【版权声明】版权所有,严禁转载,严禁用于商业用途,侵权必究。
作者:厦门大学信息学院计算机科学与技术系 2021级研究生 宋姜豪
指导老师:厦门大学数据库实验室 林子雨 博士/副教授
相关教材:林子雨、郑海山、赖永炫编著《Spark编程基础(Scala版)》
【查看基于Scala语言的Spark数据分析案例集锦】
本案例针对淘宝数据进行分析,采用Scala为编程语言,采用Hadoop存储数据,采用Spark对数据进行处理分析,并对结果进行数据可视化。
一、实验目的
综合运用大数据处理框架Spark、Hadoop及数据可视化技术,对数据进行存储、处理和分析。
二、实验内容
完整实现数据分析全流程,具体如下:
(1)从网络上下载一个数据集;
(2)对数据集进行数据预处理(比如选取部分字段、进行格式转换等),然后保存到HDFS中;可以使用任意编程语言;
(3)使用Spark对数据进行分析(只能使用Scala语言,不能使用Python),可以任意使用SparkCore、SparkSQL、SparkStreaming和SparkMLlib组件,只要使用了Spark编程知识即可;如果有需要,分析结果也可以选择保存到MySQL中;
(4)对分析结果进行可视化呈现,可以任意选择可视化方法(比如R语言可视化、网页可视化以及其他可视化方法),可以使用任意语言(包括Python、Java等在内的任意语言)。
三、实验过程
1、实验环境配置
本次实验使用的Linux操作系统为Ubuntu 18.04,需要提前配置好的环境有Hadoop 3.1.3、Spark 3.2.0、Scala 2.12.15、Python 3.6.9、Java 1.8.0_162、Sbt 1.6.2,需要用到的开发工具有IntelliJ IDEA 2022.1、Pycharm 2022.1,实验环境安装配置可以参考厦门大学数据库实验室博客完成。
2、下载数据集
从阿里云天池实验室下载数据集UserBehavior.csv
(下载链接为https://tianchi.aliyun.com/dataset/dataDetail?dataId=649)。也可以直接从百度网盘下载数据集(提取码:ziyu)。

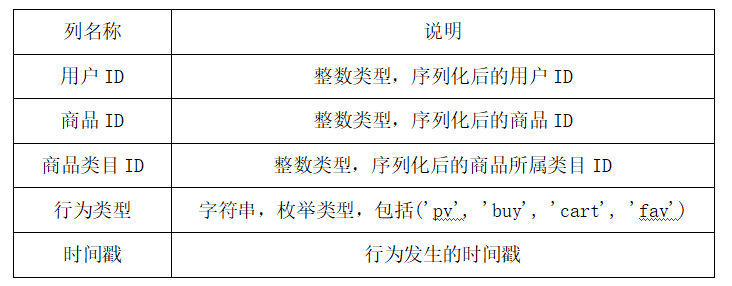
该数据集包含了2017年11月25日至2017年12月3日之间,有行为的约一百万随机用户的所有行为fav(行为包括点击、购买、加购、喜欢)。数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。关于数据集中每一列的详细描述如下:
关于数据集大小的一些说明如下:

3、数据集预处理、保存至HDFS
1)数据集预处理
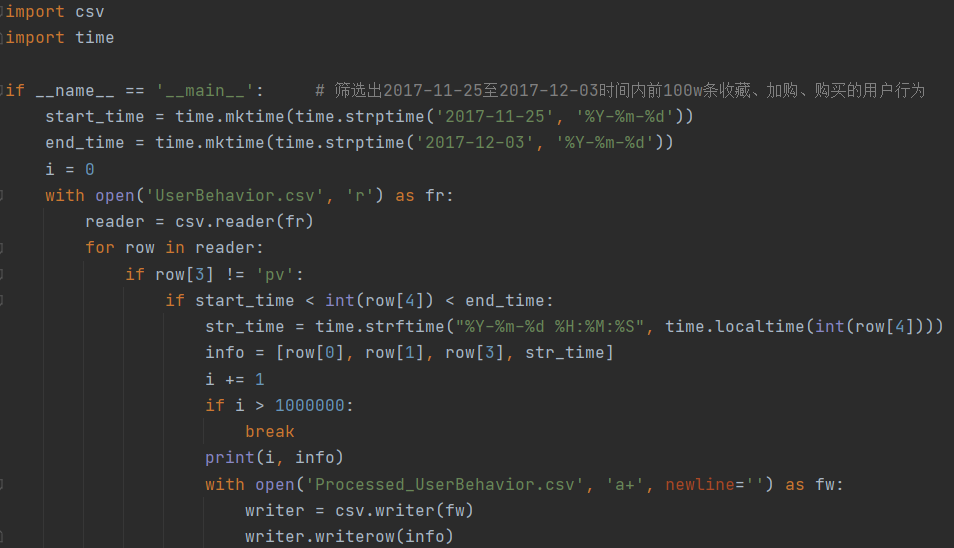
下载后的数据集占用空间3.41GB, 数据量过大,所以仅筛选出2017年11月25日至2017年12月3日时间段内前100w条收藏、加购、购买的用户行为作为本次实验的数据集,并对时间戳转换为具体时间。使用Python程序完成数据集的预处理将处理后的数据集并保存为Processed_UserBehavior.csv文件,处理后的csv文件约38.3MB。预处理相关代码截图如下:
2)数据集上传至HDFS
a、启动HDFS

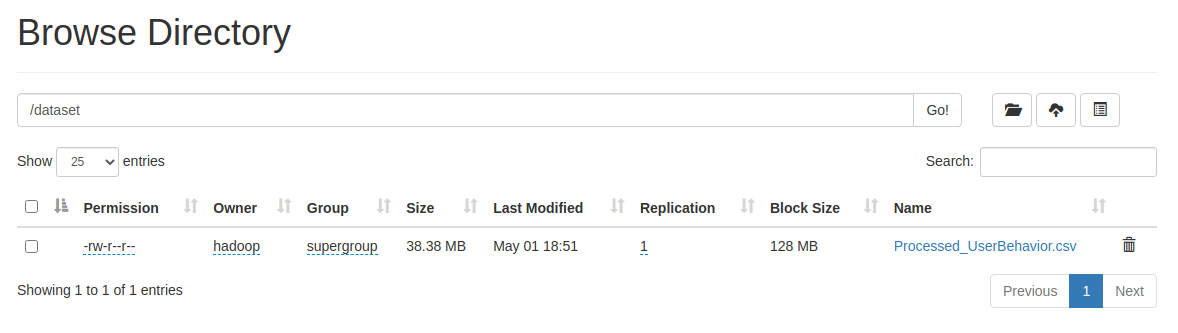
b、在HDFS根目录下新建/dataset目录,将数据集Processed_UserBehavior.csv上传到该目录下

4、使用Scala语言编写Spark程序对数据进行分析
1)使用IDEA构建基于SBT的Scala项目,其中build.sbt文件如下图:
2)启动spark-shell,创建SparkContext和SparkSession对象。
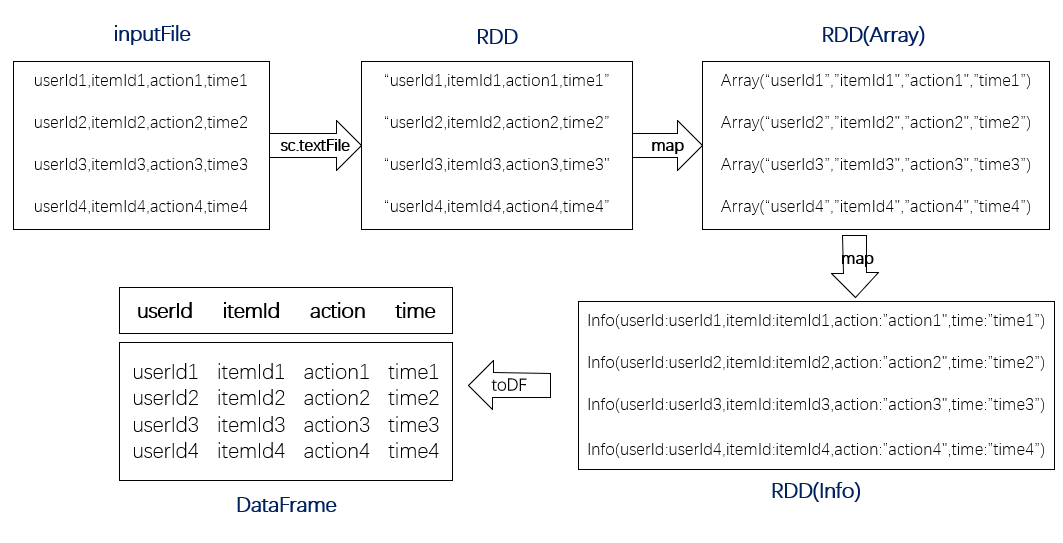
3)从分布式文件系统HDFS中加载数据、将RDD转换为DataFrame。
从RDD转换得到DataFrame有两种方式,一是利用反射机制推断RDD模式,二是使用编程方式定义RDD模式。这里使用第一种方式将RDD转换为DataFrame,需要注意的是应提前定义case class,这样才能被spark隐式转换为DataFrame。
![]()

从csv文件到DataFrame的数据转换示意图如下:
4)使用spark对数据进行分析。
a、用户行为信息统计
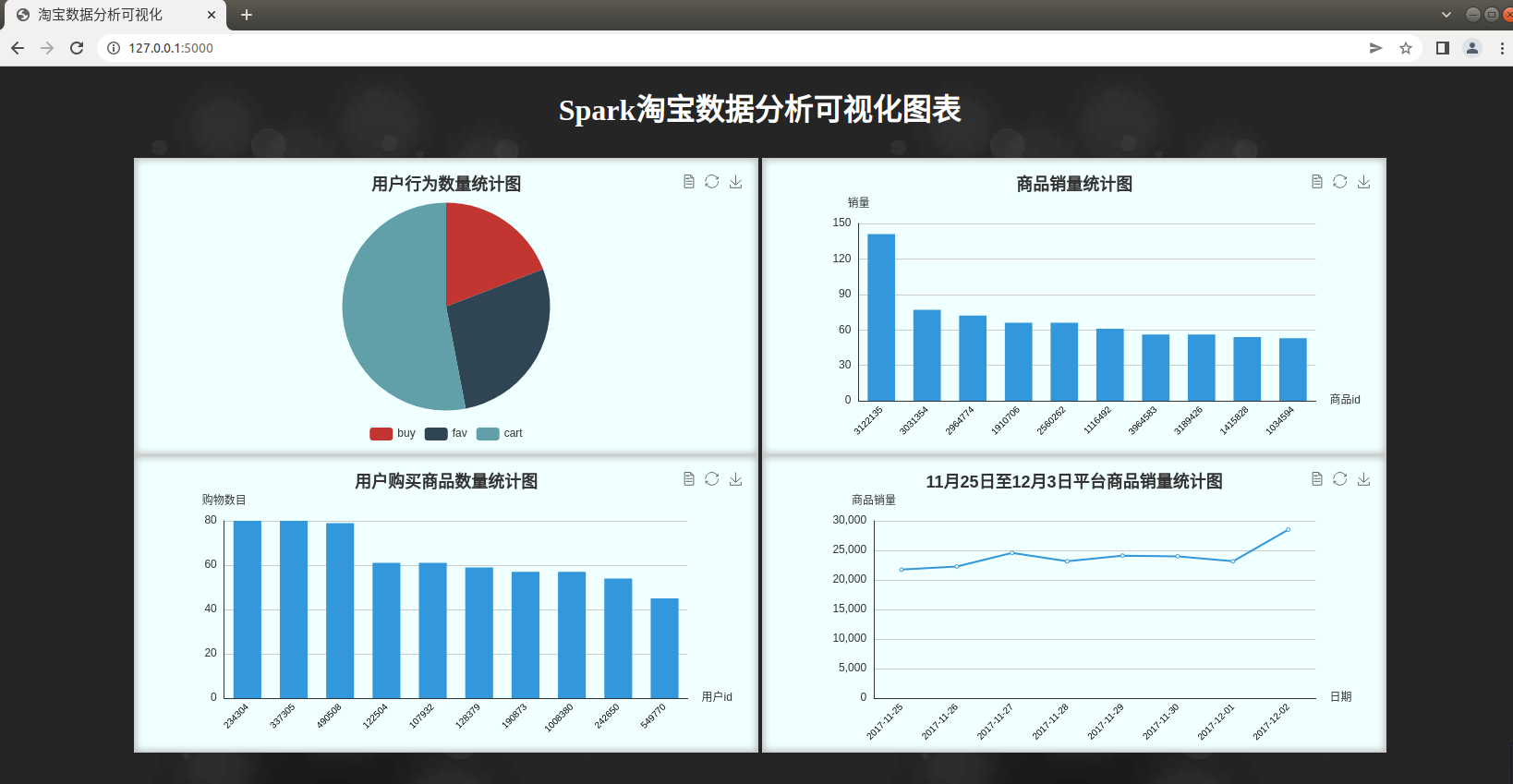
经过数据集预处理后,用户行为被分为三种(buy:购买商品、cart:加入购物车、fav:收藏商品),使用DataFrame的分组聚合操作(groupBy)来统计这三种用户行为的数量、比例等信息。返回的结果是一个DataSet,将其转换为字符串后保存至result1.json文件。

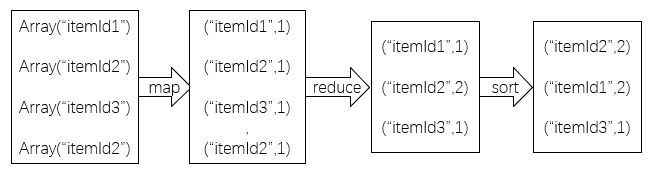
b、销量前十的商品信息统计
根据商品的购买量来统计数据集内销量前十的商品。首先需要对用户的行为
进行过滤,筛选出用户购买商品的行为,然后相应的选择购买的商品id,之后将DataFrame转换为RDD,使用RDD相关操作来统计各商品销售数量,排序后取出销量前十的商品,将商品信息其转换为字符串后保存至result2.json文件。

该过程的RDD转换操作如下图:
c、购物数量前十的用户信息统计
根据商品的购买量来统计数据集内购物数量前十的用户。过滤出用户的购买行为后选择用户id属性,将DataFrame转换为RDD,使用RDD相关操作来统计每个用户id出现的次数,排序后取出出现次数最多的10个用户id,将用户id及购物数量转换为字符串后保存至result3.json文件。

d、时间段内平台商品销量统计
过滤出用户的购买行为后选择购买日期字段,使用RDD操作对当天平台销量汇总统计,最后将每日统计信息存入result4.json文件。

5、使用Flask应用对Spark分析结果进行可视化呈现
前面已经将Spark分析结果保存至本地的json文件中,接下来使用Python编写的轻量级Web应用框架Flask对分析结果进行可视化呈现。
1)建立Flask项目,项目结构如图:
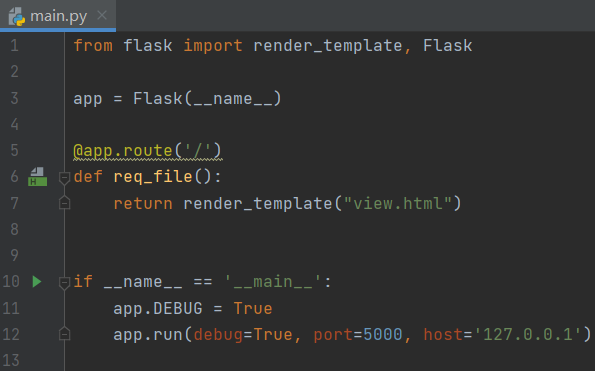
2)Flask搭建Web服务器(main.py)
设置主机为127.0.0.1,端口号5000,将view.html设置为首页,使用render_template()方法渲染模板view.html。
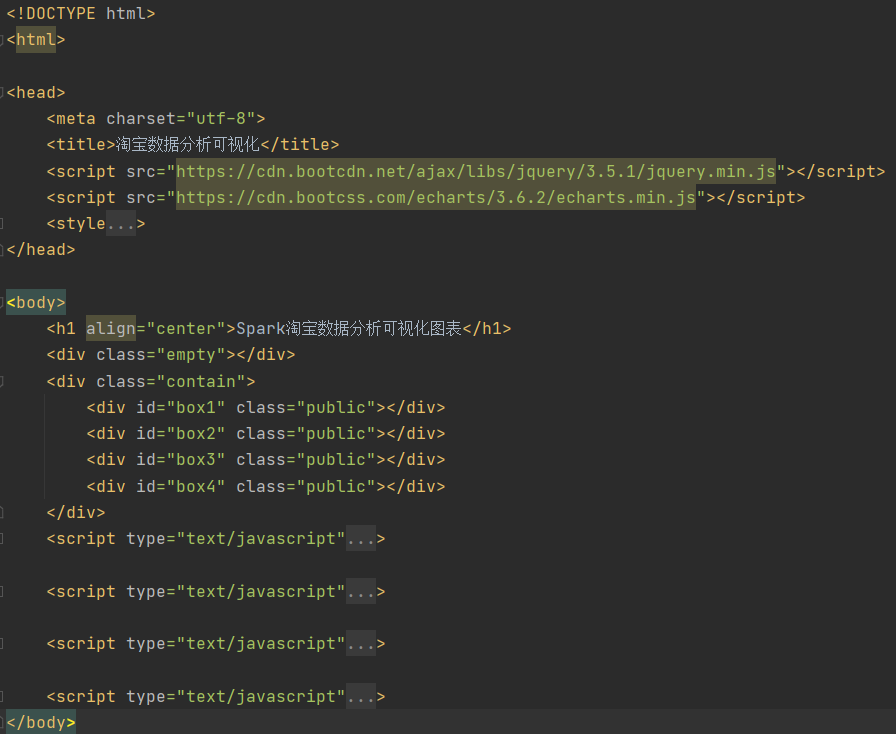
3)Flask简单网页开发(view.html)
a、view.html整体框架如下:
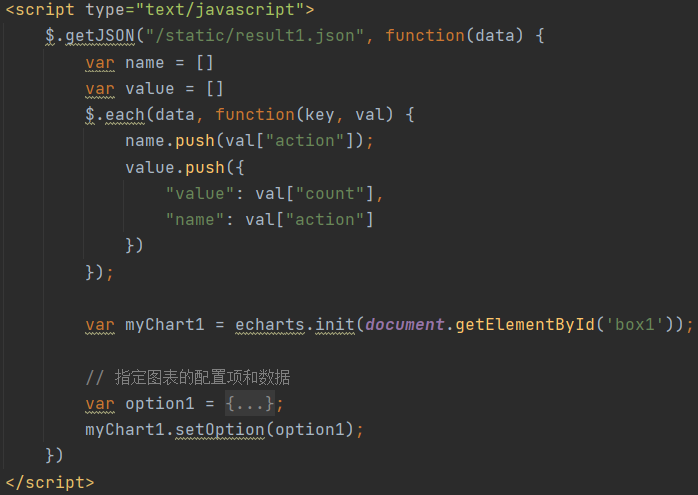
b、使用jquery读取json文件数据,利用echarts绘图
4)可视化结果展示
运行main.py

浏览器打开http://127.0.0.1:5000/,截图如下: