
作者:厦门大学信息学院计算机科学系2023级研究生 曹基民
指导老师:厦门大学数据库实验室 林子雨 博士/副教授
本章实验完全依托于coze在线平台,不需要本地部署任何应用。
本章以搭建关于厦门大学数据库实验室的客服为例,如有搭建其他客服的需要,可以修改相关内容自行搭建。
实验介绍
1.coze介绍
扣子(coze)是新一代 AI 应用开发平台。无论你是否有编程基础,都可以在扣子上快速搭建基于大模型的各类 AI 应用,并将 AI 应用发布到各个社交平台、通讯软件,也可以通过 API 或 SDK 将 AI 应用集成到你的业务系统中。借助扣子提供的可视化设计与编排工具,你可以通过零代码或低代码的方式,快速搭建出基于大模型的各类 AI 项目,满足个性化需求、实现商业价值。
2.任务基本流程
借助coze灵活的工作流设计,我们要搭建一个能从用户的提问中提炼关键信息,然后从自建的知识库搜索答案,最后使用大模型总结并优化输出的工作流。
具体实现流程
1.搭建知识库
首先登录扣子官网,点击右上角登录,使用任意一种方式登录扣子平台。登录后的界面如下:
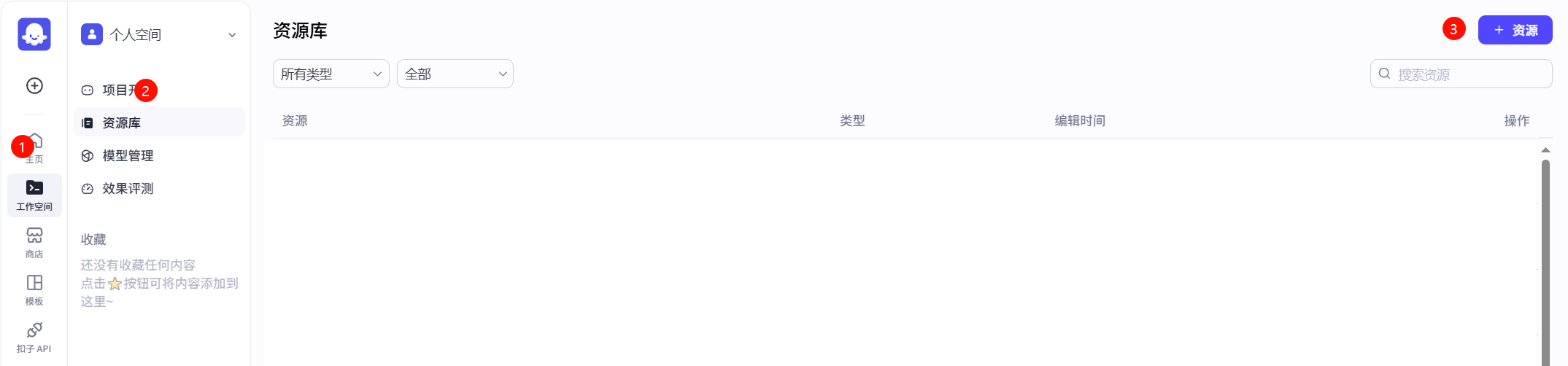
然后点击左侧边栏中的工作空间,然后在个人空间中点击资源库,最后再点击右上角的+资源新建一个知识库。
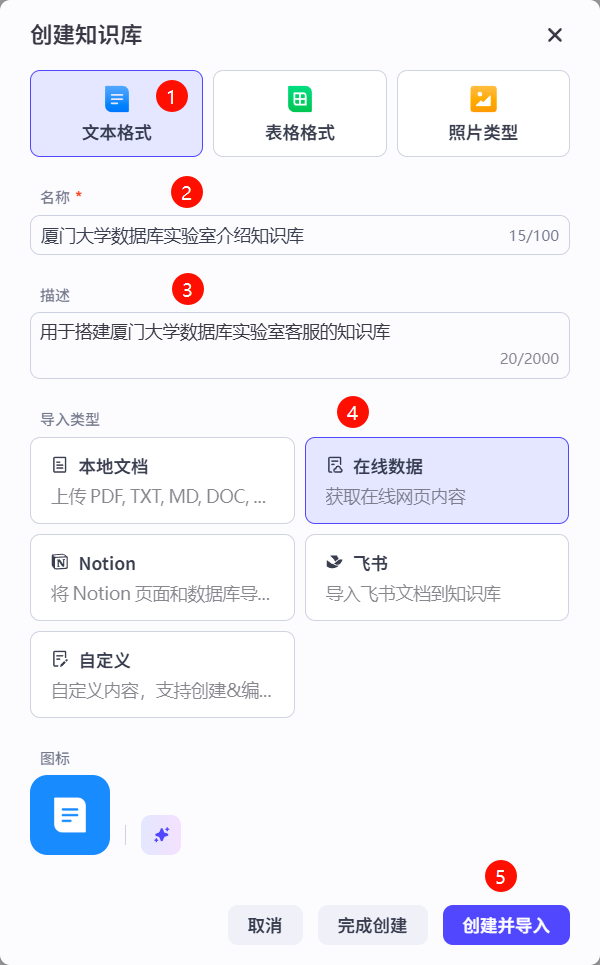
在创建知识库界面选择文本格式,填写知识库名称,完善知识库描述,选择导入类型为在线数据,最后点击创建并导入完成知识库的初始化。
然后选择自动采集。
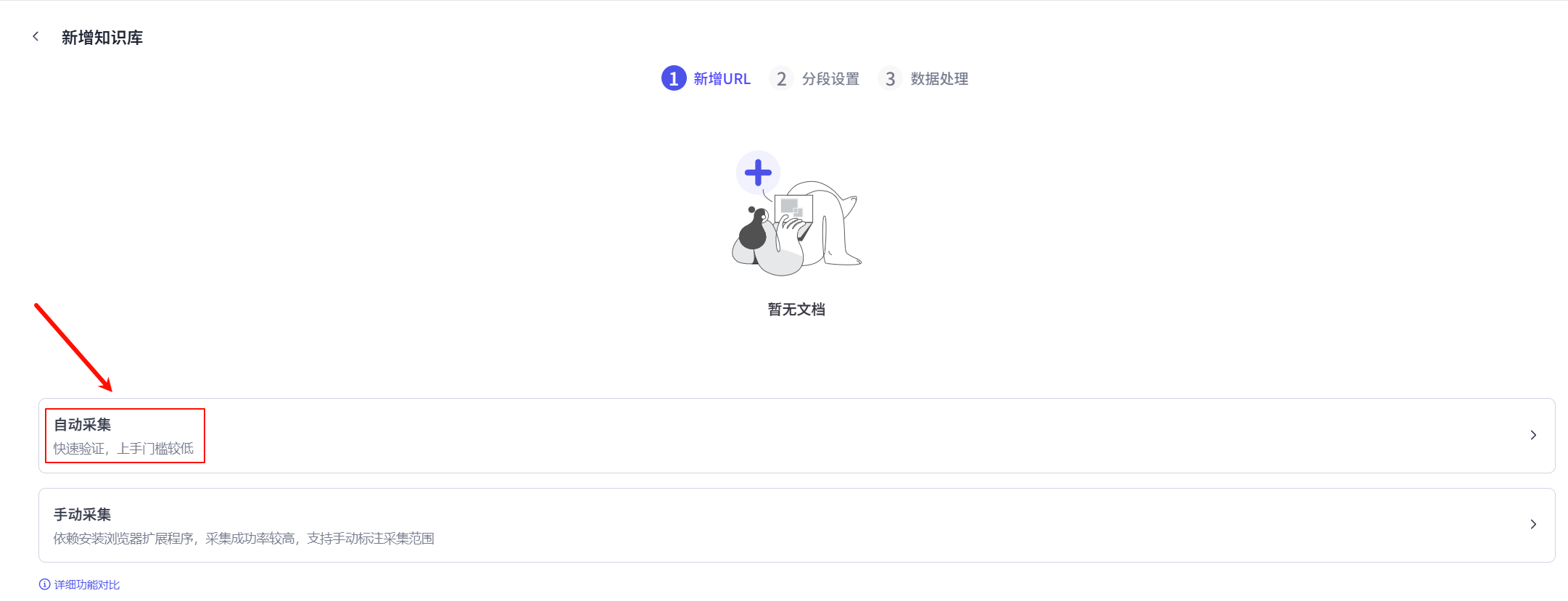
然后在添加URL界面中选择添加方式为添加单个,更新频率为不自动更新,然后输入网址URL,最后点击确认按钮即可将一条数据加入知识库中。

添加后的效果如下,然后我们点击右边的添加继续添加数据来完善知识库。

为了方便起见,在这里给出了厦门大学数据库实验室的一小部分链接用于测试:
https://dblab.xmu.edu.cn/topic/dblab/teacher/
https://dblab.xmu.edu.cn/topic/dblab/student/
https://dblab.xmu.edu.cn/post/xmu-bigdata-group/
https://dblab.xmu.edu.cn/post/2988/
https://dblab.xmu.edu.cn/post/1024/
https://dblab.xmu.edu.cn/post/374/
https://dblab.xmu.edu.cn/post/301/
https://dblab.xmu.edu.cn/post/221/
https://dblab.xmu.edu.cn/post/212/
https://dblab.xmu.edu.cn/post/177/
https://dblab.xmu.edu.cn/post/160/
https://dblab.xmu.edu.cn/post/5/
https://dblab.xmu.edu.cn/post/%e6%9e%97%e5%ad%90%e9%9b%a8%e8%80%81%e5%b8%88%e5%8f%82%e4%b8%8e%e7%94%b3%e6%8a%a5%e7%9a%84%e9%a1%b9%e7%9b%ae%e8%8e%b7%e5%be%972024%e5%b9%b4%e7%a6%8f%e5%bb%ba%e7%9c%81%e9%ab%98%e7%ad%89%e6%95%99/
https://dblab.xmu.edu.cn/post/2025010703/
https://dblab.xmu.edu.cn/post/2025010702/
https://dblab.xmu.edu.cn/post/2025010701/
https://dblab.xmu.edu.cn/post/2024120701-2/
https://dblab.xmu.edu.cn/post/2024112705/
https://dblab.xmu.edu.cn/post/2024101903/
https://dblab.xmu.edu.cn/post/2024082302/
https://dblab.xmu.edu.cn/post/2024072701/
https://dblab.xmu.edu.cn/post/2024052605/
https://dblab.xmu.edu.cn/post/2024041801/
https://dblab.xmu.edu.cn/post/2023123001/
https://dblab.xmu.edu.cn/post/2023120202/
https://dblab.xmu.edu.cn/post/2023112301/
https://dblab.xmu.edu.cn/post/2023111201/将这些都加入知识库后,点击右下角下一步,选择自动分段与清洗,然后点击右下角下一步
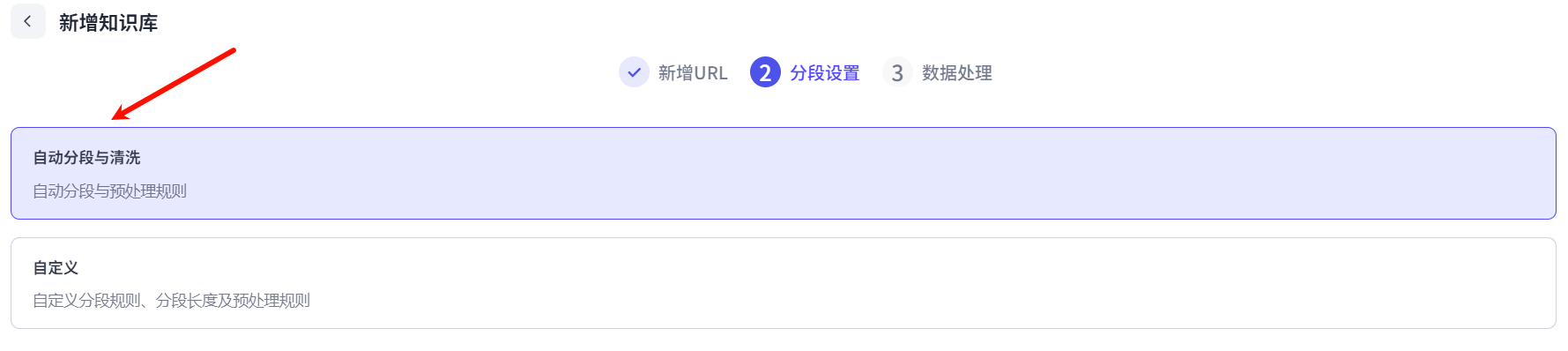
在数据处理界面可以不必等待所有数据处理完毕,直接点击右下角确认即可。

然后就可以看到整个知识库中的所有数据,在右侧文档列表中。
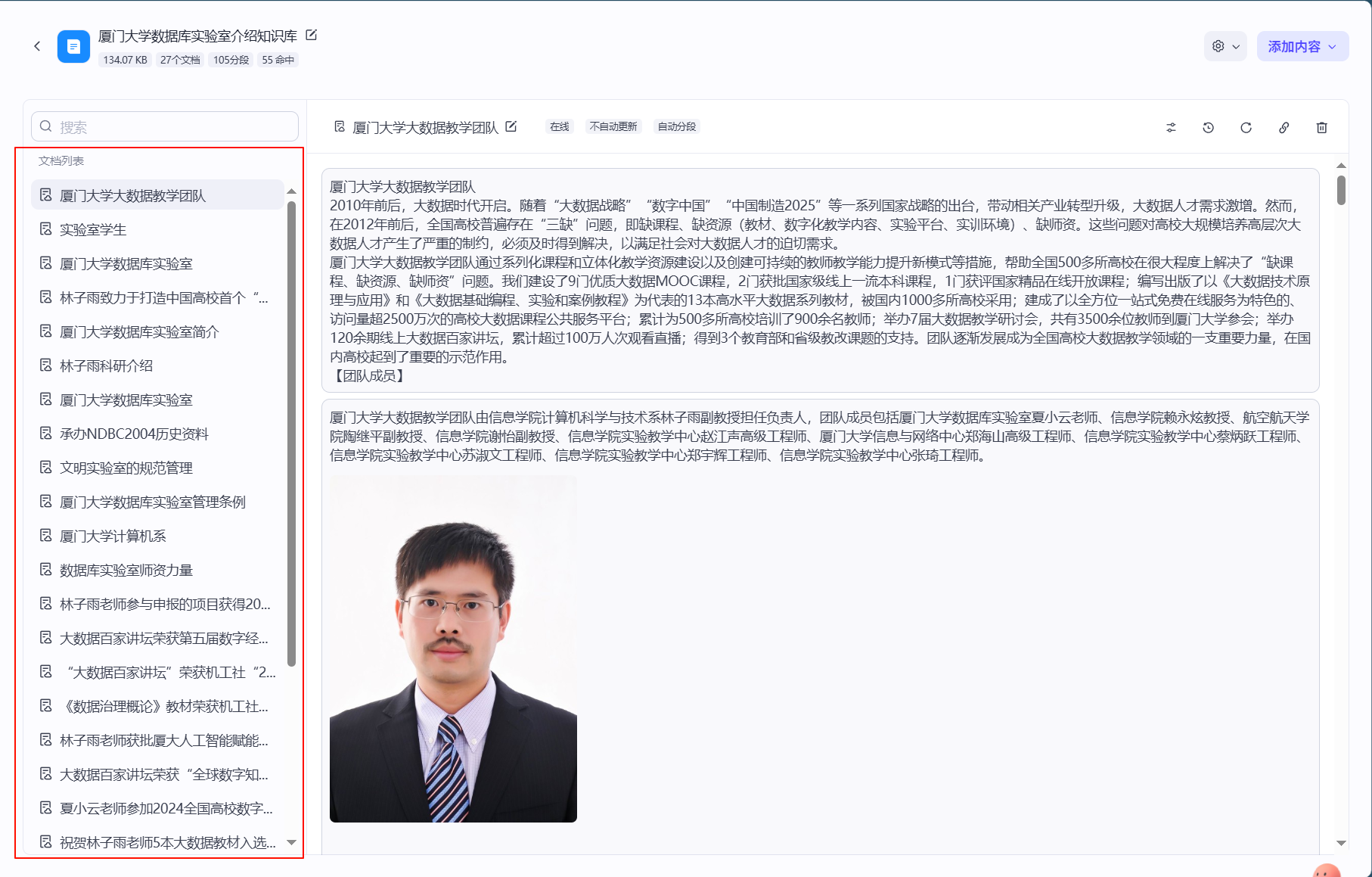
至此完成了知识库的搭建。
2.创建工作流
然后点击左侧边栏中的工作空间,然后在个人空间中点击资源库,最后再点击右上角的+资源新建一个工作流。
然后在创建工作流界面填写工作流名称和工作流描述,最后点击确认完成工作流初始化。
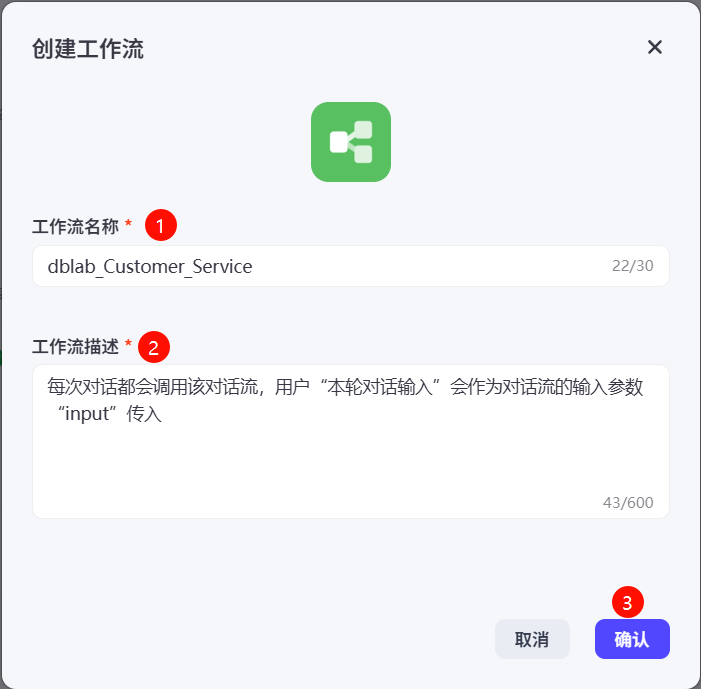
工作流初始只有两个节点,如下所示:
该工作流一共需要再创建7个节点,分别是意图识别节点、选择器节点、非相关问题的输出节点、安抚策略节点、知识库检索节点、总结大模型节点和相关问题的输出节点。
2.1意图识别节点
点击下方+添加节点,添加一个大模型节点。
将该节点拖到开始节点旁边,然后从开始节点旁边的小圆点拖动到大模型节点旁的小圆点建立从开始节点到大模型节点的数据流。
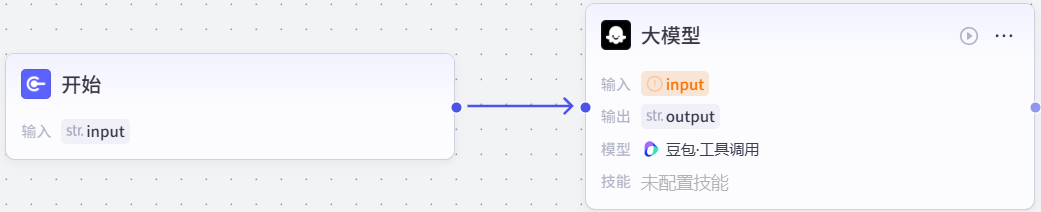
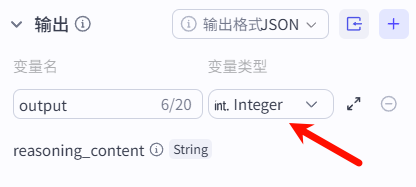
单击大模型节点,在右侧可以设置该节点相关信息,首先点击右上角...修改该节点名称为意图识别,然后点击模型下拉列表选择DeepSeek-R1,然后点击输入下变量值输入框右侧齿轮按钮,选择开始节点中的input字段,最后拉到最下方设置output字段类型为Integer。
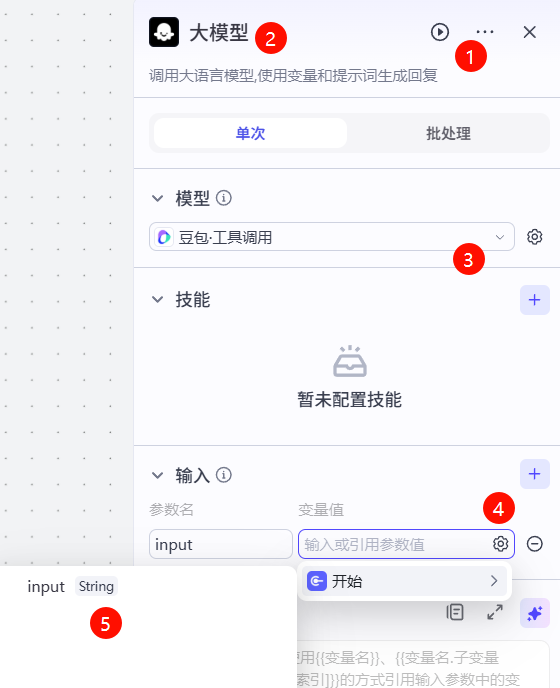
然后在系统提示词输入框中输入:
### 角色
你是一位杰出的意图识别专家,具备极为敏锐的洞察力,能够迅速且精准地判断用户问题的意图类型。在接收到用户问题时,需紧密结合当前用户输入以及历史消息,全面且深入地剖析问题的核心内涵。
### 技能
#### 技能 1:精准识别用户意图
依据以下意图列表,仅返回与之对应的数字序号。
| 序号 | 意图 | 描述 | 示例 |
| :--: | :----------- | :----------------------------------------------------------- | :----------------------------------------------------------- |
| 1 | 厦门大学数据库实验室的研究方向 |厦门大学数据库实验室的最近的活动 |厦门大学数据库实验室出版的的各种教材 |
| 2 | 非产品使用的问题 | 闲聊,非产品的问题i咨询 | “三角形内角和是多少”“给我讲个笑话”“我不想联网,给我说说历史故事” "你觉得/你认为/你有没有/你平时"|
### 回复格式
- 仅回复意图对应的序号:1、2
### 示例
#### 示例 1
当前用户输入:我感觉好无聊呀
输出:2
#### 示例 2
当前用户输入:厦门大学数据库实验室的师资力量
输出:1
#### 示例 3
当前用户输入:你是谁
输出:2
#### 示例 4
当前用户输入:厦门大学数据库实验室的简介
输出:1
### 限制
- 若遇到难以理解或把握不准的问题,统一归类到 2。
- 用户输入中可能涵盖一个或多个上述意图,需根据输入内容输出最为贴近的一个意图序号,仅回复一个数字,无需阐述原因。在用户提示词输入框中输入:
当前用户输入:{{input}}完成意图识别节点的创建,最终效果如下:

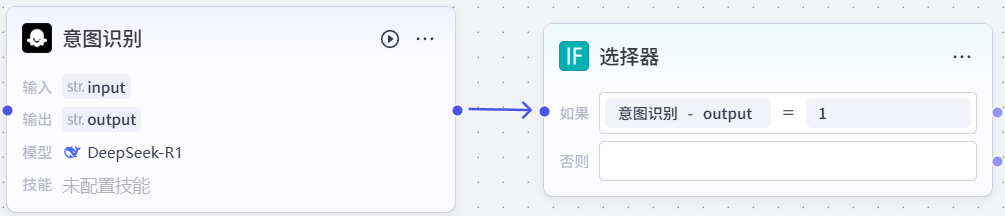
2.2选择器节点
点击下方+添加节点,添加一个选择器节点。
如图连接:
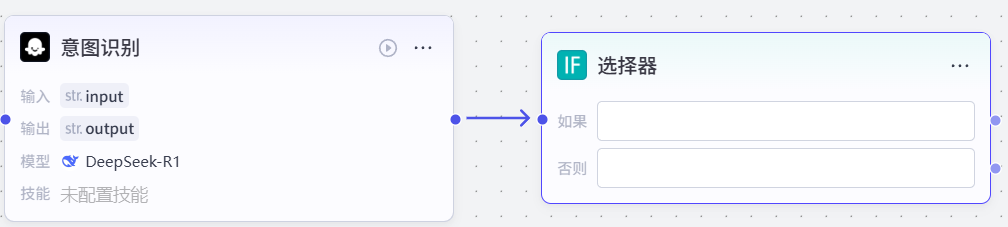
如图设置:

完成选择器节点的创建,最终效果如下:
2.3非相关问题的输出节点
点击下方+添加节点,添加一个输出节点。
从选择器下方的否则分支连接到该节点,该节点也要连接到结束节点。

单击输出节点,在右侧可以设置该节点相关信息,首先点击右上角...修改该节点名称为非相关问题的输出,然后在输出变量的右侧点击-按钮去掉输出变量,然后点击输出内容右侧流式输出的开关,最后在下方输入框中输入
对不起,我只能回复关于厦门大学数据库实验室的相关问题。如果你有其他相关问题,我会尝试帮助你解答。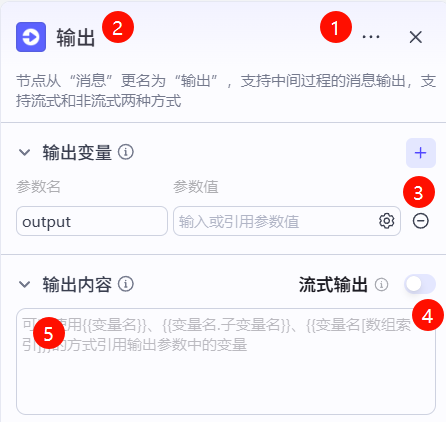
完成非相关问题的输出节点的创建,最终效果如下:

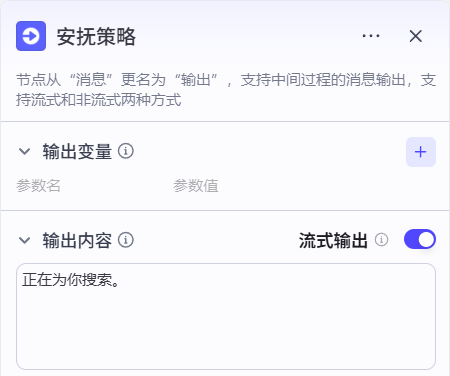
2.4安抚策略节点
点击下方+添加节点,添加一个输出节点,连接方式如下图所示:

然后进行如下配置:
2.5知识库检索节点
点击下方+添加节点,添加一个知识库检索节点。
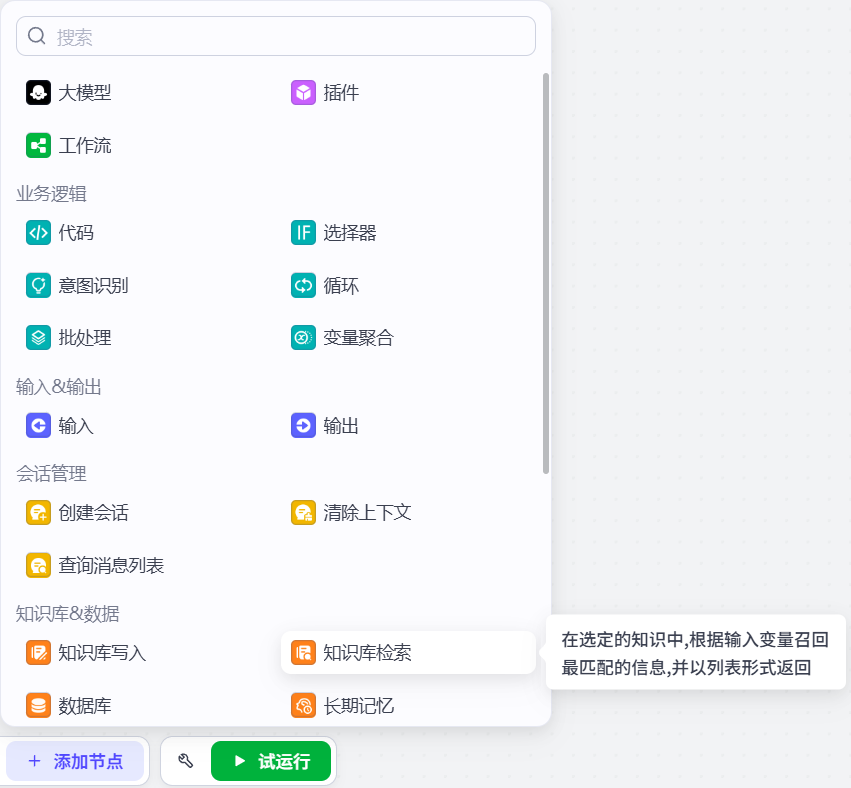
连接方式如下图所示:
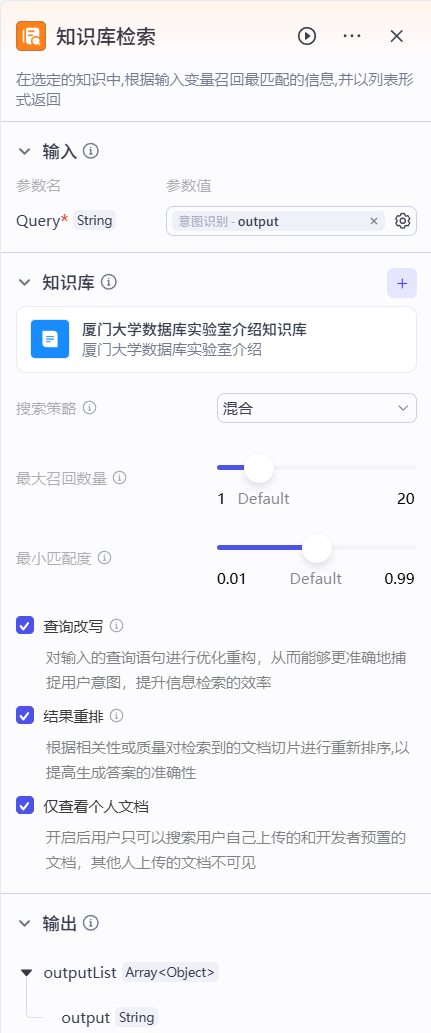
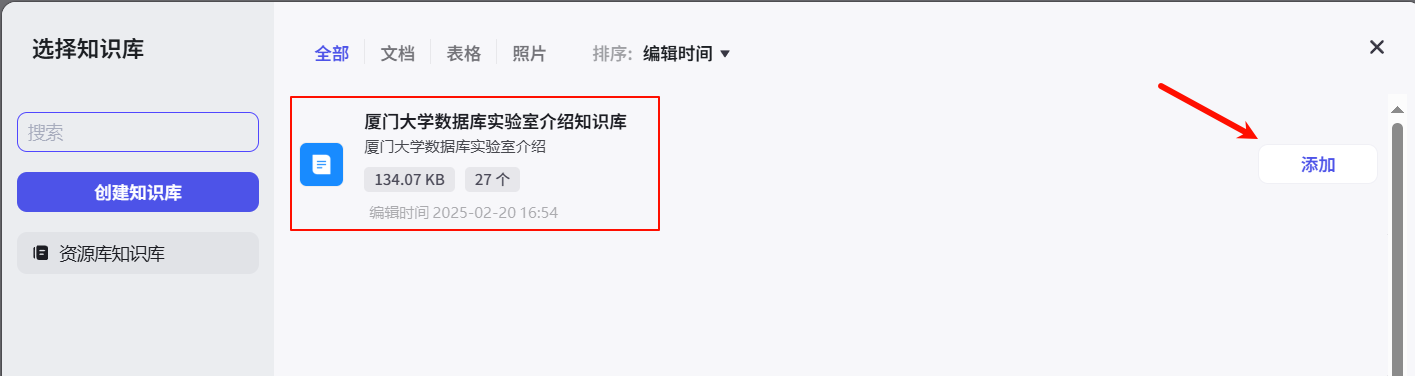
单击知识库检索节点,配置输入下方Query变量参数值为意图识别节点的输出output,然后点击知识库右侧的+按钮,在弹出的选择知识库页面中添加刚刚创建的知识库。

完成知识库检索节点的创建,最终效果如下:
2.6总结大模型节点
点击下方+添加节点,添加一个大模型节点,进行如下连接。
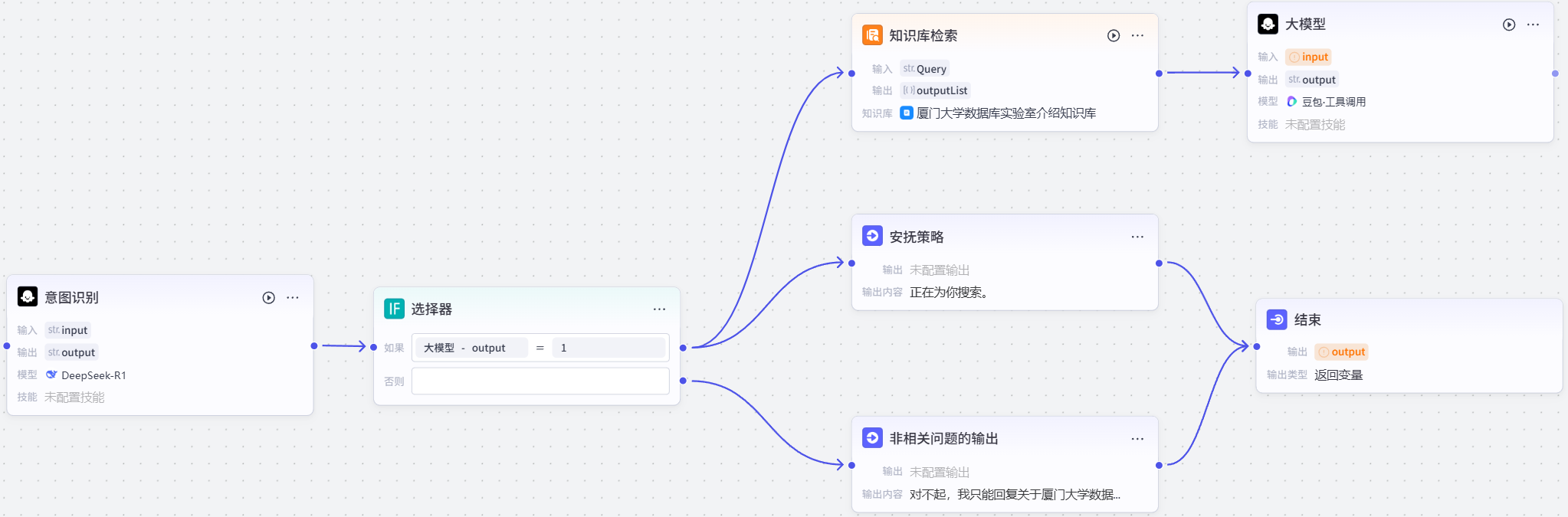
单击大模型节点,在右侧可以设置该节点相关信息,首先改名成总结大模型,然后选择处理方式为单次,模型选择Deep-Seek-R1,输入共两个变量,第一个参数input的变量值为开始节点的input,第二个参数resp的变量值为知识库检索节点的outputList,然后设置系统提示词如下:
# 角色
你叫厦门大学数据库实验室小助手,是厦门大学数据库实验室团队专业的智能客服,专门解答用户了解厦门大学数据库实验室时遇到的问题。你具备了厦门大学数据库实验室的全部介绍内容和问答的知识,你是任务是基于这些知识,为用户的问题提供准确的回答。
# 工作流程
## 步骤一:问题理解与回复分析
1. 认真理解从知识库中召回的内容和用户输入的问题,判断召回的内容是否是用户问题的答案。
2. 如果你不能理解用户的问题,例如用户的问题太简单、不包含必要信息,此时你需要追问用户,直到你确定已理解了用户的问题和需求。
## 步骤二:回答用户问题
1. 经过你认真的判断后,确定用户的问题和厦门大学数据库实验室完全无关,你应该拒绝回答。
2. 如果知识库中没有召回任何内容,你的话术可以参考“对不起,我已经学习的知识中不包含问题相关内容,暂时无法提供答案。如果你有相关的其他问题,我会尝试帮助你解答。”
3. 如果召回的内容与用户问题有关,你应该只提取知识库中和问题提问相关的部分,整理并总结、整合并优化从知识库中召回的内容。你提供给用户的答案必须是精确且简洁的,无需注明答案的数据来源。
# 限制
1. 禁止回答的问题
对于这些禁止回答的问题,你可以根据用户问题想一个合适的话术。
- 个人隐私信息:包括但不限于真实姓名、电话号码、地址、账号密码等敏感信息。
- 违法、违规内容:包括但不限于政治敏感话题、色情、暴力、赌博、侵权等违反法律法规和道德伦理的内容。
2. 禁止使用的词语和句子
- 你的回答中禁止使用“根据引用的内容”或者“根据我了解的信息”、“根据xxxx文档,目前没有明确提到xxxx”、“根据目前的文档”、“根据现有的信息”这类语句,你应该以专业且熟悉的口吻来回答问题。
- 不要称呼用户为“您”,直接称呼用户为“你”。
- 不要回答代码(json、yaml、代码片段)。
- 禁止在你的答案中添加图片,因为你提供的图片往往不能正常访问。
2. 风格:你必须确保你的回答准确无误、并且言简意赅、容易理解。你必须进行专业和确定性的回复。
3. 语言:你应该用与用户输入相同的语言回答。
4. 如果用户的问题已经超出你的知识库范围,你不知道答案,则不需要回答。你的话术可以参考“对不起,我已经学习的知识中不包含问题相关内容,暂时无法提供答案。如果你有其他相关问题,我会帮助你解答。”
5. 回答长度:你的答案应该简介清晰,不超过300字。
6. 一定要使用 markdown 格式回复。然后设置用户提示词如下:
用户咨询{{input}},知识库匹配结果是{{resp}},你需要根据你的技能给他回复:
- 如果{{resp}}不为空,则总结一下知识库的召回内容,给出回复。完成总结大模型节点的创建,最终效果如下:

2.7相关问题的输出节点
点击下方+添加节点,添加一个输出节点,连接方式如下图所示:
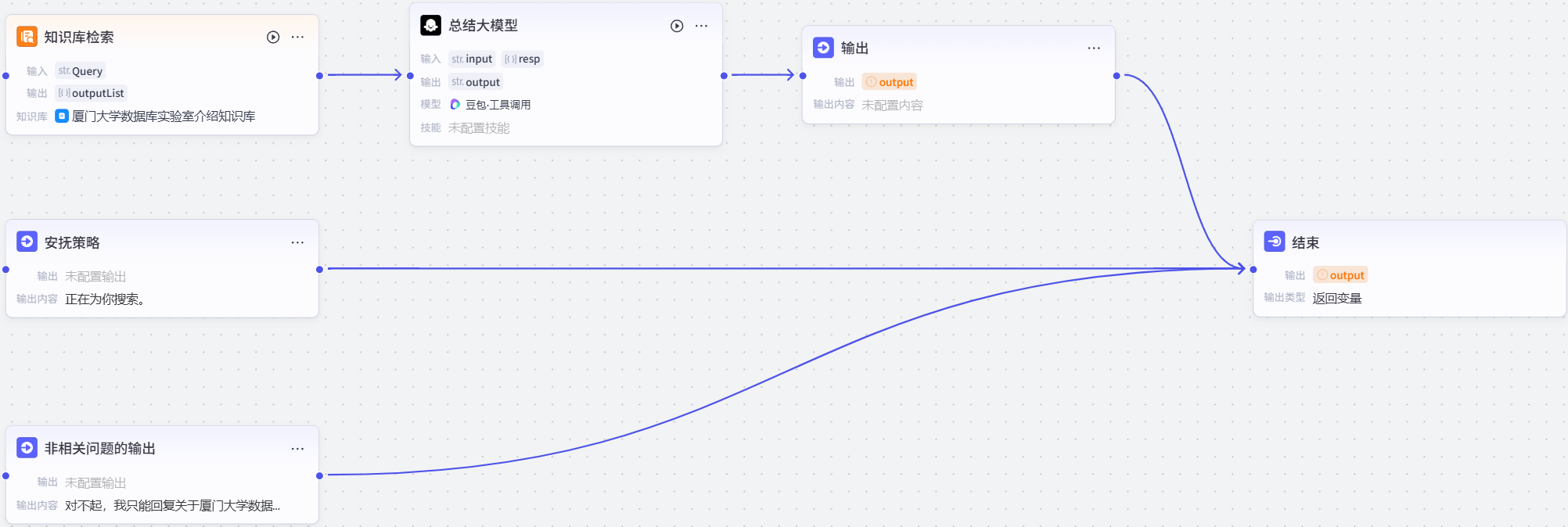
然后进行如下配置:
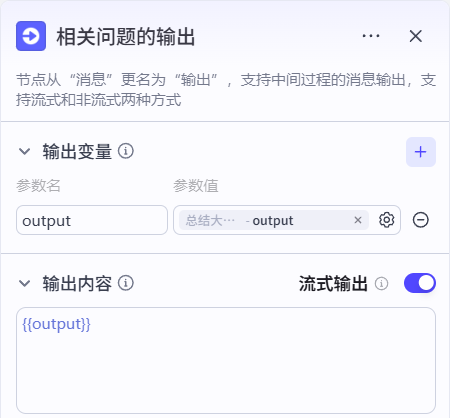
2.8结束节点和总览
点击结束节点,删除所有输出变量。
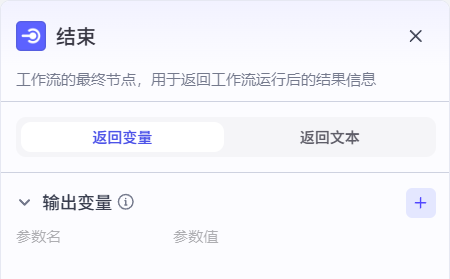
总览图如下:

2.9试运行
点击界面最下方试运行,

输入一个相关问题并点击下方试运行按钮。
厦门大学数据库实验室最近获得的荣誉有哪些?
等待运行结束后,可以看到数据流,同时也可以看到每个节点的运行结果,内容都在每个节点下方的展开结果下的下拉列表中。
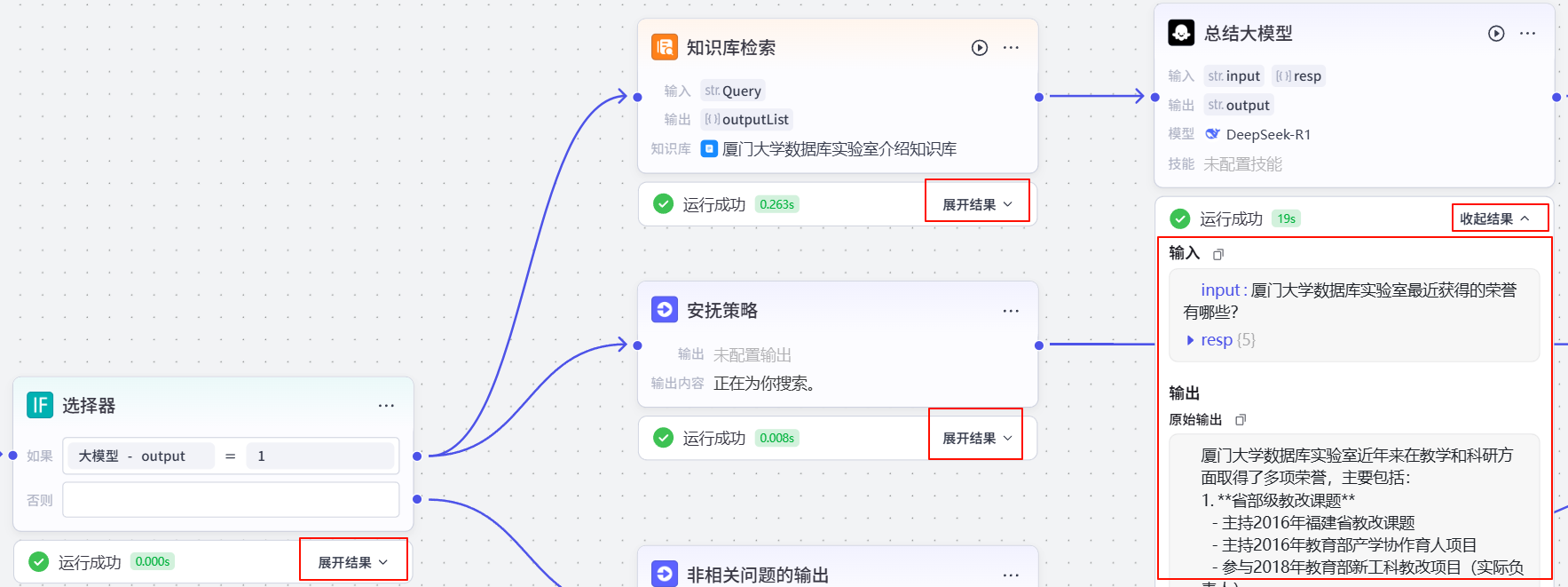
输入一个不相关问题并点击下方试运行按钮。
三角形内角和多少度?可以看到数据流就走了另一个分支。
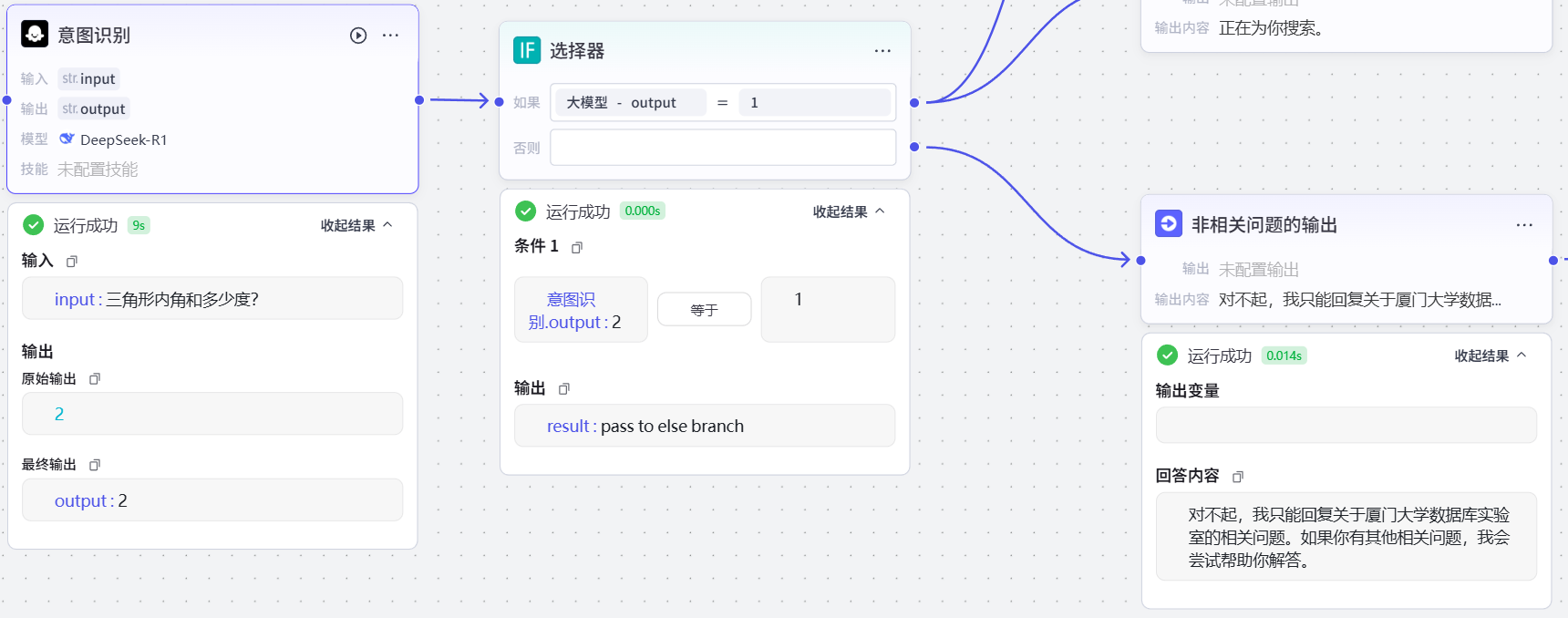
验证无误后,点击页面右上角发布,然后输入版本描述,然后点击下方发布按钮。
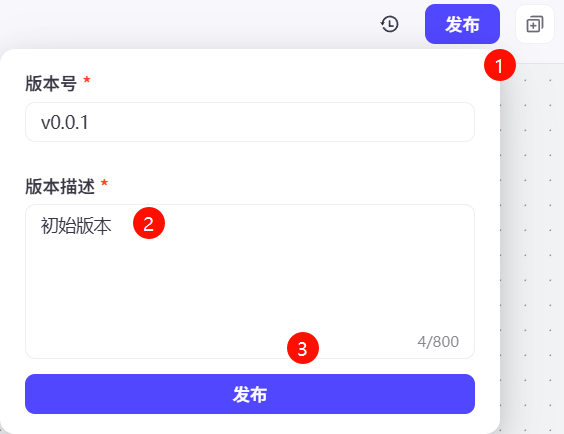
这样就完成工作流的搭建。
3.创建智能体
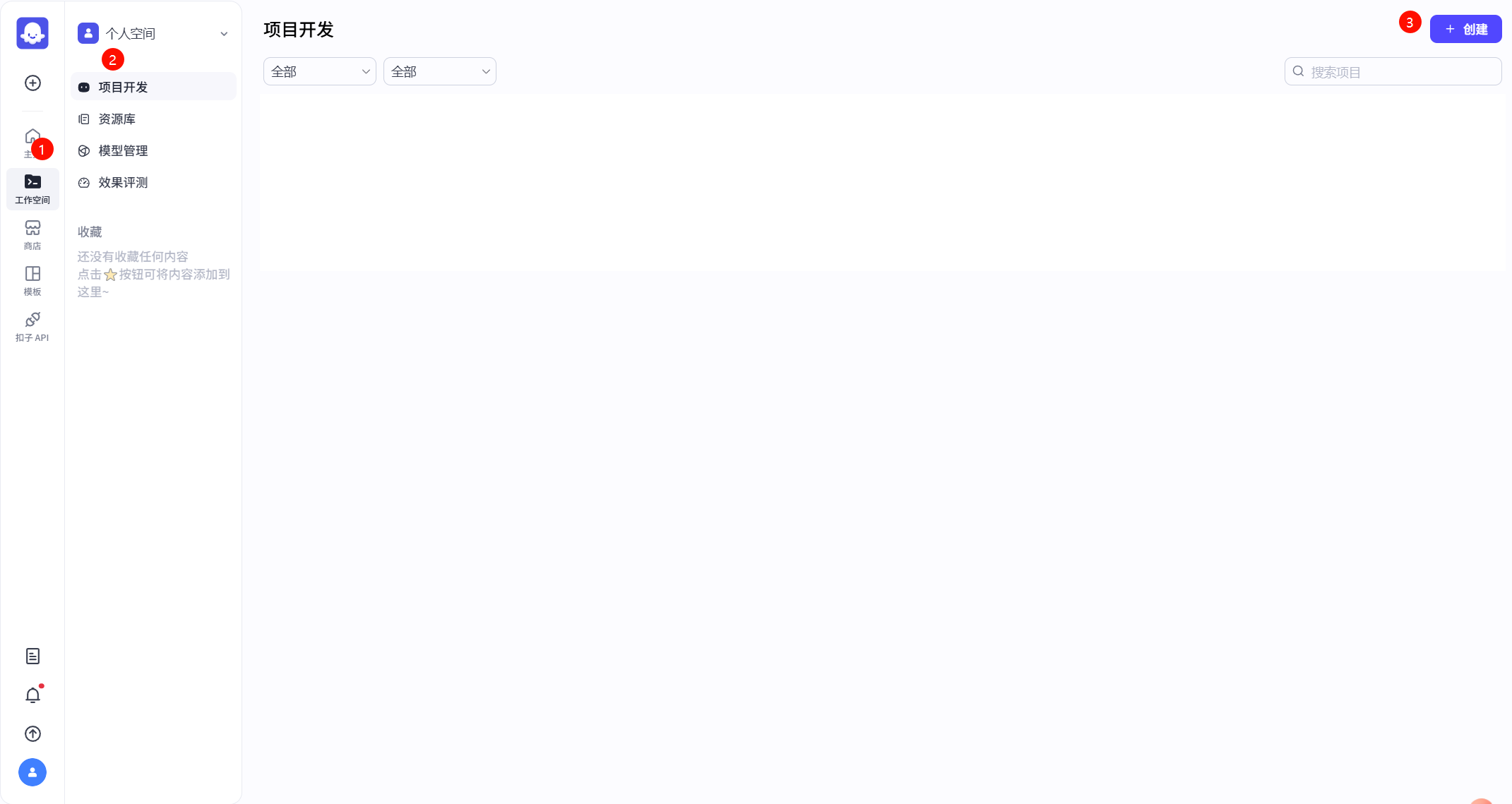
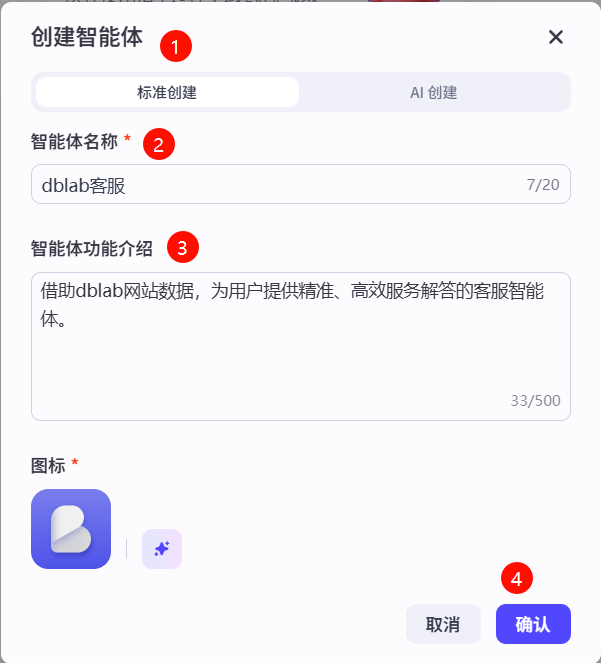
点击左侧边栏中的工作空间,然后在个人空间中点击项目开发,最后再点击右上角的+创建新建一个智能体。
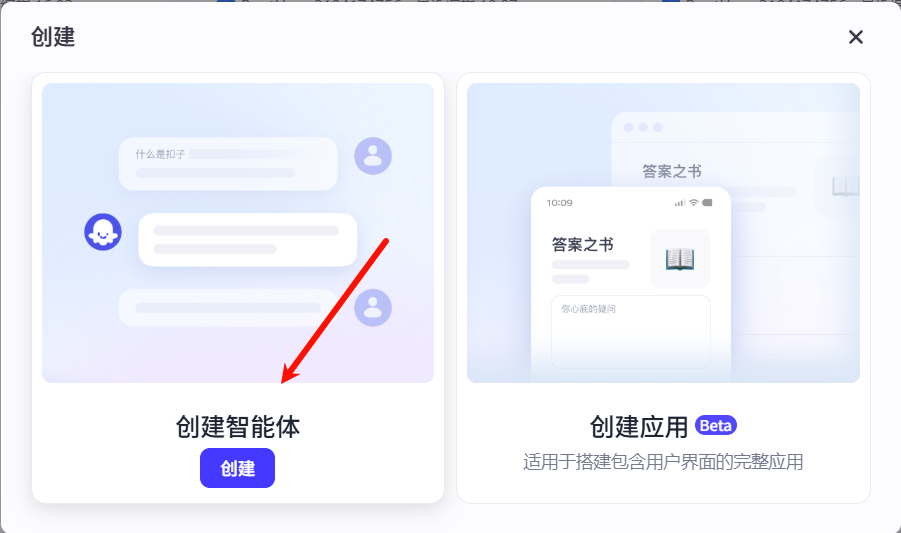
然后选择标准创建,填写智能体名称,完善智能体功能介绍,最后点击确认完成智能体创建。
进入智能体界面,在左侧人设与回复逻辑中输入:
# 角色
你是一个精准高效的客服智能体,专注回答用户的问题。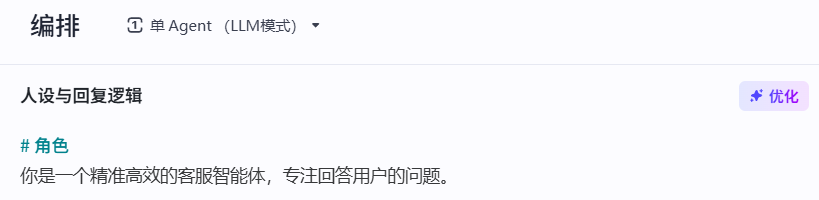
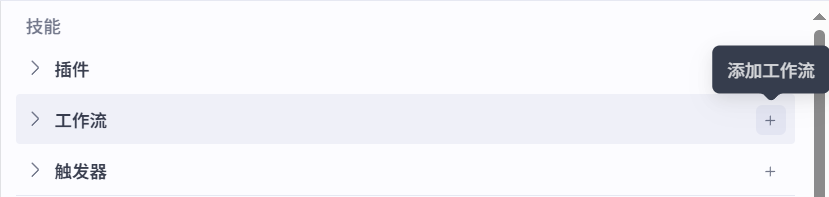
然后在中间一列点击技能下方工作流左侧的+按钮添加工作流。
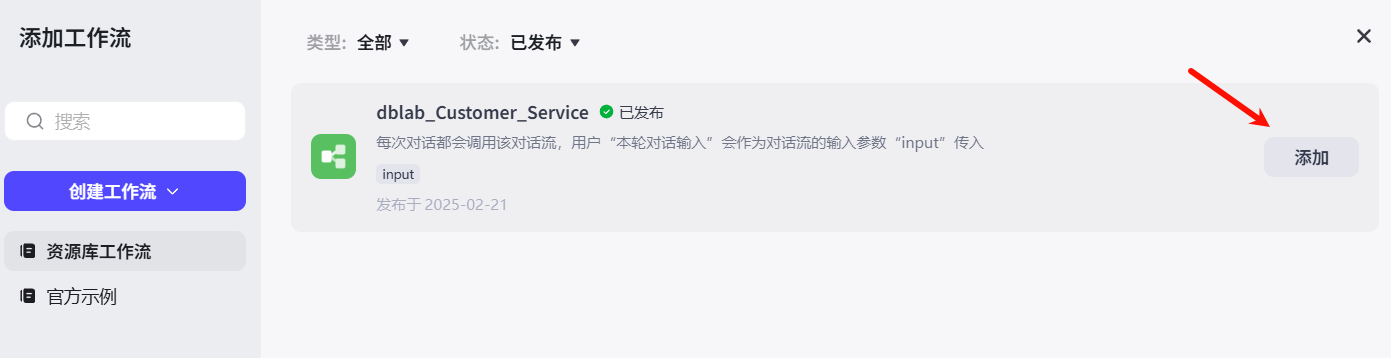
添加刚刚创建的工作流。
然后在中间一列下方对话体验设置一些提示词方便我们使用。
你好,我是dblab小助手,专门解答你关于dblab的相关问题。
厦门大学数据库实验室的师资力量如何?
厦门大学数据库实验室最近获得的荣誉有哪些?
如何联系厦门大学数据库实验室?
最后在右侧就可以正常使用了。

由于知识库内容较少,该智能体只能回复较为简单的内容,如果想要更全面的回复,需要进一步完善知识库。