
【版权声明】版权所有,严禁转载,严禁用于商业用途,侵权必究。
作者:厦门大学信息学院计算机系2020级研究生 朱航
指导老师:厦门大学数据库实验室 林子雨 博士/副教授
相关教材:林子雨、陶继平编著《Flink编程基础(Scala版)》(官网)
相关案例:基于Scala语言的Flink数据处理分析案例集锦
一、实验环境
(1)Windows
(2)Java:1.8
(3)Scala:2.11
(4)Flink:1.9.1(查看安装教程)
二、数据集
本次实验使用的数据集是Airbnb于 2019 年 4 月 17 日公开的北京地区数据集Beijing, China,可以从数据源网站上下载数据集,也可从百度网盘下载(提取码:ziyu)。这里选择了其中的短租房源基础信息表listings.csv,包括房源、房东、位置、类型、价格、评论数量和可租时间等等。数据集为csv格式,共包含25211项数据,每项数据包含以下字段:
| 字段名 | 含义 | 示例 |
|---|---|---|
| id | 房间编号 | 整型,"9567683" |
| name | 房间名称 | 字符串,"【青蕖】朝阳北路/大悦城/十里堡/6号线地铁,一室一厅独享整套阳光,可月租" |
| host_id | 房东编号 | 整型,"43175532" |
| host_name | 房东名称 | 字符串,"孜孜" |
| neighbourhood_group | 所属区域组,在本城市中无实际含义。 | 字符串,无。 |
| neighbourhood | 行政区域 | 字符串,"朝阳区 / Chaoyang" |
| latitude | 纬度 | 浮点型,"39.92218" |
| longitude | 经度 | 浮点型,"116.50494" |
| room_type | 房间类型(整套、独立房间、床位) | 字符串,"Entire home/apt" |
| price | 价格 | 整型,"343" |
| minimum_nights | 最少住几晚 | 整型,"1" |
| number_of_reviews | 评论数 | 整型,"166" |
| last_review | 上一次评论的时间 | 时间戳,"2021-02-08" |
| reviews_per_month | 平均每月评论数 | 浮点数,"2.60" |
| calculated_host_listings_count | 房间数 | 整型,"2" |
| availability_365 | 一年内可租用天数 | 整型,"295" |
三、步骤概述
由于我们使用的数据集是一种保存好的有边界数据,所以使用Flink批处理应用程序,大致包含以下5个步骤:
(1)建立环境。
(2)创建数据源读取数据。
(3)对数据集指定转换操作。
(4)输出数据转换结果。
(5)对结果进行可视化。
四、详细代码
1.建立环境
本次实验中使用IntelliJ IDEA完成对于RentAnalysis程序的开发调试。实验完整工程文件可从百度云盘中下载获取(提取码:ziyu)。
(1)IDEA项目的创建
启动IDEA后,选择New-->Project,建立一个基于java 1.8的maven项目,注意不从任何原型进行开发,详细步骤如下所示:
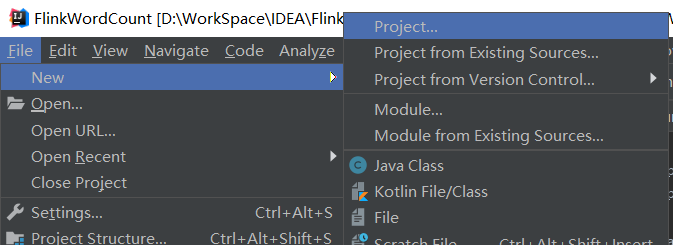
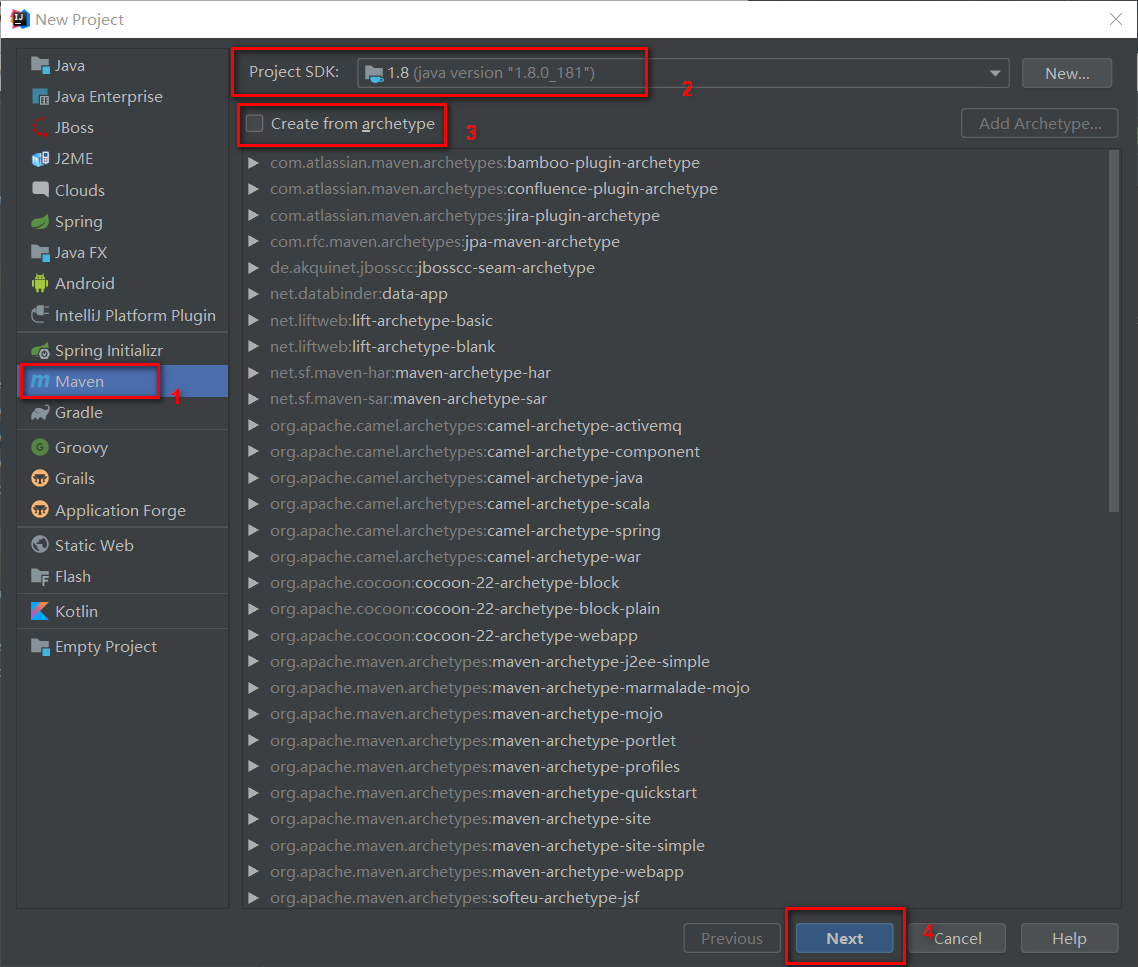
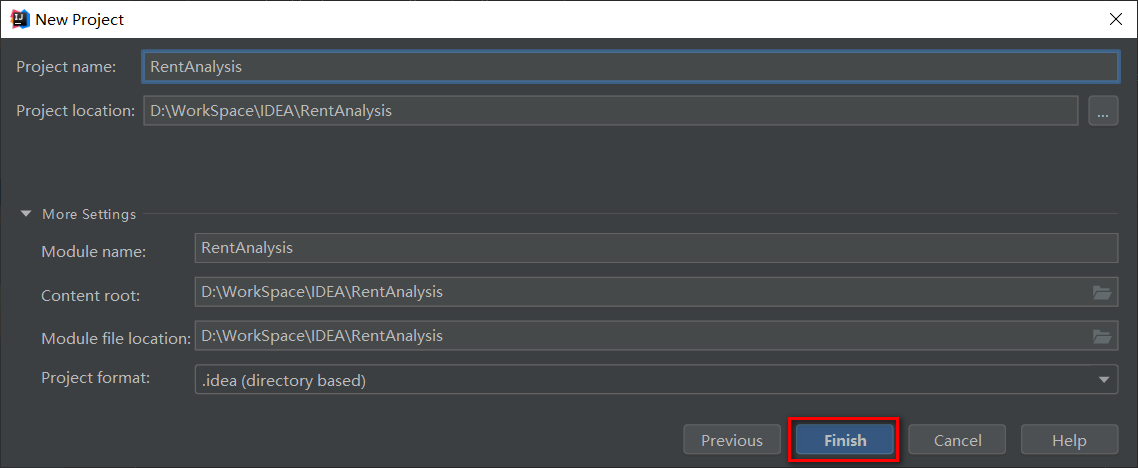
填写GroupId和ArtifactId。这里的GroupId是BigData,ArtifactId是RentAnalysis,然后一直点击下一步完成项目文件创建。

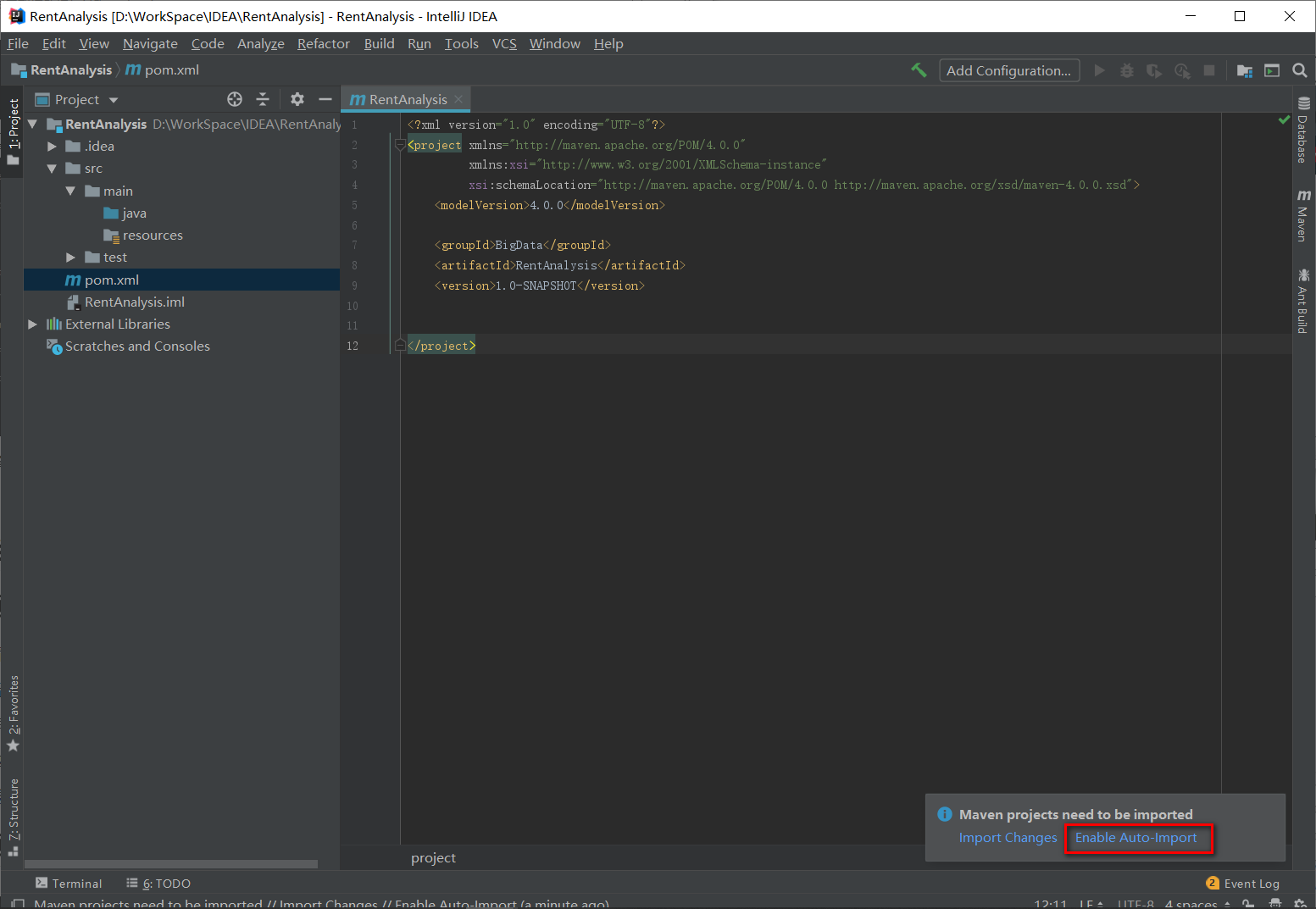
建立好的项目文件目录如下所示,记得点击Enable Auto-Import。
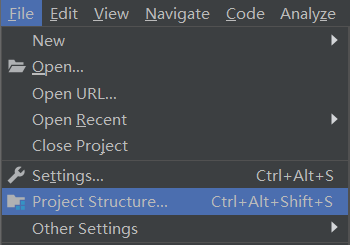
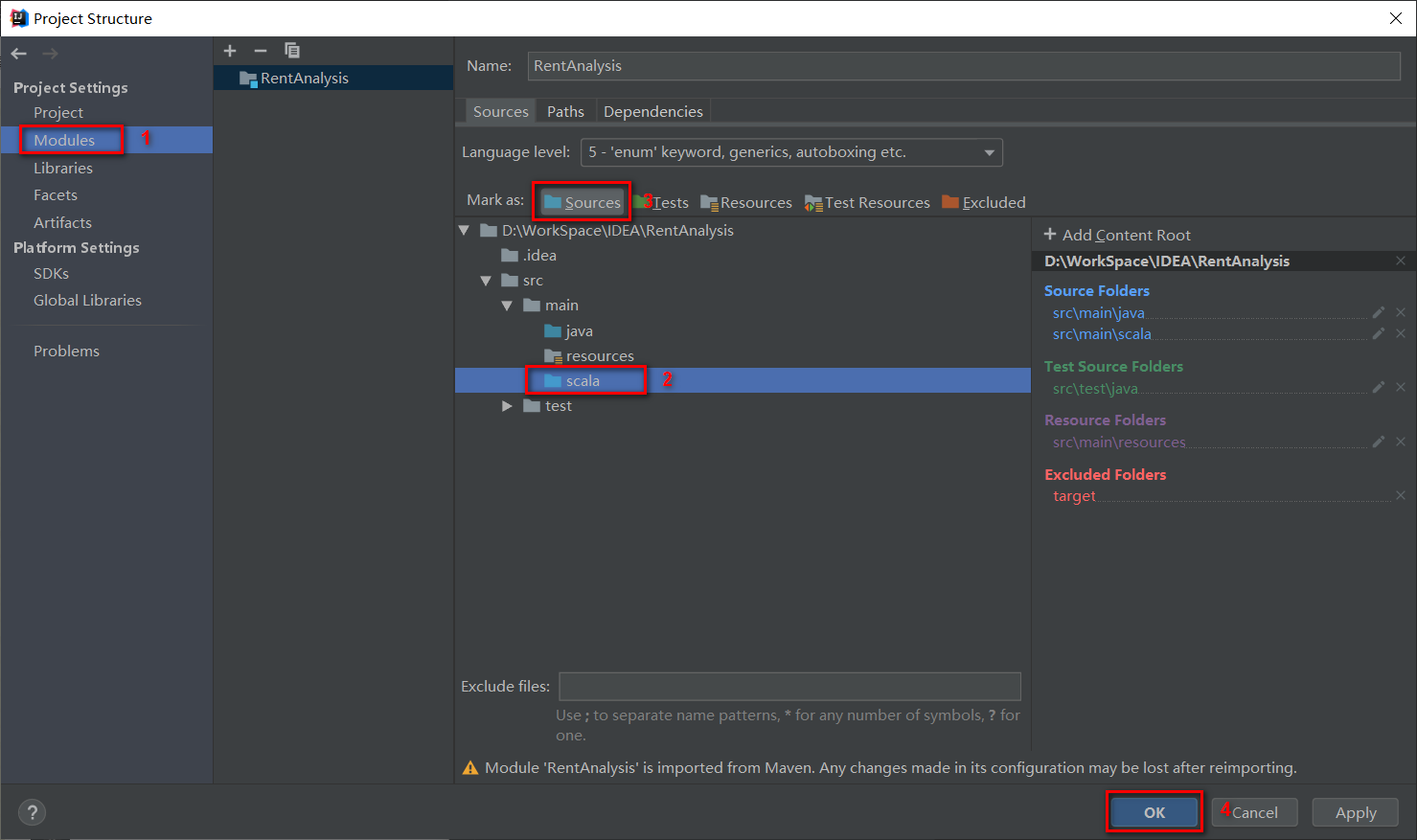
在src下新建scala目录,然后选择Project Structure,将scala目录标记为Sources;
(2)环境配置
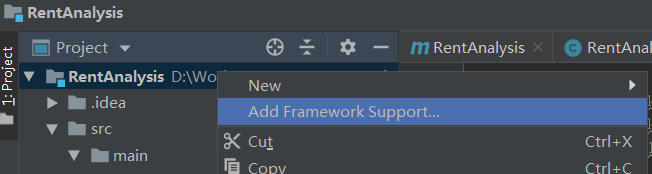
下面需要为项目添加Scala框架支持,从而可以新建Scala代码文件,在项目名称RentAnalysis上右键鼠标,选择Add Framework Support:
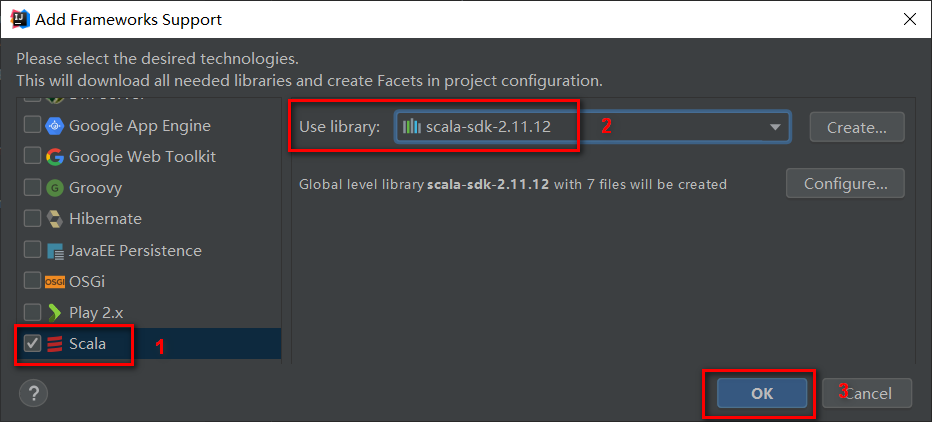
如下图所示,在Add Frameworks Support选择scala,使用2.11.12版本。
打开pom.xml文件,添加有关flink-scala的依赖,修改为如下内容:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>BigData</groupId>
<artifactId>RentAnalysis</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.9.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.6.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
(3)目录文件
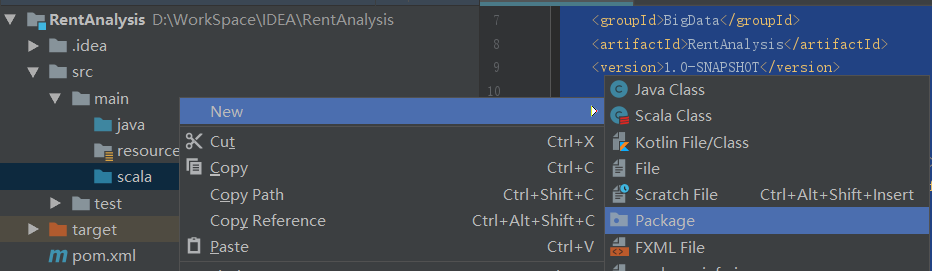
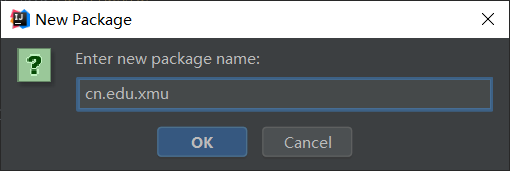
如下图所示,在scala目录下新建一个包cn.xmu.edu,以后有关数据的处理函数都放在该目录下。
将数据文件listings.csv放在resource目录下,项目结构如下图所示,我们就完成了RentAnalysis项目的搭建和环境配置。
2. 数据输入
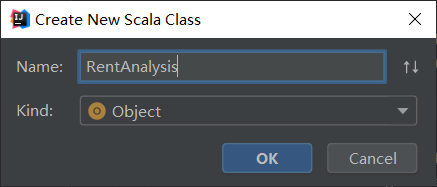
在cn.edu.xmu目录下新建RentAnalysis.scala文件用于读取resources目录下的listings.csv文件。
由于原数据集使用csv文件存储,因此读取时使用的是flink提供的readCsvFile函数,具体细节如下所示:
package cn.edu.xmu
import org.apache.flink.api.scala._
case class RentData(id:Int, name:String, host_id:Int, host_name:String, neighbourhood_group:String,
neighbourhood:String, latitude:Double, longitude:Double, room_type:String, price:Int,
minimum_nights:Int, number_of_reviews:Int, last_review:String, reviews_per_month:Double,
calculated_host_listings_count:Int, availability_365:Int)
object RentAnalysis {
def main(args: Array[String]):Unit={
val env = ExecutionEnvironment.getExecutionEnvironment
val filePath = "src/main/resources/listings.csv"
val rentList = env.readCsvFile[RentData](filePath, ignoreFirstLine=true)
rentList.print()
}
}
出现的错误:
Caused by: org.apache.flink.api.common.io.ParseException: Line could not be parsed: '43810965,兰各庄139号公寓-粉色阳光,324441744,未然,,昌平区,40.06744,116.37813,Entire home/apt,149,20,0,,,2,89'
ParserError EMPTY_COLUMN
Expect field types: class java.lang.Integer, class java.lang.String, class java.lang.Integer, class java.lang.String, class java.lang.String, class java.lang.String, class java.lang.Double, class java.lang.Double, class java.lang.String, class java.lang.Integer, class java.lang.Integer, class java.lang.Integer, class java.lang.String, class java.lang.Double, class java.lang.Integer, class java.lang.Integer
in file: file:/D:/WorkSpace/IDEA/RentAnalysis/src/main/resources/listings.csv
解决办法:
- 在readCsvFile函数中添加参数lenient,设置为true,意思是启用宽松的解析,即忽略无法正确解析的行。原来的读取命令修改为下面的内容:
val rentList = env.readCsvFile[RentData](filePath, ignoreFirstLine=true, lenient = true)
但是这种处理,会导致丢失大量的数据,使用如下命令统计数据集的大小,最终显示这种处理后得到的数据仅剩下13062条。
val list_length = rentList.count()
println(list_length)
- 将各字段的值全部先认为是字符串类型,读取之后再进行其他解析操作。
case class RawData(id:String, name:String, host_id:String, host_name:String, neighbourhood_group:String,
neighbourhood:String, latitude:String, longitude:String, room_type:String, price:String,
minimum_nights:String, number_of_reviews:String, last_review:String, reviews_per_month:String,
calculated_host_listings_count:String, availability_365:String)
object RentAnalysis {
def main(args: Array[String]):Unit={
val env = ExecutionEnvironment.getExecutionEnvironment
val filePath = "src/main/resources/listings-preprocess.csv"
val rawList = env.readCsvFile[RawData](filePath, ignoreFirstLine=true)
val list_length = rawList.count()
println(list_length)
rawList.print()
}
}
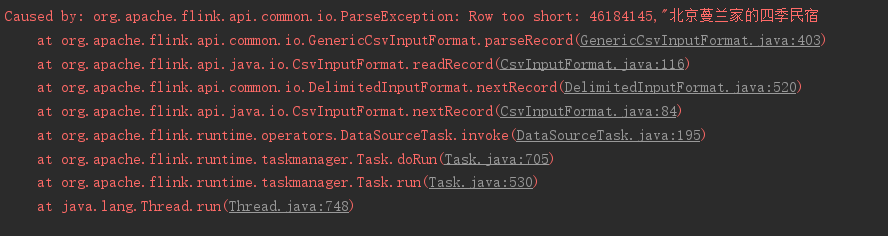
出现以下错误,有些行过短,查看数据发现,这是因为数据被分到多行导致无法正常解析。此外,还发现数据源中存在双引号之间有间隔符出现的情况,需要进行替换。




针对这种情况,应该将两引号间的多行合并起来出来,将引号间的逗号分隔符替换,故使用以下python脚本完成数据的预处理。
# 替换字符串中双引号之间的逗号为间隔号
def trim_comma(str1):
if str1.find('\"') == -1:
return str1
lid = str1.find('\"')
rid = str1.rfind('\"')
result = str1[:lid]+str1[lid:rid].replace(",", "-")+str1[rid:]
return result
f = open("listings.csv", "r", encoding='utf-8')
data = f.readlines()
newdata = []
tempdata = ""
f.close()
# 是否复制该行数据
flag = True
for i in range(len(data)):
if flag:
# 若一行只有1个双引号,就说明数据被分割到多行了,进行合并处理
if data[i].count("\"") == 1:
tempdata = tempdata+data[i][:-1]+"-"
flag = False
else:
tempdata = trim_comma(data[i])
newdata.append(tempdata)
tempdata = ""
else:
if data[i].count("\"") == 1:
tempdata = tempdata+data[i]
flag = True
tempdata = trim_comma(tempdata)
newdata.append(tempdata)
tempdata = ""
else:
tempdata = tempdata+data[i][:-1]+"-"
f = open("listings-preprocess.csv", "w", encoding='utf-8')
f.writelines(newdata)
f.close()
然后通过读取listing-preprocess.csv,发现能够正确读取数据,共25026条。
3. 数据转换
(1)数据清洗
a.冗余去重
使用如下命令进行冗余去重,删除数据集中重复的元素,并输出去重后数据集的大小:
val distinctDS = rawList.distinct()
list_length = distinctDS.count()
println(s"the distinct dataset size is $list_length")
最终输出如下所示,数据集大小为25026,可知没有重复项。
the raw dataset size is 25026
the distinct dataset size is 25026
b.选择需要的数据字段
使用如下的命令保留我们需要的字段数据,剔除id、name、host_name、neighbourhood_group、last_review字段。
val filterDS:DataSet[FilterData] = distinctDS.map(x => new FilterData(x.host_id, x.neighbourhood, x.latitude, x.longitude,
x.room_type, x.price, x.minimum_nights, x.number_of_reviews,x.reviews_per_month, x.calculated_host_listings_count, x.availability_365))
println("++筛选后的数据++")
filterDS.first(3).print()
筛选后的输出如下所示,已经剔除了我们不需要的数据:
++筛选后的数据++
FilterData(34801943,朝阳区 / Chaoyang,39.9111,116.45947,Private room,268,1,4,0.06,10,356)
FilterData(46272517,海淀区,39.93275,116.30978,Private room,258,1,2,0.04,1,90)
FilterData(34801943,朝阳区 / Chaoyang,39.91479,116.48896,Private room,288,1,5,0.09,10,173)
c. 缺失值补充,数据格式统一
根据先前的观察可知,数据存在两个问题:
- 一是区域名称不统一,有的包含英文比如朝阳区 / Chaoyang,有的不包含英文如朝阳区,但是他们的含义是一致的,我们需要对这些数据统一形式。
-
二是存在一些民宿没有评论数量,评论数与每月平均评论都为空,为了方便后面统计分析,我们需要把这些数据替换为0.
因此,我们使用如下命令对数据格式进行统一和转换:
val unifiedDS:DataSet[RentData] = filterDS.map(x => new RentData(x.host_id.toInt, x.neighbourhood.split(" / ")(0),
x.latitude.toDouble, x.longitude.toDouble, x.room_type, x.price.toInt, x.minimum_nights.toInt,
if(x.number_of_reviews.isEmpty()){0}else{x.number_of_reviews.toInt}, if(x.reviews_per_month.isEmpty()){0}else{x.reviews_per_month.toDouble},
x.calculated_host_listings_count.toInt, x.availability_365.toInt))
println("++格式转换后的数据++")
unifiedDS.first(3).print()
输出结果如下所示,可见数据形式已经统一:
++格式转换后的数据++
RentData(52648252,朝阳区,39.89688,116.46998,Entire home/apt,426,1,2,0.03,1,0)
RentData(54311665,昌平区,40.15945,116.26421,Entire home/apt,101,6,7,0.11,1,357)
RentData(39354950,朝阳区,39.90663,116.44526,Private room,688,30,12,0.19,8,365)
d. 异常值过滤
我们需要过滤掉可租日期为1天以下、366天以上,房租价格为9以下、99999以上,最短租期为1天以下、366天以上的租房数据。
val unifiedDS:DataSet[RentData] = unifiedDS_0.filter(x => (x.price>9 && x.price<99999 && x.availability_365>0&& x.availability_365<367&& x.minimum_nights>0&& x.minimum_nights<367))
println("++剔除异常值后的数据集大小++")
println(unifiedDS.count())
过滤后剩余的数据项为23676,共过滤掉1350项房租数据。
(2)全局统计
- 价格分布
将价格划分为0~150,150~300,300~450,450~600,600~1000,1000以上,分别统计各个价格段的出租房数量:
val total_price:DataSet[(String, Int)] = unifiedDS.map(x => (if(x.price<=150){"0~150"}else if(x.price>150 && x.price<=300){"150~300"}
else if(x.price>300 && x.price<=450){"300~450"}else if(x.price>450 && x.price<=600){"450~600"}
else if(x.price>600 && x.price<=1000){"600~1000"}else{"1000+"}, 1)).groupBy(0).aggregate(Aggregations.SUM, 1)
println("++价格分布++")
total_price.print()
++价格分布++
(150~300,5916)
(300~450,4926)
(600~1000,3083)
(0~150,1773)
(450~600,3434)
(1000+,4544)
- 位置分布
位置分布可以分别按经纬度和行政区域进行统计分析- 经纬度输出
// 统计全局经纬度分布
val total_coord:DataSet[(Double, Double)] = unifiedDS.map(x => (x.latitude, x.longitude))
println("++经纬度坐标分布++")
total_coord.first(3).print() // 统计全局经纬度分布
val total_coord:DataSet[(Double, Double)] = unifiedDS.map(x => (x.latitude, x.longitude))
println("++经纬度坐标分布++")
total_coord.first(3).print()
示例输出如下所示:
> ++经纬度坐标分布++
> (39.90592,116.4691)
> (40.58139,116.32172)
> (39.84024,116.44451)
- 行政区域统计
// 统计全局行政区域分布
val total_region:DataSet[(String, Int)] = unifiedDS.map(x => (x.neighbourhood, 1)).groupBy(0).aggregate(Aggregations.SUM, 1)
println("++行政区域分布++")
total_region.print()
示例输出如下所示:
> ++行政区域分布++
> (密云县,1831)
> (延庆县,2021)
> (怀柔区,1684)
> (石景山区,310)
> (通州区,1353)
> (顺义区,1143)
> (丰台区,1637)
> (房山区,901)
> (东城区,451)
> (昌平区,1253)
> (海淀区,1844)
> (平谷区,238)
> (朝阳区,7356)
> (门头沟区,288)
> (大兴区,990)
> (西城区,380)
- 房型分布:按房型进行统计分析
// 按房型统计分布
val total_type:DataSet[(String, Int)] = unifiedDS.map(x => (x.room_type, 1)).groupBy(0).aggregate(Aggregations.SUM, 1).sortPartition(1, Order.DESCENDING)
println("++房型分布++")
total_type.print()
示例输出如下所示:
++房型分布++
(Private room,8146)
(Entire home/apt,14568)
(Shared room,962)
- 租期类型
- 可租时间分布
// 统计全局可租时间分布
val total_availability:DataSet[(Int, Int)] = unifiedDS.map(x => (x.availability_365, 1)).groupBy(0).sum(1).sortPartition(1, Order.DESCENDING)
println("++可租时间分布++")
total_availability.first(7).print()
示例输出如下所示:
> (364,2075)
> (180,994)
> (1,268)
> (355,250)
> (328,72)
> (346,60)
> (171,52)
- 最短租期分布
// 统计全局最短租期分布
val total_min_nights:DataSet[(Int, Int)] = unifiedDS.map(x => (x.minimum_nights, 1)).groupBy(0).sum(1).sortPartition(1, Order.DESCENDING)
println("++最短租期分布++")
total_min_nights.first(7).print()
示例输出如下所示:
> ++最短租期分布++
> (1,20542)
> (5,196)
> (15,134)
> (180,22)
> (25,4)
> (11,3)
> (21,3)
(3)分组统计
按行政区域进行分组统计,统计每个区域的房价平均值、最大值、最小值。
// 按行政区域,分组统计房价的平均值、最大值、最小值
val region_price_0:DataSet[(String, Int, Int, Int, Int)] = unifiedDS.map(x => (x.neighbourhood, x.price, x.price, x.price, 1)).groupBy(0).aggregate(Aggregations.MAX, 1).and(Aggregations.MIN, 2).and(Aggregations.SUM, 3).and(Aggregations.SUM, 4)
val region_price:DataSet[(String, Int, Int, Int)] = region_price_0.map(x => (x._1, x._2, x._3, (x._4.toDouble / x._5).toInt)).sortPartition(3, Order.DESCENDING)
println("++按行政区域分组统计房价++")
region_price.print()
示例输出如下所示:
++按行政区域分组统计房价++
(怀柔区,23744,93,1910)
(延庆县,29249,84,1734)
(密云县,70000,65,1185)
(石景山区,9999,75,577)
(顺义区,60000,75,873)
(通州区,33658,59,553)
(房山区,15000,66,940)
(丰台区,65466,52,664)
(昌平区,66666,66,1292)
(东城区,14486,48,791)
(海淀区,68980,65,625)
(平谷区,15000,70,1871)
(门头沟区,18174,76,1369)
(朝阳区,69000,53,684)
(大兴区,30000,64,620)
(西城区,26534,128,850)
4. 输出结果
使用如下命令将七个统计分析得到的结果保存到csv文件中。
// --------数据输出--------
total_price.writeAsCsv("src/main/resources/total_price.csv", "\n", ",")
total_region.writeAsCsv("src/main/resources/total_region.csv", "\n", ",")
total_coord.writeAsCsv("src/main/resources/total_coord.csv", "\n", ",")
total_min_nights.writeAsCsv("src/main/resources/total_min_nights.csv", "\n", ",")
total_availability.writeAsCsv("src/main/resources/total_availability.csv", "\n", ",")
total_type.writeAsCsv("src/main/resources/total_type.csv", "\n", ",")
region_price.writeAsCsv("src/main/resources/region_price.csv", "\n", ",")
env.execute()
刚开始执行时出现以下错误,数据不是输出到同一个csv文件下,而是输出到了一个目录下,如下图所示:

经参考网络博客Flink--数据输出Data Sinks,发现不论是本地还是hdfs。若Parallelism>1将把path当成目录名称,若Parallelism=1将把path当成文件名。
因此将原来的输出函数修改为如下所示,文件得到了正确保存。
// --------数据输出--------
total_price.setParallelism(1).writeAsCsv("src/main/resources/total_price.csv", "\n", ",", WriteMode.OVERWRITE)
total_region.setParallelism(1).writeAsCsv("src/main/resources/total_region.csv", "\n", ",", WriteMode.OVERWRITE)
total_coord.setParallelism(1).writeAsCsv("src/main/resources/total_coord.csv", "\n", ",", WriteMode.OVERWRITE)
total_min_nights.setParallelism(1).writeAsCsv("src/main/resources/total_min_nights.csv", "\n", ",", WriteMode.OVERWRITE)
total_availability.setParallelism(1).writeAsCsv("src/main/resources/total_availability.csv", "\n", ",", WriteMode.OVERWRITE)
total_type.setParallelism(1).writeAsCsv("src/main/resources/total_type.csv", "\n", ",", WriteMode.OVERWRITE)
region_price.setParallelism(1).writeAsCsv("src/main/resources/region_price.csv", "\n", ",", WriteMode.OVERWRITE)
env.execute()
5. 结果可视化
注:本文的结果可视化均使用ECharts进行绘制。
(1)价格分布
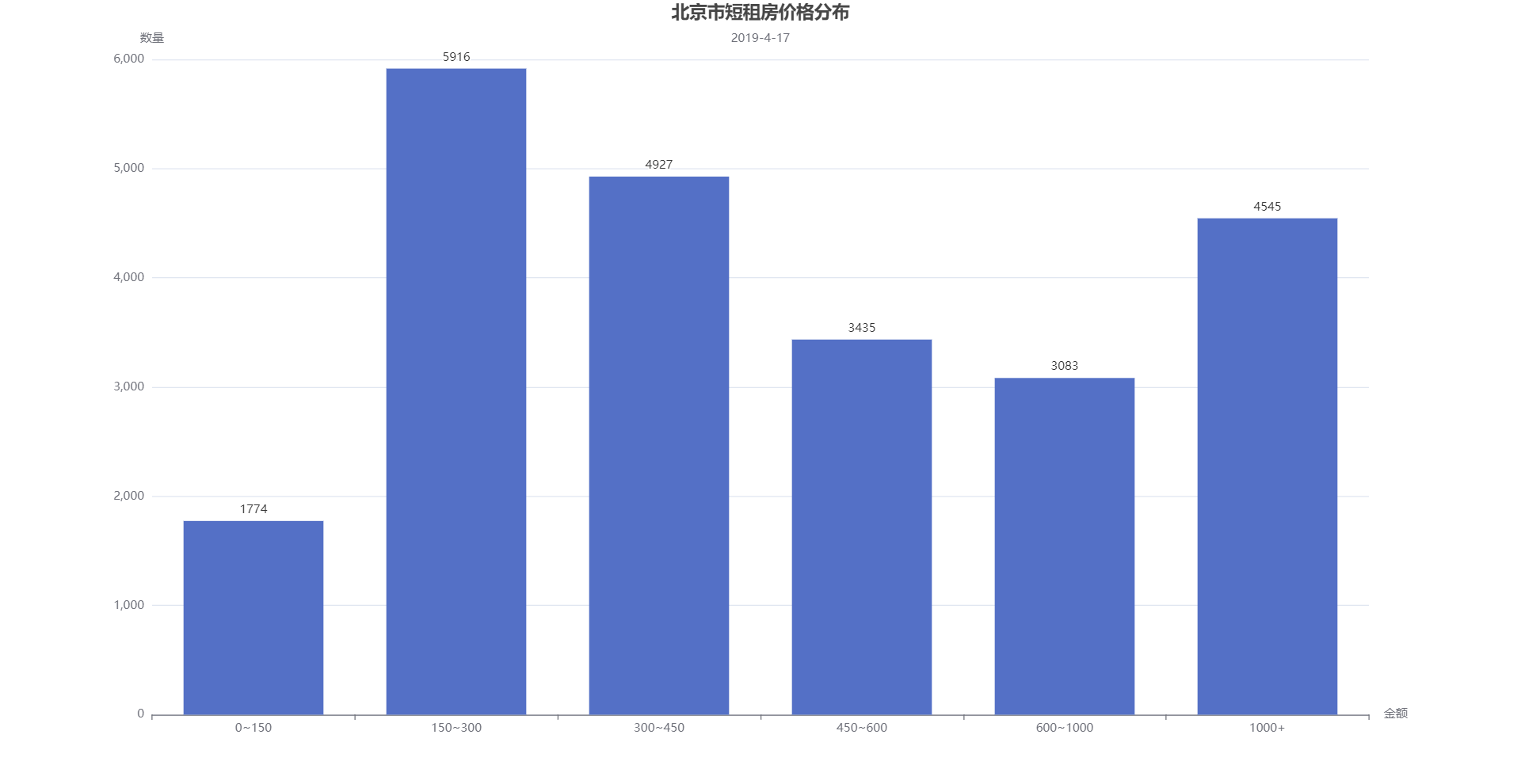
北京市短租房各个价位的房源数量如下图所示,可见房租150以下的房源较少,主要房源都位于150~450的区间。
(2)各区域租房数量分布

(3)地理位置分布
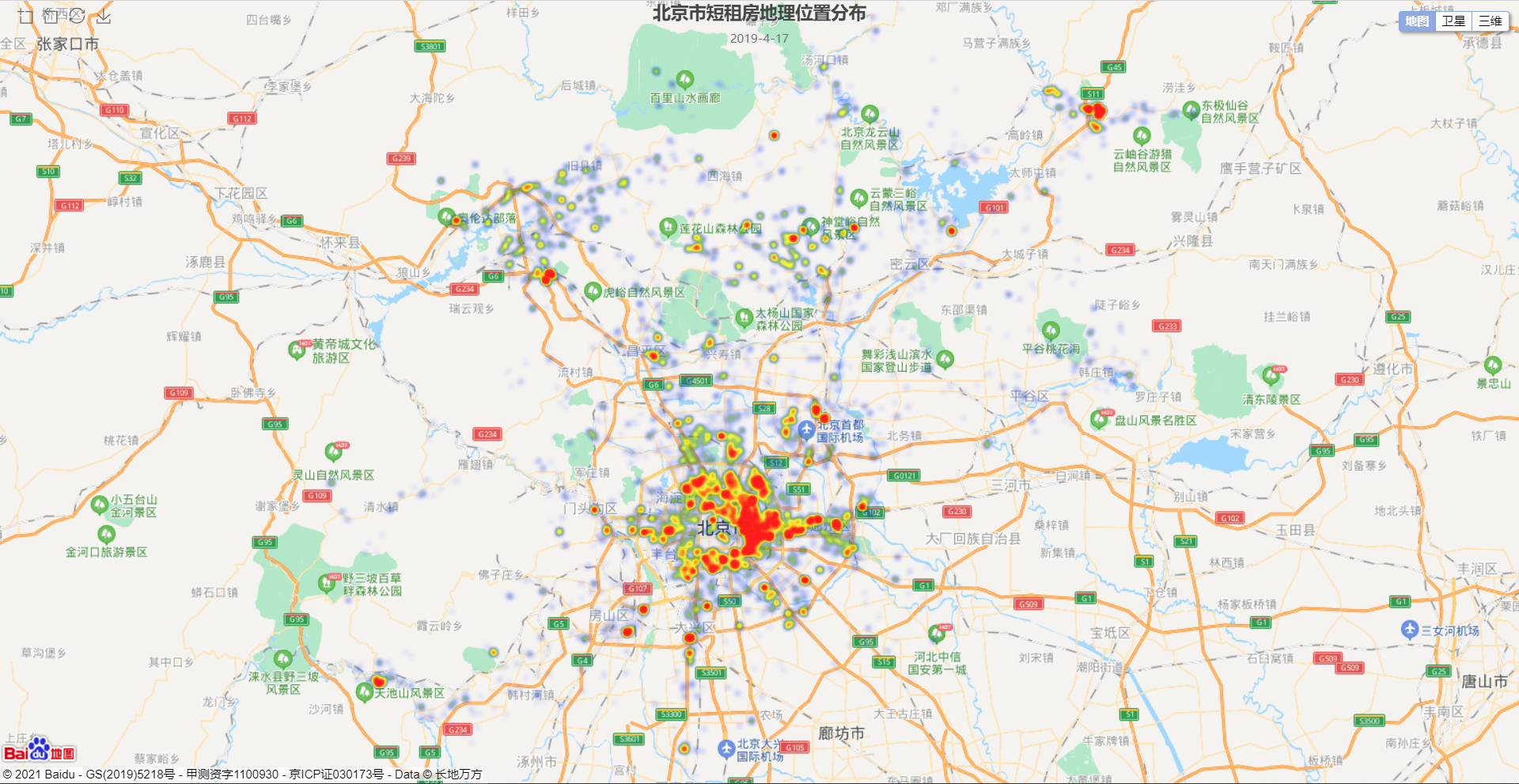
如图所示,大部分房源都位于朝阳区,与上面各区域租房数量相对应。
(4)最短租期分布
如下图所示:绝大部分短租房都支持最短租期为1天。

(5)可租时间分布
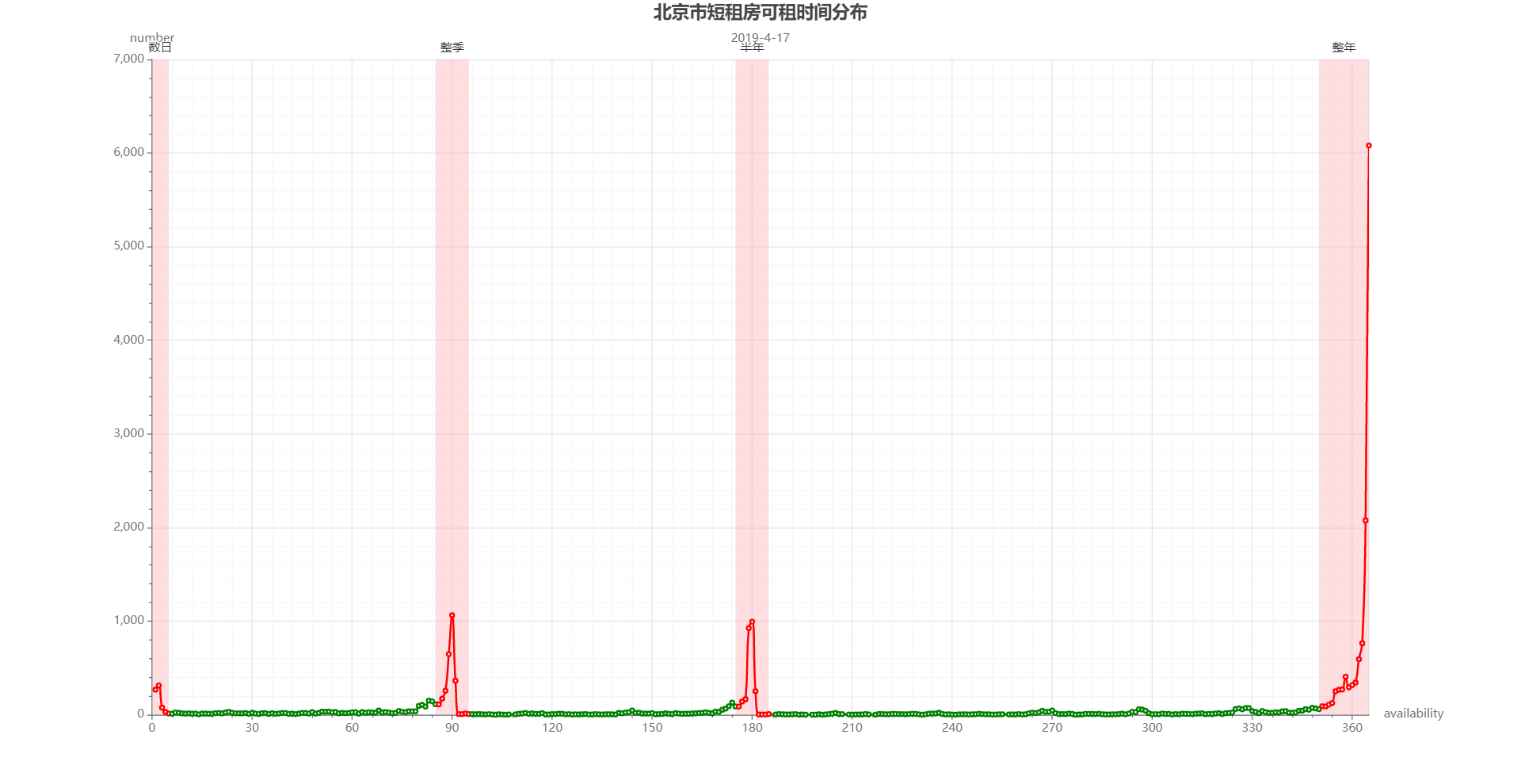
如下图所示,短租房的可租时间大部分分布在数日、整季、半年、整年,其中绝大部分都是整年可租。
(6)房屋类型分布
如下图所示,短租房的房屋类型大部分为整栋房子或者独立房间,很少是共享房间。

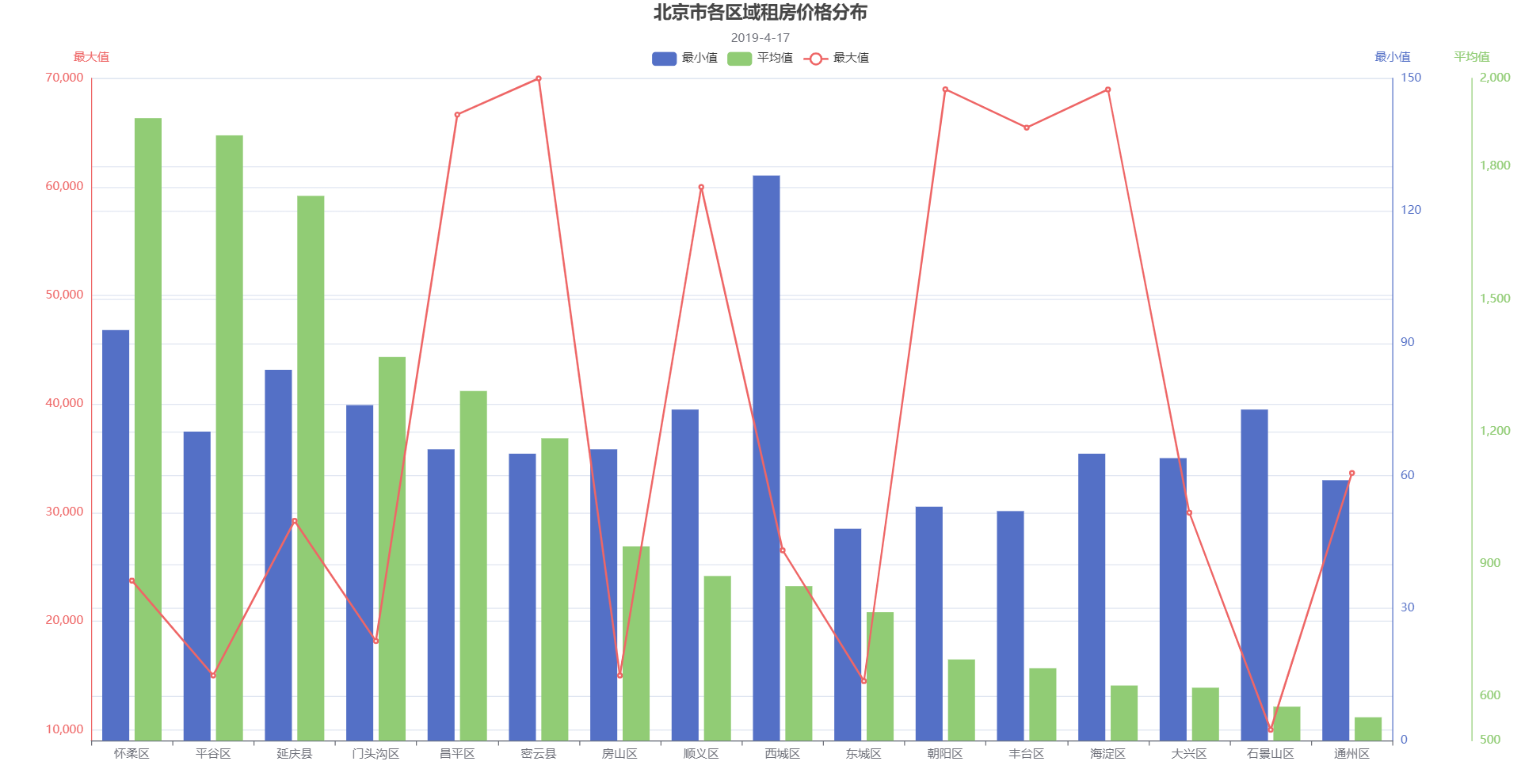
(7)各区域房价分布
如下图所示:
- 各城区的最高租房价格都非常高昂,在8000~70000之间,大大拉高了各区域的房租平均价格。
- 各城区租房价格的平均值大概位于500~2000之间,东城区的平均房价最低。
- 各城区租房价格的最低价格都位于0~150之间,这说明各个城区都能找到价格较为低廉的短租房。
五、附录
1. 代码
package cn.edu.xmu
import org.apache.flink.api.java.aggregation.Aggregations
import org.apache.flink.api.common.operators.Order
import org.apache.flink.api.scala._
import org.apache.flink.api.scala.DataSet
import org.apache.flink.core.fs.FileSystem.WriteMode
case class RentData(host_id:Int, neighbourhood:String, latitude:Double, longitude:Double, room_type:String, price:Int,
minimum_nights:Int, number_of_reviews:Int, reviews_per_month:Double, calculated_host_listings_count:Int, availability_365:Int)
case class RawData(id:String, name:String, host_id:String, host_name:String, neighbourhood_group:String,
neighbourhood:String, latitude:String, longitude:String, room_type:String, price:String,
minimum_nights:String, number_of_reviews:String, last_review:String, reviews_per_month:String,
calculated_host_listings_count:String, availability_365:String)
case class FilterData(host_id:String, neighbourhood:String, latitude:String, longitude:String, room_type:String,
price:String, minimum_nights:String, number_of_reviews:String, reviews_per_month:String,
calculated_host_listings_count:String, availability_365:String)
object RentAnalysis {
def main(args: Array[String]):Unit={
// --------数据读入--------
val env = ExecutionEnvironment.getExecutionEnvironment
val filePath = "src/main/resources/listings-preprocess.csv"
val rawList = env.readCsvFile[RawData](filePath, ignoreFirstLine=true)
var list_length = rawList.count()
println(s"the raw dataset size is $list_length ")
// rawList.print()
// --------数据清洗--------
// 去重
val distinctDS = rawList.distinct()
list_length = distinctDS.count()
println(s"the distinct dataset size is $list_length")
// 字段筛选
val filterDS:DataSet[FilterData] = distinctDS.map(x => new FilterData(x.host_id, x.neighbourhood, x.latitude, x.longitude,
x.room_type, x.price, x.minimum_nights, x.number_of_reviews,x.reviews_per_month, x.calculated_host_listings_count, x.availability_365))
println("++筛选后的数据++")
filterDS.first(3).print()
// 数据统一
val unifiedDS_0:DataSet[RentData] = filterDS.map(x => new RentData(x.host_id.toInt, x.neighbourhood.split(" / ")(0),
x.latitude.toDouble, x.longitude.toDouble, x.room_type, x.price.toInt, x.minimum_nights.toInt,
if(x.number_of_reviews.isEmpty()){0}else{x.number_of_reviews.toInt}, if(x.reviews_per_month.isEmpty()){0}else{x.reviews_per_month.toDouble},
x.calculated_host_listings_count.toInt, x.availability_365.toInt))
println("++格式转换后的数据++")
unifiedDS_0.first(3).print()
// 异常值处理
val unifiedDS:DataSet[RentData] = unifiedDS_0.filter(x => (x.price>0 && x.price<99999 && x.availability_365>0))
println("++剔除异常值后的数据集大小++")
println(unifiedDS.count())
// --------数据统计--------
// 统计全局价格分布
val total_price:DataSet[(String, Int)] = unifiedDS.map(x => (if(x.price<=150){"0~150"}else if(x.price>150 && x.price<=300){"150~300"}
else if(x.price>300 && x.price<=450){"300~450"}else if(x.price>450 && x.price<=600){"450~600"}
else if(x.price>600 && x.price<=1000){"600~1000"}else{"1000+"}, 1)).groupBy(0).aggregate(Aggregations.SUM, 1)
println("++价格分布++")
total_price.print()
// 统计全局行政区域分布
val total_region:DataSet[(String, Int)] = unifiedDS.map(x => (x.neighbourhood, 1)).groupBy(0).aggregate(Aggregations.SUM, 1)
println("++行政区域分布++")
total_region.print()
// 统计全局经纬度分布
val total_coord:DataSet[(Double, Double)] = unifiedDS.map(x => (x.latitude, x.longitude))
println("++经纬度坐标分布++")
total_coord.first(3).print()
// 统计全局最短租期分布
val total_min_nights:DataSet[(Int, Int)] = unifiedDS.map(x => (x.minimum_nights, 1)).groupBy(0).sum(1).sortPartition(1, Order.DESCENDING)
println("++最短租期分布++")
total_min_nights.first(7).print()
// 统计全局可租时间分布
val total_availability:DataSet[(Int, Int)] = unifiedDS.map(x => (x.availability_365, 1)).groupBy(0).sum(1).sortPartition(1, Order.DESCENDING)
println("++可租时间分布++")
total_availability.first(7).print()
// 按房型统计分布
val total_type:DataSet[(String, Int)] = unifiedDS.map(x => (x.room_type, 1)).groupBy(0).aggregate(Aggregations.SUM, 1).sortPartition(1, Order.DESCENDING)
println("++房型分布++")
total_type.print()
// 按行政区域,分组统计房价的平均值、最大值、最小值
val region_price_0:DataSet[(String, Int, Int, Int, Int)] = unifiedDS.map(x => (x.neighbourhood, x.price, x.price, x.price, 1)).groupBy(0)
.aggregate(Aggregations.MAX, 1).and(Aggregations.MIN, 2).and(Aggregations.SUM, 3).and(Aggregations.SUM, 4)
val region_price:DataSet[(String, Int, Int, Double)] = region_price_0.map(x => (x._1, x._2, x._3, x._4.toDouble / x._5)).sortPartition(3, Order.DESCENDING)
println("++按行政区域分组统计房价++")
region_price.print()
// --------数据输出--------
total_price.setParallelism(1).writeAsCsv("src/main/resources/total_price.csv", "\n", ",", WriteMode.OVERWRITE)
total_region.setParallelism(1).writeAsCsv("src/main/resources/total_region.csv", "\n", ",", WriteMode.OVERWRITE)
total_coord.setParallelism(1).writeAsCsv("src/main/resources/total_coord.csv", "\n", ",", WriteMode.OVERWRITE)
total_min_nights.setParallelism(1).writeAsCsv("src/main/resources/total_min_nights.csv", "\n", ",", WriteMode.OVERWRITE)
total_availability.setParallelism(1).writeAsCsv("src/main/resources/total_availability.csv", "\n", ",", WriteMode.OVERWRITE)
total_type.setParallelism(1).writeAsCsv("src/main/resources/total_type.csv", "\n", ",", WriteMode.OVERWRITE)
region_price.setParallelism(1).writeAsCsv("src/main/resources/region_price.csv", "\n", ",", WriteMode.OVERWRITE)
env.execute()
}
}
2. 参考资料
- Windows下安装scala:https://blog.csdn.net/hr786250678/article/details/86229959
- scala在Windows下的安装以及idea插件的配置:https://blog.csdn.net/Shemon_zjw/article/details/107049107
- IntelliJ IDEA上搭建Flink开发环境——Scala版:https://blog.csdn.net/x976269167/article/details/105791470
- Flink之Dataset输出:https://blog.csdn.net/weixin_45366499/article/details/114582061
- Flink数据输出:https://www.cnblogs.com/niutao/p/10548466.html
- 爱彼迎租房数据集:http://insideairbnb.com/get-the-data.html
- 爱彼迎短租房源数据分析:https://blog.csdn.net/u013788252/article/details/105413259
- 阿里天池:Airbnb短租房数据集分析:https://blog.csdn.net/lam_yx/article/details/107741800
- ECharts配置项手册:https://echarts.apache.org/zh/option.html
- ECharts示例:https://echarts.apache.org/examples/zh/index.html