
现在介绍如何在Ubuntu系统中安装开发工具IntelliJ IDEA,以及如何使用IDEA开发Spark应用程序。这里使用的Spark版本号是2.4.0(Scala版本号是2.11.12)。
下载和安装IntelliJ IDEA
IDEA分为专业版和社区版,这里使用专业版。请到IDEA官网下载安装包ideaIU-2019.3.1.tar.gz,专业版软件免费试用30天,如果要破解激活(用于学习目的),可以到淘宝网购买激活账号(到淘宝网搜索“IDEA激活”,就可以找到店铺,花10元钱可以购买一个账号用于学习,不要用于商业用途)。
打开一个命令行终端,执行如下命令进行IntelliJ IDEA安装:
cd ~
sudo tar -zxvf /home/hadoop/download/ideaIU-2019.3.1.tar.gz -C /usr/local
cd /usr/local
sudo mv ./idea-IU-173.4548.28 ./idea #对目录进行重命名
下面使用如下命令修改目录所有者:
sudo chown -R linziyu:linziyu ./idea #假设Linux用户名为linziyu
我们在Spark开发时,是使用Scala语言。这里要注意,如果是专业版,不需要额外安装Scala插件,因为专业版已经自带了Scala插件。如果是IDEA社区版,则需要为IDEA工具安装Scala插件。
可以自己到Scala插件官网去下载。但是,一定要注意,Scala插件安装包的版本,一定要和自己电脑上安装的IntellJ IDEA的版本严格一致。与社区版ideaIC-2019.3.1.tar.gz对应的Scala插件安装包是scala-intellij-bin-2019.3.1.zip。