代码通过该服务器发送给内核,内核运行代码,并将结果发送回该服务器。然后,任何输出都会返回到浏览器中。保存 Notebook 时,它将作为 JSON 文件(文件扩展名为 .ipynb)写入到该服务器中。
二、安装Anaconda
Anaconda是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。Anaconda中已经集成了Jupyter Notebook,因此,可以首先安装Anaconda,然后再配置Jupyter Notebook。
第一种下载方式:Anaconda清华大学镜像下载:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
到达清华大学镜像网站以后,找到安装文件Anaconda3-2020.02-Linux-x86_64.sh,下载到本地即可。
第二种下载方式:Anaconda官网下载:https://www.anaconda.com/products/individual
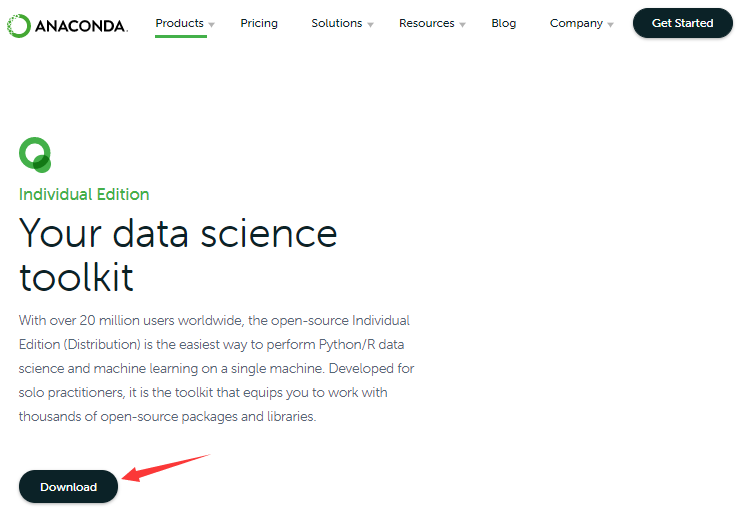
访问该网址以后,呈现如下网页,点击页面底部的“Download”。
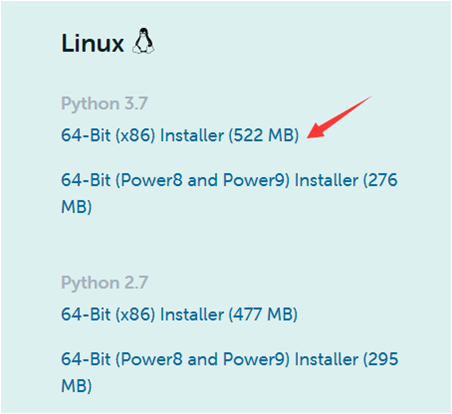
然后,出现如下所示页面,因为本教程是使用Linux系统,x86(64位),因此,点击“64-Bit(x86)Installer(522MB)”下载安装文件。
下载以后得到的安装文件是Anaconda3-2020.02-Linux-x86_64.sh,假设该安装文件已经被保存到了Linux系统(这里是Ubuntu16.04)的“/home/hadoop”目录下,执行如下命令开始安装Anaconda:
cd /home/hadoop
bash Anaconda3-2020.02-Linux-x86_64.sh
输入命令以后,如下图所示,会提示你查看许可文件,直接敲入回车即可。

敲入回车以后,会出现软件许可文件,这个文件很长,可以一直不断按回车,来翻到文件的末尾。
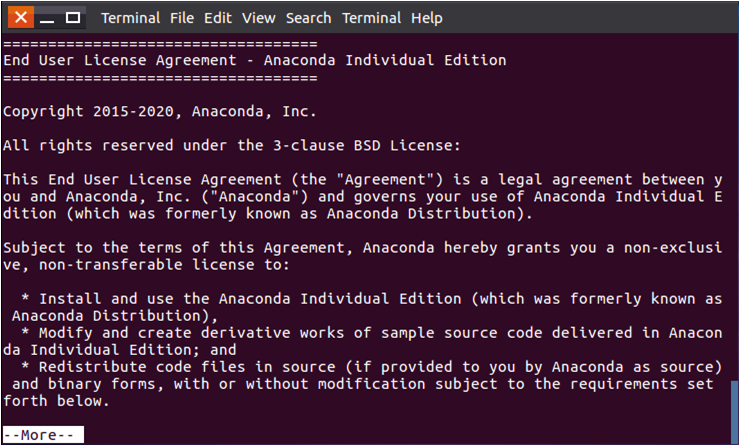
翻到许可文件末尾以后,会出现提示“是否接受许可条款”,输入yes后回车即可,如下图所示:

然后,会出现如下所示界面,提醒你选择安装路径,这里不要自己指定路径,直接回车就可以(回车后系统就会安装到默认路径,比如这里是/home/hadoop/anaconda3)。
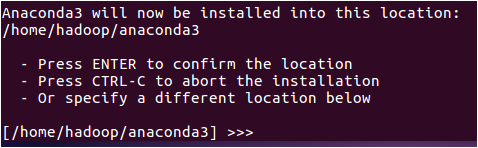
系统会提示你是否运行conda初始化,也就是设置一些环境变量,这里输入yes以后回车。

安装成功以后,可以看到如下信息。
安装结束后,要关闭当前终端。然后重新打开一个终端,输入命令:conda -V,可以查看版本信息,如下图所示。
可以查看Anaconda的版本信息,命令如下:
anaconda -V
命令执行效果如下:
这时,你会发现,在命令提示符的开头多了一个(base),看着很难受,可以在终端中运行如下命令,消除这个(base):
conda config --set auto_activate_base false
然后,关闭终端,再次新建一个终端,可以看到,已经没有(base)了。但是,这时,输入“anaconda -V”命令就会失败,提示找不到命令。如下图所示:
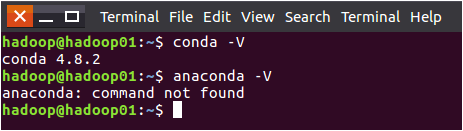
这时,需要到~/.bashrc文件中修改配置,执行如下命令打开文件:
vim ~/.bashrc
打开文件以后,按键盘上的i键,进入编辑状态,然后,在PATH环境配置中,把“/home/hadoop/anaconda3/bin”增加到PATH的末尾,也就是用英文冒号和PATH的其他部分连接起来,如下图所示:
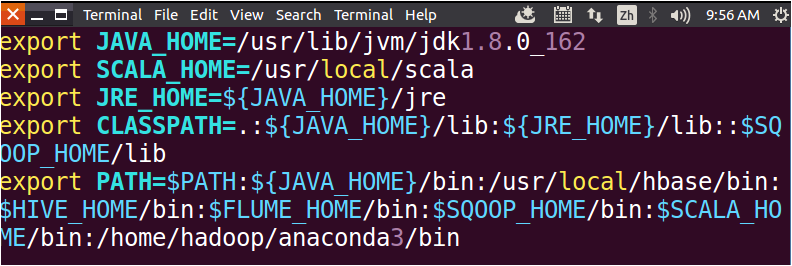
然后保存退出文件(先按Esc键退出文件编辑状态,再输入:wq(注意是英文冒号),再回车,就可以保存退出文件)。再执行如下命令使得配置立即生效:
source ~/.bashrc
执行完source命令以后,就可以成功执行“anaconda -V”命令了,如下图所示。
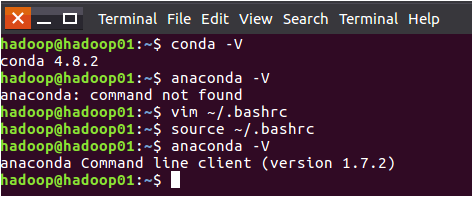
三、配置Jupyter Notebook
一般而言,安装了Anaconda发行版时,已经自动为你安装了Jupyter Notebook的,但是也可能有例外,万一如果没有自动安装,那么就在Linux终端中输入以下这一条命令安装(一定要明确知道你机器上没有安装Jupyter Notebook再执行下面命令,如果你无法确定是否已经安装Jupyter Notebook,那么就暂时不要执行下面这条命令,等到后面遇到问题的时候再来执行):
conda install jupyter notebook
假设Anaconda中已经自动安装好了Jupyter Notebook。下面开始配置Jupyter Notebook,在终端中执行如下命令:
jupyter notebook --generate-config
执行效果如下图所示。

然后,在终端中执行如下命令:
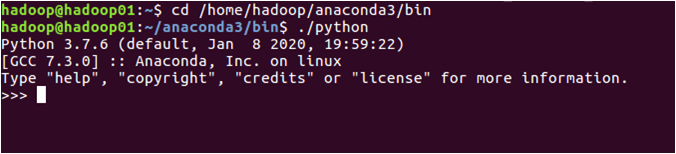
cd /home/hadoop/anaconda3/bin
./python
执行效果如下图所示。
然后,在Python命令提示符(不是Linux Shell命令提示符)后面输入如下命令:
>>>from notebook.auth import passwd
>>>passwd()
执行效果如下图所示。
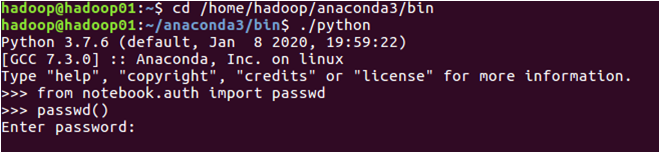
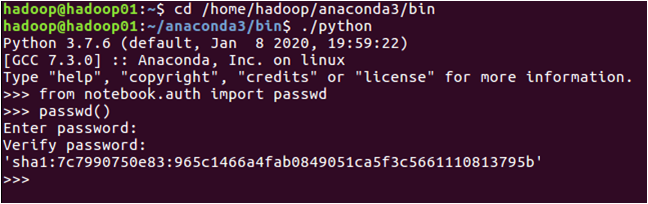
此时系统会让输入密码,并让你确认密码(如:123456),这个密码是后面进入到Jupyter网页页面的密码。然后系统会生成一个密码字符串,比如sha1:7c7990750e83:965c1466a4fab0849051ca5f3c5661110813795,把这个sha1字符串复制粘贴到一个文件中保存起来,后面用于配置密码。具体如下图所示:
然后,在Python命令提示符后面输入“exit()”,退出Python。如下图所示:

下面开始配置文件。
在终端输入如下命令:
vim ~/.jupyter/jupyter_notebook_config.py
命令执行效果如下图所示:

进入到配置文件页面,在文件的开头增加以下内容:
c.NotebookApp.ip='*' # 就是设置所有ip皆可访问
c.NotebookApp.password = 'sha1:7c7990750e83:965c1466a4fab0849051ca5f3c5661110813795b' # 上面复制的那个sha密文'
c.NotebookApp.open_browser = False # 禁止自动打开浏览器
c.NotebookApp.port =8888 # 端口
c.NotebookApp.notebook_dir = '/home/hadoop/jupyternotebook' #设置Notebook启动进入的目录
配置文件如下图所示:
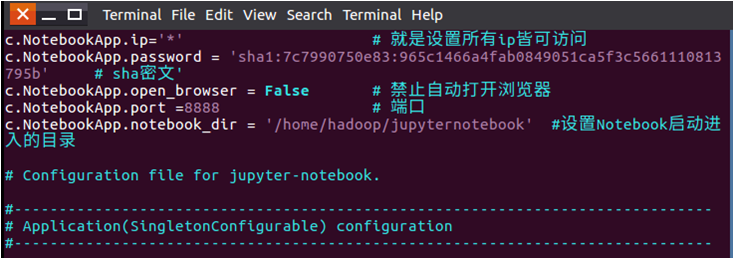
然后保存并退出vim文件(Esc键,输入:wq)
需要注意的是,在配置文件中,c.NotebookApp.password的值,就是刚才前面生成以后保存到文件中的sha1密文。另外,c.NotebookApp.notebook_dir = '/home/hadoop/jupyternotebook' 这行用于设置Notebook启动进入的目录,由于该目录还不存在,所以需要在终端中执行如下命令创建:
cd /home/hadoop
mkdir jupyternotebook
四、运行Jupyter Notebook
下面开始运行Jupyter Notebook。
在终端输入如下命令:
jupyter notebook
执行命令后出现如下效果:

打开浏览器,输入http://localhost:8888
会弹出对话框,输入Python密码123456,点击“Log in”,如下图所示。
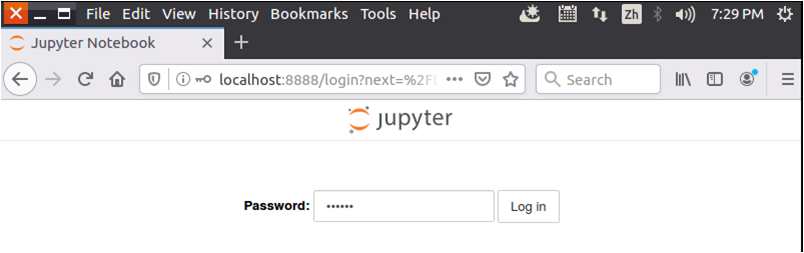
登录进去以后的界面如下图所示,这时,Jupyter Notebook的工作目录(/home/hadoop/jupyternotebook)下面没有任何文件。

可以在界面中点击“New”按钮,在弹出的子菜单中点击“Python3”,如下图所示。
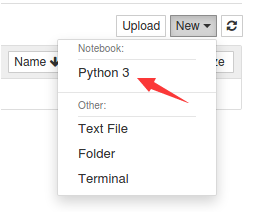
然后,会新出现一个网页,网页中包含代码文本框,可以在文本框中输入代码,比如“print(‘Hello Xiamen University’)”。
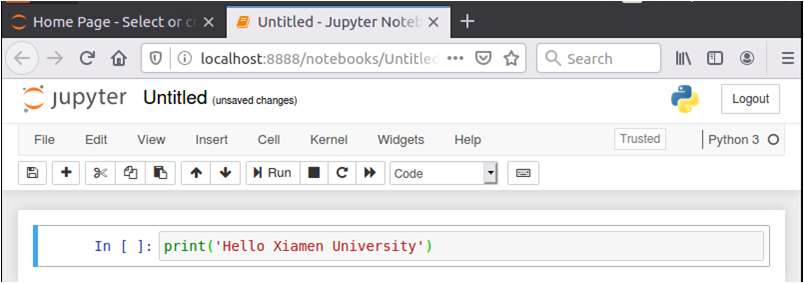
然后,如下图所示,点击“Run”按钮,就可以执行代码。
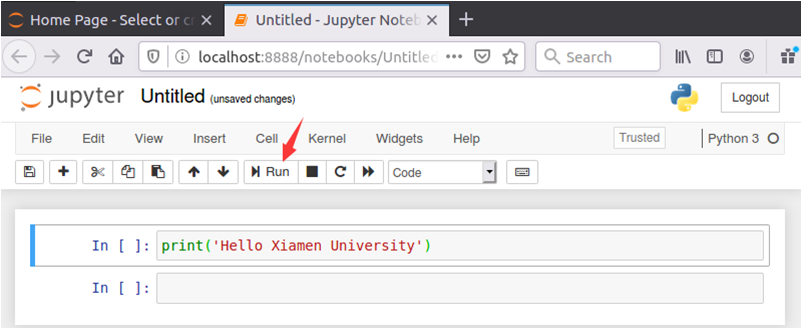
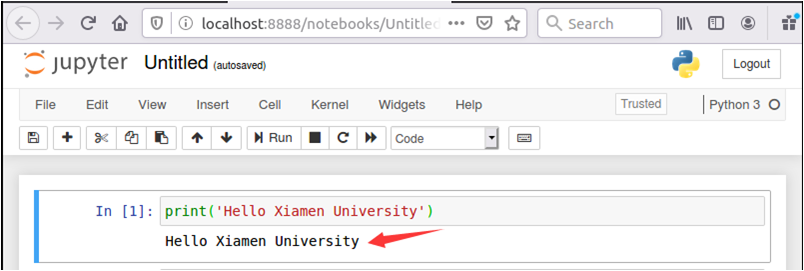
执行结果如下图所示:
要保存代码文件,可以点击界面中的“File”菜单,在弹出的子菜单中点击“Save as...”,如下图所示:
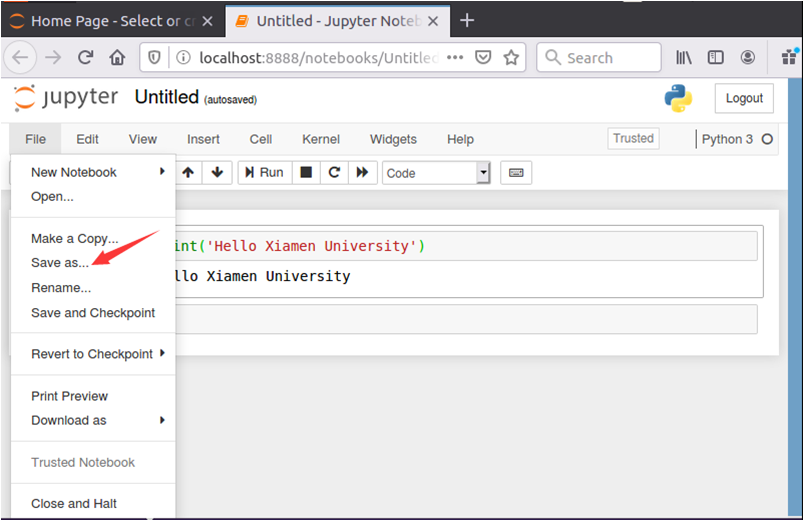
然后,在弹出的对话框中,输入文件名称,比如“HelloXMU”,然后点击“Save”按钮,如下图所示:
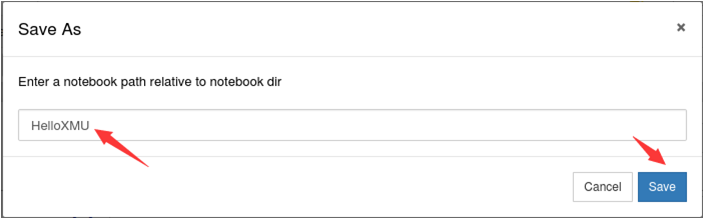
