
返回本案例首页
《Spark+Kafka构建实时分析Dashboard案例介绍》
开发团队:厦门大学数据库实验室 联系人:林子雨老师ziyulin@xmu.edu.cn
版权声明:版权归厦门大学数据库实验室所有,请勿用于商业用途;未经授权,其他网站请勿转载
本教程介绍大数据课程实验案例“Spark+Kafka构建实时分析Dashboard”。在本篇博客中,将要介绍本案例的总体架构,包括案例整体的运行流程以及每个过程具体执行内容。
案例概述
本案例利用Spark+Kafka实时分析男女生每秒购物人数,利用Spark Streaming实时处理用户购物日志,然后利用websocket将数据实时推送给浏览器,最后浏览器将接收到的数据实时展现,案例的整体框架图如下:
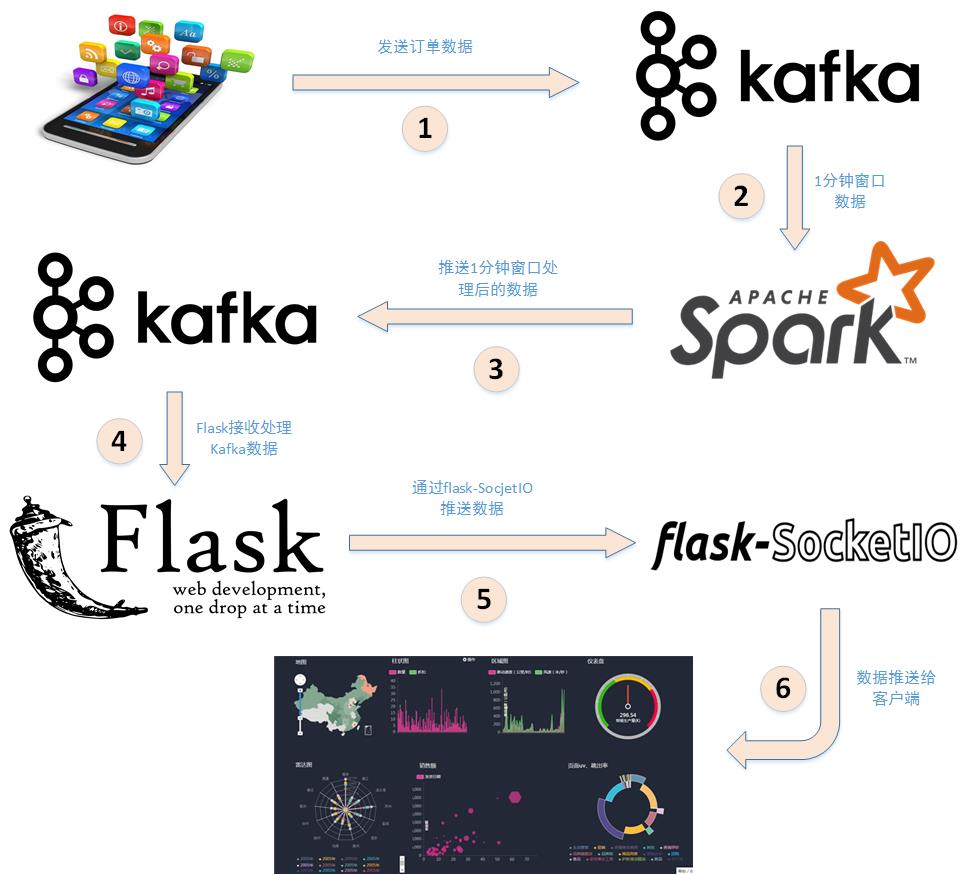
下面分析详细分析下上述步骤:
1. 应用程序将购物日志发送给Kafka,topic为"sex",因为这里只是统计购物男女生人数,所以只需要发送购物日志中性别属性即可。这里采用模拟的方式发送购物日志,即读取购物日志数据,每间隔相同的时间发送给Kafka。
2. 接着利用Spark Streaming从Kafka主题"sex"读取并处理消息。这里按滑动窗口的大小按顺序读取数据,例如可以按每5秒作为窗口大小读取一次数据,然后再处理数据。
3. Spark将处理后的数据发送给Kafka,topic为"result"。
4. 然后利用Flask搭建一个web应用程序,接收Kafka主题为"result"的消息。
5. 利用Flask-SocketIO将数据实时推送给客户端。
6. 客户端浏览器利用js框架socketio实时接收数据,然后利用js可视化库hightlights.js库动态展示。
至此,本案例的整体架构已介绍完毕,下篇文章将开始介绍具体操作细节。