安装Scala插件的方法很简单,在IDEA界面中,选择“File-->Settings”,打开设置界面,在界面左侧栏目中点击“Plugins”,在界面右侧上角点击齿轮图标,在弹出的菜单中选择“Install Plugin from Disk...”,然后找到scala-intellij-bin-2019.3.1.zip文件,点击确定即可。
创建一个新项目WordCount
在IDEA界面中,点击菜单“File-->New-->Project”,会弹出如下所示界面:

在上图中,点击界面左侧的“Maven”,并选择好Project SDK,然后,点击“Next”按钮,会弹出如下所示界面:

在上图中,把“Name”设置为“WordCount”,把“GroupId”设置为“dblab”,然后点击“Finish”按钮。
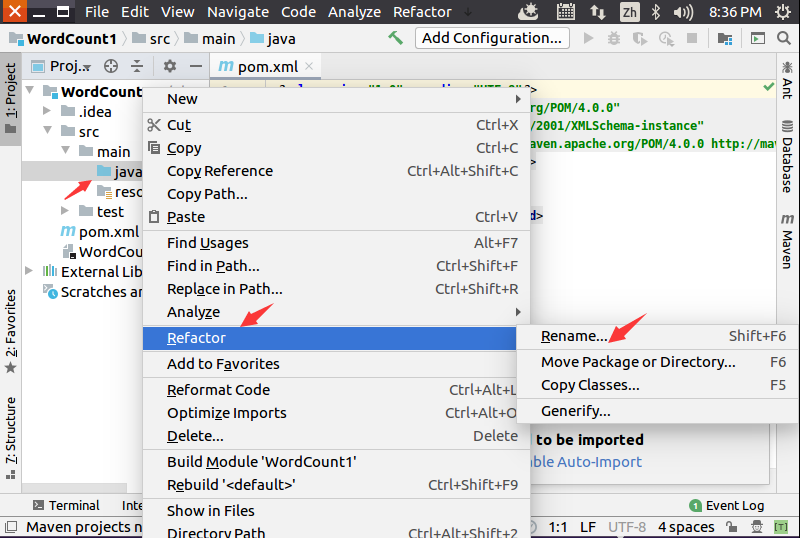
然后,如下图所示,在项目名称“WordCount”上单击鼠标右键,在弹出的菜单中点击“Add Framework Support”。
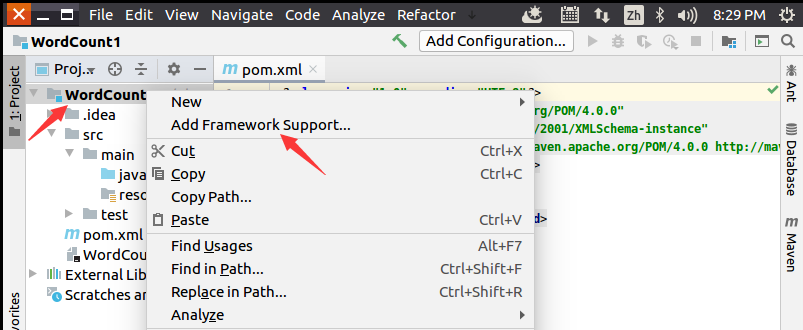
在弹出的界面中,如下图所示,在左侧栏目中找到“Scala”,点击选中(会出现勾号),然后在右侧的“Use Library”右边选择“scala_sdk_2.11.12”,最后点击“OK”按钮。
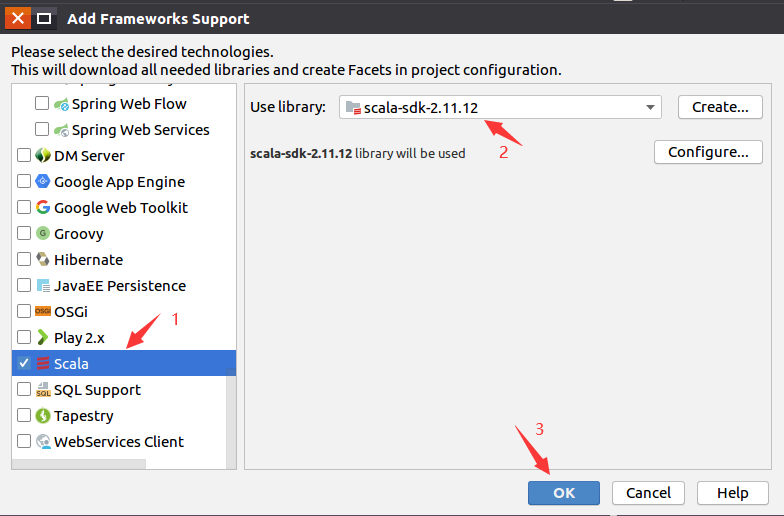
如下图所示,在“java”目录上单击鼠标右键,在弹出的菜单中选择“Refactor”,再在弹出的菜单中选择“Rename”,然后,在出现的界面中把“java”目录名称修改为“scala”。
然后,在IDEA界面中,如下图所示,在“scala”目录上单击鼠标右键,在弹出的菜单中选择“New”,再在弹出的菜单中选择“Scala Class”。

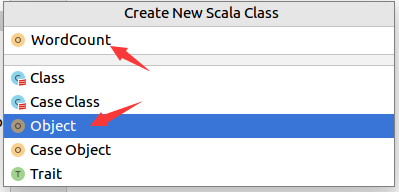
在弹出的界面中,如下图所示,点击选中“object”,然后在文本框中输入“WordCount”,然后回车。
在IDEA开发界面中,打开pom.xml,清空里面的内容,输入如下内容:
<project>
<groupId>dblab</groupId>
<artifactId>WordCount</artifactId>
<modelVersion>4.0.0</modelVersion>
<name>WordCount</name>
<packaging>jar</packaging>
<version>1.0</version>
<repositories>
<repository>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<properties>
<spark.version>2.4.0</spark.version>
<scala.version>2.11</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
然后,再打开WordCount.scala代码文件,清空里面的内容,输入如下内容:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object WordCount {
def main(args: Array[String]) {
val inputFile = "file:///home/hadoop/word.txt"
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
val textFile = sc.textFile(inputFile)
val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
wordCount.foreach(println)
}
}
这个代码文件的功能是对word.txt文件进行词频统计,所以,需要在本地文件系统中创建一个文件“/home/hadoop/word.txt”,里面输入一些英文单词,比如:
Hadoop is good
Spark is fast
Spark is better
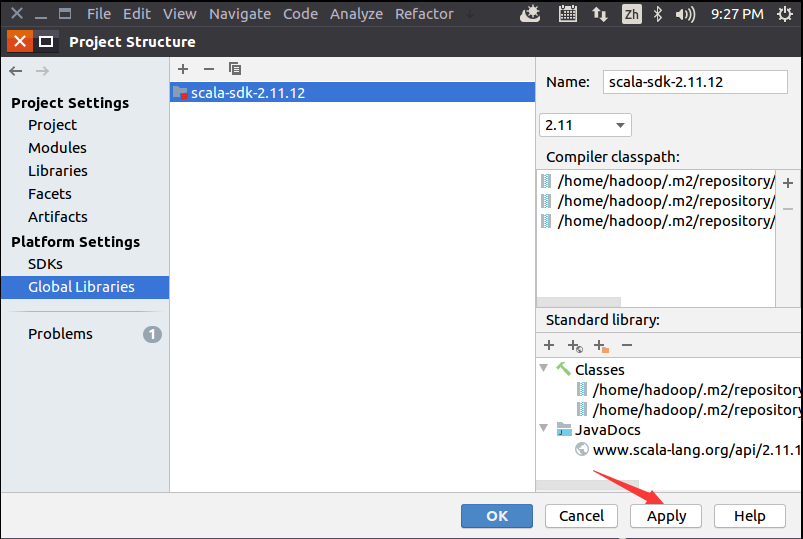
现在需要做一个很重要的事情,那就是要IDEA使用2.11.12版本的Spark依赖库,方法如下,如下图所示,选择菜单“File-->Project Structure”。
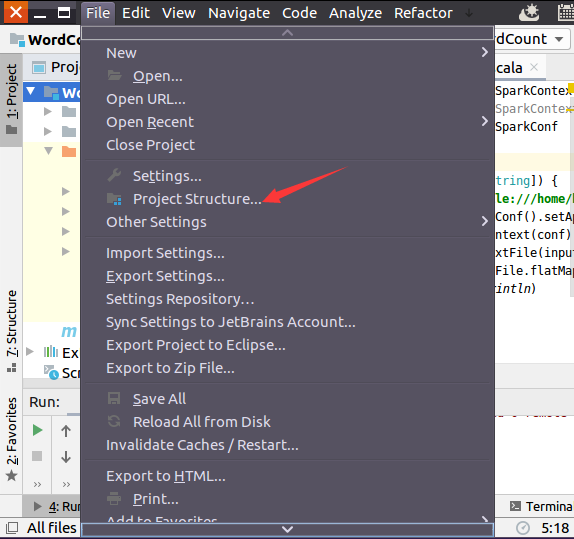
在弹出的Project Structure设置界面中,如下图所示,点击“Libraries”,这里一定要确保使用的依赖库是"scala-sdk-2.11.12",不能是其他版本,否则会导致程序无法运行。
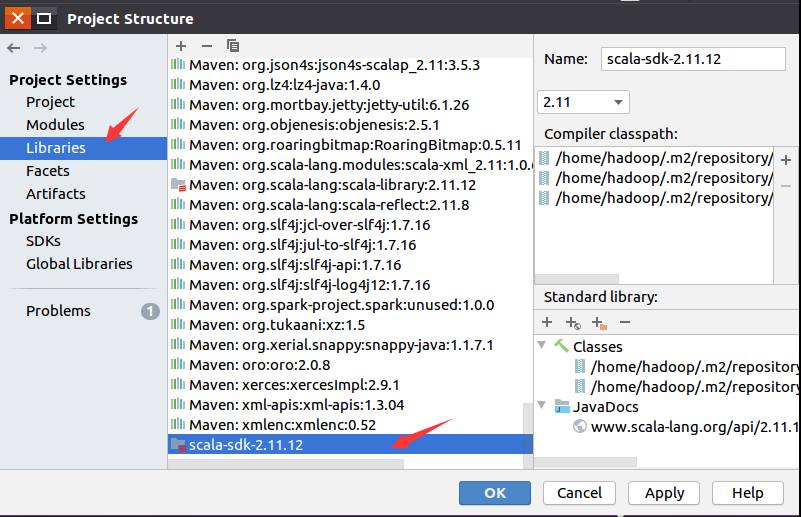
再点击“Global Libraries”,如下图所示,点击减号“-”把所有的依赖库都清空,然后点击加号“+”,新增依赖库"scala-sdk-2.11.12"。
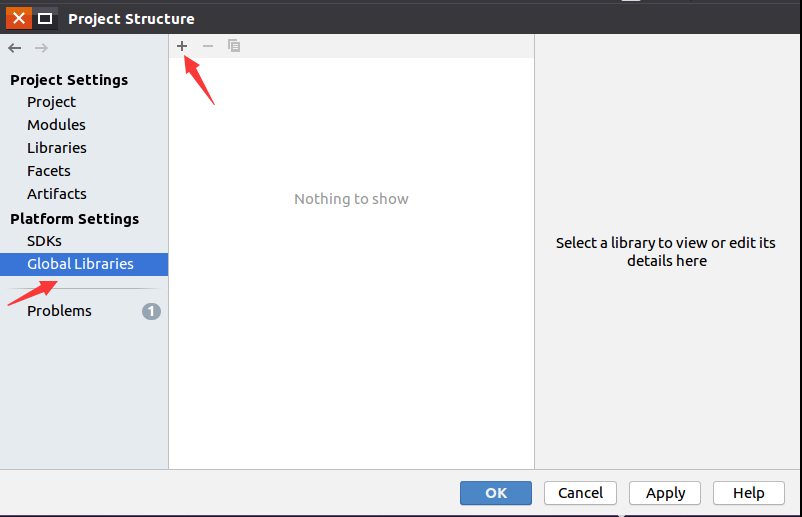
点击加号以后,会出现如下图所示的界面,在界面中点击“Scala SDK”。

然后,会弹出如下图所示界面,在里面选择Maven的2.11.12版本依赖库,然后点击OK按钮。

然后,会弹出如下所示界面,直接点击OK按钮就可以。
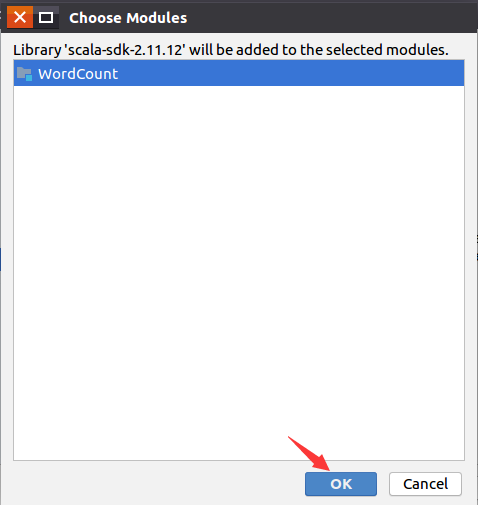
然后,会返回到如下界面,可以看出来,在加号减号的下面的矩形框里,出现了scala-sdk-2.11.12,这时,只要点击界面底部的"Apply"按钮就可以,然后再点击OK按钮。
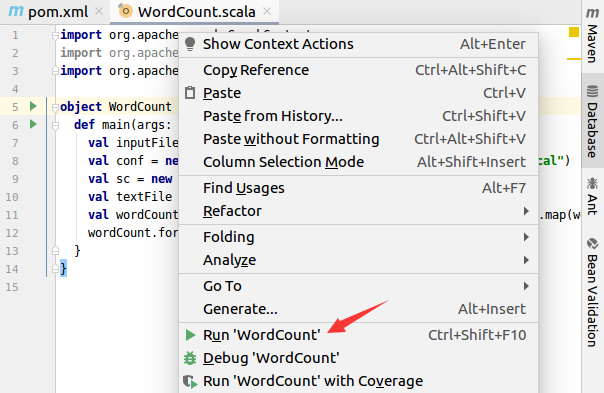
运行代码
在代码文件WordCount.scala窗口内,如下图所示,单击鼠标右键,在弹出的菜单中选择“Run WordCount”,就可以运行代码。
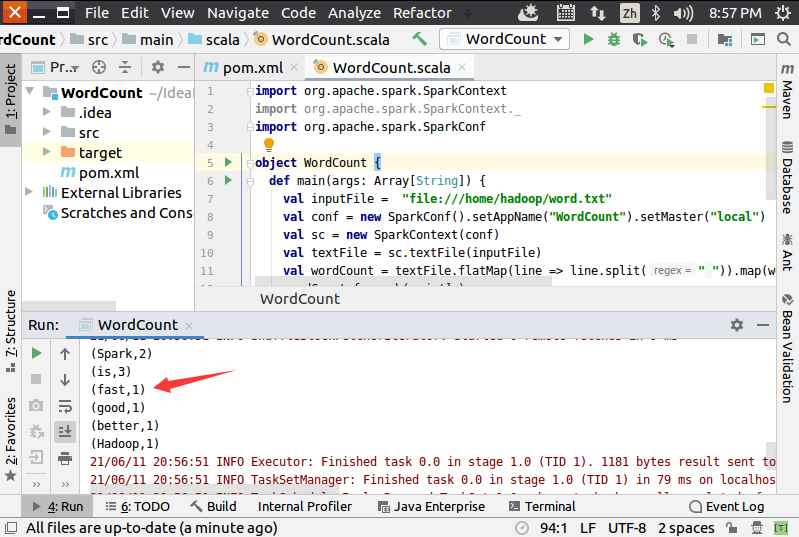
运行成功以后,就可以在运行信息窗口内看到词频统计结果,如下图所示:
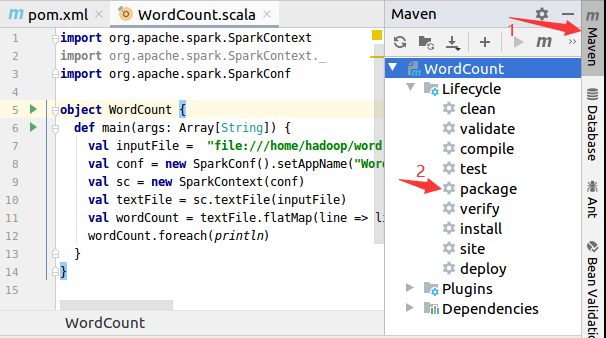
把应用程序打包成JAR包
如下图所示,在IDEA开发界面的右侧,点击“Maven”图标,会弹出Maven调试界面,在Maven调试界面中点击“package”,就可以对应用程序进行打包,打包成JAR包。
这时,到IDEA开发界面左侧的项目目录树中,在“target”目录下,就可以看到生成了两个JAR文件,分别是:WordCount-1.0.jar和WordCount-1.0-jar-with-dependencies.jar。
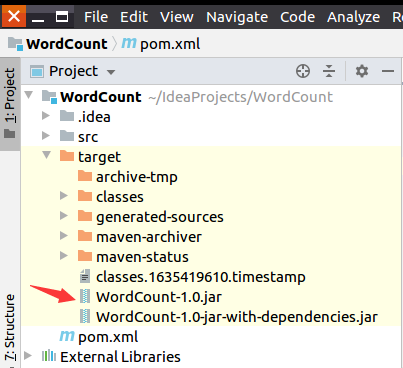
然后,打开一个Linux终端,执行如下命令运行JAR包:
cd /usr/local/spark
./bin/spark-submit --class "WordCount" /home/hadoop/IdeaProjects/WordCount/target/WordCount-1.0-jar-with-dependencies.jar
执行成功后就可以在屏幕上看到词频统计结果。