【版权声明】版权所有,严禁转载,严禁用于商业用途,侵权必究。
作者:厦门大学信息学院2021级研究生 陈韶聪
基于Scala语言的Spark数据处理分析案例
案例制作:厦门大学数据库实验室
指导老师:厦门大学信息学院计算机系数据库实验室 林子雨 博士/副教授 E-mail: ziyulin@xmu.edu.cn
相关教材:林子雨,赖永炫,陶继平《Spark编程基础(Scala版)》(访问教材官网)
【查看基于Scala语言的Spark数据分析案例集锦】
一、实验环境搭建
(1)Linux:Ubuntu20.04.4
(2)Hadoop:3.1.3
(3)Spark:3.2.0
(4)Python:3.8
(5)运行环境:IDEA22.1.1
(6)Pyecharts:1.9.1
二、数据预处理
本项目使用的数据集是来自Kaggle网站的Spotify – All Time Top 2000s Mega Dataset,可以直接从百度网盘下载(提取码:ziyu)。此数据集包含Spotify上前2000首曲目的音频统计数据。数据包含1956年至2019年发行的歌曲包括一些著名艺术家,如皇后乐队、披头士乐队等。本次项目使用此数据集Spotify-2000.csv。其中数据包含以下字段:
1) Index: ID
2) Title: 歌曲名称
3) Artist: 歌手姓名
4) Top Genre: 歌曲类型/流派
5) Year: 歌曲发行年份
6) Beats per Minute(BPM): 每分钟节拍数
7) Energy: 歌曲的能量,值越高,歌曲越具有能量
8) Danceability: 可跳舞性,值越高,越易于伴歌而舞
9) Loudness: 响度,值越高,歌曲越响亮
10) Valence: 效价(情绪),值越高,这首歌的情绪就越积极正能量
11) Length: 歌曲时长
12) Acoustic: 原声,值越高,歌曲的原声性越强对应为不插电
13) Speechiness: 口语化,值越高,歌词越口语化
14) Popularity: 流行度,值越高,歌曲越流行
将数据上传到HDFS中
/usr/local/hadoop/sbin/start-dfs.sh
./bin/hdfs dfs -mkdir -p /user/hadoop
./bin/hdfs dfs -put ~/Downloads/Spotify-2000.csv三、Spark进行数据分析
创建spark环境,读取数据,使用spark sql分析
val conf: SparkConf = new SparkConf().setAppName(getClass.getName).setMaster("local[*]")
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
//读取数据
val inputDF: Dataset[Row] = spark.read
.format("csv")
.option("header", "true")
.load("input/Spotify-2000.csv")
inputDF.show()
inputDF.createOrReplaceTempView("music_info")
//1)统计各种类型的音乐数量
val resDF01: DataFrame = spark.sql("select `Top Genre` Genre, count(*) cnt from music_info group by Genre")
resDF01.show()
//2)统计各个音乐人在榜单中的歌曲数目
val resDF02: DataFrame = spark.sql("select Artist, count(*) cnt from music_info group by Artist")
resDF02.show()
//3)统计各个年份在榜单中的歌曲数目并排序
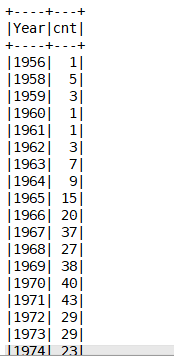
val resDF03: DataFrame = spark.sql("select Year, count(*) cnt from music_info group by Year order by Year")
resDF03.show()
//4)统计所有歌曲名称中的词频并排序
val resDF04: DataFrame = spark.sql(
"""
|select word, count(*) cnt from (
