作者:厦门大学信息学院计算机科学系2023级研究生 曹基民
指导老师:厦门大学数据库实验室 林子雨 博士/副教授
系统要求:win10及以上
硬盘空间:10G以上
硬件要求:
CPU:Intel Core i5/AMD Ryzen 5及以上
GPU:无强制要求,有1GB及以上显存可提升性能
Ollama
1.安装Ollama
访问Ollama官网下载Ollama安装包,或者可以访问百度网盘地址:https://pan.baidu.com/s/1kOcyzb3QGMnJOoIVXka4NA?pwd=ziyu ,提取码是ziyu,找到安装包OllamaSetup.exe,双击安装包安装界面如下图所示:

下载完成后双击打开安装程序,点击Install即可一键安装,安装完成后程序会自动退出。
2.验证Ollama
使用win+r组合键打开"运行"对话框,输入cmd后按下回车打开命令行界面。
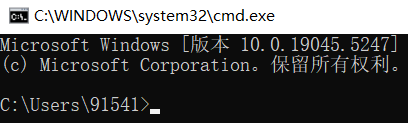
在命令行界面输入
ollama --version出现如下显示说明Ollama安装成功。

DeepSeek
1.安装DeepSeek
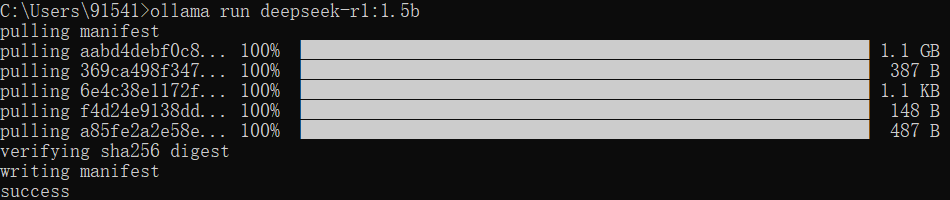
在命令行界面输入
ollama run deepseek-r1:1.5b可以快速安装deepseek-r1:1.5b模型,安装成功后的结果如下图所示。
2.验证DeepSeek
可以在命令行界面的>>>后输入who are you来验证,成功安装的结果如下所示。

AnythingLLM
1.安装AnythingLLM
访问AnythingLLM官网下载AnythingLLM安装包,或者可以访问百度网盘地址:https://pan.baidu.com/s/1kOcyzb3QGMnJOoIVXka4NA?pwd=ziyu ,提取码是ziyu,找到安装包AnythingLLMDesktop.exe,双击安装包安装界面如下图所示:
下载完成后双击打开安装程序,点击下一步。
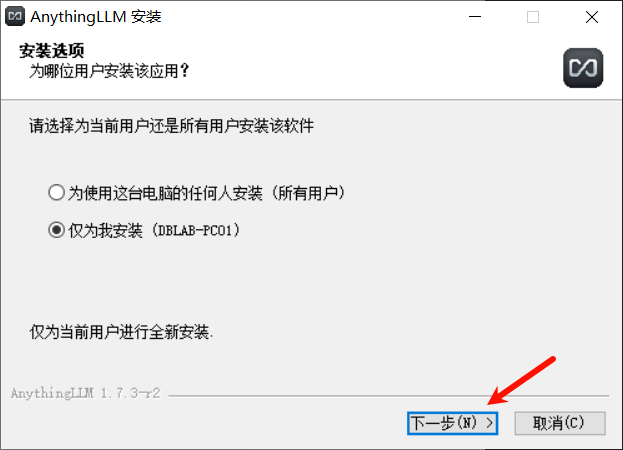
注意:如果双击打开安装程序后出现被windows防火墙拦截的界面,点击
更多信息,然后点击仍要运行,之后,就可以正常安装了。
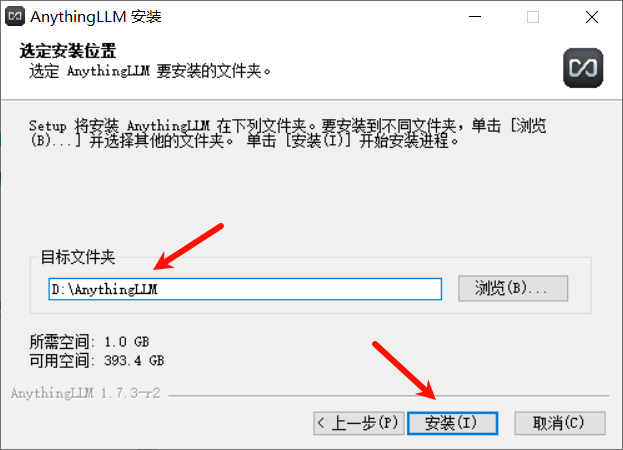
然后选择安装位置然后点击安装。
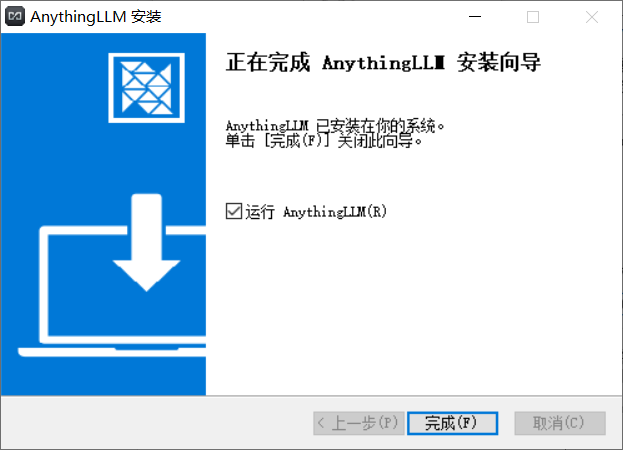
等待一段时间后出现如下界面说明安装完成。
2.配置AnythingLLM
双击桌面AnythingLLM图标打开,首次启动会出现Get started,点击即可。
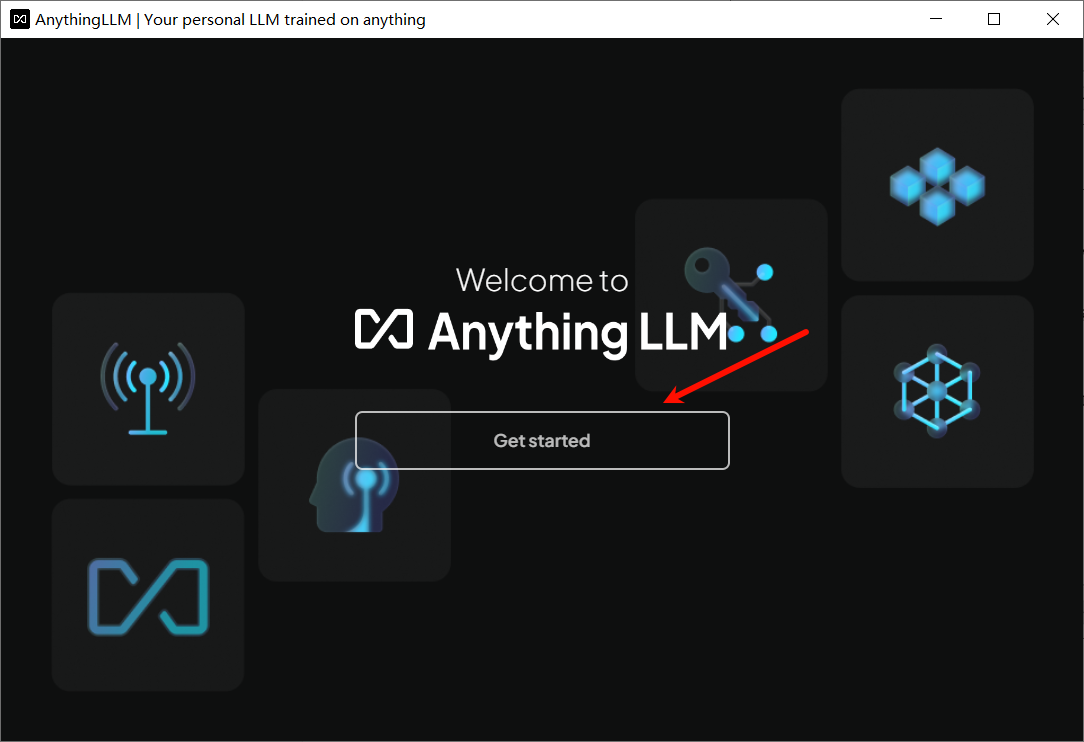
接着直接点击右箭头,配置稍后再做。
继续点击右箭头。
继续点击右箭头。
起一个工作区名称然后点击右箭头进入工作界面。
在工作界面左侧点击扳手按钮进入设置界面。
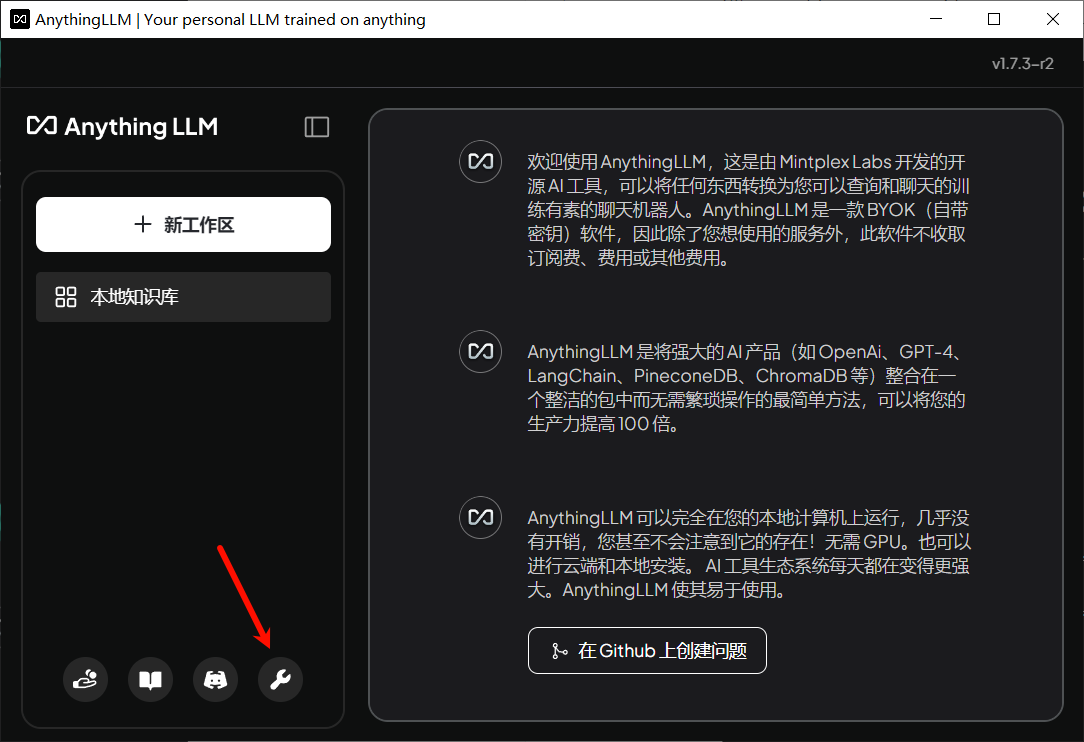
在设置界面左侧人工智能提供商下的LLM首选项中进行相关配置,如果已经正确安装了Ollama并下载了deepseek-r1:1.5b,那么只需要在右侧LLM提供商下拉列表中选中Ollama,相关信息会被自动填充到相应位置,然后点击Save changes即可。
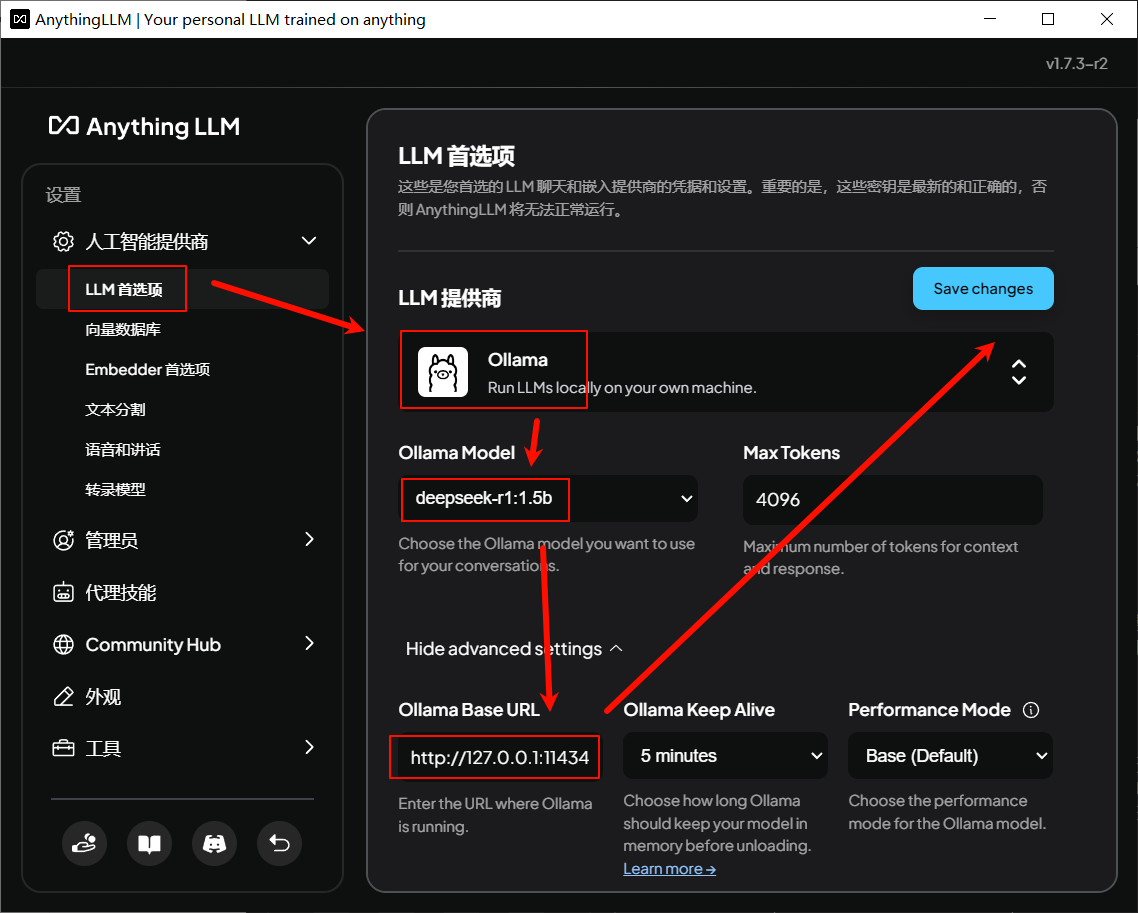
3.使用AnythingLLM
点击刚刚创建的工作区,然后点击upload a document进入文件上传界面。
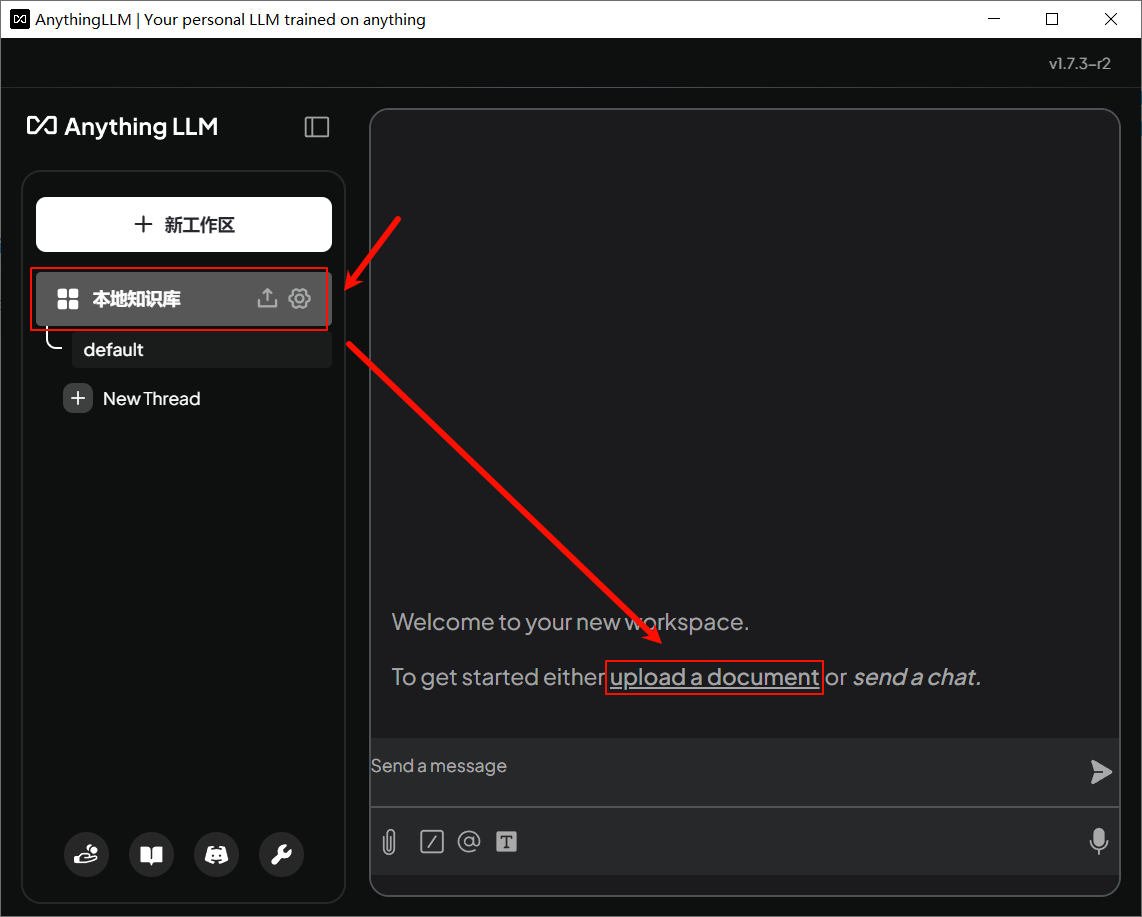
点击上传或拖拽一个文件。
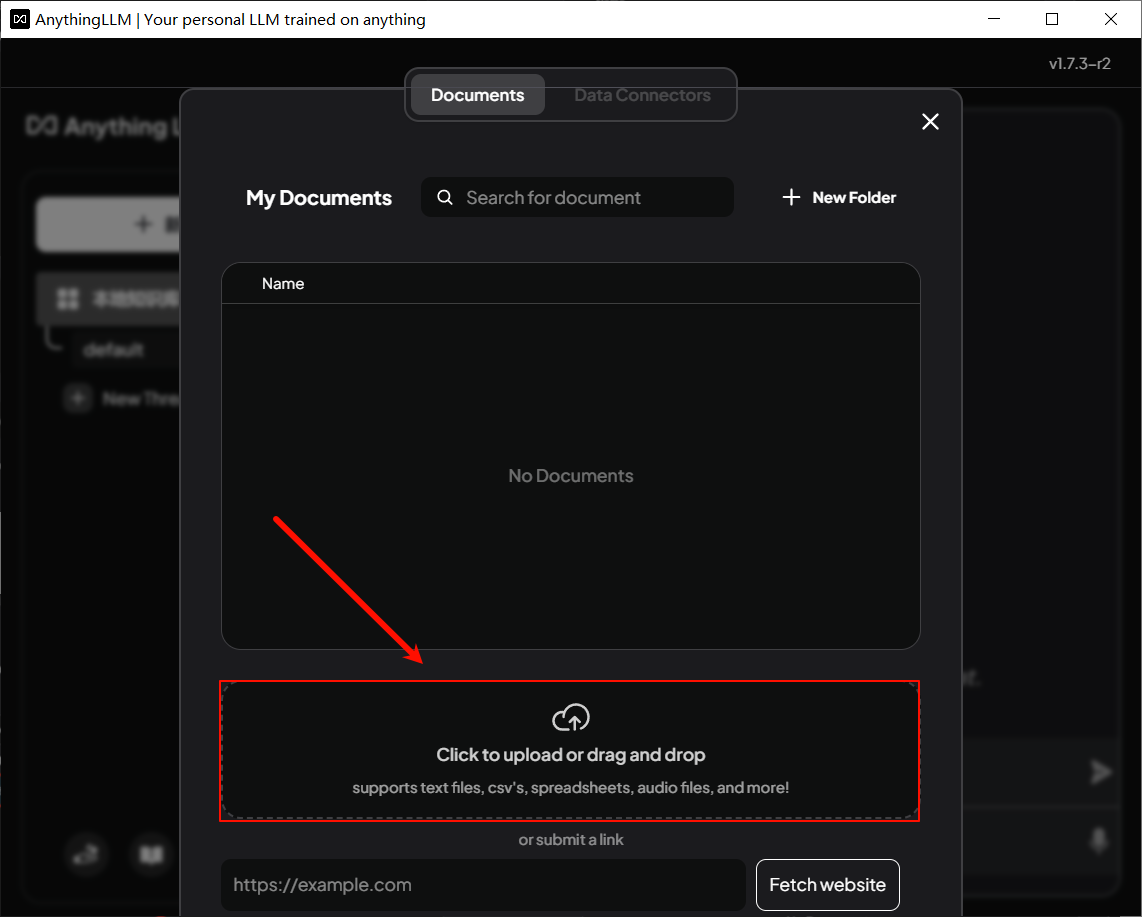
