
【版权声明】博客内容由厦门大学数据库实验室拥有版权,未经允许,请勿转载!
[返回Spark教程首页]
DataFrame的推出,让Spark具备了处理大规模结构化数据的能力,不仅比原有的RDD转化方式更加简单易用,而且获得了更高的计算性能。Spark能够轻松实现从MySQL到DataFrame的转化,并且支持SQL查询。
DataFrame与RDD的区别
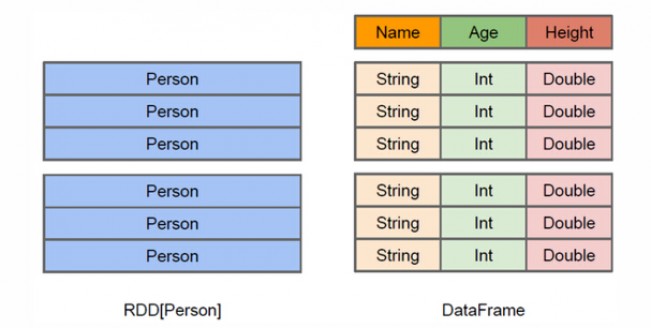
图 DataFrame与RDD的区别
从上面的图中可以看出DataFrame和RDD的区别。RDD是分布式的 Java对象的集合,比如,RDD[Person]是以Person为类型参数,但是,Person类的内部结构对于RDD而言却是不可知的。DataFrame是一种以RDD为基础的分布式数据集,也就是分布式的Row对象的集合(每个Row对象代表一行记录),提供了详细的结构信息,也就是我们经常说的模式(schema),Spark SQL可以清楚地知道该数据集中包含哪些列、每列的名称和类型。
和RDD一样,DataFrame的各种变换操作也采用惰性机制,只是记录了各种转换的逻辑转换路线图(是一个DAG图),不会发生真正的计算,这个DAG图相当于一个逻辑查询计划,最终,会被翻译成物理查询计划,生成RDD DAG,按照之前介绍的RDD DAG的执行方式去完成最终的计算得到结果。
DataFrame的创建
在进行Spark SQL编程之前,需要了解你当前安装的Spark是否包含Hive支持。Hive是基于Hadoop的数据仓库,可以让用户输入类似SQL语法的HiveQL语句,Hive会自动把HiveQL语句转换成底层的MapReduce任务去执行(要想了解更多数据仓库Hive的知识,可以参考厦门大学数据库实验室的Hive授课视频、Hive安装指南)。因为, 根据是否包含Hive支持,Spark提供了两个不同的入口,即HiveConext和SQLContext。
(1)SQLContext
SQLContext支持从不同的数据源加载数据,并把数据转换成DataFrame,并且支持把DataFrame转换成SQLContext自身中的表,然后使用SQL语句来操作数据。
(2)HiveContext
HiveContext继承自SQLContext。HiveConext提供了HiveQL以及其他依赖于Hive的功能的支持,而SQLContext则只支持Spark SQL功能的一个子集,那些依赖于Hive的功能则被排除在外。不过,需要注意的是,即使我们没有安装数据仓库Hive,我们也可以正常使用HiveContext。
那么,我们怎么知道当前安装的Spark是否包含Hive支持呢?一般来说,Hive在编译时可以包含Hive支持,也可以不包含Hive支持。本教程在前面的“Spark安装和使用”章节介绍的是,让大家下载二进制版本的Spark,这个版本在编译时已经包含了Hive支持。有了Hive支持以后,我们就可以访问Hive表,并且支持使用HiveQL查询语言。再次强调,让Spark包含Hive支持,并不需要我们事先安装Hive,只有当我们的Spark SQL程序需要访问Hive中的数据时(也就是借助于Hive实现数据存储时),才需要安装Hive。
下面我们就介绍如何使用SQLContext来创建DataFrame。
请进入Linux系统,打开“终端”,进入Shell命令提示符状态。
首先,请找到样例数据。 Spark已经为我们提供了几个样例数据,就保存在“/usr/local/spark/examples/src/main/resources/”这个目录下,这个目录下有两个样例数据people.json和people.txt。
people.json文件的内容如下:
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
people.txt文件的内容如下:
Michael, 29
Andy, 30
Justin, 19
下面我们就介绍如何从people.json文件中读取数据并生成DataFrame并显示数据(从people.txt文件生成DataFrame需要后面将要介绍的另外一种方式)。
请使用如下命令打开spark-shell:
cd /usr/local/spark
./bin/spark-shell
进入到spark-shell状态后执行下面命令:
scala> import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.SQLContext
scala> val sqlContext = new SQLContext(sc)
sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@4a65c40
scala> val df = sqlContext.read.json("file:///usr/local/spark/examples/src/main/resources/people.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> df.show()
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
现在,我们可以执行一些常用的DataFrame操作。
//打印模式信息
scala> df.printSchema()
root
|-- age: long (nullable = true)
|-- name: string (nullable = true)
//选择多列
scala> df.select(df("name"),df("age")+1).show()
+-------+---------+
| name|(age + 1)|
+-------+---------+
|Michael| null|
| Andy| 31|
| Justin| 20|
+-------+---------+
//条件过滤
scala> df.filter(df("age") > 20 ).show()
+---+----+
|age|name|
+---+----+
| 30|Andy|
+---+----+
//分组聚合
scala> df.groupBy("age").count().show()
+----+-----+
| age|count|
+----+-----+
|null| 1|
| 19| 1|
| 30| 1|
+----+-----+
//排序
scala> df.sort(df("age").desc).show()
+----+-------+
| age| name|
+----+-------+
| 30| Andy|
| 19| Justin|
|null|Michael|
+----+-------+
//多列排序
scala> df.sort(df("age").desc, df("name").asc).show()
+----+-------+
| age| name|
+----+-------+
| 30| Andy|
| 19| Justin|
|null|Michael|
+----+-------+
//对列进行重命名
scala> df.select(df("name").as("username"),df("age")).show()
+--------+----+
|username| age|
+--------+----+
| Michael|null|
| Andy| 30|
| Justin| 19|
+--------+----+
从RDD转换得到DataFrame
Spark官网提供了两种方法来实现从RDD转换得到DataFrame,第一种方法是,利用反射来推断包含特定类型对象的RDD的schema;第二种方法是,使用编程接口,构造一个schema并将其应用在已知的RDD上。
利用反射机制推断RDD模式
在利用反射机制推断RDD模式时,需要首先定义一个case class,因为,只有case class才能被Spark隐式地转换为DataFrame。
下面是在spark-shell中执行命令以及反馈的信息:
scala> import org.apache.spark.sql.SQLContext
scala> val sqlContext = new SQLContext(sc)
scala> import sqlContext.implicits._ //导入包,支持把一个RDD隐式转换为一个DataFrame
import sqlContext.implicits._
scala> case class Person(name: String, age: Int) //定义一个case class
defined class Person
scala> val people = sc.textFile("file:///usr/local/spark/examples/src/main/resources/people.txt").map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)).toDF()
16/11/15 11:19:18 INFO spark.SparkContext: Created broadcast 17 from textFile at <console>:37
people: org.apache.spark.sql.DataFrame = [name: string, age: int]
scala> people.registerTempTable("peopleTempTab") //必须注册为临时表才能供下面的查询使用
scala> val personsRDD = sqlContext.sql("select name,age from peopleTempTab where age > 20").rdd //最终生成一个RDD
personsRDD: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[43] at rdd at <console>:35
//从上面的信息可以看出,生成的RDD的每个元素的类型是org.apache.spark.sql.Row
scala> personsRDD.foreach(t => println("Name:"+t(0),"Age:"+t(1))) //RDD中的每个元素都是一行记录,包含name和age两个字段,分别用t(0)和t(1)来获取值
(Name:Michael,Age:29)
(Name:Andy,Age:30)
使用编程方式定义RDD模式
当无法提前定义case class时,就需要采用编程方式定义RDD模式。
scala> import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.SQLContext
scala> val sqlContext = new SQLContext(sc)
sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@5f7bd970
scala> val people = sc.textFile("file:///usr/local/spark/examples/src/main/resources/people.txt")
people: org.apache.spark.rdd.RDD[String] = file:///usr/local/spark/examples/src/main/resources/people.txt MapPartitionsRDD[1] at textFile at <console>:28
scala> val schemaString = "name age" //定义一个模式字符串
schemaString: String = name age
scala> import org.apache.spark.sql.Row
import org.apache.spark.sql.Row
scala> import org.apache.spark.sql.types.{StructType,StructField,StringType}
import org.apache.spark.sql.types.{StructType, StructField, StringType}
scala> val schema = StructType( schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, true))) //根据模式字符串生成模式
schema: org.apache.spark.sql.types.StructType = StructType(StructField(name,StringType,true), StructField(age,StringType,true))
//从上面信息可以看出,schema描述了模式信息,模式中包含name和age两个字段
scala> val rowRDD = people.map(_.split(",")).map(p => Row(p(0), p(1).trim)) //对people这个RDD中的每一行元素都进行解析
rowRDD: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[3] at map at <console>:32
scala> val peopleDataFrame = sqlContext.createDataFrame(rowRDD, schema)
peopleDataFrame: org.apache.spark.sql.DataFrame = [name: string, age: string]
scala> peopleDataFrame.registerTempTable("peopleTempTab") //必须注册为临时表才能供下面查询使用
scala> val personsRDD = sqlContext.sql("select name,age from peopleTempTab where age > 20").rdd
personsRDD: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[7] at rdd at <console>:32
scala> personsRDD.foreach(t => println("Name:"+t(0)+",Age:"+t(1)))
(Name:Michael,Age:29)
(Name:Andy,Age:30)
在上面的代码中,people.map(_.split(","))实际上和people.map(line => line.split(","))这种表述是等价的,作用是对people这个RDD中的每一行元素都进行解析。比如如,people这个RDD的第一行是:
Michael, 29
这行内容经过people.map(_.split(","))操作后,就得到一个集合{Michael,29}。后面经过map(p => Row(p(0), p(1).trim))操作时,这时的p就是这个集合{Michael,29},这时p(0)就是Micheael,p(1)就是29,map(p => Row(p(0), p(1).trim))就会生成一个Row对象,这个对象里面包含了两个字段的值,这个Row对象就构成了rowRDD中的其中一个元素。因为people有3行文本,所以,最终,rowRDD中会包含3个元素,每个元素都是org.apache.spark.sql.Row类型。实际上,Row对象只是对基本数据类型(比如整型或字符串)的数组的封装,本质就是一个定长的字段数组。
peopleDataFrame = sqlContext.createDataFrame(rowRDD, schema),这条语句就相当于建立了rowRDD数据集和模式之间的对应关系,从而我们就知道对于rowRDD的每行记录,第一个字段的名称是schema中的“name”,第二个字段的名称是schema中的“age”。
把RDD保存成文件
这里介绍如何把RDD保存成文本文件,后面还会介绍其他格式的保存。
进入spark-shell执行下面命令:
scala> import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.SQLContext
scala> val sqlContext = new SQLContext(sc)
sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@4a65c40
scala> val df = sqlContext.read.json("file:///usr/local/spark/examples/src/main/resources/people.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> df.rdd.saveAsTextFile("file:///usr/local/spark/mycode/newpeople.txt")
可以看出,我们是把DataFrame转换成RDD,然后调用saveAsTextFile()保存成文本文件。在后面小节中,我们还会介绍其他保存方式。
上述过程执行结束后,可以打开第二个终端窗口,在Shell命令提示符下查看新生成的newpeople.txt:
cd /usr/local/spark/mycode/
ls
可以看到/usr/local/spark/mycode/这个目录下面有个newpeople.txt文件夹(注意,不是文件),这个文件夹中包含下面两个文件:
part-00000
_SUCCESS
不用理会_SUCCESS这个文件,只要看一下part-00000这个文件,可以用vim编辑器打开这个文件查看它的内容,该文件内容如下:
[null,Michael]
[30,Andy]
[19,Justin]
如果我们要再次把newpeople.txt中的数据加载到RDD中,可以直接使用newpeople.txt目录名称,而不需要使用part-00000文件,如下:
scala> val textFile = sc.textFile("file:///usr/local/spark/mycode/newpeople.txt")
textFile: org.apache.spark.rdd.RDD[String] = file:///usr/local/spark/mycode/newpeople.txt MapPartitionsRDD[11] at textFile at <console>:28
scala> textFile.foreach(println)
[null,Michael]
[30,Andy]
[19,Justin]
读取和保存数据
Spark SQL可以支持Parquet、JSON、Hive等数据源,并且可以通过JDBC连接外部数据源。前面的介绍中,我们已经涉及到了JSON、文本格式的加载,这里不再赘述。这里介绍Parquet和JDBC数据库连接。
Parquet
Parquet是一种流行的列式存储格式,可以高效地存储具有嵌套字段的记录。Parquet是语言无关的,而且不与任何一种数据处理框架绑定在一起,适配多种语言和组件,能够与Parquet配合的组件有:
* 查询引擎: Hive, Impala, Pig, Presto, Drill, Tajo, HAWQ, IBM Big SQL
* 计算框架: MapReduce, Spark, Cascading, Crunch, Scalding, Kite
* 数据模型: Avro, Thrift, Protocol Buffers, POJOs
Spark已经为我们提供了parquet样例数据,就保存在“/usr/local/spark/examples/src/main/resources/”这个目录下,有个users.parquet文件,这个文件格式比较特殊,如果你用vim编辑器打开,或者用cat命令查看文件内容,肉眼是一堆乱七八糟的东西,是无法理解的。只有被加载到程序中以后,Spark会对这种格式进行解析,然后我们才能理解其中的数据。
下面代码演示了如何从parquet文件中加载数据生成DataFrame。
scala> import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.SQLContext
scala> val sqlContext = new SQLContext(sc)
sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@35f18100
scala> val users = sqlContext.read.load("file:///usr/local/spark/examples/src/main/resources/users.parquet")
users: org.apache.spark.sql.DataFrame = [name: string, favorite_color: string, favorite_numbers: array<int>]
scala> users.registerTempTable("usersTempTab")
scala> val usersRDD =sqlContext.sql("select * from usersTempTab").rdd
usersRDD: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[13] at rdd at <console>:34
scala> usersRDD.foreach(t=>println("name:"+t(0)+" favorite color:"+t(1)))
name:Alyssa favorite color:null
name:Ben favorite color:red
下面介绍如何将DataFrame保存成parquet文件。
进入spark-shell执行下面命令:
scala> import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.SQLContext
scala> val sqlContext = new SQLContext(sc)
sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@4a65c40
scala> val df = sqlContext.read.json("file:///usr/local/spark/examples/src/main/resources/people.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> df.select("name","age").write.format("parquet").save("file:////usr/local/spark/examples/src/main/resources/newpeople.parquet")
上述过程执行结束后,可以打开第二个终端窗口,在Shell命令提示符下查看新生成的newpeople.parquet:
cd /usr/local/spark/examples/src/main/resources/
ls
上面命令执行后,可以看到"/usr/local/spark/examples/src/main/resources/"这个目录下多了一个newpeople.parquet,不过,注意,这不是一个文件,而是一个目录(不要被newpeople.parquet中的圆点所迷惑,文件夹名称也可以包含圆点),也就是说,df.select("name","age").write.format("parquet").save()括号里面的参数是文件夹,不是文件名。下面我们可以进入newpeople.parquet目录,会发现下面4个文件:
_common_metadata
_metadata
part-r-00000-ad565c11-d91b-4de7-865b-ea17f8e91247.gz.parquet
_SUCCESS
这4个文件都是刚才保存生成的。现在问题来了,如果我们要再次把这个刚生成的数据又加载到DataFrame中,应该加载哪个文件呢?很简单,只要加载newpeople.parquet目录即可,而不是加载这4个文件,语句如下:
val users = sqlContext.read.load("file:///usr/local/spark/examples/src/main/resources/newpeople.parquet")
通过JDBC连接数据库
这里以关系数据库MySQL为例。首先,请参考厦门大学数据库实验室博客教程(Ubuntu安装MySQL),在Linux系统中安装好MySQL数据库。这里假设你已经成功安装了MySQL数据库。下面我们要新建一个测试Spark程序的数据库,数据库名称是“spark”,表的名称是“student”。
请执行下面命令在Linux中启动MySQL数据库,并完成数据库和表的创建,以及样例数据的录入:
service mysql start
mysql -u root -p
//屏幕会提示你输入密码
输入密码后,你就可以进入“mysql>”命令提示符状态,然后就可以输入下面的SQL语句完成数据库和表的创建:
mysql> create database spark;
mysql> use spark
mysql> create table student (id int(4), name char(20), gender char(4), age int(4));
mysql> insert into student values(1,'Xueqian','F',23);
mysql> insert into student values(2,'Weiliang','M',24);
mysql> select * from student;
上面已经创建好了我们所需要的MySQL数据库和表,下面我们编写Spark应用程序连接MySQL数据库并且读写数据。
Spark支持通过JDBC方式连接到其他数据库获取数据生成DataFrame。
首先,请进入Linux系统(本教程统一使用hadoop用户名登录),打开火狐(FireFox)浏览器,下载一个MySQL的JDBC驱动(下载)。在火狐浏览器中下载时,一般默认保存在hadoop用户的当前工作目录的“下载”目录下,所以,可以打开一个终端界面,输入下面命令查看:
cd ~
cd 下载
就可以看到刚才下载到的MySQL的JDBC驱动程序,文件名称为mysql-connector-java-5.1.40.tar.gz(你下载的版本可能和这个不同)。现在,使用下面命令,把该驱动程序拷贝到spark的安装目录下:
sudo tar -zxf ~/下载/mysql-connector-java-5.1.40.tar.gz -C /usr/local/spark
cd /usr/local/spark
ls
这时就可以在/usr/local/spark目录下看到这个驱动程序文件所在的文件夹mysql-connector-java-5.1.40,进入这个文件夹,就可以看到驱动程序文件mysql-connector-java-5.1.40-bin.jar。
请输入下面命令启动已经安装在Linux系统中的mysql数据库(如果前面已经启动了MySQL数据库,这里就不用重复启动了)。
service mysql start
下面,我们要启动一个spark-shell,而且启动的时候,要附加一些参数。启动Spark Shell时,必须指定mysql连接驱动jar包。
cd /usr/local/spark
./bin/spark-shell \
--jars /usr/local/spark/mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar \
--driver-class-path /usr/local/spark/mysql-connector-java-5.1.40-bin.jar
上面的命令行中,在一行的末尾加入斜杠\,是为了告诉spark-shell,命令还没有结束。
启动进入spark-shell以后,可以执行以下命令连接数据库,读取数据,并显示:
scala> import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.SQLContext
scala> val sqlContext = new SQLContext(sc)
sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@6e54bef6
scala> val jdbcDF = sqlContext.read.format("jdbc").options(Map("url" -> "jdbc:mysql://localhost:3306/spark", "driver" -> "com.mysql.jdbc.Driver", "dbtable" -> "student", "user" -> "root", "password" -> "hadoop")).load()
Tue Nov 15 21:46:29 CST 2016 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification.
jdbcDF: org.apache.spark.sql.DataFrame = [id: int, name: string, gender: string, age: int]
scala> jdbcDF.show()
+---+--------+------+---+
| id| name|gender|age|
+---+--------+------+---+
| 1| Xueqian| F| 23|
| 2|Weiliang| M| 24|
+---+--------+------+---+
下面我们再来看一下如何往MySQL中写入数据。
为了看到MySQL数据库在Spark程序执行前后发生的变化,我们先在Linux系统中新建一个终端,使用下面命令查看一下MySQL数据库中的数据库spark中的表student的内容:
service mysql start //如果前面已经启动MySQL数据库,这里不用再执行这条命令
mysql -u root -p
执行上述命令后,屏幕上会提示你输入MySQL数据库密码,我们这里给数据库设置的用户是root,密码是hadoop。
因为之前我们已经在MySQL数据库中创建了一个名称为spark的数据库,并创建了一个名称为student的表,现在查看一下:
mysql> use spark
mysql> select * from student;
//上面命令执行后返回下面结果
+------+----------+--------+------+
| id | name | gender | age |
+------+----------+--------+------+
| 1 | Xueqian | F | 23 |
| 2 | Weiliang | M | 24 |
+------+----------+--------+------+
现在我们开始在spark-shell中编写程序,往spark.student表中插入两条记录。
下面,我们要启动一个spark-shell,而且启动的时候,要附加一些参数。启动Spark Shell时,必须指定mysql连接驱动jar包(如果你前面已经采用下面方式启动了spark-shell,就不需要重复启动了):
cd /usr/local/spark
./bin/spark-shell \
--jars /usr/local/spark/mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar \
--driver-class-path /usr/local/spark/mysql-connector-java-5.1.40-bin.jar
上面的命令行中,在一行的末尾加入斜杠\,是为了告诉spark-shell,命令还没有结束。
启动进入spark-shell以后,可以执行以下命令连接数据库,写入数据,程序如下(你可以把下面程序一条条拷贝到spark-shell中执行):
import java.util.Properties
import org.apache.spark.sql.{SQLContext, Row}
import org.apache.spark.sql.types.{StringType, IntegerType, StructField, StructType}
val sqlContext = new SQLContext(sc)
//下面我们设置两条数据表示两个学生信息
val studentRDD = sc.parallelize(Array("3 Rongcheng M 26","4 Guanhua M 27")).map(_.split(" "))
//下面要设置模式信息
val schema = StructType(List(StructField("id", IntegerType, true),StructField("name", StringType, true),StructField("gender", StringType, true),StructField("age", IntegerType, true)))
//下面创建Row对象,每个Row对象都是rowRDD中的一行
val rowRDD = studentRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).trim, p(3).toInt))
//建立起Row对象和模式之间的对应关系,也就是把数据和模式对应起来
val studentDataFrame = sqlContext.createDataFrame(rowRDD, schema)
//下面创建一个prop变量用来保存JDBC连接参数
val prop = new Properties()
prop.put("user", "root") //表示用户名是root
prop.put("password", "hadoop") //表示密码是hadoop
prop.put("driver","com.mysql.jdbc.Driver") //表示驱动程序是com.mysql.jdbc.Driver
//下面就可以连接数据库,采用append模式,表示追加记录到数据库spark的student表中
studentDataFrame.write.mode("append").jdbc("jdbc:mysql://localhost:3306/spark", "spark.student", prop)
在spark-shell中执行完上述程序后,我们可以看一下效果,看看MySQL数据库中的spark.student表发生了什么变化。请在刚才的另外一个窗口的MySQL命令提示符下面继续输入下面命令:
mysql> select * from student;
+------+-----------+--------+------+
| id | name | gender | age |
+------+-----------+--------+------+
| 1 | Xueqian | F | 23 |
| 2 | Weiliang | M | 24 |
| 3 | Rongcheng | M | 26 |
| 4 | Guanhua | M | 27 |
+------+-----------+--------+------+