| select explode(split(Title,' ')) word from music_info
|)
|where length(word) > 2
|group by word order by cnt desc
""".stripMargin)
resDF04.show()读取原始数据运行结果

统计各种类型的音乐数量
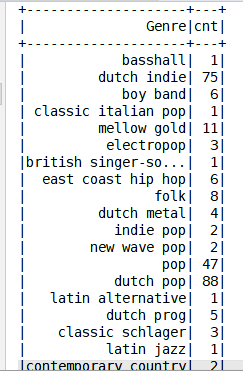
统计各个音乐人在榜单中的歌曲数目

统计各个年份在榜单中的歌曲数目
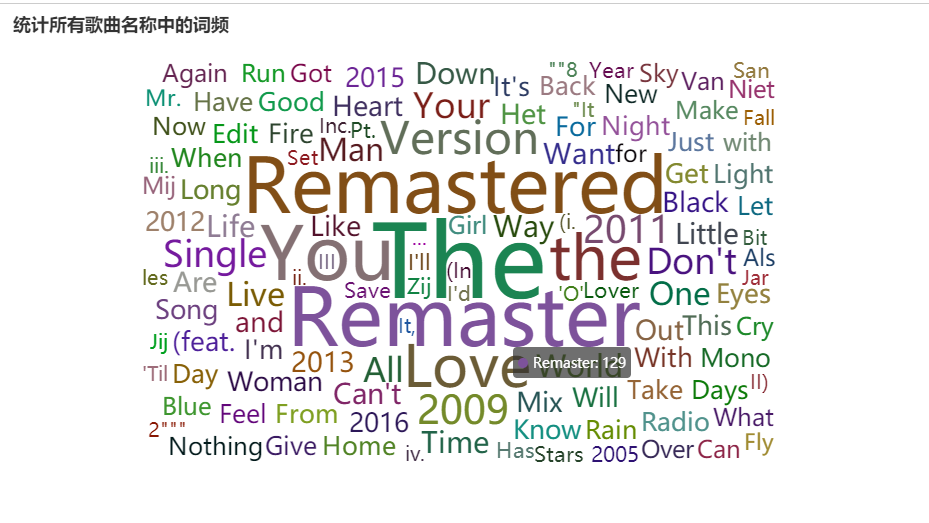
统计所有歌曲名称中的词频

四、结果可视化
将spark分析的结果保存为json文件,代码如下
//结果保存
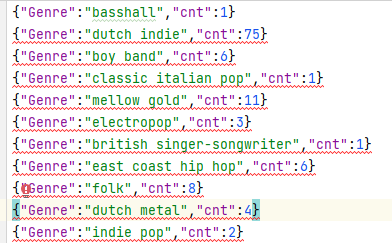
resDF01.repartition(1).write.mode(SaveMode.Overwrite).json("output/01")
resDF02.repartition(1).write.mode(SaveMode.Overwrite).json("output/02")
resDF03.repartition(1).write.mode(SaveMode.Overwrite).json("output/03")
resDF04.repartition(1).write.mode(SaveMode.Overwrite).json("output/04")查看部分保存结果
使用pyecharts可视化
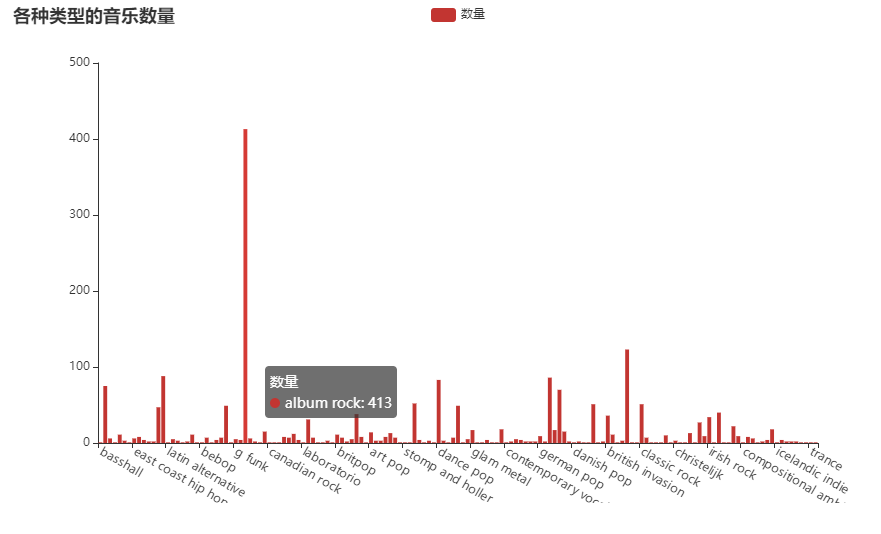
1)统计各种类型的音乐数量
# 1) 统计各种类型的音乐数量并排序
def drawChart_1():
root = "output/01/part-00000-30dd174e-b804-435e-b04b-1ec8dfd7df29-c000.json"
date = []
cases = []
with open(root, 'r',encoding='utf-8') as f:
while True:
line = f.readline()
if not line: # 到 EOF,返回空字符串,则终止循环
break
js = json.loads(line)
date.append(str(js['Genre']))
cases.append(float(js['cnt']))
d = (
Bar()
.add_xaxis(date)
.add_yaxis("数量", cases, stack="stack1")
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(xaxis_opts=opts.AxisOpts(axislabel_opts={"rotate": -30}))
.set_global_opts(title_opts=opts.TitleOpts(title="各种类型的音乐数量"))
.render("output_html/result1.html")
)
2) 统计各个音乐人在榜单中的歌曲数目并排序
# 2) 统计各个音乐人在榜单中的歌曲数目并排序
def drawChart_2():
root = "output/02/part-00000-3db30471-76ad-418e-9686-a14f3e267e90-c000.json"
state = []
totalDeath = []
with open(root, 'r') as f:
while True:
line = f.readline()
if not line: # 到 EOF,返回空字符串,则终止循环
break
js = json.loads(line)
state.insert(0, str(js['Artist']))
totalDeath.insert(0, int(js['cnt']))
c = (
PictorialBar()
.add_xaxis(state)
.add_yaxis(
"",
totalDeath,
label_opts=opts.LabelOpts(is_show=False),
symbol_size=18,
symbol_repeat="fixed",
symbol_offset=[0, 0],
is_symbol_clip=True,
symbol=SymbolType.ROUND_RECT,
)
.reversal_axis()
.set_global_opts(
title_opts=opts.TitleOpts(title="各个音乐人在榜单中的歌曲数目"),
xaxis_opts=opts.AxisOpts(axistick_opts=opts.AxisTickOpts(is_show=True),
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(opacity=0)
),),
# toolbox_opts=opts.ToolboxOpts(is_show=True),
yaxis_opts=opts.AxisOpts(
axistick_opts=opts.AxisTickOpts(is_show=True),
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(opacity=0)
),
),
)
.render("output_html/result2.html")
)
3) 统计各个年份在榜单中的歌曲数目并排序
# 3) 统计各个年份在榜单中的歌曲数目并排序
def drawChart_3():
root = "output/03/part-00000-df90099a-fe10-4ba9-80f7-6dd8b9d67f67-c000.json"
date = []
cases = []
with open(root, 'r',encoding='utf-8') as f:
while True:
line = f.readline()
if not line: # 到 EOF,返回空字符串,则终止循环
break
js = json.loads(line)
date.append(str(js['Year']))
cases.append(float(js['cnt']))
(
Line(init_opts=opts.InitOpts(width="1600px", height="800px"))
.add_xaxis(xaxis_data=date)
.add_yaxis(
series_name="歌曲数目",
y_axis=cases,
markpoint_opts=opts.MarkPointOpts(
data=[
opts.MarkPointItem(type_="max", name="最大值")
]
),
markline_opts=opts.MarkLineOpts(
data=[opts.MarkLineItem(type_="average", name="平均值")]
),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="各个年份在榜单中的歌曲数目", subtitle=""),
tooltip_opts=opts.TooltipOpts(trigger="axis"),
toolbox_opts=opts.ToolboxOpts(is_show=True),
xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=False),
)
.render("output_html/result3.html")
)
4) 统计所有歌曲名称中的词频并排序
# 4) 统计所有歌曲名称中的词频并排序
def drawChart_4():
root = "output/04/part-00000-b1f2d35d-1276-4a00-af5d-34374116abe8-c000.json"
data = []
with open(root, 'r',encoding='utf-8') as f:
while True:
line = f.readline()
if not line: # 到 EOF,返回空字符串,则终止循环
break
js = json.loads(line)
row = (str(js['word']), int(js['cnt']))
data.append(row)
c = (
WordCloud()
.add("", data, word_size_range=[20, 100], shape=SymbolType.DIAMOND)
.set_global_opts(title_opts=opts.TitleOpts(title="统计所有歌曲名称中的词频"))
.render("output_html/result4.html")
)