然后选中刚刚上传的文件并点击Move to Workspace将文件加载到AnythingLLM的本地知识库中。
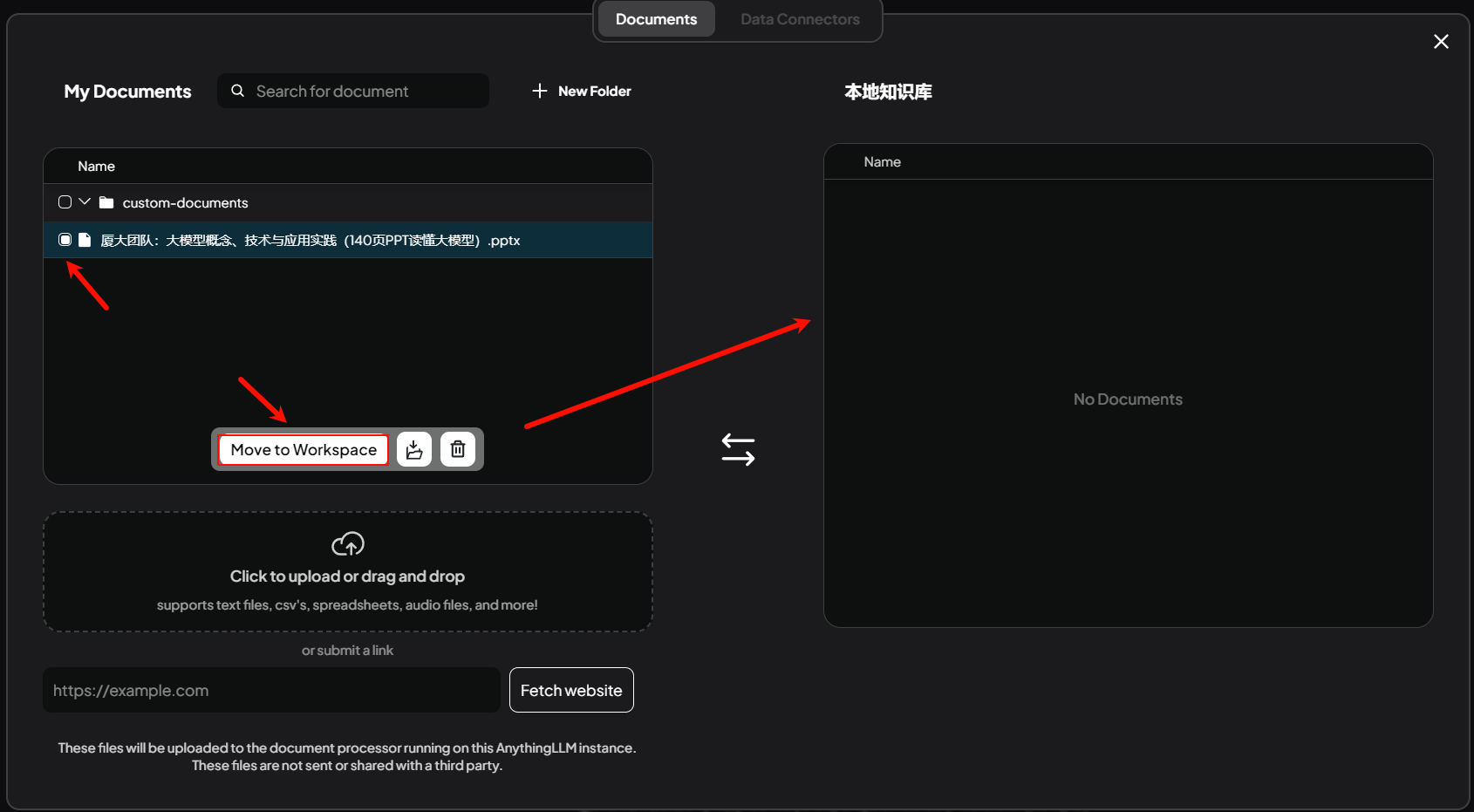
然后点击Save and Embed。
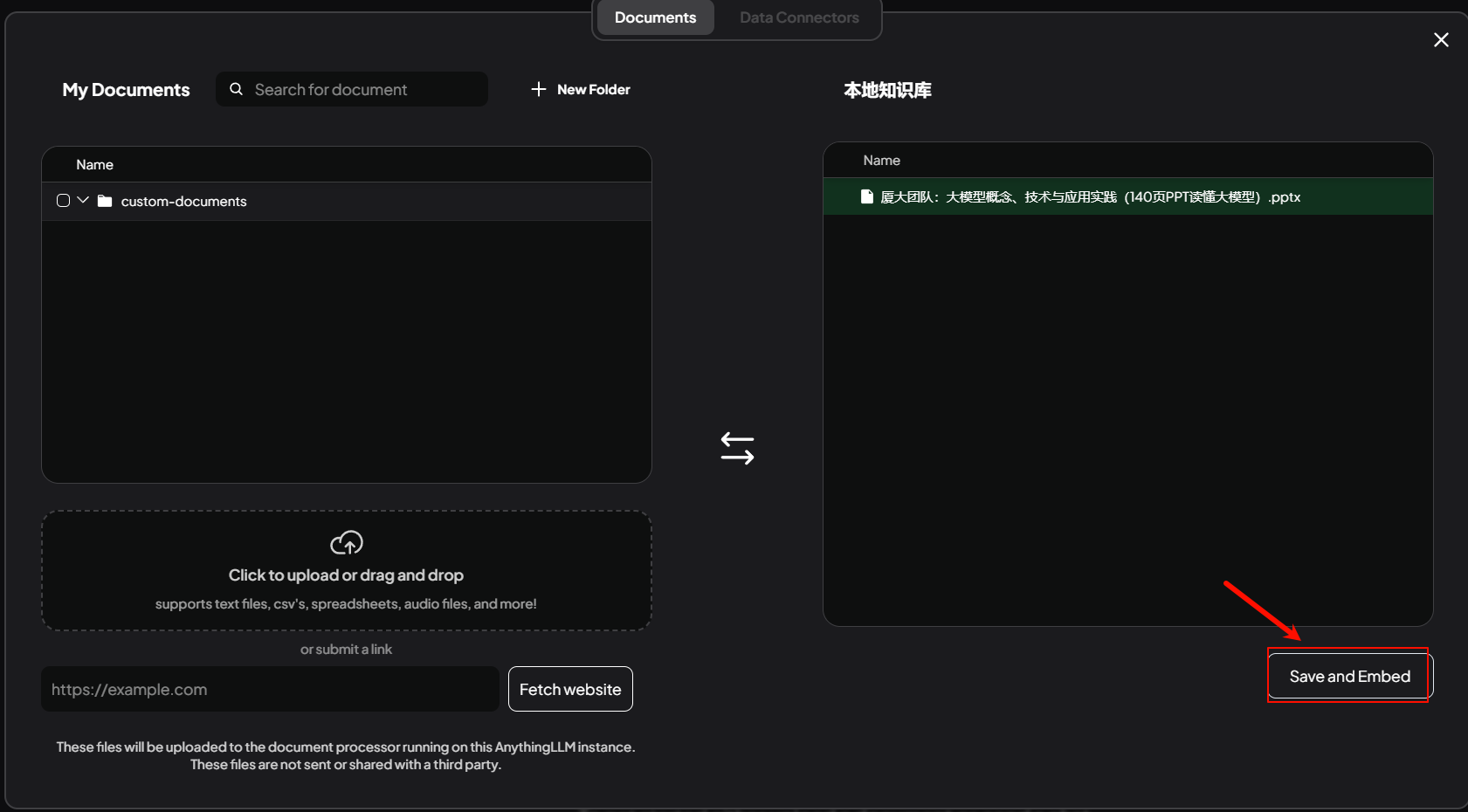
出现Workspace updated successfully就表示知识库配置已经完成。
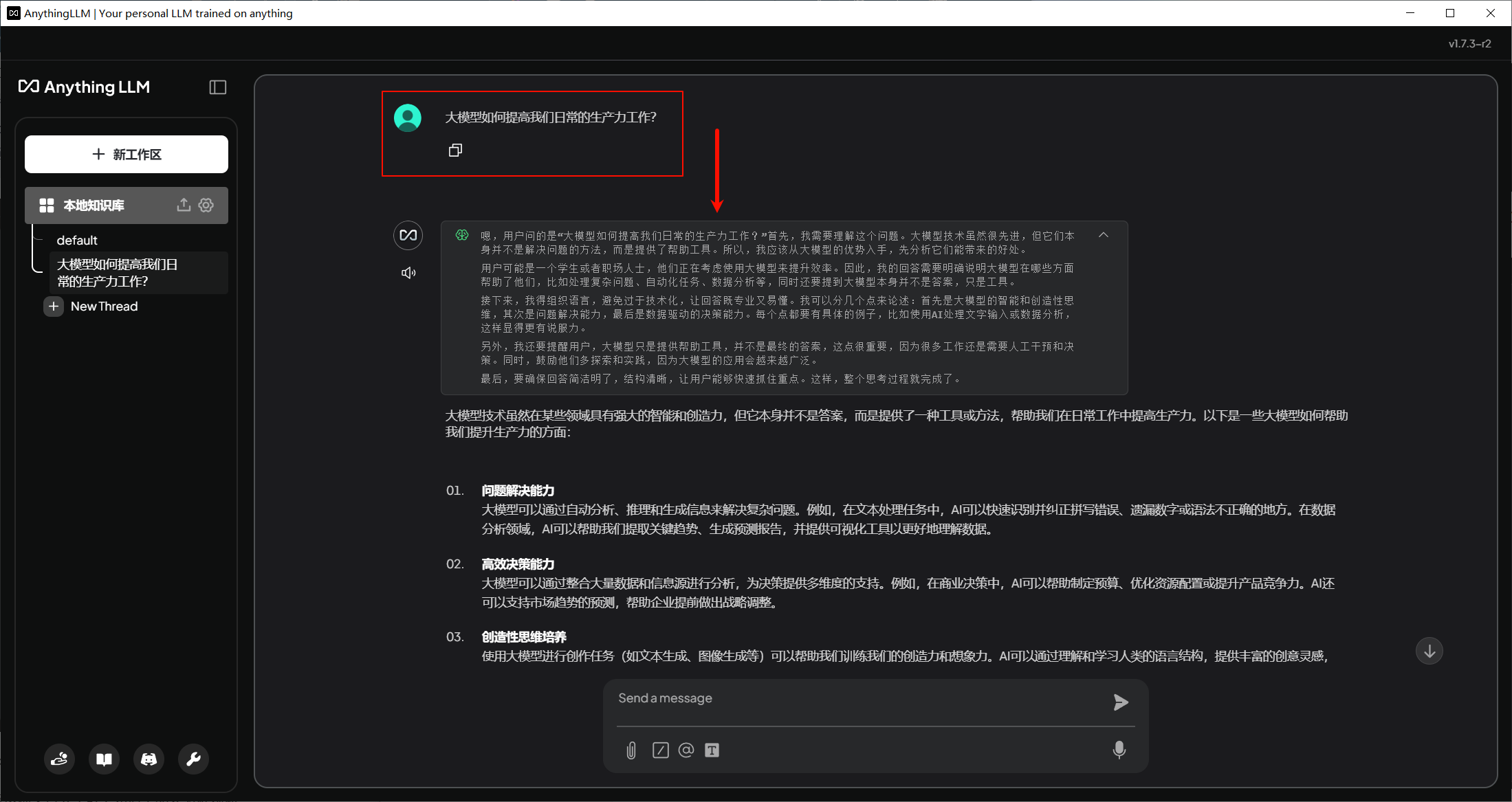
然后点击New Thread就可以开始一个新的对话了。

提问后,AI会根据知识库中的内容进行回答。
如果想确认AI回答的知识来源,可以在回答底部点击Show Citations查看引用的知识。
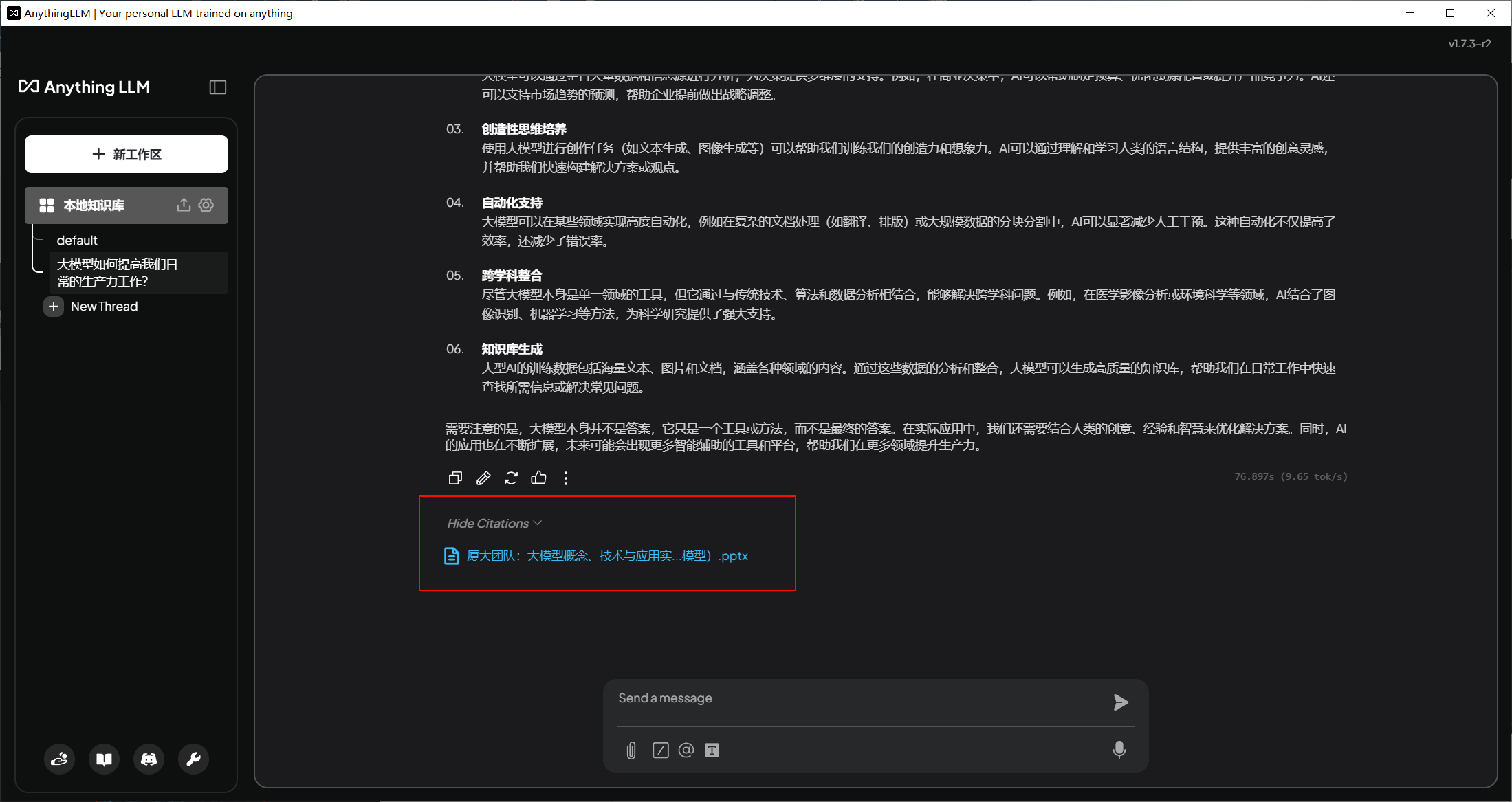
所有与
AnythingLLM Desktop有关的数据将位于以下位置:
C:\Users\\AppData\Roaming\anythingllm-desktop\storage
目录下各个文件夹的含义:
- lancedb:这是存储您的本地矢量数据库及其表的地方。
- documents:这是任何上传文件的解析文档内容。
- vector-cache:此文件夹是之前上传并嵌入的文件的缓存和嵌入表示。其文件名经过哈希处理。
- models:系统使用的任何本地存储的LLM或Embedder模型都存储在此处。通常是GGUF文件。
- anythingllm.db:这是AnythingLLM SQLite数据库。
