
【版权声明】版权所有,严禁转载,严禁用于商业用途,侵权必究。
作者:厦门大学信息学院计算机科学系2020级研究生 黄连福
指导老师:厦门大学数据库实验室 林子雨 博士/副教授
相关教材:林子雨、陶继平编著《Flink编程基础(Scala版)》(官网)
相关案例:基于Scala语言的Flink数据处理分析案例集锦
本实验针对美国县域信息数据进行分析,使用scala语言进行flink编程来处理数据,最后结果使用python进行可视化
本实验涉及到的所有数据集和代码,可以从百度网盘下载。提取码:ziyu。
一、 实验环境
- Windows 10 家庭中文版
- IntelliJ IDEA 2019.3(Ultimate Edition)
- apache-maven-3.8.1
- python 3.8.7
- flink 1.11.2
二、 数据集
美国县域信息(US County information),总共有3094行信息。每行有6个属性字段。如下所示:
- County:指美国的郡县名,比如有Autauga(奥陶加县)、Baldwin(鲍德温县)等.
- State:指对应郡县所属的州,比如有Alabama(亚拉巴马州)、Alaska(阿拉斯加州)等。
- FIPS Code:联邦信息处理标准(FIPS)现称为联邦信息处理系列,是由美国国家标准与技术研究院(NIST)指定的数字代码。
- Population:记录当前郡县人口数量。
- Area:记录当前郡县的土地面积。单位为平方英里。
- Density:记录当前郡县的人口密度。可通过人口数量与土地面积计算得出。单位为人/每平方英里。
数据具体样式如下所示:

下载地址:https://github.com/balsama/us_counties_data
三、使用flink进行数据处理与分析
为了方便数据的存储,首先定义一个案例类存储数据集中的数据。
//根据表格内容 定义一个POJOs存取内容
//字段包括county:郡县名、state:州名、FIPS Code:区域编码、population:人口数量、area:面积、Density:人口密度
case class countyInfo(county:String,state:String,FIPS:String,
population:Int,area:Int,Density:Int)
1.计算某一州面积最大的郡县
(1)流程图如下所示(以Alaska州为例):
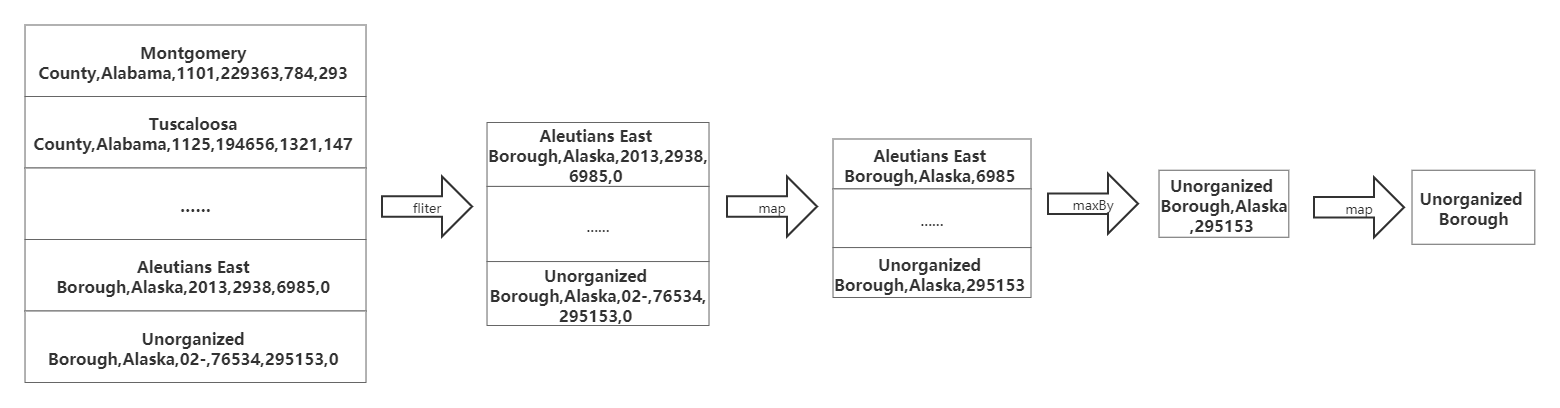
由于只计算Alaska州各郡县面积中的最大者,首先我们要对数据进行过滤,我们使用filter算子,只保留state为Alaska的数据。接着在使用map算子去掉多余的字段(比如FIPS Code、population等)。然后使用maxBy算子指定面积字段得出面积最大者。最后再次使用map算子得出郡县名字段。
在本例中Alaska州面积最大的郡县为Unorganized Borough。与下图维基百科所查一致。

(2)代码如下:
//求一个州里面积最大的郡县
def getMaxAreaCountyInState(StateName:String,inputPath:String) = {
// 设置批执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 得到输入数据
