
作者:厦门大学信息学院计算机科学系2023级研究生 黄万嘉
指导老师:厦门大学数据库实验室 林子雨 博士/副教授
随着人工智能技术的飞速发展,AI 辅助编程逐渐成为提升开发效率、优化代码质量的重要工具。本文通过结合 DeepSeek 的强大语言模型和 VSCode 的高效开发环境,展示了如何利用 AI 辅助编程完成一个经典的 MapReduce 词频统计任务。这一实践不仅展示了 AI 在编程中的应用潜力,还为开发者提供了一个高效、便捷的开发流程示例,帮助读者快速上手 AI 辅助编程,并探索其在实际项目中的应用价值。
实验环境:
- VSCode
- Cline
- DeepSeek
- Ubuntu 22.04
- Hadoop 3.3.5
以上实验环境并不要求完全一致,能实现效果即可。
安装与配置Cline
Cline 是一个 VSCode 插件,可以接入 DeepSeek 的 API,用于生成代码、解释代码或者修复代码问题。在VSCode左侧“扩展”中搜索Cline并下载

安装完成后,我们点击右上角齿轮图案进入设置,选择当前的AI辅助编程使用的大模型。对于DeepSeek,我们有两种方案:
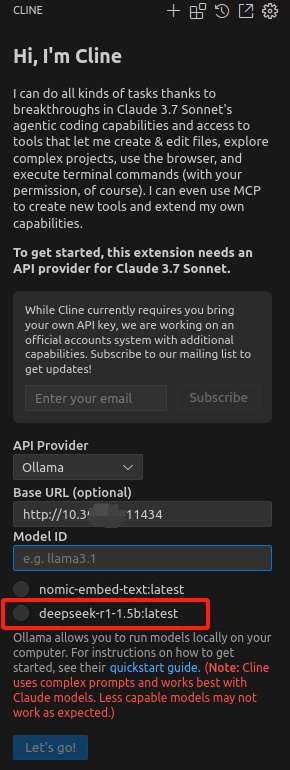
- 使用已经安装好的本地Ollama服务:https://dblab.xmu.edu.cn/blog/5816/ 可以参考这篇博客中的Ollama安装DeepSeek-r1,输入对应的Ollama服务地址,如http://localhost:11434,如果Ollama服务正确运行,则会显示你已经安装的模型,如下图中的deepseek-r1-1.5b:latest
- 可以使用DeepSeek提供的API,至https://platform.deepseek.com/usage 中就可以购买并获得API
配置完成后就可以开始使用Cline,具体的功能可以对照下图

AI辅助编程-以词频统计案例为例实现
为了更好地展示AI辅助编程的效果,笔者在这采用使用DeepSeek API的方式,这样的请求方式能使用满血的DeepSeek,方便读者们看到效果,实际实验的过程中,使用自己安装的DeepSeek 7b也是可以的。
为了更好地实现辅助编程,我首先用maven创建了一个干净的新项目,项目的架构图为
demo
├─ pom.xml
├─ src
│ └─ main
│ └─ java
└─ target我本机安装的hadoop版本为3.3.5,因此我提前在pom.xml中引入基础的包,方便AI使用
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>demo</artifactId>
<version>1.0-SNAPSHOT</version>
<name>demo</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<hadoop.version>3.3.5</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<!-- 导入hadoop依赖环境 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-api</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
<build>
<pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) -->
<plugins>
<!-- clean lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#clean_Lifecycle -->
<plugin>
<artifactId>maven-clean-plugin</artifactId>
<version>3.1.0</version>
</plugin>
<!-- default lifecycle, jar packaging: see https://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_jar_packaging -->
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.0.2</version>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
</plugin>
<plugin>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.1</version>
</plugin>
<plugin>
<artifactId>maven-jar-plugin</artifactId>
<version>3.0.2</version>
</plugin>
<plugin>
<artifactId>maven-install-plugin</artifactId>
<version>2.5.2</version>
</plugin>
<plugin>
<artifactId>maven-deploy-plugin</artifactId>
<version>2.8.2</version>
</plugin>
<!-- site lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#site_Lifecycle -->
<plugin>
<artifactId>maven-site-plugin</artifactId>
<version>3.7.1</version>
</plugin>
<plugin>
<artifactId>maven-project-info-reports-plugin</artifactId>
<version>3.0.0</version>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>之后新建对话的第一个问题就详细描述我要完成的任务:
**任务目标**
使用JAVA语言,用MapReduce框架实现词频统计,要求输出词频排序结果
**输入数据**
1. txt格式
2. 请你随意生成三个txt内容用于测试,文件不用很大,每个文件有几条数据即可
**开发要求**
1. 在我当前创建好的maven项目中开发
2. 输入数据和输出数据都保存在本地,不需要使用HDFS
3. 直接返回代码,告诉我我该怎么做。之后Cline根据我的要求,编写好对应的promt去请求DeepSeek,并依次创建了测试数据文件

接着又依次根据我的需求,创建了WordCountMapper.java WordCountReducer.java WordCount.java

package com.example;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}package com.example;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}package com.example;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: WordCount <input path> <output path>");
System.exit(-1);
}
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}之后Cline认为代码编写完成,可以使用maven直接打包,并用hadoop指令运行,但这时候遇到了一个问题,我并没有配置hadoop的环境变量(也就是说用hadoop指令需要到我安装的hadoop目录/usr/local/hadoop下),因此我提示了Cline这一点

在这之后,项目成功被打包为jar包,并执行,输出结果至创建好的/output文件夹

最终效果
最终Cline + DeepSeek自动创建的项目结构为:

output文件夹中成功输出了词频统计:
