
【版权声明:本指南为厦门大学林子雨编著的《大数据技术原理与应用》教材配套学习资料,版权所有,转载请注明出处,请勿用于商业用途】
本指南介绍Hadoop分布式文件系统HDFS,并详细指引读者对HDFS文件系统的操作实践。请务必仔细阅读完厦门大学林子雨编著的《大数据技术原理与应用》第3章节,再结合本指南进行学习。
Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)是Hadoop核心组件之一,如果已经安装了Hadoop,其中就已经包含了HDFS组件,不需要另外安装。
学习本指南需要在macOS系统安装好Hadoop.如果读者没有安装Hadoop,请返回macOS 安装Hadoop教程-单机-伪分布式配置,根据指南学习并安装。
第3章涉及到很多的理论知识点,主要的理论知识点包括:分布式文件系统、HDFS简介、HDFS的相关概念、HDFS体系结构、HDFS的存储原理、HDFS的数据读写过程。这些理论知识点,请自己依靠厦门大学林子雨编著的《大数据技术原理与应用》第3章节进行学习,本指南不再重复表述。
接下来介绍Linux操作系统中关于HDFS文件操作的常用Shell命令,利用Web界面查看和管理Hadoop文件系统,以及利用Hadoop提供的Java API进行基本的文件操作。
一、启动Hadoop
在学习HDFS编程实践前,我们需要启动Hadoop。执行如下命令
cd /usr/local/Cellar/hadoop/2.7.1/
./sbin/start-dfs.sh
注意笔者当然macOS系统的hadoop版本是2.7.1 ,读者的路径请自行切换到Homebrew安装的版本路径。
二、HDFS编程
(一)、利用Shell命令操作
Hadoop支持很多Shell命令,其中fs是HDFS最常用的命令,利用fs可以查看HDFS文件系统的目录结构、上传和下载数据、创建文件等。
注意: 教材《大数据技术原理与应用》的命令是以"./bin/hadoop dfs"开头的Shell命令方式,实际上有三种shell命令方式。
1. hadoop fs
2. hadoop dfs
3. hdfs dfs
hadoop fs适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
hadoop dfs只能适用于HDFS文件系统
hdfs dfs跟hadoop dfs的命令作用一样,也只能适用于HDFS文件系统
我们可以在终端输入如下命令,查看fs总共支持了哪些命令
hadoop fs

在终端输入如下命令,可以查看具体某个命令的作用
例如:我们查看put命令如何使用,可以输入如下命令
hadoop fs -help put

由于Hadoop支持的命令众多,想更多了解Hadoop命令,请参照《大数据技术原理与应用》3.7小节学习。
(二)、利用HDFS的Web界面管理
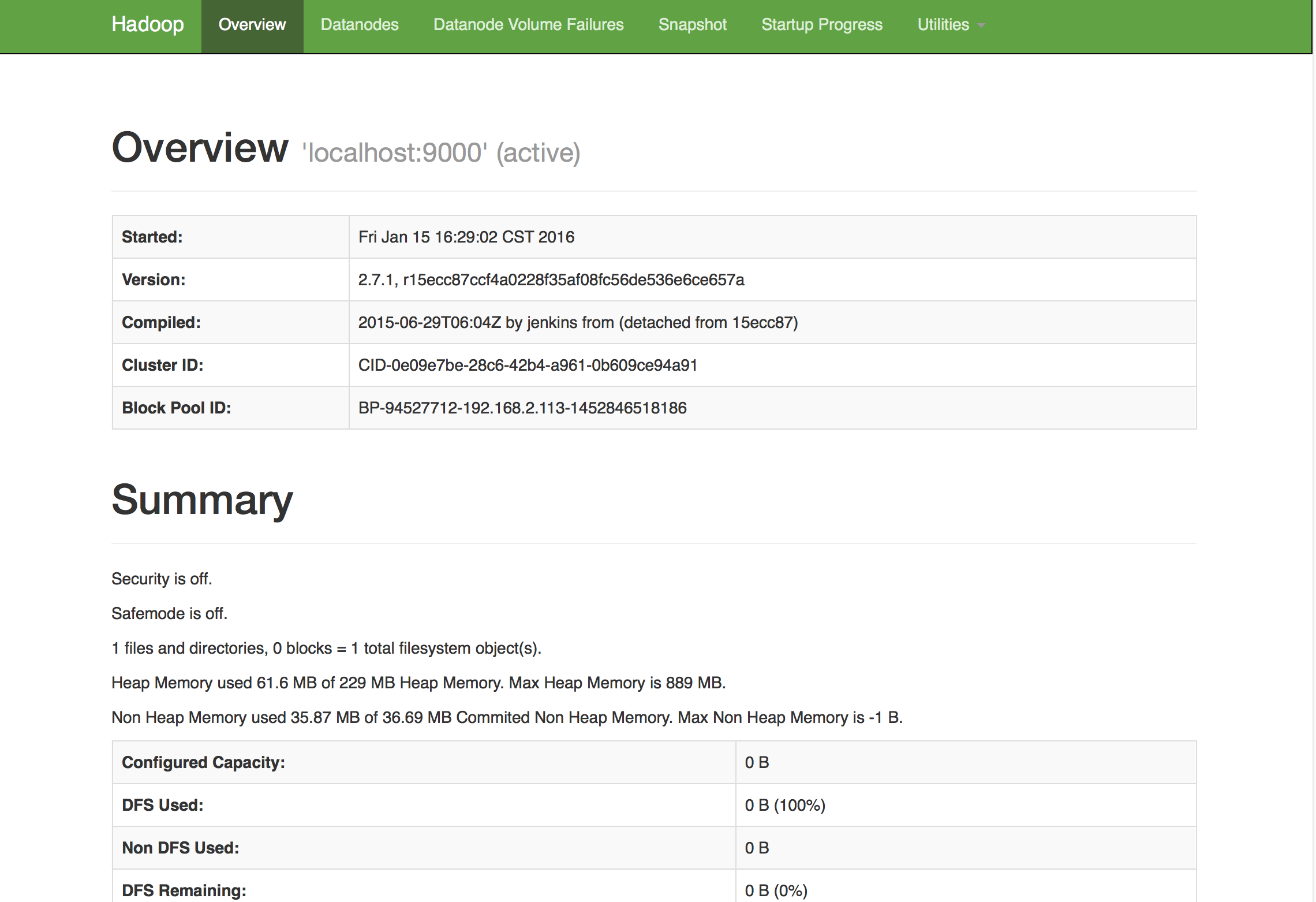
打开macOS自带的Safari浏览器或Chrome浏览器,点击此链接HDFS的Web界面,即可看到HDFS的web管理界面
(三)、利用Java API与HDFS进行交互
Hadoop不同的文件系统之间通过调用Java API进行交互,上面介绍的Shell命令,本质上就是Java API的应用。下面提供了Hadoop官方的Hadoop API文档,想要深入学习Hadoop,可以访问如下网站,查看各个API的功能。
利用Java API进行交互,需要利用软件Intellij IDEA编写Java程序。
在macOS系统中,推荐使用Intellij IDEA编写Java程序,请读者自行到官网下载Intellij IDEA: The Java IDE for Professional Developers by JetBrains
在Intellij IDEA创建一个Java项目,并加载所依赖的jar包。
如何获取Java API: API所在的jar包都在已经安装好的hadoop文件夹里,路径:/usr/local/Cellar/hadoop/2.7.1/libexec/share/hadoop(如果您安装的hadoop不在此目录,请找到jar包所在的文件夹)
加载上面路径common文件夹下:
lib所有的jar包和hadoop-common-2.7.1.jar
加载上面路径hdfs文件夹下:
lib所有的jar包和hadoop-hdfs-2.7.1.jar
- 实例:利用hadoop 的java api检测伪分布式文件系统HDFS上是否存在某个文件,写入文件,读取文件。
第一步:编写代码- 写入文件
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.Path; public class Chapter3 { public static void main(String[] args) { try { Configuration conf = new Configuration(); conf.set("fs.defaultFS","hdfs://localhost:9000"); conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem"); FileSystem fs = FileSystem.get(conf); byte[] buff = "Hello world".getBytes(); // 要写入的内容 String filename = "test"; //要写入的文件名 FSDataOutputStream os = fs.create(new Path(filename)); os.write(buff,0,buff.length); System.out.println("Create:"+ filename); os.close(); fs.close(); } catch (Exception e) { e.printStackTrace(); } } } - 判断文件是否存在
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; public class Chapter3 { public static void main(String[] args) { try { String filename = "test"; Configuration conf = new Configuration(); conf.set("fs.defaultFS","hdfs://localhost:9000"); conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem"); FileSystem fs = FileSystem.get(conf); if(fs.exists(new Path(filename))){ System.out.println("文件存在"); }else{ System.out.println("文件不存在"); } fs.close(); } catch (Exception e) { e.printStackTrace(); } } } - 读取文件
import java.io.BufferedReader; import java.io.InputStreamReader; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.fs.FSDataInputStream; public class Chapter3 { public static void main(String[] args) { try { Configuration conf = new Configuration(); conf.set("fs.defaultFS","hdfs://localhost:9000"); conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem"); FileSystem fs = FileSystem.get(conf); Path file = new Path("test"); FSDataInputStream getIt = fs.open(file); BufferedReader d = new BufferedReader(new InputStreamReader(getIt)); String content = d.readLine(); //读取文件一行 System.out.println(content); d.close(); //关闭文件 fs.close(); //关闭hdfs } catch (Exception e) { e.printStackTrace(); } } }第二步:编译部署
如果代码编写在Intellij IDEA里面,那么直接点击运行,即可看到运行结果。
如果还想Hadoop自带的实例那样运行jar包,以上述写入文件的代码为例,还需要做以下操作:
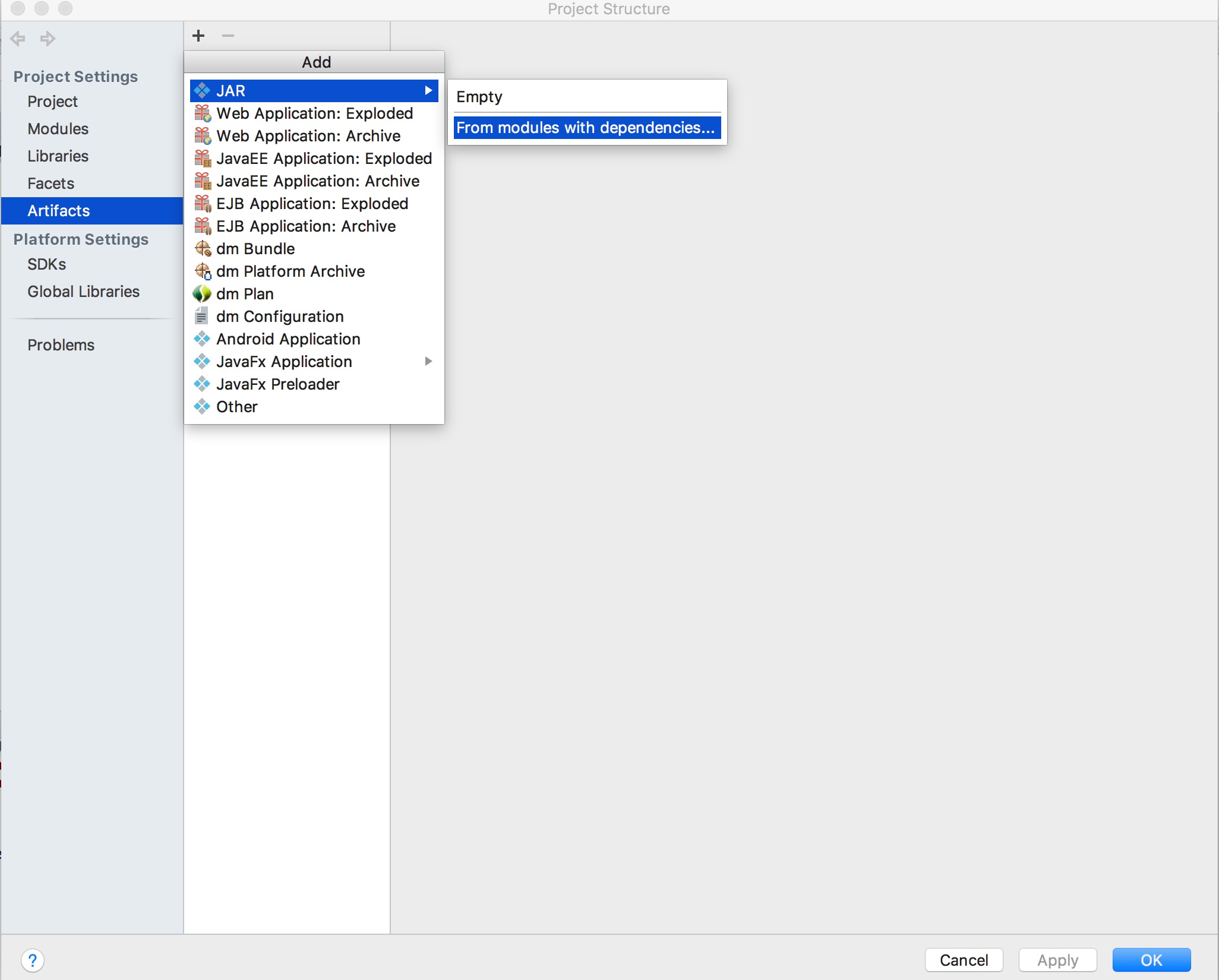
点击Intellij IDEA顶部菜单选项"File",选择"Project Structure",选择左侧菜单“Artifacts”
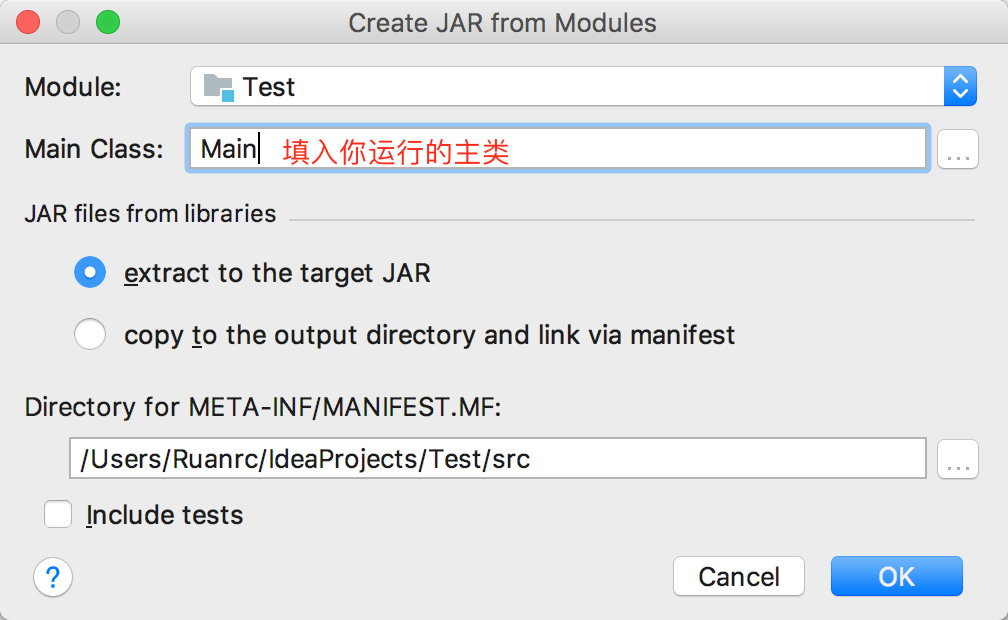
然后填入所要运行的主类
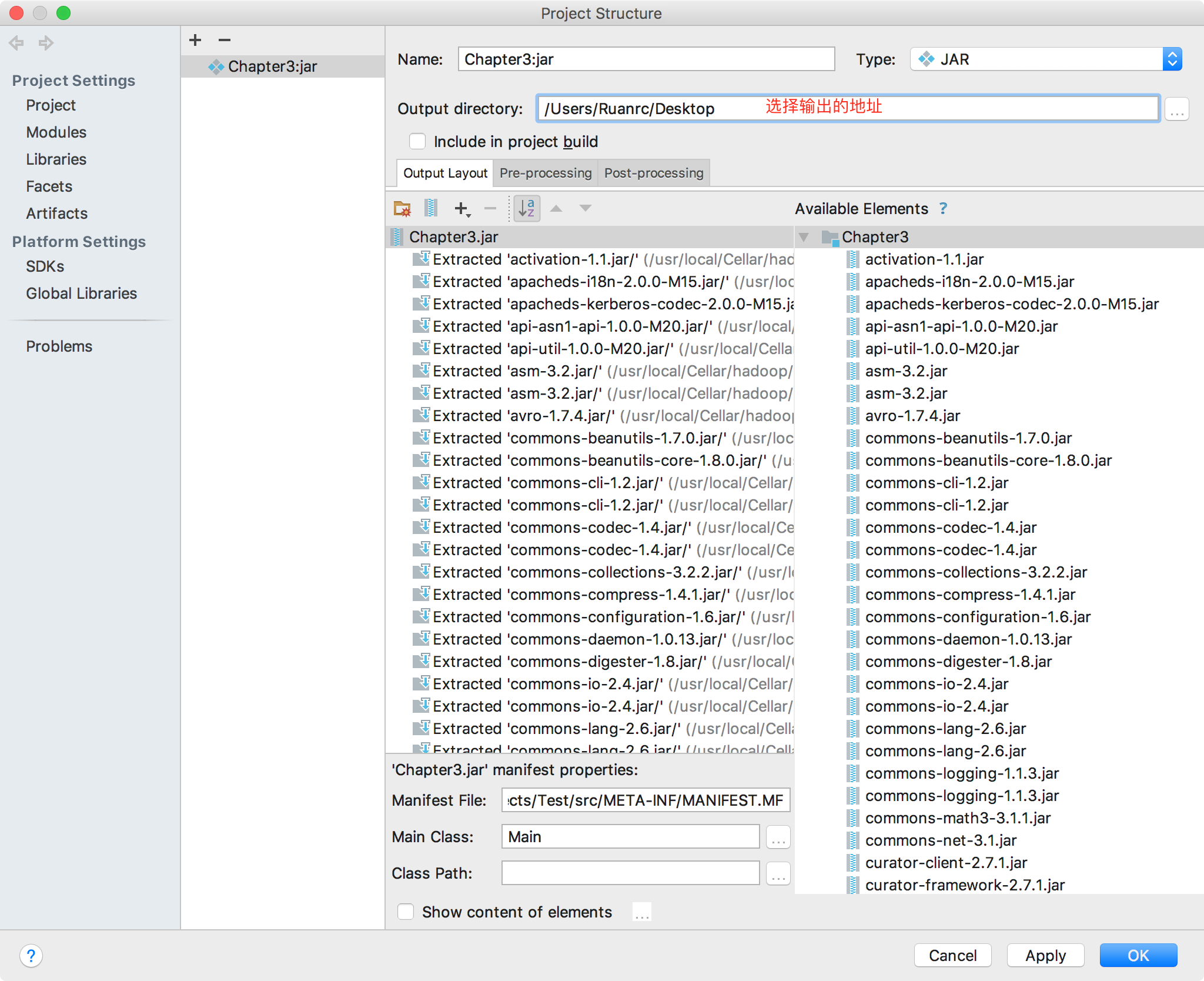
选择输出的jar包地址,点击OK按钮即可。
点击Intellij IDEA顶部菜单选项"Build",选择"Build Artifacts"
在终端输入命令:cd ~/Desktop java -jar ./Test.jar
- 写入文件