R语言是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。这里使用R的ggplot2绘图工具和recharts的绘图工具来进行可视化分析消费者行为的实例。
环境
操作系统:Ubuntu或Mac(OSX)或Windows
操作环境:R
关于R语言环境的安装,请点击厦门大学开源软件镜像服务根据操作系统选择安装。
以下操作命令,全部都是基于Ubuntu系统。
数据源
提供的数据源有两个文件,分别是small_user_table.csv和user_table.csv。将近1G的user_table.csv文件导入到内存中作数据集,可能需要花费很长的时间。所以这里选用只有13M左右的small_user_table.csv作为测试数据集。
这里使用small_user_table.csv文件作为数据源。该文件请保存到当前系统用户目录~,以便操作跟下面的命令一致。
获取small_user_table.csv的前十行,命令如下:
cd ~
head -10 ./small_user_table.csv

如上图所示,small_user_table.csv每行数据分别以\t 制表符间隔。
第一行数据user_id表示用户id,item_id表示商品id,behavior_type表示对商品的行为(包括浏览、收藏、加购物车、购买,对应取值分别是1、2、3、4),item_category表示商品分类,year表示年,month表示月份,day表示日期,province表示消费者所在省份。
第一行数据可以用来当做数据集的变量名称,每一列数据可以作为第一行变量变量的一系列值。
可视化分析
安装依赖库
运行R Console,执行如下命令
install.packages('ggplot2')
install.packages('devtools')
devtools::install_github('taiyun/recharts')
分析
以下分析使用的函数方法,都可以使用如下命令查询函数的相关文档。例如:查询sort()函数如何使用
?sort
- 导入csv文件
# header=True保留csv文件第一行变量名称,sep='\t'表示数据以制表符间隔 user_table = read.csv('~/user_table.csv',header = TRUE,sep = '\t') - 分析消费者对商品的行为
summary(user_table$behavior_type)summary()函数可以得到样本数据的最小值、最大值、四分位数以及均值。
得到结果:Min. 1st Qu. Median Mean 3rd Qu. Max. 1.000 1.000 1.000 1.105 1.000 4.000消费者行为最小值Min为1,最大值Max为4,平均值Mean为1.106.
summary(user_table$behavior_type==4)得到结果:
Mode FALSE TRUE NA's logical 296789 3210 0可以看出整个数据集中,购买行为的消费者仅仅只有3210,远远小于非购买行为的消费者。
接下来用柱状图表示:library(ggplot2) ggplot(user_table,aes(behavior_type))+geom_histogram()在使用ggplot2库的时候,需要使用library导入库。ggplot()绘制时,创建绘图对象,即第一个图层,包含两个参数(数据与变量名称映射).变量名称需要被包含aes函数里面。ggplot2的图层与图层之间用“+”进行连接。ggplot2包中的geom_histogram()可以很方便的实现直方图的绘制。
分析结果如下图:
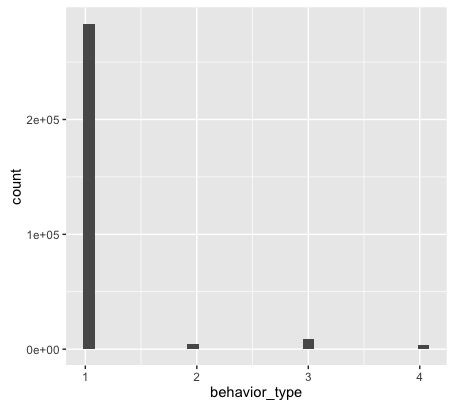
从上图可以得到:大部分消费者行为仅仅只是浏览。只有很少部分的消费者会购买商品。 -
分析哪一类商品被购买总量前十的商品和被购买总量
temp <- subset(user_table,behavior_type==4) # 获取子数据集 count <- sort(table(temp$item_category),decreasing = T) #排序 print(count[1:10]) #打印第1到10的排序结果subset()函数,从某一个数据框中选择出符合某条件的数据或是相关的列.table()对应的就是统计学中的列联表,是一种记录频数的方法.sort()进行排序,返回排序后的数值向量。
得到结果:6344 1863 5232 12189 7957 4370 13230 11537 1838 5894 79 46 45 42 40 34 33 32 31 30结果第一行表示商品分类,该类下被消费的数次。
接下来用散点图表示:result <- as.data.frame(count[1:10]) #将count矩阵结果转换成数据框 ggplot(result,aes(Var1,Freq,col=factor(Var1)))+geom_point()通过 as.data.frame() 把矩阵等转换成为数据框.
分析结果如下图:
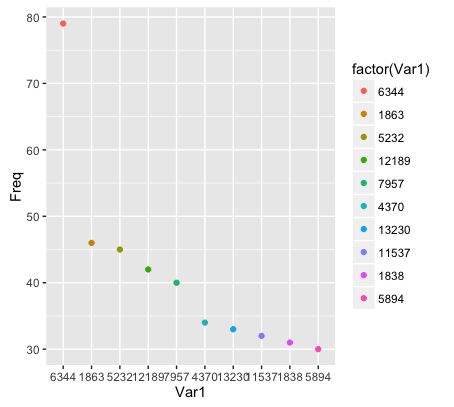
-
分析每年的哪个月份购买商品的量最多
接下来用柱状图分别表示消费者购买量library(ggplot2) ggplot(user_table,aes(behavior_type,col=factor(month)))+geom_histogram()+facet_grid(.~month)aes()函数中的col属性可以用来设置颜色。factor()函数则是把数值变量转换成分类变量,作用是以不同的颜色表示。如果不使用factor()函数,颜色将以同一种颜色渐变的颜色表现。 facet_grid(.~month)表示柱状图按照不同月份进行分区。
由于small_user_table.csv只有11月份和12月份的数据,所以上图只有显示两个表格。
分析结果如下图:
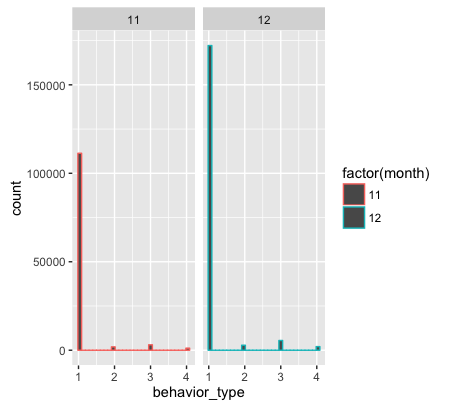
-
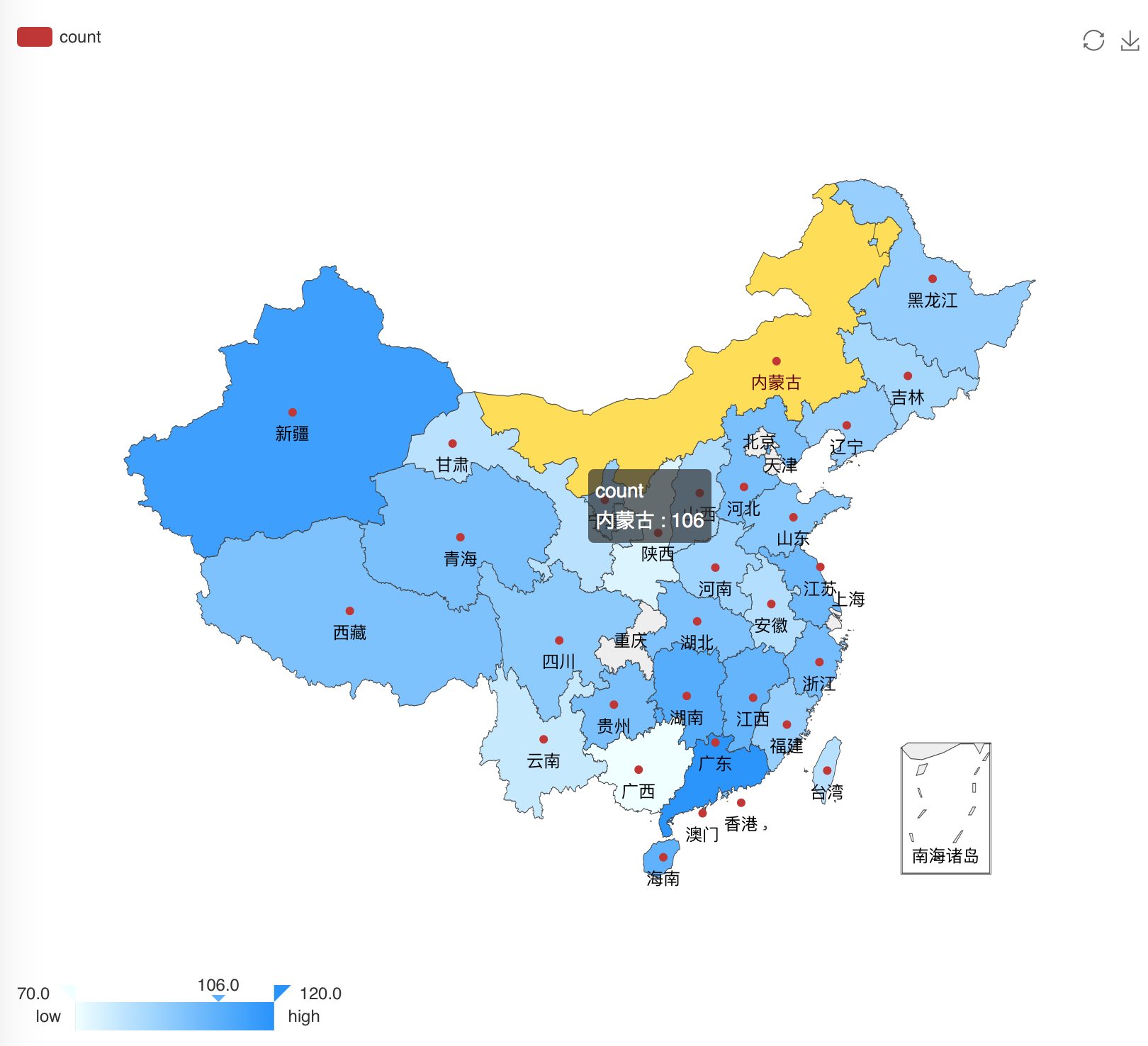
分析国内哪个省份的消费者最有购买欲望
rel <- as.data.frame(table(temp$province)) provinces <- rel$Var1 x = c() for(n in provinces){ x[length(x)+1] = nrow(subset(temp,(province==n))) } mapData <- data.frame(province=rel$Var1, count=x, stringsAsFactors=F) eMap(mapData, namevar=~province, datavar = ~count)nrow()用来计算数据集的行数。
分析结果如下图: