
问题描述
实验二计算 write 耗费的时间,来比较同步写和异步写的性能差异。显示的时间应当尽量接近write操作过程所花的时间。不要将从磁盘读文件的时间计入显示结果中。
实验要求程序必须指定输出的文件名,而该文件是否按同步方式打开,则是可以选择的。因此程序至少带一个、至多两个输入参数。程序默认从标准输入 STDIN_FILENO 读取输入文件,可以利用shell的输入定向功能选择具体的输入文件。
问题解决
实验考察的是 UNIX 的文件 I/O 系统调用。要顺利完成该实验,除了好好看下书中《文件 I/O》 那一章节的内容,需要了解几个知识点:
- 了解文件重定向,即运行参数
<f1的作用,以及 STDIN_FILENO 和 STDOUT_FILENO 的含义,具体可以看看书上P6的文件输入输出代码。体会直接通过 STDIN_FILENO 来读取文件,和通过 read() 函数读取文件的区别; main(int argc, char *argv[])中的 argc 和 argv[],第 0 个参数是运行的程序,另外参数<f1不会被记录到 argc 和 argv 中。也就是说,如果执行./timewrite <f1 f2,那么 argc = 2, argv[0] = "./timewrite", argv[1] = f2。若使用输出重定向>f.out,也是不会被记录。
另外实现程序时,要注意:-
因为每次以固定的 buff size 写入,所以需要写入(file length / buff size)次。同时考虑最后可能会剩余一部分内容(因为输入文件大小不一定能被 buff size 整除),这部分内容需单独写入(写入的 size 不一样);
- 执行不同的 buffsize 写入时,使用 lseek 重定位到文件头就可以重新写入了,避免频繁打开、关闭输出文件。
- 最终的运行时间差还要除以系统嘀嗒数。
理解了这些知识点,整个实验就没多大问题了,代码如下:
#include "apue.h"
#include <fcntl.h>
#include <sys/times.h>
int main(int argc, char *argv[]) {
int i, fd, buffSize, ticks, loopCount, remain;
long int length;
char *buff;
clock_t clockStart, clockEnd;
struct tms tmsStart, tmsEnd;
float userTime, sysTime, clockTime;
/* 参数检查 */
if (argc < 2 || argc > 3){
err_quit("agrv eroor: ./timewrite <f1 f2 or ./timewrite f1 sync <f2");
}
if (argc == 3 && strcmp(argv[2], "sync") != 0) {
err_quit("argv error: ./timewrite f1 sync <f2");
}
/* 打开文件 */
if(argc == 2){ // 异步
// 使用了O_CREATE标志,则需要指定mode,表示文件权限
if((fd = open(argv[1], O_RDWR|O_CREAT|O_TRUNC, FILE_MODE)) < 0) {
err_sys("can't open file");
}
} else { // 同步
if((fd = open(argv[1], O_RDWR|O_CREAT|O_TRUNC|O_SYNC, FILE_MODE)) < 0) {
err_sys("can't open file");
}
}
/* 读入文件 */
if((length = lseek(STDIN_FILENO, 0, SEEK_END)) < 0) { // 计算文件长度
err_sys("lseek error");
}
if ((buff = (char*)malloc(sizeof(char)*length)) == NULL){
err_sys("malloc error");
}
if (lseek(STDIN_FILENO, 0, SEEK_SET) == -1) { // 定位到输入文件的开头
err_sys("lseek error");
}
if (read(STDIN_FILENO, buff, length) < 0){ //将输入文件读入到buff中
err_sys("read error");
}
printf("%-8s\t %-8s\t %-8s\t %-8s\t %-8s\t\n", "BUFFSIZE", "USER CPU", "SYSTEM CPU", "CLOCK CPU", "LOOP COUNT");
ticks = sysconf(_SC_CLK_TCK);
/* 写文件,以不同的 buffsize 执行写入 */
for(buffSize = 1024; buffSize <= 131072; buffSize *= 2) {
if (lseek(fd, 0, SEEK_SET) == -1) { // 重定位到文件头,重新写入
err_sys("lseek error");
}
loopCount = length / buffSize; // 写入次数
clockStart = times(&tmsStart);
for(i = 0; i < loopCount; i++) { // 以 buffsize 大小写入
if(write(fd, buff + i*buffSize, buffSize) != buffSize) {
err_sys("write error");
}
}
remain = length % buffSize; // 可能有剩余内容
if (remain) {
if (write(fd, buff + loopCount * buffSize, remain) != remain) {
err_sys("write error");
}
loopCount++;
}
clockEnd = times(&tmsEnd);
userTime = (float)(tmsEnd.tms_utime - tmsStart.tms_utime)/ticks;
sysTime = (float)(tmsEnd.tms_stime - tmsStart.tms_stime)/ticks;
clockTime = (float)(clockEnd - clockStart)/ticks;
printf("%8d\t %8.2f\t %8.2f\t %8.2f\t %8d\n", buffSize, userTime, sysTime, clockTime, loopCount);
}
return 0;
}
代码编译和使用:
gcc timewrite.c error2e.c -o timewrite
./timewrite <f1 f2
./timewrite f1 sync <f2
程序执行完后,可以检查一下输入和输出这两个文件的字节数是否一致来判断程序正确性。正确的结果如下图所示,如果时间都是 0.00,则要使用更大的输入文件,下图所用输入文件为 30M:
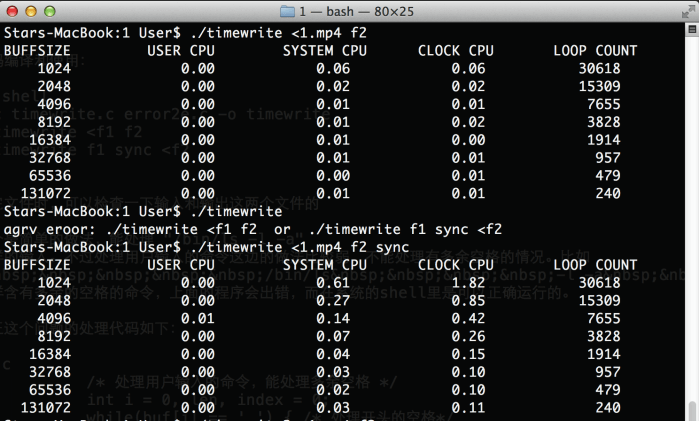
网上虽然有不少人都有贴出代码,但不得不说这些代码还是存在一些小瑕疵,尽管结果是正确的。例如这个 error2e.c ,里面提供了几个不同的 err 函数,但很少看到别人的代码里有用到,或者使用上不规范。借鉴他人代码是可以,但要有自己的理解而不是直接copy。