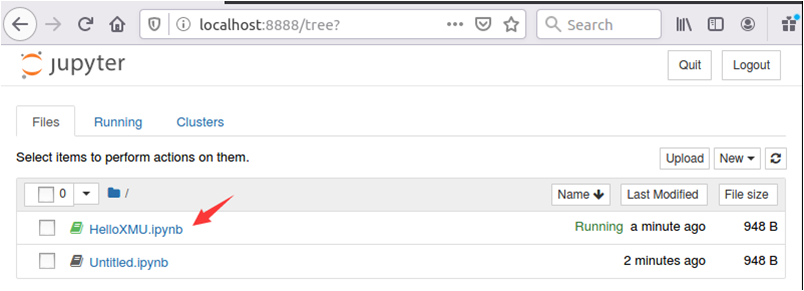
然后,切换到首页,在目录下就可以看到新生成的文件HelloXMU.ipynb。可以用鼠标点击这个文件名,进入这个文件的编辑状态。
五、配置Jupyter Notebook实现和PySpark交互
假设之前已经成功安装了Spark,并且可以顺利启动和使用PySpark。安装过程可以参考厦门大学数据库实验室网页:https://dblab.xmu.edu.cn/blog/1689-2/
下面配置Jupyter Notebook,让它实现和PySpark的交互。
在终端中输入如下命令:
vim ~/.bashrc
然后,在.bashrc文件中把原来已经存在的一行“export PYSPARK_PYTHON=python3”删除,然后,在该文件中增加如下两行:
export PYSPARK_PYTHON=/home/hadoop/anaconda3/bin/python
export PYSPARK_DRIVER_PYTHON=/home/hadoop/anaconda3/bin/python
增加后的效果如下图所示:

然后,保存退出该文件。然后执行如下命令让配置生效:
source ~/.bashrc
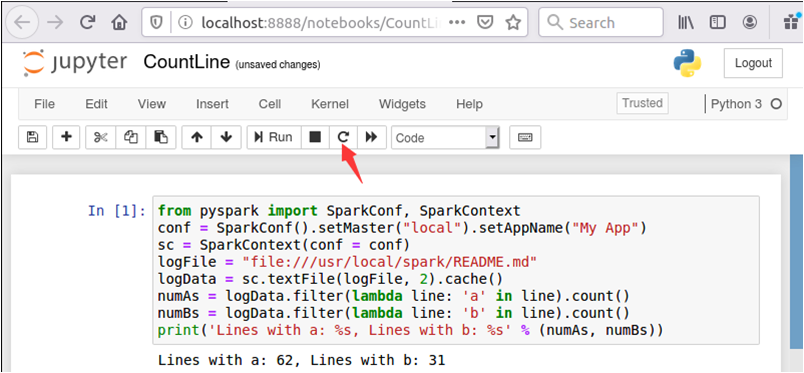
然后,在Jupyter Notebook首页中,点击“New”,再点击“Python3”,另外新建一个代码文件,把文件保存名称为CountLine,在文件中输入如下内容:
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf = conf)
logFile = "file:///usr/local/spark/README.md"
logData = sc.textFile(logFile, 2).cache()
numAs = logData.filter(lambda line: 'a' in line).count()
numBs = logData.filter(lambda line: 'b' in line).count()
print('Lines with a: %s, Lines with b: %s' % (numAs, numBs))
然后,点击界面上的“Run”按钮运行该代码,会出现统计结果“Lines with a: 62, Lines with b: 31”,执行效果如下:

注意,出现运行结果以后,不要再次点击“Run”按钮,如果再次点击“Run”按钮,会出现如下错误提示:

如果要再次运行代码,可以首先点击界面上的“刷新”按钮,如下图所示:
然后,会弹出如下图所示界面,可以点击“restart”按钮,重新启动。
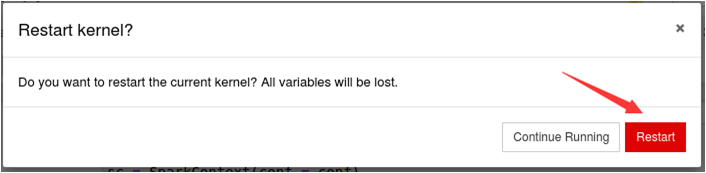
这时,再次去点击“Run”按钮,就可以成功得到结果了。
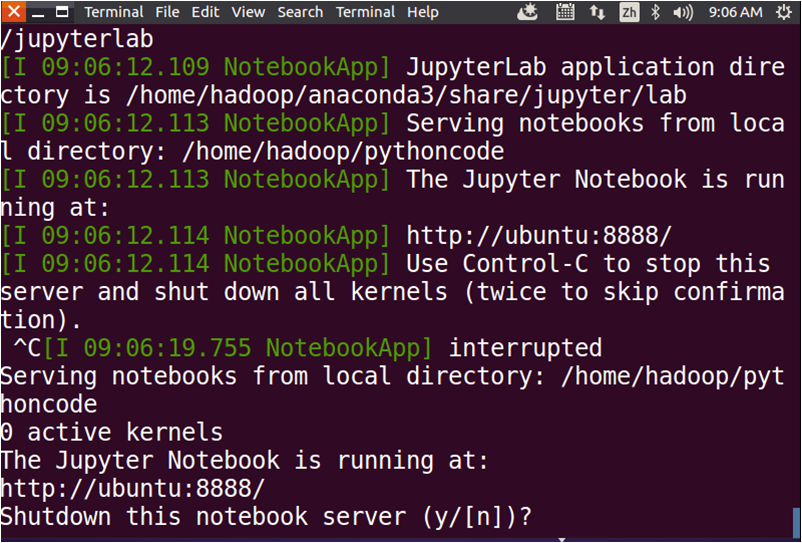
如果要关闭退出Jupyter Notebook,可以回到终端界面(正在运行Jupyter Notebook的界面),按Ctrl+C,出现提示,输入字母y,就可以退出了(如下图所示)。
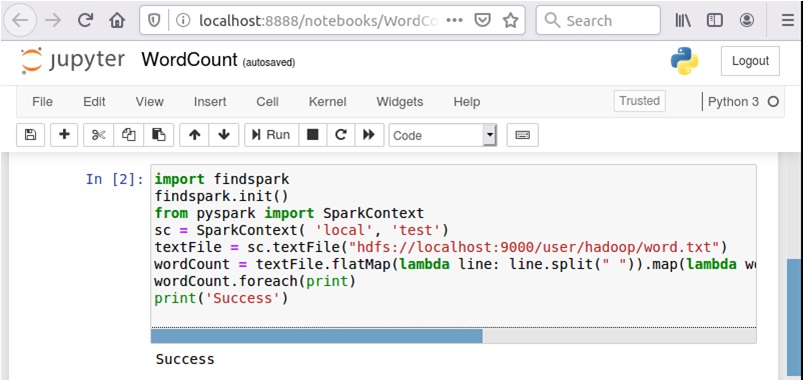
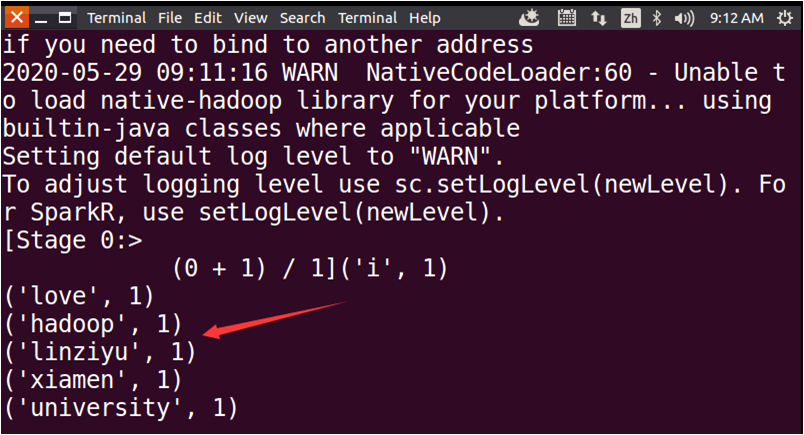
此外需要注意的是,在使用Jupyter Notebook调试PySpark程序时,有些代码的输出信息无法从网页上看到,需要到终端界面上查看。如下图所示,代码“wordCount.foreach(print)”的输出结果,是无法在网页上看到的。代码“print('Success')”的结果可以在网页上看到。
可以到运行Jupyter Notebook的终端界面上看到代码“wordCount.foreach(print)”的输出结果,如下图所示。
全文结束