
查看前一步骤操作步骤二:数据处理和Python操作Kafka
查看python版本python版本:Structured Streaming实时处理数据
《Spark+Kafka构建实时分析Dashboard案例——步骤三:Structured Streaming实时处理数据》
开发团队:厦门大学数据库实验室 联系人:林子雨老师ziyulin@xmu.edu.cn
版权声明:版权归厦门大学数据库实验室所有,请勿用于商业用途;未经授权,其他网站请勿转载
本教程介绍大数据课程实验案例“Spark+Kafka构建实时分析Dashboard”的第三个步骤,Structured Streaming实时处理数据。在本篇博客中,将介绍如何利用Structed Streaming实时接收处理Kafka数据以及将处理后的结果发给的Kafka。
所需知识储备
会使用Scala编写Structured Streaming程序,Kafka原理。
训练技能
编写Structured Streaming程序,熟悉Spark操作Kafka。
任务清单
- Structured Streaming实时处理Kafka数据;
- 将处理后的结果发送给Kafka;
编程思想
本案例在于实时统计每秒中男女生购物人数,而Structured Streaming接收的数据为1,1,0,2...,其中0代表女性,1代表男性,所以对于2或者null值,则不考虑。其实通过分析,可以发现这个就是典型的wordcount问题,而且是基于Spark流计算。女生的数量,即为0的个数,男生的数量,即为1的个数。
因此利用Structured Streaming的groupBy接口,设置窗口大小为1秒,滑动步长为1秒,这样统计出的0和1的个数即为每秒男生女生的人数。
编程实现
配置Spark开发Kafka环境
kafka的安装可以参考Kafka的安装和简单实例测试。下面主要介绍配置Spark开发Kafka环境。首先点击下载,下载Spark连接Kafka的代码库。然后把下载的代码库放到目录/usr/local/spark/jars目录下,命令如下:
sudo mv ~/下载/spark-streaming_2.12-3.2.0.jar /usr/local/spark/jars
sudo mv ~/下载/spark-streaming-kafka-0-10_2.12-3.2.0.jar /usr/local/spark/jars
然后在/usr/local/spark/jars目录下新建kafka目录,把/usr/local/kafka/libs下所有函数库复制到/usr/local/spark/jars/kafka目录下,命令如下
cd /usr/local/spark/jars
mkdir kafka
cd kafka
cp /usr/local/kafka/libs/* .
执行上述步骤之后,Spark开发Kafka环境即已配置好,下面介绍如何编码实现。
建立Spark项目
之前有很多教程都有说明如何创建Spark项目,这里再次说明。首先在/usr/local/spark/mycode新建项目主目录
cd /usr/local/spark/mycode
mkdir kafka
然后在kafka目录下新建scala文件存放目录以及scala工程文件
cd kafka
mkdir -p src/main/scala
接着在src/main/scala文件下创建两个文件,一个是用于设置日志,一个是项目工程主文件,设置日志文件为StreamingExamples.scala
package org.apache.spark.examples.streaming
import org.apache.spark.internal.Logging
import org.apache.log4j.{Level, Logger}
/** Utility functions for Spark Streaming examples. */
object StreamingExamples extends Logging {
/** Set reasonable logging levels for streaming if the user has not configured log4j. */
def setStreamingLogLevels() {
val log4jInitialized = Logger.getRootLogger.getAllAppenders.hasMoreElements
if (!log4jInitialized) {
// We first log something to initialize Spark's default logging, then we override the
// logging level.
logInfo("Setting log level to [WARN] for streaming example." +
" To override add a custom log4j.properties to the classpath.")
Logger.getRootLogger.setLevel(Level.WARN)
}
}
}
这个文件不做过多解释,因为这只是一个辅助文件,下面着重介绍工程主文件,文件名为KafkaTest.scala
package org.apache.spark.examples.streaming
import java.util.HashMap
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.json4s._
import org.json4s.jackson.Serialization
import org.json4s.jackson.Serialization.write
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.Interval
//import org.apache.spark.streaming.kafka._
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import java.sql.Timestamp
import org.apache.spark.sql.streaming.OutputMode
import org.apache.spark.sql.{Row, ForeachWriter, DataFrame, Dataset, SparkSession}
import scala.util.parsing.json.{JSONArray, JSONObject}
object KafkaWordCount {
implicit val formats = DefaultFormats//数据格式化时需要
def processed(row: Row): String={
/*val m = row.getValuesMap(row.schema.fieldNames)
val jsonstring = JSONObject(m).toString()*/
//[{"1": "3"}]"
var jsonstring = "[{\""+row(0)+"\": \""+row(1)+"\"}]"
print(jsonstring)
val props = new HashMap[String, Object]()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092")
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
// 实例化一个Kafka生产者
val producer = new KafkaProducer[String, String](props)
// rdd.colect即将rdd中数据转化为数组,然后write函数将rdd内容转化为json格式
val str = jsonstring
// 封装成Kafka消息,topic为"result"
val message = new ProducerRecord[String, String]("result", null, str)
// 给Kafka发送消息
producer.send(message)
jsonstring
}
def main(args: Array[String]): Unit={
if (args.length < 4) {
System.err.println("Usage: KafkaWordCount <zkQuorum> <group> <topics> <numThreads>")
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
/* 输入的四个参数分别代表着
* 1. zkQuorum 为zookeeper地址
* 2. group为消费者所在的组
* 3. topics该消费者所消费的topics
* 4. numThreads开启消费topic线程的个数
*/
val Array(zkQuorum, group, topics, numThreads) = args
val spark = SparkSession
.builder()
.appName("KafkaWordCount").master("local[*]")
.getOrCreate()
// 创建连接Kafka的消费者链接
import spark.implicits._
val df = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers","localhost:9092")
.option("subscribe","sex")
.option("failOnDataLoss","false")
.load()
val dataSet : Dataset[(String,Timestamp)]=
df.selectExpr("CAST(value AS STRING)", "CAST(timestamp AS TIMESTAMP)")
.as[(String,Timestamp)]
val words =dataSet.toDF("value","timestamp")
import org.apache.spark.sql.functions._
//根据窗口、开始id分组
val windowsCount=words
.withWatermark("timestamp","1 seconds")
.groupBy(
window($"timestamp","1 seconds","1 seconds")
,$"value"
).count()
val ds = windowsCount
.selectExpr("CAST(value AS STRING)", "CAST(count AS STRING)")
.writeStream.foreach(
new ForeachWriter[Row] {
def open(partitionId: Long, version: Long): Boolean = {
true
}
def process(record: Row): Unit = {
processed(record)
}
def close(errorOrNull: Throwable): Unit = {
// Close the connection
}
}
).option("checkpointLocation", "check/")
.outputMode("append")
.start()
ds.awaitTermination()
}
}
上述代码注释已经也很清楚了,下面在简要说明下:
1. 首先按每秒的频率读取Kafka消息;
2. 然后对每秒的数据执行wordcount算法,统计出0的个数,1的个数,2的个数;
3. 最后将上述结果封装成json发送给Kafka。
另外,需要注意,上面代码中有一行如下代码:
.option("checkpointLocation", "check/")
这行代码表示把检查点文件写入分布式文件系统HDFS,所以一定要事先启动Hadoop。如果没有启动Hadoop,则后面运行时会出现“拒绝连接”的错误提示。如果你还没有启动Hadoop,则可以现在在Ubuntu终端中,使用如下Shell命令启动Hadoop:
cd /usr/local/hadoop #这是hadoop的安装目录
./sbin/start-dfs.sh
运行项目
编写好程序之后,下面介绍下如何打包运行程序。在/usr/local/spark/mycode/kafka目录下新建文件simple.sbt,输入如下内容:
name := "Simple Project"
version := "1.0"
scalaVersion := "2.12.15"
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.2.0" % "provided"
libraryDependencies += "org.apache.spark" % "spark-streaming_2.12" % "3.2.0" % "provided"
libraryDependencies += "org.apache.spark" % "spark-streaming-kafka-0-10_2.12" % "3.2.0" % "provided"
libraryDependencies += "org.json4s" %% "json4s-jackson" % "3.7.0-M5" % "provided"
libraryDependencies += "org.apache.spark" %% "spark-token-provider-kafka-0-10" % "3.2.0"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "3.2.0"
然后,即可编译打包程序,输入如下命令
/usr/local/sbt/sbt package
打包成功之后,接下来编写运行脚本,在/usr/local/spark/mycode/kafka目录下新建startup.sh文件,输入如下内容:
/usr/local/spark/bin/spark-submit --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.2.0 --driver-class-path /usr/local/spark/jars/*:/usr/local/spark/jars/kafka/* --class "org.apache.spark.examples.streaming.KafkaWordCount" /usr/local/spark/mycode/kafka/target/scala-2.12/simple-project_2.12-1.0.jar 127.0.0.1:2181 1 sex 1
其中最后四个为输入参数,含义如下
1. 127.0.0.1:2181为Zookeeper地址
2. 1 为consumer group标签
3. sex为消费者接收的topic
4. 1 为消费者线程数
最后在/usr/local/spark/mycode/kafka目录下,运行如下命令即可执行刚编写好的Structured Streaming程序
sh startup.sh
程序运行成功之后,下面通过之前的KafkaProducer和KafkaConsumer来检测程序。
测试程序
下面开启之前编写的KafkaProducer投递消息,然后将KafkaConsumer中接收的topic改为result,验证是否能接收topic为result的消息,更改之后的KafkaConsumer为
from kafka import KafkaConsumer
consumer = KafkaConsumer('result')
for msg in consumer:
print((msg.value).decode('utf8'))
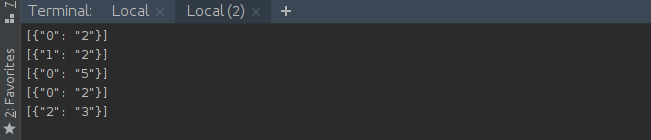
在同时开启Structured Streaming项目,KafkaProducer以及KafkaConsumer之后,可以在KafkaConsumer运行窗口看到如下输出:
到此为止,Structured Streaming程序编写完成,下篇文章将分析如何处理得到的最终结果。