Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。为了更好演示集群分布,本文没有使用一台电脑上构建多个虚拟机的方法来模拟集群,而是使用三台电脑来搭建一个小型分布式集群环境安装。本文记录如何搭建并配置Hadoop分布式集群环境。
继续阅读
Hama图计算模型
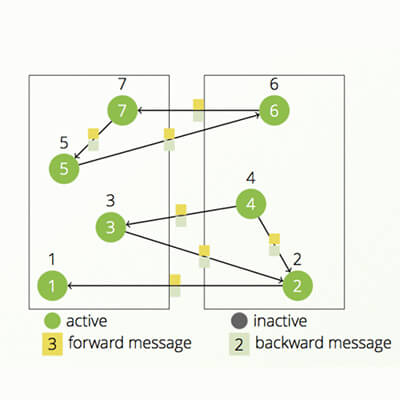
Hame是Google Pregel的开源实现,与Hadoop适合于分布式大数据处理不同,Hama主要用于分布式的矩阵、graph、网络算法的计算。简单说,Hama是在HDFS上实现的BSP(Bulk Synchronous Parallel)计算框架,弥补Hadoop在计算能力上的不足。本教程主要介绍hama的单机模式安装配置以及用hama解决一些算法问题。
Linux安装hadoop-2.7.1

hadoop的官网现在已经更新2.7.1版本,本文将指导如何在Linux如何安装hadoop 2.7.1。
Hadoop安装教程_伪分布式配置_CentOS6.4/Hadoop2.6.0

本 Hadoop 教程由厦门大学数据库实验室出品,转载请注明。本教程适合于在 CentOS 6.x 系统中安装原生 Hadoop 2,适用于Hadoop 2.7.1, Hadoop 2.6.0 等版本,主要参考了官方安装教程,步骤详细,辅以适当说明,相信按照步骤来,都能顺利在 CentOS 中安装并运行 Hadoop。
Hadoop安装配置简略教程

本Hadoop安装教程为简略版本,包含伪分布式和集群的配置,只列出命令与配置,不作详细说明,方便有基础的读者。完整版请浏览Hadoop安装配置教程_伪分布式,以及Hadoop集群安装配置教程。
使用Eclipse编译运行MapReduce程序_Hadoop2.6.0_Ubuntu/CentOS


点击这里观看厦门大学林子雨老师主讲《大数据技术原理与应用》授课视频
本教程介绍的是如何在 Ubuntu/CentOS 中使用 Eclipse 来开发 MapReduce 程序,在 Hadoop 2.6.0 下验证通过。虽然我们可以使用命令行编译打包运行自己的MapReduce程序,但毕竟编写代码不方便。使用 Eclipse,我们可以直接对 HDFS 中的文件进行操作,可以直接运行代码,省去许多繁琐的命令。
使用命令行编译打包运行自己的MapReduce程序 Hadoop2.6.0

点击这里观看厦门大学林子雨老师主讲《大数据技术原理与应用》授课视频
网上的 MapReduce WordCount 教程对于如何编译 WordCount.java 几乎是一笔带过... 而有写到的,大多又是 0.20 等旧版本版本的做法,即 javac -classpath /usr/local/hadoop/hadoop-1.0.1/hadoop-core-1.0.1.jar WordCount.java,但较新的 2.X 版本中,已经没有 hadoop-core*.jar 这个文件,因此编辑和打包自己的MapReduce程序与旧版本有所不同。
本文以 Hadoop 2.6.0 单机模式环境下的 WordCount 实例来介绍 2.x 版本中如何编辑自己的 MapReduce 程序。
Hadoop 2.4.1单机版 自定义实现类以及编译运行
概述
博主最近在学hadoop,而且在本实验室一位大神的指导下,我已配置好hadoop2.4.1开发环境,还没有配置或者不会配置的,请看链接hadoop单机版配置。由于之前运行的都是hadoop自带的实例,但是对于个人学习而言,肯定是要自己编写实现类以及编译运行实现类,因此博主就撰写了这篇文章,希望对学习hadoop的同道中人有所帮助。
Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS

本教程讲述如何配置 Hadoop 集群,默认读者已经掌握了 Hadoop 的单机伪分布式配置,否则请先查看Hadoop安装教程_单机/伪分布式配置 或 CentOS安装Hadoop_单机/伪分布式配置。
本教程由厦门大学数据库实验室出品,转载请注明。本教程适合于原生 Hadoop 2,包括 Hadoop 2.6.0, Hadoop 2.7.1 等版本,主要参考了官方安装教程,步骤详细,辅以适当说明,保证按照步骤来,都能顺利安装并运行 Hadoop。另外有Hadoop安装配置简略版方便有基础的读者快速完成安装。
Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0(2.7.1)/Ubuntu14.04(16.04)

点击这里观看厦门大学林子雨老师主讲《大数据技术原理与应用》授课视频
当开始着手实践 Hadoop 时,安装 Hadoop 往往会成为新手的一道门槛。尽管安装其实很简单,书上有写到,官方网站也有 Hadoop 安装配置教程,但由于对 Linux 环境不熟悉,书上跟官网上简略的安装步骤新手往往 Hold 不住。加上网上不少教程也甚是坑,导致新手折腾老几天愣是没装好,很是打击学习热情。
本教程由厦门大学数据库实验室出品,转载请注明。本教程适合于原生 Hadoop 2,包括 Hadoop 2.6.0, Hadoop 2.7.1 等版本,主要参考了官方安装教程,步骤详细,辅以适当说明,相信按照步骤来,都能顺利安装并运行Hadoop。另外有Hadoop安装配置简略版方便有基础的读者快速完成安装。此外,希望读者们能多去了解一些 Linux 的知识,以后出现问题时才能自行解决。
为了方便学习本教程,请读者们利用Linux系统中自带的firefox浏览器打开本指南进行学习。
Hadoop安装文件,可以到Hadoop官网下载,也可以点击这里从百度云盘下载(提取码:99bg),进入该百度云盘链接后,找到Hadoop安装文件hadoop-2.7.1.tar.gz(本教程也可以用于安装Hadoop 2.7.1版本)。