val input = env.readCsvFile[countyInfo](inputPath,ignoreFirstLine = true)//从CSV中读取数据,并忽略第一行属性字段
// 统计该州面积最大的郡
val county = input.filter( _.state == StateName)//过滤数据,只留下该州的信息
.map(x => (x.area,x.county,x.state))//保留有用字段
.maxBy(0)//取出面积最大的元组
.map(x => x._2)//只保留名称字段
// 执行并输出结果
println(StateName+"面积最大的县是")
county.print()
2.统计各州总人数、总面积、人口密度
(1)流程图如下所示:
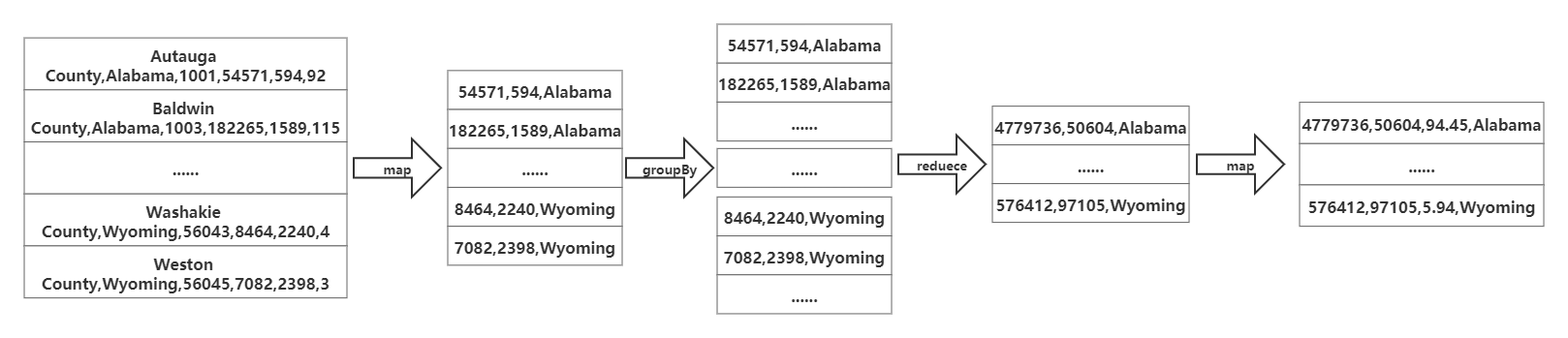
由于要统计的数据为各州的总人数、总面积及人口密度。首先我们先使用map算子去掉一些无用的字段。接着使用groupBy算子指定以州字段进行分组。然后再使用reduce算子计算州的总人数和总面积。最后使用map算子额外映射出一个人口密度字段,值为总人数除以总面积,单位为人/每平方英里,保留两位小数。
(2)代码如下:
//统计州信息
def getStateInformation(inPath:String,outPath:String)={
// 设置批执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 得到输入数据
val input = env.readCsvFile[countyInfo](inPath,ignoreFirstLine = true)//从CSV中读取数据,并忽略第一行属性字段
// 统计每州的数据
val state = input.map(x => (x.population,x.area,x.state)) //去掉一些无用的字段,比如FIPS Code
.groupBy(2) //按州来聚合数据
.reduce((x,y)=>(x._1+y._1,x._2+y._2,x._3)) //计算每州的总人口,和总面积
.map((x)=>(x._1,x._2,(x._1.asInstanceOf[Float]/x._2.asInstanceOf[Float]).formatted("%.2f"),x._3))//计算每州的人口密度保留两位小数
.setParallelism(1)
// 执行并输出结果
state.writeAsCsv(outPath)
state.print()
}
}
3.计算统计数据Top-10的州
(1)流程图如下所示(以统计面积前10的州为例):
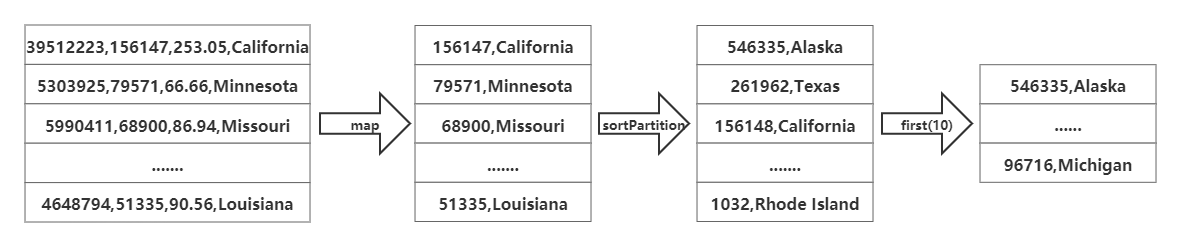
由于要计算面积前10的州,可以使用3.2节得出的结果文件state.csv作为输入,首先使用map算子取出我们需要统计的字段(面积、人口或者人口密度)及州名,接着使用sortPartition算子并指定排序字段及排序方式进行排序。最后使用first(n)算子取出前n条数据。
(2)代码如下:
//计算统计数据top10的州
def getStateTop10(relativePath: String) = {
// 设置批执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 得到输入数据
val input:DataSet[(Int,Int,Float,String)] = env.readCsvFile(relativePath+"state.csv")
//计算每种数据的top10
//1.计算人口总数top10
val population = input.map((x)=>(x._1,x._4)) //取出字段
.sortPartition(0,Order.DESCENDING) //按人数降序排序
.setParallelism(1)
.first(10) //取排序后前10的州
//2.计算面积top10
val area = input.map((x)=>(x._2,x._4)) //取出字段
.sortPartition(0,Order.DESCENDING) //按面积降序排序
.setParallelism(1)
.first(10) //取排序后前10的州
//3.计算人口密度top10
val density = input.map((x)=>(x._3,x._4)) //取出字段
.sortPartition(0,Order.DESCENDING) //按人口密度降序排序
.setParallelism(1)
.first(10) //取排序后前10的州
// 执行并输出结果
population.writeAsCsv(relativePath+"populationTop10.csv")
population.print()
area.writeAsCsv(relativePath+"areaTop10.csv")
area.print()
density.writeAsCsv(relativePath+"densityTop10.csv")
density.print()
}
四、数据可视化
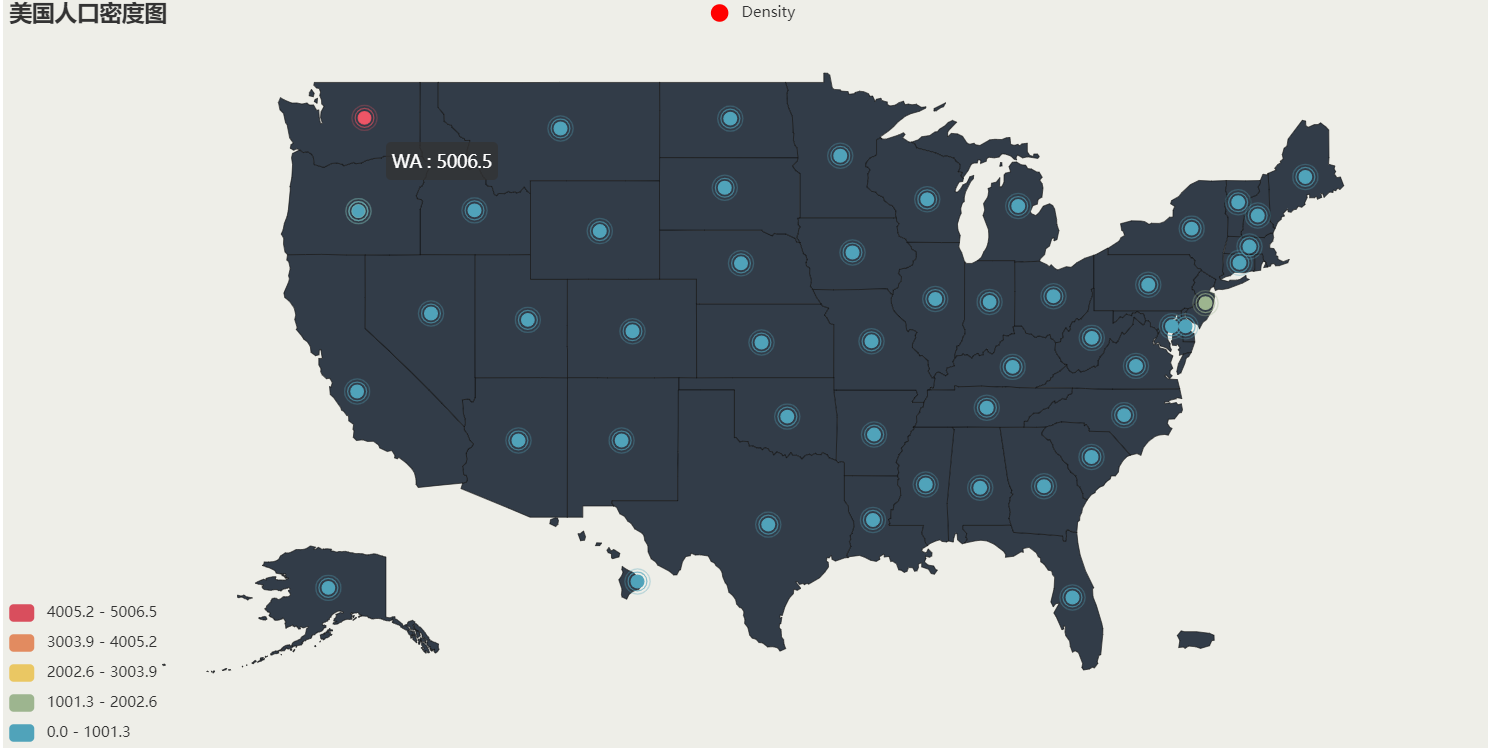
1.美国人口密度散点图
(1)代码如下:
def drawUsDensityMap(inUrl,outUrl):
#各州对应缩写的字典
state_dict = {"Alabama":"AL","Alaska":"AK","Arizona":"AZ","Arkansas":"AR","California":"CA",
"Colorado":"CO","Connecticut":"CT","Delaware":"DE","Florida":"FL","Georgia":"GA",
"Hawaii":"HI","Idaho":"ID","Illinois":"IL","Indiana":"IN","Iowa":"IA",
"Kansas":"KS","Kentucky":"KY","Louisiana":"LA","Maine":"ME","Maryland":"MD",
"Massachusetts":"MA","Michigan":"MI","Minnesota":"MN","Mississippi":"MS","Missouri":"MO",
"Montana":"MT","Nebraska":"NE","Nevada":"NV","New Hampshire":"NH","New Jersey":"NJ",
"New Mexico":"NM","New York":"NY","North Carolina":"NC","North Dakota":"ND","Ohio":"OH",
"Oklahoma":"OK","Oregon":"OR","Pennsylvania":"PA","Rhode Island":"R","South Carolina":"SC",
"South Dakota":"SD","Tennessee":"TN","Texas":"TX","Utah":"UT","Vermont":"VT",
"Virginia":"VA","Washington":"WA","West Virginia":"WV","Wisconsin":"WI","Wyoming":"WY"
}
try:
register_url("https://echarts-maps.github.io/echarts-countries-js/")
except Exception:
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
register_url("https://echarts-maps.github.io/echarts-countries-js/")
df = pd.read_csv(inUrl,names=['population','area','density','state'])#从文件中读取数据
density = df['density'].tolist()
state = df['state'].tolist()
#全称和缩写的映射
for i in range(len(state)):
state[i] = state_dict[state[i]]
list = [[state[i],density[i]] for i in range(len(state))] # 合并两个list为一个list
maxDensity = max(density) # 计算最大密度,用作图例的上限
geo = ( # 添加坐标点
Geo(init_opts=opts.InitOpts(width = "1200px", height = "600px", bg_color = '#EEEEE8'))
.add_schema(maptype="美国",itemstyle_opts=opts.ItemStyleOpts(color="#323c48", border_color="#111"))
.add_coordinate('WA',-120.04,47.56).add_coordinate('OR',-120.37,43.77).add_coordinate('CA',-120.44,36.44).add_coordinate('AK',-122.00,28.46)
.add_coordinate('ID',-114.08,43.80).add_coordinate('NV',-116.44,39.61).add_coordinate('MT',-109.42,47.13).add_coordinate('WY',-107.29,42.96)
.add_coordinate('UT',-111.19,39.35).add_coordinate('AZ',-111.70,34.45).add_coordinate('HI',-105.25,28.72).add_coordinate('CO',-105.52,38.89)
.add_coordinate('NM',-106.11,34.45).add_coordinate('ND',-100.22,47.53).add_coordinate('SD',-100.52,44.72).add_coordinate('NE',-99.64,41.65)
.add_coordinate('KS',-98.53,38.43).add_coordinate('OK',-97.13,35.42).add_coordinate('TX',-98.16,31.03).add_coordinate('MN',-94.26,46.02)
.add_coordinate('IA',-93.60,42.09).add_coordinate('MO',-92.57,38.48).add_coordinate('AR',-92.43,34.69).add_coordinate('LA',-92.49,31.22)
.add_coordinate('WI',-89.55,44.25).add_coordinate('MI',-84.62,43.98).add_coordinate('IL',-89.11,40.20).add_coordinate('IN',-86.17,40.08)
.add_coordinate('OH',-82.71,40.31).add_coordinate('KY',-84.92,37.44).add_coordinate('TN',-86.32,35.78).add_coordinate('MS',-89.63,32.66)
.add_coordinate('AL',-86.68,32.53).add_coordinate('FL',-81.68,28.07).add_coordinate('GA',-83.22,32.59).add_coordinate('SC',-80.65,33.78)
.add_coordinate('NC',-78.88,35.48).add_coordinate('VA',-78.24,37.48).add_coordinate('WV',-80.63,38.62).add_coordinate('PA',-77.57,40.78)
.add_coordinate('NY',-75.22,43.06).add_coordinate('MD',-76.29,39.09).add_coordinate('DE',-75.55,39.09).add_coordinate('NJ',-74.47,40.03)
.add_coordinate('VT',-72.70,44.13).add_coordinate('NH',-71.64,43.59).add_coordinate('MA',-72.09,42.33).add_coordinate('CT',-72.63,41.67)
.add_coordinate('RI',-71.49,41.64).add_coordinate('ME',-69.06,45.16).add_coordinate('PR',-75.37,26.42).add_coordinate('DC',-77.04,38.90)
.add("Density", list,symbol_size = 10,itemstyle_opts = opts.ItemStyleOpts(color="red"))
.set_series_opts(label_opts=opts.LabelOpts(is_show=False),type='effectScatter')
.set_global_opts(
title_opts=opts.TitleOpts(title="美国人口密度图"),
visualmap_opts=opts.VisualMapOpts(max_ = maxDensity,is_piecewise=True),
)
.render(outUrl)
)
(2)结果如下:
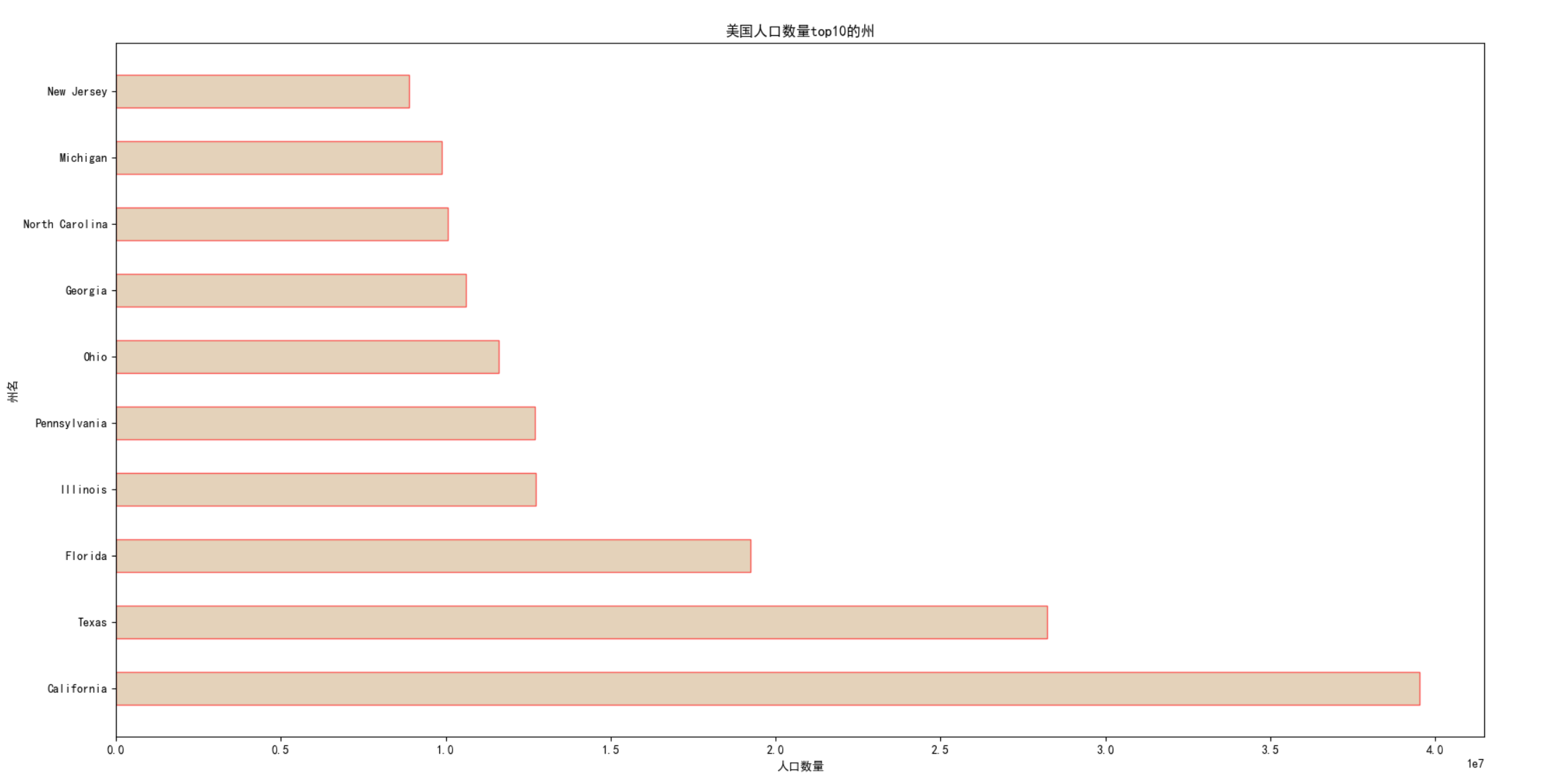
2.美国人口前10的州柱状图
(1)代码如下:
def drawTop10PopulationState(inUrl):
#解决中文乱码
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#从文件中读取数据
df = pd.read_csv(inUrl,names=['population','state'])
population = df['population'].tolist()
state = df['state'].tolist()
#画图
# 设置x,y轴标签
plt.xlabel("人口数量")
plt.ylabel("州名")
plt.barh(state,population,facecolor='tan',height=0.5,edgecolor='r',alpha=0.6)
plt.title("美国人口数量top10的州")
plt.show()
(2)结果如下:
3.美国各州基于面积的词云图
(1)代码如下:
def drawAreaWordCloud(inUrl):
#1从文件中读取数据
df = pd.read_csv(inUrl,names=['population','area','density','state'])
area = df['area'].tolist()
state = df['state'].tolist()
#2.将面积和州名建立成字典
dict = {}
for i in range(len(state)):
dict[state[i]]=area[i]
#3.生成词云
wc = wordcloud.WordCloud(
background_color='white', # 背景颜色
width=800,
height=600,
max_font_size=50, # 字体大小
min_font_size=10,
mask=plt.imread('C:\\Users\\91541\\Pictures\\Saved Pictures\\map.jpg'), # 背景图片
max_words=1000 )
wc.generate_from_frequencies(dict)
wc.to_file('D:\\Area.jpg') # 4.图片保存
(2)结果如下:
4.美国人口密度前10的州饼状图
(1)代码如下:
def drawDensityPie(inUrl):
#解决中文乱码
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#从文件中读取数据
df = pd.read_csv(inUrl,names=['density','state'])
density = df['density'].tolist()
state = df['state'].tolist()
#画图
plt.axes(aspect=1)
plt.pie(x=density,labels=state,autopct="%0f%%",shadow=True)
plt.title("美国人口密度前10的州饼状图")
plt.show()
(2)结果如下:
