
返回大数据案例首页
《大数据课程实验案例:网站用户行为分析—-步骤四:利用R进行数据可视化分析》
开发团队:厦门大学数据库实验室 联系人:林子雨老师 ziyulin@xmu.edu.cn
版权声明:版权归厦门大学数据库实验室所有,请勿用于商业用途;未经授权,其他网站请勿转载
本教程介绍大数据课程实验案例“网站用户行为分析”的第四个步骤,利用R进行数据可视化分析。在实践本步骤之前,请先完成该实验案例的第一个步骤——本地数据集上传到数据仓库Hive,第二个步骤——Hive数据分析,和第三个步骤:Hive、MySQL、HBase数据互导。这里假设你已经完成了前面的这三个步骤。
R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。在实际的案例中,更多的是跟其他数据分析工具结合起来,如:MySQL,Hive等。这里使用R的ggplot2绘图工具和recharts的绘图工具来进行可视化分析消费者行为的实例。
环境
本步骤需要涉及以下环境:
操作系统:Linux系统(比如Ubuntu16.04)
可视化:R(安装在Linux系统下)
数据库:MySQL(安装在Linux系统下)
R语言包的安装方式如下:
Ubuntu自带的APT包管理器中的R安装包总是落后于标准版,因此需要添加新的镜像源把APT包管理中的R安装包更新到最新版。
请登录Linux系统,打开一个终端,然后执行下面命令(并注意保持网络连通,可以访问互联网,因为安装过程要下载各种安装文件):
利用vim打开/etc/apt/sources.list文件
sudo vim /etc/apt/sources.list
在文件的最后一行添加厦门大学的镜像源:
deb http://mirrors.tuna.tsinghua.edu.cn/CRAN/bin/linux/ubuntu/ trusty/
退出vim,更新软件源列表
sudo apt-get update
如果更新软件源出现由于没有公钥,无法验证下列签名的错误,请执行如下命令: sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 51716619E084DAB9
安装R语言
sudo apt-get install r-base
会提示“您希望继续执行吗?[Y/n]”,可以直接键盘输入“Y”,就可以顺利安装结束。
安装结束后,可以执行下面命令启动R:
R
启动后,会显示如下信息,并进入“>”命令提示符状态:
R version 3.3.2 (2016-10-31) -- "Sincere Pumpkin Patch"
Copyright (C) 2016 The R Foundation for Statistical Computing
Platform: x86_64-pc-linux-gnu (64-bit)
R是自由软件,不带任何担保。
在某些条件下你可以将其自由散布。
用'license()'或'licence()'来看散布的详细条件。
R是个合作计划,有许多人为之做出了贡献.
用'contributors()'来看合作者的详细情况
用'citation()'会告诉你如何在出版物中正确地引用R或R程序包。
用'demo()'来看一些示范程序,用'help()'来阅读在线帮助文件,或
用'help.start()'通过HTML浏览器来看帮助文件。
用'q()'退出R.
>
“>”就是R的命令提示符,你可以在后面输入R语言命令。
可以执行下面命令退出R:
>q()
可视化分析MySQL中的数据
安装依赖库
为了完成可视化功能,我们需要为R安装一些依赖库,包括:RMySQL、ggplot2、devtools和recharts。
RMySQL是一个提供了访问MySQL数据库的R语言接口程序的R语言依赖库。
ggplot2和recharts则是R语言中提供绘图可视化功能的依赖库。
请启动R进入R命令提示符状态,执行如下命令安装RMySQL:
> install.packages('RMySQL')
上面命令执行后, 屏幕会提示"Would you like to user a personal library instead?(y/n)"等问题,只要遇到提问,都在键盘输入y后回车即可。然后,屏幕会显示“---在此连线阶段时请选用CRAN的镜子---”,并会弹出一个白色背景的竖条形窗口,窗口标题是“HTTPS CRAN mirros”,标题下面列出了很多国家的镜像列表,我们可以选择位于China的镜像,比如,选择“China(Beijing)[https]”,然后点击“ok”按钮,就开始安装了。安装过程需要几分钟(当然,也和当前网络速度有关系)。
由于不同用户的Ubuntu开发环境不一样,安装有很大可能因为缺少组件导致失败,如果出现如下错误信息:
Configuration failed because libmysqlclient was not found. Try installing:
* deb: libmariadb-client-lgpl-dev (Debian, Ubuntu 16.04)
libmariadbclient-dev (Ubuntu 14.04)
* rpm: mariadb-devel | mysql-devel (Fedora, CentOS, RHEL)
* csw: mysql56_dev (Solaris)
* brew: mariadb-connector-c (OSX)
.................
ERROR: configuration failed for package ‘RMySQL’
* removing ‘/home/hadoop/R/x86_64-pc-linux-gnu-library/3.3/RMySQL’
下载的程序包在
‘/tmp/RtmpvEArxz/downloaded_packages’里
Warning message:
In install.packages("RMySQL") : 安装程序包‘RMySQL’时退出狀態的值不是0
只要根据错误给出的错误信息,进行操作即可。q()退出R命令提示符状态,回到Shell状态,笔者的系统是Ubuntu 16.04,那么,根据上面的英文错误信息,就需要在Shell命令提示符状态下执行下面命令安装libmariadb-client-lgpl-dev:
sudo apt-get install libmariadb-client-lgpl-dev
然后,再次输入下面命令进入R命令提示符状态:
R
启动后,并进入“>”命令提示符状态。然后,执行如下命令安装绘图包ggplot2,如果还出现缺少组件的错误,请按照上面的解决方案解决!
> install.packages('ggplot2')
然后,屏幕会显示“---在此连线阶段时请选用CRAN的镜子---”,并会弹出一个白色背景的竖条形窗口,窗口标题是“HTTPS CRAN mirros”,标题下面列出了很多国家的镜像列表,我们可以选择位于China的镜像,比如,选择“China(Beijing)[https]”,然后点击“ok”按钮,就开始安装了。这个命令运行后,大概需要安装10分钟时间(当然,也和当前网络速度有关系)。
下面继续运行下面命令安装devtools:
> install.packages('devtools')
如果在上面安装devtools的过程中,又出现了错误,处理方法很简单,还是按照上面介绍的方法,根据屏幕上给出的英文错误信息,缺少什么软件,就用sudo apt-get install命令安装该软件就可以了。笔者在Ubuntu16.04上执行devtools安装时,出现了三次错误,笔者根据每次错误的英文提示信息,安装了三个软件libssl-dev、libssh2-1-dev、libcurl4-openssl-dev,安装命令如下:
sudo apt-get install libssl-dev
sudo apt-get install libssh2-1-dev
sudo apt-get install libcurl4-openssl-dev
读者在安装过程中,可能会出现不同的错误,按照同样的处理方法可以顺利解决。
下面在R命令提示符下再执行如下命令安装taiyun/recharts:
> devtools::install_github('taiyun/recharts')
分析
以下分析使用的函数方法,都可以使用如下命令查询函数的相关文档。例如:查询sort()函数如何使用
?sort
这时,就会进入冒号“:”提示符状态(也就是帮助文档状态),在冒号后面输入q即可退出帮助文档状态,返回到R提示符状态!
- 连接MySQL,并获取数据
请在Linux系统中新建另外一个终端,然后执行下面命令启动MySQL数据库:
service mysql start
屏幕上会弹出窗口提示你输入密码,本教程的MySQL数据库的用户名是root,密码是hadoop,所以,直接输入密码hadoop,这样就成功启动了MySQL数据库。
下面,让我们查看一下MySQL数据库中的数据,请执行下面命令进入MySQL命令提示符状态:
mysql -u root -p
会提示你输入密码,我们输入密码hadoop,就进入了“mysql>”提示符状态,下面就可以输入一些SQL语句查询数据:
mysql> use dblab;
mysql> select * from user_action limit 10;
这样,就可以查看到数据库dblab中的user_action表的前10行记录,如下:
+--------+-----------+-----------+---------------+---------------+------------+-----------+
| id | uid | item_id | behavior_type | item_category | visit_date | province |
+--------+-----------+-----------+---------------+---------------+------------+-----------+
| 225653 | 102865660 | 164310319 | 1 | 5027 | 2014-12-08 | 香港 |
| 225654 | 102865660 | 72511722 | 1 | 1121 | 2014-12-13 | 天津市 |
| 225655 | 102865660 | 334372932 | 1 | 5027 | 2014-11-30 | 江苏 |
| 225656 | 102865660 | 323237439 | 1 | 5027 | 2014-12-02 | 广东 |
| 225657 | 102865660 | 323237439 | 1 | 5027 | 2014-12-07 | 山西 |
| 225658 | 102865660 | 34102362 | 1 | 1863 | 2014-12-13 | 内蒙古 |
| 225659 | 102865660 | 373499226 | 1 | 12388 | 2014-11-26 | 湖北 |
| 225660 | 102865660 | 271583890 | 1 | 5027 | 2014-12-06 | 山西 |
| 225661 | 102865660 | 384764083 | 1 | 5399 | 2014-11-26 | 澳门 |
| 225662 | 102865660 | 139671483 | 1 | 5027 | 2014-12-03 | 广东 |
+--------+-----------+-----------+---------------+---------------+------------+-----------+
10 rows in set (0.00 sec)
然后切换到刚才已经打开的R命令提示符终端窗口:
library(RMySQL)
conn <- dbConnect(MySQL(),dbname='dblab',username='root',password='hadoop',host="127.0.0.1",port=3306)
user_action <- dbGetQuery(conn,'select * from user_action')
- 分析消费者对商品的行为
summary(user_action$behavior_type)summary() 函数可以得到样本数据类型和长度,如果样本是数值型,我们还能得到样本数据的最小值、最大值、四分位数以及均值信息。
得到结果:Length Class Mode 300000 character character可以看出原来的MySQL数据中,消费者行为变量的类型是字符型。这样不好做比较,需要把消费者行为变量转换为数值型变量
summary(as.numeric(user_action$behavior_type))得到结果:
Min. 1st Qu. Median Mean 3rd Qu. Max. 1.000 1.000 1.000 1.105 1.000 4.000接下来用柱状图表示:
library(ggplot2) ggplot(user_action,aes(as.numeric(behavior_type)))+geom_histogram()在使用ggplot2库的时候,需要使用library导入库。ggplot()绘制时,创建绘图对象,即第一个图层,包含两个参数(数据与变量名称映射).变量名称需要被包含aes函数里面。ggplot2的图层与图层之间用“+”进行连接。ggplot2包中的geom_histogram()可以很方便的实现直方图的绘制。
分析结果如下图:
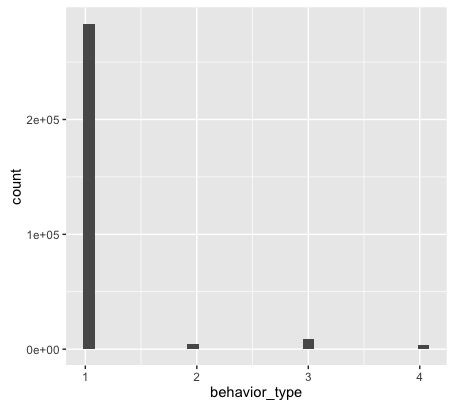
从上图可以得到:大部分消费者行为仅仅只是浏览。只有很少部分的消费者会购买商品。 -
分析哪一类商品被购买总量前十的商品和被购买总量
temp <- subset(user_action,as.numeric(behavior_type)==4) # 获取子数据集 count <- sort(table(temp$item_category),decreasing = T) #排序 print(count[1:10]) # 获取第1到10个排序结果subset()函数,从某一个数据框中选择出符合某条件的数据或是相关的列.table()对应的就是统计学中的列联表,是一种记录频数的方法.sort()进行排序,返回排序后的数值向量。
得到结果:6344 1863 5232 12189 7957 4370 13230 11537 1838 5894 79 46 45 42 40 34 33 32 31 30结果第一行表示商品分类,该类下被消费的数次。
接下来用散点图表示:result <- as.data.frame(count[1:10]) #将count矩阵结果转换成数据框 ggplot(result,aes(Var1,Freq,col=factor(Var1)))+geom_point()通过 as.data.frame() 把矩阵等转换成为数据框.
分析结果如下图:
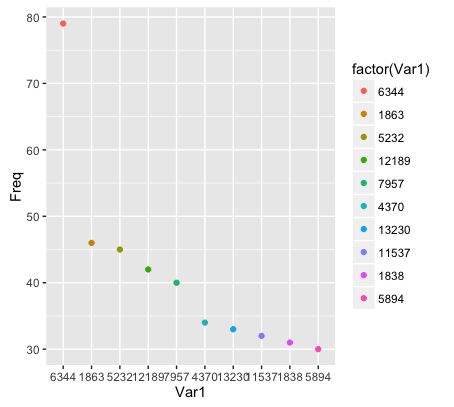
-
分析每年的哪个月份购买商品的量最多
从MySQL直接获取的数据中visit_date变量都是2014年份,并没有划分出具体的月份,那么可以在数据集增加一列月份数据。month <- substr(user_action$visit_date,6,7) # visit_date变量中截取月份 user_action <- cbind(user_action,month) # user_action增加一列月份数据接下来用柱状图分别表示消费者购买量
ggplot(user_action,aes(as.numeric(behavior_type),col=factor(month)))+geom_histogram()+facet_grid(.~month)aes()函数中的col属性可以用来设置颜色。factor()函数则是把数值变量转换成分类变量,作用是以不同的颜色表示。如果不使用factor()函数,颜色将以同一种颜色渐变的颜色表现。 facet_grid(.~month)表示柱状图按照不同月份进行分区。
由于MySQL获取的数据中只有11月份和12月份的数据,所以上图只有显示两个表格。
分析结果如下图:
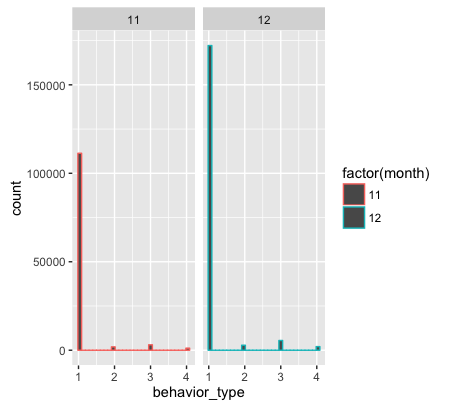
-
分析国内哪个省份的消费者最有购买欲望
library(recharts) rel <- as.data.frame(table(temp$province)) provinces <- rel$Var1 x = c() for(n in provinces){ x[length(x)+1] = nrow(subset(temp,(province==n))) } mapData <- data.frame(province=rel$Var1, count=x, stringsAsFactors=F) # 设置地图信息 eMap(mapData, namevar=~province, datavar = ~count) #画出中国地图nrow()用来计算数据集的行数。
分析结果如下图:
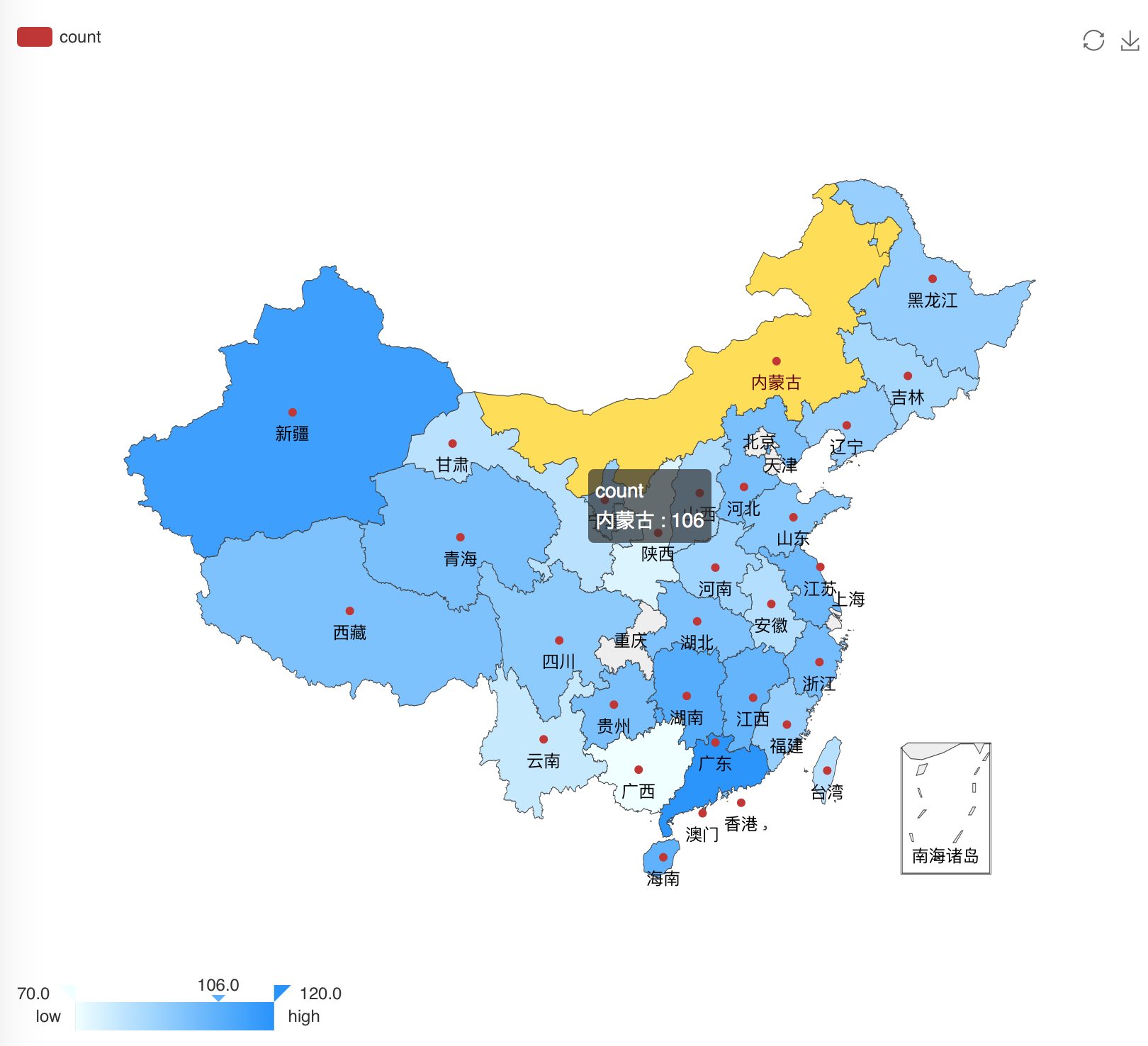
大数据案例网站用户购物行为分析所有实验步骤到此结束!