
【版权声明】博客内容由厦门大学数据库实验室拥有版权,未经允许,请勿转载!
[返回Spark教程首页]
Structured Streaming是Spark2.0新增的可扩展和高容错性的实时计算框架,它构建于Spark SQL引擎,当实时数据持续到达时,Spark SQL引擎会不断的计算和更新处理结果。类似于静态结构化数据的批处理,Structured Streaming可以用同样的方式进行流计算。因此,Structured Streaming非常适合处理结构化的实时数据。
之前在学习Spark Streaming章节的内容时,我们知道,Spark Streaming采用的数据抽象是DStream,而本质上就是RDD,对数据流的操作就是针对RDD的操作。而在Spark 2.0以后,Spark设计了新的组件Structured Streaming,它把流式计算也统一到DataFrame里去了。如果Structured Streaming 仅仅是换个API,或者能够支持DataFrame操作,那么它并没有突出之处,因为在Spark2.0之前通过某些封装也能够很好地支持DataFrame的操作。那么 Structured Streaming 的意义在哪里呢?第一,重新抽象了流式计算;第二,易于实现数据的exactly-once。2.0之前的Spark Streaming只能做到at-least once,框架层次很难帮你做到exactly-once。 现在通过重新设计流式计算框架,使得实现exactly-once 变得容易了。
Structured Streaming编程模型
Structured Streaming最核心的思想就是将实时到达的数据看作是一个不断追加的"unbound table",如下图所示,因此这就产生了一种新的类似于批处理的流计算模型。和表格的标准批量查询一样,用户可以用同样的方法进行流计算,即对到来的每一行数据进行实时查询处理;
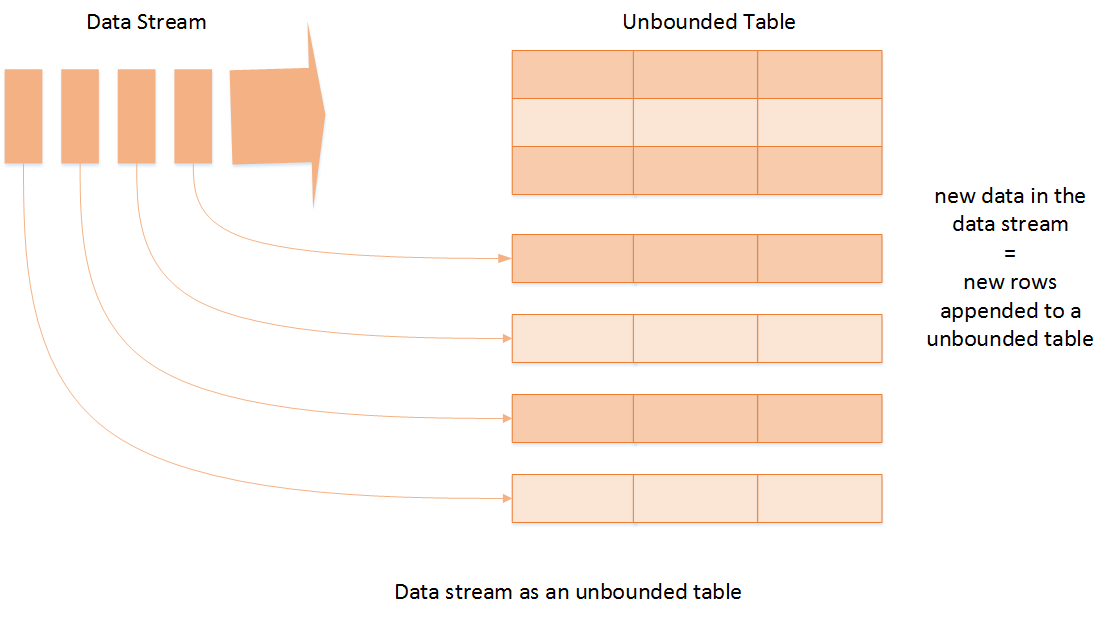
针对实时数据的查询将会产生一个结果集,每隔一段时间(假如是1秒),新到来的实时数据行将会添加到"unbound table",Spark会对新添加的行进行实时计算,并更新结果集。每当结果集更新时,用户可以将新添加的结果行写入到外部存储中。
对于输出到外部存储这一步骤,有三种模式可以选择:
1. Complete Mode - 即每次更新结果集时,都将整个结果集写入外部存储中;
2. Append Mode - 即每次更新结果集时,只将新添加到结果集的结果行写入外部存储中;
3. Update Mode - 即每次更新结果集时,只有被更新的结果行写入到外部存储中(Spark2.0暂不支持);
我们用一个例子来说明下Structured Streaming编程模型;如下图所示,第一行表示从socket不断接收数据,第二行是时间轴,表示每隔1秒进行一次数据处理,第三行可以看成是之前提到的“unbound table”,而第四行为最终的wordCounts是结果集。当有新的数据到达时,Spark会执行“增量”查询,并更新结果集;该示例设置为Complete Mode,因此每次都将所有数据输出到控制台;
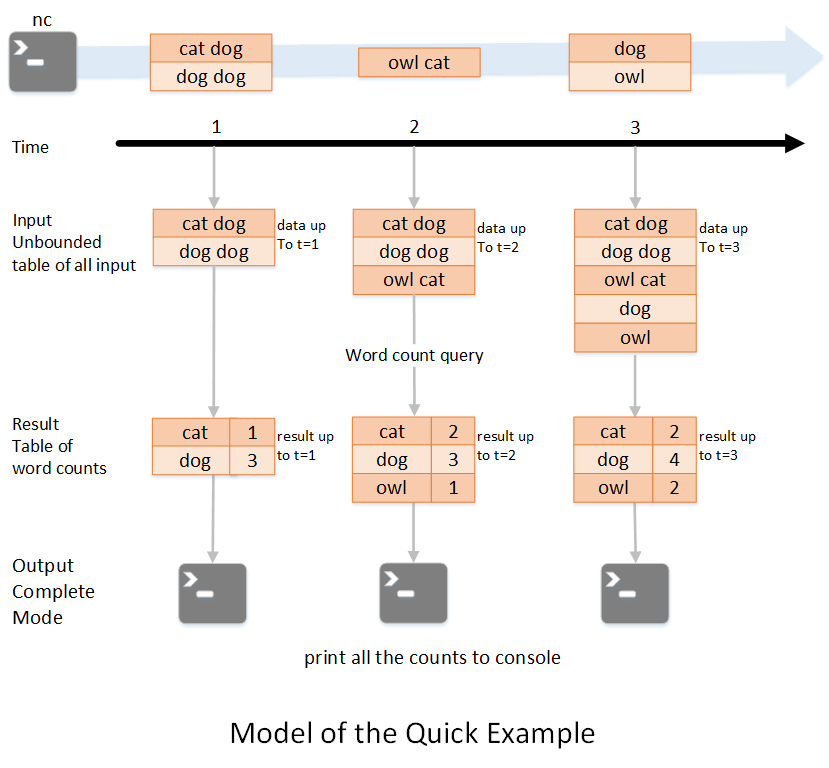
笔者来解释下上述执行过程;
1. 在第1秒时,此时到达的数据为"cat dog"和"dog dog",因此我们可以得到第1秒时的结果集cat=1 dog=3,并输出到控制台;
2. 当第2秒时,到达的数据为"owl cat",此时"unbound table"增加了一行数据"owl cat",执行word count查询并更新结果集,可得第2秒时的结果集为cat=2 dog=3 owl=1,并输出到控制台;
3. 当第3秒时,到达的数据为"dog"和"owl",此时"unbound table"增加两行数据"dog"和"owl",执行word count查询并更新结果集,可得第3秒时的结果集为cat=2 dog=4 owl=2;
以上就是Spark2.0新增的Structured Streaming编程模型的简要介绍。

