
【版权声明】版权所有,严禁转载,严禁用于商业用途,侵权必究。
作者:厦门大学信息学院2021级研究生 胡健龙
基于Scala语言的Spark数据处理分析案例
案例制作:厦门大学数据库实验室
指导老师:厦门大学信息学院计算机系数据库实验室 林子雨 博士/副教授 E-mail: ziyulin@xmu.edu.cn
相关教材:林子雨,赖永炫,陶继平《Spark编程基础(Scala版)》(访问教材官网)
【查看基于Scala语言的Spark数据分析案例集锦】
一、实验环境
Ubuntu 22.04 LTS(arm64)# Linux
Hadoop 3.1.3
Spark 3.2.0
python 3.8
pandas(1.3.5) # python第三方库
matplotlib(3.2.2) # python第三方库
wordcloud(1.5.0) # python第三方库
seaborn(0.11.2) # python第三方库
二、数据说明
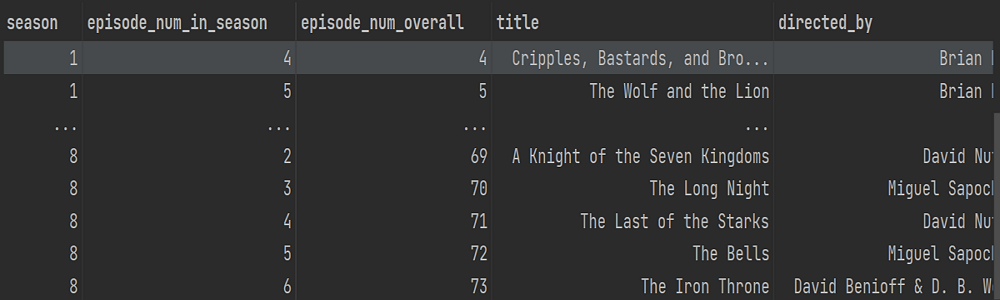
本次实验所使用的数据集名称为“Game of Thrones Episodes”,也就是美剧《权力的游戏》剧集的数据,可以直接从百度网盘下载(提取码:ziyu),这个数据集包括两张csv表(game_of_thrones_episodes.csv以及game_of_thrones_imdb.csv),第一张表包括以下的字段:“season”(表示第几季),“episode_num_in_season”(表示第几季中的第几集),“episode_num_overall”,表示在整部剧中是第几集,“title”(剧集的标题),“directed_by”(剧集的导演),“written_by”剧集的作者,“original_air_date”(预定播出时间),“us_viewers”(美国地区的观看人数)。
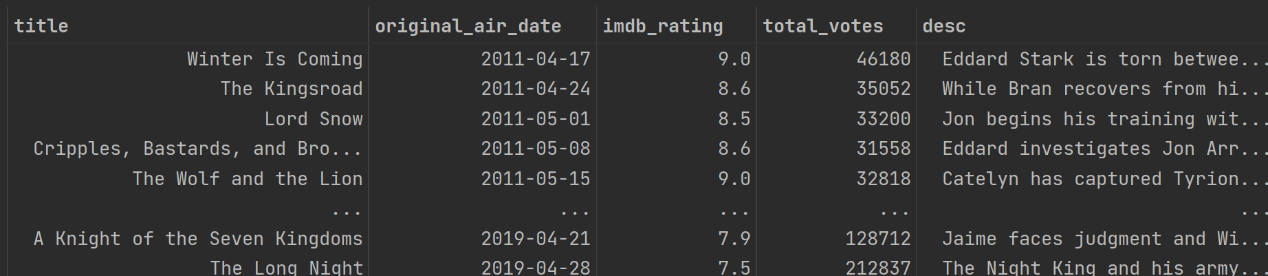
第二张表包括以下几个字段:“season”(表示第几季),“episode_num”(表示第几季中的第几集),“title”(剧集的标题),“original_air_date”(预定播出时间),“imdb_rating”(平均的IMDb 评级,IMDb是一个关于电影演员、电影、电视节目、电视明星和电影制作的在线数据库),“total_votes”,参与评分的人数,“desc”(剧集的主要内容描述)。
三、数据预处理
为了后续数据分析的方便,对数据进行预处理,这里很自然的操作就是将这两张csv进行合并。使用pandas的read_csv方法分别读入两张csv表:
episodes_data=pandas.read_csv('./数据集/game_of_thrones_episodes.csv', parse_dates=['original_air_date'])
# 这里的parse_dates是把日期数据转为一致的数据类型
imdb_data=pandas.read_csv('./数据集/game_of_thrones_imdb.csv', parse_dates=['original_air_date'])接下来为了合并两张表首先取出imdb表中的部分字段,然后和episodes表进行合并, 之后对合并后的数据表进行保存:
imdb_data=imdb_data[['title','original_air_date','imdb_rating','total_votes', 'desc']]
total_data=episodes_data.merge(imdb_data,how='left',on=['title','original_air_date'])
total_data.to_csv('./数据集/game_of_thrones.csv', encoding='utf8', index=False)四、Spark数据分析
首先进入到Hadoop目录下(cd /usr/local/Hadoop),启动hdfs(./sbin/start-dfs.sh)并将数据表保存到hdfs(./bin/hdfs dfs -put /home/hadoop/Documents/game_of_thrones.csv)。
启动scala shell交互式编程环境(cd/usr/local/spark bin/spark-shell)。
1) 读入CSV文件创建Dataframe
通过代码spark.read.format("csv").option("header", "True").load()
2) 对desc字段进行词频统计以及数据可视化
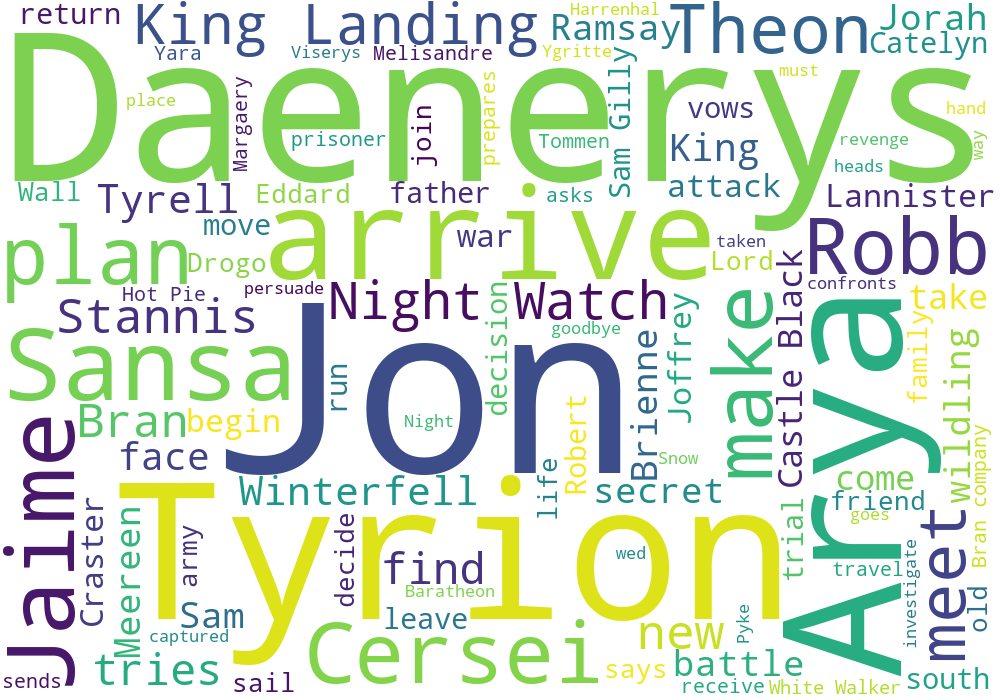
game_of_thrones.csv文件中的desc字段是剧集的总结描述,通过对这一列的数据进行分词,然后进行词频统计,根据词频就可以绘出词云图,就能够很直观地得知剧集中出现的主要人物的名字。
为了方便分析,首先提取出desc这一列(val desc_df = data_df.select(data_df("desc"))),然后使用flatMap方法对每一行的数据以空格进行拆分,从而得到新的dataframe对象(var words = descdf.flatMap(.getString(0).split(" ")).toDF())。
接下来根据value字段进行分组聚合,然后使用count方法计数,再根据计数结果降序排序,就可以直观地看到词频了。
words.groupBy("value").count().orderBy($"count".desc) 但还需要注意的一个地方是有很多词比如连词、代词等是没有意义的,也就是停用词,所以需要进行一些停用词的过滤:
words.filter(!$"value".equalTo("the")&&!$"value".equalTo("The")
&& ! $"value".equalTo("a") && ! $"value".equalTo("A")
&& ! $"value".equalTo("an") && ! $"value".equalTo("An")
&& ! $"value".equalTo("as") && ! $"value".equalTo("from")
&& ! $"value".equalTo("is") && ! $"value".equalTo("are")
&& ! $"value".equalTo("and") && ! $"value".equalTo("has")
&& ! $"value".equalTo("with") && ! $"value".equalTo("to")
&& ! $"value".equalTo("of") && ! $"value".equalTo("for")
&& ! $"value".equalTo("at") && ! $"value".equalTo("in")
&&!$"value".equalTo("his")&&!$"value".equalTo("her")).toDF()之后使用.write.option("header", "true").csv()方法将结果保存为csv文件方便后续数据可视化处理。
这里使用wordcloud包来生成词云
import wordcloud
# 读取文本
with open("./数据集/desc.txt",encoding="utf-8") as f:
s = f.read()
wc=wordcloud.WordCloud(width=1000,height=700,background_color='white',max_words=100)
wc.generate(s) # 加载词云文本
wc.to_file("word_cloud_result.png") # 保存词云文件从结果可以看出,剧中的主角Jon和龙妈Daenerys的名字很显眼。
3) 对每一季的观看人数、IMDb评分还有参与评分的人数进行分析
我们首先从数据表中选取season、us_viewers、imdb_rating、total_votes这四列,并且定义好各列的数据类型:
val season_df = data_df.select(data_df("season").cast("int"),
data_df("us_viewers").cast("int"),data_df("imdb_rating").cast("float")
,data_df("total_votes").cast("int"))接下来我们按照season进行分组聚合,然后计算出其他三列的平均值:
同样地,我们将结果保存为csv文件,使用python的seaborn包进行数据可视化。
import pandas
import matplotlib.pyplot as plt
import seaborn as sns
season_avgdata = pandas.read_csv('./数据集/season_avgdata.csv')
sns.lineplot(x="season", y="avg(us_viewers)", data=season_avgdata)首先来看每一季的观看人数的变化趋势(使用折线图):
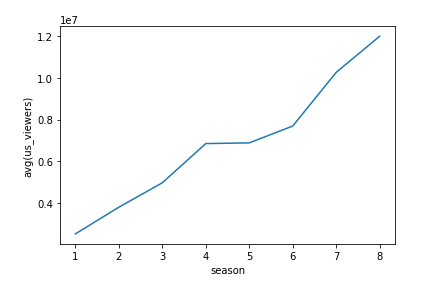
随着时间推移,观看该剧的人数越来越多,说明了该剧越来越火。
然后来看投票人数,同样地,这也反映了这部剧的火爆程度。
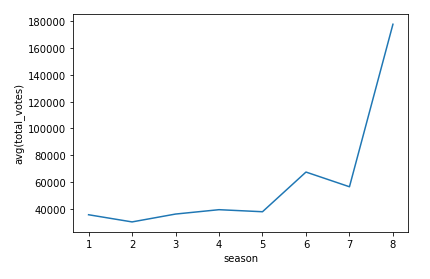
从这个折线图中看出,前7季的剧集的参与评价的人数都在稳步上升,而到了第8季时突然上升到了最高点,根据网上公开信息显示,《权力的游戏》前7季都是逐年放送的,而第8季时隔两年才放送,同时第8季也是整个剧集系列的最后一季,因此热度突然变得的那么高也有一定的原因。
接下来看剧集的评价:
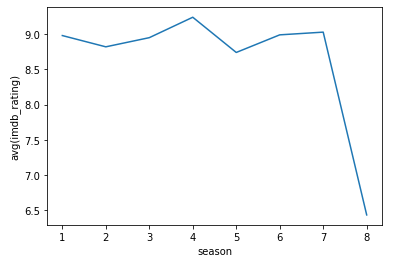
可以看出这部剧在第4季时候评价达到了顶峰,到了第7季也还不错,但到了第8季的评价就断崖式下跌了,可以很直观的看出这部剧烂尾了。
4) 分析不同的导演和评分的关系
首先从数据表中选取directed_by、imdb_rating这两列,
val director_df = data_df.select(data_df("directed_by"), data_df("imdb_rating").cast("float"))然后按照directed_by这一列进行聚合,计算评分的平均值,排序,
val director_avgdata = director_df.groupBy("directed_by").
mean("imdb_rating").orderBy($"avg(imdb_rating)".desc).toDF()即可直观地看出不同的导演拍摄的剧集的平均得分,使用柱状图进行表示:
import pandas
import seaborn as sns
director_avgdata = pandas.read_csv('director_avgdata.csv')
sns.barplot(director_avgdata['directed_by'], director_avgdata['avg(imdb_rating)'])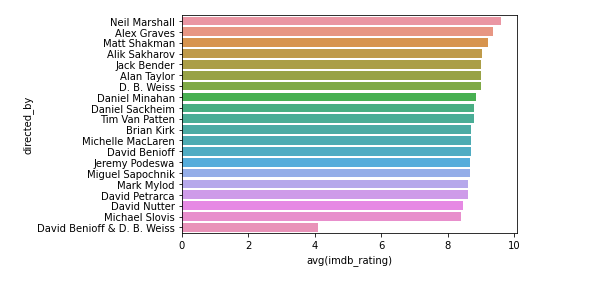
可以看出,其中David Benioff & D.B.Weiss这个导演的平均得分是最低的,其他的导演导演的剧集得分都差不多。
再来看看各个导演所导演的剧集的占比,对数据表中的directed_by这一列分组聚合后进行count()计数:
director_df.groupBy("directed_by").count().orderBy($"count".desc)
使用饼图进行可视化,python代码为:
director_countdata = pandas.read_csv('./数据集/director_countdata.csv')
plt.pie(x=director_countdata['count'], labels=director_countdata['directed_by'])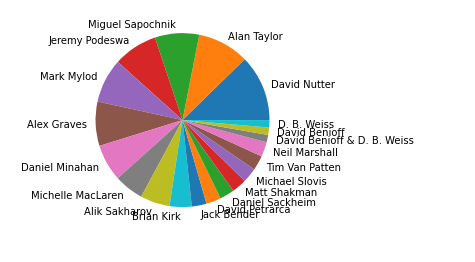
可以看出执导最多的导演是David Nutter。
5) 分析不同作者和评分的关系
和分析不同导演与评分的关系的分析类似,首先选取written_by、imdb_rating这两列,之后根据written_by这列进行分组聚合,计算imdb_rating的平均,这样就得到了不同剧集的作者的平均得分。
data_df.select(data_df("written_by"),data_df("imdb_rating").cast("float"))
print(writer_df.show())
val writer_avgdata = writer_df.groupBy("written_by").
mean("imdb_rating").orderBy($"avg(imdb_rating)".desc).toDF()还是以柱状图的形式可视化:
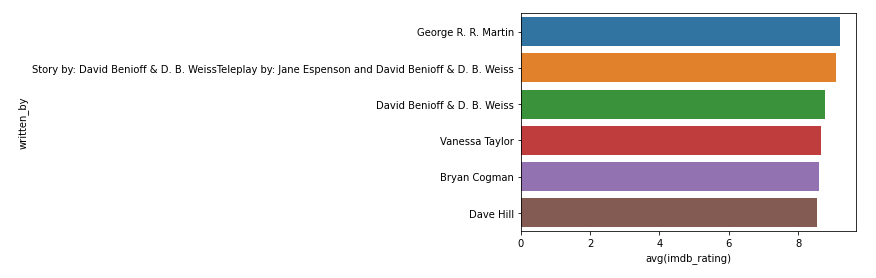
可以看出剧本本身是没有问题的,各个作者的剧集的得分都差不多(可以看到最高分就是原著作者George R.R Martin)
再来看看每位作者所写作的剧本在整个剧集中占了多大比重:
writer_df.groupBy("written_by").count().orderBy($"count".desc)
writer_countdata.write.option("header", "true").csv("file:///home/hadoop/Documents/writer_countdata.csv")以饼图的形式进行可视化:
writer_countdata = pandas.read_csv('./数据集/writer_countdata.csv')
plt.pie(x=writer_countdata['count'], labels=writer_countdata['written_by'])
可以看出,大部分剧集是由David Benioff&D.BWeiss写的,这两位也是这部剧集的总编剧。
6) 整部剧评分最高的剧集和评分最低的剧集
val first_video_msg = data_df.orderBy($"imdb_rating".desc).first()
println(first_video_msg)
val last_video_msg = data_df.orderBy("imdb_rating").first()
println(last_video_msg)
可以看出,评分最高的是第3季第9集,“The rains of Castamere”,最低的是第8季第6集,“The Iron Throne”。