- plugins:这是存储您的自定义代理技能的文件夹。
一些问题
1.Show Citations太少
当您使用了多篇文档构建本地知识库时,AnythingLLM的回答仅使用了一篇或少部分文档,即Show Citations展示的文档数量较少,这可能是由于以下三个原因造成的:
- 提出的问题不需要那么多文档就可以回答。
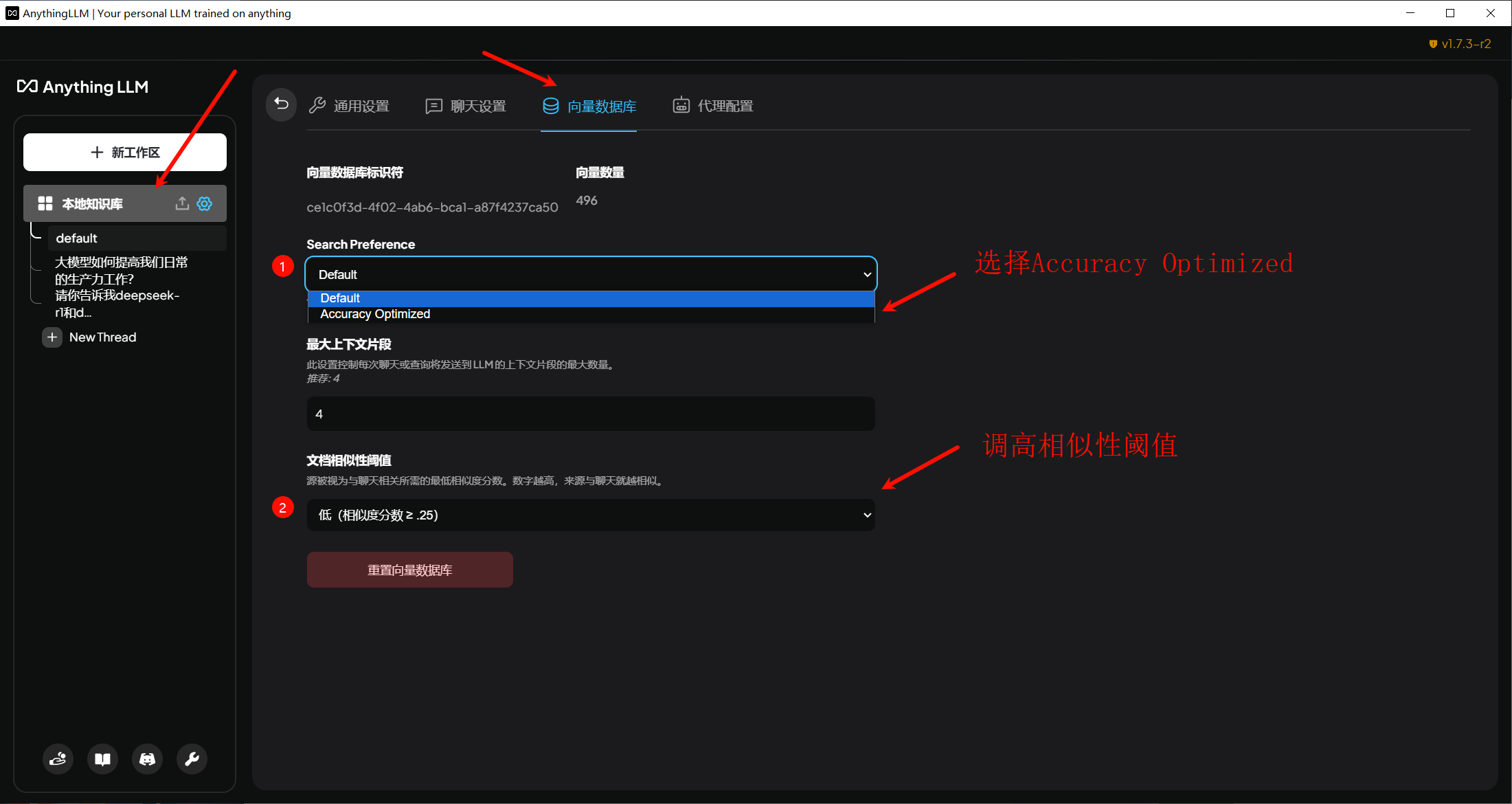
- 应当修改向量数据库的搜索偏好为
Accuracy Optimized,这将搜索更多文本块。 - 应当提高文档相似性阈值,这会减少筛选掉可能与查询无关的低分矢量块的概率。
可能不需要同时使用以上三种方法。
向量数据库搜索偏好和文档相似性阈值修改位置: