
**【版权声明】博客内容由厦门大学数据库实验室拥有版权,未经允许,请勿转载!
四、分布式矩阵(Distributed Matrix)
分布式矩阵由长整型的行列索引值和双精度浮点型的元素值组成。它可以分布式地存储在一个或多个RDD上,MLlib提供了三种分布式矩阵的存储方案:行矩阵RowMatrix,索引行矩阵IndexedRowMatrix、坐标矩阵CoordinateMatrix和分块矩阵Block Matrix。它们都属于org.apache.spark.mllib.linalg.distributed包。
(一)行矩阵(RowMatrix)
行矩阵RowMatrix是最基础的分布式矩阵类型。每行是一个本地向量,行索引无实际意义(即无法直接使用)。数据存储在一个由行组成的RDD中,其中每一行都使用一个本地向量来进行存储。由于行是通过本地向量来实现的,故列数(即行的维度)被限制在普通整型(integer)的范围内。在实际使用时,由于单机处理本地向量的存储和通信代价,行维度更是需要被控制在一个更小的范围之内。RowMatrix可通过一个RDD[Vector]的实例来创建,如下代码所示:
scala> import org.apache.spark.rdd.RDD
import org.apache.spark.rdd.RDD
scala> import org.apache.spark.mllib.linalg.{Vector,Vectors}
import org.apache.spark.mllib.linalg.{Vector,Vectors}
scala> import org.apache.spark.mllib.linalg.distributed.RowMatrix
import org.apache.spark.mllib.linalg.distributed.RowMatrix
// 创建两个本地向量dv1 dv2
scala> val dv1 : Vector = Vectors.dense(1.0,2.0,3.0)
dv1: org.apache.spark.mllib.linalg.Vector = [1.0,2.0,3.0]
scala> val dv2 : Vector = Vectors.dense(2.0,3.0,4.0)
dv2: org.apache.spark.mllib.linalg.Vector = [2.0,3.0,4.0]
// 使用两个本地向量创建一个RDD[Vector]
scala> val rows : RDD[Vector] = sc.parallelize(Array(dv1,dv2))
rows: org.apache.spark.rdd.RDD[org.apache.spark.mllib.linalg.Vector] = ParallelCollectionRDD[13] at parallelize at <console>:38
// 通过RDD[Vector]创建一个行矩阵
scala> val mat : RowMatrix = new RowMatrix(rows)
mat: org.apache.spark.mllib.linalg.distributed.RowMatrix = org.apache.spark.mllib.linalg.distributed.RowMatrix@76fc0fa
//可以使用numRows()和numCols()方法得到行数和列数
scala> mat.numRows()
res0: Long = 2
scala> mat.numCols()
res1: Long = 3
scala> mat.rows.foreach(println)
[1.0,2.0,3.0]
[2.0,3.0,4.0]
在获得RowMatrix的实例后,我们可以通过其自带的computeColumnSummaryStatistics()方法获取该矩阵的一些统计摘要信息,并可以对其进行QR分解,SVD分解和PCA分解,这一部分内容将在特征降维的章节详细解说,这里不再叙述。
统计摘要信息的获取如下代码段所示(接上代码段):
// 通过computeColumnSummaryStatistics()方法获取统计摘要
scala> val summary = mat.computeColumnSummaryStatistics()
// 可以通过summary实例来获取矩阵的相关统计信息,例如行数
scala> summary.count
res2: Long = 2
// 最大向量
scala> summary.max
res3: org.apache.spark.mllib.linalg.Vector = [2.0,3.0,4.0]
// 方差向量
scala> summary.variance
res4: org.apache.spark.mllib.linalg.Vector = [0.5,0.5,0.5]
// 平均向量
scala> summary.mean
res5: org.apache.spark.mllib.linalg.Vector = [1.5,2.5,3.5]
// L1范数向量
scala> summary.normL1
res6: org.apache.spark.mllib.linalg.Vector = [3.0,5.0,7.0]
(二)索引行矩阵(IndexedRowMatrix)
索引行矩阵IndexedRowMatrix与RowMatrix相似,但它的每一行都带有一个有意义的行索引值,这个索引值可以被用来识别不同行,或是进行诸如join之类的操作。其数据存储在一个由IndexedRow组成的RDD里,即每一行都是一个带长整型索引的本地向量。
与RowMatrix类似,IndexedRowMatrix的实例可以通过RDD[IndexedRow]实例来创建。如下代码段所示(接上例):
scala>import org.apache.spark.mllib.linalg.distributed.{IndexedRow, IndexedRowMatrix}
import org.apache.spark.mllib.linalg.distributed.{IndexedRow, IndexedRowMatrix}
// 通过本地向量dv1 dv2来创建对应的IndexedRow
// 在创建时可以给定行的索引值,如这里给dv1的向量赋索引值1,dv2赋索引值2
scala> val idxr1 = IndexedRow(1,dv1)
idxr1: org.apache.spark.mllib.linalg.distributed.IndexedRow = IndexedRow(1,[1.0,2.0,3.0])
scala> val idxr2 = IndexedRow(2,dv2)
idxr2: org.apache.spark.mllib.linalg.distributed.IndexedRow = IndexedRow(2,[2.0,3.0,4.0])
// 通过IndexedRow创建RDD[IndexedRow]
scala> val idxrows = sc.parallelize(Array(idxr1,idxr2))
idxrows: org.apache.spark.rdd.RDD[org.apache.spark.mllib.linalg.distributed.IndexedRow] = ParallelCollectionRDD[14] at parallelize at <console>:45
// 通过RDD[IndexedRow]创建一个索引行矩阵
scala> val idxmat: IndexedRowMatrix = new IndexedRowMatrix(idxrows)
idxmat: org.apache.spark.mllib.linalg.distributed.IndexedRowMatrix = org.apache.spark.mllib.linalg.distributed.IndexedRowMatrix@532887bc
//打印
scala> idxmat.rows.foreach(println)
IndexedRow(1,[1.0,2.0,3.0])
IndexedRow(2,[2.0,3.0,4.0])
(三)坐标矩阵(Coordinate Matrix)
坐标矩阵CoordinateMatrix是一个基于矩阵项构成的RDD的分布式矩阵。每一个矩阵项MatrixEntry都是一个三元组:(i: Long, j: Long, value: Double),其中i是行索引,j是列索引,value是该位置的值。坐标矩阵一般在矩阵的两个维度都很大,且矩阵非常稀疏的时候使用。
CoordinateMatrix实例可通过RDD[MatrixEntry]实例来创建,其中每一个矩阵项都是一个(rowIndex, colIndex, elem)的三元组:
scala> import org.apache.spark.mllib.linalg.distributed.{CoordinateMatrix, MatrixEntry}
// 创建两个矩阵项ent1和ent2,每一个矩阵项都是由索引和值构成的三元组
scala> val ent1 = new MatrixEntry(0,1,0.5)
ent1: org.apache.spark.mllib.linalg.distributed.MatrixEntry = MatrixEntry(0,1,0.5)
scala> val ent2 = new MatrixEntry(2,2,1.8)
ent2: org.apache.spark.mllib.linalg.distributed.MatrixEntry = MatrixEntry(2,2,1.8)
// 创建RDD[MatrixEntry]
scala> val entries : RDD[MatrixEntry] = sc.parallelize(Array(ent1,ent2))
entries: org.apache.spark.rdd.RDD[org.apache.spark.mllib.linalg.distributed.MatrixEntry] = ParallelCollectionRDD[15] at parallelize at <console>:42
// 通过RDD[MatrixEntry]创建一个坐标矩阵
scala> val coordMat: CoordinateMatrix = new CoordinateMatrix(entries)
coordMat: org.apache.spark.mllib.linalg.distributed.CoordinateMatrix = org.apache.spark.mllib.linalg.distributed.CoordinateMatrix@25b2d465
//打印
scala> coordMat.entries.foreach(println)
MatrixEntry(0,1,0.5)
MatrixEntry(2,2,1.8)
坐标矩阵可以通过transpose()方法对矩阵进行转置操作,并可以通过自带的toIndexedRowMatrix()方法转换成索引行矩阵IndexedRowMatrix。但目前暂不支持CoordinateMatrix的其他计算操作。
// 将coordMat进行转置
scala> val transMat: CoordinateMatrix = coordMat.transpose()
transMat: org.apache.spark.mllib.linalg.distributed.CoordinateMatrix = org.apache.spark.mllib.linalg.distributed.CoordinateMatrix@c1ee50
scala> transMat.entries.foreach(println)
MatrixEntry(1,0,0.5)
MatrixEntry(2,2,1.8)
// 将坐标矩阵转换成一个索引行矩阵
scala> val indexedRowMatrix = transMat.toIndexedRowMatrix()
indexedRowMatrix: org.apache.spark.mllib.linalg.distributed.IndexedRowMatrix = org.apache.spark.mllib.linalg.distributed.IndexedRowMatrix@7ee7e1bb
scala> indexedRowMatrix.rows.foreach(println)
IndexedRow(1,(3,[0],[0.5]))
IndexedRow(2,(3,[2],[1.8]))
####(四)分块矩阵(Block Matrix)
分块矩阵是基于矩阵块MatrixBlock构成的RDD的分布式矩阵,其中每一个矩阵块MatrixBlock都是一个元组((Int, Int), Matrix),其中(Int, Int)是块的索引,而Matrix则是在对应位置的子矩阵(sub-matrix),其尺寸由rowsPerBlock和colsPerBlock决定,默认值均为1024。分块矩阵支持和另一个分块矩阵进行加法操作和乘法操作,并提供了一个支持方法validate()来确认分块矩阵是否创建成功。
分块矩阵可由索引行矩阵IndexedRowMatrix或坐标矩阵CoordinateMatrix调用toBlockMatrix()方法来进行转换,该方法将矩阵划分成尺寸默认为1024x1024的分块,可以在调用toBlockMatrix(rowsPerBlock, colsPerBlock)方法时传入参数来调整分块的尺寸。
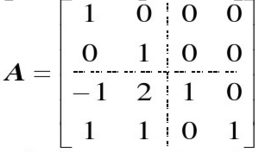
下面以矩阵A(如图)为例,先利用矩阵项MatrixEntry将其构造成坐标矩阵,再转化成如图所示的4个分块矩阵,最后对矩阵A与其转置进行乘法运算:
scala> import org.apache.spark.mllib.linalg.distributed.{CoordinateMatrix, MatrixEntry}
import org.apache.spark.mllib.linalg.distributed.{CoordinateMatrix, MatrixEntry}
scala> import org.apache.spark.mllib.linalg.distributed.BlockMatrix
import org.apache.spark.mllib.linalg.distributed.BlockMatrix
// 创建8个矩阵项,每一个矩阵项都是由索引和值构成的三元组
scala> val ent1 = new MatrixEntry(0,0,1)
...
scala> val ent2 = new MatrixEntry(1,1,1)
...
scala> val ent3 = new MatrixEntry(2,0,-1)
...
scala> val ent4 = new MatrixEntry(2,1,2)
...
scala> val ent5 = new MatrixEntry(2,2,1)
...
scala> val ent6 = new MatrixEntry(3,0,1)
...
scala> val ent7 = new MatrixEntry(3,1,1)
...
scala> val ent8 = new MatrixEntry(3,3,1)
...
// 创建RDD[MatrixEntry]
scala> val entries : RDD[MatrixEntry] = sc.parallelize(Array(ent1,ent2,ent3,ent4,ent5,ent6,ent7,ent8))
entries: org.apache.spark.rdd.RDD[org.apache.spark.mllib.linalg.distributed.MatrixEntry] = ParallelCollectionRDD[21] at parallelize at <console>:57
// 通过RDD[MatrixEntry]创建一个坐标矩阵
scala> val coordMat: CoordinateMatrix = new CoordinateMatrix(entries)
coordMat: org.apache.spark.mllib.linalg.distributed.CoordinateMatrix = org.apache.spark.mllib.linalg.distributed.CoordinateMatrix@31c5fb43
// 将坐标矩阵转换成2x2的分块矩阵并存储,尺寸通过参数传入
val matA: BlockMatrix = coordMat.toBlockMatrix(2,2).cache()
matA: org.apache.spark.mllib.linalg.distributed.BlockMatrix = org.apache.spark.mllib.linalg.distributed.BlockMatrix@26b1df2c
// 可以用validate()方法判断是否分块成功
matA.validate()
构建成功后,可通过toLocalMatrix转换成本地矩阵,并查看其分块情况:
scala> matA.toLocalMatrix
res31: org.apache.spark.mllib.linalg.Matrix =
1.0 0.0 0.0 0.0
0.0 1.0 0.0 0.0
-1.0 2.0 1.0 0.0
1.0 1.0 0.0 1.0
// 查看其分块情况
scala> matA.numColBlocks
res12: Int = 2
scala> matA.numRowBlocks
res13: Int = 2
// 计算矩阵A和其转置矩阵的积矩阵
scala> val ata = matA.transpose.multiply(matA)
ata: org.apache.spark.mllib.linalg.distributed.BlockMatrix = org.apache.spark.mllib.linalg.distributed.BlockMatrix@3644e451
scala> ata.toLocalMatrix
res1: org.apache.spark.mllib.linalg.Matrix =
3.0 -1.0 -1.0 1.0
-1.0 6.0 2.0 1.0
-1.0 2.0 1.0 0.0
1.0 1.0 0.0 1.0
分块矩阵BlockMatrix将矩阵分成一系列矩阵块,底层由矩阵块构成的RDD来进行数据存储。值得指出的是,用于生成分布式矩阵的底层RDD必须是已经确定(Deterministic)的,因为矩阵的尺寸将被存储下来,所以使用未确定的RDD将会导致错误。而且,不同类型的分布式矩阵之间的转换需要进行一个全局的shuffle操作,非常耗费资源。所以,根据数据本身的性质和应用需求来选取恰当的分布式矩阵存储类型是非常重要的。

