
【版权声明】版权所有,严禁转载,严禁用于商业用途,侵权必究。
作者:厦门大学信息学院2021级研究生 陈涛
基于Scala语言的Spark数据处理分析案例
案例制作:厦门大学数据库实验室
指导老师:厦门大学信息学院计算机系数据库实验室 林子雨 博士/副教授 E-mail: ziyulin@xmu.edu.cn
相关教材:林子雨,赖永炫,陶继平《Spark编程基础(Scala版)》(访问教材官网)
【查看基于Scala语言的Spark数据分析案例集锦】
一、实验环境
(1) Linux: Ubuntu Kylin 16.04 LTS
(2) Hadoop: 3.1.3
(3) Scala:2.12.15
(4) Spark:3.2.0
(5) 开发工具:IntelliJ IDEA 2022.1
(6) 可视化工具:bottle-0.12.19
二、数据预处理
1. 数据集说明
本次作业使用的数据集是来自Kaggle的Dota 2 Matches,可以直接从百度网盘下载(提取码:ziyu)。该数据集收集自DOTA2,主要用于探索玩家行为并预测比赛结果。DOTA2是一款天辉和夜魇两个阵营对战的游戏。本次作业用到的部分数据如下:
- test_labels.csv
match_id: 每场比赛的唯一标识
radiant_win: 天辉阵营是否胜利 - test_player.csv
account_id: 每位玩家的唯一标识,0代表该玩家匿名
hero_id: 每位玩家所选英雄的唯一标识
player_slot: 所在阵营的唯一标识,其中0-4代表天辉阵营,128-132代表夜魇阵营 - hero_names.csv
localized_name: 每位英雄的名字 - player_ratings.csv
Trueskill_mu: 每位玩家的技术评分,评分越高越好2. 将数据集存放至分布式文件系统 HDFS 中
-
启动 hadoop
- cd /usr/local/hadoop
- ./sbin/start-dfs.sh
-
创建 input 文件夹
- ./bin/hdfs dfs -mkdir -p input
-
上传数据集
- ./bin/hdfs dfs -put ~/*.csv input
-
查看数据是否上传成功
- ./bin/hdfs dfs -ls /user/hadoop/input
三、数据分析
1. 建立工程文件
创建项目过程参照(https://dblab.xmu.edu.cn/blog/2825-2/#more-2825)
2. 配置 pom.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>untitled1</artifactId>
<version>1.0-SNAPSHOT</version>
<repositories>
<repository>
<id>alimaven</id>
<name>aliyun maven</name>
<url>https://maven.aliyun.com/repository/public</url>
</repository>
</repositories>
<properties>
<spark.version>3.2.0</spark.version>
<scala.version>2.12</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>3. 具体代码
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SparkSession
import com.alibaba.fastjson.JSON
import org.apache.spark.sql.functions.bround
import java.io.{File, PrintWriter}
import Array._
object DOTA2 {
// 定义样例类
case class match_win(match_id: String, radiant_win: String)
case class match_player(match_id: String, account_id: String, hero_id: String, player_slot: String)
case class hero_names(hero_id: String, localized_name: String)
case class player_rating(account_id: String, trueskill_mu: String)
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("DOTA2").setMaster("local")
val spark = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
// 本地文件路径
val DATA_PATH = "file:///home/hadoop/IdeaProjects/untitled1/src/main/resources/"
// HDFS 文件系统文件路径
val HDFS_PATH = "hdfs://localhost:9000/user/hadoop/input/"
// 读取数据
val InputData1 = spark.read.option("header", "true").csv(DATA_PATH + "test_labels.csv").as[match_win]
val InputData2 = spark.read.option("header", "true").csv(DATA_PATH + "test_player.csv").as[match_player]
val InputData3 = spark.read.option("header", "true").csv(DATA_PATH + "hero_names.csv").as[hero_names]
val InputData4 = spark.read.option("header", "true").csv(DATA_PATH + "player_ratings.csv").as[player_rating]
// 最常选的英雄
val ResData1 = InputData2.groupBy("hero_id").count().join(InputData3, "hero_id").sort($"count".desc)
.select($"localized_name" as ("hero_name"), $"count" as ("pick_nums"))
save("hero_pick.json", ResData1.sample(0.1).collect().map(row => JSON.parse(row.prettyJson)))
val WinNums = InputData1.join(InputData2, "match_id").filter("radiant_win=1 and player_slot<10 or radiant_win=0 and player_slot>100")
.groupBy("hero_id").count().select($"hero_id", $"count" as ("win_nums"))
val PickNums = InputData2.groupBy("hero_id").count().select($"hero_id", $"count" as ("pick_nums"))
val WinPer = WinNums.join(PickNums, "hero_id").map(row => (row.getString(0), row.getLong(1).toFloat / row.getLong(2).toFloat * 100)).toDF("hero_id", "win_per")
// 英雄的胜率
val ResData2 = WinPer.join(InputData3, "hero_id").sort($"win_per".desc)
.select($"localized_name" as ("hero_name"), bround($"win_per", scale=2).alias("win_per"))
val output = concat(ResData2.head(30), ResData2.tail(30))
save("hero_win.json", output.map(row => JSON.parse(row.prettyJson)))
// 玩家数量
val PlayerNum = InputData2.select("account_id").distinct().count() - 1
println(s"the number of players is $PlayerNum")
// 玩家水平
InputData4.createTempView("player_ratings")
// 使用 sql 语句
val SqlData1 = spark.sql("select account_id, ROUND(trueskill_mu, 2) AS skill_rating from player_ratings where account_id > 0 order by trueskill_mu - 0.0 desc limit 10")
val ResData3 = InputData4.select($"trueskill_mu".cast("int")).groupBy($"trueskill_mu".alias("skill_rating")).count().sort($"skill_rating".asc)
val json = ResData3.collect().map(row => JSON.parse(row.prettyJson))
save("player_ratings.json", json)
}
// 将数据存入文件
def save(name: String, data: Array[Object]): Unit = {
val file = new PrintWriter(new File("file:///home/hadoop/IdeaProjects/untitled1/src/main/VisualData/" + name))
file.println("[" + data.mkString(",") + "]")
file.close()
}
}四、数据可视化
1. 具体代码
使用 python Web 框架 bottle 访问可视化页面方便进行 json 数据的读取。使用下面代码web.py 可以实现一个简单的静态文件读取:
from bottle import route, run, static_file
import json
@route('/static/<filename>')
def server_static(filename):
return static_file(filename, root="./static")
@route("/<name:re:.*\.html>")
def server_page(name):
return static_file(name, root=".")
@route("/")
def index():
return static_file("index.html", root=".")
run(host="0.0.0.0", port=9999)
实现主页文件 index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width,height=device-height">
<title>TMDb 电影数据分析</title>
<style>
/* 略,详见项目文件 */
</style>
</head>
<body>
<div class="container">
<h1 style="font-size: 40px;"># DOTA2 Matches Data Analysis <br> <small style="font-size: 55%;color: rgba(0,0,0,0.65);">>
Big Data Processing Technology on Spark</small> </h1>
<hr>
<h1 style="font-size: 30px;color: #404040;">I. Overviews</h1>
<div class="chart-group">
<h2>- Skill Rating Distribution for Players <br> <small style="font-size: 72%;">> This figure
shows the skill rating distribution for players, most players are concentrated
bear the median.</small> </h2>
<iframe src="player_ratings.html" class="frame" frameborder="0"></iframe>
</div>
<br>
/* 其他图表页面导入方式同上,略 */
</div>
<script>/*Fixing iframe window.innerHeight 0 issue in Safari*/document.body.clientHeight;</script>
</body>
</html> 启动网页服务器 python3 web.py
打开浏览器访问 http://0.0.0.0:9995/ 查看数据可视化后的图表
2. 可视化结果
(1). 玩家的技术评分分布
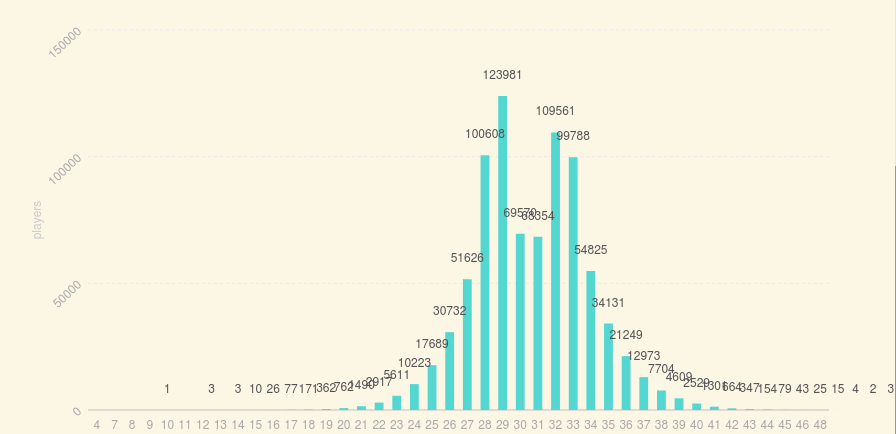
从图中可以看出大部分玩家的技术评分集中在中值附近。
(2). 前30个胜率高的和后30个胜率低的英雄

胜率最高的英雄是 Omniknight, 胜率最低的英雄是 Broodmother
(3). 英雄的出场数分布
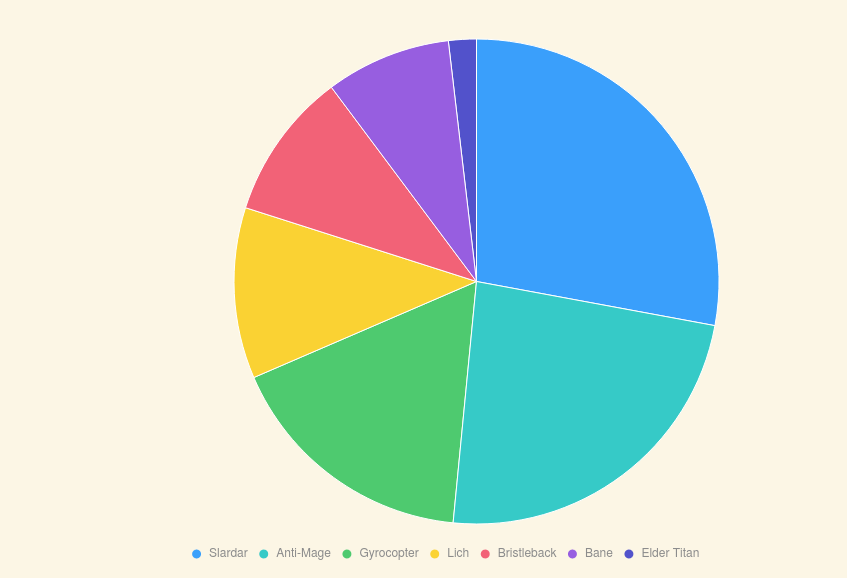
随机抽样10位英雄,比较不同英雄的出场比例。玩家最常选的英雄是 Slardar, 最少选的英雄是 Elder Titan。