【版权声明】版权所有,严禁转载,严禁用于商业用途,侵权必究。
作者:厦门大学信息学院计算机科学系2019级研究生 卢思维
指导老师:厦门大学数据库实验室 林子雨 博士/副教授
相关教材:林子雨、郑海山、赖永炫编著《Spark编程基础(Python版)》(访问教材官网)
相关案例:基于Python语言的Spark数据处理分析案例集锦(PySpark)
本案例以2020年美国新冠肺炎疫情数据作为数据集,以Python为编程语言,使用Spark对数据进行分析,并对分析结果进行可视化。
一、实验环境
(1)Linux: Ubuntu 16.04
(2)Hadoop3.1.3 (查看安装教程)
(3)Python: 3.6
(4)Spark: 2.4.0 (查看安装教程)
(5)Jupyter Notebook (查看安装和使用方法教程)
二、数据集
1. 数据集下载
本次作业使用的数据集来自数据网站Kaggle的美国新冠肺炎疫情数据集(从百度网盘下载,提取码:t7tu),该数据集以数据表us-counties.csv组织,其中包含了美国发现首例新冠肺炎确诊病例至今(2020-05-19)的相关数据。数据包含以下字段:
字段名称 字段含义 例子
date 日期 2020/1/21;2020/1/22;etc
county 区县(州的下一级单位) Snohomish;
state 州 Washington
cases 截止该日期该区县的累计确诊人数 1,2,3…
deaths 截止该日期该区县的累计确诊人数 1,2,3…
2.格式转换
原始数据集是以.csv文件组织的,为了方便spark读取生成RDD或者DataFrame,首先将us-counties.csv转换为.txt格式文件us-counties.txt。转换操作使用python实现,代码组织在toTxt.py中,具体代码如下:
import pandas as pd
#.csv->.txt
data = pd.read_csv('/home/hadoop/us-counties.csv')
with open('/home/hadoop/us-counties.txt','a+',encoding='utf-8') as f:
for line in data.values:
f.write((str(line[0])+'\t'+str(line[1])+'\t'
+str(line[2])+'\t'+str(line[3])+'\t'+str(line[4])+'\n'))
3. 将文件上传至HDFS文件系统中
然后使用如下命令把本地文件系统的“/home/hadoop/us-counties.txt”上传到HDFS文件系统中,具体路径是“/user/hadoop/us-counties.txt”。具体命令如下:
./bin/hdfs dfs -put /home/hadoop/us-counties.txt /user/hadoop
三、使用Spark对数据进行分析
这里采用Python作为编程语言。
1. 完整代码
本部分操作的完整实验代码存放在了analyst.py中,具体如下:
from pyspark import SparkConf,SparkContext
from pyspark.sql import Row
from pyspark.sql.types import *
from pyspark.sql import SparkSession
from datetime import datetime
import pyspark.sql.functions as func
def toDate(inputStr):
newStr = ""
if len(inputStr) == 8:
s1 = inputStr[0:4]
s2 = inputStr[5:6]
s3 = inputStr[7]
newStr = s1+"-"+"0"+s2+"-"+"0"+s3
else:
s1 = inputStr[0:4]
s2 = inputStr[5:6]
s3 = inputStr[7:]
newStr = s1+"-"+"0"+s2+"-"+s3
date = datetime.strptime(newStr, "%Y-%m-%d")
return date
#主程序:
spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate()
fields = [StructField("date", DateType(),False),StructField("county", StringType(),False),StructField("state", StringType(),False),
StructField("cases", IntegerType(),False),StructField("deaths", IntegerType(),False),]
schema = StructType(fields)
rdd0 = spark.sparkContext.textFile("/user/hadoop/us-counties.txt")
rdd1 = rdd0.map(lambda x:x.split("\t")).map(lambda p: Row(toDate(p[0]),p[1],p[2],int(p[3]),int(p[4])))
shemaUsInfo = spark.createDataFrame(rdd1,schema)
shemaUsInfo.createOrReplaceTempView("usInfo")
#1.计算每日的累计确诊病例数和死亡数
df = shemaUsInfo.groupBy("date").agg(func.sum("cases"),func.sum("deaths")).sort(shemaUsInfo["date"].asc())
#列重命名
df1 = df.withColumnRenamed("sum(cases)","cases").withColumnRenamed("sum(deaths)","deaths")
df1.repartition(1).write.json("result1.json") #写入hdfs
#注册为临时表供下一步使用
df1.createOrReplaceTempView("ustotal")
#2.计算每日较昨日的新增确诊病例数和死亡病例数
df2 = spark.sql("select t1.date,t1.cases-t2.cases as caseIncrease,t1.deaths-t2.deaths as deathIncrease from ustotal t1,ustotal t2 where t1.date = date_add(t2.date,1)")
df2.sort(df2["date"].asc()).repartition(1).write.json("result2.json") #写入hdfs
#3.统计截止5.19日 美国各州的累计确诊人数和死亡人数
df3 = spark.sql("select date,state,sum(cases) as totalCases,sum(deaths) as totalDeaths,round(sum(deaths)/sum(cases),4) as deathRate from usInfo where date = to_date('2020-05-19','yyyy-MM-dd') group by date,state")
df3.sort(df3["totalCases"].desc()).repartition(1).write.json("result3.json") #写入hdfs
df3.createOrReplaceTempView("eachStateInfo")
#4.找出美国确诊最多的10个州
df4 = spark.sql("select date,state,totalCases from eachStateInfo order by totalCases desc limit 10")
df4.repartition(1).write.json("result4.json")
#5.找出美国死亡最多的10个州
df5 = spark.sql("select date,state,totalDeaths from eachStateInfo order by totalDeaths desc limit 10")
df5.repartition(1).write.json("result5.json")
#6.找出美国确诊最少的10个州
df6 = spark.sql("select date,state,totalCases from eachStateInfo order by totalCases asc limit 10")
df6.repartition(1).write.json("result6.json")
#7.找出美国死亡最少的10个州
df7 = spark.sql("select date,state,totalDeaths from eachStateInfo order by totalDeaths asc limit 10")
df7.repartition(1).write.json("result7.json")
#8.统计截止5.19全美和各州的病死率
df8 = spark.sql("select 1 as sign,date,'USA' as state,round(sum(totalDeaths)/sum(totalCases),4) as deathRate from eachStateInfo group by date union select 2 as sign,date,state,deathRate from eachStateInfo").cache()
df8.sort(df8["sign"].asc(),df8["deathRate"].desc()).repartition(1).write.json("result8.json")
2. 读取文件生成DataFrame
上面已经给出了完整代码。下面我们再对代码做一些简要介绍。首先看看读取文件生成DataFrame。
由于本实验中使用的数据为结构化数据,因此可以使用spark读取源文件生成DataFrame以方便进行后续分析实现。
本部分代码组织在analyst.py中,读取us-counties.txt生成DataFrame的代码如下:
from pyspark import SparkConf,SparkContext
from pyspark.sql import Row
from pyspark.sql.types import *
from pyspark.sql import SparkSession
from datetime import datetime
import pyspark.sql.functions as func
def toDate(inputStr):
newStr = ""
if len(inputStr) == 8:
s1 = inputStr[0:4]
s2 = inputStr[5:6]
s3 = inputStr[7]
newStr = s1+"-"+"0"+s2+"-"+"0"+s3
else:
s1 = inputStr[0:4]
s2 = inputStr[5:6]
s3 = inputStr[7:]
newStr = s1+"-"+"0"+s2+"-"+s3
date = datetime.strptime(newStr, "%Y-%m-%d")
return date
#主程序:
spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate()
fields = [StructField("date", DateType(),False),StructField("county", StringType(),False),StructField("state", StringType(),False),
StructField("cases", IntegerType(),False),StructField("deaths", IntegerType(),False),]
schema = StructType(fields)
rdd0 = spark.sparkContext.textFile("/user/hadoop/us-counties.txt")
rdd1 = rdd0.map(lambda x:x.split("\t")).map(lambda p: Row(toDate(p[0]),p[1],p[2],int(p[3]),int(p[4])))
shemaUsInfo = spark.createDataFrame(rdd1,schema)
shemaUsInfo.createOrReplaceTempView("usInfo")
3.进行数据分析
本实验主要统计以下8个指标,分别是:
1) 统计美国截止每日的累计确诊人数和累计死亡人数。做法是以date作为分组字段,对cases和deaths字段进行汇总统计。
2) 统计美国每日的新增确诊人数和新增死亡人数。因为新增数=今日数-昨日数,所以考虑使用自连接,连接条件是t1.date = t2.date + 1,然后使用t1.totalCases – t2.totalCases计算该日新增。
3) 统计截止5.19日,美国各州的累计确诊人数和死亡人数。首先筛选出5.19日的数据,然后以state作为分组字段,对cases和deaths字段进行汇总统计。
4) 统计截止5.19日,美国确诊人数最多的十个州。对3)的结果DataFrame注册临时表,然后按确诊人数降序排列,并取前10个州。
5) 统计截止5.19日,美国死亡人数最多的十个州。对3)的结果DataFrame注册临时表,然后按死亡人数降序排列,并取前10个州。
6) 统计截止5.19日,美国确诊人数最少的十个州。对3)的结果DataFrame注册临时表,然后按确诊人数升序排列,并取前10个州。
7) 统计截止5.19日,美国死亡人数最少的十个州。对3)的结果DataFrame注册临时表,然后按死亡人数升序排列,并取前10个州
8) 统计截止5.19日,全美和各州的病死率。病死率 = 死亡数/确诊数,对3)的结果DataFrame注册临时表,然后按公式计算。
在计算以上几个指标过程中,根据实现的简易程度,既采用了DataFrame自带的操作函数,又采用了spark sql进行操作。
4. 结果文件
上述Spark计算结果保存.json文件,方便后续可视化处理。由于使用Python读取HDFS文件系统不太方便,故将HDFS上结果文件转储到本地文件系统中,使用以下命令:
./bin/hdfs dfs -get /user/hadoop/result1.json/*.json /home/hadoop/result/result1
对于result2等结果文件,使用相同命令,只需要改一下路径即可。
四、数据可视化
1. 可视化工具选择与代码
选择使用python第三方库pyecharts作为可视化工具。
在使用前,需要安装pyecharts,安装代码如下:
pip install pyecharts
具体可视化实现代码组织与showdata.py文件中。具体代码如下:
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.charts import Line
from pyecharts.components import Table
from pyecharts.charts import WordCloud
from pyecharts.charts import Pie
from pyecharts.charts import Funnel
from pyecharts.charts import Scatter
from pyecharts.charts import PictorialBar
from pyecharts.options import ComponentTitleOpts
from pyecharts.globals import SymbolType
import json
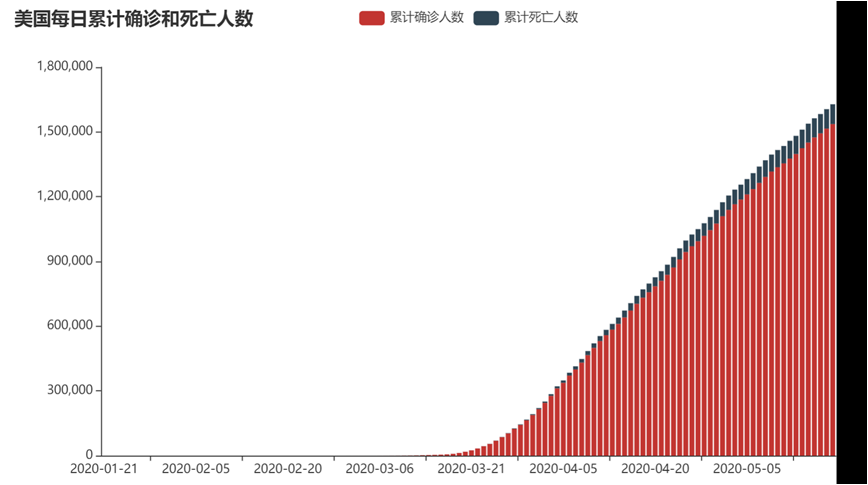
#1.画出每日的累计确诊病例数和死亡数——>双柱状图
def drawChart_1(index):
root = "/home/hadoop/result/result" + str(index) +"/part-00000.json"
date = []
cases = []
deaths = []
with open(root, 'r') as f:
while True:
line = f.readline()
if not line: # 到 EOF,返回空字符串,则终止循环
break
js = json.loads(line)
date.append(str(js['date']))
cases.append(int(js['cases']))
deaths.append(int(js['deaths']))
d = (
Bar()
.add_xaxis(date)
.add_yaxis("累计确诊人数", cases, stack="stack1")
.add_yaxis("累计死亡人数", deaths, stack="stack1")
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(title_opts=opts.TitleOpts(title="美国每日累计确诊和死亡人数"))
.render("/home/hadoop/result/result1/result1.html")
)
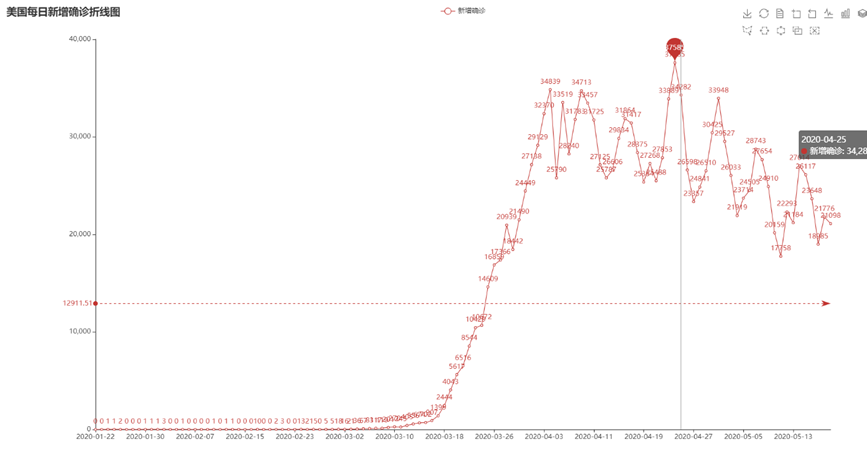
#2.画出每日的新增确诊病例数和死亡数——>折线图
def drawChart_2(index):
root = "/home/hadoop/result/result" + str(index) +"/part-00000.json"
date = []
cases = []
deaths = []
with open(root, 'r') as f:
while True:
line = f.readline()
if not line: # 到 EOF,返回空字符串,则终止循环
break
js = json.loads(line)
date.append(str(js['date']))
cases.append(int(js['caseIncrease']))
deaths.append(int(js['deathIncrease']))
(
Line(init_opts=opts.InitOpts(width="1600px", height="800px"))
.add_xaxis(xaxis_data=date)
.add_yaxis(
series_name="新增确诊",
y_axis=cases,
markpoint_opts=opts.MarkPointOpts(
data=[
opts.MarkPointItem(type_="max", name="最大值")
]
),
markline_opts=opts.MarkLineOpts(
data=[opts.MarkLineItem(type_="average", name="平均值")]
),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="美国每日新增确诊折线图", subtitle=""),
tooltip_opts=opts.TooltipOpts(trigger="axis"),
toolbox_opts=opts.ToolboxOpts(is_show=True),
xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=False),
)
.render("/home/hadoop/result/result2/result1.html")
)
(
Line(init_opts=opts.InitOpts(width="1600px", height="800px"))
.add_xaxis(xaxis_data=date)
.add_yaxis(
series_name="新增死亡",
y_axis=deaths,
markpoint_opts=opts.MarkPointOpts(
data=[opts.MarkPointItem(type_="max", name="最大值")]
),
markline_opts=opts.MarkLineOpts(
data=[
opts.MarkLineItem(type_="average", name="平均值"),
opts.MarkLineItem(symbol="none", x="90%", y="max"),
opts.MarkLineItem(symbol="circle", type_="max", name="最高点"),
]
),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="美国每日新增死亡折线图", subtitle=""),
tooltip_opts=opts.TooltipOpts(trigger="axis"),
toolbox_opts=opts.ToolboxOpts(is_show=True),
xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=False),
)
.render("/home/hadoop/result/result2/result2.html")
)
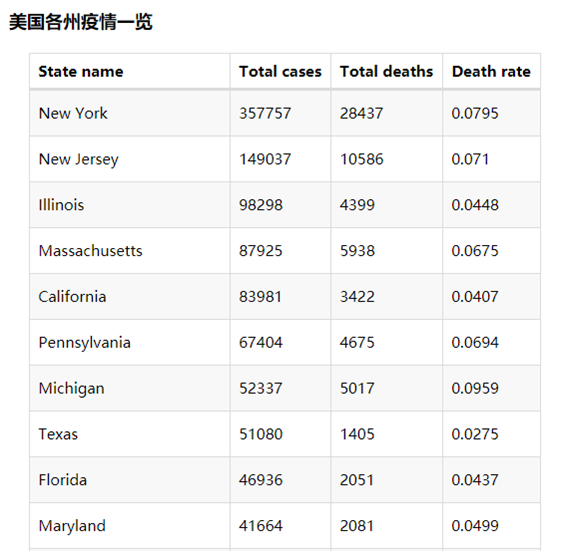
#3.画出截止5.19,美国各州累计确诊、死亡人数和病死率--->表格
def drawChart_3(index):
root = "/home/hadoop/result/result" + str(index) +"/part-00000.json"
allState = []
with open(root, 'r') as f:
while True:
line = f.readline()
if not line: # 到 EOF,返回空字符串,则终止循环
break
js = json.loads(line)
row = []
row.append(str(js['state']))
row.append(int(js['totalCases']))
row.append(int(js['totalDeaths']))
row.append(float(js['deathRate']))
allState.append(row)
table = Table()
headers = ["State name", "Total cases", "Total deaths", "Death rate"]
rows = allState
table.add(headers, rows)
table.set_global_opts(
title_opts=ComponentTitleOpts(title="美国各州疫情一览", subtitle="")
)
table.render("/home/hadoop/result/result3/result1.html")
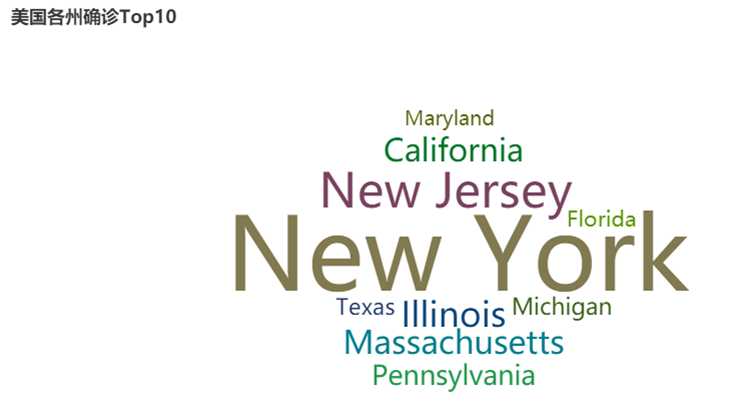
#4.画出美国确诊最多的10个州——>词云图
def drawChart_4(index):
root = "/home/hadoop/result/result" + str(index) +"/part-00000.json"
data = []
with open(root, 'r') as f:
while True:
line = f.readline()
if not line: # 到 EOF,返回空字符串,则终止循环
break
js = json.loads(line)
row=(str(js['state']),int(js['totalCases']))
data.append(row)
c = (
WordCloud()
.add("", data, word_size_range=[20, 100], shape=SymbolType.DIAMOND)
.set_global_opts(title_opts=opts.TitleOpts(title="美国各州确诊Top10"))
.render("/home/hadoop/result/result4/result1.html")
)
#5.画出美国死亡最多的10个州——>象柱状图
def drawChart_5(index):
root = "/home/hadoop/result/result" + str(index) +"/part-00000.json"
state = []
totalDeath = []
with open(root, 'r') as f:
while True:
line = f.readline()
if not line: # 到 EOF,返回空字符串,则终止循环
break
js = json.loads(line)
state.insert(0,str(js['state']))
totalDeath.insert(0,int(js['totalDeaths']))
c = (
PictorialBar()
.add_xaxis(state)
.add_yaxis(
"",
totalDeath,
label_opts=opts.LabelOpts(is_show=False),
symbol_size=18,
symbol_repeat="fixed",
symbol_offset=[0, 0],
is_symbol_clip=True,
symbol=SymbolType.ROUND_RECT,
)
.reversal_axis()
.set_global_opts(
title_opts=opts.TitleOpts(title="PictorialBar-美国各州死亡人数Top10"),
xaxis_opts=opts.AxisOpts(is_show=False),
yaxis_opts=opts.AxisOpts(
axistick_opts=opts.AxisTickOpts(is_show=False),
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(opacity=0)
),
),
)
.render("/home/hadoop/result/result5/result1.html")
)
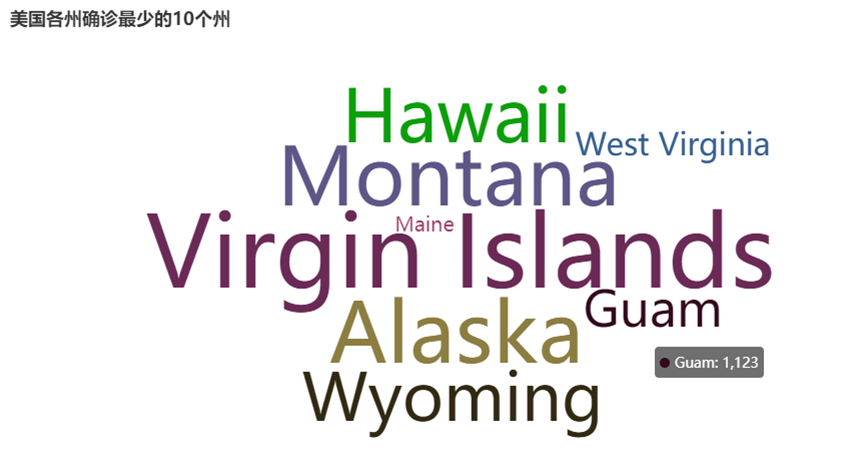
#6.找出美国确诊最少的10个州——>词云图
def drawChart_6(index):
root = "/home/hadoop/result/result" + str(index) +"/part-00000.json"
data = []
with open(root, 'r') as f:
while True:
line = f.readline()
if not line: # 到 EOF,返回空字符串,则终止循环
break
js = json.loads(line)
row=(str(js['state']),int(js['totalCases']))
data.append(row)
c = (
WordCloud()
.add("", data, word_size_range=[100, 20], shape=SymbolType.DIAMOND)
.set_global_opts(title_opts=opts.TitleOpts(title="美国各州确诊最少的10个州"))
.render("/home/hadoop/result/result6/result1.html")
)
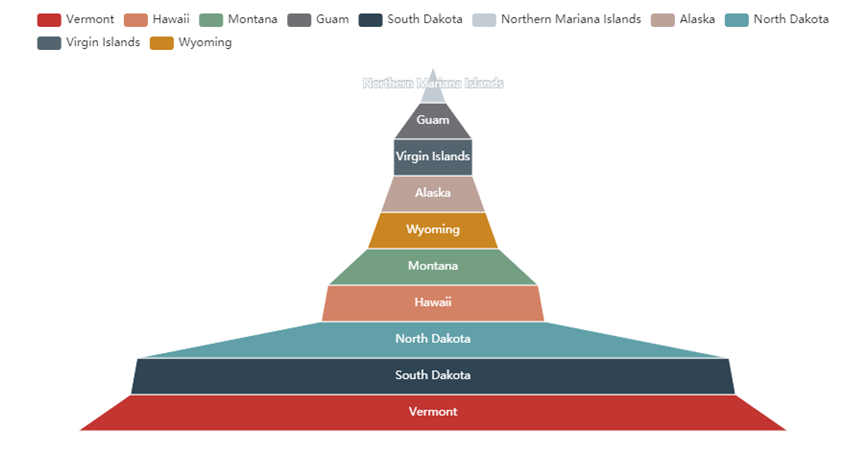
#7.找出美国死亡最少的10个州——>漏斗图
def drawChart_7(index):
root = "/home/hadoop/result/result" + str(index) +"/part-00000.json"
data = []
with open(root, 'r') as f:
while True:
line = f.readline()
if not line: # 到 EOF,返回空字符串,则终止循环
break
js = json.loads(line)
data.insert(0,[str(js['state']),int(js['totalDeaths'])])
c = (
Funnel()
.add(
"State",
data,
sort_="ascending",
label_opts=opts.LabelOpts(position="inside"),
)
.set_global_opts(title_opts=opts.TitleOpts(title=""))
.render("/home/hadoop/result/result7/result1.html")
)
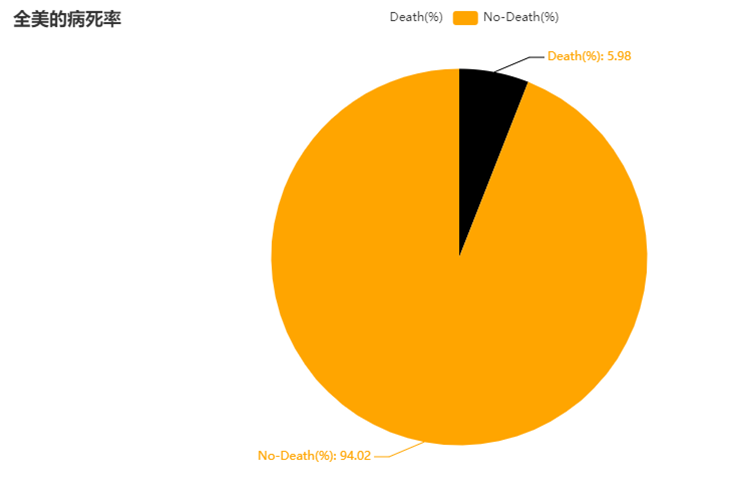
#8.美国的病死率--->饼状图
def drawChart_8(index):
root = "/home/hadoop/result/result" + str(index) +"/part-00000.json"
values = []
with open(root, 'r') as f:
while True:
line = f.readline()
if not line: # 到 EOF,返回空字符串,则终止循环
break
js = json.loads(line)
if str(js['state'])=="USA":
values.append(["Death(%)",round(float(js['deathRate'])*100,2)])
values.append(["No-Death(%)",100-round(float(js['deathRate'])*100,2)])
c = (
Pie()
.add("", values)
.set_colors(["blcak","orange"])
.set_global_opts(title_opts=opts.TitleOpts(title="全美的病死率"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
.render("/home/hadoop/result/result8/result1.html")
)
#可视化主程序:
index = 1
while index<9:
funcStr = "drawChart_" + str(index)
eval(funcStr)(index)
index+=1
2.结果图标展示
可视化结果是.html格式的,reslut1的结果展示图保存路径为“/home/hadoop/result/result1/result1.html”,reslut2的结果展示图保存路径为“/home/hadoop/result/result2/result1.html”,其余类似递推。具体截图如下:
(1)美国每日的累计确诊病例数和死亡数——>双柱状图
(2)美国每日的新增确诊病例数——>折线图
(3)美国每日的新增死亡病例数——>折线图

(4)截止5.19,美国各州累计确诊、死亡人数和病死率--->表格
(5)截止5.19,美国累计确诊人数前10的州--->词云图
(6)截止5.19,美国累计死亡人数前10的州--->象柱状图

(7)截止5.19,美国累计确诊人数最少的10个州--->词云图
(8)截止5.19,美国累计死亡人数最少的10个州--->漏斗图
(9)截止5.19,美国的病死率--->饼状图