
返回《在阿里云中搭建大数据实验环境》首页
现在介绍如何在阿里云ECS的Ubuntu系统中安装开发工具IntelliJ IDEA和Scala插件。
下载和安装IntelliJ IDEA
请在本地电脑中执行下载操作。笔者已经把IntelliJ IDEA安装包(版本号:2017.3.4)保存到了百度云盘中,可以点击这里直接从百度云盘下载文件ideaIC-2017.3.4.tar.gz(提取码:gx0b)。下载成功以后,可以在本地电脑,打开FTP软件,使用linziyu用户名登录到阿里云ECS的Ubuntu系统,把ideaIC-2017.3.4.tar.gz通过FTP软件上传到“/home/linziyu/Downloads”目录下。
然后,在本地电脑通过VNC Viewer连接远程的阿里云ECS实例中的Ubuntu系统,打开一个命令行终端,执行如下命令进行IntelliJ IDEA安装:
cd ~
sudo tar -zxvf /home/hadoop/download/ideaIC-2017.3.4.tar.gz -C /usr/local
cd /usr/local
sudo mv ./idea-IC-173.4548.28 ./idea
然后,使用ls命令查看目录的所有者:
linziyu@iZbp11gznj7n38xkztu64dZ:/usr/local$ ls -l idea
total 48
drwxr-xr-x 2 root root 4096 Apr 7 17:02 bin
-rw-r--r-- 1 root root 14 Jan 30 07:13 build.txt
-rw-r--r-- 1 root root 1909 Jan 30 07:13 Install-Linux-tar.txt
drwxr-xr-x 4 root root 4096 Apr 7 17:02 jre64
drwxr-xr-x 5 root root 4096 Apr 7 17:02 lib
drwxr-xr-x 2 root root 4096 Apr 7 17:02 license
-rw-r--r-- 1 root root 11352 Jan 30 07:13 LICENSE.txt
-rw-r--r-- 1 root root 128 Jan 30 07:13 NOTICE.txt
drwxr-xr-x 34 root root 4096 Apr 7 17:02 plugins
drwxr-xr-x 2 root root 4096 Apr 7 17:02 redist
可以看出,idea目录的所有者是root,下面使用如下命令修改目录所有者:
sudo chown -R linziyu:linziyu ./idea
下载Scala插件安装包
我们在Spark开发时,是使用Scala语言,所以,需要为IDEA工具安装Scala插件。
请在本地电脑中执行下载操作。笔者已经把Scala插件安装包保存到了百度云盘中,可以点击这里直接从百度云盘下载文件scala-intellij-bin-2017.3.4.zip(提取码:vsr2)。
或者,你也可以自己到Scala插件官网去下载。但是,一定要注意,Scala插件安装包的版本,一定要和自己电脑上安装的IntellJ IDEA的版本严格一致。笔者在本教程中安装的IDEA的版本是2017.3.4。
进入Scala插件官网以后,把网页往下拉一些,可以看到如下图所示的文件列表:
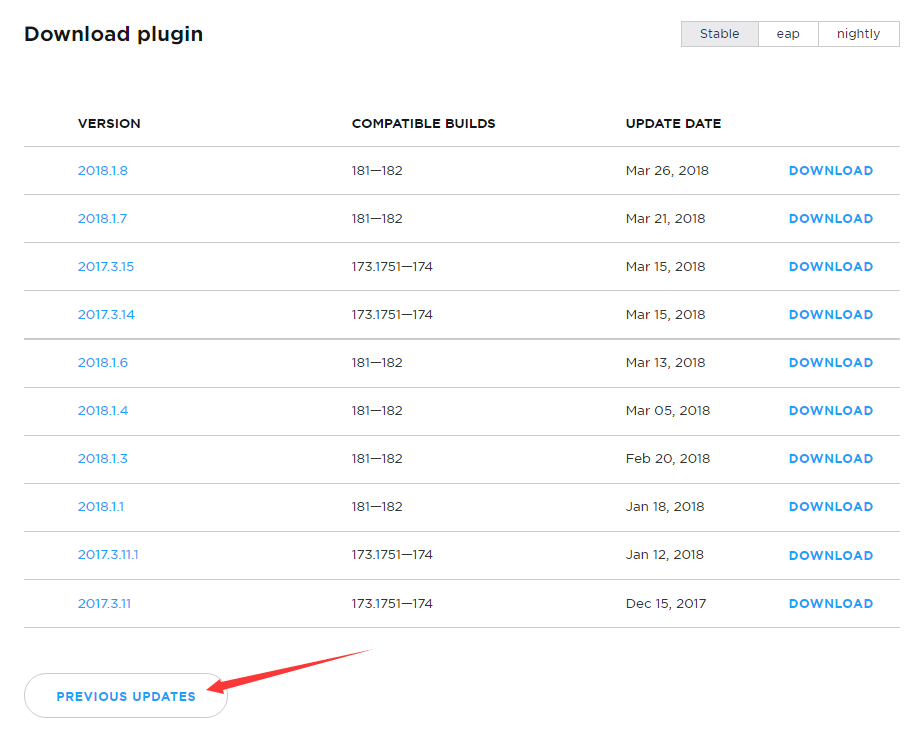
这个列表只是一部分版本,没有看到我们想要的2017.3.4这个版本,可以点击页面中的“PREVIOUS UPDATES”,显示更多的历史其他版本,如下图所示,就可以看到2017.3.4这个版本了,点击图中的“DOWNLOAD”按钮,把Scala插件安装包文件下载到本地电脑中,可以看到,下载后的文件名是scala-intellij-bin-2017.3.4.zip。
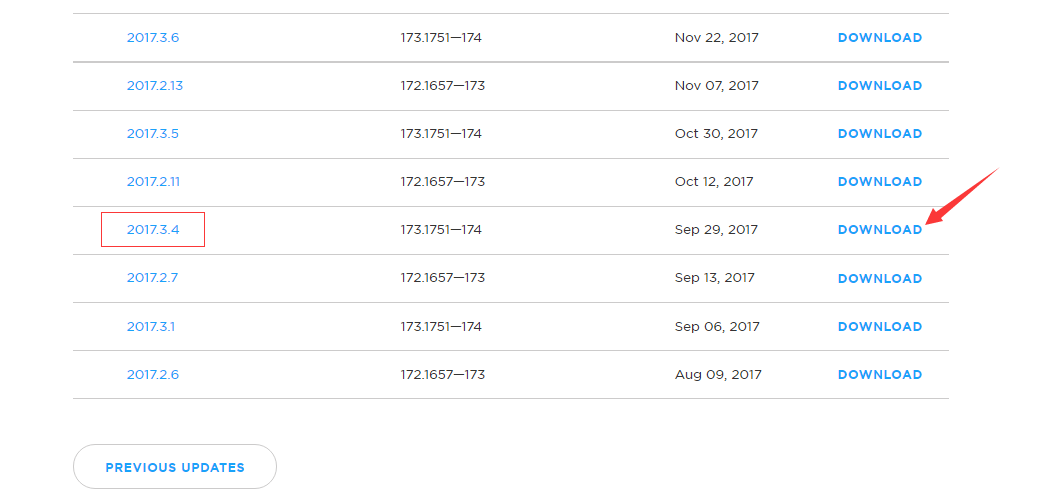
下载成功以后,可以在本地电脑,打开FTP软件,使用linziyu用户名登录到阿里云ECS的Ubuntu系统,把scala-intellij-bin-2017.3.4.zip通过FTP软件上传到“/home/linziyu/Downloads”目录下,后面我们会用到。
启动IDEA
然后,就可以启动开发工具IDEA了,使用如下命令启动:
cd /usr/local/idea
./bin/idea.sh
启动以后,会弹出如下界面,点击“OK”即可。

然后,会弹出如下界面,直接点击“Next:Desktop Entry”。
然后,会弹出如下界面,直接点击“Next:Launcher Script”。
然后,会弹出如下界面,点击“Next: Default plugins”。

然后,会弹出如下界面,点击“Next: Featured plugins”。
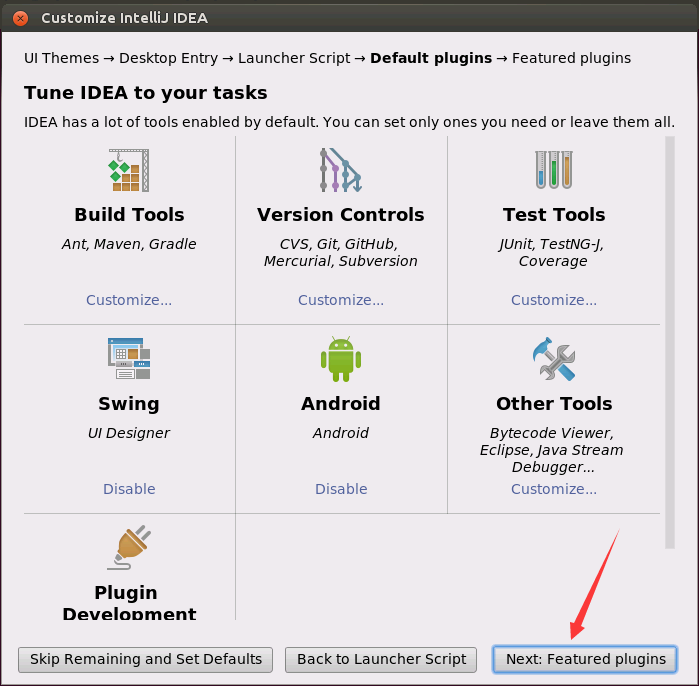
然后,会弹出如下界面,如果你打算在线安装Scala插件(笔者不建议这样做),点击Scala下面的“Install”按钮,但是,这样在线安装非常慢,不建议在线安装,所以,这里不要点击“Install”按钮,后面我们会手动安装Scala插件。现在,只需要做一个动作,就是点击“Start using IntelliJ IDEA”按钮。
然后,会弹出如下启动画面,可以看出版本时间是IntelliJ IDEA Community(社区)2017年3月版本。

为IntelliJ IDEA安装Scala插件
然后,会出现如下界面,点击界面右下角的“configure”按钮。

然后,会弹出如下界面,点击界面中的“Plugins”。
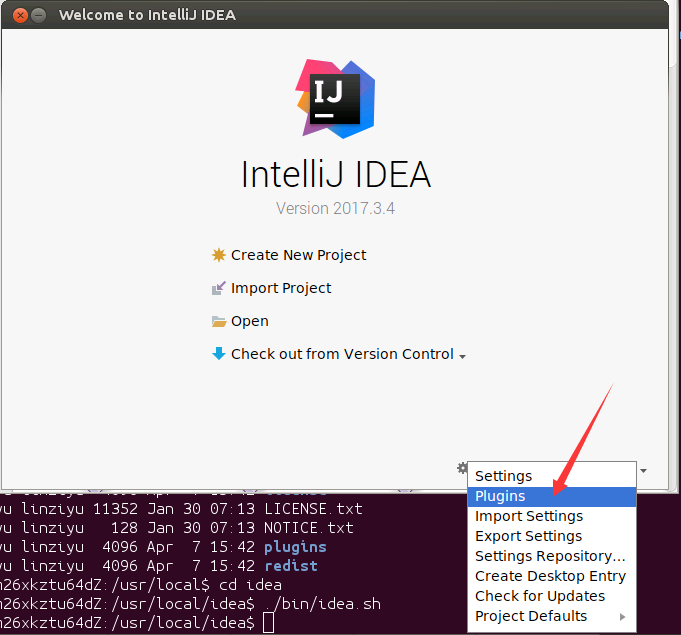
然后,会弹出如下界面,点击界面右下角的“Install plugin from disk...”按钮。
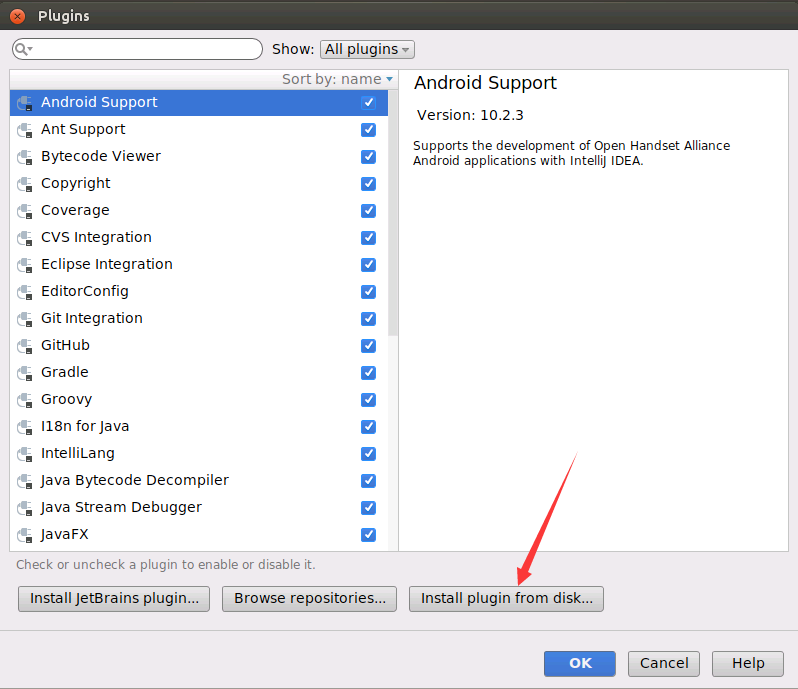
然后,会弹出如下界面,请找到前面Scala插件安装包scala-intellij-bin-2017.3.4.zip所在的目录“/home/linziyu/Downloads”,然后,点击“OK”按钮。
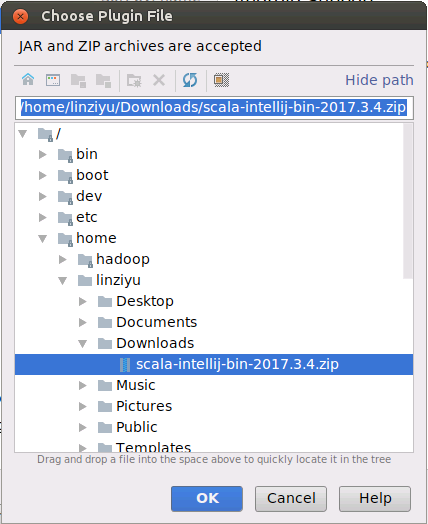
然后,会弹出如下界面,请点击右上角的“Restart IntelliJ IDEA”,重新启动IDEA。
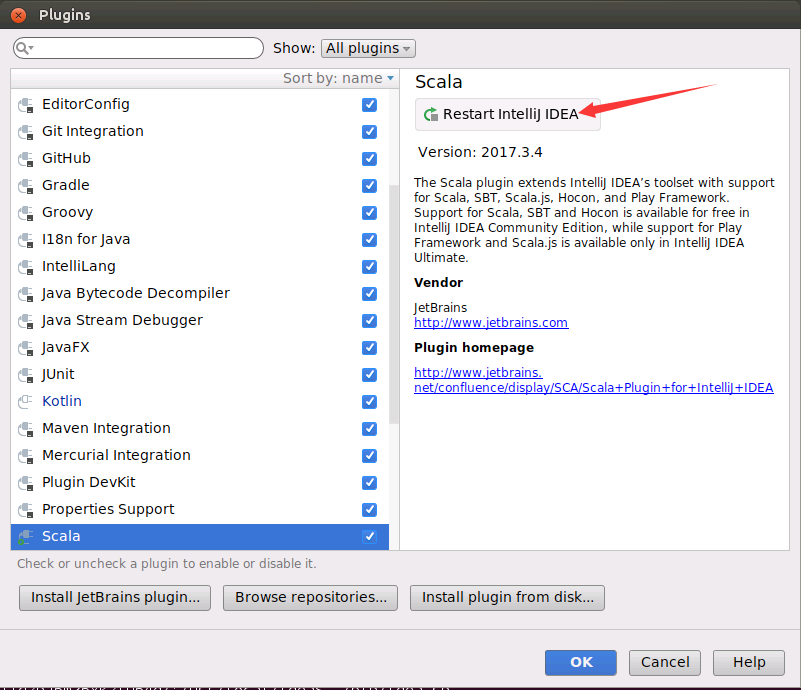
重启动以后,会再次出现如下的欢迎界面:
配置项目的JDK
在上面这个欢迎界面中,请点击“Configure”,在弹出的菜单中点击“Project Defaults”,在弹出的菜单中点击“Project Structure”,如下图所示:
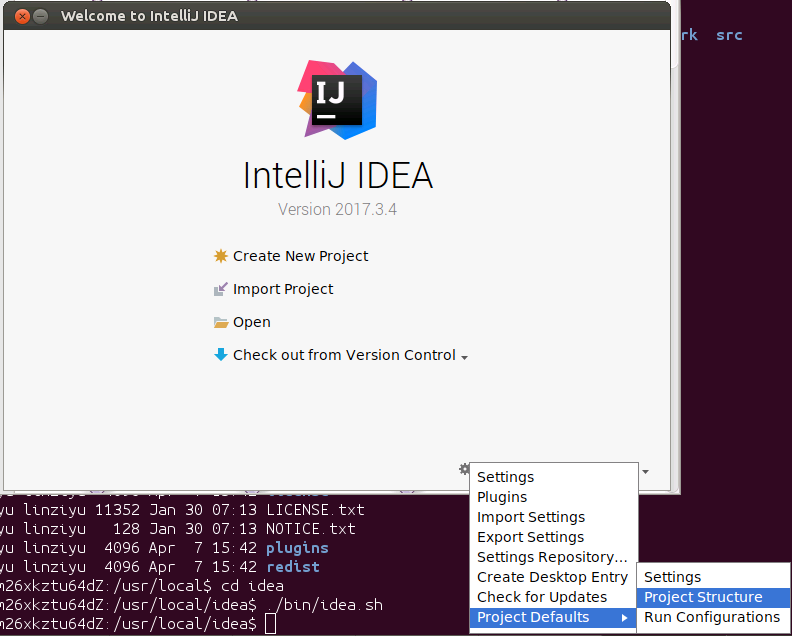
然后,在弹出的界面(如下图所示)中,点击左侧“Project Settings”中的“Project”,在右边点击No SDK后面的“New”按钮,在弹出的菜单中点击“JDK”。
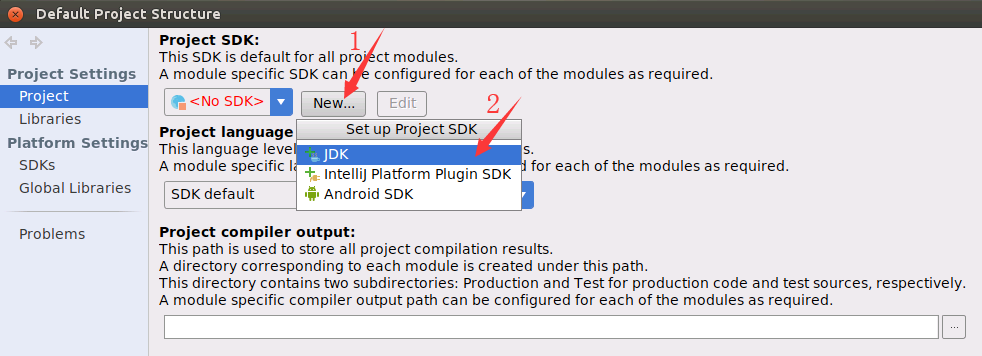
然后,会弹出如下界面,要找到之前已经在Ubuntu中安装的JDK的目录,也就是“/usr/lib/jvm/jdk1.8.0_162”,点击“OK”按钮。

然后会返回到如下界面,请在界面中点击“OK”按钮。

创建一个新项目WordCount
然后,又会返回到欢迎界面,如下所示,请点击“Create New Project”,开始创建一个新项目。
然后,弹出如下界面,请点击左侧的“Maven”,右侧“Create from archetype”这个复选框,不要选中,不用管它,直接点击界面底部的“Next”按钮。
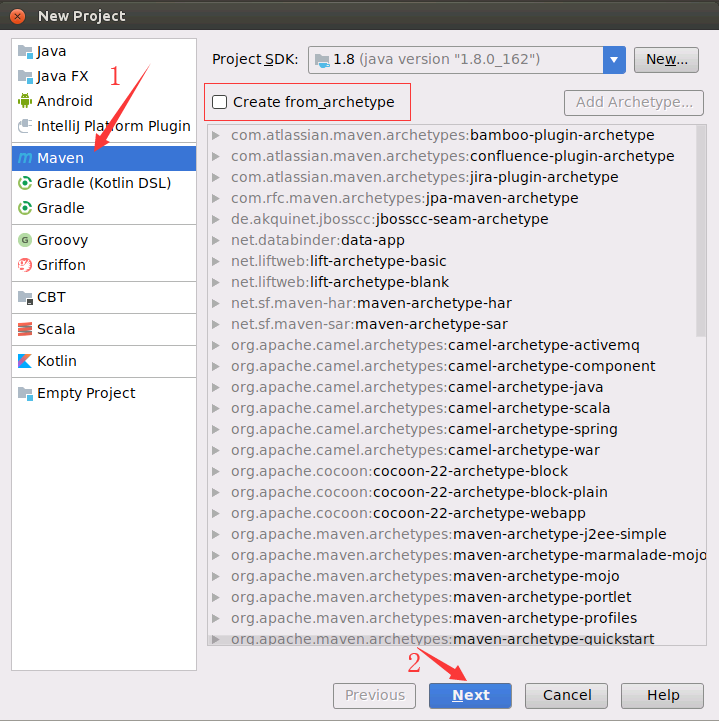
然后,会弹出如下界面,在GroupId中填入dblab,在ArtifactId中填入WordCount,然后,点击“Next”。
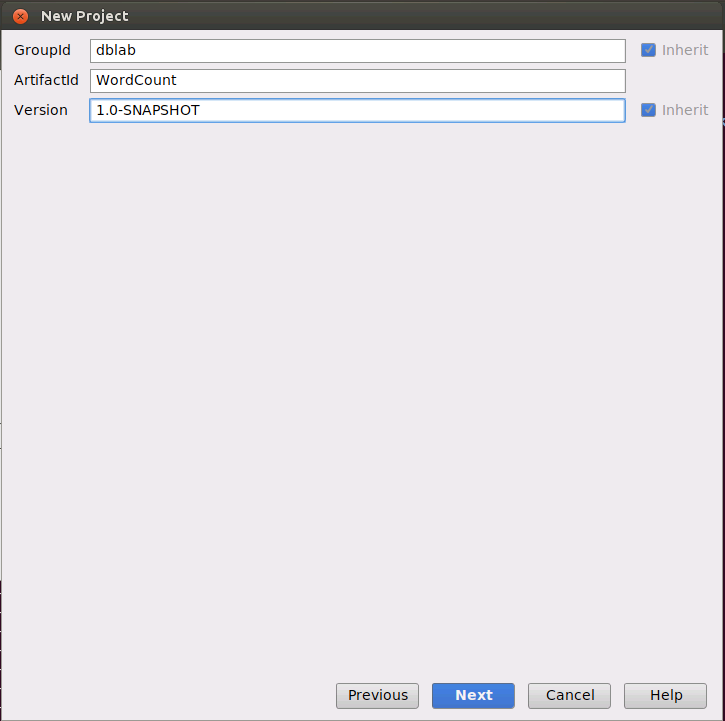
会弹出如下界面,请点击“Finish”按钮。
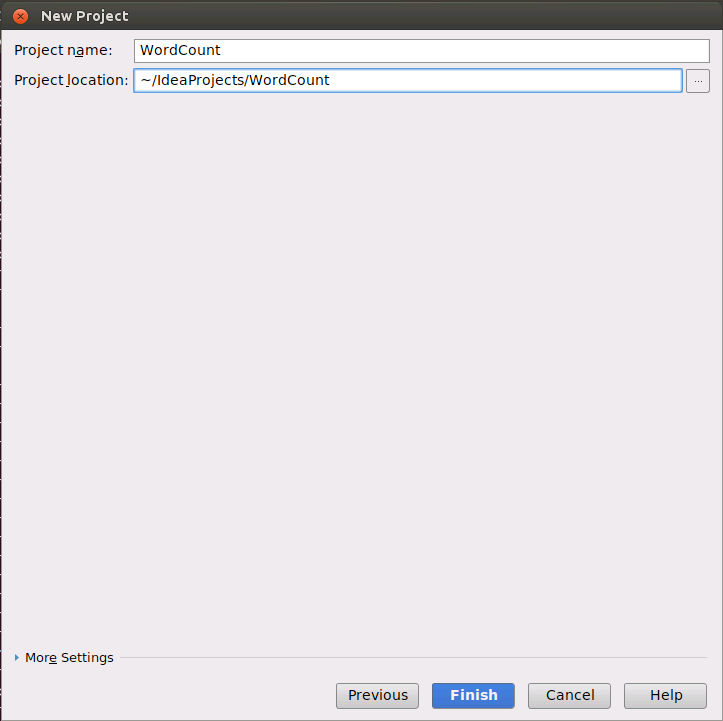
然后,进入如下所示的项目界面,界面中出现一个“Tip of the Day”提示框,直接点击“Close”关闭。另外,请点击界面底部的“Maven projects need to be imported”这个区域的“Enable Auto-Import”。这样,IDEA就可以自动到网络上下载Maven相关的依赖文件,以后,每次修改项目中的pom.xml内容时,IDEA都会自动到网络下载相关的依赖文件。
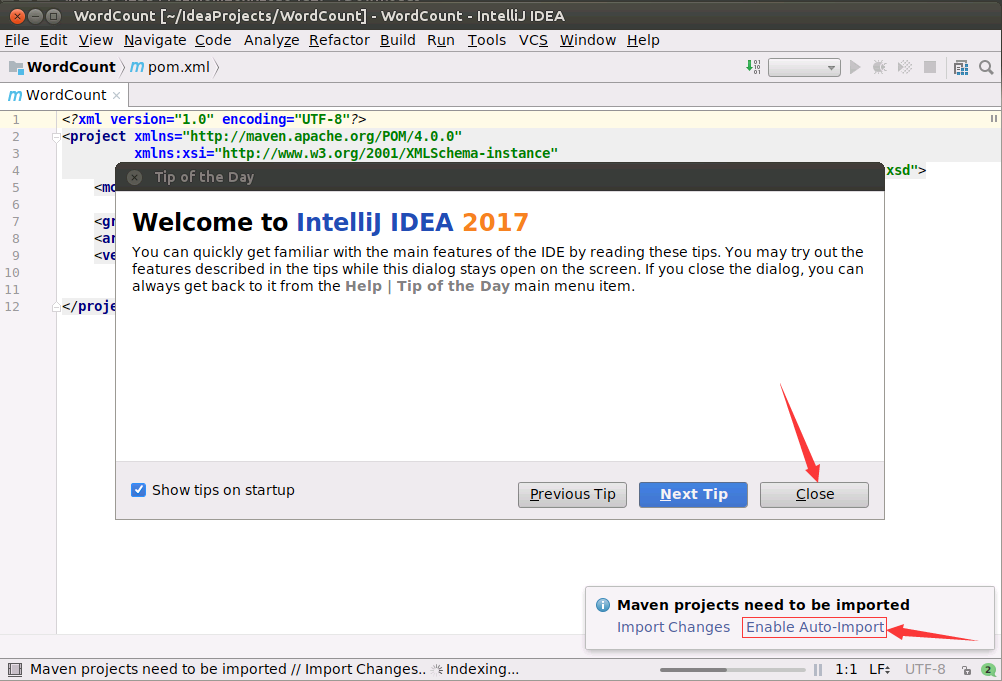
然后,项目的界面应该呈现如下样子:
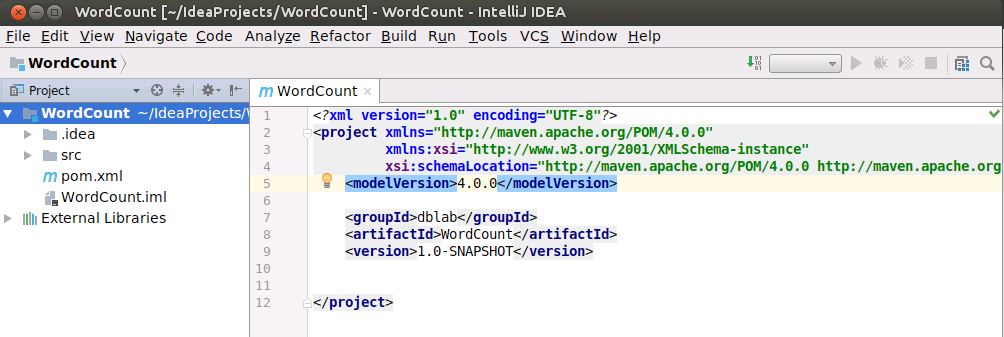
为WordCount项目添加Scala框架支持
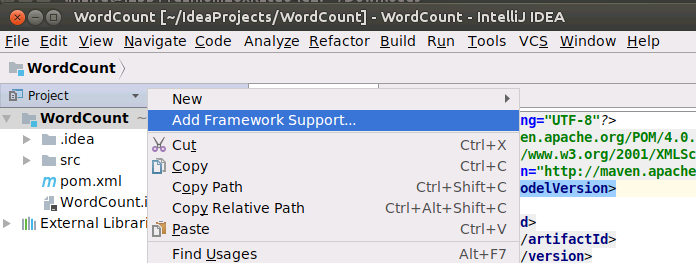
在界面左侧的项目名称“WordCount”上单击鼠标右键,在弹出的菜单中选择“Add Framework Support...”,如下图所示:
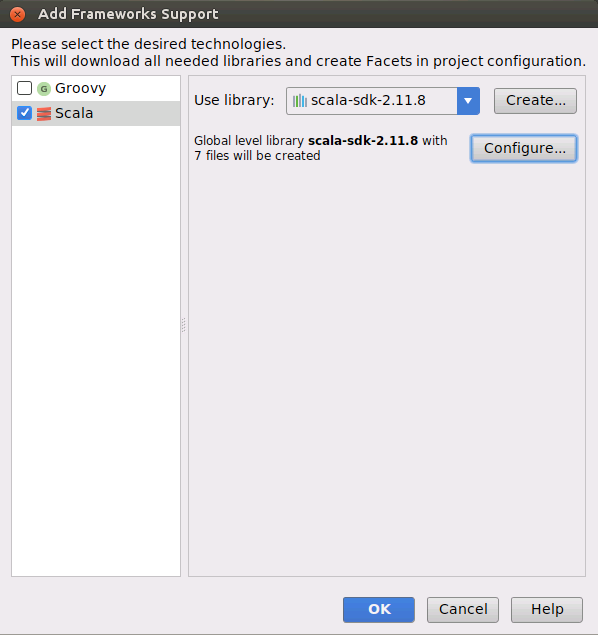
会弹出如下界面,请在界面左侧点击“Scala”复选框,勾中,选上,右侧点击“Use Library”右边的“Create”按钮。

会弹出如下界面,请点击界面底部的“Browse...”按钮。
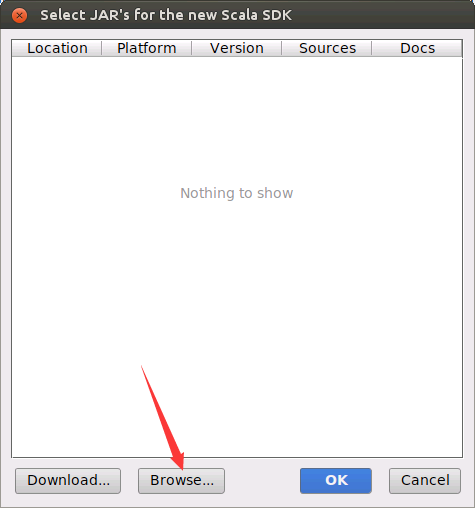
会弹出如下界面,需要找到之前Scala的安装目录/usr/local/scala,然后,点击界面底部的“OK”按钮。

然后,返回到如下界面,点击界面底部的“OK”按钮。
然后会返回到如下图所示界面,注意界面底部的状态信息,会显示正在构建索引。
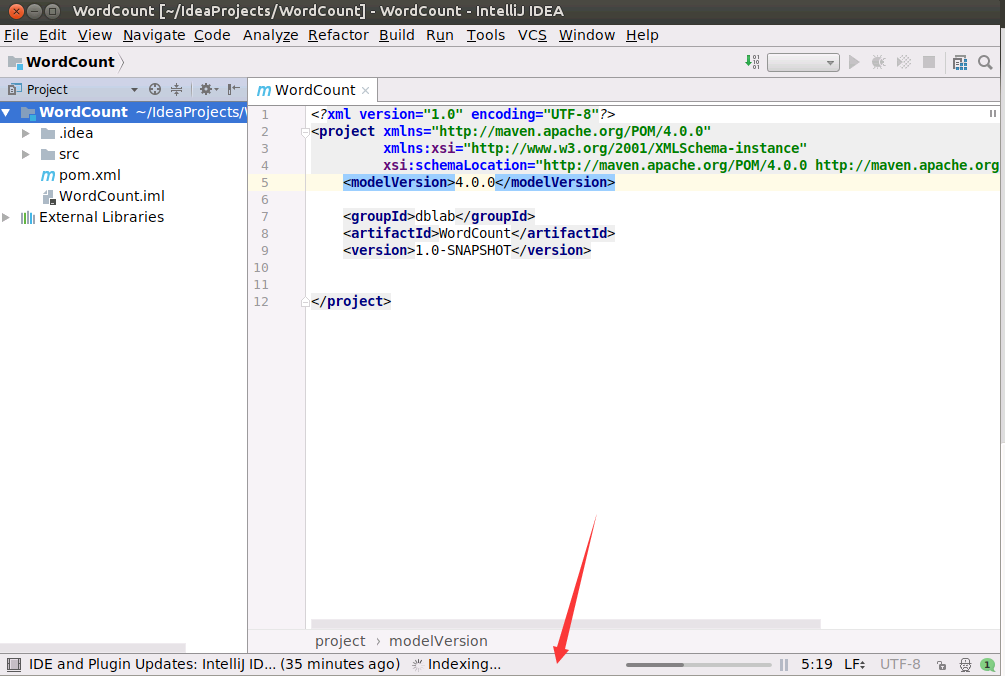
新建Scala代码目录
然后,如下图所示,在界面左侧的项目栏中,在src目录的main子目录上,单击鼠标右键,在弹出的菜单中点击"New",然后,在弹出的菜单中点击“Directory”,创建一个新目录。
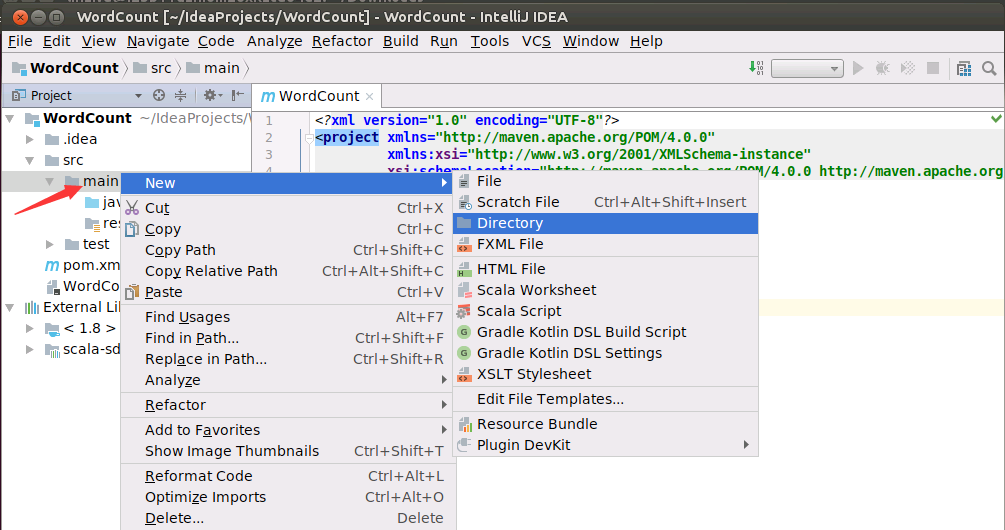
会弹出如下界面,请在里面输入新的目录的名称scala,点击OK按钮。
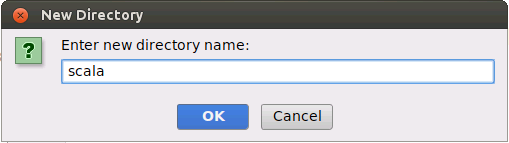
然后,如下图所示,在scala这个子目录上,单击鼠标右键,在弹出的菜单中点击"Mark Directory as",然后,在弹出的菜单中点击“Sources Root”,把scala目录设置为源代码目录。
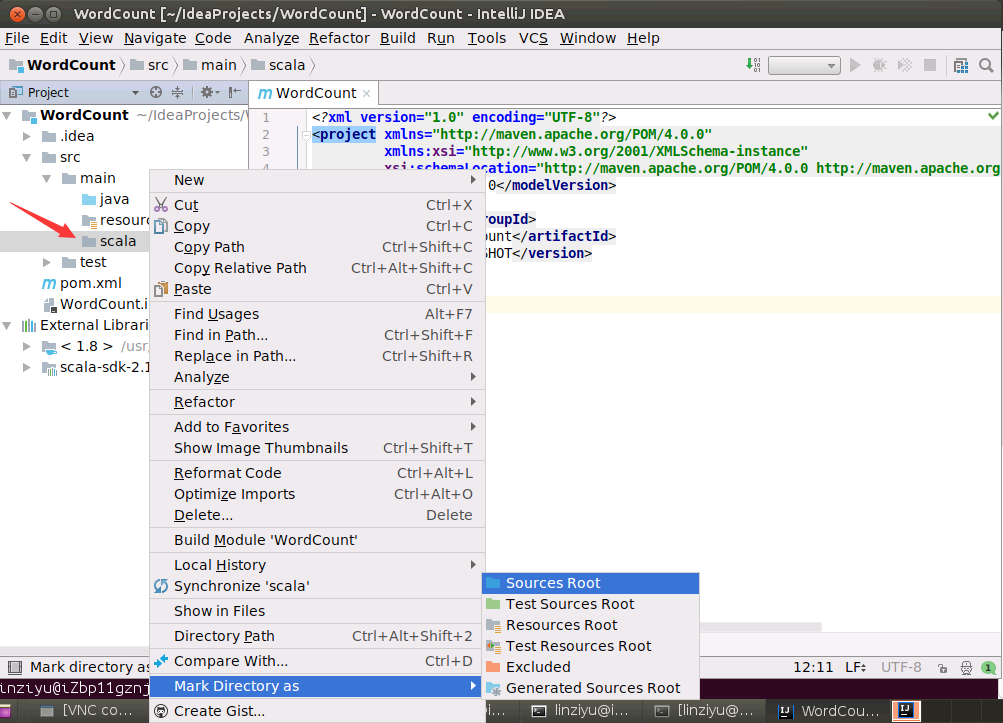
然后,如下图所示,在java子目录上,单击鼠标右键,在弹出的菜单中点击"Delete...",删除这个目录。
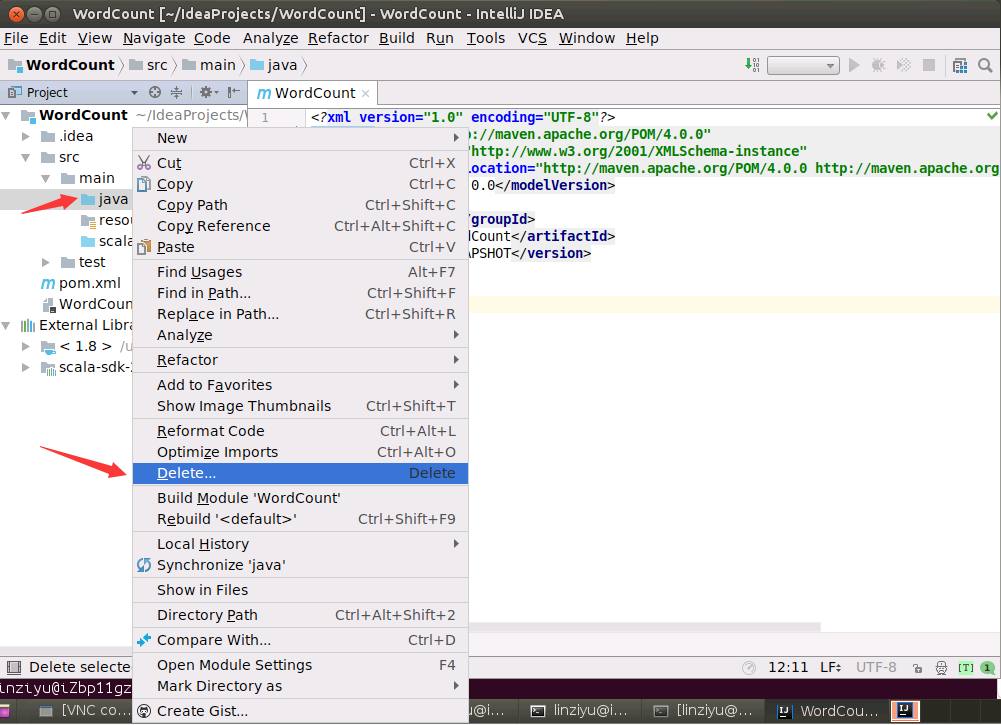
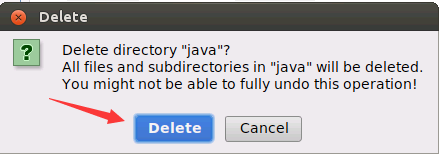
会弹出一个删除确认界面,询问你是否删除,可以直接点击“Delete”按钮。
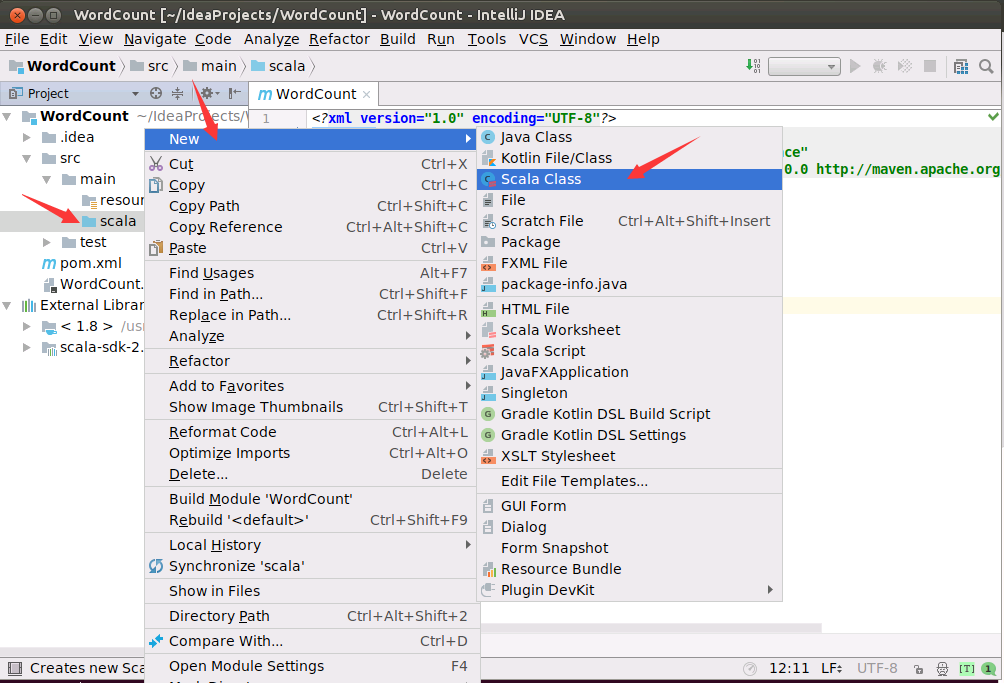
新建Scala代码文件
然后,在scala目录上单击鼠标右键,,在弹出的菜单中点击"New",然后,在弹出的菜单中点击“Scala Class”,新建一个Scala代码文件。
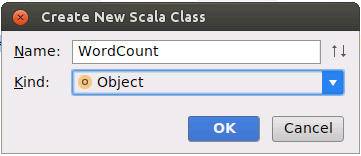
如下图所示,在Name后面输入WordCount,在Kind后面选择Object,然后点击OK按钮。
然后,就可以看到,在项目界面中,生成了一个WordCount.scala代码文件,请清空这个文件里面的内容,然后,把如下代码粘贴到里面:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object WordCount {
def main(args: Array[String]) {
val inputFile = "file:///usr/local/spark/mycode/wordcount/word.txt"
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
val textFile = sc.textFile(inputFile)
val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
wordCount.foreach(println)
}
}
需要注意的是,上面代码是对阿里云ECS中的Ubuntu系统中的“/usr/local/spark/mycode/wordcount/word.txt”这个文件进行词频统计,统计出word.txt中每个单词出现的次数,所以,一定要在阿里云ECS中的Ubuntu系统中创建这个word.txt文件,并且在里面随便输入几行英文单词,用来做词频统计。
修改pom.xml文件
然后,再打开项目中的pom.xml文件,清空这个文件里面的内容,然后,把如下代码粘贴到里面:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>dblab</groupId>
<artifactId>WordCount</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<spark.version>2.1.0</spark.version>
<scala.version>2.11</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.19</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build>
</project>
然后,如下图所示,界面底部就会出现正在运行后台进程的相关信息。
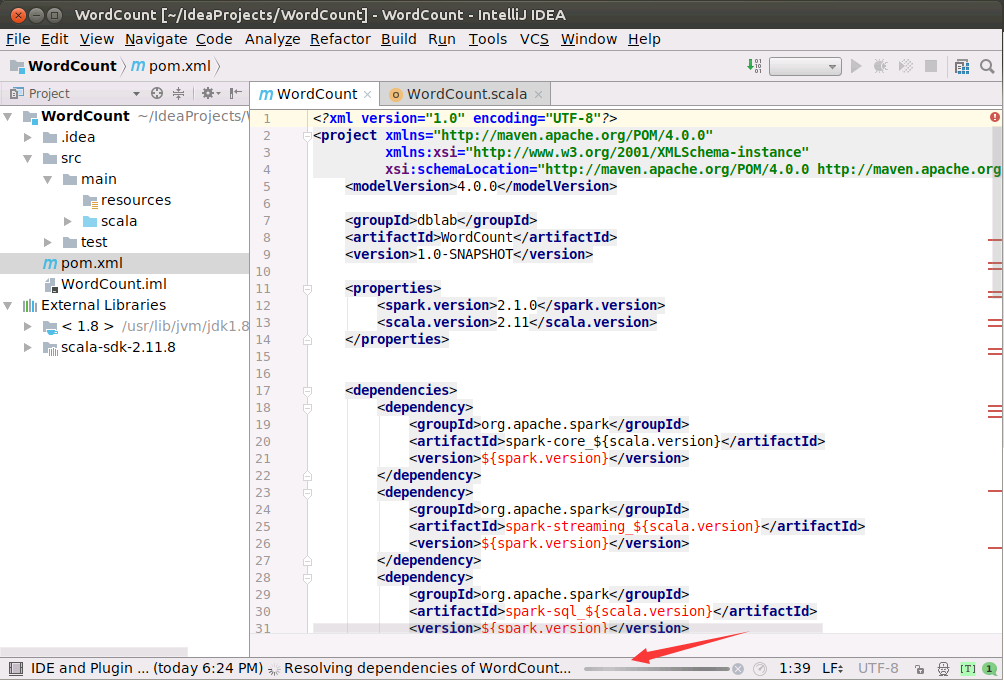
更新Maven的依赖文件
请打开项目中的pom.xml文件,在该文件内容窗口内的任意位置,用鼠标单击右键,如下图所示,在弹出的菜单中点击“Maven”,在弹出的菜单中点击“Generate Sources and Update Folders”。然后,IDEA就会开始到网络上下载相关的依赖文件。界面底部可以看到,正在运行“Resolving dependencies of WordCount...”。IDEA正在从网络上下载相关的依赖文件,由于是一次运行Scala代码,所以,需要从网络上下载大量依赖文件,会耗费较长时间,大概半个小时到1个小时左右。以后再运行时,就不需要再次下载,速度就会快很多。
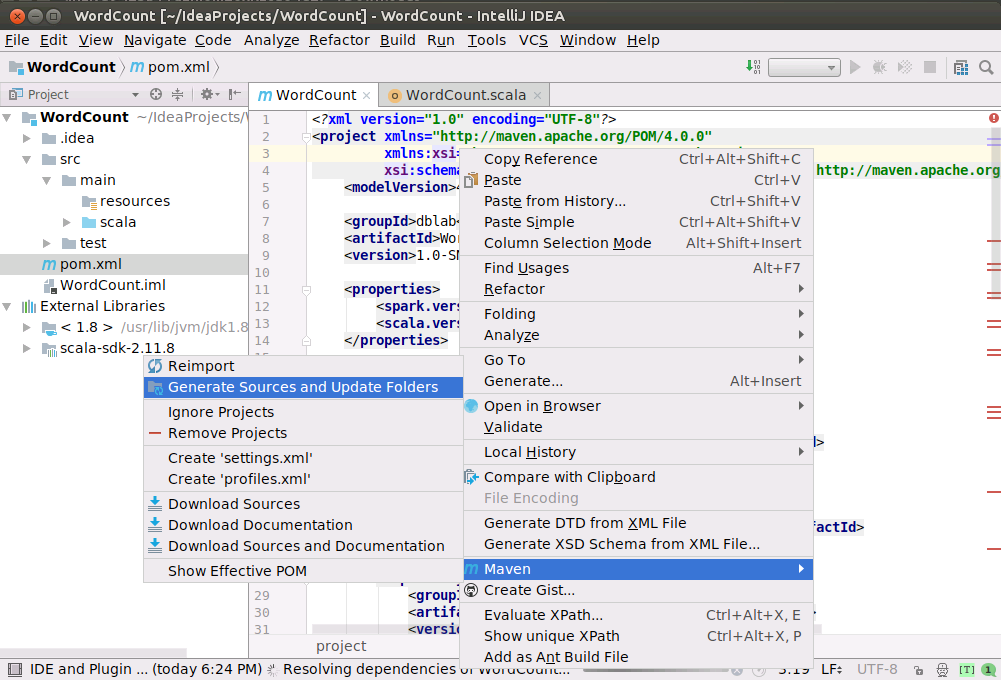
如果界面中的圆圈一直在转动,长条型的状态条一直在闪动,就说明IDEA一直在下载文件。当圆圈静止,长条型的状态条不动时,就说明下载结束。就可以进行下面的操作。
运行WordCount程序
如下图所示,请在项目中打开WordCount.scala代码文件,在该代码文件内容窗口内的任意位置,用鼠标单击右键,在弹出的菜单中点击“Run WordCount”,就可以运行WordCount程序了。
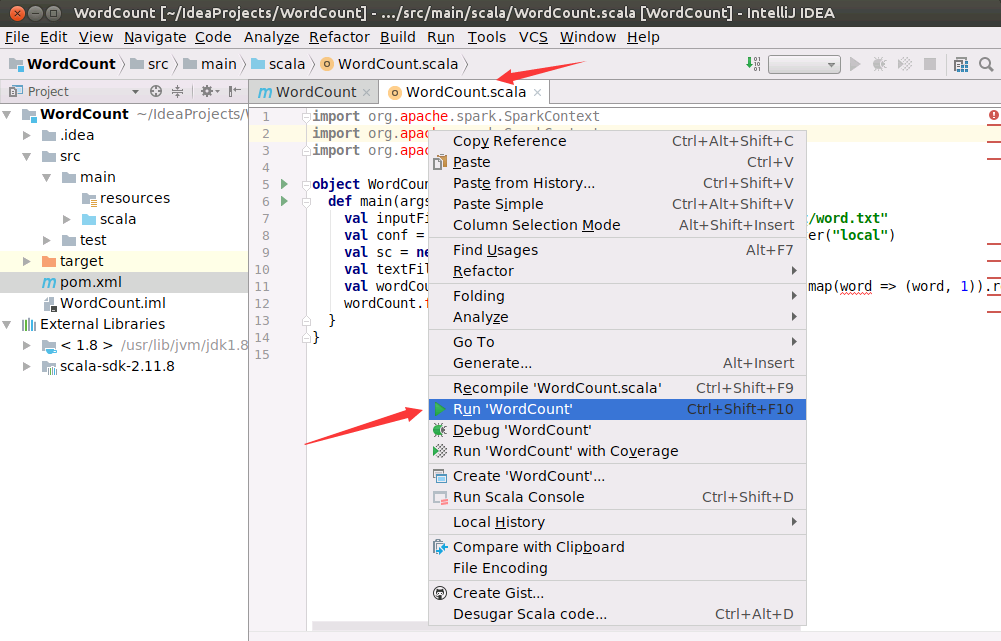
然后,IDEA就开始对WordCount.scala程序进行编译,如下图所示,编译过程中会显示状态条信息。
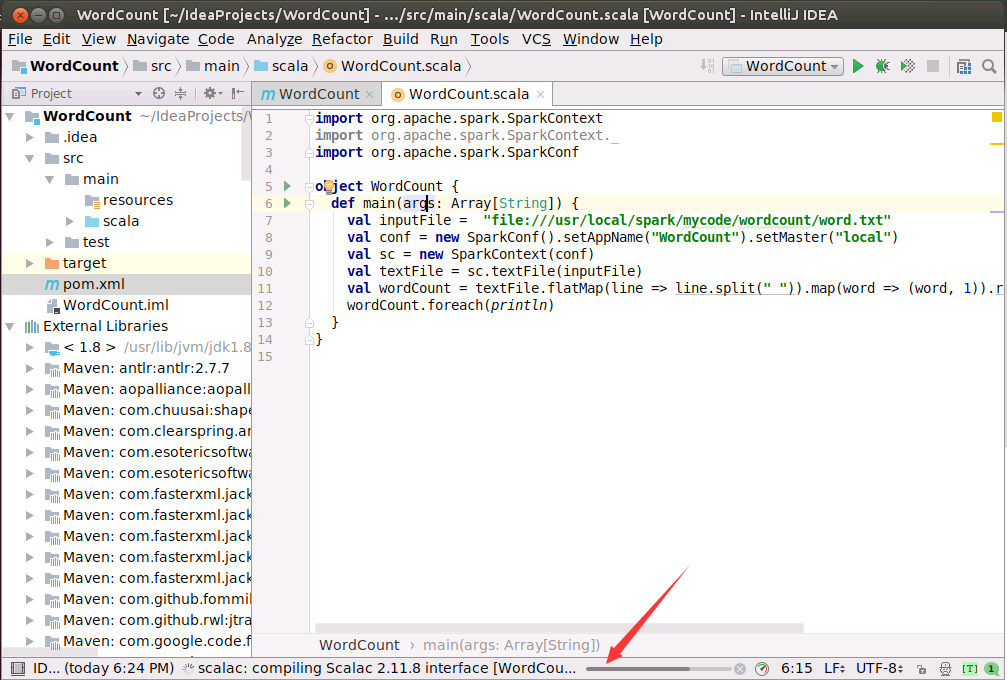
最终,如下图所示,程序顺利运行得到结果。
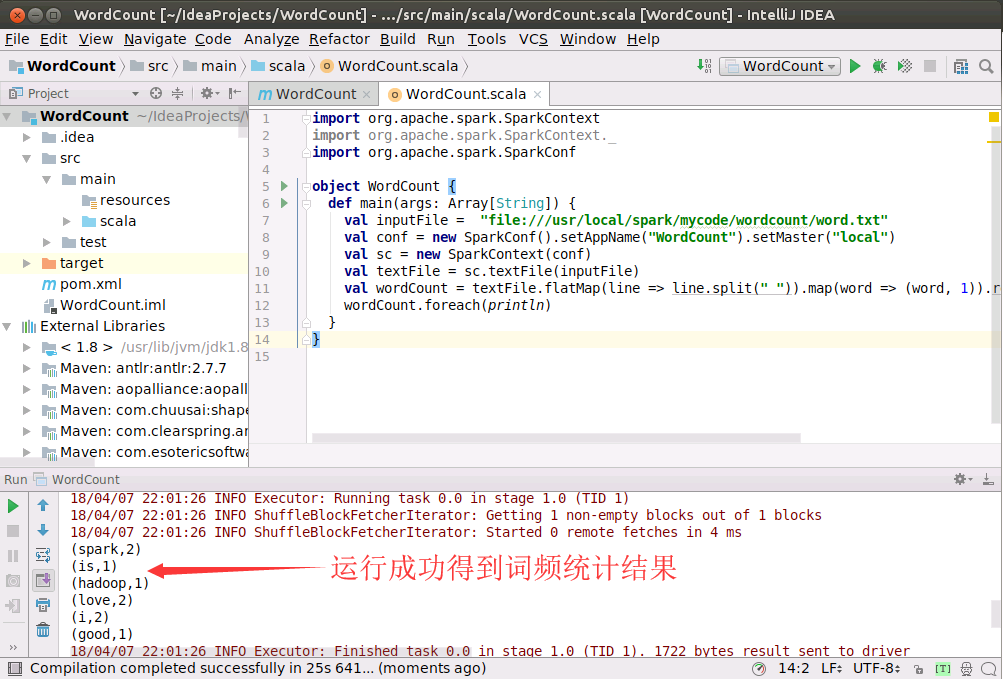
打包WordCount程序生成jar包
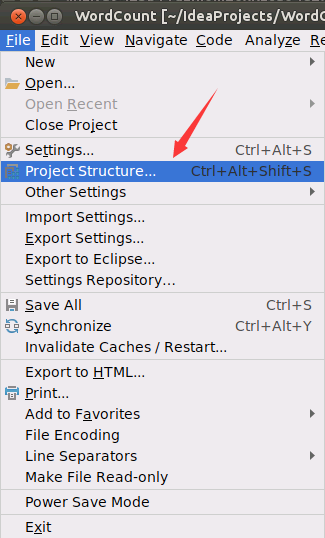
首先,在IDE中,打开菜单File->Project Structure,如下图所示。
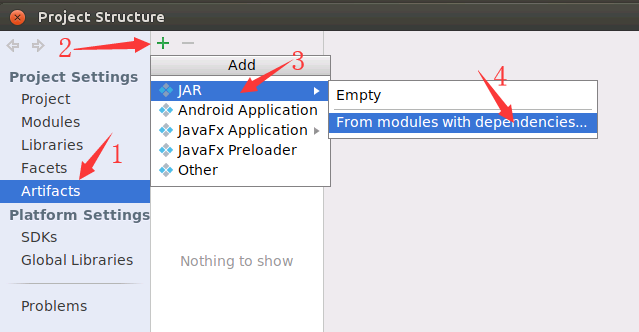
然后,会弹出如下图所示界面,请依次点击“Artifacts”、绿色加号、JAR和From modules with dependencies...。
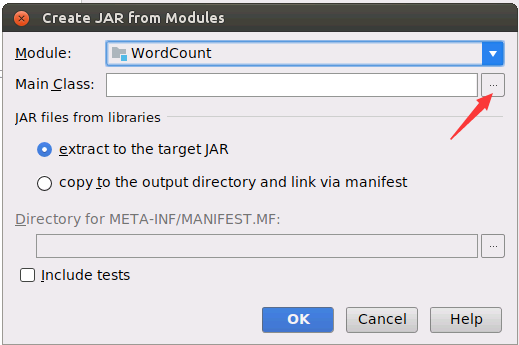
然后,在弹出的界面(如下图所示)中,点击“Main Class”右边的省略号按钮。
然后,在弹出的界面(如下图所示)中,在搜索文本框中输入wordcount,再点击OK按钮。
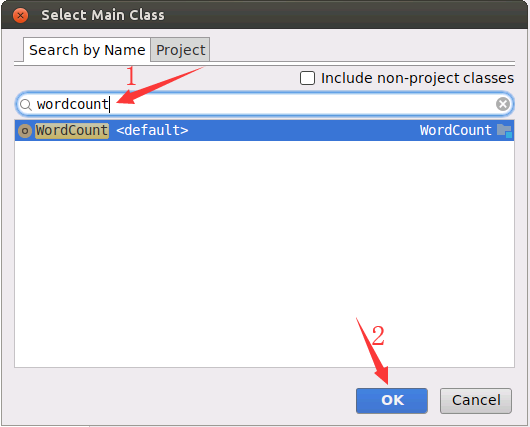
然后,在弹出的界面(如下图所示)中,点击OK按钮。
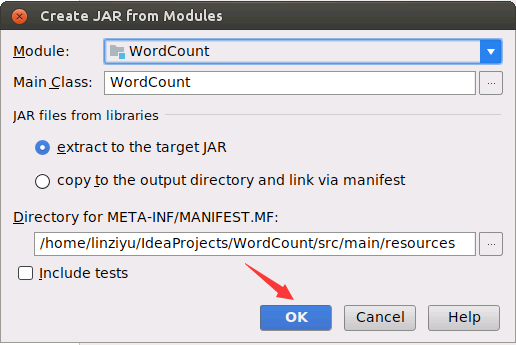
然后,返回到了如下图所示的界面,因为我们只是在Spark上运行的,所以我们要删除下图红框里多余的部分,保留WordCount.jar以及‘WordCount’ compile output。小提示,可以用鼠标点击红色方框区域,然后可以利用Ctrl+A全选功能,选中红色方框中的全部选项,然后,配合Crtl加上鼠标左键进行反选,也就是按住Ctrl键的同时用鼠标左键分别点击WordCount.jar和‘WordCount’ compile output,从而不选中这两项,最后,点击界面中的删除按钮(是一个红色减号图标),这样就把其他选项都删除,只保留了WordCount.jar以及‘WordCount’ compile output。
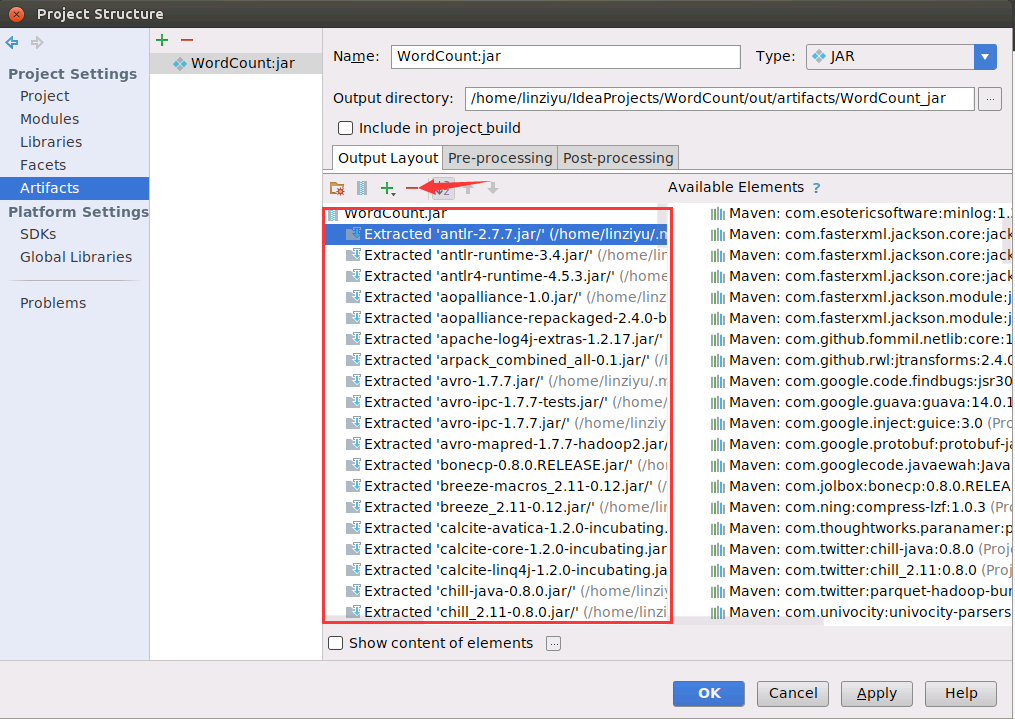
删除以后,剩下两项就是WordCount.jar以及‘WordCount’ compile output,如下图所示,然后点击界面中的OK按钮。

最后,如下图所示,点击顶部菜单中的“Build”菜单,在弹出的子菜单中点击“Build Artifacts...”。
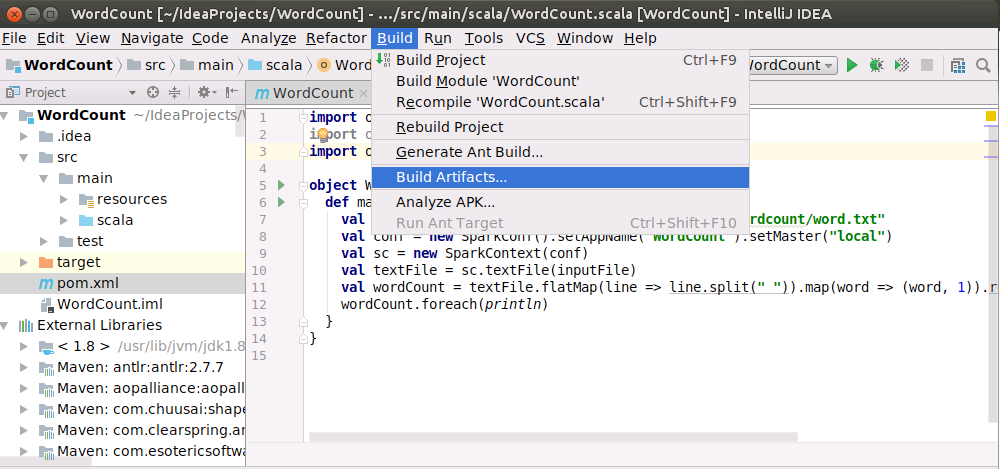
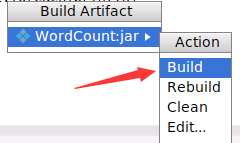
然后,会弹出如下界面,请点击“Build”,就开始打包了。
把jar提交到Spark中运行
打包成功以后,生成的JAR包文件在“/home/linziyu/IdeaProjects/WordCount/out/artifacts/WordCount_jar/WordCount.jar”。
下面可以在Ubuntu系统中打开一个命令行终端,执行如下Shell命令,运行WordCount.jar程序:
cd /usr/local/spark
./bin/spark-submit --class "WordCount" /home/linziyu/IdeaProjects/WordCount/out/artifacts/WordCount_jar/WordCount.jar
然后,程序就开始运行,得到词频统计结果。
让IntelliJ IDEA中的WordCount程序访问HDFS中的文件
上面我们在进行词频统计程序时,我们使用的是阿里云ECS实例的Ubuntu系统中的本地文件,现在,我们修改一下,让WordCount程序访问HDFS中的“/user/linziyu/word.txt”文件(如果不存在该HDFS文件,请先使用HDFS Shell命令创建该文件,点击这里阅读HDFS Shell命令使用方法)。请把WordCount.scala代码文件修改为如下内容:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object WordCount {
def main(args: Array[String]) {
val inputFile = "hdfs://192.168.1.106:9000/user/linziyu/word.txt"
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
val textFile = sc.textFile(inputFile)
val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
wordCount.foreach(println)
}
}
上面代码中的192.168.1.106,是阿里云ECS实例的私网IP地址(你的可能不是这个IP地址,请查询你自己的私网IP)。
然后,按照上面介绍的步骤,在WordCount.scala代码窗口内,单击鼠标右键,在弹出的菜单中点击“Run as WordCount”,运行程序。可以看到,可以成功运行程序,如下图所示:

如果运行失败,提示信息反馈说访问HDFS失败,首先,请使用jps命令检查HDFS是否已经启动成功。如果HDFS已经成功启动,WordCount还是执行失败,就请去修改 /etc/hosts文件。具体方法是:
使用用户名linziyu登录ECS中的Ubuntu系统,打开一个终端,执行如下命令修改hosts文件内容:
cd ~
sudo vim /etc/hosts
/etc/hosts这个文件的原来内容如下:
192.168.1.106 iZbp11gznj7n38xkztu64dZ
127.0.0.1 localhost
# The following lines are desirable for IPv6 capable hosts
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
修改后,请把里面的最后三行注释掉,使用#可以注释掉一行内容,修改后如下:
192.168.1.106 iZbp11gznj7n38xkztu64dZ
127.0.0.1 localhost
# The following lines are desirable for IPv6 capable hosts
#::1 localhost ip6-localhost ip6-loopback
#ff02::1 ip6-allnodes
#ff02::2 ip6-allrouters
修改后保存文件并退出vim编辑器。
这样,再去调试WordCount程序就可以成功了。