【版权声明】版权所有,严禁转载,严禁用于商业用途,侵权必究。
作者:厦门大学信息学院2021级研究生 杜晓雄
基于Scala语言的Spark数据处理分析案例
案例制作:厦门大学数据库实验室
指导老师:厦门大学信息学院计算机系数据库实验室 林子雨 博士/副教授 E-mail: ziyulin@xmu.edu.cn
相关教材:林子雨,赖永炫,陶继平《Spark编程基础(Scala版)》(访问教材官网)
【查看基于Scala语言的Spark数据分析案例集锦】
一、实验概述
1.实验环境
本次实验主要通过综合运用大数据处理框架 Spark、 Hadoop及数据可视化技术,对数据进行存储、处理和分析,实验的主要环境配置及其版本信息如下:
(1)操作系统Linux:Ubuntu16.04
(2)Hadoop:3.1.3
(3)Spark:3.2.0
(4)Python:3.6.9
(5)Scala:2.12.15
(6)IntelliJ IDEA:2022.1
其中,Hadoop安装参考教程,Spark安装教程参考。
2.数据说明
实验数据来源于kaggle的coffee chain,可以直接从百度网盘下载(提取码:ziyu),共有数据4248条。其数据字典如下:
Area Code Ddate Market Market Size Product Product Type State Type Budget Cogs Budget Margin
区号 统计日期 市场位置 市场规模 产品 产品类别 所在州 产品属性 预算成本 预算盈余
Budget Profit Budget Sales Coffee Sales Cogs Inventory Margin Marketing Number of Records Profit Total Expenses
利润预算 销售预算 实际销售 实际成本 库存 实际盈余 销售量 记录数 实际利润 其他成本
3.内容概述
本次实验的主要内容如下:
(1)对数据集进行数据预处理,删除冗余列,将数据保存在本地。
(2)使用 Spark 对数据进行分析。
(3)对分析结果进行可视化呈现,如汇总数据可视化等,使用的语言为Python。
二、数据预处理
预处理分析
通过查看数据集介绍,并且实际考察数据集,发现其中并无脏数据,但是有冗余列,并且只有一个冗余列,为了最大化效率,我直接在excel中手动删除该冗余列。
其读取路径为:“file:///home/hadoop/桌面/CoffeeChain.csv”。
三、数据分析
1. 查看咖啡销售量排名。
(1)读入coffee_chain.csv。
(2)将选取的数据按照销售量降序排列。
(3)将结果存入文件。
# 读入csv文件,读取完后df的类型为dataframe
val filePath=“file:///home/hadoop/桌面/CoffeeChain.csv”
val df=spark.read.options(
Map("inferSchema"->"true","delimiter"->",","header"->"true")).csv(filePath)
# 创建表用于sql查询
df.createOrReplaceTempView("coffee")
# 执行查询
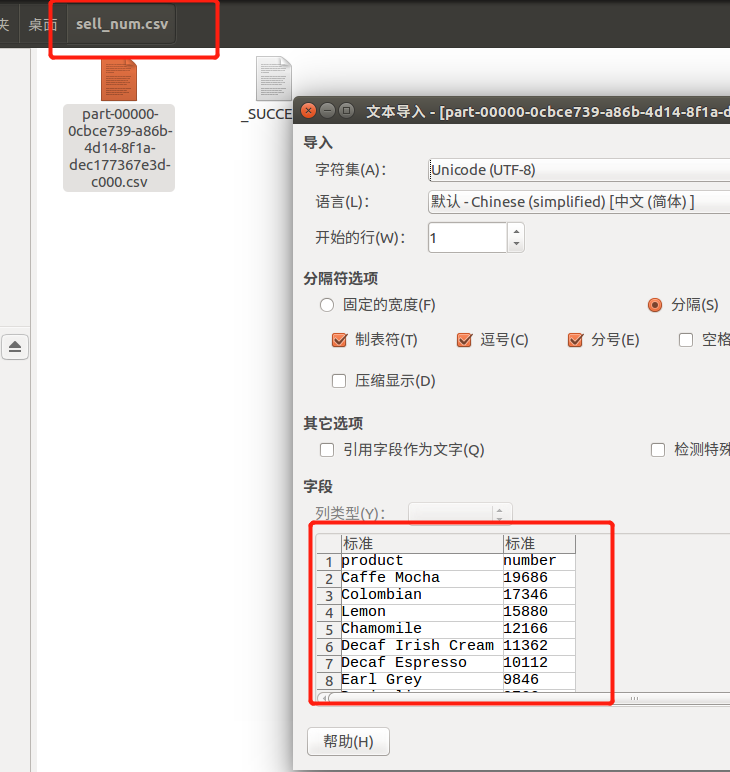
val b = spark.sql("select product,sum(Marketing) as number from coffee group by product order by number desc")
# 保存文件为sell_num.csv
b.write.option("header",true).csv("file:///home/hadoop/桌面/sell_num.csv")以下为运行截图:

2. 观察咖啡销售量的分布情况
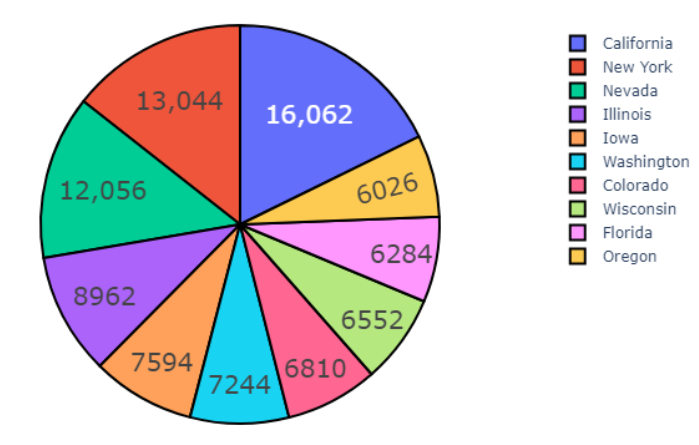
(1)查询咖啡销售量和state的关系。
代码如下:
# 读入csv文件,读取完后df的类型为dataframe
val filePath=“file:///home/hadoop/桌面/CoffeeChain.csv”
val df=spark.read.options(
Map("inferSchema"->"true","delimiter"->",","header"->"true")).csv(filePath)
# 创建表用于sql查询
df.createOrReplaceTempView("coffee")
# 执行查询
val b = spark.sql("select market,state,sum(Marketing) as number from coffee group by state,market order by number desc")
# 保存文件为csv
b.write.option("header",true).csv("file:///home/hadoop/桌面/state_sell_num.csv")以下为运行截图:
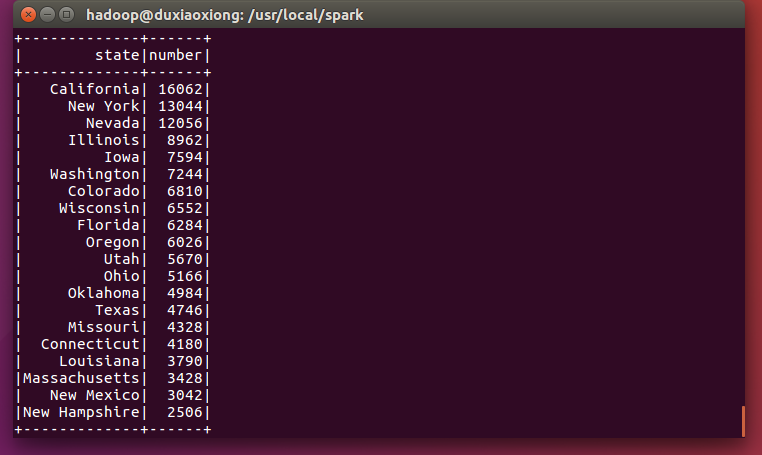
可以发现,比较有钱的城市(加利福尼亚和纽约)最喜欢喝咖啡。
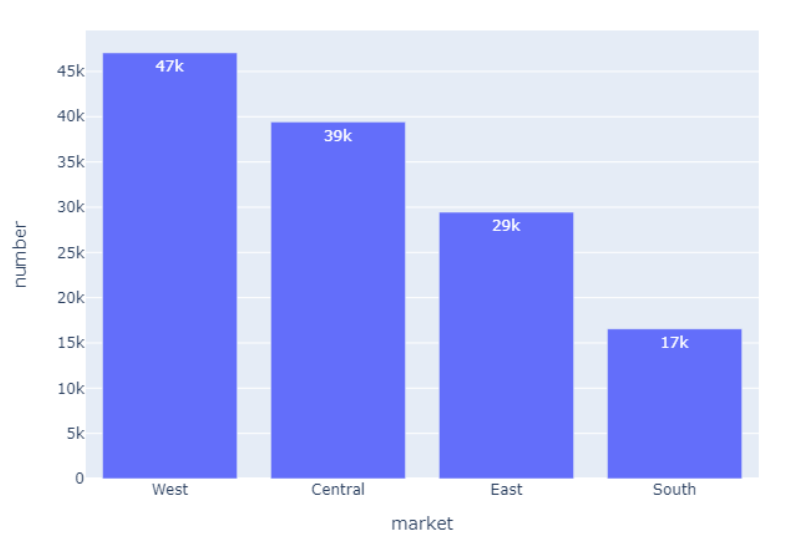
(2)查询咖啡销售量和market销售关系。
# 读入csv文件,读取完后df的类型为dataframe
val filePath=“file:///home/hadoop/桌面/CoffeeChain.csv”
val df=spark.read.options(
Map("inferSchema"->"true","delimiter"->",","header"->"true")).csv(filePath)
# 创建表用于sql查询
df.createOrReplaceTempView("coffee")
# 执行查询
val b = spark.sql("select market,sum(Marketing) as number from coffee group by market order by number desc")
# 保存文件为csv
b.write.option("header",true).csv("file:///home/hadoop/桌面/market_sell_num.csv")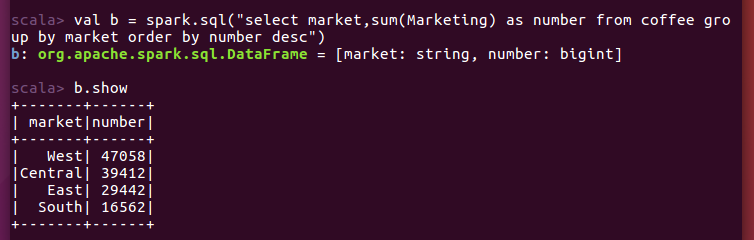
可以发现西部地区和中部地区消费咖啡的量远远大于东部和南部。
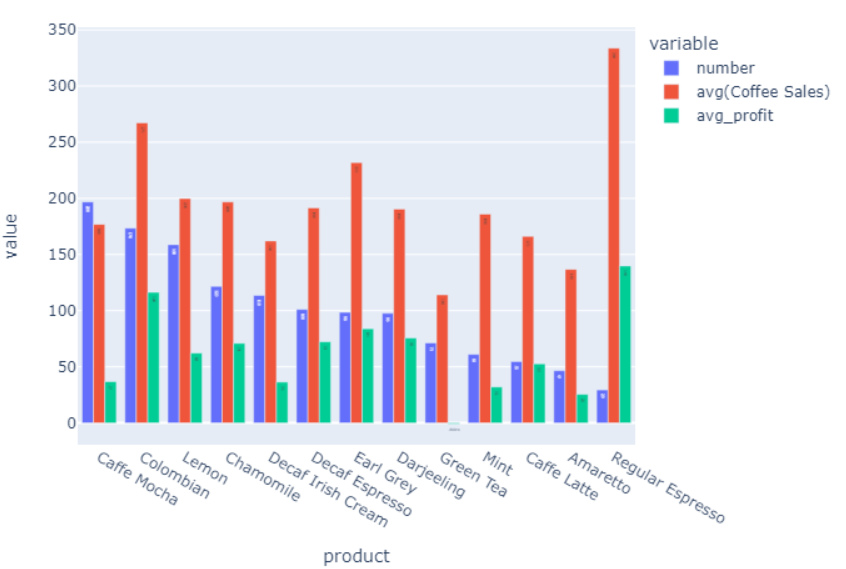
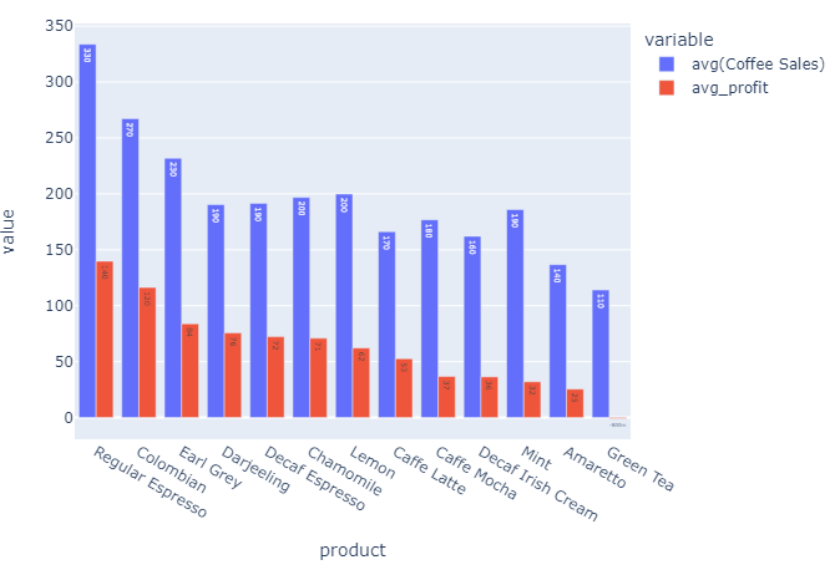
(3)查询咖啡的平均利润和售价。
# 读入csv文件,读取完后df的类型为dataframe
val filePath=“file:///home/hadoop/桌面/CoffeeChain.csv”
val df=spark.read.options(
Map("inferSchema"->"true","delimiter"->",","header"->"true")).csv(filePath)
# 创建表用于sql查询
df.createOrReplaceTempView("coffee")
# 执行查询
val b = spark.sql("select product,avg(`Coffee Sales`),avg(profit) as avg_profit from coffee group by product order by avg_profit desc")
# 保存文件为csv
b.write.option("header",true).csv("file:///home/hadoop/桌面/coffee_avg_sell_price_and_profit.csv")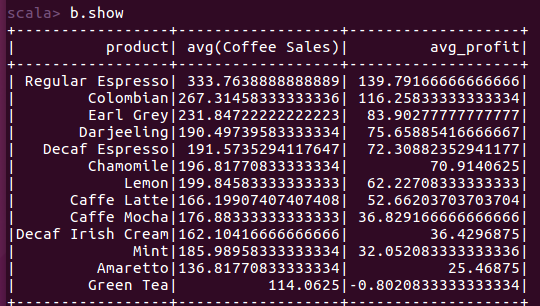
(4)查询咖啡的平均利润和售价和销售量的关系。
# 读入csv文件,读取完后df的类型为dataframe
val filePath=“file:///home/hadoop/桌面/CoffeeChain.csv”
val df=spark.read.options(
Map("inferSchema"->"true","delimiter"->",","header"->"true")).csv(filePath)
# 创建表用于sql查询
df.createOrReplaceTempView("coffee")
# 执行查询
val b = spark.sql("select a.product,avg(`Coffee Sales`),avg(profit) as avg_profit , b.number from coffee as a, (select product,sum(Marketing) as number from coffee group by product) as b where a.product == b.product group by a.product,b.number order by b.number desc ")
# 保存文件为csv
b.write.option("header",true).csv("file:///home/hadoop/桌面/coffee_avg_price_profit_relation_sell_num.csv")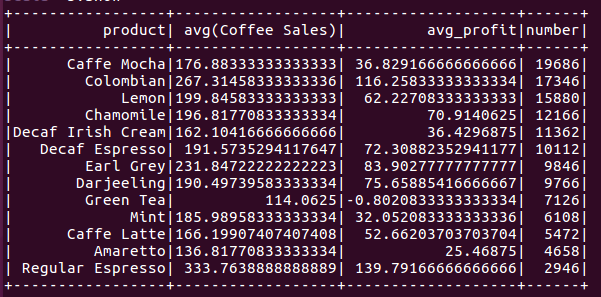
我们发现售价和利润与销售额似乎没有特别明显的关系。更进一步的,我们可以看看是否销售额高的商品,其他成本(人力成本抑或是广告成本)更高?
(5)查询咖啡的平均利润、销售量与其他成本的关系。
# 读入csv文件,读取完后df的类型为dataframe
val filePath=“file:///home/hadoop/桌面/CoffeeChain.csv”
val df=spark.read.options(
Map("inferSchema"->"true","delimiter"->",","header"->"true")).csv(filePath)
# 创建表用于sql查询
df.createOrReplaceTempView("coffee")
# 执行查询
val b = spark.sql("select a.product, avg(profit) as avg_profit , b.number , avg(a.`Total Expenses`) as other_cost from coffee as a, (select product,sum(Marketing) as number from coffee group by product) as b where a.product == b.product group by a.product,b.number order by b.number desc ")
# 保存文件为csv
b.write.option("header",true).csv("file:///home/hadoop/桌面/coffee_relation_price_ _sellnum_othercost.csv")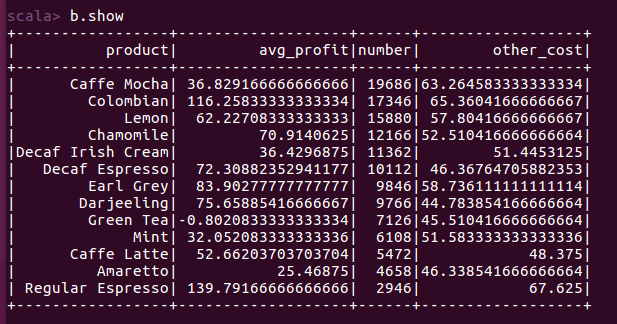
果然,销售额好的商品,他们的其他支出较高,极有可能是花了较多的钱去做广告或是雇佣更好的工人做咖啡,抑或是有着更好的包装。
(6)查询咖啡属性与平均售价、平均利润、销售量与其他成本的关系。
# 读入csv文件,读取完后df的类型为dataframe
val filePath=“file:///home/hadoop/桌面/CoffeeChain.csv”
val df=spark.read.options(
Map("inferSchema"->"true","delimiter"->",","header"->"true")).csv(filePath)
# 创建表用于sql查询
df.createOrReplaceTempView("coffee")
# 执行查询
val b = spark.sql("select a.type,avg(a.`Coffee Sales`) as avg_sales, avg(profit) as avg_profit , sum(b.number) as total_sales , avg(a.`Total Expenses`) as other_cost from coffee as a, (select product,sum(Marketing) as number from coffee group by product) as b where a.product == b.product group by a.type order by total_sales desc ")
# 保存文件为csv
b.write.option("header",true).csv("file:///home/hadoop/桌面/coffee_relation_type_price_ _sellnum_profit_othercost.csv")
可以发现,这两种咖啡的平均售价和利润不会差的很多,其他花费也差不多,但是销售量却差了近七百万,原因可能在于Decaf的受众不多,Decaf为低因咖啡,Regular为正常的咖啡。
(7)查询市场规模、市场地域与销售量的关系。
# 读入csv文件,读取完后df的类型为dataframe
val filePath=“file:///home/hadoop/桌面/CoffeeChain.csv”
val df=spark.read.options(
Map("inferSchema"->"true","delimiter"->",","header"->"true")).csv(filePath)
# 创建表用于sql查询
df.createOrReplaceTempView("coffee")
# 执行查询
val b = spark.sql("select Market,`Market Size`, sum(`Coffee Sales`) as total_sales from coffee group by Market,`Market Size` order by total_sales desc ")
# 保存文件为csv
b.write.option("header",true).csv("file:///home/hadoop/桌面/coffee_relation_market_marketsize_total_sales.csv")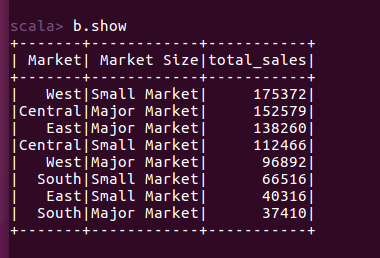
可以发现,小商超卖的咖啡竟然会比大商超卖的数量更多!
五、数据可视化
完整可视化代码
import plotly.graph_objects
import plotly.express as px
import pandas as pd
InvestorsCount = pd.read_csv('big_data/sell_num.csv')
sample_InvestorsCount = InvestorsCount.head(10)
fig_InvestorsCount = px.pie(sample_InvestorsCount, values='number', names='product', title='investorsCount')
fig_InvestorsCount.update_traces(hoverinfo='label+percent', textinfo='value', textfont_size=20,
marker=dict(line=dict(color='#000000', width=2)))
fig_InvestorsCount.write_image('big_data/investorsCount.png')
InvestorsCount = pd.read_csv('big_data/state_sell_num.csv')
sample_InvestorsCount = InvestorsCount.head(10)
fig_InvestorsCount = px.pie(sample_InvestorsCount, values='number', names='state', title='investorsCount')
fig_InvestorsCount.update_traces(hoverinfo='label+percent', textinfo='value', textfont_size=20,
marker=dict(line=dict(color='#000000', width=2)))
fig_InvestorsCount.write_image('big_data/state_sell_num.png')
Count = pd.read_csv('big_data/market_sell_num.csv')
sample_Count = Count.head(5)
fig_industryCount = px.bar(sample_Count, x='market', y='number', text_auto='.2s')
fig_industryCount.write_image('big_data/market_sell_num.png')
import plotly.express as px
long_df = px.data.medals_long()
long_df.head()
Count = pd.read_csv('big_data/coffee_avg_price_and_profit.csv')
sample_Count = Count.head(14)
fig_industryCount = px.bar(sample_Count, x='product', y=['product','avg(Coffee Sales)','avg_profit'], barmode='group',text_auto='.2s')
fig_industryCount.write_image('big_data/coffee_avg_price_and_profit.png')
import plotly.express as px
long_df = px.data.medals_long()
long_df.head()
Count = pd.read_csv('big_data/coffee_relation_market_marketsize_total_sales.csv')
sample_Count = Count.head(14)
fig_industryCount = px.bar(sample_Count, x='Market', y=['total_sales'],text_auto='.2s')
fig_industryCount.write_image('big_data/coffee_relation_market_marketsize_total_sales.png')- 咖啡销售量排名

2.销售量与state的关系
- 查询咖啡销售量和market销售关系
- 查询咖啡的平均利润和售价
- 查询咖啡的平均利润和售价和销售量的关系